
Representing Hierarchical Structured Data Using Cone Embedding

Abstract
:1. Introduction
2. Methods
2.1. Problem Settings
2.2. Graph Embedding in Non-Euclidean Spaces
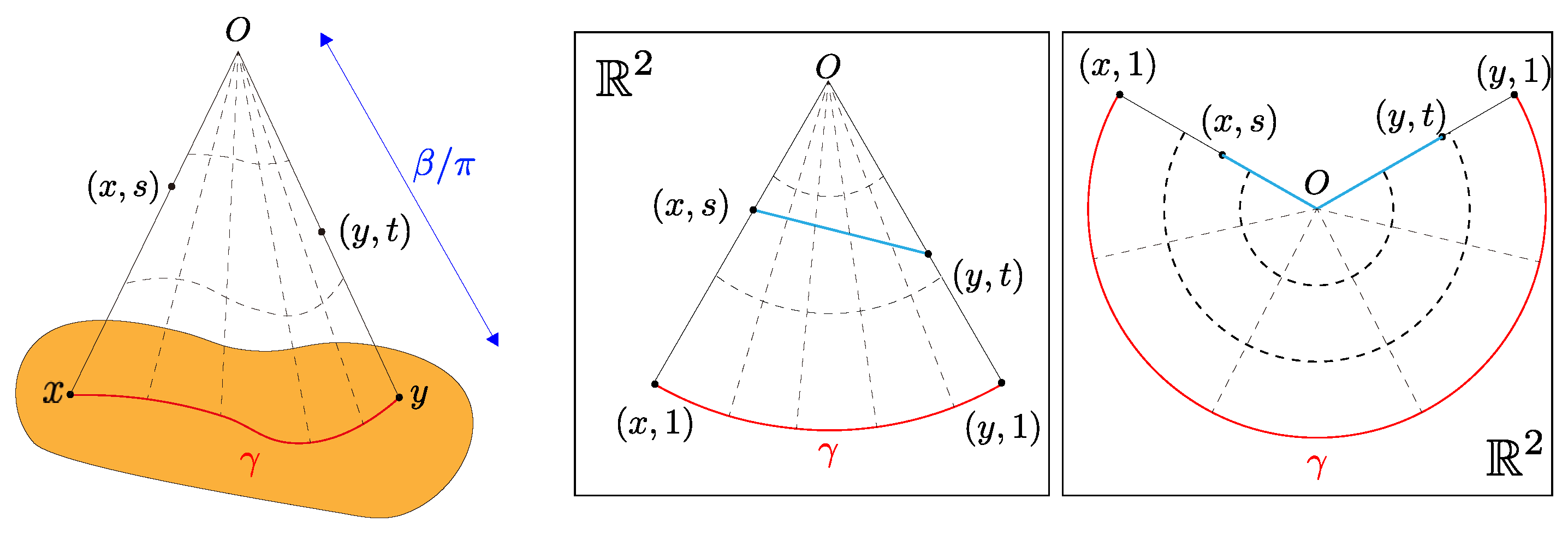
2.3. The Metric Cone
| Algorithm 1 Learn the cone embedding {} |
| Input:
graph , cone’s hyperparameter , learning rate , and the pre-trained embedding in original space Z Output: the cone embedding {} 1: calculate the distance matrix 2: minimize the softmax loss function: (calculate efficiently by referencing the distance matrix D) |
2.4. Score Function of Hierarchy
2.5. Using Pre-Trained Model for Computational Efficiency and Adaptivity for Adding Hierarchical Information
2.6. Comparison with Hierarchical Clustering
3. Theory
3.1. Identifiability of the Heights in Cone Embedding
- (b)
- Let and assume and take “general” positions and heights, respectively. Then, the heights are identifiable uniquely.
- (c)
- If for all , then the heights are identifiable uniquely.
3.2. Variable Curvature
4. Experiments
- Prediction of edge direction for artificially directed graphs;
- Estimation of the hierarchical score by humans for WordNet.
4.1. Prediction of Edge Direction for Directed Graphs
4.1.1. Settings
- Graphs generated by a growing random network model called the Barabási–Albert preferential attachment [31] with , where m is the number of edges to attach from a new node to existing nodes;
- Complete k-ary tree;
- Concatenated tree of two complete k-ary sub-trees.
4.1.2. Results
4.2. Embedding Taxonomies
- Fix one node and calculate the distance to all other nodes.
- Consider the node adjacent to the fixed node as the correct data, and calculate the average precision for this correct data using the distance as the confidence score.
- Perform the above two operations on all the nodes and take the average.
5. Discussion and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Derivation of the Metric Tensor of a Metric Cone
Appendix B. Derivation of the Ricci and the Scalar Curvatures of a Metric Cone
Appendix C. Identifiability of the Heights in the Cone Embedding
- (a)
- Assume are not all aligned in a geodesic. Given and , the number of possible values of is at most four.
