1. Introduction
The prognostics and health management (PHM) of aircraft engines has received increasing attention owing to the fast development of deep learning. Remaining useful life (RUL) estimation, which is a technical term used to describe the progression of faults in PHM [
1], is defined as the time from the current moment to the end of the useful life. In traditional industry, RUL estimation mainly depends on the physical model-based method. In the first international conference on prognostics and health management, Saxena et al. [
2] used a damage propagation model to predict the RUL value. In comparison with other model-based methods (e.g., Arrhenius and Eyring models), Saxena achieved a better performance. Owing to the highly nonlinear features, it is difficult to improve the performance to a relatively large extent on physical model-based methods.
Apart from model-based methods, data-based methods have become more popular and are widely used in the industry. With the attribution of the fast development of neural networks (NN) [
3], data-based methods have achieved great progress in RUL problems. Heimes proposed a method based on recurrent neural networks (RNN) [
4], whereas Peel proposed a method using a Kalman filter based on NN [
5], both of which have achieved excellent performance in the PHM08 conference. To date, convolutional neural networks (CNN) and RNN have become the most important branches of NN. Thus, great achievements have been realized in signal processing [
6] and motion captures [
7]. Several advanced networks have been proposed based on CNN and RNN (for instance, deep convolution neural networks (DCNN) [
8,
9], echo state networks [
10], and long short-term memory networks (LSTM) [
11]).
Compared with manually designed networks, whose performances are mainly dominated by the fixed network architecture and hyper parameters, neural architecture search (NAS) is a more efficient method to design a proper architecture [
12]. The performance of NAS mainly depends on the transformative network architecture and NAS has achieved success in image classification and semantic segmentation [
13,
14]. According to different methods used in the architecture search, the search strategies can be divided into several categories: random search, reinforcement learning (RL), evolutionary algorithm, Bayesian optimization (BO), and gradient-based algorithm [
15]. To solve the NAS problem in a RL method [
16,
17], the generation of a neural architecture can be considered to be the agent’s action, and the search space is considered the action space. The performance of the candidate architecture is identical to the agent’s reward. However, because of the reason that there is no external observed state and intermediate rewards, the RL method on NAS is more similar to a stateless multi-armed bandit problem. The first method of an evolutionary algorithms for network architecture dates back to the work of Miller at al. [
18] in which the genetic algorithm is proposed to design architectures and backpropagation is used to optimize the weights. Since then, many works have used similar methods to optimize the network architecture weights [
19,
20,
21]. Bayesian optimization on NAS was first proposed by Swersky et al. [
22] and Kandasamy et al. [
23]; in their works, kernel functions is derived for architecture search spaces in order to use classic GP-based BO methods.
Different from these approaches, a softmax function is used to optimize the edge parameters, making the search space a continuous from, and thereafter, differentiable architecture search (DARTS) can be used for the architecture search [
24]. Both network weights and architecture parameters are optimized by alternating gradient descent steps on the differentiable loss function. By choosing the operation with the best performance on every edge, the best architecture is obtained. The continuous search strategy remarkably reduces the search cost. A problem with DARTS is that a collapse in performance usually happens when the search epoch becomes large. The “early stopping” strategy is proposed to solve these problems without degrading the performance [
25]. Furthermore, a partial channel strategy is proposed to reduce the search cost with only a slight influence on the network performance [
26].
Until now, most of the research has preferred to use a human-designed network to give a solution in RUL problems [
27]. NAS has been applied to the RUL problem in a few works. A gradient descent method is proposed to search for the best architecture in a continuous search space on a recurrent neural network [
28]; another solution is based on the evolutionary algorithm to explore the combinatorial parameter space of a multi-head CNN network with LSTM [
29]. The application of NAS on RUL problems does not need much preliminary research on the architecture of the artificial neural network, and thus, it is a efficient method to design a suitable network for RUL problems.
The remainder of this paper is organized as follows:
Section 2 introduces an outline of our proposed method, including a brief introduction of NAS and the basic algorithm of DARTS.
Section 3 introduces the C-MAPSS dataset, and thereafter, highlights the data processing and the fault detection.
Section 4 elucidates the experimental results and the superiority performance of our method in comparison with other related works. Finally,
Section 5 concludes the paper.
4. Experiments and Result Analysis
4.1. Experimental Platform
Our experimental device is a personal computer, with Intel Core i3 CPU, 16GB RAM and NVIDIA GTX 1070 GPU. The operating system is Windows 10 Professional and the programming language is Python 3.8 with the library PyTorch 1.7.1.
