1. Introduction
The pervasive presence of deep learning models in contemporary artificial intelligence research and applications has given rise to an urgent need for a thorough understanding of the underlying structures and properties of these models [
1,
2,
3,
4,
5]. One of the most prominent and yet enigmatic aspects of deep learning models is the geometry of feature spaces [
6], which constitutes the foundation upon which various learning algorithms and optimization techniques are established. In this scholarly work, a holistic perspective on the geometry of feature space in deep learning models hopes to be offered by meticulously examining the interconnections between feature spaces and a plethora of factors that impact their geometrical properties, such as activation functions, normalization methods, and model architectures [
6,
7,
8,
9,
10,
11,
12,
13].
The exploration begins with a review of the background in deep learning, encompassing a diverse array of models such as feedforward neural networks (FNNs), convolutional neural networks (CNNs), and transformer models, as well as an investigation of activation functions and normalization methods. Subsequently, an in-depth analysis of the geometry of feature space is undertaken, scrutinizing the relationships between feature space and activation functions, and probing the interplay between feature space and normalization methods. Throughout the investigation, various aspects of isotropy, connectivity, and the combination of ReLU-inspired activations with normalization methods are investigated.
After a thorough examination of recent studies that have informed the understanding of feature space geometry, manifold structures, curvature, wide neural networks and Gaussian processes, critical points and loss landscapes, singular value spectra, and adversarial robustness, among other topics, are discussed. The state of the art in transfer learning and disentangled representations in feature space is also evaluated, emphasizing the advances and challenges in these areas.
As a deeper dive into the topic of deep learning is taken, the limitations in current review papers that concentrate on particular aspects or applications within the field [
14,
15,
16,
17,
18] become apparent, while previous studies have made notable progress in shedding light on various aspects of deep learning models, a gap persists in providing a truly comprehensive and integrative understanding of the geometry of feature spaces. In particular, the extant literature often concentrates on discrete aspects, such as manifold structures, curvature, or adversarial robustness, without adequately situating these elements within the broader framework of deep learning models. Additionally, the rapidly evolving nature of deep learning research calls for a current synthesis that encompasses the most recent findings and methodological advancements.
To address these gaps, several innovative contributions to the field are offered in the current work. First, a cogent and unified framework that cohesively integrates the diverse aspects of feature space geometry in deep learning is introduced, promoting a comprehensive understanding of the subject. Second, by leveraging a collection of state-of-the-art research, a timely overview of the most recent breakthroughs and trends in the field is delivered, making it a valuable resource for both experienced professionals and newcomers alike. Lastly, the exploration of the challenges and future research directions in feature space geometry serves to stimulate and direct further investigation, thus paving the way for groundbreaking advancements in this intricate and compelling area.
A set of inclusion and exclusion criteria was established to ensure a focused and comprehensive mathematical examination of the geometry of feature space in deep learning. Studies were included if they primarily discussed the mathematical properties of feature spaces in deep learning models, with an emphasis on their geometrical aspects. In contrast, studies were excluded if they primarily focused on applications or implementation aspects without a significant contribution to the understanding of feature space geometry. This selection process allowed for concentration of efforts on providing a thorough and up-to-date review of the most relevant research in this domain.
The research questions examined in this paper are centered on providing a comprehensive mathematical understanding of the geometry of feature spaces in deep learning models. The relationships between feature spaces and activation functions, as well as the synergistic integration of ReLU-inspired activation functions and normalization techniques, are explored. Furthermore, how these interactions can lead to mutual benefits and potential improvements in model performance is investigated. The review also covers a wide range of topics in feature space geometry, including manifold structures, curvature, critical points, and adversarial robustness, as well as transfer learning and disentangled representations in feature space.
