
An End-to-End Formula Recognition Method Integrated Attention Mechanism


Abstract
:1. Introduction
2. Related Work
2.1. Traditional Methods
2.2. Neural Methods for Formula Recognition
3. Methods
3.1. Encoder
3.2. Decoder
3.3. Loss Function
4. Experiments
4.1. Preprocessed Data
| Algorithm 1 LaTeX sequence normalization |
|
4.2. Settings
4.3. Measurements
| Algorithm 2 Calculate the maximum edit distance |
|
5. Discussion and Implications
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Suzuki, M.; Tamari, F.; Fukuda, R.; Uchida, S.; Kanahori, T. Infty: An integrated ocr system for mathematical documents. In Proceedings of the 2003 ACM Symposium on Document Engineering, Grenoble, France, 20–22 November 2003; pp. 95–104. [Google Scholar]
- Ion, P.; Miner, R.; Buswell, S.; Devitt, A. Mathematical Markup Language (MathML) 1.0 Specification; World Wide Web Consortium (W3C): Cambridge, MA, USA, 1998. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep structured output learning for unconstrained text recognition. arXiv 2014, arXiv:1412.5903. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Cheng, H.; Yu, R.; Tang, Y.; Fang, Y.; Cheng, T. Text Classification Model Enhanced by Unlabeled Data for LaTeX Formula. Appl. Sci. 2021, 11, 10536. [Google Scholar] [CrossRef]
- Zhong, W.; Yang, J.H.; Lin, J. Evaluating Token-Level and Passage-Level Dense Retrieval Models for Math Information Retrieval. arXiv 2022, arXiv:2203.11163. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Luo, C.; Jin, L.; Sun, Z. Moran: A multi-object rectified attention network for scene text recognition. Pattern Recognit. 2019, 90, 109–118. [Google Scholar] [CrossRef]
- Anderson, R.H. Syntax-directed recognition of hand-printed two-dimensional mathematics. In Symposium on Interactive Systems for Experimental Applied Mathematics; Association for Computing Machinery Inc. Symposium: New York, NY, USA, 1967; pp. 436–459. [Google Scholar]
- Deng, Y.; Kanervisto, A.; Rush, A.M. What you get is what you see: A visual markup decompiler. arXiv 2016, arXiv:1609.04938. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Okamoto, M.; Imai, H.; Takagi, K. Performance evaluation of a robust method for mathematical expression recognition. In Proceedings of the Sixth International Conference on Document Analysis and Recognition, Seattle, WA, USA, 10–13 September 2001; pp. 121–128. [Google Scholar]
- Berman, B.P.; Fateman, R.J. Optical character recognition for typeset mathematics. In Proceedings of the International Symposium on Symbolic and Algebraic Computation, Oxford, UK, 20–22 July 1994; pp. 348–353. [Google Scholar]
- Álvaro, F.; Sánchez, J.A. Comparing several techniques for offline recognition of printed mathematical symbols. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 1953–1956. [Google Scholar]
