1. Introduction
In machine learning and other relevant fields, kernel [
1,
2] is defined as a special function to characterize the similarity (or distance) between any two samples after mapping them to a high-dimensional space. For the quantum and quantum-inspired machine learning (QML), an essential step to process classical data is to embed the data (e.g., images, texts, etc.) to the quantum space known as Hilbert space [
3,
4,
5,
6,
7]. The quantum kernel function (QKF) that characterizes the distributions in the Hilbert space [
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18] is usually a critical factor for the performance of a QML scheme.
Among the existing mappings from data to the quantum state representations, a widely recognized example is known as the quantum feature map (see, e.g., [
10,
19,
20,
21]). It maps each feature to the state of one qubit, and each sample to an
M-qubit product state (with
M the number of features). Such a quantum feature map brings interpretability from the perspective of quantum probabilities, and have succeeded in the supervised [
10,
20,
21] and unsupervised learning [
19,
22] algorithms as well as in the QML experiments [
23]. It is unexplored to use such a quantum feature map for semi-supervised learning.
In quantum information and computation [
24], fidelity serves as a fundamental quantity to characterize the similarity of two quantum states, and has been applied in tomography [
25], verification [
26], and detection of quantum phase transitions [
27,
28,
29,
30,
31,
32]. One drawback of fidelity for the many-qubit states is that it usually decreases exponentially with the number of qubits
M, which is known as the “orthogonal catastrophe”. Instability or overflow of the precisions may occur for large
M. One way to avoid the “orthogonal catastrophe” is to use the logarithmic fidelity as the QKF (for instance [
27,
33,
34]). However, it is unclear for machine learning how the mutual distances of the samples or the data structure will be altered by taking logarithm on the fidelity.
Motivated by the growing needs on investigating QKFs for particularly machine learning, we here propose the rescaled logarithmic fidelity (RLF) as a tunable quantum-inspired kernel function (QIKF). To show its validity, we implement non-parametric semi-supervised learning in the Hilbert space based on RLF, which we name as RLF-NSSL. Being non-parametric, we can exclude the possible effects from the variational parameters and focus on the space and kernel. Note for the parametrized models, say neural networks, the performances are mainly determined by their architecture and parameter complexities, such as the arrangements of different types of layers and the numbers of variational parameters therein. In the RLF-NSSL, a given sample is classified by comparing the RLF’s between this sample and the clusters that are formed by labeled and pseudo-labeled samples. A strategy for pseudo-labeling is proposed. RLF-NSSL achieves better accuracy comparing with several established non-parametric methods such as naive Bayes classifiers, k-nearest neighbors, and spectral clustering. Particularly for the unsupervised or few-shot cases where the choice of kernel is crucial, the high performance of our method indicates the validity of RLF for QML.
The clusters formed by the samples with labels and pseudo-labels also define a mapping from the original space to a low-dimensional effective space. With the visualization by t-SNE [
35], we show that the low-dimensional data exhibit within-class compressibility, between-class discrimination, and overall diversity. It implies that the machine learning in the Hilbert space also complies with the principles of maximal coding rate reduction (MCR
) [
36,
37]. We expect that these findings, including the RLF and the pseudo-labeling strategy, would generally benefit the QML using the parametric models, such as tensor networks [
10,
19,
20,
21,
22,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48], parametric quantum circuits [
49,
50,
51,
52,
53,
54,
55,
56,
56], and quantum neural networks [
57,
58,
59,
60,
61,
62,
63]. The connections to the maximal coding rate reduction shows the possibility of understanding and evaluating the QML methods from the perspective of coding rate. Our code can be publicly found on Github [
64].
2. Hilbert Space and Rescaled Logarithmic Fidelity
Given a sample that we assume to be a
M-component vector
with
, the feature map (see, e.g., [
10,
19,
20,
21]) to encode it to a
M-qubit product states is written as
Here, and form a set of orthonormal basis for the m-th qubit, which satisfy .
In quantum information, the quantity to characterize the similarity between two states and is the fidelity f defined as the absolute value of their inner product . As each state is normalized, we have . With , the two states are orthogonal to each other and have the smallest similarity. With , the states satisfy with a universal phase factor. In this case, and can be deemed as a same state (meaning zero distance).
