1. Introduction
In recent years, with the rapid development of information technology, massive amounts of multi-modal data (i.e., text [
1], image [
2], audio [
3], video [
4], and 3D models [
5]) have been collected and stored on the Internet. How to utilize the extensive multi-modal data to improve cross-modal retrieval performance has attracted increasing attention [
6,
7]. Cross-modal retrieval, a hot issue in the multimedia community, is the use of queries from one modality to retrieve all semantically relevant instances from another modality [
8,
9,
10]. In general, the structuring of data in different modalities is heterogeneous, but there are strong semantic correlations between these structures. Therefore, the main tasks of cross-modal retrieval are discovering how to narrow the semantic gap and exploring the common representations of multi-modal data, the former being the most challenging problem faced by researchers in this field [
11,
12,
13,
14].
Most of existing cross-modal retrieval methods, including traditional statistical correlation analysis [
15], graph regularization [
16], and dictionary learning [
17], learn a common subspace [
18,
19,
20,
21] for multi-modal samples, in which the semantic similarity between different modalities can be measured easily. For example, based on canonical correlation analysis (CCA) [
22], several cross-modal retrieval methods [
23,
24,
25] have been proposed to learn a common subspace in which the correlations between different modalities are easily measured. Besides, graph regularization has been applied in many studies [
16,
26,
27,
28] to preserve the semantic similarity between cross-modal representations in the common subspace. The methods in [
17,
29,
30] draw support from dictionary learning to learn consistent representations for multi-modal data. However, these methods usually have high computational costs and low retrieval efficiency [
31]. In order to overcome these shortcomings, hashing-based cross-modal retrieval techniques are gradually replacing the traditional ones. A practical way to speed up similarity searching is with binary representation learning, referred to as hashing learning, which projects a high-dimensional feature representation from each modality as a compact hash code and preserves similar instances with similar hash codes. In this paper, we focus on the cross-modal binary representation learning task, which can be applied to large-scale multimedia searches in the cloud [
32,
33,
34].
In general, most of the existing traditional cross-modal hashing methods can be roughly divided into two groups: unsupervised [
35,
36,
37,
38,
39] and supervised methods [
40,
41,
42,
43,
44]. Unlike unsupervised methods, supervised methods can excavate similarity relationships between data through semantic labels to achieve better performance. However, these methods rely on shallow features that cannot provide sufficient semantic discrimination information. Recently, deep models [
45,
46,
47,
48] have been widely adopted to perform feature learning from scratch with very promising performance. This powerful representation learning technique boosts the non-linear correlation learning capabilities of cross-modal hashing models. Thus, lots of deep hashing method [
28,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58] have been developed, which can effectively learn more discriminative semantic representations from multi-modal samples and are gradually replacing the traditional hashing approaches.
Motivation. Although deep hashing algorithms have made remarkable progress in cross-modal retrieval, the semantic gap and heterogeneity gap between different modalities need to be further narrowed. On the one hand, most methods lack mining of ample semantic information from multiple category labels. That means these methods cannot completely retain multi-label semantic information during cross-modal representation learning. Taking [
28] as an example, graph regularization is used to support intra-modal and inter-modal similarity learning, but the multi-label semantics are not mined fully during the cross-modal representation learning, which affect the semantic discrimination of hash codes. On the other hand, after the features learned from normal networks are quantized into binary representations, some semantic correlations may be lost in Hamming subspace. For instance, [
59] studies the effective distance measurement of cross-modal binary representations in Hamming subspace. However, multi-label semantics learning is ignored, which leads to insufficient semantic discriminability of the hash code. Therefore, to further improve the quality of cross-modal hash codes, two particularly important problems cannot be overlooked during the hashing learning: (1)
how to capture more semantic discriminative features, and (2)
how to efficiently preserve cross-modal semantic similarity in common Hamming subspaces. In this work, we consider these two key issues simultaneously during the cross-modal hashing learning to generate more semantically discriminative hash codes.
