
Revisiting the Copula-Based Trading Method Using the Laplace Marginal Distribution Function


Abstract
:1. Introduction
2. Laplace Distribution
3. A Review of Pairs Trade
4. An Algorithm Based on the Laplace Distribution
| Algorithm 1 Pairs trade employing the Laplace marginal distribution function. |
|
5. Simulation Results
6. Conclusions
- How to determine the best pairs while limiting the search space; and,
- How to stop facing long decline periods due to prolonged divergent pairs.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Basel Committee on Banking Supervision. Basel III: A Global Regulatory Framework for More Resilient Banks and Banking Systems; Basel Committee on Banking Supervision: Basel, Switzerland, 2011. [Google Scholar]
- Company, R.; Egorova, V.N.; Jódar, L.; Soleymani, F. A stable local radial basis function method for option pricing problem under the Bates model. Numer. Methods Part. Differ. Equ. 2019, 35, 1035–1055. [Google Scholar] [CrossRef]
- Tsoulos, I.G.; Kosmas, O.T.; Stavrou, V.N. DiracSolver: A tool for solving the Dirac equation. Comput. Phys. Commun. 2019, 236, 237–243. [Google Scholar] [CrossRef] [Green Version]
- Alexander, C. Market Risk Analysis, Chichester; John Wiley & Sons Ltd.: West Sussex, UK, 2008. [Google Scholar]
- Kinlay, J. Pairs Trading with Copulas. 2019, pp. 1–9. Available online: community.wolfram.com (accessed on 26 January 2022).
- Maneejuk, P.; Yamaka, W. The role of economic contagion in the inward investment of emerging economies: The dynamic conditional copula approach. Mathematics 2021, 9, 2540. [Google Scholar] [CrossRef]
- Sklar, A. Fonctions de répartition à n dimension et leurs marges. Publ. L’Institut Stat. L’Université Paris 1959, 8, 229–231. [Google Scholar]
- Okhrin, O.; Ristig, A.; Xu, Y.-F. Copulae in High Dimensions: An Introduction. Appl. Quant. Financ. Stat. Comput. 2017, 13, 247–277. [Google Scholar]
- Gerlach, R.; Lu, Z.; Huang, H. Exponentially smoothing the skewed Laplace distribution for value-at-risk forecasting. J. Forecast. 2013, 32, 534–550. [Google Scholar] [CrossRef]
- Ghanadian, A.; Lotfi, T. Approximate solution of nonlinear Black-Scholes equation via a fully discretized fourth-order method. AIMS Math. 2020, 5, 879–893. [Google Scholar] [CrossRef]
- Itkin, A.; Soleymani, F. Four-factor model of quanto CDS with jumps-at-default and stochastic recovery. J. Comput. Sci. 2021, 54, 101434. [Google Scholar] [CrossRef]
- Ernst, P.A.; Soleymani, F. A Legendre-based computational method for solving a class of Itô stochastic delay differential equations. Numer. Algorithms 2019, 80, 1267–1282. [Google Scholar] [CrossRef]
- Kotz, S.; Kozubowski, T.J.; Podgórski, K. The Laplace Distribution and Generalizations: A Revisit with Applications to Communications, Economics, Engineering and Finance; Birkhauser: Basel, Switzerland, 2001. [Google Scholar]
