
Nonparametric Estimation of the Density Function of the Distribution of the Noise in CHARN Models


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. On the Kernel Density Estimation
2.1. A Short Review
2.2. Some Properties of the Kernel Estimator
2.3. Bandwidth Selection
3. The Semi-Parametric Models Case
3.1. The Parameter Estimation
3.2. The Kernel Estimation of the Density Function of the Noise
- (A1)
- For all and , is invertible with inverse .
- (A2)
- The functions , and are each continuously differentiable with respect to . There exists a finite positive number r such that the closed ball is contained within , and a positive function with such that
- (A3)
- The true parameter has a consistent estimator satisfyingandwhere “⟹” denotes the convergence in distribution, and is a positive definite matrix.
- (A4)
- is positive, even, and has compact support and bounded variation.
- (A5)
- (A6)
- For all and , as , and , and the sequence of functions is bounded.
3.2.1. The Consistency of to f
3.2.2. The Bias Study
3.2.3. Asymptotic Normality
4. The Nonparametric Models Case
4.1. The Conditional Mean and Variance Functions Estimation
4.2. The Kernel Estimation of the Density of the Noise
- (A7)
- .
Bias Study of
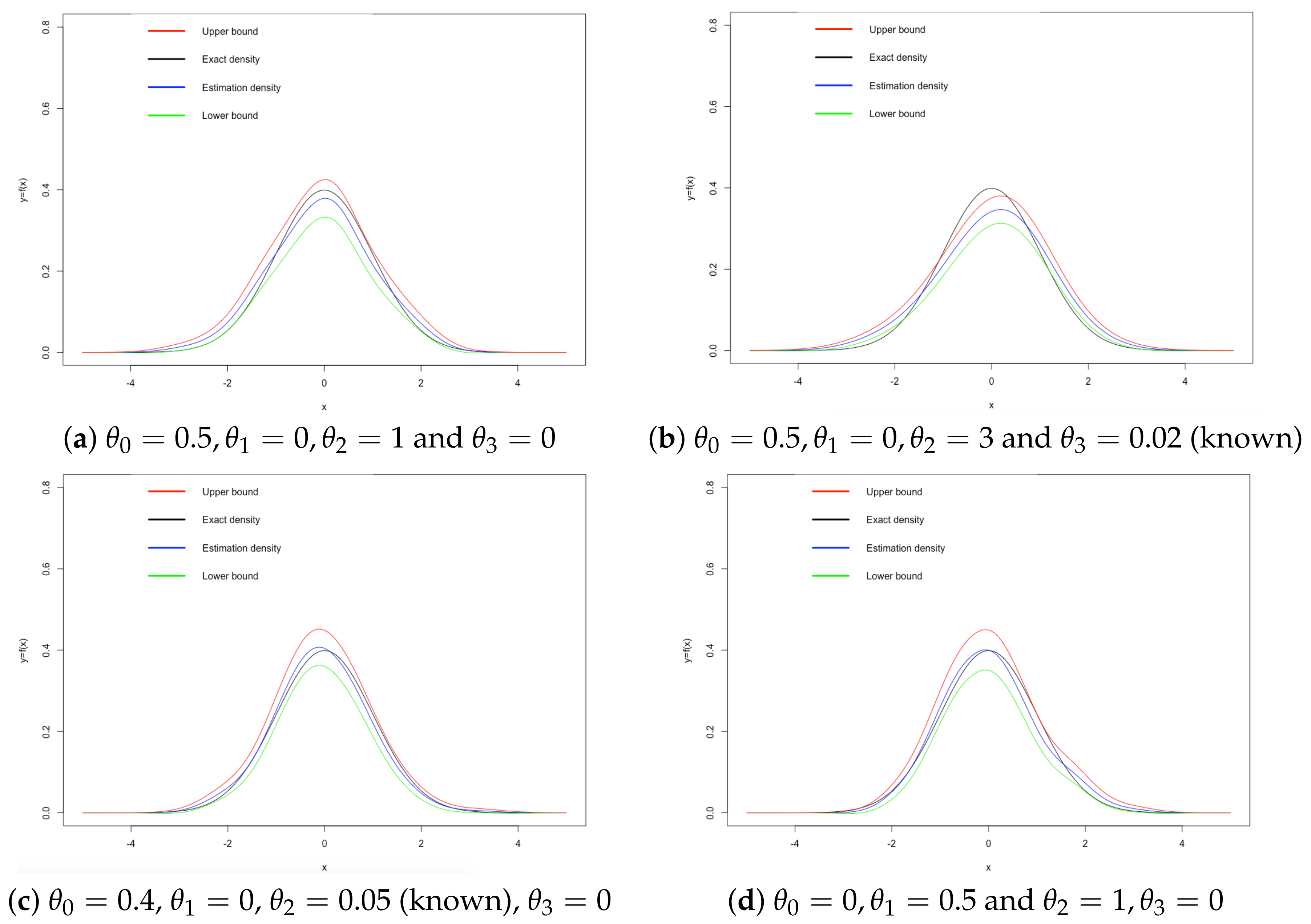
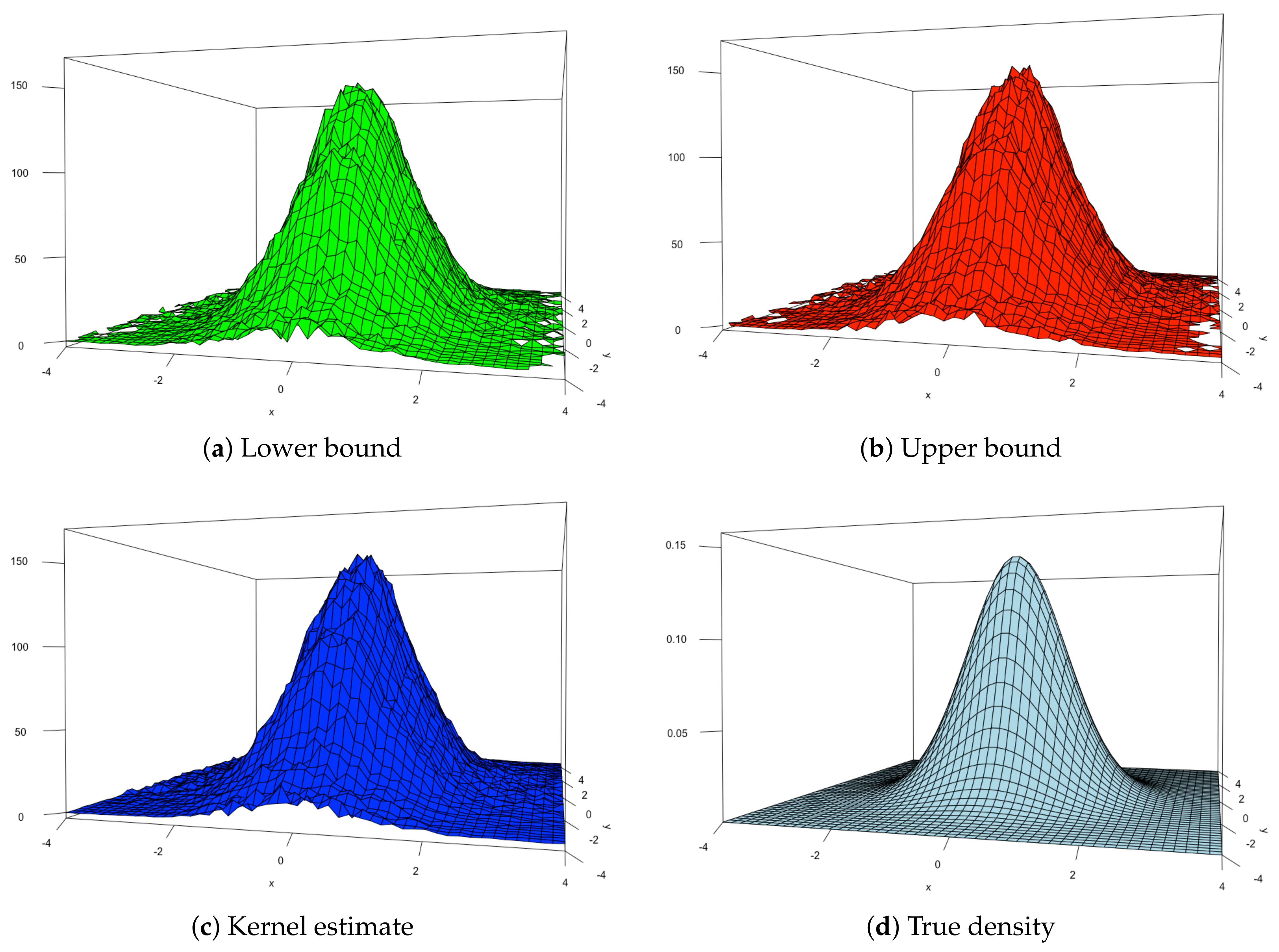
5. Simulation Experiments
5.1. Unidimensional Case
5.2. Bidimensional Case
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Theorem III.3 of Bosq and Lecoutre (1987), p. 65
- 1.
