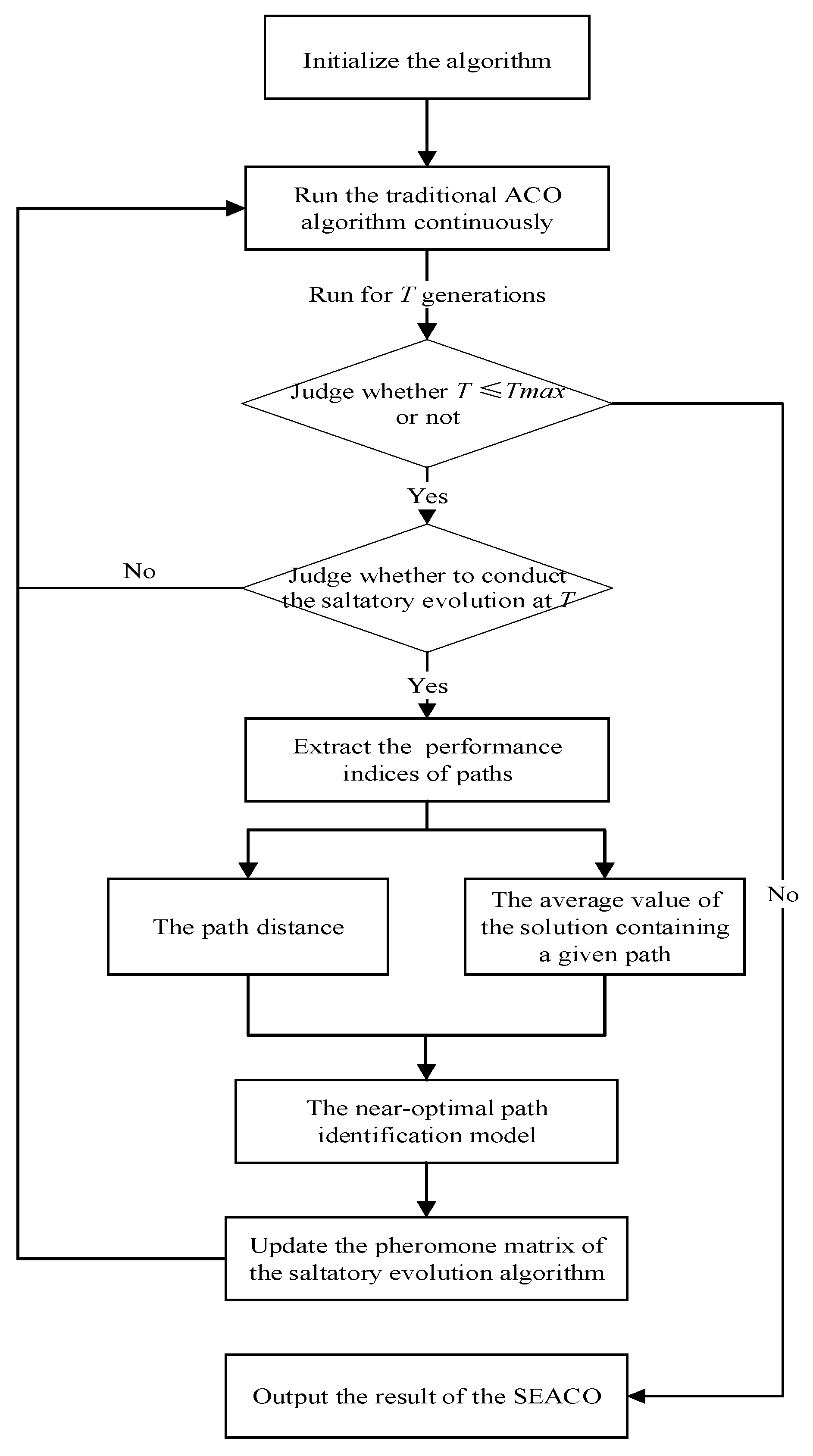
5.1.1. The Path Performance Evaluation
The near-optimal paths in TSP refer to those paths that appear in the near-optimal solution. The continuous iterative optimization process of the ACO algorithm can be regarded as a process in which many ants constantly evaluate and adjust the path performance based on the past search experience to find the near-optimal paths. In this process, the path pheromone acts as a communication medium among ants, carrying and disseminating the path performance information shown in the past. Therefore, the cumulative pheromone of the path when the overall-optimal or near-optimal solution is found, is used to represent the path performance in this study.