- Taylor, J. Forecasting value at risk and expected shortfall using a semiparametric approach based on the asymmetric Laplace distribution. J. Bus. Econ. Stat. 2019, 37, 121–133. [Google Scholar] [CrossRef]
- Blázquez, M.C.; De la Cruz, C.D.O.; Román, C.P. Pairs trading techniques: An empirical contrast. Eur. Res. Manag. Bus. Econ. 2018, 24, 160–167. [Google Scholar] [CrossRef]
- Do, B.; Faff, R. Does simple pairs trading still work? Finan. Anal. J. 2010, 66, 83–95. [Google Scholar] [CrossRef]
- Soleymani, F.; Vasighi, M. Efficient portfolio construction by means of CVaR and k-means++ clustering analysis: Evidence from the NYSE. Int. J. Finan. Econ. 2021, 1–15. [Google Scholar] [CrossRef]
- Rice, J.A. Mathematical Statistics and Data Analysis, 3rd ed.; Thomson Brooks/Cole.: Belmont, CA, USA, 2007. [Google Scholar]
- Georgakopoulos, N.L. Illustrating Finance Policy with Mathematica; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar]
- Liew, R.Q.; Wu, Y. Pairs trading: A copula approach. J. Deriv. Hedge Funds 2013, 19, 12–30. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
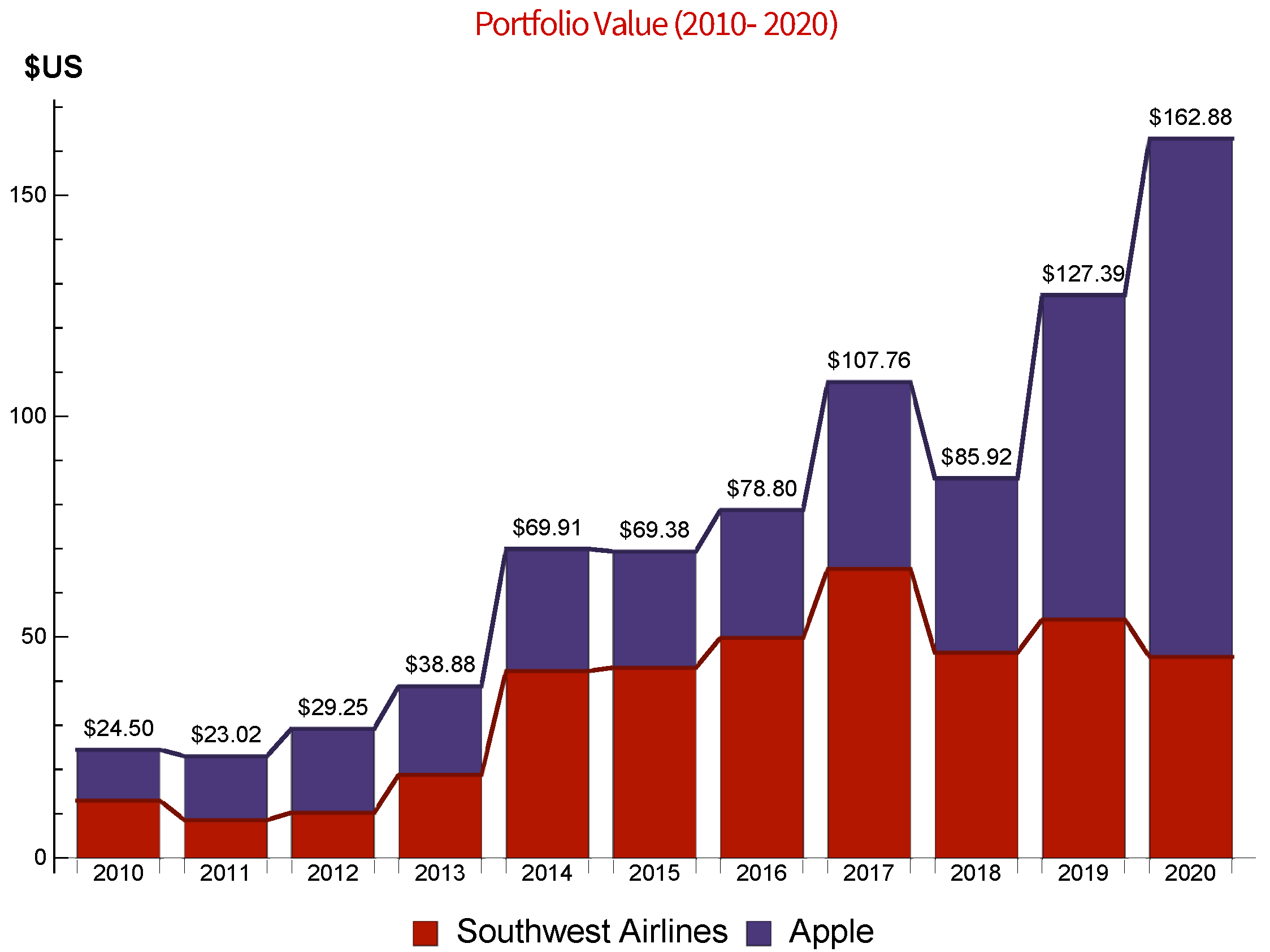
| Title | Symbol of Ticker | Market | Sector | Floating Shares | In-Sample Formation Period | Out of Sample Period |
|---|---|---|---|---|---|---|
| Southwest Airlines | NYSE:LUV | NYSE | Airlines | 590273067 | 1 January 2015 through 31 December 2019 | 4 January 2020 through 20 November 2020 |
| Apple | NASDAQ:AAPL | NASDAQ | Consumer Electronics | 17001802000 | 1 January 2015 through 31 December 2019 | 4 January 2020 through 20 November 2020 |
| NYSE:LUV | NASDAQ:AAPL | |||
|---|---|---|---|---|
| Statistical Test | Statistic | p-Value | Statistic | p-Value |
| Pearson | 121.37 | 9.61 × 10 | 144.16 | 1.60 × 10 |
| Cramér-von Mises | 2.12 | 6.75 × 10 | 2.47 | 1.09 × 10 |
| Anderson-Darling | 12.23 | 1.82 × 10 | 14.21 | 6.50 × 10 |
| Baringhaus-Henze | 17.12 | 1.27 × 10 | 21.01 | 1.21 × 10 |
| Jarque-Bera ALM | 1510.45 | 0. | 896.42 | 0. |
| Mardia Combined | 1510.45 | 0. | 896.42 | 0. |
| Mardia Kurtosis | 37.95 | 2.86 × 10 | 29.25 | 3.64 × 10 |
| Mardia Skewness | 49.46 | 2.02 × 10 | 27.98 | 1.22 × 10 |
| Shapiro–Wilk | 0.94 | 1.46 × 10 | 0.94 | 2.67 × 10 |
| NYSE:LUV | NASDAQ:AAPL | |||
|---|---|---|---|---|
| Statistical Test | Statistic | p-Value | Statistic | p-Value |
| Pearson | 34.20 | 0.45 | 48.14 | 0.05 |
| Cramér-von Mises | 0.10 | 0.58 | 0.19 | 0.27 |
| Anderson-Darling | 0.67 | 0.57 | 1.10 | 0.30 |
| Pearson | Spearman | Kendall | |
|---|---|---|---|
| Overall | 0.380776 | 0.360071 | 0.250801 |
| Lower 5%-tile | 0.375530 | 0.438191 | 0.323109 |
| Upper 95%-tile | 0.349495 | 0.333201 | 0.230797 |
| NYSE:LUV | NASDAQ:AAPL | Probability | |
|---|---|---|---|