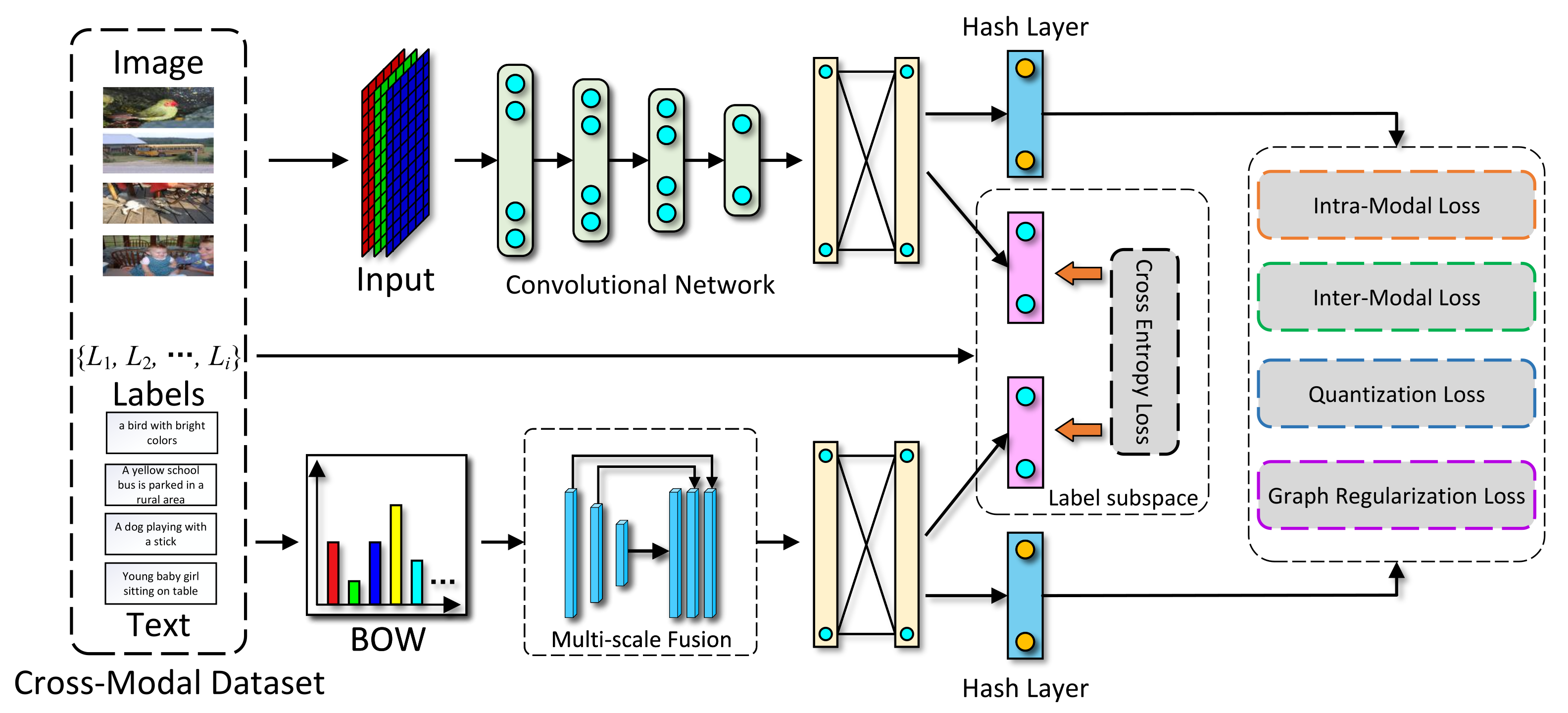
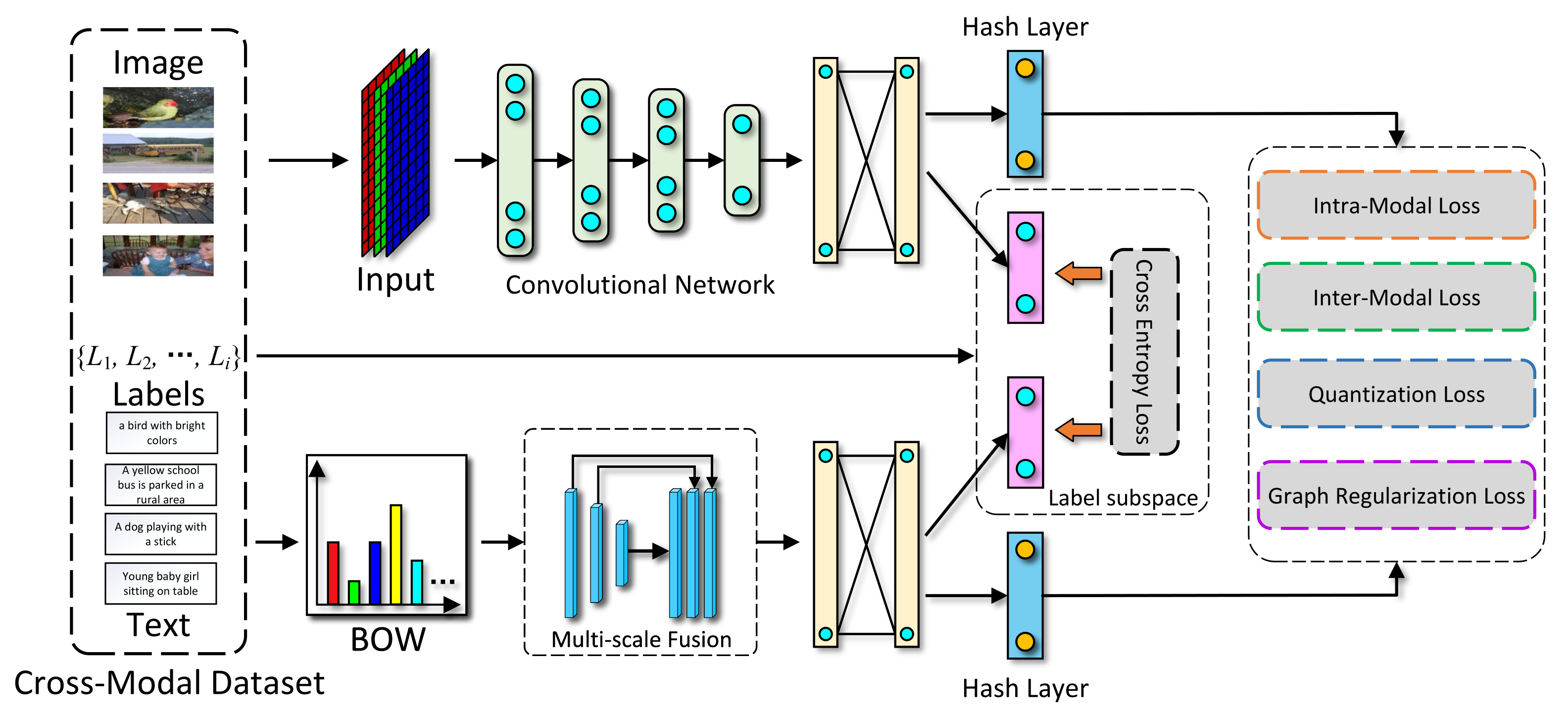
Our Method. To this end, we propose a novel end-to-end cross-modal hashing learning approach, named deep multi-semantic fusion-based cross-modal hashing (DMSFH for short) to efficiently capture multi-label semantics and generate high-quality cross-modal hash codes. Firstly, two deep neural networks are used to learn cross-modal representations. Then, intra-modal loss and inter-modal loss are utilized by generating a semantic similarity matrix to preserve semantic similarity. To further capture the rich semantic information, a multi-label semantic fusion module is used following the feature learning module, which fuses the multiple label semantics into cross-modal representations to preserve the semantic consistency across different modalities. In addition, we introduce a graph regularization method to preserve semantic similarity among cross-modal hash codes in Hamming subspace.
Contributions. The main contributions of this paper are summarized as follows:
We propose a novel deep learning-based cross-modal hashing method, termed DMSFH, which integrates cross-modal feature learning, multi-label semantic fusion, and hash code learning into an end-to-end architecture.
We combine the graph regularization method with inter-modal and intra-modal pairwise loss to enhance cross-modal similarity learning in Hamming subspace. Additionally, a multi-label semantic fusion module was developed to enhance the cross-modal consistent semantics learning.
Extensive experiments conducted on two well-known multimedia datasets demonstrate the outstanding performance of our methods compared to other state-of-the-art cross-modal hashing methods.
Roadmap. The rest of this paper is organized as follows. The related work is summarized in
Section 2. The problem definition and the details of the proposed method DMSFH are presented in
Section 3. The experimental results and evaluations are reported in