A series of distinct yet interconnected contributions aimed at providing a comprehensive understanding of the geometry of feature spaces in deep learning models is presented. Specifically, (1) a novel perspective on the relationships between feature space and activation functions in deep learning is offered, providing the intricate interplay between these key components; (2) the synergistic integration of ReLU-inspired activation functions and normalization techniques is explored, revealing the mutual benefits and potential improvements in model performance; (3) an extensive review of recent studies in feature space geometry in deep learning is provided, covering a wide range of topics such as manifold structures, curvature, critical points, and adversarial robustness; (4) the current state of transfer learning and disentangled representations in feature space is discussed, highlighting both achievements and challenges in these areas; and (5) the challenges and future research directions in feature space geometry are identified and outlined, including overparameterized models, unsupervised and semi-supervised learning, interpretable geometry, topological analysis, and multimodal and multi-task learning. Collectively, these contributions serve to advance our understanding of feature space geometry in deep learning, providing a solid foundation for further exploration and innovation in this rapidly evolving domain.
The exploration of feature space geometry in deep learning is organized into several sections to provide a structured and coherent overview.
Section 2 offers essential background information on deep learning architectures, activation functions, and normalization methods.
Section 3 provides perspectives on the relationships between feature spaces and various factors that impact their geometrical properties.
Section 4 delves into the recent studies that have shaped our understanding of feature space geometry, examining a wide range of topics and approaches.
Section 5 discusses the challenges and future research directions in feature space geometry, outlining the areas where progress is needed to advance our knowledge. Finally, in
Section 6, the conclusions are presented and the implications of the findings for the broader field of deep learning are reflected upon.
2. Background
2.1. Deep Learning Architectures
Deep learning architectures encompass a diverse array of artificial neural networks specifically engineered to unravel and interpret hierarchical structures within input data. These intricate models are composed of a multitude of interconnected layers, each diligently processing and transforming input data into increasingly abstract representations. In the following sections, the fundamental types of deep learning architectures and their mathematical underpinnings are explored, with a focus on feedforward neural networks, CNNs, and cutting-edge transformer models.
2.1.1. Feedforward Neural Networks (FNNs)
Feedforward neural networks (FNNs) represent the most elementary and foundational type of deep learning models [
19]. They are comprised of input, hidden, and output layers that work in tandem to receive high-dimensional data, process it, and ultimately generate the final prediction. The layers are interconnected through synaptic weights, and the neurons within each layer employ activation functions to incorporate nonlinearity into the model. Consider a compact subset
that characterizes the latent space of a sample space with high dimensionality, where
D denotes the hypothetical dimension of the latent space. The input layer can be expressed as a vector
, with
symbolizing the mapping between the latent space and the sample space. The output of each layer can be formulated as follows:
where
signifies the output of the
l-th layer,
denotes the weight matrix interconnecting layers
and
l,
represents the bias vector for layer
l,
corresponds to the number of neurons in layer
l, and
is the element-wise activation function. Widely adopted activation functions encompass the rectified linear unit (ReLU)
, sigmoid
, and hyperbolic tangent
.
For the input layer, holds, while the ultimate output layer L furnishes the prediction, denoted by . The FNN maps the high-dimensional data from the finite set to the output space via a sequence of transformations, encoding the data’s inherent structure in the hidden layers’ activations. This chain of transformations empowers the FNN to discern intricate patterns and associations within the high-dimensional data embedded in the compact set of the latent space.
The transformations applied to the input data as it advances through the network can be meticulously examined to comprehend how the hidden layers of FNNs accurately emulate the latent space. Given
within the latent space and
, the transformations transpire through the weight matrices
and activation functions
, as explicated in Equation (
1).
The transformations executed by the hidden layers can be perceived as a succession of mappings
, where
corresponds to the quantity of neurons in layer
l. The mapping function for layer
l is articulated by:
The synthesis of these mappings constitutes the comprehensive transformation employed by the FNN. For a network encompassing
L layers, the ultimate mapping
is delineated by:
The approximation of
can be interpreted as the FNN’s capacity to acquire a mapping
that renders the data analogous to
, such that the distances between points in the input space are manifested in the hidden layer activations with the approximation of the latent space. This concept can be formalized via the notion of a Lipschitz continuous mapping, where for a specific constant
:
When an FNN is proficient in learning a Lipschitz continuous mapping
that fulfills the inequality stipulated in Equation (
4), it can efficaciously approximate the latent space by conserving the data structure within the hidden layers’ activations. This endows the FNN with the ability to discern intricate patterns and associations within the high-dimensional data, ultimately bolstering its generalization capabilities.
