Abstract
Text representation is an important topic in the field of natural language processing, which can effectively transfer knowledge to downstream tasks. To extract effective semantic information from text with unsupervised methods, this paper proposes a quantum language-inspired tree structural text representation model to study the correlations between words with variable distance for semantic analysis. Combining the different semantic contributions of associated words in different syntax trees, a syntax tree-based attention mechanism is established to highlight the semantic contributions of non-adjacent associated words and weaken the semantic weight of adjacent non-associated words. Moreover, the tree-based attention mechanism includes not only the overall information of entangled words in the dictionary but also the local grammatical structure of word combinations in different sentences. Experimental results on semantic textual similarity tasks show that the proposed method obtains significant performances over the state-of-the-art sentence embeddings.
1. Introduction
The parallelism of quantum computing has attracted more and more attention in different fields. Some scholars have combined quantum computing with natural language processing (NLP). In the quantum computing-based text representation model, the word vector was multiplied by its own transposed vector tensor to obtain a density matrix, and the weighted density matrix was summed to obtain a sentence tensor representation [1,2].
where denoted the trace operation. The probability that event belongs to a system was defined as the semantic measurement [3],
where .
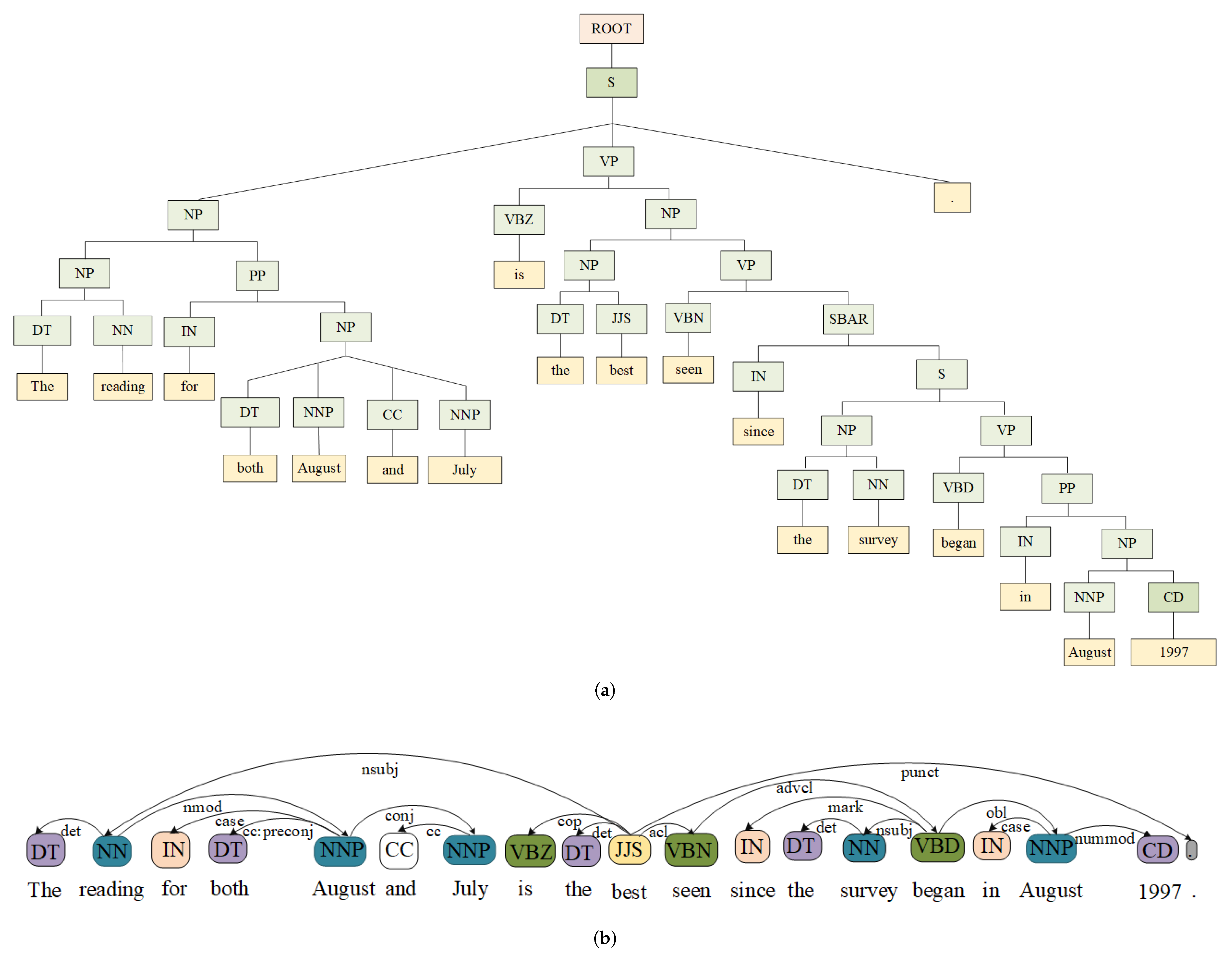
The association between adjacent words with all of the entanglement coefficients set to 1 was discussed, ignoring the long-range modified relationship between non-adjacent words [4]. When the sentence structure is complex, the two words that have a direct modified relationship are not necessarily in close proximity. Especially for long sentences, the complex syntactic structure makes adjacent words not necessarily grammatically related, and the grammatically related words separated by several words. Take the following sentence for example with the constituency parser and the dependency parser (https://nlp.stanford.edu/software/lex-parser.shtml (accessed on 1 October 2020)) of shown in Figure 1.
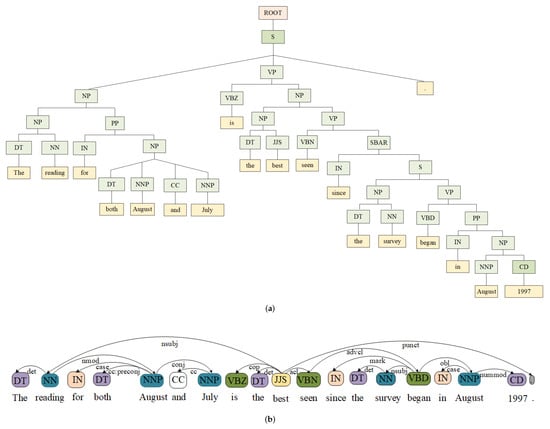
Figure 1.
: (a) constituency parser; (b) dependency parser. : The reading for both August and July is the best seen since the survey began in August 1997.
According to the adjacent words to form a related phrase, the closest to the word is the nominal word , but the two syntax trees in Figure 1 both show that there is no direct modification relationship between the two words. The dependent relation between and is (nominal subject), but the distance between them is 8 words, meaning that at least 9-gram can contain both of the words. If the 9-gram is considered, it will contain at least seven irrelevant words except and , thus introducing semantic errors. Furthermore, the distance difference between two words of different relation entities is different, which requires the size of the kernel function to change according to the change of the distance difference between the two ends of the relation entity. Obviously, this is difficult to achieve in reality. AS different weights of part-of-speech (PoS) combinations of entangled word have different influences on sentence semantics [5], PoS combination weight can be integrated with the attention mechanism to express the different modified relationship. Inspired by the density matrix and attention mechanism, a quantum language-inspired tree structural text representation model is established to reflect the association between variable distance words.
