
Robust Detection and Modeling of the Major Temporal Arcade in Retinal Fundus Images

 , , and
, , and
Abstract
:1. Introduction
- Blood-vessel-width and intensity features are integrated into the MTA detection and modeling process.
- A modeling strategy addressing both symmetric and asymmetric scenarios is presented to improve the MTA characterization.
- A weighted-RANSAC scheme is included to robustly select a MTA model configuration.
- A set of MTA manual delineations for the benchmark DRIVE dataset has been released for scientific purposes.
2. Methods
2.1. Pre-Processing
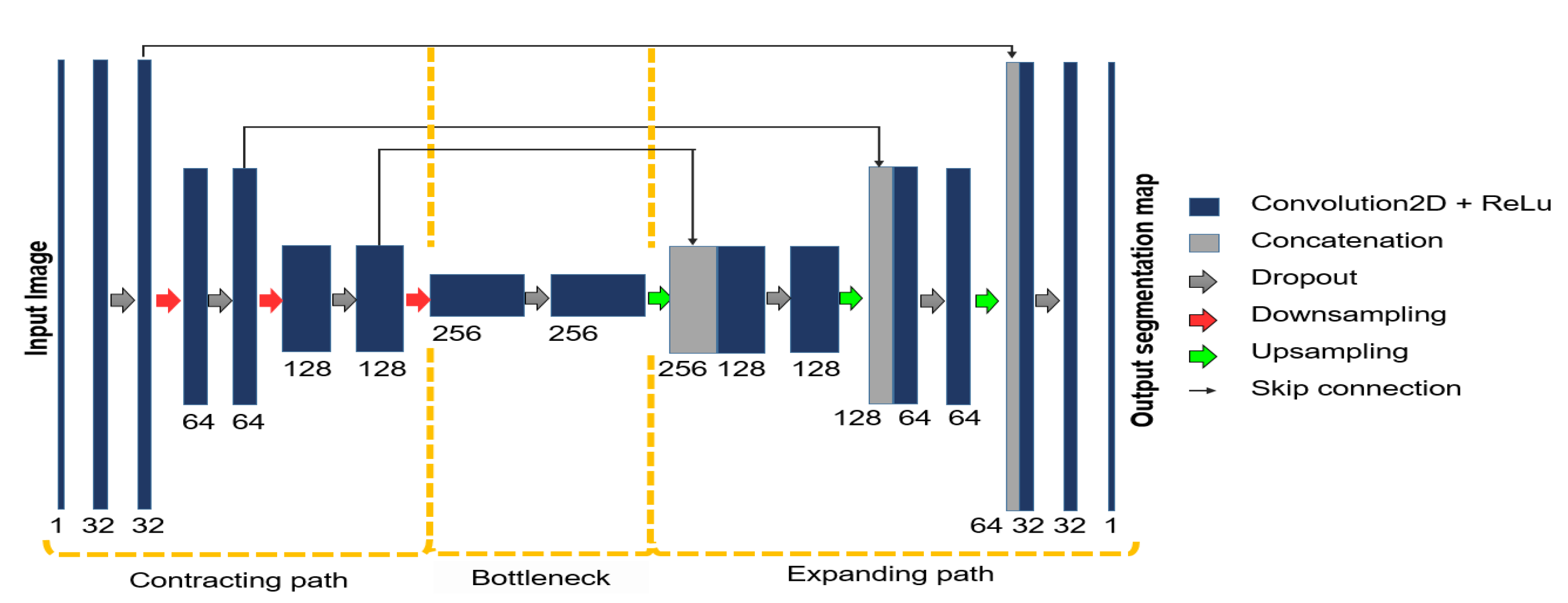
2.2. Automatic Segmentation of the Vascular Tree
2.3. Feature Extraction
2.3.1. Vessel Thickness
- When a pixel is not located in a blood vessel, the metric returns a value of zero.
- When a pixel is located in the center of a thin blood vessel, the metric returns a value close to zero.
- When a pixel is located in the center of a thick blood vessel, the metric returns a value close to one.