2.1.2. Convolutional Neural Networks (CNNs)
Convolutional neural networks (CNNs) represent a distinct class of deep learning models, predominantly tailored for processing grid-structured data, such as images. CNNs utilize convolutional layers that perform convolution operations on input data, enabling the model to discern local patterns and spatial hierarchies [
20]. A convolution operation can be expressed as:
where
signifies the output of the
l-th convolutional layer at position
,
denotes the weights of the convolutional kernel at position
, and the sum encompasses the spatial extent of the kernel. CNNs frequently integrate pooling layers, which minimize the spatial dimensions of the feature maps, and fully connected layers, analogous to those present in FNNs.
To obtain an exhaustive understanding of how CNNs’ hidden layers efficaciously reconstruct the compact subspace of the latent space containing spatial information, a thorough examination of the unique structure and operations of CNNs is required, concentrating particularly on the convolutional and pooling layers. These specialized layers are explicitly devised to capture local patterns and spatial hierarchies in grid-like data, such as images, more efficiently than FNNs. By leveraging these intrinsic advantages, CNNs can adeptly extract and represent the most pertinent and informative features of the input data, facilitating superior pattern recognition and classification accuracy.
Suppose that high-dimensional data is possessed, where the data exhibits robust spatial correlations by the properties of
. The input layer of a CNN can be represented as a tensor
, and the output of each convolutional layer can be expressed as:
where
represents the output of the
l-th convolutional layer at position
,
signifies the weights of the convolutional kernel at position
, and the sum spans the spatial extent of the kernel.
In conjunction with convolutional layers, CNNs frequently integrate pooling layers that reduce the spatial dimensions of feature maps while retaining the most prominent spatial information. A pooling layer can be portrayed as:
where
denotes the output of the
l-th pooling layer at position
,
M and
N represent the dimensions of the pooling window, and
constitutes the pooling operation, such as max or average pooling.
The synergistic effect of convolutional and pooling layers in a CNN enables the more efficient recovery of the compact subspace of the latent space of spatial information by learning a series of mappings
, where
signifies the number of features in layer
l. The comprehensive transformation applied by the CNN can be expressed as:
2.1.3. Transformer Models and Attention Mechanism
Transformer models have revolutionized natural language processing and are now widely employed for various sequential data tasks. These models rely on self-attention mechanisms to capture long-range dependencies in input data, rather than using recurrent or convolutional architectures. The fundamental building block of a transformer model is the scaled dot-product self-attention mechanism, which can be expressed as follows:
where
,
, and
are the query, key, and value matrices, respectively, and
is the dimension of the key vectors. These matrices are derived from the input embeddings through linear transformations using learnable weight matrices
,
, and
:
Transformer models employ multi-head attention to learn different types of dependencies in the input data. The output of each attention head is concatenated and linearly transformed to produce the final output:
where
, and
is a learnable weight matrix. The transformer architecture consists of multiple layers of multi-head attention, followed by position-wise feedforward layers and layer normalization.
2.2. Activation Functions in Deep Learning
The choice of activation function in a deep learning model has a significant impact on the geometry of the feature space. The relationship between the choice of activation function and the geometry of the feature space is discussed in this section [
21].
The activation function is typically chosen to introduce nonlinearity into the model. Common choices include the rectified linear unit (ReLU), sigmoid, and hyperbolic tangent (tanh) functions. The choice of activation function affects the shape of the decision boundary and the geometry of the feature space.
For example, the ReLU activation function is defined as:
The ReLU function introduces sparsity into the model, as it sets negative values to zero. This sparsity can lead to a fragmented and disconnected feature space, as some regions of the input space may be completely separated from others.