4.2. Architecture Search
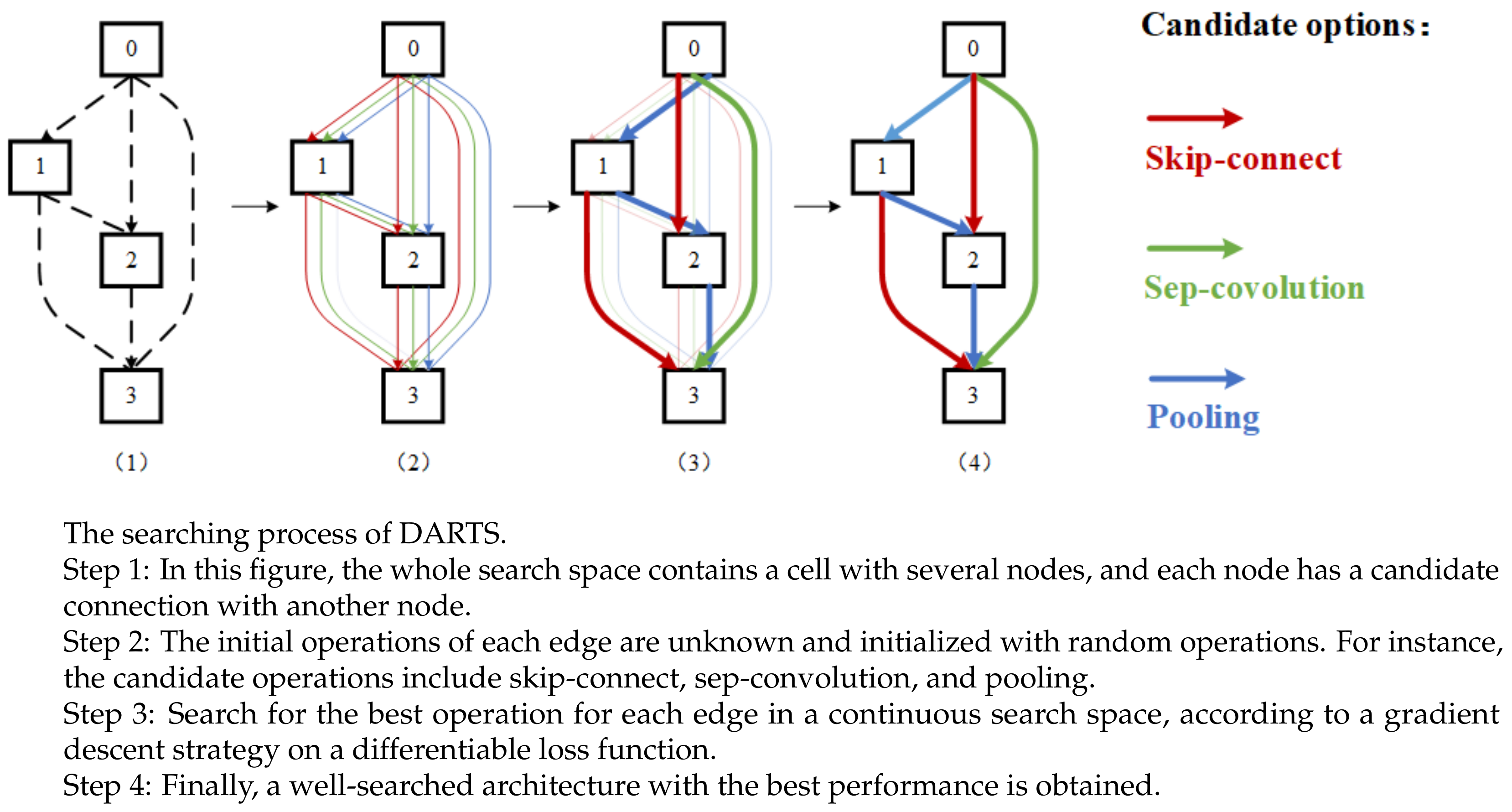
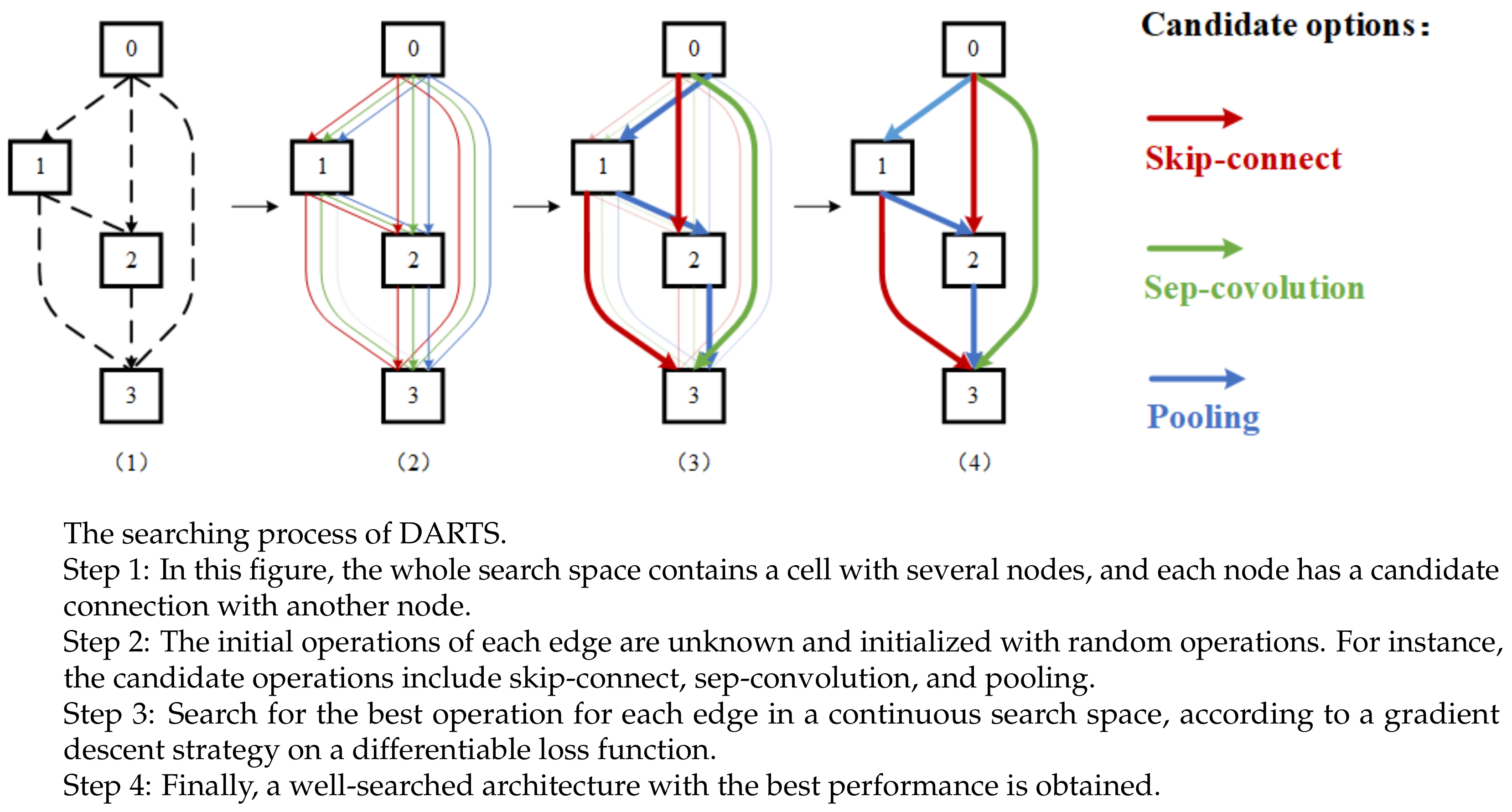
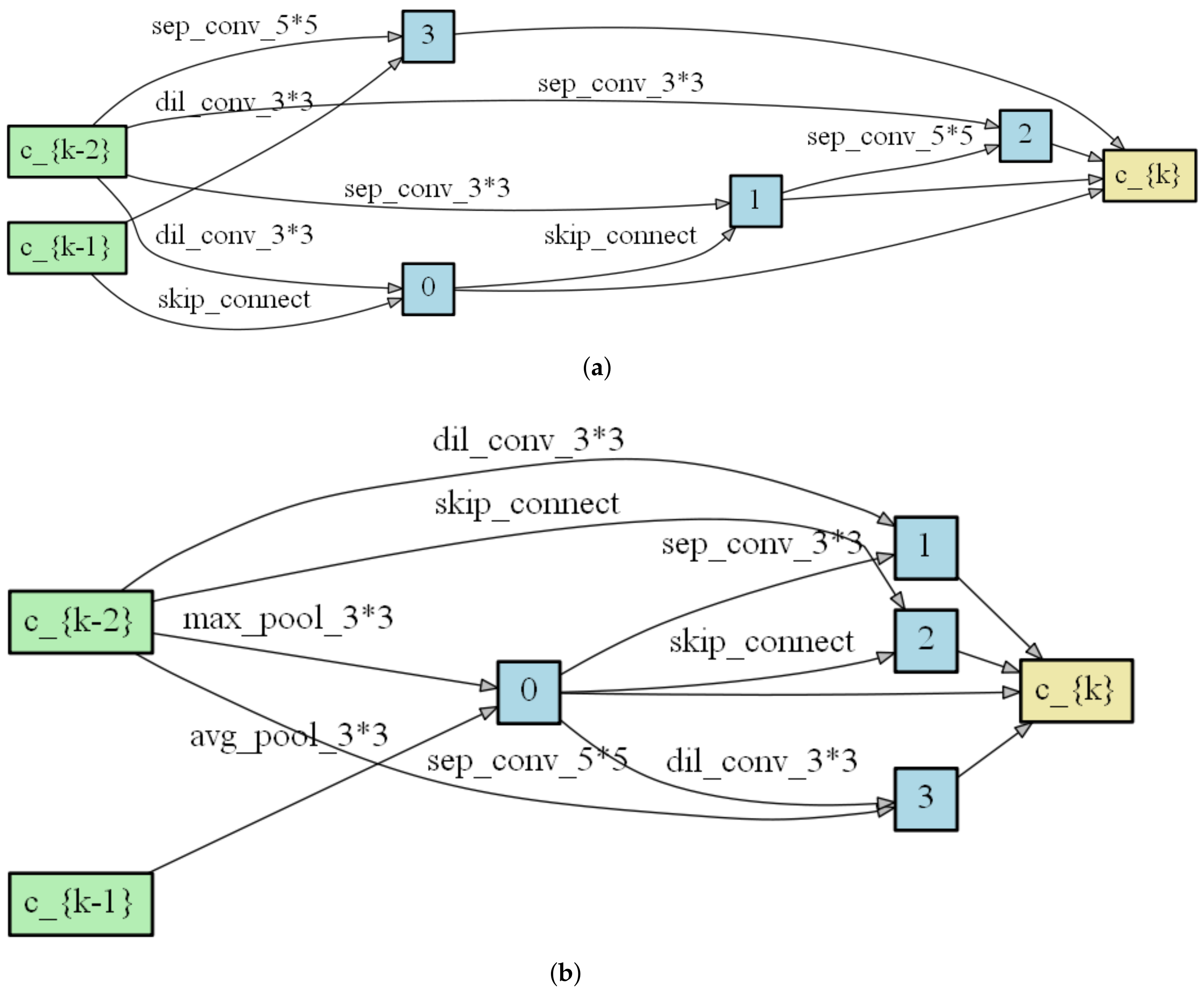
Our network training consists of two steps: cell architecture search and network weights training. In the search step, the aim is to search for a suitable architecture based on the performance of the valid set. In the training step, the aim is to update network weights and construct the entire network with the architectures obtained from the first step.