2.3.2. Foreground Location
2.3.3. MTA Probability Map
2.4. Numerical Modeling of the MTA
2.4.1. Piecewise Parametric Modeling
2.4.2. Weighted RANSAC
| Algorithm 1: The weighted-RANSAC algorithm. |
 |
2.4.3. Constraints on Point Selection
3. Results and Discussion
3.1. Dataset and Delineation of the MTA
3.2. Evaluation Metrics
3.3. Implementation Details
3.4. Comparative Analysis
4. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| bACC | Skeleton-based balanced Accuracy |
| CLAHE | Contrast Limited Adaptive Histogram Equalization |
| CNN | Convolutional Neural Network |
| DCP | Distance to Closest Point |
| DRIVE | Digital Retinal Images for Vessel Extraction |
| FP | False Positives |
| IMSS | Mexican Social Security Institute |
| ITA | Inferior Temporal Arcade |
| MDCP | Mean Distance to Closest Point |
| MTA | Major Temporal Arcade |
| N | Skeleton-based Negatives |
| P | Positives |
| Pre | Precision |
| RANSAC | Random Sample Consensus |
| Rec | Skeleton-based Recall |
| STA | Superior Temporal Arcade |
| UMDA | Univariate Marginal Distribution Algorithm |
| TAA | Temporal Arcade Angle |
| TP | True Positives |
References
- Wilson, C.; Theodorou, M.; Cocker, K.D.; Fielder, A.R. The temporal retinal vessel angle and infants born preterm. Br. J. Ophthalmol. 2006, 90, 702–704. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oloumi, F.; Rangayyan, R.M.; Casti, P.; Ells, A.L. Computer-aided diagnosis of plus disease via measurement of vessel thickness in retinal fundus images of preterm infants. Comput. Biol. Med. 2015, 66, 316–329. [Google Scholar] [CrossRef] [PubMed]
- Nabi, F.; Yousefi, H.; Soltanian-Zadeh, H. Segmentation of major temporal arcade in angiography images of retina using generalized hough transform and graph analysis. In Proceedings of the 2015 22nd Iranian Conference on Biomedical Engineering (ICBME), Tehran, Iran, 25–27 November 2015; pp. 287–292. [Google Scholar]
- Fleming, A.D.; Philip, S.; Goatman, K.A.; Olson, J.A.; Sharp, P.F. Automated assessment of diabetic retinal image quality based on clarity and field definition. Investig. Ophthalmol. Vis. Sci. 2006, 47, 1120–1125. [Google Scholar] [CrossRef] [Green Version]
- Fleming, A.D.; Goatman, K.A.; Philip, S.; Prescott, G.J.; Sharp, P.F.; Olson, J.A. Automated grading for diabetic retinopathy: A large-scale audit using arbitration by clinical experts. Br. J. Ophthalmol. 2010, 94, 1606–1610. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fledelius, H.C.; Goldschmidt, E. Optic disc appearance and retinal temporal vessel arcade geometry in high myopia, as based on follow-up data over 38 years. Acta Ophthalmol. 2010, 88, 514–520. [Google Scholar] [CrossRef] [PubMed]
- Oloumi, F.; Rangayyan, R.M.; Ells, A.L. Parabolic modeling of the major temporal arcade in retinal fundus images. IEEE Trans. Instrum. Meas. 2012, 61, 1825–1838. [Google Scholar] [CrossRef]
- Oloumi, F.; Rangayyan, R.; Ells, A.L. Dual-parabolic modeling of the superior and the inferior temporal arcades in fundus images of the retina. In Proceedings of the 2011 IEEE International Symposium on Medical Measurements and Applications, Bari, Italy, 30–31 May 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Oloumi, F.; Rangayyan, R.M.; Ells, A.L. Computer-Aided Diagnosis of Retinopathy of Prematurity in Retinal Fundus Images. In Medical Image Analysis and Informatics; CRC Press: Boca Raton, FL, USA, 2017; pp. 57–83. [Google Scholar] [CrossRef]