The fidelity with the feature map in Equation (
1) results in a QKF to characterize the similarity between two samples
and
, which reads
In other words, the similarity between and is characterized by the fidelity f between the two product states obtained by implementing the feature map on these two samples.
Equation (
2) shows that the fidelity is the product of
M non-negative numbers
(the equality holds when the corresponding feature takes the same value in the two samples, i.e.,
). Consequently,
decreases exponentially with the number of pixels that take different values in
and
. Taking MNIST dataset as an example, there are usually
such pixels. Then,
f will be extremely small, meaning that the states from any two of the samples are almost orthogonal to each other. This is known as the “orthogonal catastrophe”, where instability or precision overflow may occur.
One way to resolve this problem is to use the logarithmic fidelity (for instance [
27,
33,
34]).
with
a small positive constant to avoid
.
F is a non-positive scalar that also characterizes the similarity between the given states. Though
F changes monotonously with
f, the mutual distances among the samples obtained by these two kernels are definitely different. For instance, we might have
while
, due to the nonlinearity of the logarithmic function.
3. Rescaled Logarithmic Fidelity and Classification Scheme
In this work, we take advantage of the nonlinearity and define the rescaled logarithmic fidelity (RLF) as
with
a tunable parameter that we dub as the rescaling factor. In particular, for
, the RLF becomes the fidelity, i.e.,
.
With certain labeled training samples
from
P classes, an unlabeled sample
can be classified in a supervised learning process. First, we transform
to a
P-dimensional effective vector
, where its
p-th element is the average RLF with the training samples from the
p-th class
with
the number of the labeled samples that belong to the
p-th class. We call the labeled samples in a same class as a cluster. The clusters define a dimensionality reduction map given by Equation (
5) from the original feature space to a
P-dimensional space. In practice, we take
as a same number for all
p. The classification of
is then indicated by the largest element of
as
One can see that except certain hyper-parameters such as the rescaling factor and the number of labeled samples, the above method contains no variational parameters, thus is dubbed as non-parametric supervised learning with RLF (RLF-NSL).
Classically, RLF can be easily calculated. Therefore, the classification algorithms based on RLF can be regarded as the quantum-inspired machine learning schemes running on classical computers. Considering to run such algorithms on the quantum platforms, the main challenge is the estimation of Equation (
5) in order to obtain the similarity between a given sample and the clusters. It requires to estimate the rescaled logarithmic fidelity