Section 4. We discuss the main contributions and characteristics of our research in
Section 5. Finally, we conclude this paper in
Section 6.
2. Related Work
According to learning manner, the existing cross-modal hashing techniques fall into two categories: unsupervised approaches and supervised approaches. Due to the vigorous development of deep learning, cross-modal deep hashing approaches sprang up in the last decade. This section reviews the works that are related to our paper.
Unsupervised Methods. To learn a hash function, the unsupervised hashing methods aim to mine the unlabeled samples to discover the relationship between multi-modal data. One of the most typical technique is collective matrix factorization hashing (CMFH) [
60], which utilizes matrix decomposition to learn two view-specific hash functions, and then different modal data can be mapped into unified hash codes. The latent sematic sparse hashing (LSSH) method [
35] uses sparse coding to find the salient structures of images, and matrix factorization to learn the latent concepts from text. Then, the learned latent semantic features are mapped to a joint common subspace. Semantic topic multimodal hashing (STMH) [
37], which discovers clustering patterns of texts and factorizes the matrix of images, to acquire multiple semantic of texts and concepts of images in order to learn multimodal semantic features, into a common subspace by their correlations. Multi-modal graph regularized smooth matrix factorization hashing (MSFH) [
61] utilizes a multi-modal graph regularization term which includes an intra-modal similarity graph and an inter-modal similarity graph to preserve the topology of the original instances. The latent structure discrete hashing factorization (LSDHF) [
62] approach uses the Hadamard matrix to align all eigenvalues of the similarity matrix to generate a hash dictionary, and then straightforwardly distills the shared hash codes from the intrinsic structure of modalities.