- Guerrero-Turrubiates, J.D.J.; Cruz-Aceves, I.; Ledesma, S.; Sierra-Hernandez, J.M.; Velasco, J.; Avina-Cervantes, J.G.; Avila-Garcia, M.S.; Rostro-Gonzalez, H.; Rojas-Laguna, R. Fast parabola detection using estimation of distribution algorithms. Comput. Math. Methods Med. 2017, 2017, 6494390. [Google Scholar] [CrossRef]
- Valdez, S.I.; Espinoza-Perez, S.; Cervantes-Sanchez, F.; Cruz-Aceves, I. Hybridization of the Univariate Marginal Distribution Algorithm with Simulated Annealing for Parametric Parabola Detection. In Hybrid Metaheuristics for Image Analysis; Springer: Berlin/Heidelberg, Germany, 2018; pp. 163–186. [Google Scholar] [CrossRef]
- Zhou, M.; Jin, K.; Wang, S.; Ye, J.; Qian, D. Color retinal image enhancement based on luminosity and contrast adjustment. IEEE Trans. Biomed. Eng. 2017, 65, 521–527. [Google Scholar] [CrossRef]
- Soomro, T.A.; Khan, T.M.; Khan, M.A.; Gao, J.; Paul, M.; Zheng, L. Impact of ICA-based image enhancement technique on retinal blood vessels segmentation. IEEE Access 2018, 6, 3524–3538. [Google Scholar] [CrossRef]
- Alwazzan, M.J.; Ismael, M.A.; Ahmed, A.N. A hybrid algorithm to enhance colour retinal fundus images using a Wiener filter and CLAHE. J. Digit. Imaging 2021, 34, 750–759. [Google Scholar] [CrossRef]
- Pizer, S.M.; Johnston, R.E.; Ericksen, J.P.; Yankaskas, B.C.; Muller, K.E. Contrast-Limited Adaptive Histogram Equalization: Speed and Effectiveness. In Proceedings of the First Conference on Visualization in Biomedical Computing, Atlanta, GA, USA, 22–25 May 1990; IEEE Computer Society Press: Washington, DC, USA, 1990; p. 337. [Google Scholar]
- Sule, O.; Viriri, S.; Gwetu, M. Contrast Enhancement in Deep Convolutional Neural Networks for Segmentation of Retinal Blood Vessels. In Asian Conference on Intelligent Information and Database Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 278–290. [Google Scholar] [CrossRef]
- Arjuna, A.; Rose, R.R. Performance Analysis of Various Contrast Enhancement techniques with Illumination Equalization on Retinal Fundus Images. In Proceedings of the 2019 International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 27–29 November 2019; pp. 406–411. [Google Scholar] [CrossRef]
- Ningsih, D.R. Improving Retinal Image Quality Using the Contrast Stretching, Histogram Equalization, and CLAHE Methods with Median Filters. Int. J. Image Graph. Signal Process. 2020, 12, 30. [Google Scholar] [CrossRef]
- da Rocha, D.A.; Barbosa, A.B.L.; Guimarães, D.S.; Gregório, L.M.; Gomes, L.H.N.; da Silva Amorim, L.; Peixoto, Z.M.A. An unsupervised approach to improve contrast and segmentation of blood vessels in retinal images using CLAHE, 2D Gabor wavelet, and morphological operations. Res. Biomed. Eng. 2020, 36, 67–75. [Google Scholar] [CrossRef]
- dos Santos, J.C.M.; Carrijo, G.A.; dos Santos Cardoso, C.F.; Ferreira, J.C.; Sousa, P.M.; Patrocinio, A.C. Fundus image quality enhancement for blood vessel detection via a neural network using CLAHE and Wiener filter. Res. Biomed. Eng. 2020, 36, 107–119. [Google Scholar] [CrossRef]
- Zhou, C.; Zhang, X.; Chen, H. A new robust method for blood vessel segmentation in retinal fundus images based on weighted line detector and hidden Markov model. Comput. Methods Programs Biomed. 2020, 187, 105231. [Google Scholar] [CrossRef] [PubMed]