Next, based on the traditional ACO algorithm mechanism, an index system for evaluating the path performance is proposed. As shown in
Figure 2, the index system includes three aspects: (1)
, the distance of the path (
i,
j). It represents the cost could be paid when ants moving through the given path, which is generally determined by the specific problem. (2)
, the selected frequency of path (
i,
j) in the first
T generations. It is the frequency with which the given path is selected into the solution during the algorithm running process. (3)
, the average value of solution containing the path (
i,
j) in the first
T generations. It describes the capability of the given path to be compatible with other paths to form a near-optimal solution. The specific calculation methods of index (2) and (3) are respectively shown in Formulas (5) and (6).
where
denotes the selected number of the path (
i,
j) during the first
T iterations, and
refers to the solution value containing the path (
i,
j) of ant
k at the
t iteration. The larger the value of
, the weaker the capability of path (
i,
j) to be compatible with other paths to form a near-optimal solution, as the objective function of the TSP is to find the minimum value.
5.1.2. The Generation of the Near-Optimal Path Identification Rules
In this section, based on the path performance evaluation indicators proposed in
Section 5.1.1, the quantitative analysis model is used to refine the TSP near-optimal path identification rule working as the domain knowledge to support the construction of the SEACO algorithm from the pheromone matrix evolution data of the traditional ACO algorithm.
At the initial moment of ACO, the pheromone of each path is the same, and the pheromone matrix is uniformly distributed. With the continuous iteration of the algorithm, the distribution of the pheromone matrix changes based on the search results and only one path is selected in each row of the pheromone matrix during each iteration of the TSP. In order to reflect the evolutionary trend of the pheromone matrix more clearly, the path pheromone is normalized in each row after each iteration. It is obvious that the total amount of path pheromones in each row of the pheromone matrix will converge to the near-optimal path when the algorithm achieves the global optimal solution. This matrix is defined as the near-optimal pheromone matrix in this study. In conclusion, the evolutionary process of the pheromone matrix is a process in which the path pheromone continuously converges from a uniform distribution to the near-optimal path. If the near-optimal path prediction rules can be found based on historical iterative data and be used to predict the future evolutionary trend of the pheromone matrix reasonably, it will greatly save the search time of the ACO algorithm and increase the convergence speed in this process.
Next, the quantitative analysis model will be used to test hypotheses, which is to mine the near-optimal path prediction rules from the pheromone matrix evolution data of the traditional ACO algorithm. First of all, each path pheromone in the near-optimal pheromone matrix is set as an explanatory variable Y, which describes the path performance, and then, three key assumptions that could affect the path pheromone in the near-optimal pheromone matrix are proposed based on the path performance evaluation indexes.
Hypothesis 0 (H0). The larger the path distance, the smaller the path pheromone in the near-optimal pheromone matrix.
Hypothesis 1 (H1). The larger the average value of the solution containing a given path, the smaller the path pheromone in the near-optimal pheromone matrix.
Hypothesis 2 (H2). The higher the selected frequency of a given path, the larger the path pheromone in the near-optimal pheromone matrix.
It can be seen from Formula (2) that the pheromone importance factor α and the important factor of heuristic function β in the ACO algorithm affect the value of the path selection probability. Therefore, in the hypothesis test model, α and β are defined as the adjustment variables for the average value of the path solution and the frequency of path selection. The following four hypotheses are proposed based on the above algorithm mechanism:
Hypothesis 3 (H3). The pheromone importance factor α can enhance the negative influence of the average value of the solution containing a given path on the path pheromone value in the near-optimal pheromone matrix.
Hypothesis 4 (H4). The heuristic function degree factor β can weaken the negative influence of the average value of the solution containing a given path on the path pheromone value in the near-optimal pheromone matrix.