We propose a network with 10 cells—7 normal cells and 3 reduction cells—each containing
nodes. The search batch size is 64, with 200 search epochs and 36 initial channels. We run the network repeatedly several times with different random initial cell architectures. Then,
of the train set is randomly chosen for training use and the remaining
are for valid use. Adam optimizer [
34] is used with a learning rate of
, weight decay of
, and momentum of
. Finally, the normal cells and reduction cells are obtained, as shown in
Figure 5.
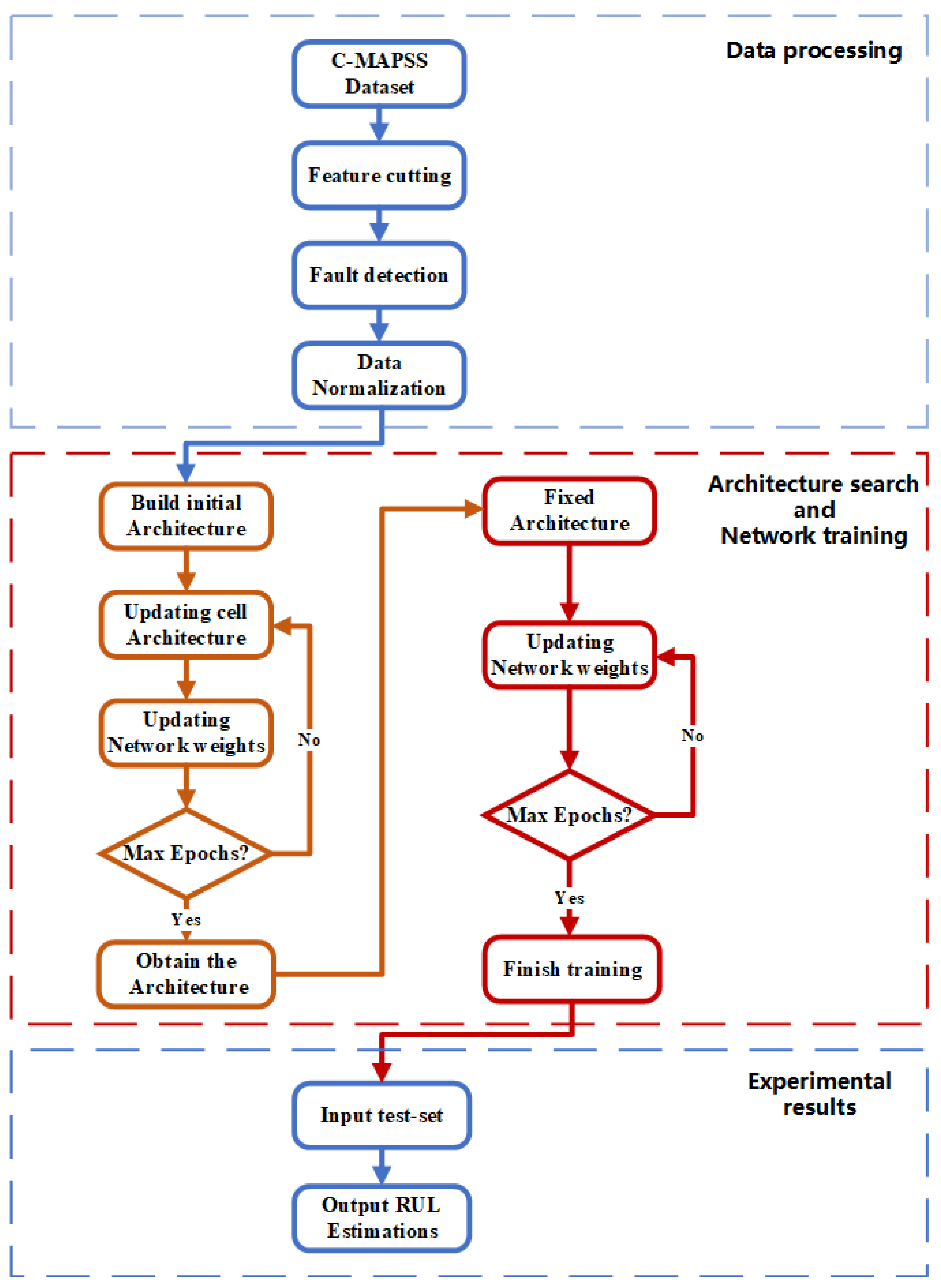
Figure 6 is a flowchart to give an introduction of our method for RUL problem. This flowchart contains three parts. The first part describes the pre-process of C-MAPSS dataset. The second part is process of network training, which includes architecture search and network weights updating. The third part is the experimental results.