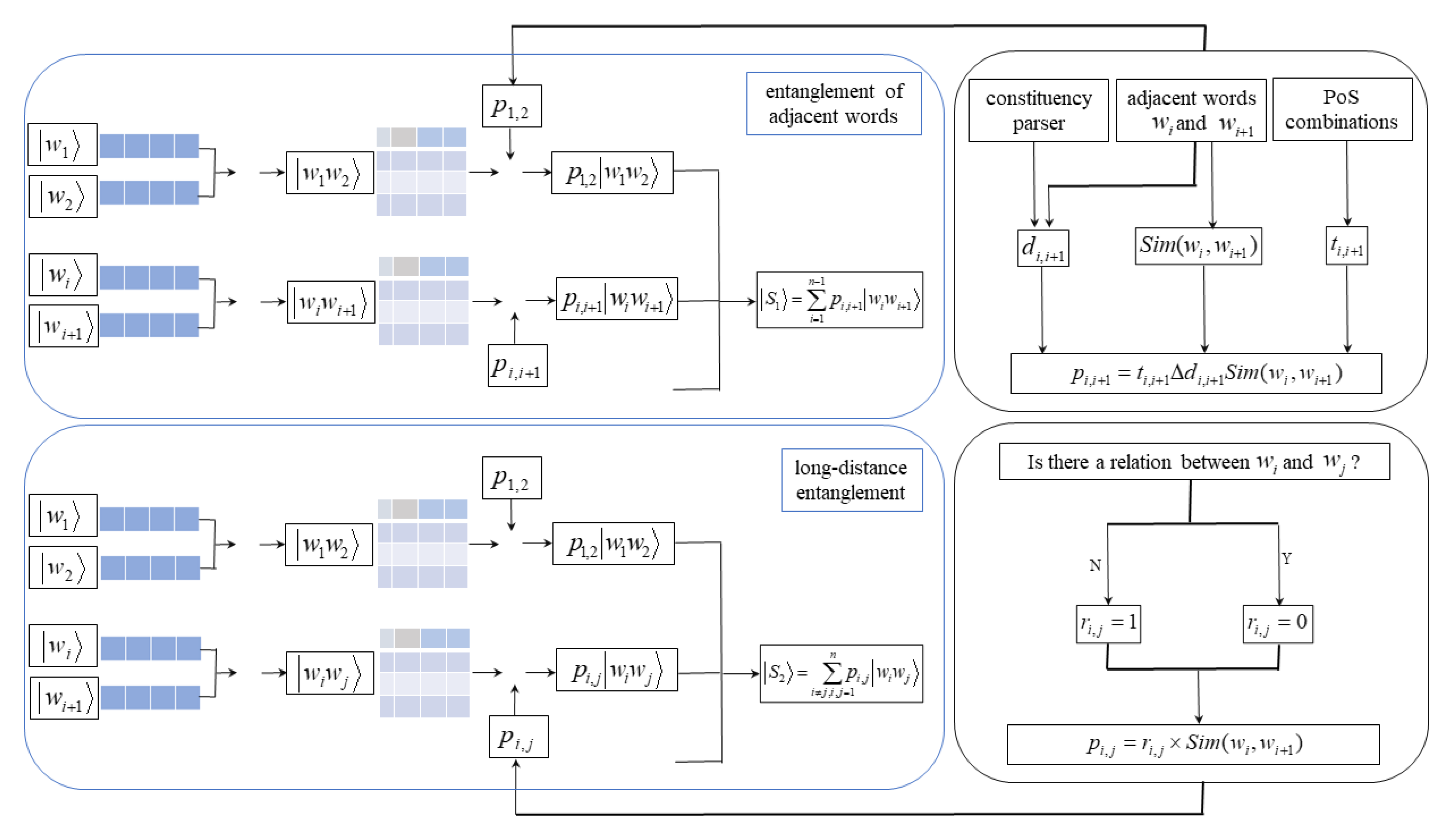
As different syntactic tree structures reflect different associations between words, different semantic association models between words according to the dependency parser and constituency parser of sentences are constructed. According to the association between relation entities in the dependency parser of the sentence, the text representation based on the dependency parser combines the word vector tensors of two words with relation entities to establish the semantics between long-distance dependent words with relation entities entanglement, so that distant words with a direct modified relationship can also be semantically related. According to the different degrees of modified relationship between words in the constituency parser, the text representation based on the constituency parser combines the semantic correlation coefficient with the distribution characteristics of adjacent words to establish the semantic association. The proposed model consists of two parts, as shown in Figure 2. The first part is composed of all of the tensor products of the two adjacent words in a sentence, combining the characteristics to establish the contribution of the short-range dependence between words to the semantics. The second part consists of the two words with long-range dependency of the direct modified relationship. Finally, the entanglement between adjacent words is integrated with the word entanglement of direct long-range modified relationship to form the sentence representation.
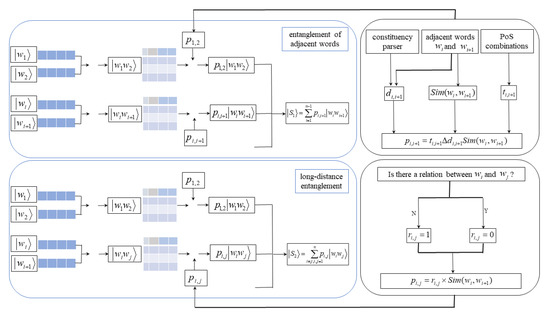
Figure 2.
Flowchart of the quantum language-inspired tree structural text representation model.
In brief, the contributions of this work are as follows.
- (1)
- A quantum language-inspired text representation model based on relation entity and constituency parser is established, including long-range and short-range semantic associations between words.
- (2)
- The combination of attention mechanism and entanglement coefficient reduces the semantic impact of indirect modified relationships between adjacent words and enhances the semantic contribution of direct modified relationships with long-range associations.
- (3)
- The attention mechanism contains not only the overall information of the related words in the dictionary, but also the local grammatical structure of different sentences.
- (4)
- The semantic association between words with variable distances is established by combining the dependency parser.
The rest of the paper is organized as follows. Section 2 summarizes some related literature on attention-based semantic analysis, the dependency tree and quantum based NLP. Section 3 explains the approach in detail. The experimental settings are presented in Section 4. Section 5 describes the experimental results and lists the detailed effects of different parameters. In Section 6, some conclusions are drawn.
2. Related Work
2.1. Attention-Based Semantic Analysis
The neural network-based methods use the attention mechanism to assign different semantic weights to words with good experimental results in many downstream tasks, such as LSTM [6], BiLSTM [7] and BERT [8]. Semantic analysis based on attention mechanism has been involved in many works [9,10,11] and can reflect the different weights of words in different texts. The attention mechanism is introduced to obtain different weight of words in order to extract enough key information. Semantic analysis can be applied to many problems such as image-text matching [12], question answering [13,14], knowledge extraction [15,16,17,18,19], and entailment reasoning [20]. To discover visual-textual interactions across different dimensions of concatenations, memory attention networks were adopted while marginalizing the effect of other dimensions [12]. A deep multimodal network with a top-k ranking loss mitigated the data ambiguity problem for image-sentence matching [21]. LSTM with a bilinear attention function was adopted to infer the image regions [22]. A mutual attention mechanism between the local semantic features and global long-term dependencies was introduced for mutual learning [23]. A scheme of the efficient semantic label extraction was developed to achieve an accurate image-text similarity measure [24].
Compared to the previous works mentioned above, the method proposed here is mainly based on the traditional attention mechanism, which mainly reflects the relation dependency between input and hidden without considering the relations of input words. The transformer mainly relies on attention mechanisms [25]. An improved self-attention module was proposed by introducing low-rank and locality linguistic constraints [26]. With the introduction of the self-attention mechanism, new models based on transformer obtained much success in semantic analysis on large datasets [27,28,29]. The new model BERT [30] and its variants [31,32] based on transformer divided the pretraining methods into feature-based methods and fine-tuning methods [33].
2.2. Dependency Tree
Relation extraction plays a very important role in extracting structured information from unstructured text resources. The dependency tree not merely expresses the semantics of sentences but also reflects the modified relationship relationship between words. Each note in dependency trees represents a word, and every word has at least one grammatically related word. The dependency tree is constituted by the head word, PoS of the head word, dependent word, PoS of the dependent word and the label of dependency. The works on the dependency tree are mainly divided into two categories: statistics-based models and deep-learning-based models [34]. Wang et al. structured a regional CNN-LSTM model based on a subtree to analyze sentiment predictions [35]. A reranking approach for the dependency tree was provided utilizing complex subtree representations [36]. A bidirectional dependency tree representation was provided to extract dependency features from the input sentences [37]. Zhang et al. [38] tried to upgrade the synchronous tree substitution grammar-based syntax translation model by utilizing the string-to-tree translation model. A graph-based dependency parsing model was presented by Chen et al. [39]. A bidirectional tree-structured LSTM was provided to extract structural features based on the dependency tree [40]. Fei et al. utilized a dependency-tree-based RNN to extract syntactic features and used the CRF layer to decode the sentence labels [41]. Global reasoning on a dependency tree parsed from the question was performed [42]. A phrase-based text embedding considering the integrity of semantic with a structured representation is reported [43].
2.3. Quantum Based NLP
In recent years, the application of quantum language models (QLM) in NLP has attracted more and more attention [44]. Aerts and Sozzo theoretically proved that under some conditions, the joint probability density of the two entities selected to define the uncertainty of selection to establish an entanglement between the concepts was reasonable [45]. Quantum theory is applied to neural networks to form quantum neural networks. To achieve comparable or better results, quantum network needed far fewer epochs and a much smaller network [46]. Quantum probability was first practically applied in information retrieval (IR) with significant improvements over a robust bag-of-words baseline [47,48,49,50,51,52]. At the same time, an unseparable semantic entity was used in IR, considering the pure high-order dependence among words or phrases [53]. On this basis, quantum entanglement (QE) was applied to terms dependency co-occurrences on quantum language models with theoretical proof of the connection between QE and statistically unconditional pure dependence [54].
Commonly, semantic representation generalized quantum or quantum-like use Hilbert spaces to model concepts, and the similarity is measured by scalar product and projection operators [55]. Density matrix representation can be used to many fields, such as document interaction [2], different modality correlations [56] and sentiment analysis [1,3,57]. The mathematical formalism of quantum theory could resist traditional model with significant effectiveness in cognitive phenomena [58]. A semiotic interpretation of the role played based on quantum entanglement was provided to find a finite number of the smallest semantic units to form every possible complex meaning [59].
3. Approaches
3.1. Read Text and Generate Syntax Tree
Each sentence is read, and the dependency tree and relation entity are generated. The word2vec embedding, PoS tagging and tree depth of each word in a sentence are stored, forming a quadruple . The array stores all of the words with the original sequences in the sentence.
where is the ith word in the sentence and n is the total number of the words.
The array stores the PoS of each word in sequence.
where is the PoS of the ith word .
The array denotes the tree depth of the ith word in the dependency tree.
where represents the tree depth of the ith word .
The array denotes the relation entity of the ith word in the dependency tree. We only consider whether an entity relationship exists between entangled words. If a relationship exists, the words, the associated vocabularies and the relationship between them are saved.