- (b)
- Let and assume and are in a “general” position. Here “general” position means that, besides the assumption in (a), given any four distinct points and corresponding heights , can still take infinitely many values. Then are determined uniquely by and .
- (c)
- If for all , then are determined uniquely by and .


References
- Zhang, J.; Ackerman, M.S.; Adamic, L. Expertise networks in online communities: Structure and algorithms. In Proceedings of the 16th international Conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 221–230. [Google Scholar]
- De Choudhury, M.; Counts, S.; Horvitz, E. Social media as a measurement tool of depression in populations. In Proceedings of the 5th Annual ACM Web Science Conference, Paris, France, 2–4 May 2013; pp. 47–56. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Technical Report; Stanford InfoLab, Stanford University: Stanford, CA, USA, 1999. [Google Scholar]
- Barabasi, A.L.; Oltvai, Z.N. Network biology: Understanding the cell’s functional organization. Nat. Rev. Genet. 2004, 5, 101–113. [Google Scholar] [CrossRef] [PubMed]
- Yahya, M.; Berberich, K.; Elbassuoni, S.; Weikum, G. Robust question answering over the web of linked data. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 1107–1116. [Google Scholar]
- Hoffart, J.; Milchevski, D.; Weikum, G. STICS: Searching with strings, things, and cats. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, Queensland, Australia, 6–11 July 2014; pp. 1247–1248. [Google Scholar]
- Klimovskaia, A.; Lopez-Paz, D.; Bottou, L.; Nickel, M. Poincaré maps for analyzing complex hierarchies in single-cell data. Nat. Commun. 2020, 11, 2966. [Google Scholar] [CrossRef] [PubMed]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Ribeiro, L.F.; Saverese, P.H.; Figueiredo, D.R. struc2vec: Learning node representations from structural identity. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 385–394. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1025–1035. [Google Scholar]
- Goyal, P.; Ferrara, E. Graph embedding techniques, applications, and performance: A survey. Knowl. Based Syst. 2018, 151, 78–94. [Google Scholar] [CrossRef]
- Grover, A.; Leskovec, J. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 855–864. [Google Scholar]
- Cao, S.; Lu, W.; Xu, Q. Grarep: Learning graph representations with global structural information. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, VIC, Australia, 19–23 October 2015; pp. 891–900. [Google Scholar]
- Tang, J.; Qu, M.; Wang, M.; Zhang, M.; Yan, J.; Mei, Q. Line: Large-scale information network embedding. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 1067–1077. [Google Scholar]
- Sun, Z.; Chen, M.; Hu, W.; Wang, C.; Dai, J.; Zhang, W. Knowledge Association with Hyperbolic Knowledge Graph Embeddings. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Online, 16–20 November 2020; pp. 5704–5716. [Google Scholar] [CrossRef]
- Rezaabad, A.L.; Kalantari, R.; Vishwanath, S.; Zhou, M.; Tamir, J. Hyperbolic graph embedding with enhanced semi-implicit variational inference. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Virtual, 13–15 April 2021; pp. 3439–3447. [Google Scholar]
- Nickel, M.; Kiela, D. Poincaré embeddings for learning hierarchical representations. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6338–6347. [Google Scholar]
- Zhang, Z.; Cai, J.; Zhang, Y.; Wang, J. Learning hierarchy-aware knowledge graph embeddings for link prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3065–3072. [Google Scholar]
- Chami, I.; Wolf, A.; Juan, D.C.; Sala, F.; Ravi, S.; Ré, C. Low-Dimensional Hyperbolic Knowledge Graph Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6901–6914. [Google Scholar] [CrossRef]
- Dhingra, B.; Shallue, C.; Norouzi, M.; Dai, A.; Dahl, G. Embedding Text in Hyperbolic Spaces. In Proceedings of the Twelfth Workshop on Graph-Based Methods for Natural Language Processing (TextGraphs-12), Association for Computational Linguistics, New Orleans, LA, USA, 6 June 2018; pp. 59–69. [Google Scholar] [CrossRef]
- Nickel, M.; Kiela, D. Learning Continuous Hierarchies in the Lorentz Model of Hyperbolic Geometry. In Proceedings of the Machine Learning Research, PMLR, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 3779–3788. [Google Scholar]
- Ganea, O.; Becigneul, G.; Hofmann, T. Hyperbolic Entailment Cones for Learning Hierarchical Embeddings. In Proceedings of the Machine Learning Research, PMLR, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 1646–1655. [Google Scholar]
- Sala, F.; De Sa, C.; Gu, A.; Ré, C. Representation tradeoffs for hyperbolic embeddings. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4460–4469. [Google Scholar]
- Kobayashi, K.; Wynn, H.P. Empirical geodesic graphs and CAT (k) metrics for data analysis. Stat. Comput. 2020, 30, 1–18. [Google Scholar] [CrossRef]
- Wilson, R.C.; Hancock, E.R.; Pekalska, E.; Duin, R.P. Spherical and Hyperbolic Embeddings of Data. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2255–2269. [Google Scholar] [CrossRef] [PubMed]
- Chami, I.; Ying, Z.; Ré, C.; Leskovec, J. Hyperbolic Graph Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Sturm, K.T. Probability measures on metric spaces of nonpositive curvature. In Proceedings of the Heat Kernels and Analysis on Manifolds, Graphs, and Metric Spaces: Lecture Notes A Quart, Program Heat Kernels, Random Walks, Analysis Manifolds Graphs, Emile Borel Cent, Henri Poincaré Institute, Paris, France, 16 April–13 July 2002; Volume 338, p. 357. Available online: https://bookstore.ams.org/conm-338 (accessed on 24 February 2023).