Supervised Methods. Supervised cross-modal hashing methods improve the search performance by using supervised information, such as training data labels. Typical supervised approaches include cross-modal similarity sensitive hashing (CMSSH) [
40], semantic preserving hashing for cross-view retrieval (SEPH) [
41], semantic correlation maximization (SCM) [
42], and discrete cross-modal hashing (DCH) [
43]. CMSSH applies boosting techniques to preserve the intra-modal similarity. SEPH transforms the semantic similarity of training data into an affinity matrix by using a label as supervised information, and minimizes the Kullback–Leibler divergence to learn hash codes. SCM utilizes all the supervised information for training with linear-time complexity by avoiding explicitly computing the pairwise similarity matrix. DCH learns discriminative binary codes without relaxation, and label information is used to elevate the discriminability of binary codes through linear classifiers. Nevertheless, these cross-modal hashing methods are established on hand-crafted features [
43,
63]. It is hard to explore the semantic relationships among multi-modal data. Therefore, it is difficult to obtain satisfying retrieval results.
Deep Methods. In recent years, deep learning, as a powerful representation learning technique, has been widely used in cross-modal retrieval tasks. A number of methods integrating deep neural networks and cross-modal hashing have been developed. For example, deep cross-modal hashing (DCMH) [
64] firstly applies the end-to-end deep learning architecture for cross-modal hashing retrieval and utilizes the negative logistic likelihood loss to achieve great performance. Pairwise relationship-guided deep hashing (PRDH) [
65] uses pairwise label constraints to supervise the similarity learning of inter-modal and intra-modal data. A correlation hashing network (CHN) [
66] adapts the triplet loss measured by cosine distance to find the semantic relationship between pairwise instances. Cross-modal hamming hashing (CMHH) [
59] learns high-quality hash representations to significantly penalize similar cross-modal pairs with Hamming distances larger than the Hamming radius threshold. The ranking-based deep cross-modal hashing approach (RDCMH) [
49] integrates the semantic ranking information into a deep cross-modal hashing model and jointly optimizes the compatible parameters of deep feature representations and hashing functions. In fusion-supervised deep cross-modal hashing (FDCH) [
67], both pair-wise similarity information and classification information are embedded in the hash model, which simultaneously preserves cross-modal similarity and reduces semantic inconsistency. Despite the above-mentioned benefits, most of these methods only use binary similarity to constrain the generation of different instances of hash codes. This causes low correlations between retrieval results and the inputs, as the semantic label information cannot be expressed adequately. Besides, most methods only concentrate on hash code learning, but ignore the deep mining of semantic features. Thus, it is essential to keep sufficient semantic information in the modal structure and generate discriminative hash codes to enhance the cross-modal hashing learning.
To overcome the above challenges, this paper proposes a novel approach to excavate multi-label semantic information to improve the semantic discrimination of cross-modal hash codes. This approach not only uses the negative logistic likelihood loss, but also exploits multiple semantic labels’ prediction losses based on cross entropy to enhance semantic information mining. Apart from this, we introduce graph regularization to preserve the semantic similarity of hash codes in Hamming subspace. Therefore, the proposed method is designed to generate high-quality hash codes that better reflect high-level cross-modal semantic correlations.
3. The Proposed Approach
In this section, we propose our method DMSFH, including the model’s formulation and the learning algorithm. The framework of the proposed DMSFH is shown in
Figure 1, which mainly consists of three parts. The first part is the feature learning module, in which multimedia samples are transformed into high-dimensional feature representations by corresponding deep neural networks. The second part is the multi-label semantic fusion part. This part aims to embed rich multi-label semantic information into feature learning. The third part is the hashing learning module, which retains the semantic similarity of the cross-modal data in the hash codes using a carefully designed loss function. In the following, we introduce the problem definition first, and then discuss DMSFH method in detail.
3.1. Problem Definition
Without loss of generality, bold uppercase letters, such as
, represent matrices. Bold lowercase letters, such as
, represent vectors. Moreover, the
-th element of
is denoted as
, the
i-th row of
is denoted as
, and the
j-th column of
is denoted as
.
is the transpose of
. We use
for the identity matrix.
and
denote the trace of the matrix and the Frobenius norm of a matrix, respectively.
is the sign function, shown as follows:
To facilitate easier reading, the frequently used mathematical notation is summarized in
Table 1.