| 6 January 2020 | 0.01580 | 0.02255 | 0.02 |
| 7 January 2020 | −0.00897 | −0.00976 | 0.65 |
| 8 January 2020 | −0.00405 | 0.00793 | 0.20 |
| 9 January 2020 | 0.00295 | −0.00471 | 0.33 |
| 10 January 2020 | 0.00147 | 0.01595 | 0.08 |
| 13 January 2020 | −0.00128 | 0.02101 | 0.06 |
| 14 January 2020 | −0.00665 | 0.00225 | 0.35 |
| 15 January 2020 | 0.00092 | 0.02113 | 0.05 |
| 16 January 2020 | 0.00921 | −0.01359 | 0.23 |
| 17 January 2020 | 0.00986 | −0.00429 | 0.19 |
| 21 January 2020 | 0.00489 | 0.01248 | 0.09 |
| 22 January 2020 | −0.00525 | 0.01101 | 0.16 |
| 23 January 2020 | −0.02708 | −0.00679 | 0.72 |
| 24 January 2020 | −0.00112 | 0.00356 | 0.26 |
| 27 January 2020 | 0.03527 | 0.00480 | 0.01 |
| 28 January 2020 | 0.02054 | −0.00288 | 0.08 |
| 29 January 2020 | −0.00531 | −0.02984 | 0.67 |
| 30 January 2020 | 0.02371 | 0.02789 | 0.009 |
| 31 January 2020 | −0.01240 | 0.02071 | 0.07 |
| 3 February 2020 | −0.01880 | −0.00145 | 0.55 |
| 4 February 2020 | −0.01534 | −0.04535 | 0.85 |
| 5 February 2020 | 0.00435 | −0.00275 | 0.28 |
| 6 February 2020 | 0.00829 | 0.03248 | 0.01 |
| 7 February 2020 | 0.02255 | 0.00812 | 0.04 |
| 10 February 2020 | 0.01343 | 0.01162 | 0.05 |
| 11 February 2020 | −0.00800 | −0.01605 | 0.69 |
| 12 February 2020 | 0.00279 | 0.00473 | 0.19 |
| 13 February 2020 | 0.00884 | −0.00605 | 0.21 |
| 14 February 2020 | 0.00944 | 0.02347 | 0.03 |
| 18 February 2020 | 0.00102 | −0.00714 | 0.40 |
| 19 February 2020 | −0.00978 | 0.00024 | 0.44 |
| 20 February 2020 | −0.00640 | −0.01848 | 0.67 |
| 21 February 2020 | −0.00854 | 0.01437 | 0.13 |
| 24 February 2020 | −0.00298 | −0.01031 | 0.54 |
| 25 February 2020 | −0.00722 | −0.02289 | 0.70 |
| 26 February 2020 | −0.04375 | −0.04866 | 0.98 |
| 27 February 2020 | −0.08581 | −0.03445 | 0.97 |
| 28 February 2020 | −0.01542 | 0.01573 | 0.12 |
| 2 March 2020 | −0.04753 | −0.06760 | 0.98 |
| 3 March 2020 | −0.00948 | −0.00058 | 0.47 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nadaf, T.; Lotfi, T.; Shateyi, S. Revisiting the Copula-Based Trading Method Using the Laplace Marginal Distribution Function. Mathematics 2022, 10, 783. https://doi.org/10.3390/math10050783
Nadaf T, Lotfi T, Shateyi S. Revisiting the Copula-Based Trading Method Using the Laplace Marginal Distribution Function. Mathematics. 2022; 10(5):783. https://doi.org/10.3390/math10050783
Chicago/Turabian StyleNadaf, Tayyebeh, Taher Lotfi, and Stanford Shateyi. 2022. "Revisiting the Copula-Based Trading Method Using the Laplace Marginal Distribution Function" Mathematics 10, no. 5: 783. https://doi.org/10.3390/math10050783
APA StyleNadaf, T., Lotfi, T., & Shateyi, S. (2022). Revisiting the Copula-Based Trading Method Using the Laplace Marginal Distribution Function. Mathematics, 10(5), 783. https://doi.org/10.3390/math10050783