- Deza, M.M.; Deza, E. Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–583. [Google Scholar]
- Loustau, B. Hyperbolic geometry. arXiv 2020, arXiv:2003.11180. [Google Scholar]
- Sarkar, R. Low distortion delaunay embedding of trees in hyperbolic plane. In Proceedings of the International Symposium on Graph Drawing, Eindhoven, The Netherlands, 21–23 September 2011; pp. 355–366. [Google Scholar]
- Barabasi, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed]
- Janson, S. Riemannian geometry: Some examples, including map projections. Notes. 2015. Available online: http://www2.math.uu.se/~svante/papers/sjN15.pdf (accessed on 24 February 2023).
- Cox, D.; Little, J.; OShea, D. Ideals, Varieties, and Algorithms: An Introduction to Computational Algebraic Geometry and Commutative Algebra; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Barabási–Albert | Complete k-Ary-Tree | Concatenated k-Ary Trees | ||
|---|---|---|---|---|---|
| (Nodes: 100) | k = 3 (121) | k = 5 (781) | k = 3 (81) | k = 5 (313) | |
| Cone | 0.936 (sd: 0.005) | 0.787 (0.049) | 0.799 (0.037) | 0.783 (0.045) | 0.744 (0.056) |
| Euclidean | 0.181 (0.004) | 0.074 (0.088) | 0.127 (0.020) | 0.190 (0.136) | 0.155 (0.031) |
| Poincaré | 0.957 (0.012) | 0.935 (0.015) | 0.351 (0.022) | 0.880 (0.060) | 0.606 (0.043) |
| Model | Evaluation Metric | Dimensions | |||
|---|---|---|---|---|---|
| 10 | 20 | 50 | 100 | ||
| Euclidean | MR | 1681.18 | 583.75 | 233.7 | 162.43 |
| MAP | 0.07 | 0.12 | 0.25 | 0.37 | |
| corr | 0.25 | 0.34 | 0.38 | 0.39 | |
| comp. time | 976.48 | 984.72 | 2169.1 | 2095.7 | |
| Poincaré | MR | 1306.22 | 1183.29 | 1112.42 | 1096.08 |
| MAP | 0.09 | 0.13 | 0.14 | 0.16 | |
| corr | 0.07 | 0.08 | 0.09 | 0.09 | |
| comp. time | 2822.99 | 1807.73 | 3954 | 2241.7 | |
| Cone | MR | 426.75 | 675.09 | 777.3 | 910.51 |
| () | MAP | 0.10 | 0.08 | 0.07 | 0.06 |
| corr | 0.39 | 0.40 | 0.40 | 0.40 | |
| comp. time | 177.94 | 174.67 | 168.33 | 187.83 | |
| Cone | MR | 688.85 | 143.23 | 74.39 | 51.32 |
| () | MAP | 0.07 | 0.23 | 0.50 | 0.57 |
| corr | 0.35 | 0.35 | 0.37 | 0.38 | |
| comp. time | 176.04 | 171.21 | 168.7 | 189.89 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Takehara, D.; Kobayashi, K. Representing Hierarchical Structured Data Using Cone Embedding. Mathematics 2023, 11, 2294. https://doi.org/10.3390/math11102294
Takehara D, Kobayashi K. Representing Hierarchical Structured Data Using Cone Embedding. Mathematics. 2023; 11(10):2294. https://doi.org/10.3390/math11102294
Chicago/Turabian StyleTakehara, Daisuke, and Kei Kobayashi. 2023. "Representing Hierarchical Structured Data Using Cone Embedding" Mathematics 11, no. 10: 2294. https://doi.org/10.3390/math11102294