and calculate the summation over the samples in the cluster. In our cases, estimating
is much easier than estimating the fidelity or implementing the full-state tomography for arbitrary states, since it is essentially the fidelity between two product states. Quantum acceleration over classical computation is unlikely in calculating such a fidelity, however, it is possible to gain quantum acceleration by parallelly computing the summations over the samples. This requires to design the corresponding quantum circuit regarding RLF, which is an open issue for the future investigations.
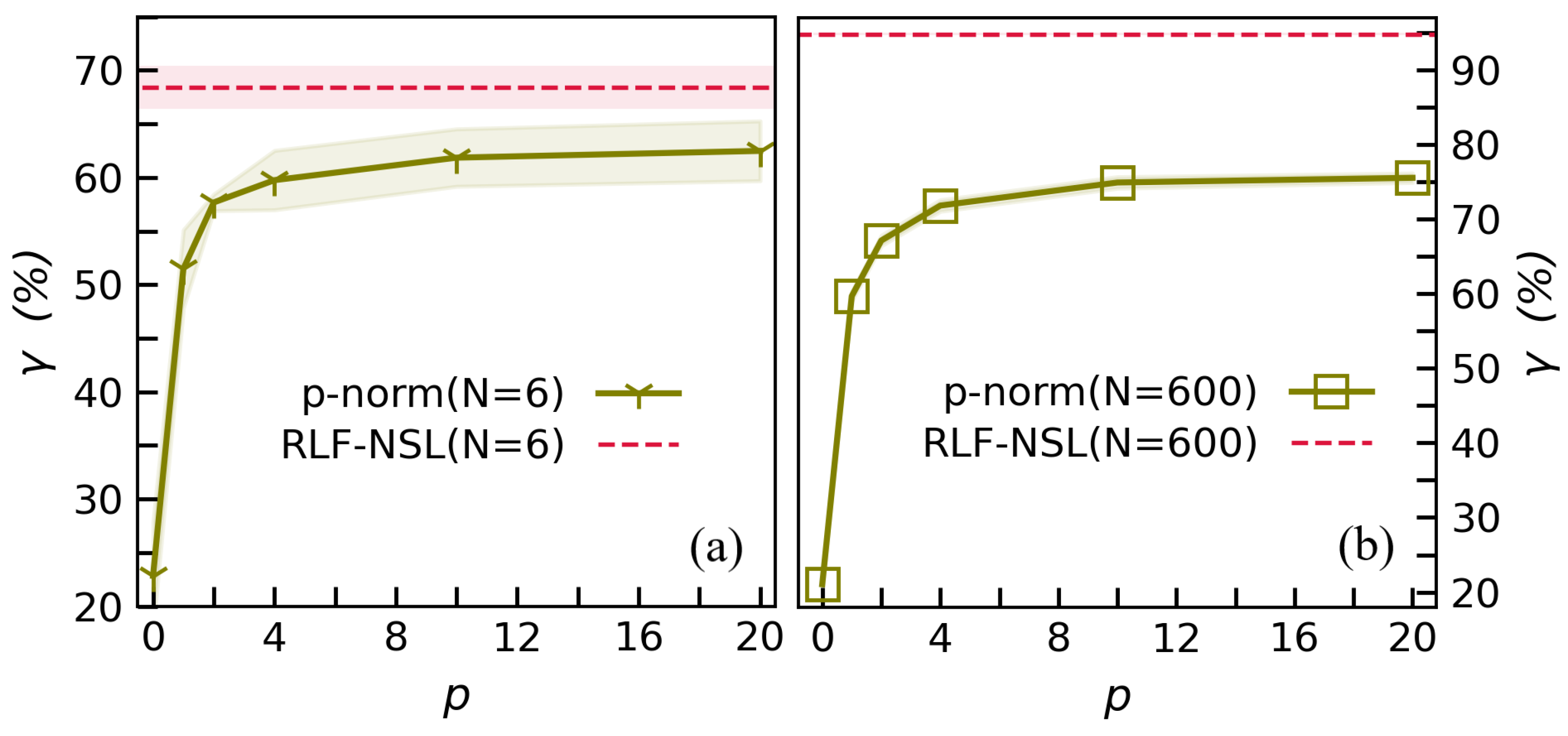
To demonstrate how
affects the classification accuracy, we choose the MNIST dataset [
65] as an example, and randomly take
labeled samples from each class of the training set. The MNIST dataset contains the grey-scale images of hand-written digits, where the resolution of each image is
(meaning 784 features in each image). The images are divided into two sets with 60,000 images as the training samples and 10,000 as the testing samples. We obtain the effective vectors
of all testing samples using Equation (
5), and calculate the classification using Equation (
6). The testing accuracy
is calculated as the number of the correctly classified testing samples divided by the total number.
Figure 1 shows the
when the number of the labeled samples in each class is small (few-shot learning with
). We show the average of
by implementing the simulations for 20 times, and the variances are illustrated by the shadowed areas. All the variances in this paper are obtained a similar way. One can see
firstly rises and then drops by increasing
, and reaches the maximum around
. Note the
that gives the maximal
slightly changes with different
N.
In the insets, we randomly take 200 testing samples from each class, and reduce the dimension of the effective vectors
from 10 to 2 by t-SNE [
35], in order to visualize the distribution of the testing samples. The t-SNE is a non-linear dimensionality reduction method. It maps the given samples to a lower-dimensional space by reducing the number of features. The reduction is optimal in the sense that the mutual distances (or similarities) among the samples in the lower-dimensional space should be close to those in the original space. By eyes, one can observe better separation for larger
(e.g.,
) compared with those
’s giving smaller
. More discussions are given below from the perspective of rate reduction [
36,
37]. We also confirm with more simulations that the fidelity (equivalently with
in the RLF) gives lower accuracy with
. Note this accuracy is also not stable since the fidelity is exponentially small.
Figure 2 demonstrates how the testing accuracy of RLF-NSL is affected by
with different numbers of labeled samples
N in each class. In all
Ns that vary from 6 to 240,
firstly rapidly rises and the slowly decreases with
. Approximately for
, relatively high testing accuracy is obtained in all cases.