4.3. Experimental Results on Single Fault Mode
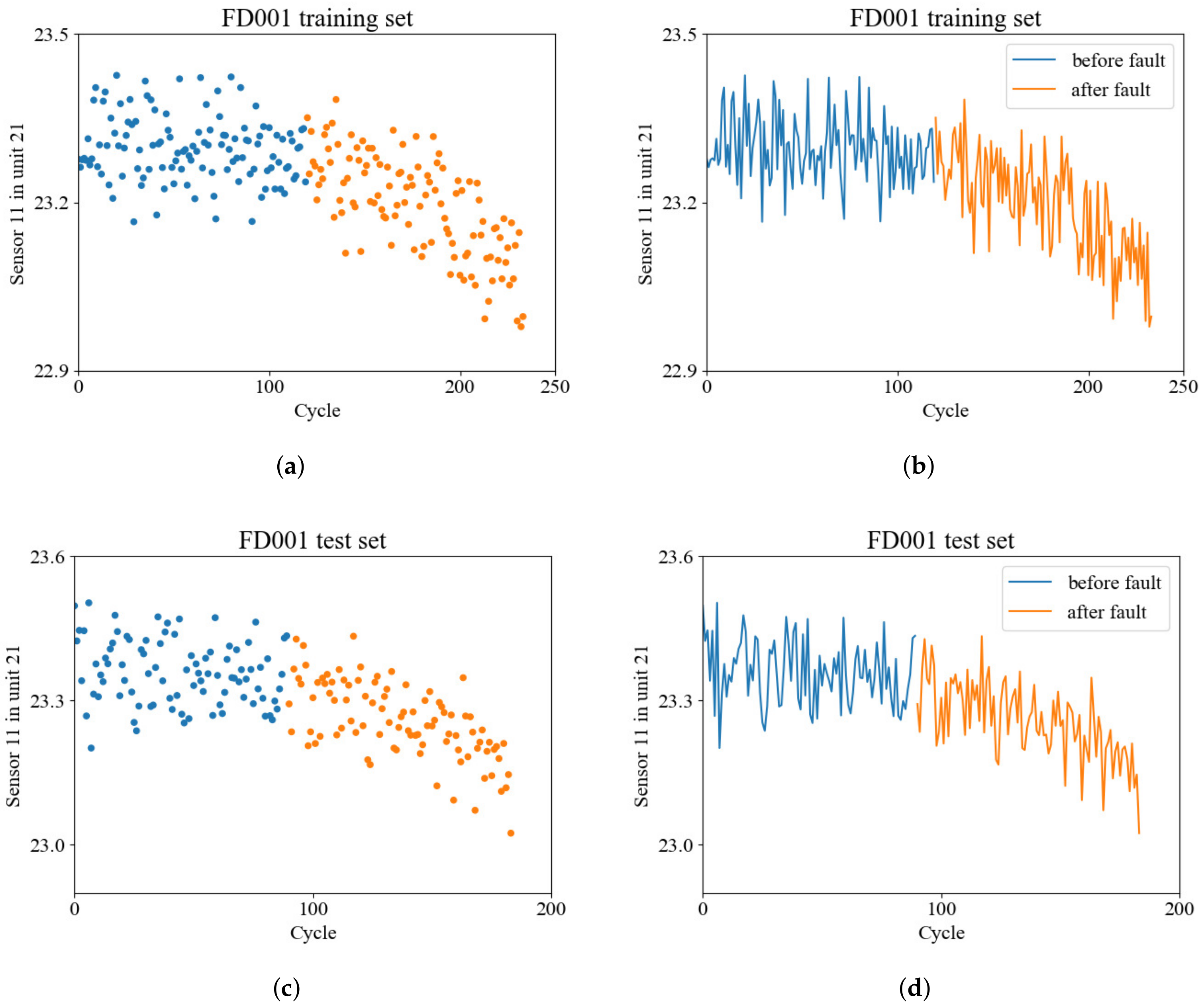
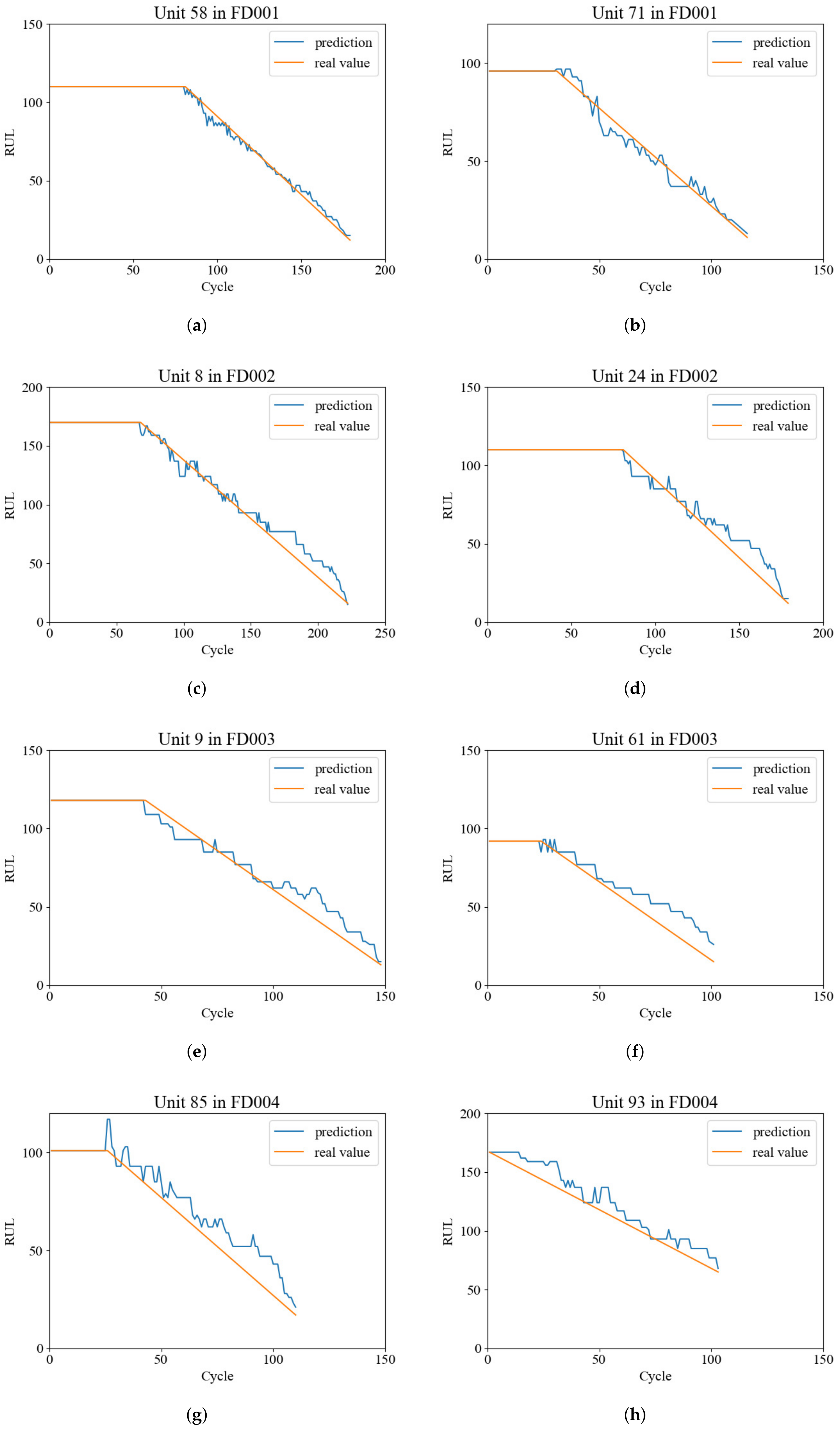
FD001 contains 100 different aero-engine units, and 4 out of the 100 units are randomly selected to show the RUL estimation results in
Figure 7. The engine unit numbers are 58 and 71. As shown in the figure, the engines work normally at the initial stage. After several time steps, faults are detected with performance degradation.