3.2. Entanglement between Words with Short-Range Modified Relationship
The model mainly describes the entanglement between two adjacent words. The attention mechanism is introduced to highlight word entanglement with a direct modified relationship while weakening the impact of the entanglement of indirect modified relationship on sentence semantics.
3.2.1. Normalize the Word Vector
Normalize the word2vec of an input word.
where is the d dimensional column vector of the ith word and is the module of . Therefore, is set as , with d dimensional column vector.
3.2.2. Embedding of Entangled Word
Two adjacent words are entangled together in order, forming the arrays
and
where is the combination of the adjoint words and , and is the PoS combination of . The representation of is defined by the tensor product between and .
For simplicity and clarity, is rewritten into a square matrix form.
Similarly, is obtained,
Obviously, the inequality is obtained, , which reflects the influence of the order of the entangled words.
3.2.3. Attention Mechanism
The attention mechanism consists of three components: the cosine similarity between the entangled words, the influence of PoS combination and the dependency tree depth difference of the two words.
The similarity between the adjacent words is defined as follows:
where
The weight of PoS combination of the entangled words can reflect some common modified relationships between words [5]. The different combinations of the two adjacent words are set to different values to express the different contributions for grammatical structures. We use to represent the influence of the PoS combination of the ith word and the th word, where , reflecting the global information of the corpus.
The last part is a parameter , which is determined by the dependent relationship in the syntax tree and the tree depth difference. The tree depth difference is the absolute value of the difference between the tree depth of the ith word and that of the th word.
The weight of is set as follows:
where , and satisfy the condition of , and the value of a can be altered.
Hence, the attention mechanism is described as follows:
3.2.4. Adjacent Words Entanglement-Based Sentence Representation
The adjacent words entanglement-based sentence representation is defined as follows.
where .
3.2.5. Sentence Similarity
Since both the representations of and are the second-order tensor with dimensions, the normalized dot product between the two sentence representations and is defined as the sentence similarity of the sentence pair,
where denotes the inner product of and , and are the norms of and , respectively, and is the conjugate transpose of .
3.3. Optimize the Sentence Embedding
The ultimate goal of text representation is to enable computers to understand human language. For the calculation of the text semantic similarity in this paper, the calculated value is infinitely close to the artificial score . Therefore, the Pearson correlation coefficient (Pcc) reaches the maximum value and the mean square error (MSE) reaches the minimum values. To maximize the Pcc and minimize the MSE, we optimize the sentence embedding using two approaches.
3.3.1. Entanglement between Words with Long-Range Modified Relationship
For long sentences or sentences with complex structures, two modified words are not necessarily adjacent. Aiming at the modified relationship of the long-distance association, a long-range dependent relationship is defined as the R array between words and .
where is a binary element, defined by whether there is a correlation entity between words and . If there is a relation entity between words and , ; if not, . The entanglement between and is
Equation (24) indicates that only the word pair with relation entity is considered to expand the sentence semantics.
Therefore, the sentence embedding based on relation entity is altered as follows.
where defines that all of the long-range dependencies in the sentence are taken into account, and .
3.3.2. Sentence Embedding Based on Constituency Parser and Relation Entity
The entanglement between the short-range modified words and the entanglement between the long-range modified relationship form a sentence representation. Hence, the optimized sentence representation is altered as
uses the entanglement coefficient to highlight the semantic contribution of adjacent words with modified relationships, and to weaken the semantic contribution of the adjacent words without modified relationship. only considers the semantic contribution of word pairs with a relation entity. Therefore, includes not only the modified relationship between adjacent words, but also the long-range modified relationship between related words. In addition, the entanglement coefficient analyzes the relevant degree between words from multiple perspectives by the relation entity of the text, combining the local information of the words in the same text with the global information in a dictionary.
3.3.3. Reduce Sentence Embedding Dimensions
The semantics of some phrases cannot be expressed by any of their constituent words alone, nor can the semantics of these two words be simply added together, such as . The semantics of is less than the semantics adding of and . To reduce the redundant information after word entanglement, we use the two methods of dimensionality reduction on the level of sentence embedding and of entangled word representation. For dimensionality reduction at the sentence level, we delete some smaller absolute values in the sentence embedding. At the entangled word level, we delete some smaller absolute values of the entangled word embedding to reduce the dimension of the sentence representation.
4. Experimental Settings
4.1. Parameters Definition
Some parameters and variables are defined in Table 1.

Table 1.
Definitions of the parameters and variables.
4.2. Datasets
Datasets include the SemEval Semantic Textual Similarity (STS) Tasks (years of 2012 (STS’12), 2014 (STS’14), 2015 (STS’15)) and STS-benchmark (STSb). E. Agirre et al. selected and piloted annotations of 4300 sentence pairs to compose the STS tasks in SemEval, including machine translation, surprise datasets and lexical resources [60]. E. Agirre et al. added new genres to the previous corpora, including 5 aspects in STS’14 [61]. In 2015, sentence pairs on answer pairs and belief annotations were added [62]. STS-benchmark and STS-companion include English text from image captions, news headlines and user forums [63]. In the study, the public lib of word2vec with 300 dimensions is assigned (http://code.google.com/archive/p/word2vec (accessed on 1 October 2020)). The input vectors of fasttext are 300 dimensions (http://fasttext.cc/docs/en/english-vectors.html (accessed on 1 October 2020)). The total number of sentence pairs for each corpus is summarized in Table 2 (http://groups.google.com/group/STS-semeval (accessed on 1 October 2020)). The corpora consist of English sentence pairs and the annotated similarities ranging from to (divided by 5). All the grammatical structures of sentences in the provided model are generated by Stanford Parser models package (https://nlp.stanford.edu/software/lex-parser.shtml (accessed on 1 October 2020)).
Table 2.
The number of sentence pairs in each corpus.
4.3. Experimental Settings
To make the calculated sentence similarity approximately equal to the annotated score , we perform a simple classification of the calculated results based on the relative error :
When , we introduce the optimized models to recompute the sentence similarities. This is performed in order to reduce the difference between the calculated value and the labeled value:
Then, we divide the calculated results into two parts. The first is computed by the short-range entanglement, and the other is modeled by the optimized models. When , the calculated result is considered feasible and is stored as . When , the calculated result is too large and must be optimized. To exploit the advantages of the two dimensionality reduction models, we divide the sentence pairs with into two parts according to the annotated scores . When , the sentence similarity is recomputed by the sentence-level dimensionality reduction model with the result of . When , we utilize the entangled-word-level dimensionality reduction model to recompute the sentence similarity, with the calculated result of . The algorithm is listed in Algorithm 1.
| Algorithm 1: Framework of sentence embedding based on constituency parser and relation entity for semantic similarity computation. |
 |
5. Experimental Results
5.1. Comparing with Some Unsupervised Methods
The Spearman’s rank correlation and Pearson correlation are used to compare the experimental results, as shown in Table 3 and Table 4. Table 3 shows that the Srcs of STS’14, STS’15 and STSb are significantly higher than the comparison models, but the average Src of our model is higher than all the comparison models. The results in Table 4 show that, except for 4 corpora, the Pcc of all corpora has increased. The average Pccs of STS’12, STS’14 and STS’15 have all been significantly improved, especially the maximum improvement rate of the provided model compared to ACVT on STS’12 has reached . The growth rates of the top three are , and for STS’12.MSRpar, STS’14.tweet-news and STS’12.SMTeuroparl, respectively. Moreover, STS’12.SMTeuroparl achieves a growth rate of . Comparing all the Pccs of the 16 corpora, The Pccs of 3 corpora are above , of 3 corpora are below , and only of 1 corpus is below . Though the Pcc of STS’14.deft-forum is less than , it is also increased slightly, with an increase of .
Table 3.
Comparison of the Spearman’s rank correlation (Src) in each dataset.
Table 4.
Comparison of the Pearson correlation coefficient (Pcc) in each dataset.
To compare the semantic influence of the input word embedding, the entanglement coefficients of word2vec and fasttext for each corpus in Table 5 are set to the same value, that is, the influence of the syntax tree is mainly considered. For easy comparison, the entanglement coefficients of ‘word2vec’ and ‘fasttext’ are set to the same values for each corpus in the table; namely, the influence of the long-range dependency relation is mainly considered. Comparison of the experimental results in Table 5 shows that all of the MSEs of ‘word2vec’ are smaller than those of ‘fasttext’. There are 5 datasets with a difference of less than and 5 corpora with an MSE with a multiplied value greater than 2. The main reason for this result is that all of the MSEs are adjusted under the parameters of ‘word2vec’, which are not the optimal parameters of ‘fasttext’. Additionally, the maximum value of ‘word2vec’ is less than , and that of ‘fasttext’ is less than .
Table 5.
The semantic influence of the input word embedding.
5.2. Influence of PoS Combination Weight
We mainly discuss the influence of notional words on sentence semantics including noun, verb, adjective and adverb. The four PoS types of notional words are combined in pairs to form 16 different PoS combinations. The weights of other PoS combinations are set to .
