
Lightweight Image Super-Resolution Based on Local Interaction of Multi-Scale Features and Global Fusion


Abstract
:1. Introduction
- We propose a lightweight image super-resolution reconstruction network based on local feature channels and global connection mechanism, which separates the channels in the model and retains the channel features with rich spatial information. Our model significantly reduces the number of model parameters.
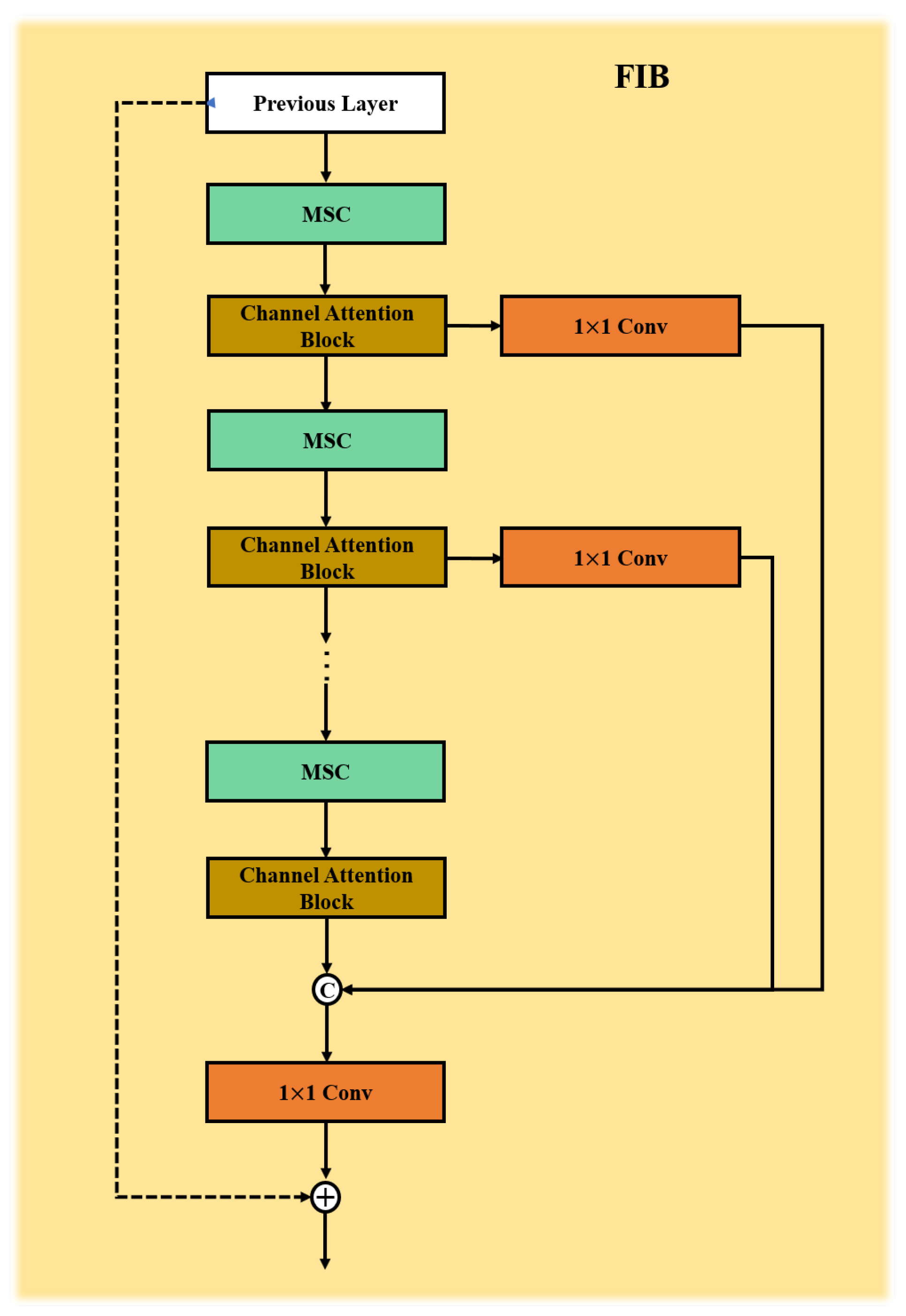
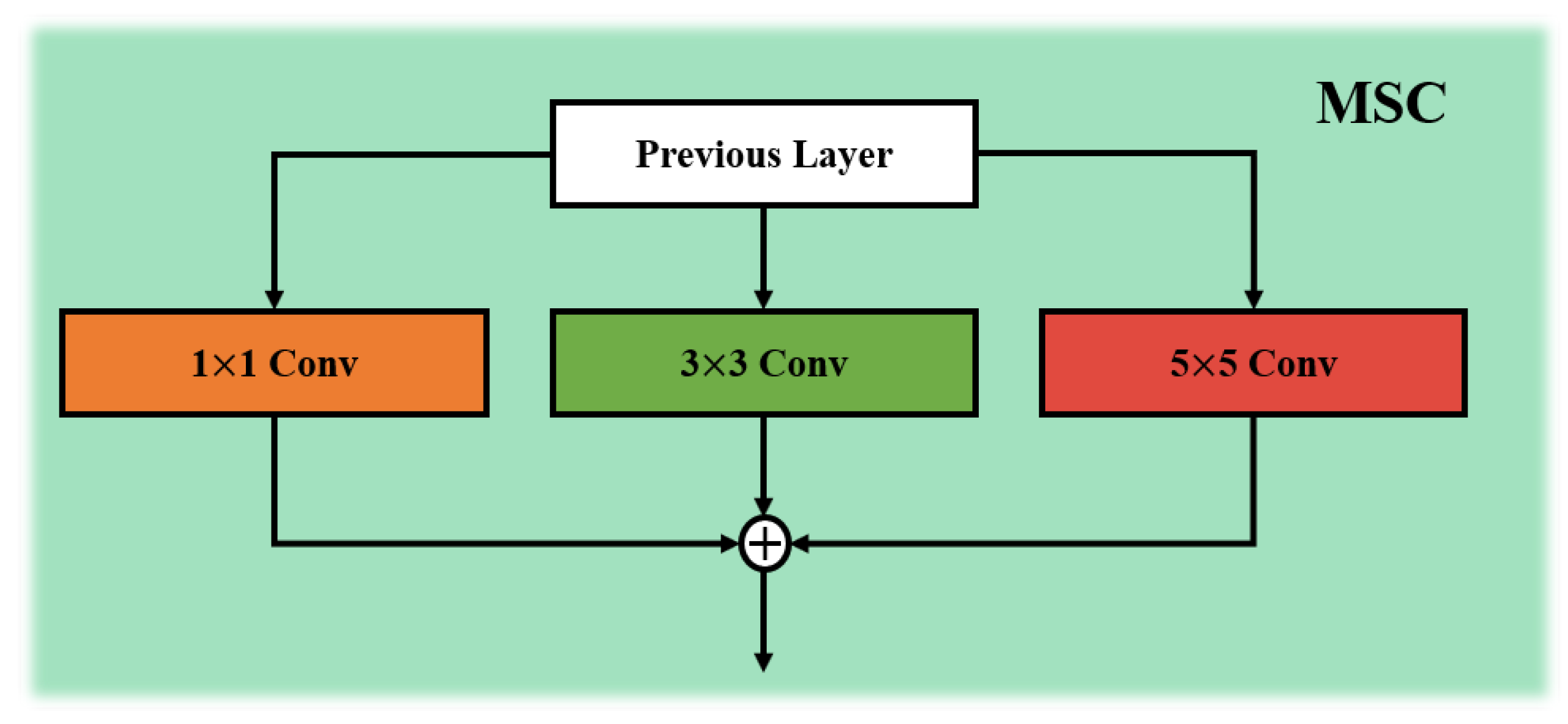
- We construct a feature fusion block based on local interaction of multi-scale features, which includes channel attention mechanism and multi-scale local feature interaction mechanism. The multi-scale local feature interaction mechanism is mainly composed of feature interaction blocks, through which local attention and interaction can effectively improve the authenticity of the reconstructed image compared with the original image, and realize the connection and fusion of multi-scale features.