In general, the estimation error is relatively higher when the system is far from complete failure. However, when the system is close to failure, the error decreases rapidly and tends close to zero. This is because in the initial stage, the data attenuation is small, and the healthy features are stronger. When the system is close to zero, the signal damping is enhanced, and the fault features are easily captured by the networks, so the error is relatively lower. Moreover, all the test data end before zero because the last part of the entire cycle is not provided.
4.4. Experimental Results on Multiple Fault Modes
As shown in
Table 2, in FD001, the fault mode and working condition are simple, but the fault modes and working conditions are more complicated and hard to deal with in dataset FD002–FD004. In FD002, the working conditions vary from a sea level environment to a high-altitude, high-speed environment; in FD003, the fault modes contains both HPC degradation and fan degradation; in FD004, the problem is a collection of all the two faults modes and six working conditions. Because of the different fault modes and working conditions, the tendencies of sensors in FD002–FD004 are different and complex, and the process of feature cutting is the same as in
Section 3.2, so the data processing procedure is omitted here.
We list the estimation results in
Figure 7, which are randomly chosen from FD002 to FD004. Because of the single fault mode and the large scale of training set, the result on FD002 achieves excellent performance, and the error varies in a very small range during the whole life span. In FD003 and FD004, the absolute error grows larger in the beginning then descends slowly with the growth of the life cycle. Generally, due to the complexity of the fault modes and working conditions, the estimation accuracy result of the last three datasets is relatively lower than in FD001. In addition, the average life span of the last three datasets is larger than in FD001, so the absolute error is bigger. However, with the time approaching the end of a life span, the local error descends remarkably, and the local relative error is basically equal with it in FD001. For a brief summary, the proposed network is able to give an accurate estimation of the RUL problem in both the simple fault condition and complicated fault condition.
In this study, a particular performance index is proposed to evaluate the network performance: local estimation accuracy . is defined as the estimation error within a particular RUL cycle interval. For instance, when the system is less than 50 cycles away from complete failure, is defined as the estimation accuracy under the condition: if the absolute discrepancy between the real remaining life value and the prediction value is less than i cycles, which means when , the estimation is regarded as correct.
We select
,
, and
under the conditions that the system is less than 50, 20, and 10 cycles away from failure, and the prediction accuracy is illustrated in
Table 3. In fact, when the system is far from complete failure, a relatively higher error is tolerable. However, when the system is close to failure, the estimation error has to be limited to a lower value, since a higher error may be a threat on the safety of both aircraft engines and aeroplanes, which may lead to unacceptable disasters. In subset FD001, when the engine unit is less than 50 cycles away from failure,
of the estimation errors are limited within
cycles; when it is less than 10 cycles away, more than
of the estimation errors are limited within
cycles. In subsets FD002 to FD004, the absolute errors are relatively higher than in subset FD001, and this result is in correspondence with the performance in
Figure 7.