In Table 6, is set to different values to illustrate the influence of the parameters of the combination of PoS for different word entanglement. The word ‘first’ denotes the number combination of ‘, , , , , , , , , , , , , , , ’, for which the numbers are scattered around 0.5. The word ‘second’ denotes the number combination of ‘, , , , , , , , , , , , , , , ’, for which the numbers are concentrated around . means that all sixteen weights of the PoS combinations are set to . Comparing all of the Pccs, there are 10 out of 16 corpora achieving the maximum for , with the greatest improvement by from STS’15.headlines. Additionally, the top three advances are derived from , with an improvement of from STS’15.headlines, an increase of from STS’12.MSRpar and an increase of from STS’14.headlines. Comparing the three different MSEs of the same corpus in Table 6, the ratio of the minimums among the three PoS parameters combinations is 6:5:6, approximately evenly distributed. However, there are 8 out of 16 corpora reaching the maximum from , and the other corpora average from and . In brief, the Pcc and MSE are clearly affected by the distribution of the PoS combination weights. A more discrete parameter distribution corresponds to greater influence on the Pcc and MSE.
Table 6.
Influence of parameters on sentence semantics of different corpora. The figures in bold-type refer to the maximum Pearson correlation coefficient of each corpus. The figures in red-type refer to the minimum mean squared error of each corpus.
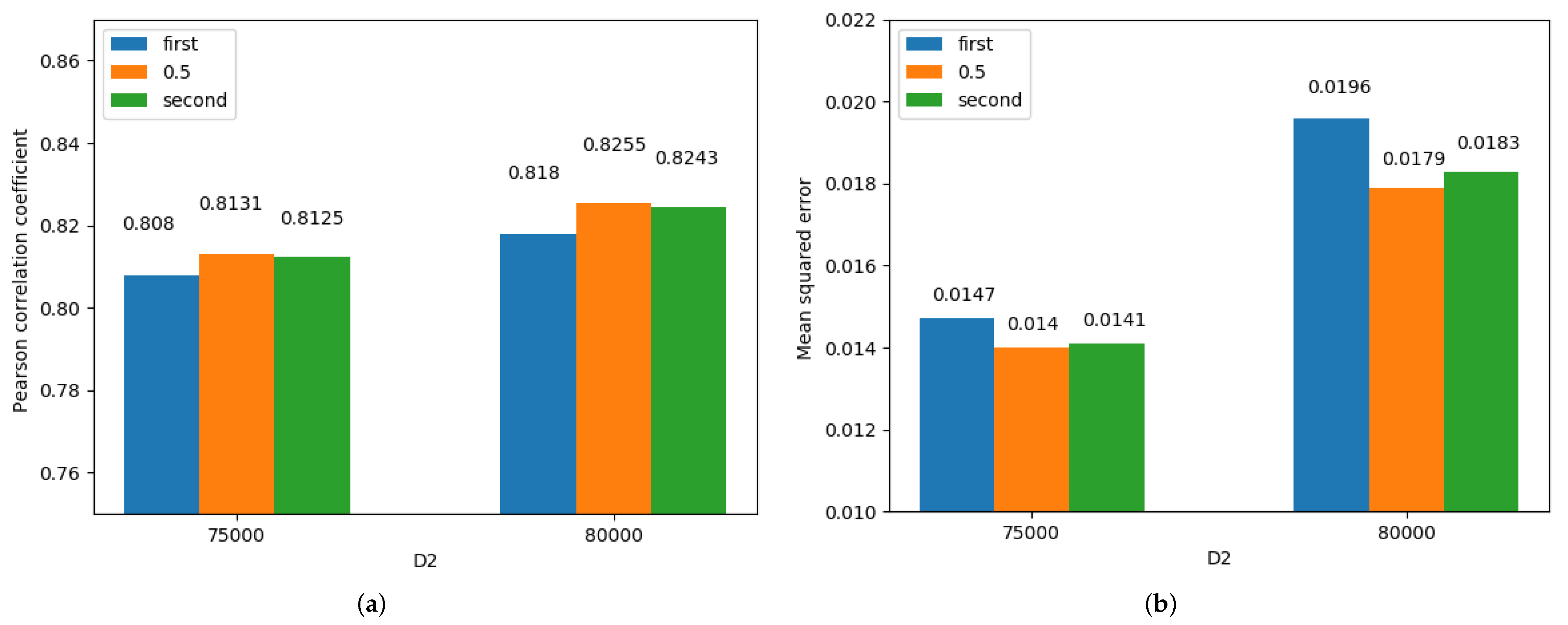
The detailed influence of on STS’12.OnWN is shown in Table 7. When changes, the trends of the Pcc and MSE with are still consistent. A higher concentration of corresponds to a larger Pcc and smaller MSE, as shown in Figure 3. Comparison of the Pccs in Figure 3a and the MSEs in Figure 3b shows that for , the Pcc reaches the maximum and the MSE reaches the minimum. This result can be explained based on the entanglement coefficient . When the entangled words and are determined, the cosine similarity of the two words is a fixed value. For the same input sentence, the dependency tree of the sentence is a certain structure; that is, the tree depth difference between the two words is a constant value so that the difference weight is a certain value. Hence, when the input sentence is known, is only changed by . The value of has a strong effect. For example, when the two weights are and , the weight of the PoS combination corresponding to is nine times that of the PoS combination corresponding to . To compare the influence of other parameters, is set to for the experiments discussed below.
Table 7.
Influence of parameters on sentence semantics of STS’12.surprise.OnWN.txt with the variables of , , and = 10,000.
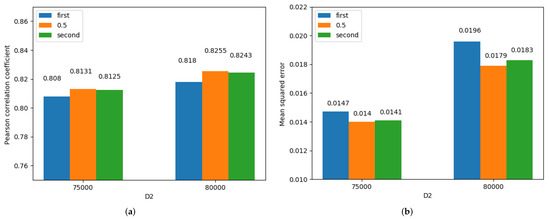
Figure 3.
Detailed influence of on STS’12.OnWN. (a) Pearson correlation coefficient, (b) Mean squred error.
5.3. Influence of the Tree Depth Difference
5.3.1. On STS-Benchmark
The influence of the tree depth difference on STS-benchmark is listed in Table 8. The list named ‘ changes’ represents the condition, and the list labeled ‘ stays the same’ describes the values under this condition. For example, the condition combination of ‘(1.5, 1.2, 0.8)’ and ‘(, , )’ denotes that when , ; when , ; and when , . The condition that denotes the tree depth difference between the two words is zero; that is, the two words have a direct modified relationship. When changes, the Pcc and MSE show very small changes. The main reason for this result is that the corpus consists mostly of short sentences, with sentence lengths of less than 10. A shorter sentence tends to have a simpler parser tree structure.
Table 8.
Influence of parameters and on sentence semantics of STS-benchmark with the variables of , , , = 10,000 and 75,000.
5.3.2. On STS’14.deft-News
The influences of the tree depth difference and the tree depth difference weight on STS’14.deft-news are illustrated in Table 9. In the STS’14.deft-news corpus, there are some long-sentences with more than 20 words. The complexity of the sentence structure tends to increase with the sentence length.
Table 9.
Influence of parameters and on sentence semantics of STS’14.deft-news.txt with the variables of , , , = 10,000 and 85,000.
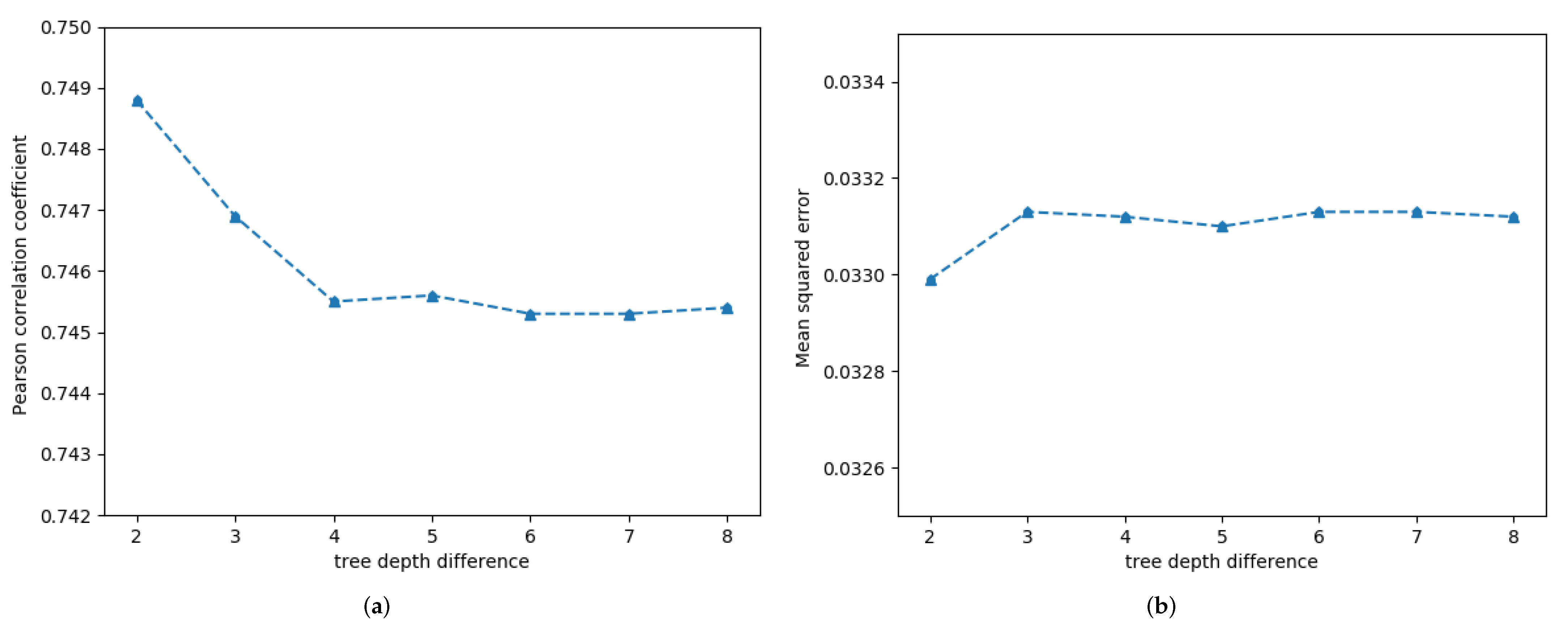
We use the variable-controlling approach to discuss the impact of and on semantics from two aspects, as shown in the upper and lower parts of Table 9. The upper half shows the semantic changes when changes. The detailed influence of the tree depth difference between the entangled words with indirect modified relationship on sentence semantics is illustrated in Figure 4. As shown in Figure 4a, when , the Pcc decreases markedly, whereas for , the change curve of the Pcc is almost horizontal. Examination of Figure 4b shows that the MSE changes only slightly. The lower part of Table 9 shows the influence of the weight of the direct modified relationship and that of the indirect modified relationship on sentence semantics. The values in blue are the values of the variable changes, and the values in red indicate the maximum Pcc and the minimum MSE. When the weight of direct modified relationship is altered, the Pcc and MSE remain unchanged. However, comparing the second group and the third group, it is found that when increases, the Pcc decreases and MSE increases, implying that entangled words modified indirectly will produce semantic errors. Additionally, when all three weights increase, the Pcc decreases and the MSE increases. Hence, when two adjacent words are entangled together by the tensor, if their modified relationship is indirect, semantic errors will be introduced.