- We use residual learning and global connection to fuse local features and global features, retain the high-frequency information and edge details of the original image, and improve the quality of the reconstructed image. As shown in Figure 1, on the Urban100 test set with scaling factor ×4, the PSNR of the reconstructed image of the MSFN model reaches 26.34 dB. Compared with the models CARN and SRMDNF of the same size, the reconstruction effect of our model is greatly improved.
2. Related Work
2.1. Deep CNN for Image Super-Resolution
2.2. Lightweight CNN for Image Super-Resolution
3. Proposed Method
3.1. Network Architecture
3.2. Multi-Scale Feature Interaction Block
4. Experiments
4.1. Training Settings
4.2. Ablation Experiment
4.3. Quantitative Analysis
4.4. Qualitative Visual Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, W.J.; Lin, X.Y.; Zhou, X.; Lei, J.S.; Yu, L.; Luo, T. Multi-layer fusion network for blind stereoscopic 3D visual quality prediction. Signal Process.-Image Commun. 2021, 91, 116095. [Google Scholar] [CrossRef]
- Lu, B.; Chen, J.; Chellappa, R. UID-GAN: Unsupervised Image Deblurring via Disentangled Representations. IEEE Trans. Biom. Behav. Identity Sci. 2020, 2, 26–39. [Google Scholar] [CrossRef]
- Lei, S.; Shi, Z.W.; Zou, Z.X. Super-Resolution for Remote Sensing Images via Local-Global Combined Network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Shermeyer, J.; Van Etten, A. The effects of super-resolution on object detection performance in satellite imagery. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Yoo, S.; Lee, J.; Bae, J.; Jang, H.; Sohn, H.-G. Automatic generation of aerial orthoimages using sentinel-2 satellite imagery with a context-based deep learning approach. Appl. Sci. 2021, 11, 1089. [Google Scholar] [CrossRef]
- Ren, S.; Jain, D.K.; Guo, K.H.; Xu, T.; Chi, T. Towards efficient medical lesion image super-resolution based on deep residual networks. Signal Process.-Image Commun. 2019, 75, 1–10. [Google Scholar] [CrossRef]
- Shafiei, F.; Fekri-Ershad, S. Detection of Lung Cancer Tumor in CT Scan Images Using Novel Combination of Super Pixel and Active Contour Algorithms. Trait. Du Signal 2020, 37, 1029–1035. [Google Scholar] [CrossRef]
- Mahapatra, D.; Bozorgtabar, B.; Garnavi, R.J.C.M.I. Image super-resolution using progressive generative adversarial networks for medical image analysis. Comput. Med. Imaging Graph. 2019, 71, 30–39. [Google Scholar] [CrossRef] [PubMed]
- Wu, M.-J.; Karls, J.; Duenwald-Kuehl, S.; Vanderby, R., Jr.; Sethares, W. Spatial and frequency-based super-resolution of ultrasound images. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2014, 2, 146–156. [Google Scholar] [CrossRef] [PubMed]
- Kwon, O. Face recognition Based on Super-resolution Method Using Sparse Representation and Deep Learning. J. Korea Multimed. Soc. 2018, 21, 173–180. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.M.; Tang, X.O. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 723–731. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual feature distillation network for lightweight image super-resolution. In Proceedings of the ECCV, Glasgow, UK, 23–28 August 2020; pp. 41–55. [Google Scholar]
