Human emotion identification is a growing area in the field of Cognitive Computing that incorporates facial expression [
1], speech [
2], and texts [
3]. Understanding human feelings is the key to the next era of digital evolution. Recent developments in the field have realized its potential in fields such as mental health [
4], intelligent vehicles [
5], and music [
6]. Recognizing emotions from facial expressions is a trivial task for the human brain, but it associates a higher level of complexity when carried out using machines. The reason for this intricacy is the non-verbal nature of the communication that is enacted through facial cues. Emotion prediction through other forms of data sources such as texts are comparatively easier tasks because of the word-level expressions that can be easily annotated through hashtags or word dictionaries [
7,
8,
9].
Emotion recognition through facial images has been comprehensively studied in the last decade. The studies conducted in the recent years are mostly focused on the application of Deep Neural models. This is mostly because of the variance in the real-world sets. In [
10], the use of two residual layers (each composed of four convolutional layers, two short-connection, and one skip-connection) with traditional Convolutional Neural Networks (CNNs) resulted in an average enhancement in performance of 94.23% accuracy. Lin et al. [
11] proposed a model utilizing multiple CNNs and utilized an improved Fuzzy integral to find out the optimal solution among the ensemble of CNNs. Facial Emotion Recognition has also been utilized in medical applications. Specifically, Facial Emotion analysis has been mostly utilized in psychiatric domains such as Autism and Schizophrenia. Sivasangari et al. [
12] illustrated an IoT-based approach to understand patients suffering from Autism Spectrum Disorder (ASD) by integrating facial emotions. Their framework is built to monitor the patients and is equipped to propagate information to the patient’s well-wisher. The emotion identification module developed using a Support Vector Machine is designed to help the caretaker to understand the emotional status of the subject. Jiang et al. [
13] proposed an approach to identify subjects with ASD by utilizing facial emotions detected using an ensemble model of decision trees. Their approach was found to be 86% accurate in the appropriate classification of subjects. One study by Lee et al. [
4] performed emotional recognition on 452 subjects (with 351 patients with schizophrenia and 101 healthy adults). Facial Emotion Recognition Deficit (FERD) is a common deficit found in patients with Schizophrenia. In [
14], the authors highlighted the drawbacks of FERD screeners and proposed an ML-FERD screener to undertake a concrete discrimination between Schizophrenia patients and healthy adults. The ML-FERD framework was built using an Artificial Neural Network (ANN) and trained using 168 images. Their approach demonstrated a high True Positive Rate (TPR) and True Negative Rate (TNR). Recent studies have also focused on the emotion inspection from videos. Hu et al. [
15] concentrated their study on extracting facial components from a video sequence. The authors developed a model that modifies Motion History Image (MHI) by understanding the local facial aspects from a facial sequence. One interesting approach proposed by Gautam and Thangavel [
16] trains the CNN with 3000 facial images using an iterative optimization and tested the model on a video of American Prison. The primary interest of the authors was to develop an automated prison surveillance system, and the proposed approach recorded an average accuracy of 93.5% over the video tests. Haddad et al. [
17] tried to preserve the temporal aspect of video sequences by using a 3D-CNN architecture and optimized it using a Tree-structured Parzen Estimator. Another approach called Contrastive Adversarial learning [
18] was recently proposed by Kim and Song to perform a person-independent learning by capturing the emotional change through adversarial learning. Their approach resulted in reliable results on video sequence data. Auto-encoder networks in emotion recognition has also been accentuated in recent years [
19]. In 2018, two studies [
20,
21] addressed the problem of computational complexity in Deep Networks and proposed a Deep Sparse Autoencoder Network (DSAN) to re-construct the images and integrated it with a softmax classifier capable of sorting out seven emotional categories that can be determined from the faces. Convolutional Autoencoders were found to be useful in continuous emotion recognition from images [
22]. One approach using Generative Adversarial Stacked Convolutional Autoencoders was illustrated by Ruiz-Gracia et al. [
23] in the context of Emotion Recognition. The pose and illumination invariant model was found to achieve 99.6% accuracy on a bigger image dataset. Sparse autoencoders were also explored with Fuzzy Deep Neural Architectures by Chen et al. [
24]. The authors obtained reliable results on three popular datasets by applying a 3-D face model using Candide3. In another recent work by Lakshmi and Ponnusamy [
25], the authors used Support Vector Machine (SVM) with Deep Stacked Autoencoder (DSAE) to predict the emotions from facial expressions. The pre-processing approach proposed by the authors is developed on a spatial and texture information extraction using a Histogram of Oriented Gradients (HOG) and a Local Binary Pattern (LBP) feature descriptor. Multimodal applications in emotion recognition have also been explored with autoencoders. In [
26], the authors developed a novel autoencoder-based framework to integrate visual and audio signals and classified emotions using a two-layered Long Short-Term Memory network. Label distribution learning has been explored in [
27,
28] for chronological age estimation from human facial images.