4. Non-Parametric Semi-Supervised Learning with Pseudo-Labels
Based on RLF, we propose a non-parametric semi-supervised learning algorithm (RLF-NSSL). Different from supervised learning where sufficiently many labeled samples are required to implement the machine learning tasks, the key of semi-supervised learning is, in short, to utilize the samples whose labels are predicted by the algorithm itself. The generated labels are called pseudo-labels. The supervised learning can be considered as a special case of semi-supervised learning with zero pseudo-labels. For the unsupervised kernel-based classifications where there is no labeled samples, pseudo-labels can be useful to implement the classification tasks in a way similar to the supervised cases. The strategy of tagging the pseudo-labels is key to the prediction accuracy. Therefore, for the unsupervised (and also the few-shot cases with a small number of labeled samples), the performance should strongly rely on the choice of kernel. Here, we define P clusters, of which each contains two parts: all the N labeled training samples in this class and unlabeled samples that are classified to this class. The rescaling factor is taken as the optimal with labeled samples in RLF-NSL. The key is how to choose the samples with pseudo-labels to expand the clusters.
Our strategy is to divide the unlabeled training samples into batches for classification and pseudo-labeling. The clusters are initialized by the labeled samples. Then, for each batch of the unlabeled samples, we classify them by calculating the effective vectors given by Equation (
5), where the summation is over all the samples with labels and pseudo-labels (if any). Then, we add these samples to the corresponding clusters according to their classifications. The cluster is used to classify the testing set after all unlabeled training samples are classified.
Inevitably, the incorrect pseudo-labels would be introduced into the clusters, which may harm the classification accuracy. Therefore, we propose to update the samples in the clusters. To this aim, we define the confidence. For a sample
in the
p-th cluster, it is defined as
with
obtained by Equation (
5). Then, in each cluster, we keep
pseudo-labels with the highest confidence. The rest pseudo-labels are removed, and the corresponding samples are thrown to the pool of the unlabeled samples, which are to be classified in the future iterations.
Figure 3 shows the testing accuracy
of the MNIST dataset with different numbers of the labeled samples
N. The accuracy of RLF-NSL (green line) already surpasses the recognized non-parametric methods including
k-nearest neighbors (KNN) [
66] with
and 10, and the naive Bayesian classifier [
67]. KNN is also a kernel-based classification method. One first calculates the distances (or similarities) between the target sample and all labeled samples, and then find the
k labeled samples with the smallest distances. The classification of the target sample is given by finding the class that has the largest number in these
k samples. The performance of RLF-NSL significantly surpasses a baseline model, where we simply replace the RLF
in Equation (
5) by the Euclidean kernel
The RLF-NSSL achieves the highest accuracy among all the presented methods. Significant improvement is observed particularly for the few-shot learning with small N, as shown in the inset. Note for different N, we optimize in RLF-NSL and we fix in RLF-NSSL.
For the unsupervised learning, we assume there are no labeled samples from the very beginning. All samples in the clusters will be those with pseudo-labels. To start with, we randomly chose one sample to form a cluster. From all the unlabeled samples, every time we select a new sample (denoted as
) that satisfies two conditions:
with
a preset small constant. Repeating the above procedure for
times, we have
P clusters, of which each contains one sample. These samples have relatively small mutual similarities, thus are reasonable choices to initialize the clusters. We classify all the samples out of the clusters using the method explained in
Section 3. Then, all samples will be added to the corresponding clusters according to the classifications.
The next step is to use the semi-supervised learning method introduced in
Section 4 to update the samples in the clusters. Specifically, we remove the pseudo-labels for part of the samples in each cluster with the lowest confidence, and throw them to the pool of the unlabeled samples. We subsequently classify all the unlabeled samples and add them to the clusters correspondingly. Repeat the processes above until the clusters converge.
Table 1 compares the testing accuracy
of our RLF-NSSL with other two unsupervised methods
k-means [
68,
69] and spectral clustering [
70,
71,
72]. We use the way proposed in [
73] to determine the labels of the clusters. For each iteration in the RLF-NSSL to update the clusters, we remove the pseudo-labels of
of the samples with the lowest confidence in each cluster, which are to be re-classified in the next iteration. Our RLF-NSSL achieves the highest accuracy among these three methods. RLF-NSSL exhibits relatively high standard deviation, possibly due to the large fluctuation induced by the (nearly) random initialization of the clusters. Such fluctuation can be suppressed by incorporating a proper initialization strategy.