- Chen, H.; He, X.; Qing, L.; Wu, Y.; Ren, C.; Sheriff, R.E.; Zhu, C. Real-world single image super-resolution: A brief review. Inf. Fusion 2022, 79, 124–145. [Google Scholar] [CrossRef]
- Dun, Y.; Da, Z.; Yang, S.; Xue, Y.; Qian, X. Kernel-attended residual network for single image super-resolution. Knowl.-Based Syst. 2021, 213, 106663. [Google Scholar] [CrossRef]
- Tao, Y.; Conway, S.J.; Muller, J.-P.; Putri, A.R.; Thomas, N.; Cremonese, G. Single image super-resolution restoration of TGO CaSSIS colour images: Demonstration with perseverance rover landing site and Mars science targets. Remote Sens. 2021, 13, 1777. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1664–1673. [Google Scholar]
- Yang, X.; Li, X.; Li, Z.; Zhou, D. Image super-resolution based on deep neural network of multiple attention mechanism. J. Vis. Commun. Image Represent. 2021, 75, 103019. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Yang, X.; Zhang, Y.; Guo, Y.; Zhou, D. An image super-resolution deep learning network based on multi-level feature extraction module. Multimed. Tools Appl. 2021, 80, 7063–7075. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Li, Z.; Wang, C.; Wang, J.; Ying, S.; Shi, J. Lightweight adaptive weighted network for single image super-resolution. Comput. Vis. Image Underst. 2021, 211, 103254. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Tian, C.; Zhuge, R.; Wu, Z.; Xu, Y.; Zuo, W.; Chen, C.; Lin, C.-W. Lightweight image super-resolution with enhanced CNN. Knowl.-Based Syst. 2020, 205, 106235. [Google Scholar] [CrossRef]
- Jiang, X.; Wang, N.; Xin, J.; Xia, X.; Yang, X.; Gao, X. Learning lightweight super-resolution networks with weight pruning. Neural Netw. 2021, 144, 21–32. [Google Scholar] [CrossRef] [PubMed]
- Bouvrie, J. Notes on Convolutional Neural Networks. 2006. Available online: https://web-archive.southampton.ac.uk/cogprints.org/5869/ (accessed on 1 February 2022).
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference Location (BMVC), Guildford, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; pp. 711–730. [Google Scholar]
- Huang, J.-B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the ICCV, Vancouver, BC, Canada, 7–14 July 2001; pp. 416–423. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based manga retrieval using manga109 dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef] [Green Version]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the ECCV, Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X.; Xu, C. Memnet: A persistent memory network for image restoration. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 4539–4547. [Google Scholar]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the CVPR Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 126–135. [Google Scholar]
- Namozov, A.; Im Cho, Y. An improvement for medical image analysis using data enhancement techniques in deep learning. In Proceedings of the 2018 International Conference on Information and Communication Technology Robotics (ICT-ROBOT), Busan, Korea, 6–8 September 2018; pp. 1–3. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016; pp. 391–407. [Google Scholar]