- The set of discontinuity points of has zero measure;
- 2.
- The function is integrable on .
- 1.
- The indicator function is a Geffroy kernel;
- 2.
- Any bounded variation kernel is a Geffroy kernel.
Appendix A.2. Theorem V.2 of Bosq and Lecoutre (1987), p. 75
Appendix A.3. Theorem VIII.2 of Bosq and Lecoutre (1987), p. 86
Appendix A.4. Cesàro Means
References
- Ruppert, D.; Wand, M.; Holst, U.; Hösjer, O. Local polynomial variance-function estimation. Technometrics 1997, 39, 262–273. [Google Scholar] [CrossRef]
- Härdle, W.; Tsybakov, A. Local polynomial estimators of the volatility function in nonparametric autoregression. J. Econom. 1997, 81, 223–242. [Google Scholar] [CrossRef]
- Neumeyer, N.; Pablo, A.; Perri, F. Business cycles in emerging economies: The role of interest rates. J. Monet. Econ. 2005, 52, 345–380. [Google Scholar] [CrossRef] [Green Version]
- Pardo-Fernández, J.; Van Keilegom, I.; González-Manteiga, W. Testing for the equality of k regression curves. Stat. Sin. 2007, 17, 1115–1137. [Google Scholar]
- Dette, H.; Neumeyer, N.; Van Keilegom, I. A new test for the parametric form of the variance function in non-parametric regression. J. R. Stat. Soc. Ser. B 2007, 69, 903–917. [Google Scholar] [CrossRef] [Green Version]
- Neumeyer, N.; Van Keilegom, I. Estimating the error distribution in nonparametric multiple regression with applications to model testing. J. Multivar. Anal. 2010, 101, 1067–1078. [Google Scholar] [CrossRef] [Green Version]
- Engle, R. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T.; Chou, R.; Kroner, K. ARCH modeling in finance: A review of the theory and empirical evidence. J. Econom. 1992, 52, 5–59. [Google Scholar] [CrossRef]
- Gourieroux, C.; Monfort, A. Qualitative threshold ARCH models. J. Econom. 1992, 52, 159–199. [Google Scholar] [CrossRef] [Green Version]
- Härdle, W.; Mammen, E.; Müller, M. Testing parametric versus semiparametric modeling in generalized linear models. J. Am. Stat. Assoc. 1998, 93, 1461–1474. [Google Scholar] [CrossRef]
- Brockwell, P.; Davis, R. Introduction to Time Series and Forecasting; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Geffroy, J. Sur la convergence uniforme des estimateurs d’une densité de probabilité. Séminaire de Statistique ISUP 1973. [Google Scholar]
- Scott, D.; Tapia, R.; Thompson, J. Multivariate density estimation by discrete maximum penalized likelihood methods. In Graphical Representation of Multivariate Data; Elsevier: Amsterdam, The Netherlands, 1978; pp. 169–182. [Google Scholar]
- Deheuvels, P. Estimation non paramétrique de la densité par histogrammes généralisés. Rev. Stat. Appliquée 1977, 25, 5–42. [Google Scholar]
- Deheuvels, P. Non Parametric Tests of Independence. In Statistique non Paramétrique Asymptotique; Springer: Berlin/Heidelberg, Germany, 1980; pp. 95–107. [Google Scholar]
- Prakasa-Rao, B. Asymptotic theory for non-linear least squares estimator for diffusion processes. J. Theor. Appl. Stat. 1983, 14, 195–209. [Google Scholar] [CrossRef]
- Devroye, L.; Gyorfi, L. Nonparametric Density Estimation: The L1 View; Wiley: New York, NY, USA, 1985. [Google Scholar]
- Bosq, D.; Lecoutre, J.P. Theorie de L’estimation Fonctionnelle; Economica: Paris, France, 1987. [Google Scholar]
- Silverman, B. Density Estimation for Statistics and Data Analysis; Chapman and Hall: London, UK, 1986. [Google Scholar]