Hypothesis 5 (H5). The pheromone importance factor α can enhance the positive influence of the selected frequency of a given path on the path pheromone value in the near-optimal pheromone matrix.
Hypothesis 6 (H6). The heuristic function degree factor β can weaken the positive influence of the selected frequency of a given path on the path pheromone value in the near-optimal pheromone matrix.
Finally, the variance
reflecting the dispersion degree of the paths distance in the TSP data sets and the index ΔE reflecting the influence of the extreme value of the path distance on the average value are added as control variables in the hypothesis test model as shown in
Figure 2. The control variable ΔE is calculated with Formula (7), where
refers to the vertex set of the graph
G when removed top 10 edges with minimum distance, and
denotes the vertex set of the graph
G when removed top 10 edges with maximum distance.
In order to verify the above hypotheses, 60% of the 79 data sets in international traveling salesman problem library (TSPLIB) database [
20] were randomly selected as the training data sets, and the traditional ACO algorithm pheromone matrix evolution data in 200 generations were used to test the quantitative analysis model. The parameters of the traditional ACO algorithm according to previous research [
21,
22,
23] were set as follows: the number of ants
m was 50, the pheromone volatilization factor
ρ was 0.1, the constant coefficient
Q was 1, the maximum number of iterations was 200, and the running node
T was 20. In addition, the pheromone value of the path (
i,
j) at the 200th generation was regarded as the estimated value of the path pheromone amount in the near-optimal pheromone matrix, so the regression equation is constructed as Formula (8).
where
represents
stands for
denotes
is
α (the value is 1 or 5),
refers to
β (the value is 2 or 5),
is defined as
stands for ΔE.
The results of quantitative analysis model test are shown in
Table 1. The
p-value of the regression equation is 0, which passes the significance test. The variance inflation factor (VIF) value of the regression equation without cross terms is equal to 6.3, indicating that there is no serious multicollinearity between variables. The regression coefficient of
is negative, and the
p-value is 0, indicating that the larger the path distance, the smaller the pheromone value of the path (
i,
j) in the near-optimal pheromone matrix. Therefore, the hypothesis H0 is supported. The regression coefficient of
is positive indicating that the larger the average value of the solutions containing the path (
i,
j), the larger the pheromone value of path (
i,
j) in the near-optimal pheromone matrix, which is contrary to the original hypothesis H1. The evolutionary strategies in ACO algorithm to avoid the prematurity of pheromone matrix may be the reason, such as pheromone volatilization mechanism and roulette random selection strategy. The regression coefficient of
is 0, indicating that the selected frequency of path (
i,
j) in the first
T generations has no correlation with the pheromone value of path (
i,
j) in the near-optimal pheromone matrix. The hypothesis H2 is not supported, and thus, the hypothesis H5 and H6 about the adjustment variables are also not supported. What is more, the regression coefficient of the adjustment variable
α is negative, and the regression coefficient of the cross term of
α is also negative, indicating that
α can weaken the positive effect of the average value of the solutions containing path (
i,
j) on the path pheromone value in the near-optimal pheromone matrix. Therefore, H3 is supported. The regression coefficient of the adjustment variable
β is positive, but the regression coefficient of the cross term of
β is negative, indicating that
β can weaken the positive effect of the average value of the solutions containing path (
i,
j) on the path pheromone value in the near-optimal pheromone matrix, so H4 is supported. Finally, four near-optimal path identification rules are obtained, and the hypothesis test results are shown in
Figure 3.
5.1.3. The Near-Optimal Path Identification
In this section, the adjustment variables α and β are fixed. The supported H0 and H2 are used to make a qualitative identification of the near-optimal path firstly, and then a model for predicting the near-optimal path is constructed to realize the saltatory evolution of the pheromone matrix of the traditional ACO algorithm and speed up the process of optimizing.
The qualitative identification process of the near-optimal path is as follows:
- (a)
Discretizing variables.
All possible paths starting from i are considered as an analysis unit. Then variable and variable are mapped to one of the low value interval , the median interval , and the high value interval and are converted to the low, medium, and high value accordingly to be the discrete variables, where is the minimum variable value of all N possible paths starting from node i, and is the maximum variable value of all N possible paths starting from node i. It should be emphasized that the discretization will not be needed if is null.