- Lai, W.-S.; Huang, J.-B.; Ahuja, N.; Yang, M.-H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 624–632. [Google Scholar]
- Zhang, K.; Zuo, W.; Zhang, L. Learning a single convolutional super-resolution network for multiple degradations. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3262–3271. [Google Scholar]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 4799–4807. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scale | Number of FIBs | Number of Channels | Params (K) | Set14 | |
|---|---|---|---|---|---|
| PSNR (dB) | SSIM | ||||
| 4× | 4 | 48 | 395 | 28.47 | 0.7789 |
| 6 | 571 | 28.61 | 0.7814 | ||
| 8 | 747 | 28.69 | 0.7824 | ||
| Scale | Number of FIBs | Number of Channels | Params (K) | Set5 | |
|---|---|---|---|---|---|
| PSNR (dB) | SSIM | ||||
| 4× | 6 | 48 | 571 | 32.12 | 0.8941 |
| 56 | 772 | 32.16 | 0.8947 | ||
| 64 | 1004 | 32.23 | 0.8950 | ||
| Method | Scale | Params | Set5 | Set14 | BSD100 | Urban100 | Manga109 |
|---|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | |||
| Bicubic | 2× | - | 33.66/0.9299 | 30.24/0.8688 | 29.56/0.8431 | 26.88/0.8403 | 30.80/0.9339 |
| SRCNN | 57 K | 36.66/0.9542 | 32.45/0.9067 | 31.36/0.8879 | 29.50/0.8946 | 35.60/0.9663 | |
| FSRCNN | 13 K | 37.05/0.9560 | 32.66/0.9090 | 31.53/0.8920 | 29.88/0.9020 | 36.67/0.9710 | |
| VDSR | 666 K | 37.53/0.9590 | 33.05/0.9130 | 31.90/0.8960 | 30.77/0.9140 | 37.22/0.9750 | |
| LapSRN | 813 K | 37.52/0.9591 | 33.08/0.9130 | 31.08/0.8950 | 30.41/0.9101 | 37.27/0.9740 | |
| DRRN | 297 K | 37.74/0.9591 | 33.23/0.9136 | 32.05/0.8973 | 31.23/0.9188 | 37.60/0.9736 | |
| MemNet | 678 K | 37.78/0.9597 | 33.28/0.9142 | 32.08/0.8978 | 31.31/0.9195 | 37.72/0.9740 | |
| LESRCNN | 516 K | 37.65/0.9586 | 33.32/0.9148 | 31.95/0.8964 | 31.45/0.9206 | -/- | |
| SRMDNF | 1511 K | 37.79/0.9601 | 33.32/0.9159 | 32.05/0.8985 | 31.33/0.9204 | 38.07/0.9761 | |
| CARN | 1592 K | 37.76/0.9590 | 33.52/0.9166 | 32.09/0.8978 | 31.92/0.9256 | 38.36/0.9764 | |
| IDN | 715 K | 37.83/0.9600 | 33.30/0.9148 | 32.08/0.8985 | 31.27/0.9196 | -/- | |
| IMDN | 694 K | 38.00/0.9605 | 33.63/0.9177 | 32.19/0.8996 | 32.17/0.9283 | 38.88/0.9774 | |
| MSFN-S | 555 K | 37.96/0.9603 | 33.61/0.9181 | 32.15/0.8988 | 32.14/0.9272 | 38.85/0.9772 | |
| MSFN | 1568 K | 38.01/0.9606 | 33.77/0.9193 | 32.24/0.9000 | 32.24/0.9286 | 38.97/0.9776 | |
| Bicubic | 3× | - | 30.39/0.8682 | 27.55/0.7742 | 27.21/0.7385 | 24.46/0.7349 | 26.95/0.8556 |
| SRCNN | 8 K | 32.75/0.9090 | 29.30/0.8215 | 28.41/0.7863 | 26.24/0.7989 | 30.48/0.9117 | |
| FSRCNN | 13 K | 33.18/0.9140 | 29.37/0.8240 | 28.53/0.7910 | 26.43/0.8080 | 31.10/0.9210 | |
| VDSR | 666 K | 33.67/0.9210 | 29.78/0.8320 | 28.83/0.7990 | 27.14/0.8290 | 32.01/0.9340 | |
| LapSRN | 813 K | 33.82/0.9227 | 29.87/0.8230 | 28.82/0.7980 | 27.07/0.8280 | 32.31/0.9350 | |
| DRRN | 297 K | 34.03/0.9244 | 29.96/0.8349 | 28.95/0.8004 | 27.53/0.8378 | 32.42/0.9359 | |
| MemNet | 678 K | 34.09/0.9248 | 30.00/0.8350 | 28.96/0.8001 | 27.56/0.8376 | 32.51/0.9369 | |