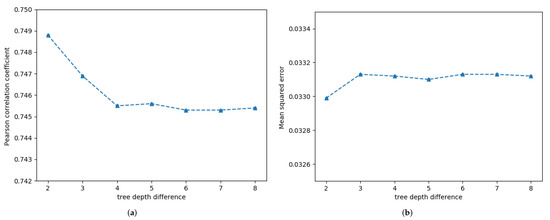
Figure 4.
Detailed influence of the distance between the entangled words with indirect modified relationship on sentence semantics in STS’14.deft-news. (a) Pearson correlation coefficient, (b) Mean squred error.
5.4. Influence of the Dimension Reduction
5.4.1. Influence on STS’15.Images
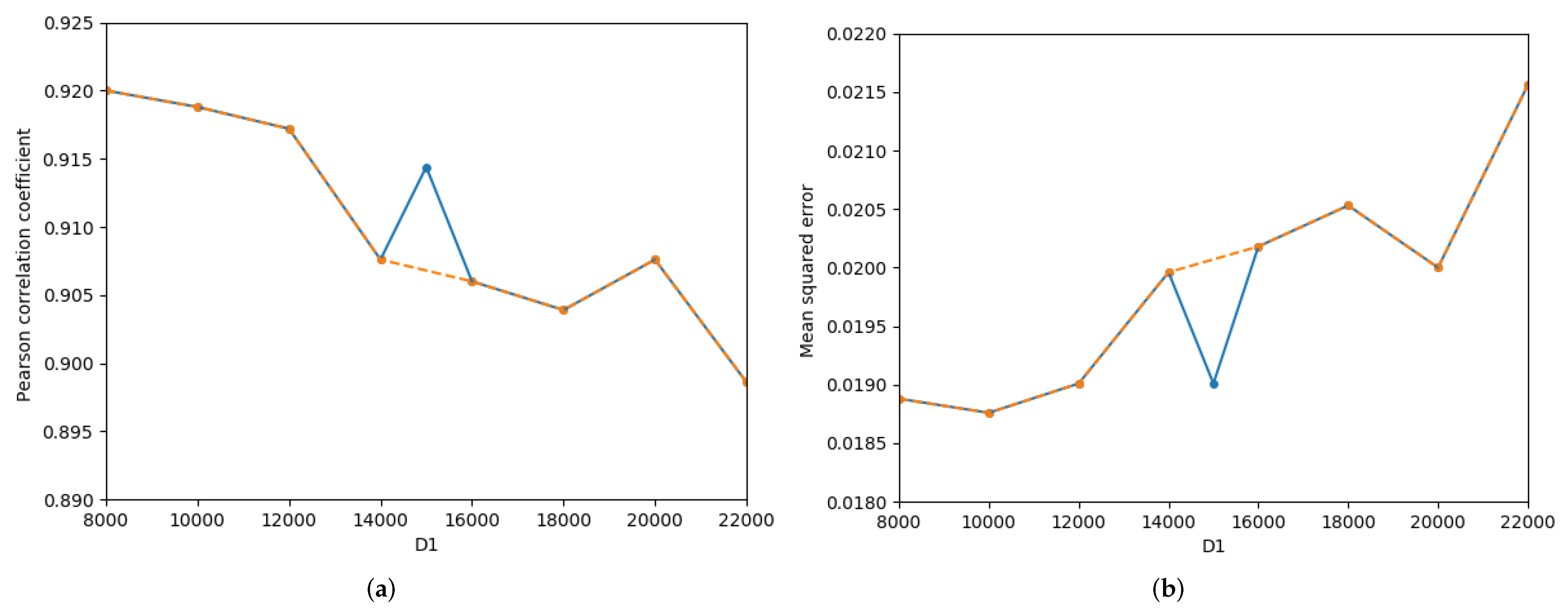
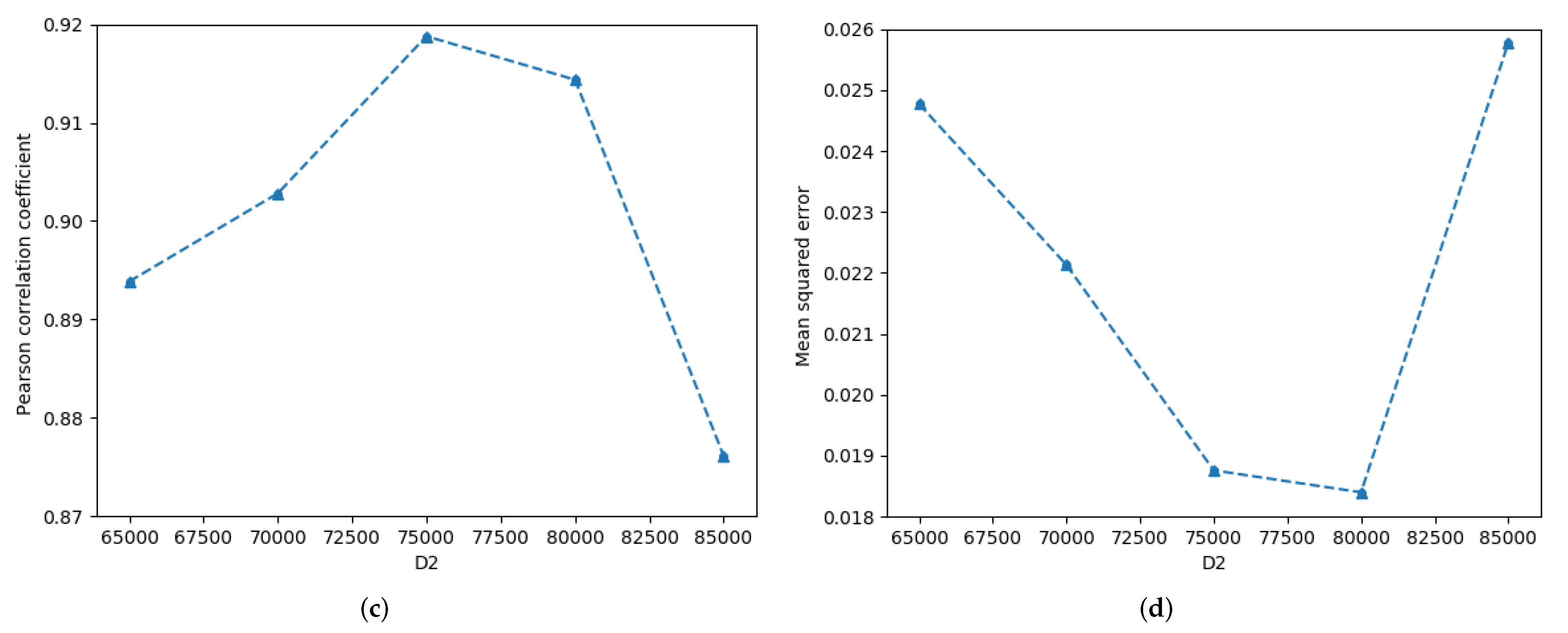
The influences of dimension of the sentence dimensionality reduction and dimension of the entangled word dimensionality reduction on STS’15.images are illustrated in Figure 5. As increases, the Pcc first decreases slowly and then fluctuates with smaller variables, as shown by the orange curve in Figure 5a. Excluding = 15,000, the overall change in the MSE is small; as increases, the MSE gradually increases, as explained by the orange curve in Figure 5b. As increases, the Pcc first increases and then decreases, and the MSE first decreases and then increases, as shown in Figure 5c and Figure 5d, respectively. When the Pcc reaches the maximum, the MSE is not the minimum, such that = 75,000. When = 80,000, the MSE reaches the minimum, but the Pcc is not at the maximum.