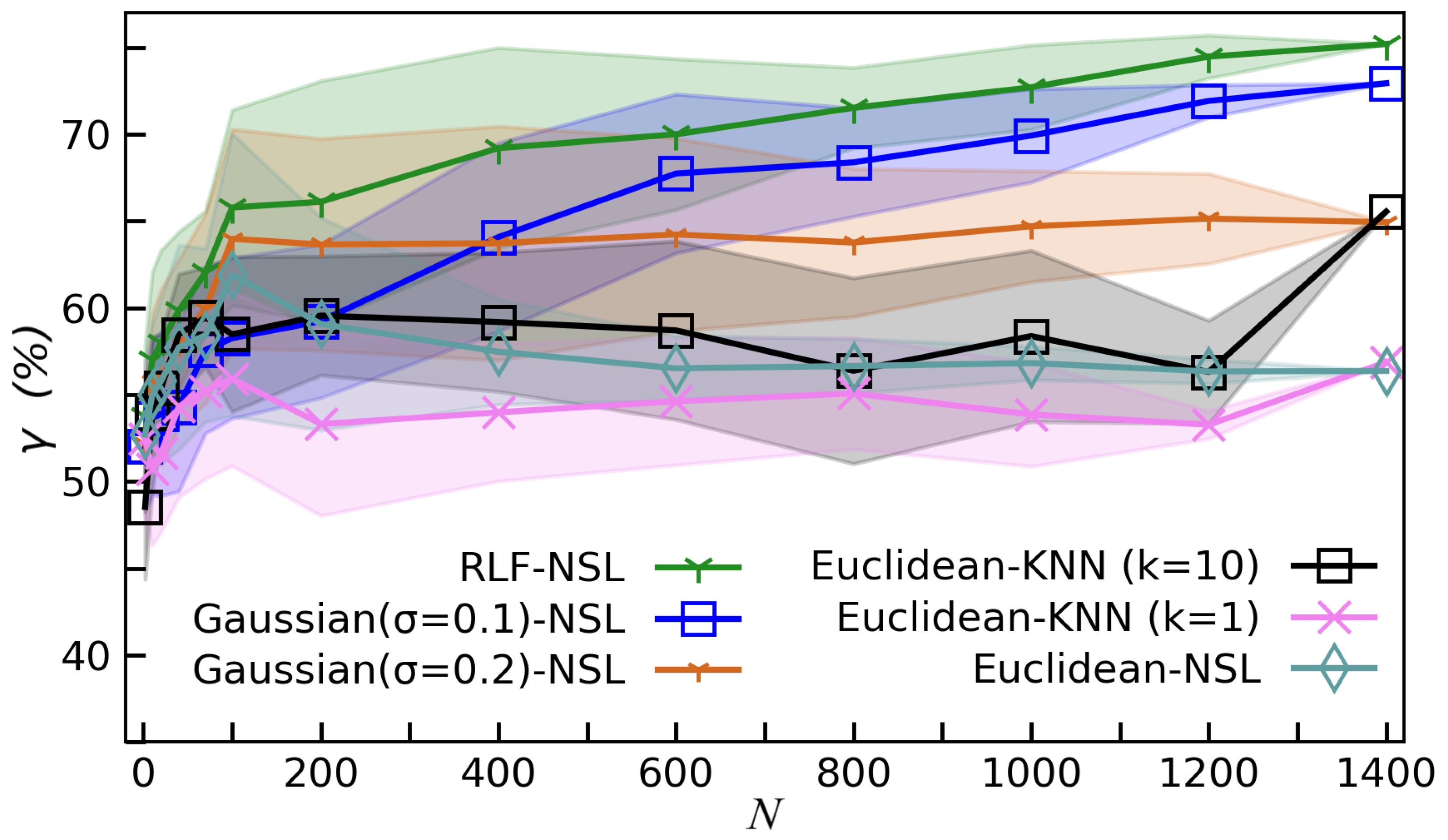
We compare the testing accuracy by using different kernels and classification strategies, as shown in
Figure 4. We choose IMDb [
74], a recognized dataset in the field of natural language processing. Each sample is a comment on a movie, and the task is to predict whether it is positive or negative. The dataset contains 50,000 samples, in which half for training and half for testing. For convenience, we limit the maximal number of the features in a sample (i.e., the maximal number of words in a comment) to
, and finally use 2773 training samples and 2963 testing samples. The labeled samples are randomly selected from the training samples, and the testing accuracy is evaluated by the testing samples. We test two classification strategies, which are KNN and NSL. We also compare different kernels. The Euclidean distance
is given by Equation (
8). For the Gaussian kernel, the distance is defined by a Gaussian distribution, which satisfies
where
controls the variance. For the Euclidean-NSL algorithm, we use
in Equation (
5) to obtain the classifications. The rest parts are the same as RLF-NSL. For the Euclidean-KNN algorithm, we use
to obtained the
k labeled samples with the smallest distances. In RLF-NSL, we flexibly adjust the rescaling factor
as the number of labeled samples varies. The RLF-NSL achieves the highest testing accuracy among these algorithms.