1.1. Motivation
The class overlapping problem is well-known in the research community, however, very few research works have addressed it. The majority of research work focuses on the effects of class overlapping in the presence of imbalanced classes. Apart from these, few domain-specific works have been reported. The class overlapping problem in the context of face recognition has been studied in [
29]. The proposed method used Fisher’s Linear Discriminant combat majority biased face recognition; however, in the presence of overlapping classes, a new distance-based technique has been proposed. The study also pointed out the challenges in learning overlapped classes by various classifiers such as ANNs. Fuzzy rules have been used to address the same [
30], where both imbalanced and overlapped classes are learned. The fuzzy membership values of data points have been used to partition the data points into several fuzzy sets. Batista et al. [
31] found that classifiers may find difficulty in learning imbalanced classes in presence of overlapped classes, especially the minority classes. Similar studies [
32,
33] have also pointed out this issue where the performance of classifiers have been tested by varying the degree of overlapping. Another study [
34] reported the effect of overlapped classes, where the overlapping region has majorly occupied minority samples. It has been found that the presence of overlap makes class-biased learning difficult. Later, Garcia et al. [
35] studied the problem in detail and recorded the effects of overlapping classes in the presence of overlapping. It has been reported that the imbalance ratio might not be the primary cause behind the dramatic degradation of the classifier, whereas overlapped classes play a vital role. It established the fact that class overlapping is more important to classifier performance than class imbalance. Lee et al. [
36] proposed an overlap sensitive margin classifier by taking the leverage of fuzzy support vector machines and k-nearest neighbor classifiers. The degree of overlap for individual data points are then calculated using the KNN classifier and used in a modified objective function to train the fuzzy SVM in order to split the data space into two regions, known as the Soft overlap and Hard overlap regions. Devi et al. [
37] adopted a similar approach, where a
-SVM was used as one class classifier to identify novel data instances from a dataset. However, the explicit detection of data points in an overlapping region is not reported. Neighborhood-based strategies have also been employed to undersample data points in the overlapping region and subsequently removing those data points to improve classifier performance [
38].