This paper focuses on two common modalities: texts and images. Assume that a cross-modal training dataset consists of n instances, i.e., , where denotes the i-th training instances, and and are the i-th image and text, respectively. is the multi-label annotation assigned to , where c is the number of categories. If belongs to the jth class, ; otherwise, . In addition, a cross-modal similarity matrix is given. If image and text are similar, ; otherwise, .
Given a set of training data
O, the goal of cross-modal hashing is to learn two hashing functions, i.e.,
and
for image modality and textual modality, respectively, where
,
,
k is the length of the hash code. In addition, the hash codes preserve the similarities in similarity matrix
. If the Hamming distance between the codes
and
is small,
; otherwise
. To easily calculate the similarity between two binary codes
and
, we use the inner product
to measure the Hamming distance as follows:
where
K is the length of the hash code.
3.2. Feature Learning Networks
For cross-modal feature learning, deep neural networks are used to extract semantic features from each modality individually. Specifically, for image modality, ResNet34 [
46], a well-known deep convolutional network, is used to extract image data features. The original ResNet was pre-trained on imagenet datasets; in addition, excellent results have been achieved on image recognition issues. We replaced the last layer with a network that has
hidden nodes, which is followed by a hash layer and a tag layer. The hash layer has
k hidden nodes for generating binary representations. The label layer has
c hidden nodes for generating predictive labels.
For text modality, a deep model named TxtNet is used to generate textual feature representations, which is a three-layer network followed by a multi-scale () fusion model . The last layer of TxtNet is a fully-connected layer with () hidden nodes, which outputs deep textual features and prediction labels. The input of TxtNet is the Bag-of-Words (BoW) representation of each text sample. The BoW vector is too sparse, but the features extracted by the multi-scale fusion model are more abundant. Firstly, the BoW vectors are evenly pooled at different scales; then, the semantic information is extracted by nonlinear mapping through a convolution operation and an activation function. Finally, the representations from different scales are fused to obtain richer semantic information. The fusion model contains 5 interpretation blocks. Each block contains a convolutional layer and an average pooling layer. The filter sizes of the average pooling layer are set to , , , and , respectively.
3.3. Hash Function Learning
In the network of image modality, let denote the learned image feature of the i-th sample , where is all network parameters before the last layer of the deep neural network, and is the network parameter of the hash layer. Furthermore, let denote the output of the label layer for sample , where is the network parameter of the label layer. In the network of text modality, let denote the learned text feature of the i-th sample , where is all network parameters before the last layer of deep neural network, and is the network parameter of the hash layer. Furthermore, let denote the output of the label layer for sample , where is the network parameter of the label layer.
To capture the semantic consistency between different modalities, the inter-modal negative log likelihood function is used in our approach, which is formulated as:
where
is the inner product of two instances,
with
, and
with
. The likelihood function composed of text feature
and image feature
is as follows:
where
is a sigmoid function, and
.
To generate the hash codes with rich semantic discrimination, two essential factors need to be considered: (1) the semantic similarity between different modes should be preserved, and (2) the high-level semantics within each mode should be preserved, which can raise the accuracy of cross-modal retrieval effectively. To realize this strategy, we define the intra-modal pair-wise loss as follows:
where
is the intra-modal pair-wise loss for image-to-image and
is the intra-modal pair-wise loss for text-to-text, and
and
are defined as:
where
is the inner product of image data, and
is the inner product of text data.
Based on the negative log likelihood, the loss function can be used to distinguish identical and completely dissimilar instances. However, for more fine-grained hash features, we can extract higher-level semantic information by adding a tag prediction layer, so that the network can learn hash features with deep semantics. The semantic label cross-entropy loss is:
where
is the cross entropy loss for image modalities and
is the cross entropy loss for text modalities.
and
are defined as:
where
is the original semantic label information, for instance,
; and
and
represent the prediction labels of instance
in the image network and text network, respectively.
In order to enhance the correlation between the same hash code in Hamming subspace, we introduce graph regularization to establish the degree of correlation between multi-modal datasets. We formulate a spectral graph learning loss from the label similarity matrix
as follows:
where
is the similarity matrix, and
represents the unified hash codes. we define diagonal matrix
, and
is the graph Laplacian matrix.
We regard
and
as the continuous substitution of the image network hash code
and the text network hash code
to reduce quantization loss. According to the empirical analysis, the training effect will be better if the same hash code is used for different modes of the same training data, so we set
. Therefore, quantization loss can be defined as:
The overall objective function, combining the inter-modality pair-wise loss
, the intra-modal pair-wise loss
, the cross entropy loss
for the predicted label, graph regularization loss
and quantization loss
, is written as below:
where
and
are hyper-parameters to control the weight of each part.