- Pearson, K. On the systematic fitting of curves to observations and measurements I, II. Biometrika 1902, 1, 265–303. [Google Scholar] [CrossRef]
- Pearson, K. On the systematic fitting of curves to observations and measurements I, II. Biometrika 1902, 2, 1–23. [Google Scholar] [CrossRef]
- Rosenblatt, M. Remark on some nonparametric estimates of a density function. Ann. Math. Statist. 1956, 27, 832–837. [Google Scholar] [CrossRef]
- Silverman, B.; Jones, M. E. Fix and J.L. Hodges (1951): An important contribution to nonparametric discriminant analysis and density estimation. Int. Stat. Rev. 1989, 57, 233–247. [Google Scholar] [CrossRef]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Cacoullos, T. On a Class of Admissible Partitions. Ann. Math. Stat. 1966, 37, 189–195. [Google Scholar] [CrossRef]
- Bierens, H. Uniform consistency of kernel estimators of a regression function under generalized conditions. J. Am. Stat. Assoc. 1983, 78, 699–707. [Google Scholar] [CrossRef]
- Devroye, L.; Penrod, C. Distribution-free lower bounds in density estimation. Ann. Stat. 1984, 12, 1250–1262. [Google Scholar] [CrossRef]
- Abdous, B. Étude d’une classe d’estimateurs à noyaux de la densité une loi de probabilité. Ph.D. Thesis, Paris, France, 1986. [Google Scholar]
- Tsybakov, A. Introduction to Nonparametric Estimation; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Tiago de Oliveira, M. Chromatographic isolation of monofluoroacetic acid from Palicourea marcgravii St. Hil. Experientia 1963, 19, 586–587. [Google Scholar] [CrossRef] [PubMed]
- Heidenreich, N.B.; Schindler, A.; Sperlich, S. Bandwidth selection for kernel density estimation: A review of fully automatic selectors. Adv. Stat. Anal. 2013, 97, 403–433. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Racine, J. Nonparametric Econometrics: Theory and Practice; Princeton University Press: Princeton, NJ, USA, 2007. [Google Scholar]
- Lecoutre, J.P. Convergence et Optimisation de Certains Estimateurs des Densités de Probabilité. Ph.D. Thesis, 1975. [Google Scholar]
- Chandra, S.; Taniguchi, M. Estimating functions for nonlinear time series models. Ann. Inst. Stat. Math. 2001, 53, 125–141. [Google Scholar] [CrossRef]
- Amano, T. Asymptotic Optimality of Estimating Function Estimator for CHARN Model. Adv. Decis. Sci. 2012, 2012, 515494. [Google Scholar] [CrossRef]
- Kanai, H.; Ogata, H.; Taniguchi, M. Estimating function approach for CHARN models. Metron 2010, 68, 1–21. [Google Scholar] [CrossRef]
- Godambe, V. An optimum property of regular maximum likelihood estimation. Ann. Math. Stat. 1960, 31, 1208–1211. [Google Scholar] [CrossRef]
- Godambe, V. The foundations of finite sample estimation in stochastic processes. Biometrika 1985, 72, 419–428. [Google Scholar] [CrossRef]
- Hansen, L. Large sample properties of generalized method of moments estimators. J. Econom. Soc. 1982, 50, 1029–1054. [Google Scholar] [CrossRef]
- Li, D.; Turtle, H. Semiparametric ARCH models: An estimating function approach. J. Bus. Econ. Stat. 2000, 18, 174–186. [Google Scholar]
- Ngatchou-Wandji, J. Estimation in a class of nonlinear heteroscedastic time series models. Electron. J. Stat. 2008, 2, 40–62. [Google Scholar] [CrossRef]
- Ozaki, T. Non-linear time series models for non-linear random vibrations. J. Appl. Probab. 1980, 17, 84–93. [Google Scholar] [CrossRef]