- Zanibbi, R.; Blostein, D.; Cordy, J.R. Recognizing mathematical expressions using tree transformation. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1455–1467. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.J.; Wang, J.S. Design of a mathematical expression recognition system. In Proceedings of the 3rd International Conference on Document analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 2, p. 1084. [Google Scholar]
- Twaakyondo, H.M.; Okamoto, M. Structure analysis and recognition of mathematical expressions. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 430–437. [Google Scholar]
- Suzuki, M.; Terada, Y.; Kanahori, T.; Yamaguchi, K. New Tools to Convert PDF Math Contents into Accessible e-Books Efficiently. In Assistive Technology; IOS Press: Washington, DC, USA, 2015; pp. 1060–1064. [Google Scholar]
- Gao, L.; Yi, X.; Liao, Y.; Jiang, Z.; Yan, Z.; Tang, Z. A deep learning-based formula detection method for PDF documents. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 553–558. [Google Scholar]
- Wu, J.W.; Yin, F.; Zhang, Y.M.; Zhang, X.Y.; Liu, C.L. Image-to-markup generation via paired adversarial learning. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2018; pp. 18–34. [Google Scholar]
- Deng, Y.; Kanervisto, A.; Ling, J.; Rush, A.M. Image-to-markup generation with coarse-to-fine attention. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 980–989. [Google Scholar]
- Zhang, J.; Du, J.; Dai, L. A gru-based encoder-decoder approach with attention for online handwritten mathematical expression recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; Volume 1, pp. 902–907. [Google Scholar]
- Zhang, J.; Du, J.; Dai, L. Track, attend, and parse (tap): An end-to-end framework for online handwritten mathematical expression recognition. IEEE Trans. Multimed. 2018, 21, 221–233. [Google Scholar] [CrossRef]
- Wang, J.; Sun, Y.; Wang, S. Image to latex with densenet encoder and joint attention. Procedia Comput. Sci. 2019, 147, 374–380. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–27 July 2017; pp. 4700–4708. [Google Scholar]
- Zhang, W.; Bai, Z.; Zhu, Y. An improved approach based on CNN-RNNs for mathematical expression recognition. In Proceedings of the 2019 4th International Conference on Multimedia Systems and Signal Processing, Guangzhou, China, 10–12 May 2019; pp. 57–61. [Google Scholar]
- Peng, S.; Yuan, K.; Gao, L.; Tang, Z. Mathbert: A pre-trained model for mathematical formula understanding. arXiv 2021, arXiv:2105.00377. [Google Scholar]
- Wu, J.W.; Yin, F.; Zhang, Y.M.; Zhang, X.Y.; Liu, C.L. Graph-to-graph: Towards accurate and interpretable online handwritten mathematical expression recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2925–2933. [Google Scholar]