3.4. Optimization
The objective in Equation (
13) can be solved by using an alternative optimization iteratively. We adopt the mini-batch stochastic gradient descent (SGD) method to learn parameter
in an image network and parameter
in a text network, and
. Each time we optimize one network with the other parameters fixed. The whole alternating learning algorithm for DMSFH is briefly outlined in Algorithm 1, and a detailed derivation is described in the following subsections.
3.4.1. Optimize
When
and
are fixed, we can learn the deep network parameter
for the image modality by using SGD with back-propagation(BP). For the
i-th image
, we first calculate the following gradient:
Then we can compute
,
, and
by utilizing the chain rule, based on which BP can be used to update the parameters
.
3.4.2. Optimize
Similarly, when
and
are fixed, we also learn the network parameter
of the text modality by using SGD and the BP algorithm. For the
i-th text
, we calculate the following gradient:
Then we can compute
,
, and
by utilizing the chain rule, based on which BP can be used to update the parameters
.
3.4.3. Optimize
When
and
are fixed, the objective in Equation (
13) can be reformulated as follows:
We compute the derivation of Equation (
18) with respect to
and infer that
should be defined as follows:
where
and
are hyper-parameters, and
denotes the identity matrix.
3.4.4. The Optimization Algorithm
As shown in Algorithm 1, DMSFH’s learning algorithm takes raw input training data, including images, text, and labels:
, with
. Before the training, parameters
and
of image network and text network were initialized; mini-batch size
; the maximal number of epochs
; iteration times in each epoch was
;
, where
n is the total number of training data. The training of each epoch consisted of three steps. Step 1: Randomly selecting
images from
O and setting them as a mini-batch. For each datum in the mini-batch, we calculated
and
by forward propagation. After the gradient was calculated, the network parameters
,
and
were updated using SGD and back propagation. Step 2: Randomly selecting
texts from
O and setting them as a mini-batch. For each datum in the mini-batch, we calculated
and
by forward propagation. After the gradient is calculated, the network parameters
,
and
were updated using SGD and back propagation. Step 3: Updating
by Equation (
19). The above three steps were repeatedly iterated to realize the alternating training of image hash network and text hash network until the maximum epoch number of iterations was reached.
| Algorithm 1 The learning algorithm for DMSFH |
Require: Training data includes images, text, and labels: , with . Ensure: Parameters and of deep neural networks, and binary code matrix . Initialization initialize parameters and , mini-batch size , the maximal number of epoches , and iteration number , . repeat for do Randomly sample images from O to construct a mini-batch of images. For each instance in the mini-batch, calculate and by forward propagation. Updata . Calculate the derivatives according to Equations ( 14) and ( 15) Update the network parameters , and by applying backpropagation. end for for do Randomly sample texts from O to construct a mini-batch of texts. For each instance in the mini-batch, calculate and by forward propagation. Updata . Calculate the derivatives according to Equations ( 16) and ( 17) Update the network parameters , and by applying backpropagation. end for Update using Equation ( 19) until the max epoch number
|
4. Experiment
We conducted extensive experiments on two commonly used benchmark datasets, i.e., MIRFLICKR-25K [
68] and NUS-WIDE [
69], to evaluate the performance of our method, DMSFH. Firstly, we introduce the datasets, evaluation metrics, and implementation details, and then discuss performance comparisons of DMSFH and 6 state-of-the-art methods.
4.1. Datasets
MIRFLICKR-25K: The original MIRFLICKR-25K [
68] dataset contains 25,000 image–text pairs, which were collected from the well-known photo sharing website Flickr. Each of these images has several textual tags. We selected those instances that have at least 20 textual tags for our experiments. The textual tags for each of the selected instances were transformed into a 1386-dimensional BoW vector. In addition, each instance was manually annotated with at least one of the 24 unique labels. We selected 20,015 instances for our experiments.
NUS-WIDE: The NUS-WIDE [
69] dataset is a large real-world Web image dataset comprising over 269,000 images with over 5000 user-provided tags, and 81 concepts for the entire dataset. The text of each instance is represented as a 1000-dimensional BoW vector. In our experiment, we removed the instances without labels, and selected instances labeled by the 21 most-frequent categories. This gave 190,421 image–text pairs.
Table 2 presents the statistics of the above two datasets.
Figure 2 shows some samples of these two datasets.