1.2. Contribution
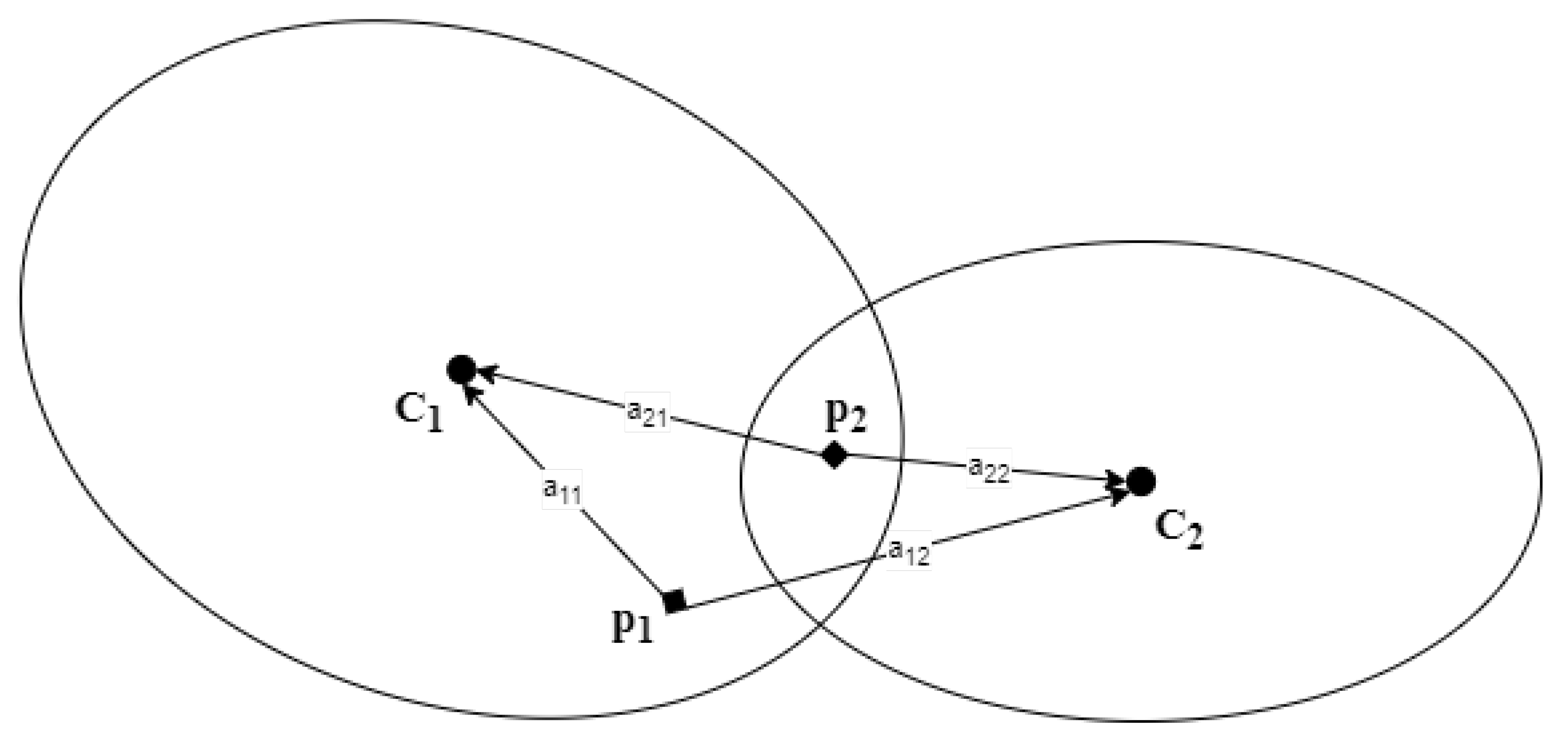
In the context of emotion recognition, the effect of class overlapping has not been preciously addressed. The challenge of overlapped classes appear as studies have revealed [
39] that the presence of multiple facial expression is common in humans. Hence, facial images categorized in a particular class may have close similarity with other categories, which leads to the severe overlapping of classes. In order to address this problem, in the current study, a residual variational autoencoder (RVA) has been used to represent a facial image in latent space. After training the RVA model, only the encoder part transforms the images of all classes to a latent vector form. Now, to overcome the overlapped classes, an affinity-based overlap reduction technique (AFORET) has been proposed in the current article. The proposed method reduces the overlapping of classes in latent space. After modifying the dataset, it has been used to train a wide range of well-known classifiers. The performances of the classifiers have been tested by using well-known performance indicators. A thorough comparative analysis has been conducted to understand how the degree of overlap affects the classifiers’ performance. The ingenuity of the proposed algorithm has been compared with the OSM [
36],
-SVM [
37], and Neighborhood Undersampling (NBU) techniques, which have also attempted to address the overlapping problem in general. Overall the contributions of the current study are as follows:
The rest of the article is arranged as follows:
Section 2 introduces the residual variational autoencoder model, which is followed by the affinity-based overlap reduction technique. Next, in
Section 4, these two methods are combined together to address the class overlapping problem in facial emotion recognition.
Section 5 begins with a discussion on experimental setup, and the classifier and overlapping techniques are compared in terms of experimental performances. Finally, the conclusions are made in
Section 6.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}