4.5. Other Effective Factors
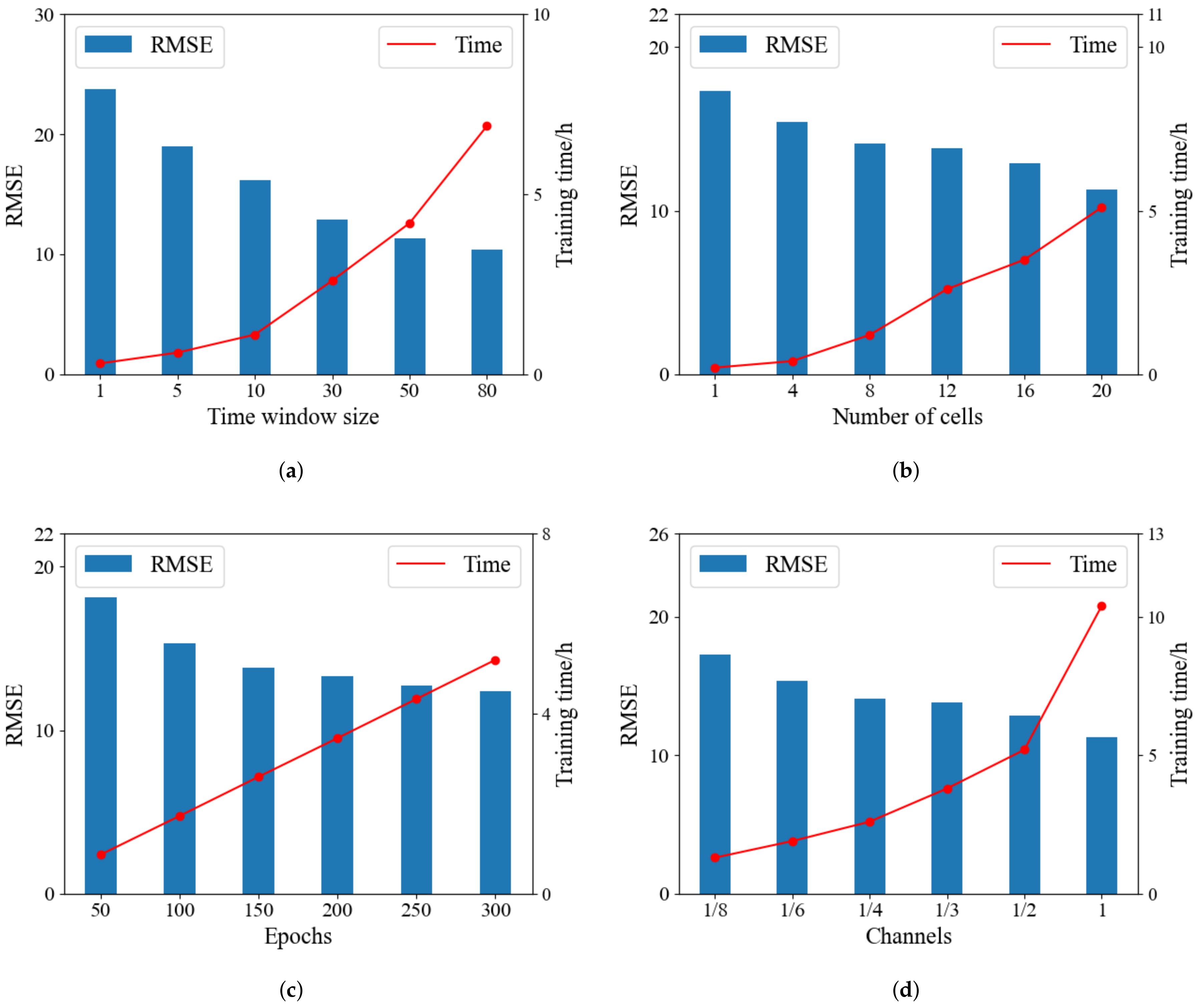
Generally, there are four factors that have an effect on the test performance: the size of the time window, network layers, training epochs, and channels. The effects of these factors are as follows.
The size of the time window has an important effect on RUL performance. A large time window implies that the time data sequences can obtain more information from the previous sequence, and develops a strong connection between the present and previous sequences. However, two additional factors limit the size of the time window. As shown in
Figure 8a, an increase in the time window apparently enhances the experimental time. Another factor is the dataset itself. According to
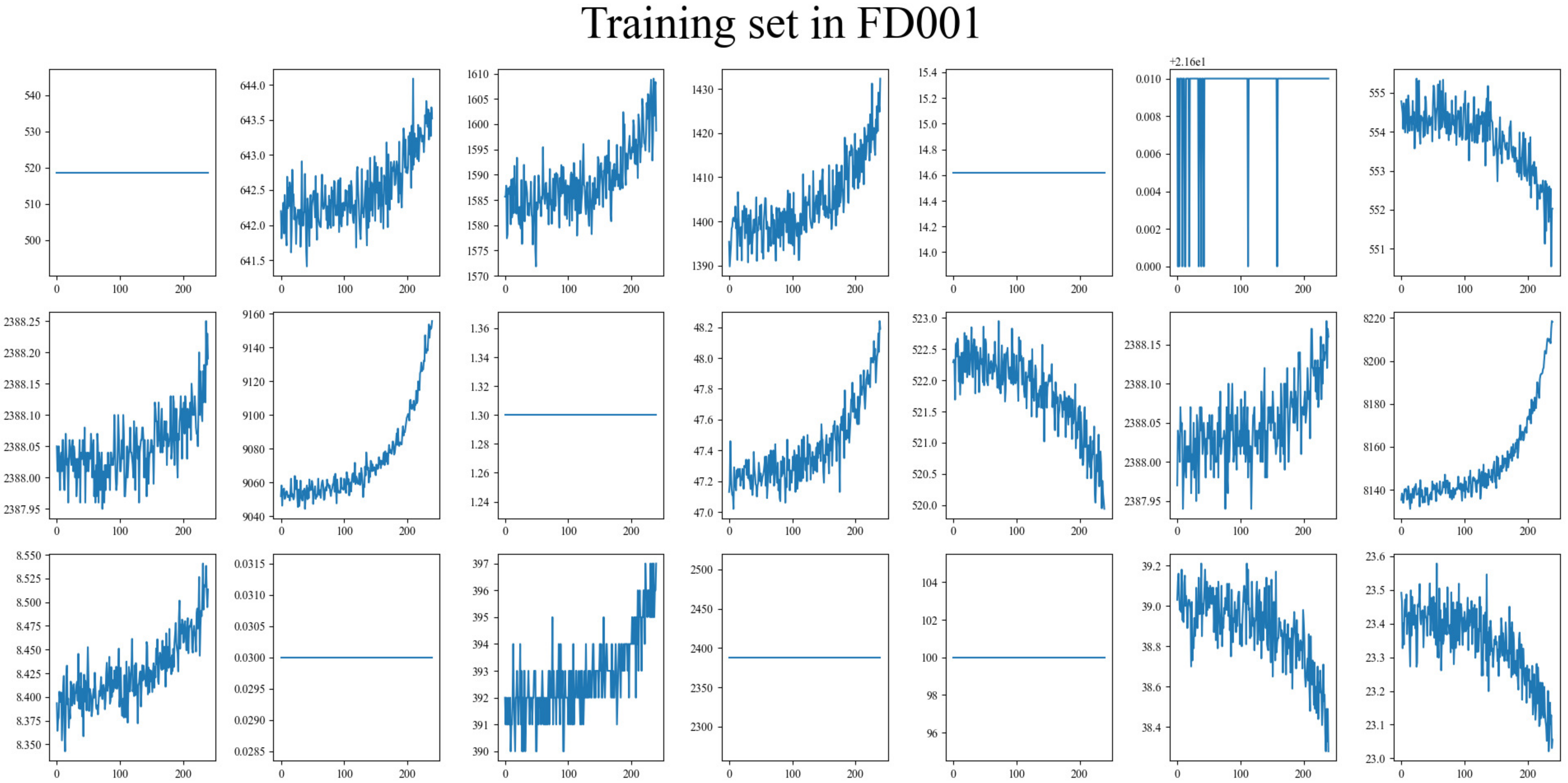
Figure 2, in subset FD0001, the shortest engine unit has only 31 cycles, followed by FD002 to FD004 for which the shortest unit cycles are 21, 38, and 19, respectively. Considering these two factors, the window size is set to 30 for the four subsets. The engine unit with fewer than 30 cycles is filled with zeros at the beginning of the time steps.
The number of network layers and the training epoch play another two important roles. In our method, the depth of the network is determined by both the number of nodes in a cell and the number of cells.
Table 4,
Table 5,
Table 6 and
Table 7 show the influence of different depths on the experimental results. Because of the larger scale of samples and complex working conditions, the depths in subsets FD002 and FD004 are higher than in FD001 and FD003. An increase in the network depth can help to obtain better results on RMSE and scoring function, but with an ascent in training time. To achieve a balance between performance and training time, and also prevent overfitting, we set depth
for subset FD001 and FD003, and
for FD002 and FD004. Training epoch is set for 200.
Figure 8b,c show the influence of these two factors.
The partial channels method was proposed to accelerate the searching and training process of DARTS by sampling a small part of the super network to reduce the redundancy in exploring the network space [
26]. Here, we define a binary signal
, which assigns 1 to selected channels and 0 to skipped ones. The selected channels are sent into computation as usual, while the skipped ones are directly copied to the output:
In the partial channels step, all the channels in the cells are randomly chosen for optimization. However, the uncertainty of the randomness may cause unstable searching results. To retard this problem, edge normalization is proposed:
where
is introduced to reinforce searching stability. Thus, every edge is parameterized with both
and
, making the architecture less sensitive.
In the operation selection step, we regard
K as a hyperparameter, and thereafter, only