4.2. Evaluation
Two widely used evaluation methods, i.e., Hamming ranking and hash lookup, were utilized for cross-modal hash retrieval evaluations. Based on the query data and the Hamming distance of the retrieved samples as the sorting criteria, Hamming sorting sorts the retrieved data one by one according to the increasing order of the Hamming distance. In Hamming sorting, mean average precision (MAP) is one of the performance metrics that is commonly used to measure the accuracy of the query results. The larger the MAP value, the better the method retrieval performance. The topN precision curve reflects the changes in precision according to the number of retrieved instances. Besides, a hash search is also based on the criteria of the query data and the Hamming distance of the retrieved samples. However, it only returns the data to be retrieved within the specified Hamming distance as the final result. This can be measured by a precision recall (PR) curve. The larger the area enclosed by the curve and the coordinate axis, the better the retrieval performance of the method.
The value of MAP is defined as:
where
M is the query dataset and
is the average accuracy of query data
. The average value of accuracy is calculated as shown in Equation (
21):
where
N is the number of relevant instances in the retrieved set, and
R represents the total amount of data.
denotes the precision of the top
r retrieved instances, and
if the
r-th retrieved result is relevant to the query instances; otherwise,
.
To comprehensively measure the retrieval performance, we utilize another important evaluation metric, i.e., F-score. It is an important evaluation metrics that comprehensively considers precision and recall, which are defined as:
if
, this measurement is called F1-score. At this time, the accuracy rate and recall rate have the same weight. That means they are same important. In our experiments, we used F1-score to evaluate the cross-modal retrieval performance.
4.3. Baselines and Implementation Detail
Baselines. In this paper, the proposed SFDCH method is compared with several baselines, including SCM [
42], SEPH [
41], PRDH [
65], CMHH [
59], CHN [
66], and DCMH [
64]. SCM and SEPH use manual features, and the other approaches extract features through deep neural networks. Here is a brief introduction to these competitors:
SCM integrates semantic labels into the process of hash learning to conduct large-scale data modeling, which not only maintains the correlation between models, but also achieves good performance in accuracy.
SEPH transforms the semantic similarity of training data into affinity matrix by using a label as supervised information, and minimizes the Kullback–Leibler divergence to learn hash codes.
PRDH integrates two types of pairwise constraints from inter-modality and intra-modality to enhance the similarities of the hash codes.
CMHH learns high-quality hash representations to significantly penalize similar cross-modal pairs with Hamming distances larger than the Hamming radius threshold.
CHN is a hybrid deep architecture that jointly optimizes the new cosine max-margin loss in semantic similarity pairs and the new quantization max-margin loss in compact hash codes.
DCMH integrates features and hash codes learning into a general learning framework. The cross-modal similarities are preserved by using a negative log-likelihood loss.
Implementation Details. Our SFDCH approach was implemented by Pytorch framework. All the experiments were performed on a workstation with Intel(R) Xeon E5-2680_v3 2.5 GHz, 128 GB RAM, 1 TB SSD, and 3TB HDD storage; and 2 NVIDIA GeForce RTX 2080Ti GPUs with Windows 10 64-bit operating system. We set the ; the learning rate was initialized to and gradually lowered to in 500 epochs. We set the batch size of the mini-batch to 128 and the iteration number of the outer-loop in Algorithm 1 to 500, and the hyper-parameters . For whole experiment, we used to denote using a querying image while returning text, and to denote using a querying text while returning an image.
4.4. Performance Comparisons
To evaluate the performance of the proposed method, we compare DMSFH with the six baselines in terms of MAP and PR curves on MIRFLICKR-25K and NUS-WIDE, respectively. Two query tasks, i.e., image-query-text and text-query-image, are considered.
Table 3 and
Table 4 illustrate the MAP results of DMSFH and other methods on different lengths (16, 32, 64 bits) of hash codes on MIRFlickr-25K and NUS-WIDE, respectively.
Figure 3,
Figure 4 and
Figure 5 demonstrate the PR curves of different coding lengths on MIRFlickr-25K and NUS-WIDE, respectively.
Table 5 reports the F1-measure with hash code length 32 bits on the MIRFLICKR-25K dataset.