- Chan, K.S.; Tong, H. On the use of the deterministic Lyapunov function for the ergodicity of stochastic difference equations. Adv. Appl. Probab. 1985, 17, 666–678. [Google Scholar] [CrossRef]
- Al-Qassam, M.; Lane, J. Forecasting exponential autoregressive models of order 1. J. Time Ser. Anal. 1989, 10, 95–113. [Google Scholar] [CrossRef]
- Koul, H.L.; Schick, A. Efficient estimation in nonlinear autoregressive time-series models. Bernoulli 1997, 3, 247–277. [Google Scholar] [CrossRef]
- Ismail, M. Bayesian analysis of exponential AR models. Far East J. Stat. 2001, 5, 1–15. [Google Scholar]
- Baragona, R.; Battaglia, F.; Cucina, D. A note on estimating autoregressive exponential models. Quad. Stat. 2002, 4, 71–88. [Google Scholar]
- Ghosh, H.; Gurung, B.; Gupta, P. Fitting EXPAR models through the extended Kalman filter. Sankhya B 2015, 77, 27–44. [Google Scholar] [CrossRef]
- Rosenblatt, M. Conditional Probability Density and Regression Estimator; Academic Press: New York, NY, USA, 1969. [Google Scholar]
- Noda, K. Estimation of a regression function by the Parzen kernel type density estimators. Ann. Inst. Statist. Math. 1976, 28, 221–234. [Google Scholar] [CrossRef]
- Greblicki, W.; Krzyzak, A. Asymptotic properties of kernel estimates of a regression function. J. Stat. Plan. Inference 1980, 4, 81–90. [Google Scholar] [CrossRef]
- Collomb, G. Conditions nécessaires et suffisantes de convergence uniforme d’un estimateur de la régression, estimation des dérivées de la régression. CRAS 1979, A, 161–163. [Google Scholar]
- Nadaraya, E.A. Some new estimates for distribution functions. Theory Probab. Appl. 1964, 9, 497–500. [Google Scholar] [CrossRef]
- Nadaraya, E. On non-parametric estimates of density functions and regression curves. Theory Probab. Appl. 1965, 10, 186–190. [Google Scholar] [CrossRef]
- Devroye, L. The uniform convergence of nearest neighbor regression function estimators and their application in optimization. IEEE Trans. Inf. Theory 1978, 24, 142–151. [Google Scholar] [CrossRef] [Green Version]
- Devroye, L.P. The uniform convergence of the nadaraya-watson regression function estimate. Can. J. Stat. 1978, 6, 179–191. [Google Scholar] [CrossRef]
- Schuster, E.; Yakowitz, S. Contributions to the theory of nonparametric regression, with application to system identification. Ann. Stat. 1979, 7, 139–149. [Google Scholar] [CrossRef]
- Hardle, W.; Luckhaus, S. Uniform consistency of a class of regression function estimators. Ann. Stat. 1984, 12, 612–623. [Google Scholar] [CrossRef]
- Devroye, L.; Wagner, T. Distribution-free consistency results in nonparametric discrimination and regression function estimation. Ann. Stat. 1980, 8, 231–239. [Google Scholar] [CrossRef]
- Devroye, L.; Wagner, T. The strong uniform consistency of kernel density estimates. In Proceedings of the fifth International Symposium on Multivariate Analysis, New York, NY, USA, 1 January 1980; Volume 5, pp. 59–77. [Google Scholar]
- Spiegelman, C.; Sacks, J. Consistent window estimation in nonparametric regression. Ann. Stat. 1980, 8, 240–246. [Google Scholar] [CrossRef]
- Devroye, L. On the almost everywhere convergence of nonparametric regression function estimates. Ann. Stat. 1981, 9, 1310–1319. [Google Scholar] [CrossRef]
- Collomb, G. Estimation non paramétrique de la régression par la méthode du noyau: Propriété de convergence asymptotiquememt normale indépendante. Mathematics 1977, 65, 24–46. [Google Scholar]