| LESRCNN | 516 K | 33.93/0.9231 | 30.12/0.8380 | 28.91/0.8005 | 27.70/0.8415 | -/- | |
| SRMDNF | 1528 K | 34.12/0.9254 | 30.04/0.8382 | 28.97/0.8025 | 27.57/0.8398 | 33.00/0.9403 | |
| CARN | 1592 K | 34.29/0.9255 | 30.29/0.8407 | 29.06/0.8034 | 28.06/0.8493 | 33.49/0.9440 | |
| IDN | 715 K | 34.11/0.9253 | 29.99/0.8354 | 28.95/0.8013 | 27.42/0.8359 | -/- | |
| IMDN | 703 K | 34.36/0.9270 | 30.32/0.8417 | 29.09/0.8046 | 28.17/0.8519 | 33.61/0.9445 | |
| MSFN-S | 562 K | 34.31/0.9265 | 30.33/0.8421 | 29.11/0.8053 | 28.22/0.8531 | 33.65/0.9451 | |
| MSFN | 1574 K | 34.47/0.9275 | 30.38/0.8428 | 29.20/0.8082 | 28.55/0.8549 | 33.71/0.9463 | |
| Bicubic | 4× | - | 28.42/0.8104 | 26.00/0.7027 | 25.96/0.6675 | 23.14/0.6577 | 24.89/0.7866 |
| SRCNN | 8 K | 30.48/0.8628 | 27.50/0.7513 | 26.90/0.7101 | 24.52/0.7221 | 27.58/0.8555 | |
| FSRCNN | 13 K | 30.72/0.8660 | 27.61/0.7550 | 26.98/0.7150 | 24.62/0.7280 | 27.90/0.8610 | |
| VDSR | 666 K | 31.35/0.8830 | 28.02/0.7680 | 27.29/0.7260 | 25.18/0.7540 | 28.83/0.8870 | |
| LapSRN | 813 K | 31.54/0.8850 | 28.19/0.7720 | 27.32/0.7270 | 25.21/0.7560 | 29.09/0.8900 | |
| DRRN | 297 K | 31.68/0.8888 | 28.21/0.7720 | 27.38/0.7284 | 25.44/0.7638 | 29.18/0.8914 | |
| MemNet | 678 K | 31.74/0.8893 | 28.26/0.7723 | 27.40/0.7281 | 25.50/0.7630 | 29.42/0.8942 | |
| LESRCNN | 516 K | 31.88/0.8903 | 28.44/0.7772 | 27.45/0.7313 | 25.77/0.7732 | -/- | |
| SRMDNF | 1552 K | 31.96/0.8925 | 28.35/0.7787 | 27.49/0.7337 | 25.68/0.7731 | 30.09/0.9024 | |
| SRDenseNet | 2015 K | 32.02/0.8934 | 28.50/0.7782 | 27.53/0.7337 | 26.05/0.7819 | -/- | |
| CARN | 1592 K | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | 30.40/0.9082 | |
| IDN | 715 K | 31.82/0.8903 | 28.25/0.7730 | 27.41/0.7297 | 25.41/0.7632 | -/- | |
| IMDN | 715 K | 32.21/0.8948 | 28.58/0.7811 | 27.56/0.7353 | 26.04/0.7838 | 30.42/0.9074 | |
| MSFN-S | 571 K | 32.12/0.8941 | 28.61/0.7814 | 27.56/0.7348 | 26.02/0.7834 | 30.45/0.9075 | |
| MSFN | 1583 K | 32.26/0.8946 | 28.65/0.7815 | 27.62/0.7364 | 26.34/0.7906 | 30.58/0.9089 |
| Method | FLOPs (G) | Time (ms) | PSNR (dB) |
|---|---|---|---|
| LESRCNN | 77 | 44 | 26.37 |
| CARN | 41 | 62 | 26.57 |
| IMDN | 21 | 37 | 26.62 |
| MSFN-S | 18 | 31 | 26.67 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meng, Z.; Zhang, J.; Li, X.; Zhang, L. Lightweight Image Super-Resolution Based on Local Interaction of Multi-Scale Features and Global Fusion. Mathematics 2022, 10, 1096. https://doi.org/10.3390/math10071096
Meng Z, Zhang J, Li X, Zhang L. Lightweight Image Super-Resolution Based on Local Interaction of Multi-Scale Features and Global Fusion. Mathematics. 2022; 10(7):1096. https://doi.org/10.3390/math10071096
Chicago/Turabian StyleMeng, Zhiqing, Jing Zhang, Xiangjun Li, and Lingyin Zhang. 2022. "Lightweight Image Super-Resolution Based on Local Interaction of Multi-Scale Features and Global Fusion" Mathematics 10, no. 7: 1096. https://doi.org/10.3390/math10071096
APA StyleMeng, Z., Zhang, J., Li, X., & Zhang, L. (2022). Lightweight Image Super-Resolution Based on Local Interaction of Multi-Scale Features and Global Fusion. Mathematics, 10(7), 1096. https://doi.org/10.3390/math10071096