- Ali, A.; Mimi Diyana Wan Zaki, W.; Hussain, A.; Haslina Wan Abdul Halim, W.; Hashim, N.; Noorshahida Mohd Isa, W. B-COSFIRE and Background Normalisation for Efficient Segmentation of Retinal Vessels. In Proceedings of the 2021 IEEE Symposium on Industrial Electronics Applications (ISIEA), Langkawi Island, Malaysia, 10–11 July 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Ma, Y.; Zhu, Z.; Dong, Z.; Shen, T.; Sun, M.; Kong, W. Multichannel Retinal Blood Vessel Segmentation Based on the Combination of Matched Filter and U-Net Network. BioMed Res. Int. 2021, 2021, 5561125. [Google Scholar] [CrossRef]
- Khan, T.M.; Khan, M.A.; Rehman, N.U.; Naveed, K.; Afridi, I.U.; Naqvi, S.S.; Raazak, I. Width-wise vessel bifurcation for improved retinal vessel segmentation. Biomed. Signal Process. Control 2022, 71, 103169. [Google Scholar] [CrossRef]
- Rodrigues, E.O.; Conci, A.; Liatsis, P. ELEMENT: Multi-modal retinal vessel segmentation based on a coupled region growing and machine learning approach. IEEE J. Biomed. Health Inform. 2020, 24, 3507–3519. [Google Scholar] [CrossRef]
- Tamim, N.; Elshrkawey, M.; Abdel Azim, G.; Nassar, H. Retinal blood vessel segmentation using hybrid features and multi-layer perceptron neural networks. Symmetry 2020, 12, 894. [Google Scholar] [CrossRef]
- Shi, Y.; Liu, L.; Li, F. An Adaptive Topology-enhanced Deep Learning Method Combined with Fast Label Extraction Scheme for Retinal Vessel Segmentation. In Proceedings of the 2021 14th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Shanghai, China, 23–25 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Jin, Q.; Meng, Z.; Pham, T.D.; Chen, Q.; Wei, L.; Su, R. DUNet: A deformable network for retinal vessel segmentation. Knowl.-Based Syst. 2019, 178, 149–162. [Google Scholar] [CrossRef] [Green Version]
- Feng, S.; Zhuo, Z.; Pan, D.; Tian, Q. CcNet: A cross-connected convolutional network for segmenting retinal vessels using multi-scale features. Neurocomputing 2020, 392, 268–276. [Google Scholar] [CrossRef]
- Li, L.; Verma, M.; Nakashima, Y.; Nagahara, H.; Kawasaki, R. IterNet: Retinal Image Segmentation Utilizing Structural Redundancy in Vessel Networks. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 3656–3665. [Google Scholar] [CrossRef]
- Jiang, Y.; Liu, W.; Wu, C.; Yao, H. Multi-Scale and Multi-Branch Convolutional Neural Network for Retinal Image Segmentation. Symmetry 2021, 13, 365. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Yang, X.; Chen, H.; Qin, J.; Heng, P.A. Volumetric ConvNets with Mixed Residual Connections for Automated Prostate Segmentation from 3D MR Images. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 66–72. [Google Scholar]
- Alom, M.Z.; Hasan, M.; Yakopcic, C.; Taha, T.M.; Asari, V.K. Recurrent residual convolutional neural network based on u-net (r2u-net) for medical image segmentation. arXiv 2018, arXiv:1802.06955. [Google Scholar]
- Dalmış, M.U.; Litjens, G.; Holland, K.; Setio, A.; Mann, R.; Karssemeijer, N.; Gubern-Mérida, A. Using deep learning to segment breast and fibroglandular tissue in MRI volumes. Med. Phys. 2017, 44, 533–546. [Google Scholar] [CrossRef] [PubMed]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Jiang, X.; Mojon, D. Adaptive local thresholding by verification-based multithreshold probing with application to vessel detection in retinal images. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 131–137. [Google Scholar] [CrossRef] [Green Version]