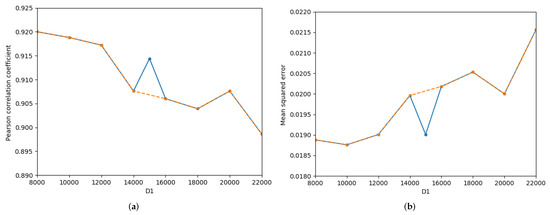
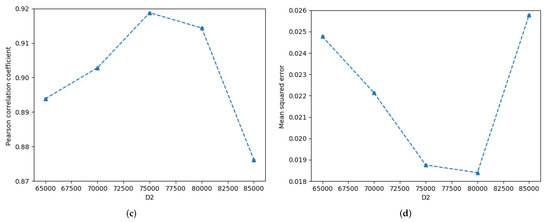
Figure 5.
Detailed influence of the and on semantics of STS’15.images.txt. (a) Pearson correlation coefficient-, (b) Mean squred error-, (c) Pearson correlation coefficient-, (d) Mean squred error-.
5.4.2. Influence on STS’15.Headlines
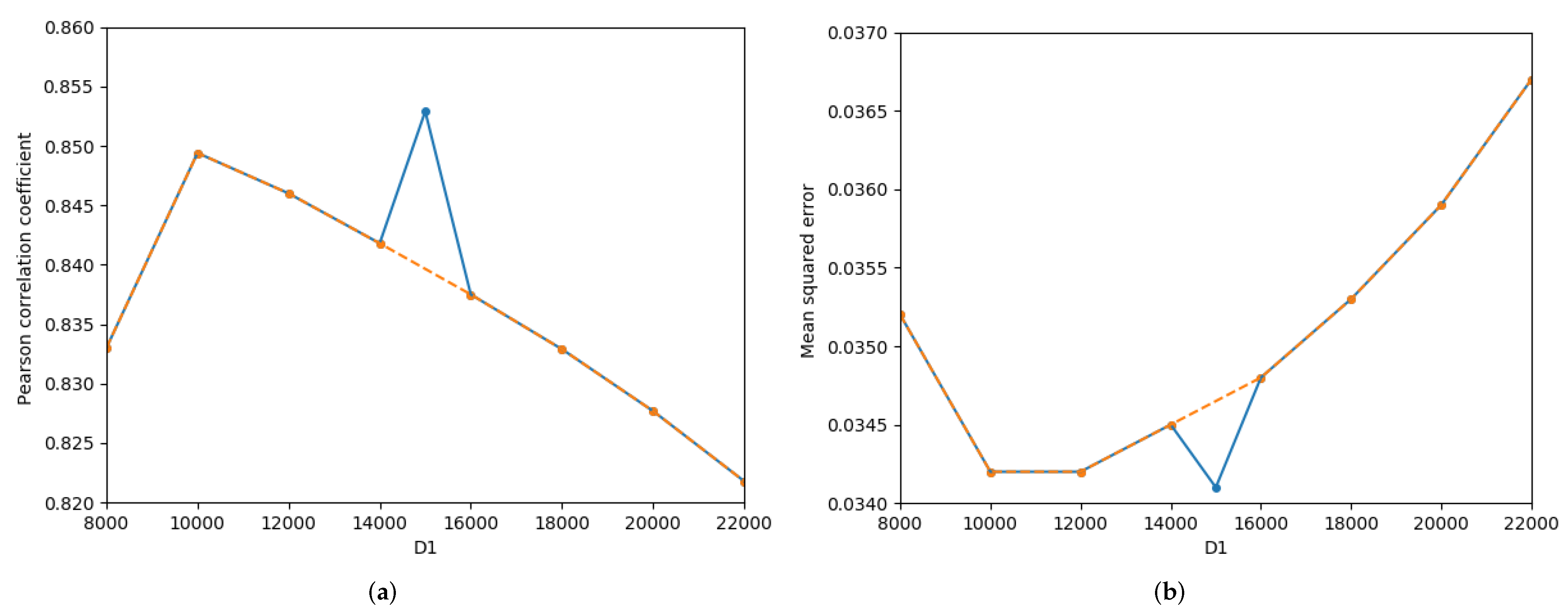
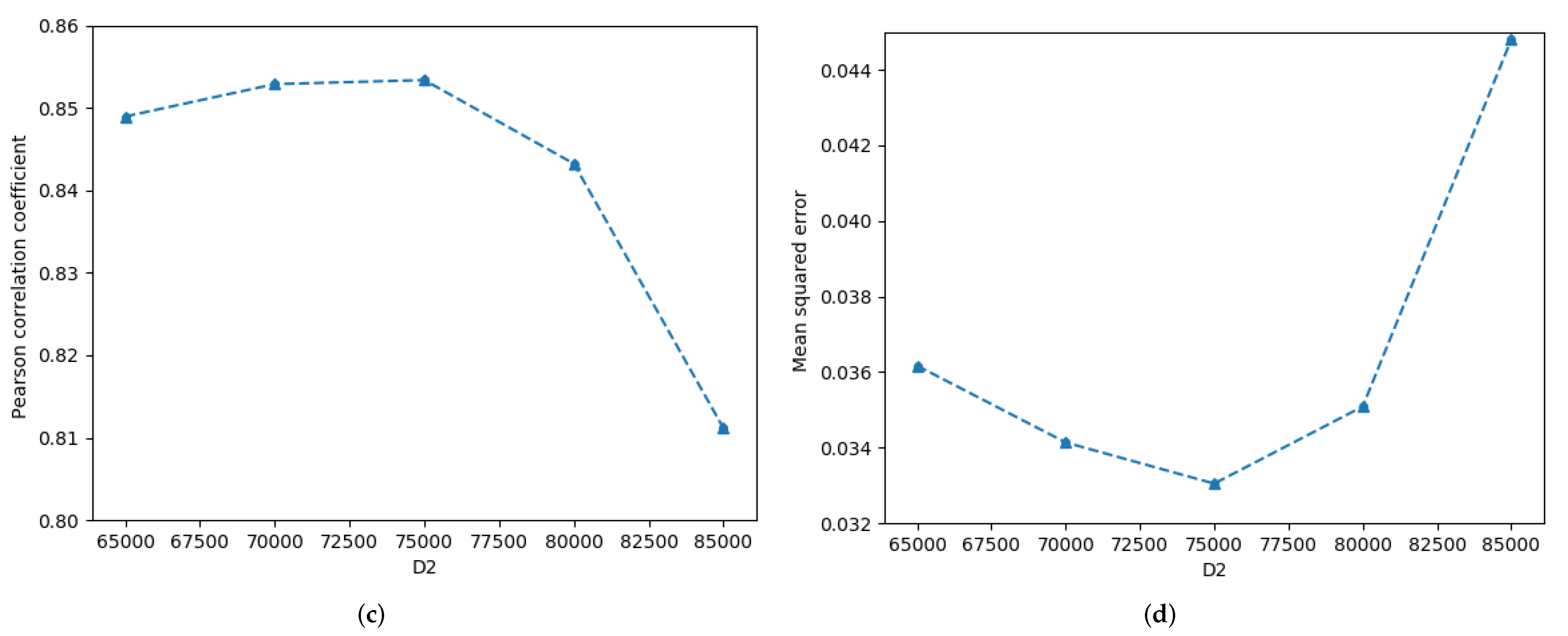
The effects of dimension of dimensionality reduction at the sentence level and dimension of the dimensionality reduction at the entangled word level on sentence semantics in STS’15.headlines are described in Figure 6. With the except of = 15,000, with increasing , the Pcc first increases and then linearly decreases, while the MSE first decreases and then gradually increases, as shown by the orange curves in Figure 6a,b. However, considering all of the experimental results including = 15,000, the change curves of the Pcc and MSE both show large fluctuations, as presented by the blue curves in Figure 6a,b. Moreover, the Pcc of = 15,000 is higher than all of the Pcc values, and the MSE of = 15,000 achieves the minimum value. Comparisons of Figure 6c,d show that with the increasing of , the Pcc first increases slowly and then decreases sharply, while the MSE decreases slightly and then increases rapidly.
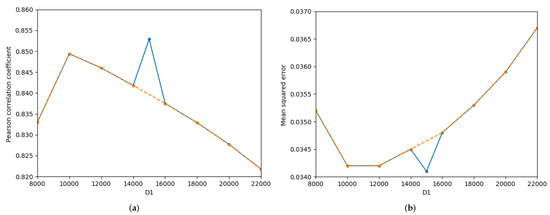
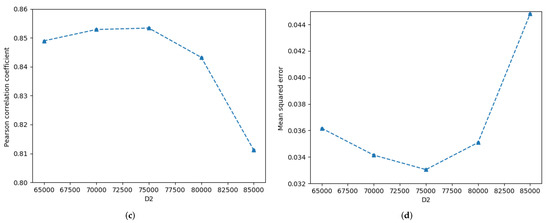
Figure 6.