- (b)
Incorporating the identification rules and predicting the near-optimal path in different scenarios.
After the variables’ discretization, there would be 12 scenarios that are composed of different
and
, as shown in
Table 2. It is assumed that the effect of one main variable will not completely offset the effect of another main variable, and the identification results are denoted by three grade variables, which are high, middle, and low value. When
belongs to a high level and
belongs to a low level, the final judgment result is a low level because both main variables predict that the pheromone value of the path (
i,
j) in the near-optimal pheromone matrix will be a low level. In the same way, when
and
are both at the middle level, the path (
i,
j) pheromone value in the near-optimal pheromone matrix is predicted to be at the middle level. When
is a low level and
is a high level, the value of the path pheromone in the near-optimal pheromone matrix is predicted to be a high level. When
is null, H2 will be invalid and the pheromone value of the path (
i,
j) in the near-optimal pheromone matrix is only judged according to
based on H0.
- (c)
Updating the pheromone matrix.
The high, low, and medium values of the qualitative identification results of the path pheromone respectively represent the increased, decreased, or unchanged evolutionary trend that the pheromone value of the path (
i, j), namely,
, would show during the evolution of the pheromone matrix, and it is assumed that the change value of each path pheromone
Q1 is fixed. According to
Table 2, the qualitative pheromone matrix updating formula is obtained, as shown in Formula (9), where
is the prediction value of the path pheromone of (
i,
j).
- (d)
The test of the qualitative identification rules.
In order to preliminarily verify the validity and applicability of the near-optimal path qualitative identification rules, 24 test data sets were used, and the experimental results were compared with the traditional ACO algorithm. First of all, in order to reasonably distinguish the different path performance from the pheromone value level,
Q1 was selected as three values which are 0.1, 0.5, and 1 by observing the path pheromone value before updating. These three values could cover the change range of path pheromone and good simulation results would be relatively obtained through such parameter setting. Then, when the traditional ACO algorithm ran to the 20th generation, the pheromone matrix was updated with Formula (8). After updating, the ACO algorithm continued to run for one generation to output the optimized results. The average optimization result
. of the 24 data sets after the pheromone updating was compared with the average optimization result
of the traditional ACO algorithm on the same data sets at the 20th generation so as to evaluate the effectiveness of the near-optimal path qualitative identification rules. Meanwhile, the optimization rate, that is, the proportion of the data sets with reduced running time after the application of the prediction rules in all experimental data sets, is used to evaluate the applicability of the near-optimal path qualitative identification rules. The experimental results are shown in
Table 3. When
Q1 is equal to 0.1,
of 24 data sets is better than
, and the overall optimization rate reaches 41.67%. When Q1 is equal to 1, although
of 24 data sets is not better than
, the overall optimization rate reaches 50%.
The experiment preliminarily confirms that the domain knowledge extracted in this study can effectively predict the evolutionary trend of the pheromone matrix. However, this experiment only used a qualitative method to make a rough discrete prediction of the near-optimal path. However, when the value of Q1 is 0.1, the average optimization results improved. While the optimization degree and optimization rate are not particularly prominent, this study further constructs a model for predicting the near-optimal path from a quantitative perspective to predict the near-optimal pheromone matrix continuously and improve performance of the SEACO algorithm.
The model of near-optimal path prediction is as follows:
- (1)
Null variable treatment. When the is null, will be equal to , so it is transformed into a continuous variable.
- (2)
Construct the model for predicting the near-optimal path. Based on the verified Formula (9), the following model for predicting the near-optimal path is shown in Formula (10).
where
denotes the pheromone value of the path (
i,
j) at the Tth generation.
refers to pheromone prediction value of the path (
i,
j) in the near-optimal pheromone matrix.
describes the average value of the solutions containing paths (
i,
j) before
T generations.
is a vector representing average values of the solutions, and each solution contains one path starting from
i.
is defined as the distance of path (
i,
j) and
symbolizes a vector which contains all the paths distance starting from
i.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}