To demonstrate how the classification precision is improved by updating the pseudo-labeled samples in the clusters, we take the few-shot learning by RLF-NSSL as an example. At the beginning, there are labeled samples in each class to define the cluster. For the zeroth epoch, the low-dimensional data and classifications are obtained by these labeled samples. In the update process, each epoch contains three sub-steps. In the first sub-step, we classify 500 samples with the highest RLF samples and add them to the corresponding clusters according to their classifications. In the second and third sub-steps, we update the clusters by replacing part of the pseudo-labeled samples. Specifically, we move 500 samples that have the lowest confidence from each cluster to the pool of the unclassified samples. Then we calculate the classifications of all samples in the pool, and add the 500 samples with the highest RLF to the corresponding clusters.
In
Figure 5a,b, we show the confidence
and classification accuracy
for the samples inside the clusters. Each time when we add new samples to the clusters in the first sub-step of each epoch (see red markers), both
and
decrease. By updating the clusters, we observe obvious improvement of
by replacing the less confident samples in the clusters. Slight improvement of
is observed in general after the second sub-step. Even though the pseudo-labels of the samples in the clusters become less accurate as the clusters contain more and more pseudo samples, we observe monotonous increase (with insignificant fluctuations) of the testing accuracy
as shown in
Figure 5c. This is a convincing evidence on the validity of our RLF-NSSL and the pseudo-labeling strategy.
5. Discussion from the Perspective of Rate Reduction
In Refs. [
36,
37], several general principles were proposed on the continuous mapping from the original feature space to a low-dimensional space for the purposes of classification or clustering, known as the principles of maximal coding rate reduction (MCR
). Considering the classification problems, the representations should satisfy the following properties: (a) samples from the same class should belong to low-dimensional linear subspaces; (b) samples from different classes should belong to different low-dimensional subspaces and be uncorrelated; (c) the variance of features for the samples in the same class should be as large as possible as long as (b) is satisfied. These three principles are known as within-class compressibility, between-class discrimination, and overall diversity, respectively.
Our results imply that MCR
should also apply to the machine learning in the Hilbert space of many qubits. In our scheme, the clusters map each sample ( the product state obtained by the feature map given by Equation (
4)) to a
P-dimensional vector. The distribution of these vectors is defined by their mutual distances based on the RLF.
The insets of
Figure 5c show the visualizations of the
P-dimensional vectors from the testing set at the 0th and 11th epochs. At the 0th epoch, we simply use the labeled samples to define the clusters. The testing accuracy is less than
. At the 11th epoch, the clusters consist of the labeled and pseudo-labeled samples. The pseudo-labeled samples are updated using the RLF-NSSL algorithm. The testing accuracy is round
. Comparing the two distributions in the two-dimensional space, it is obvious that at the 11th epoch, the samples in the same class tend to form a one-dimensional stream in the visualization, indicating the within-class compressibility. The samples are distributed as “radiations” from the middle toward the edges, indicating the overall diversity. Each two neighboring radial lines give a similar angel, indicating the between-class discrimination. Inspecting from these three aspects, one can see that the samples at the 11th epoch better satisfy the MCR
than those at the 0th epoch. Similar phenomena can be observed in the insets of
Figure 1. The
giving higher testing accuracy would better obey the MCR
, and vice versa. These results provide preliminary evidence for the validity of MCR
for the machine learning in the Hilbert space.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