Detailed influence of the and on semantics of STS’15.headlines.txt. (a) Pearson correlation coefficient-, (b) Mean squred error-, (c) Pearson correlation coefficient-, (d) Mean squred error-.
5.4.3. Summary
Comparisons of the orange curves to the blue curves in Figure 5a,b and Figure 6a,b show that the change trend of the orange curves is smoother than that of the blue curves. The blue curves only consider one more point = 15,000 than the orange curve. Hence, the optimum value is related to the interval variables. A larger interval variable corresponds to greater fluctuations of the the curve, as observed by the comparison of the orange curves and the blue curves of Figure 5a,b and Figure 6a,b. A smaller interval variable makes it more likely that the optimal value will be obtained. This result shows that the optimal solution obtained when the interval variable is large may not even be the local optimal value.
6. Conclusions and Future Works
This paper proposes a quantum entangled word representation based on syntax trees to represent sentences. When the sentence structure is complex, the two words that have a direct modified relationship are not necessarily in close proximity. Introducing quantum entanglement between words that have long-range dependencies enables remote words to also directly establish modified relationships. Combining the attention mechanism based on the dependency tree with the quantum entanglement coefficient, the entanglement coefficient between words is related not only to the PoS combination of the two words and the distribution of the two words in the dictionary but also to the modified relationship between the words. Utilizing the dependency trees of sentences to establish long-distance connections between words only considering the entangled words reduces semantic errors. Moreover, the use of the dependency tree-based attention weight can reduce the influence of adjacent entangled words without directly modifying the sentence semantics, thereby more accurately expressing the sentence semantics. We also discuss the impact of PoS combination, tree depth difference, and dimensionality reduction of entangled words on the sentence semantics. As the maximum of Pcc and the minimum value of MSE obtained here are not the optimal solutions, and may not even be the local optimal solutions, in future works, we mainly consider how to obtain the optimal value easily and effectively by introducing the theory of convex optimization to generalize this model. In this model, the semantic expansion of associated words is obtained by the tensor product of word vectors of the two related words, which is not applicable to the short sentences consisting of only one content word.
Author Contributions
Y.Y. conceptualization and project administration; D.Q., data curation and formal analysis; R.Y., software and validation. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (Grant no. 12171065 and 11671001) and the Doctor Training Program of Chongqing University of Posts and Telecommunications, China (Grant no. BYJS201915).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhang, Y.; Song, D.; Li, X.; Zhang, P.; Wang, P.; Rong, L.; Yu, G.; Wang, B. A quantum-like multimodal network framework for modeling interaction dynamics in multiparty conversational sentiment analysis. Inf. Fusion 2020, 62, 14–31. [Google Scholar] [CrossRef]
- Zhang, P.; Niu, J.; Su, Z.; Wang, B.; Ma, L.; Song, D. End-to-end quantum-like language models with application to question answering. In Proceedings of the 32nd Conference on Artificial Intelligence, and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence, Baltimore, MD, USA, 9–11 November 2018; pp. 5666–5673. [Google Scholar]
- Zhang, Y.; Song, D.; Zhang, P.; Li, X.; Wang, P. A quantum-inspired sentiment representation model for twitter sentiment analysis. Appl. Intell. 2018, 49, 3093–3108. [Google Scholar] [CrossRef]
- Yu, Y.; Qiu, D.; Yan, R. A quantum entanglement-based approach for computing sentence similarity. IEEE Access 2020, 8, 174265–174278. [Google Scholar] [CrossRef]
- Yu, Y.; Qiu, D.; Yan, R. Quantum entanglement based sentence similarity computation. In Proceedings of the 2020 IEEE International Conference on Progress in Informatics and Computing (PIC2020), Online, 18–20 December 2020; pp. 250–257. [Google Scholar]
- Zhang, Y.; Wang, Y.; Yang, J. Lattice LSTM for chinese sentence representation. IEEE ACM Trans. Audio Speech Lang. Process. 2020, 28, 1506–1519. [Google Scholar] [CrossRef]
- Liu, D.; Fu, J.; Qu, Q.; Lv, J. BFGAN: Backward and forward generative adversarial networks for lexically constrained sentence generation. IEEE ACM Trans. Audio Speech Lang. Process. 2019, 27, 2350–2361. [Google Scholar] [CrossRef]
- Wang, B.; Kuo, C. SBERT-WK: A sentence embedding method by dissecting bert-based word models. IEEE ACM Trans. Audio Speech Lang. Process. 2020, 28, 2146–2157. [Google Scholar] [CrossRef]
- Hosseinalipour, A.; Gharehchopogh, F.; Masdari, M.; Khademi, A. Toward text psychology analysis using social spider optimization algorithm. Concurr. Comp.-Pract. E 2021, 33, e6325. [Google Scholar] [CrossRef]
- Hosseinalipour, A.; Gharehchopogh, F.; Masdari, M.; Khademi, A. A novel binary farmland fertility algorithm for feature selection in analysis of the text psychology. Appl. Intell. 2021, 51, 4824–4859. [Google Scholar] [CrossRef]
- Osmani, A.; Mohasefi, J.; Gharehchopogh, F. Enriched latent Dirichlet allocation for sentiment analysis. Expert Syst. 2020, 37, e12527. [Google Scholar] [CrossRef]
- Huang, X.; Peng, Y.; Wen, Z. Visual-textual hybrid sequence matching for joint reasoning. IEEE Trans. Cybern. 2020, 51, 5692–5705. [Google Scholar] [CrossRef]
- Dai, D.; Tang, J.; Yu, Z.; Wong, H.; You, J.; Cao, W.; Hu, Y.; Chen, C. An inception convolutional autoencoder model for chinese healthcare question clustering. IEEE Trans. Cybern. 2021, 51, 2019–2031. [Google Scholar] [CrossRef] [PubMed]
- Yin, C.; Tang, J.; Xu, Z.; Wang, Y. Memory augmented deep recurrent neural network for video question answering. IEEE Trans. Neural Netw. Learn Syst. 2020, 31, 3159–3167. [Google Scholar] [CrossRef] [PubMed]
- Mohammadzadeh, H.; Gharehchopogh, F. A multi-agent system based for solving high-dimensional optimization problems: A case study on email spam detection. Int. J. Commun. Syst. 2021, 34, e4670. [Google Scholar] [CrossRef]
- Li, X.; Jiang, H.; Kamei, Y.; Chen, X. Bridging semantic gaps between natural languages and apis with word embedding. IEEE Trans. Softw. Eng. 2020, 46, 1081–1097. [Google Scholar] [CrossRef] [Green Version]
- Osmani, A.; Mohasefi, J.; Gharehchopogh, F. Sentiment classification using two effective optimization methods derived from the artificial bee colony optimization and imperialist competitive algorithm. Comput. J. 2022, 65, 18–66. [Google Scholar] [CrossRef]
- Li, L.; Jiang, Y. Integrating language model and reading control gate in BLSTM-CRF for biomedical named entity recognition. IEEE ACM Trans. Comput. Biol. Bioinform. 2020, 17, 841–846. [Google Scholar] [CrossRef] [PubMed]
- Maragheh, H.K.; Gharehchopogh, F.; Majidzadeh, K.; Sangar, A. A new hybrid based on long Short-term memory network with spotted Hyena optimization algorithm for multi-label text classification. Mathematics 2022, 10, 488. [Google Scholar] [CrossRef]
- Choi, H.; Lee, H. Multitask learning approach for understanding the relationship between two sentences. Inf. Sci. 2019, 485, 413–426. [Google Scholar] [CrossRef]
- Zhang, L.; Luo, M.; Liu, J.; Chang, X.; Yang, Y.; Hauptmann, A. Deep top-k ranking for image-sentence matching. IEEE Trans. Multimed. 2020, 22, 775–785. [Google Scholar] [CrossRef]
- Huang, F.; Zhang, X.; Zhao, Z.; Li, Z. Bidirectional spatial-semantic attention networks for image-text matching. IEEE Trans. Image Process. 2019, 28, 2008–2020. [Google Scholar] [CrossRef]
- Ma, Q.; Yu, L.; Tian, S.; Chen, E.; Ng, W. Global-local mutual attention model for text classification. IEEE ACM Trans. Audio Speech. Lang. Process. 2019, 27, 2127–2139. [Google Scholar] [CrossRef]
- Xu, X.; Wang, T.; Yang, Y.; Zuo, L.; Shen, F.; Shen, H. Cross-modal attention with semantic consistence for image-text matching. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5412–5425. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Guo, Q.; Qiu, X.; Xue, X.; Zhang, Z. Low-rank and locality constrained self-attention for sequence modeling. IEEE ACM Trans. Audio Speech Lang. Process. 2019, 27, 2213–2222. [Google Scholar] [CrossRef]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 5754–5764. [Google Scholar]
- Dong, L.; Yang, N.; Wang, W.; Wei, F.; Liu, X.; Wang, Y.; Gao, J.; Zhou, M.; Hon, H. Unified language model pre-training for natural language understanding and generation. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 13042–13054. [Google Scholar]