of the channels are randomly selected. By reducing the number of channels, we can select a larger batch size and reduce the experimental time.
Figure 8d shows the relationship between channels, RMSE, and the training time. In our experiment, we select
.
4.6. Compared with Other Related Researches
The C-MAPSS dataset in widely used in the study of the RUL problem, with many research works published in recent years. To show the superiority of the performance,
Table 8 reports the estimation results of our proposed method and other popular works. All the experimental results in this table are the best results provided from the references. Our method has a similar scale in network layers, time window size, training batch size and other hyperparameters with all the referenced studies. It is obvious to see that the estimation result of our proposed method achieves the best performance over all these popular works. Whatever the prognostic approach used, both of the score functions in subsets FD002 and FD004 are much higher than in subsets FD001 and FD003, due to the mixed conditions of the fault mode and operation conditions. DARTS achieves lower RMSE and scoring functions in all the popular works.
5. Conclusions
In this study, we introduce an autoML approach to design a network architecture based on gradient descent, to solve the RUL estimation problem on the C-MAPSS dataset. In the data processing stage, a fault detector is proposed to determine when the fault occurred. We construct the whole search space as a DAG, where each subgraph of the DAG represents a network architecture. Thereafter, we relax the search space into a continuous form by using a softmax function, then the search space and loss function become continuous and differentiable, so gradient descent can be used for optimization in the searching process. In the architecture search step, a particular group of normal convolutional cells and reduction cells are well searched for subsequent network weights training. Finally, a partial channel connection method is introduced to accelerate the searching efficiency. Compared with other related work on the C-MAPSS dataset, our proposed method achieves better performance on all four subsets, with a lower RMSE function and a lower scoring function. Moreover, the local estimation accuracy is proposed to evaluate the network performance. To take an average estimation accuracy of the four subsets, when the system is less than 50 cycles away from complete failure, the accuracy is up to under an error of cycles, and is under a error of cycle. When the system is less than 10 cycles away from failure, the accuracy is up to and is up to . As a result, with the system approaching failure, becomes higher. That is to say, when the engine approaches failure, the estimation accuracy is at a very high level.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}