- Azegrouz, H.; Trucco, E.; Dhillon, B.; MacGillivray, T.; MacCormick, I. Thickness dependent tortuosity estimation for retinal blood vessels. In Proceedings of the 2006 International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; pp. 4675–4678. [Google Scholar] [CrossRef]
- Sironi, A.; Lepetit, V.; Fua, P. Multiscale centerline detection by learning a scale-space distance transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2697–2704. [Google Scholar] [CrossRef] [Green Version]
- McKinley, S.; Levine, M. Cubic Spline Interpolation. Coll. Redwoods 1998, 45, 1049–1060. [Google Scholar]
- Dyer, S.A.; Dyer, J.S. Cubic-spline interpolation. 1. IEEE Instrum. Meas. Mag. 2001, 4, 44–46. [Google Scholar] [CrossRef]
- Marsh, L.; Cormier, L.; Cormier, D.; Publications, S. Spline Regression Models; Number n.º 137 in Quantitative Applications in the Social Sciences; SAGE Publications: New York, NY, USA, 2001. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Derpanis, K.G. Overview of the RANSAC Algorithm. Image Rochester N. Y. 2010, 4, 2–3. [Google Scholar]
- Zhang, D.; Wang, W.; Huang, Q.; Jiang, S.; Gao, W. Matching images more efficiently with local descriptors. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; pp. 1–4. [Google Scholar] [CrossRef]
- Staal, J.; Abramoff, M.; Niemeijer, M.; Viergever, M.; van Ginneken, B. Ridge based vessel segmentation in color images of the retina. IEEE Trans. Med. Imaging 2004, 23, 501–509. [Google Scholar] [CrossRef]
- Giacinti, D.J.; Cervantes Sánchez, F.; Cruz Aceves, I.; Hernández González, M.A.; López Montero, L.M. Determination of the parabola of the retinal vasculature using a segmentation computational algorithm. Nova Sci. 2019, 11. [Google Scholar] [CrossRef]
- Sanchez, C. Parabola Detection Using Hough Transform. 2007. Available online: https://www.mathworks.com/matlabcentral/fileexchange/15841-parabola-detection-using-hough-transform (accessed on 9 March 2022).
- McAuliffe, M. Medical Image Processing, Analysis, and Visualization (MIPAV); National Institutes of Health: Bethesda, MD, USA, 2009. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MDCP (px.) | Hausdorff (px.) |
|---|---|---|
| Mean ± Std. | Mean ± Std. | |
| Gabor+Hough [7] | 12.10 ± 6.16 | 34.90 ± 16.60 |
| General Hough [48] | 31.28 ± 0.00 | 64.49 ± 0.00 |
| MIPAV [49] | 25.69 ± 0.00 | 59.91 ± 0.00 |
| UMDA+SA [11] | 30.45 ± 12.94 | 105.80 ± 27.54 |
| Proposed method | 7.40 ± 5.34 | 27.96 ± 17.66 |
| Method | Pre | Rec | bACC |
|---|---|---|---|
| General Hough [48] | 0.0454 | 0.0338 | 0.5024 |
| MIPAV [49] | 0.1749 | 0.1785 | 0.5405 |
| UMDA+SA [11] | 0.2236 | 0.2426 | 0.6150 |
| Proposed method | 0.4517 | 0.4255 | 0.7067 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alvarado-Carrillo, D.E.; Cruz-Aceves, I.; Hernández-González, M.A.; López-Montero, L.M. Robust Detection and Modeling of the Major Temporal Arcade in Retinal Fundus Images. Mathematics 2022, 10, 1334. https://doi.org/10.3390/math10081334
Alvarado-Carrillo DE, Cruz-Aceves I, Hernández-González MA, López-Montero LM. Robust Detection and Modeling of the Major Temporal Arcade in Retinal Fundus Images. Mathematics. 2022; 10(8):1334. https://doi.org/10.3390/math10081334
Chicago/Turabian StyleAlvarado-Carrillo, Dora Elisa, Iván Cruz-Aceves, Martha Alicia Hernández-González, and Luis Miguel López-Montero. 2022. "Robust Detection and Modeling of the Major Temporal Arcade in Retinal Fundus Images" Mathematics 10, no. 8: 1334. https://doi.org/10.3390/math10081334