Hamming Ranking:Table 3 and
Table 4 report the MAP scores of the proposed method and its competitors for image-query-text and text-query-image on MIRFLICKR-25K and NUS-WIDE, where
and
represent image retrieval by text and text retrieval by image, respectively. It is clear from the
Table 3 and
Table 4 that the deep hashing methods perform better than the non-deep methods. Specifically, on MIRFLICKR-25K, we can see in
Table 3 that the proposed method DMSFH achieved the highest MAP score for both queries (
: 16 bits MAP = 79.12%, 32 bits MAP = 79.60%, 64 bits MAP = 80.45%;
: 16 bits MAP = 78.22%, 32 bits MAP = 78.62%, 64 bits MAP = 79.50%). It defeated the two most competitive deep learning-based baselines, CNH and DCMH, due to the multiple label semantic fusion. Similarly, we can find from
Table 4 that DMSFH won the competition again on NUS-WIDE by
MAP = 64.08% (16 bits), 65.12% (32 bits), 66.43% (64 bits); and
MAP = 63.89% (16 bits), 65.31% (32 bits), 66.08% (64 bits), respectively. This superiority of DMSFH due to the fact that it incorporates richer semantic information than other techniques. In addition, DMSFH leverages graph regularization to measure the semantic correlation of the unified hash codes. That means it can capture more semantic consistent features between different modalities than other deep hashing models, such as CHN and DCMH. Therefore, the above results confirm that the hash codes generated by DMSFH have better semantic discrimination and can better adapt to the task of mutual retrieval of multi-modal data.
Hash Lookup: To further demonstrate the comparison of the proposed model with these baselines, we used PR curves to evaluate their retrieval performances.
Figure 3,
Figure 4 and
Figure 5 show the PR curves with different coding lengths (16 bits, 32 bits, and 64 bits) on MIRFLICKR-25K and NUS-WIDE datasets, respectively. As expected, the deep learning-based models had better performances than the manual features-based models, mainly due to the powerful representation capabilities of deep neural networks. Besides, no matter what the length of the hash code was, our method performed better, obviously, on the PR curve than the other deep based competitors. That happened mainly because DMSFH has stronger cross-modal consistent semantic learning capabilities by not only considering both the intra-modal and inter-modal semantic discriminative information, but integrating graph regularization into hashing learning as well. Besides, we selected the best five methods, and report their average precision, average recall, and average F1-measure with Hamming radius
in
Table 5 on MIRFLICKR-25K for when the code length was 32. We found that in all cases our DMSFH can achieve the best F1-measure.
4.5. Ablation Experiments of DMSFH
To verify the validity of the DMSFH components, we conducted ablation experiments on the MIRFLICKR-25K dataset, and the experimental results are shown in
Table 6. We define DMSFH-P as employing only intra-modal pairwise loss and inter-modal pairwise loss, and DMSFH-S removed the graph regularization loss. From
Table 6, we can see that both the semantic prediction discriminant loss and graph regularization loss employed by DMSFH can effectively improve the retrieval accuracy. From the results, it can be seen that DMSFH can obtain better performance when using the designed modules.
5. Discussion
This paper proposes deep multi-semantic fusion-based cross-modal hashing (DMSFH) for cross-modal retrieval tasks. Firstly, it preserves the semantic similarity between data through intra-modal loss and inter-modal loss, and then introduces a multi-label semantic fusion module to further capture more semantic discriminative features. In addition, semantic similarity in Hamming space is preserved by graph regularization loss.
We compared DMSFH with other methods. We used the cross-modal multi-label datasets MIRFLICKR-25K and NUS-WIDE, which have 24 and 21 label attributes, respectively. According to
Table 3 and
Table 4, it can be seen that the map scores of DMSFH are better than those of the other methods. As for DCMH and PRDH, DMSFH outperformed these two deep learning methods based on the same inter-modal and intra-modal pairwise loss, precisely because it captured more semantic information with the addition of new losses. Therefore, DMSFH is able to optimize the semantic heterogeneity problem to a certain extent and improve the accuracy. In addition, the computational cost of the model is measured using floating point operations (FLOPs), with an approximate number of FLOPs of 3.67 billion for DMSFH. Compared with real-valued cross-modal retrieval methods, the computational and retrieval cost of our method is quite low due to the shorter binary cross-modal representations (i.e., 64 bits hash codes) and Hamming distance measurements. As they generate higher dimensional feature representations (i.e., 1000 dimensional feature map), the real-valued cross-modal representation learning models always have higher complexity.
Although our study achieved some degree of performance improvement, there are limitations. First, when constructing the sample similarity matrix, our method in this paper does not fully extract the fine-grained labeling information between data, and there is still a higher performance improvement in fine-grained semantic information extraction. Second, our method mainly focuses on the construction and optimization of the loss function, but how to improve the cross-modal semantic feature representation learning is also an important issue. Therefore, deeper semantic mining in the semantic feature learning part is also a direction for our future research. Third, our method was tested on a specific dataset, and common cross-modal hash retrieval methods use data of known categories, but in practical applications, the rapid emergence of new unlabeled things often affects the accuracy of cross-modal data retrieval. How to achieve high precision cross-modal retrieval in the absence of annotation information is also an important research problem.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}