- Collomb, G. Estimation non-paramétrique de la régression: Revue bibliographique. Int. Stat. Rev. 1981, 49, 75–93. [Google Scholar] [CrossRef]
- Härdle, W.; Tsybakov, A.; Yang, L. Nonparametric vector autoregression. J. Stat. Plan. Inference 1998, 68, 221–245. [Google Scholar] [CrossRef]
- Collomb, G.; Härdle, W. Strong uniform convergence rates in robust nonparametric time series analysis and prediction: Kernel regression estimation from dependent observations. Stoch. Process. Their Appl. 1986, 23, 77–89. [Google Scholar] [CrossRef] [Green Version]
- Laïb, N.; Ould-Saïd, E. A robust nonparametric estimation of the autoregression function under an ergodic hypothesis. Can. J. Stat. 2000, 28, 817–828. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Yao, Q. Efficient estimation of conditional variance functions in stochastic regression. Biometrika 1998, 85, 645–660. [Google Scholar] [CrossRef] [Green Version]
- Linton, O.; Yan, Y. Semi-and nonparametric arch processes. J. Probab. Stat. 2011, 2011, 906212. [Google Scholar] [CrossRef] [Green Version]
- Franke, J.; Neumann, M.; Stockis, J.P. Bootstrapping nonparametric estimators of the volatility function. J. Econom. 2004, 118, 189–218. [Google Scholar] [CrossRef]
- Laïb, N. Kernel estimates of the mean and the volatility functions in a nonlinear autoregressive model with ARCH errors. J. Stat. Plan. Inference 2005, 134, 116–139. [Google Scholar] [CrossRef]
- Ziegelmann, F. Nonparametric estimation of volatility functions: The local exponential estimator. Econom. Theory 2002, 18, 985–991. [Google Scholar] [CrossRef]
- Kristensen, D. Nonparametric filtering of the realized spot volatility: A kernel-based approach. Econom. Theory 2010, 26, 60–93. [Google Scholar] [CrossRef]
- Zu, Y.; Boswijk, H. Estimating spot volatility with high-frequency financial data. J. Econom. 2014, 181, 117–135. [Google Scholar] [CrossRef] [Green Version]
- Maillot, B. Propriétés Asymptotiques de Quelques Estimateurs Non-Paramétriques Pour des Variables Vectorielles et Fonctionnelles. Ph.D. Thesis, Université du Littoral, Paris, France, 2008. [Google Scholar]
- Chesneau, C.; Fadili, J.; Maillot, B. Adaptive estimation of an additive regression function from weakly dependent data. J. Multivar. Anal. 2015, 133, 77–94. [Google Scholar] [CrossRef]
- Crambes, C.; Delsol, L.; Laksaci, A. Robust nonparametric estimation for functional data. J. Nonparametr. Stat. 2008, 20, 573–598. [Google Scholar] [CrossRef]
- Gheriballah, A.; Laksaci, A.; Rouane, R. Robust nonparametric estimation for spatial regression. J. Stat. Plan. Inference 2010, 140, 1656–1670. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngatchou-Wandji, J.; Ltaifa, M.; Njamen Njomen, D.A.; Shen, J. Nonparametric Estimation of the Density Function of the Distribution of the Noise in CHARN Models. Mathematics 2022, 10, 624. https://doi.org/10.3390/math10040624
Ngatchou-Wandji J, Ltaifa M, Njamen Njomen DA, Shen J. Nonparametric Estimation of the Density Function of the Distribution of the Noise in CHARN Models. Mathematics. 2022; 10(4):624. https://doi.org/10.3390/math10040624
Chicago/Turabian StyleNgatchou-Wandji, Joseph, Marwa Ltaifa, Didier Alain Njamen Njomen, and Jia Shen. 2022. "Nonparametric Estimation of the Density Function of the Distribution of the Noise in CHARN Models" Mathematics 10, no. 4: 624. https://doi.org/10.3390/math10040624