- Wang, Z.; Liu, J.C. Translating math formula images to LaTeX sequences using deep neural networks with sequence-level training. Int. J. Doc. Anal. Recognit. 2021, 24, 63–75. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Rubinstein, R. The cross-entropy method for combinatorial and continuous optimization. Methodol. Comput. Appl. Probab. 1999, 1, 127–190. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Chowdhury, S.D.; Bhattacharya, U.; Parui, S.K. Online handwriting recognition using Levenshtein distance metric. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 79–83. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Formula Type | Formula Picture | LaTeX Expression |
|---|---|---|
| Matrix (square brackets) |  | |
| Matrix (parentheses) |  | |
| Angle bracket formula | 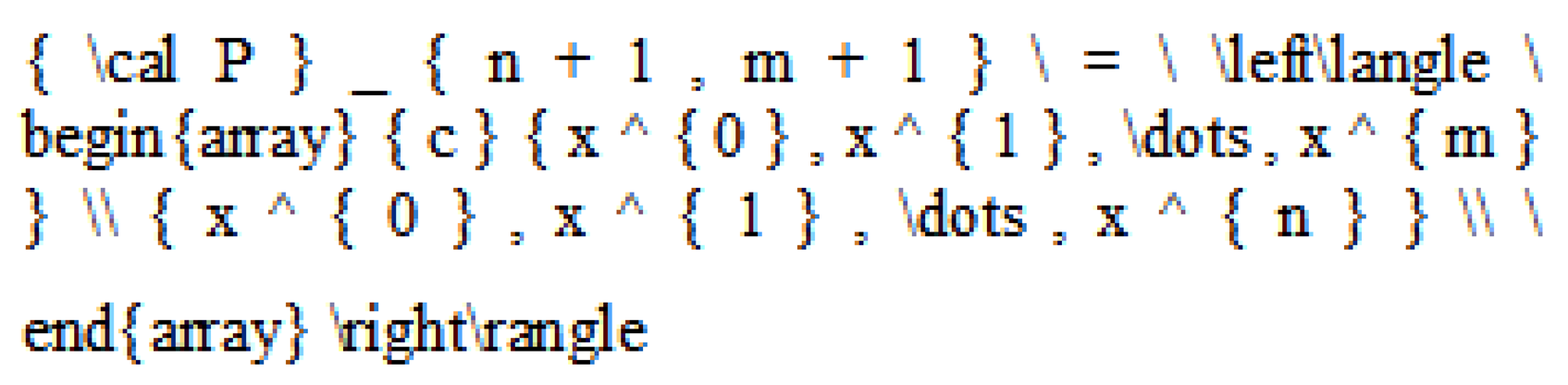 | |
| Curly bracket formula |  | |
| Piecewise Function |  | |
| Multi-line Expression |  |
| Ling | Model | BLEU | MED | Exact Match |
|---|---|---|---|---|
| Single Line | INFTY | 56.9 | 56.70 | 56.8 |
| WYGIWYS | 58.71 | 63.6 | 61.0 | |
| DoubleAttention | 59.5 | 67.2 | 63.1 | |
| DenseNet | 71.34 | 59.6 | - | |
| MI2LS | 73.53 | 78.33 | 63.8 | |
| MathBERT | 86.0 | 81.61 | 73.77 | |
| Our Model | 90.02 | 90.34 | 70.24 | |
| Multi-Line | INFTY | 45.45 | 50.32 | 15.70 |
| WYGIWYS | 53.77 | 57.51 | 45.31 | |
| DoubleAttention | 58.17 | 54.32 | 32.12 | |
| DenseNet | 61.41 | 63.34 | - | |
| MI2LS | 67.15 | 65.60 | 70.57 | |
| MathBERT | 69.32 | 71.37 | 74.93 | |
| Our Model | 71.45 | 73.55 | 65.27 |
| Ling | Model | BLEU | MED | Exact Match |
|---|---|---|---|---|
| Single Line | INFTY | 36.41 | 37.50 | 27.25 |
| WYGIWYS | 35.19 | 40.80 | 32.84 | |
| DoubleAttention | 40.40 | 43.94 | 37.51 | |
| DenseNet | 39.66 | 42.51 | - | |
| MI2LS | 43.00 | 46.78 | 32.09 | |
| MathBERT | 50.41 | 47.94 | 53.6 | |
| G2G | 54.46 | 52.05 | 55.28 | |
| Our Model | 54.29 | 57.80 | 60.20 | |
| Multi-Line | INFTY | 46.15 | 32.0 | 15.27 |
| WYGIWYS | 47.46 | 42.45 | 45.46 | |
| DoubleAttention | 49.49 | 51.3 | 47.68 | |
| DenseNet | 52.13 | 55.72 | - | |
| MI2LS | 53.65 | 52.21 | 48.3 | |
| MathBERT | 54.65 | 56.71 | 57.22 | |
| G2G | 54.90 | 57.81 | 55.28 | |
| Our Model | 55.39 | 58.20 | 60.22 |
| Model | BLEU | MED | Exact Match |
|---|---|---|---|
| INFTY | 66.65 | 53.82 | 15.60 |
| WYGIWYS | 87.73 | 87.60 | 77.46 |
| DoubleAttention | 88.42 | 88.57 | 79.81 |
| DenseNet | 88.25 | 91.57 | - |
| MI2LS | 90.28 | 91.90 | 82.33 |
| MathBERT | 90.45 | 90.11 | 87.52 |
| Our Model | 92.11 | 90.0 | 60.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, M.; Cai, M.; Li, G.; Li, M. An End-to-End Formula Recognition Method Integrated Attention Mechanism. Mathematics 2023, 11, 177. https://doi.org/10.3390/math11010177
Zhou M, Cai M, Li G, Li M. An End-to-End Formula Recognition Method Integrated Attention Mechanism. Mathematics. 2023; 11(1):177. https://doi.org/10.3390/math11010177
Chicago/Turabian StyleZhou, Mingle, Ming Cai, Gang Li, and Min Li. 2023. "An End-to-End Formula Recognition Method Integrated Attention Mechanism" Mathematics 11, no. 1: 177. https://doi.org/10.3390/math11010177