- Bao, H.; Dong, L.; Wei, F.; Wang, W.; Yang, N.; Liu, X.; Wang, Y.; Gao, J.; Piao, S.; Zhou, M.; et al. Unilmv2: Pseudo-masked language models for unified language model pre-training. In Proceedings of the 37th International Conference on Machine Learning, (ICML 2020), Online, 13–18 July 2020; pp. 642–652. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACLHLT 2019), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A lite BERT for selfsupervised learning of language representations. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–16. [Google Scholar]
- Conneau, A.; Lample, G. Cross-lingual language model pretraining. In Proceedings of the Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 7057–7067. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2018), New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Gharehchopogh, F. Advances in tree seed algorithm: A comprehensive survey. Arch. Comput. Methods Eng. 2022, 1–24. [Google Scholar] [CrossRef]
- Wang, J.; Yu, L.; Lai, K.; Zhang, X. Treestructured regional CNN-LSTM model for dimensional sentiment analysis. IEEE ACM Trans. Audio Speech Lang. Process. 2020, 28, 581–591. [Google Scholar] [CrossRef]
- Shen, M.; Kawahara, D.; Kurohashi, S. Dependency parser reranking with rich subtree features. IEEE ACM Trans. Audio Speech Lang. Process. 2014, 22, 1208–1218. [Google Scholar] [CrossRef]
- Luo, H.; Li, T.; Liu, B.; Wang, B.; Unger, H. Improving aspect term extraction with bidirectional dependency tree representation. IEEE ACM Trans. Audio Speech Lang. Process. 2019, 27, 1201–1212. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Zhai, F.; Zong, C. Syntax-based translation with bilingually lexicalized synchronous tree substitution grammars. IEEE Trans. Speech Audio Process. 2013, 21, 1586–1597. [Google Scholar] [CrossRef]
- Chen, W.; Zhang, M.; Zhang, Y. Distributed feature representations for dependency parsing. IEEE ACM Trans. Audio Speech Lang. Process. 2015, 23, 451–460. [Google Scholar] [CrossRef]
- Geng, Z.; Chen, G.; Han, Y.; Lu, G.; Li, F. Semantic relation extraction using sequential and treestructured LSTM with attention. Inf. Sci. 2020, 509, 183–192. [Google Scholar] [CrossRef]
- Fei, H.; Ren, Y.; Ji, D. A tree-based neural network model for biomedical event trigger detection. Inf. Sci. 2020, 512, 175–185. [Google Scholar] [CrossRef]
- Cao, Q.; Liang, X.; Li, B.; Lin, L. Interpretable visual question answering by reasoning on dependency trees. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 887–901. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, Y.; Zhao, S.; Li, W. Phrase2vec: Phrase embedding based on parsing. Inf. Sci. 2020, 517, 100–127. [Google Scholar] [CrossRef]
- Widdows, D.; Cohen, T. Graded semantic vectors: An approach to representing graded quantities in generalized quantum models. In Proceedings of the Quantum Interaction—9th International Conference (QI 2015), Filzbach, Switzerland, 15–17 July 2015; Volume 9535, pp. 231–244. [Google Scholar]
- Aerts, D.; Sozzo, S. Entanglement of conceptual entities in quantum model theory (qmod). In Proceedings of the Quantum Interaction—6th International Symposium (QI 2012), Paris, France, 27–29 June 2012; Volume 7620, pp. 114–125. [Google Scholar]
- Nguyen, N.; Behrman, E.; Moustafa, M.; Steck, J. Benchmarking neural networks for quantum computations. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2522–2531. [Google Scholar] [CrossRef] [Green Version]
- Sordoni, A.; Nie, J.; Bengio, Y. Modeling term dependencies with quantum language models for IR. In Proceeding of the 36th International ACM SIGIR conference on research and development in Information Retrieval (SIGIR’13), Dublin, Ireland, 28 July–1 August 2013; pp. 653–662. [Google Scholar]
- Cohen, T.; Widdows, D. Embedding probabilities in predication space with hermitian holographic reduced representations. In Proceedings of the Quantum Interaction—9th International Conference (QI 2015), Filzbach, Switzerland, 15–17 July 2015; Volume 9535, pp. 245–257. [Google Scholar]
- Yuan, K.; Xu, W.; Li, W.; Ding, W. An incremental learning mechanism for object classificationbased on progressive fuzzy three-way concept. Inf. Sci. 2022, 584, 127–147. [Google Scholar] [CrossRef]
- Xu, W.; Yuan, K.; Li, W. Dynamic updating approximations of local generalized multigranulation neighborhood rough set. Appl. Intell. 2022. [Google Scholar] [CrossRef]
- Xu, W.; Yu, J. A novel approach to information fusion in multi-source datasets: A granular computing viewpoint. Inf. Sci. 2017, 378, 410–423. [Google Scholar] [CrossRef]
- Xu, W.; Li, W. Granular computing approach to two-way learning based on formal concept analysis in fuzzy datasets. IEEE Trans. Cybern. 2016, 46, 366–379. [Google Scholar] [CrossRef]
- Hou, Y.; Zhao, X.; Song, D.; Li, W. Mining pure high-order word associations via information geometry for information retrieval. ACM Trans. Inf. Syst. 2013, 31, 1–12. [Google Scholar] [CrossRef]
- Xie, M.; Hou, Y.; Zhang, P.; Li, J.; Li, W.; Song, D. Modeling quantum entanglements in quantum language models. In Proceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, 25–31 July 2015; pp. 1362–1368. [Google Scholar]
- Aerts, D.; Beltran, L.; Bianchi, M.; Sozzo, S.; Veloz, T. Quantum cognition beyond hilbert space: Fundamentals and applications. In Proceedings of the Quantum Interaction—10th International Conference (QI 2016), San Francisco, CA, USA, 20–22 July 2016; Volume 10106, pp. 81–98. [Google Scholar]
- Zhang, Y.; Song, D.; Zhang, P.; Wang, P.; Li, J.; Li, X.; Wang, B. A quantum-inspired multimodal sentiment analysis framework. Theor. Comput. Sci. 2018, 752, 21–40. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Li, Q.; Song, D.; Zhang, P.; Wang, P. Quantum-inspired interactive networks for conversational sentiment analysis. In Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI 2019), Macao, China, 10–16 August 2019; pp. 5436–5442. [Google Scholar]
- Aerts, D.; Arguelles, J.; Beltran, L.; Distrito, I.; Bianchi, M.; Sozzo, S.; Veloz, T. Context and interference effects in the combinations of natural concepts. In Proceedings of the Modeling and Using Context—10th International and Interdisciplinary Conference (CONTEXT 2017), Paris, France, 20–23 July 2017; Volume 10257, pp. 677–690. [Google Scholar]
- Galofaro, F.; Toffano, Z.; Doan, B. A quantumbased semiotic model for textual semantics. Kybernetes 2018, 47, 307–320. [Google Scholar] [CrossRef]
- Agirre, E.; Cer, D.; Diab, M.; Gonzalez-Agirre, A. Semeval-2012 task 6: A pilot on semantic textual similarity. In Proceedings of the 6th International Workshop on Semantic Evaluation, Montreal, QC, Canada, 7–8 June 2012; pp. 385–393. [Google Scholar]
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.; Diab, M.T.; Gonzalez-Agirre, A.; Guo, W.; Mihalcea, R.; Rigau, G.; Wiebe, J. Semeval-2014 task 10: Multilingual semantic textual similarity. In Proceedings of the 8th International Workshop on Semantic Evaluation, Dublin, Ireland, 23–24 August 2014; pp. 81–91. [Google Scholar]
- Agirre, E.; Banea, C.; Cardie, C.; Cer, D.; Diab, M.; Gonzalez-Agirre, A.; Guo, W.; Lopez-Gazpio, I.; Maritxalar, M.; Mihalcea, R.; et al. Semeval-2015 task 2: Semantic textual similarity, english, spanish and pilot on interpretability. In Proceedings of the 9th International Workshop on Semantic Evaluation, Denver, CO, USA, 4–5 June 2015; pp. 252–263. [Google Scholar]
- Cer, D.; Diab, M.; Agirre, E.; Lopez-Gazpio, I.; Specia, L. Semeval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In Proceedings of the 11th International Workshop on Semantic Evaluation, Vancouver, BC, Canada, 3–4 August 2017; pp. 1–14. [Google Scholar]
- Gao, T.; Yao, X.; Chen, D. SimCSE: Simple contrastive learning of sentence embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP 2021), Online, 10–11 November 2021; pp. 6894–6910. [Google Scholar]
- Zhang, Y.; He, R.; Liu, Z.; Lim, K.; Bing, L. An unsupervised sentence embedding method by mutual information maximization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), Online, 16–20 November 2020; pp. 1601–1610. [Google Scholar]
- Li, B.; Zhou, H.; He, J.; Wang, M.; Yang, Y.; Li, L. On the sentence embeddings from pre-trained language models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020), Online, 16–20 November 2020; pp. 9119–9130. [Google Scholar]
- Schick, T.; Schütze, H. Generating datasets with pretrained language models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP 2021), Online, 10–11 November 2021; pp. 6943–6951. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence embeddings using siamese BERT-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP 2019), Hong Kong, China, 2–7 November 2019; pp. 3982–3992. [Google Scholar]
- Quan, Z.; Wang, Z.; Le, Y. An efficient framework for sentence similarity modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 853–865. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, J.; Zong, C. Learning sentence representation with guidance of human attention. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI2017), Melbourne, Australia, 19–25 August 2017; pp. 4137–4143. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).