Conversely, the sigmoid activation function is defined as:
The sigmoid function introduces smoothness into the model, as it maps any input to a value between 0 and 1. This can lead to a more connected feature space, as points that are nearby in the input space are likely to have similar feature representations.
The choice of activation function can also affect the curvature of the feature space. For example, the hyperbolic tangent (tanh) function is defined as:
The tanh function maps any input to a value between −1 and 1, which can lead to a feature space with negative curvature. This negative curvature can be advantageous in some applications, as it allows the model to learn more complex decision boundaries.
The Gaussian Error Linear Unit (GELU) activation function [
22] is a newer activation function that has shown improved performance over the commonly used ReLU function. The GELU function is defined as:
where erf is the error function. GELU combines the smoothness of sigmoid and tanh functions with the sparsity of ReLU, leading to a feature space that can balance the trade-off between connectivity and fragmentation, thereby improving the model’s ability to learn complex patterns and generalize to unseen data.
The Exponential Linear Unit (ELU) activation function [
23] is an alternative to the ReLU function. The ELU function is defined as:
where
is a hyperparameter that controls the slope of the negative part of the function. Like the GELU function, the ELU function aims to be more robust to the vanishing gradient problem compared to the ReLU function. One interesting property of the ELU function is that it has a smooth gradient, unlike the ReLU function, which has a discontinuous gradient at zero. This smoothness can make the ELU function easier to optimize using gradient-based methods.
The Scaled Exponential Linear Unit with Squish (SWISH) activation function [
24] is a more recent alternative to the ReLU function, showing promise in achieving state-of-the-art performance on several benchmarks. The SWISH function is defined as:
where
is the sigmoid function and
is a trainable parameter. The SWISH function has a similar shape to the ReLU function but with a smooth gradient. The SWISH function possesses a gating mechanism that dynamically adjusts the slope of the function based on the input, making it more adaptable to different types of input data.
The activation functions are summarized in
Table 1. The choice of activation function can also affect the curvature of the feature space. For example, the tanh function can lead to a feature space with negative curvature, which can be advantageous in some applications, as it allows the model to learn more complex decision boundaries. The GELU and ELU activation functions address the limitations of the ReLU function, such as the vanishing gradient problem and the discontinuous gradient at zero. The GELU function presents a smooth approximation to the ReLU function and can be viewed as a form of soft attention mechanism. The ELU function, with its smooth gradient, can be easier to optimize using gradient-based methods compared to the ReLU function.
2.3. Normalization Methods in Deep Learning
Normalization is a prevalent technique in deep learning to enhance the performance of models. Normalization methods aim to rescale the activations in the feature space so that they have zero mean and unit variance. The relationship between the choice of normalization method and the geometry of the feature space is discussed in this section.
Let be a deep neural network with m layers and activation function . The output of the i-th layer is denoted by , where is the dimensionality of the feature space at layer i.
Batch normalization (BN) [
25] is a widely used normalization method in deep learning. It aims to rescale the activations in the feature space so that they have zero mean and unit variance with respect to the mini-batch of input data. BN is defined as:
where
and
are the mean and variance of the activations in the mini-batch,
is a small constant to prevent division by zero, and
and
are learnable parameters controlling the scaling and shifting of the activations.
Layer normalization (LN) [
26] is another common normalization method. It aims to rescale the activations in the feature space so that they have zero mean and unit variance with respect to the entire layer of input data. LN is defined as:
where
and
are the mean and variance of the activations in the entire layer, and
and
are learnable parameters controlling the scaling and shifting of the activations.
Group normalization (GN) [
27] is another normalization technique that has been shown to improve the performance of deep learning models. GN is similar to BN, but instead of normalizing the activations with respect to the mini-batch, it normalizes the activations with respect to groups of channels. In GN, the output of the
i-th layer is denoted by
, where
,
,
, and
are the depth, number of channels, height, and width of the feature map at layer
i, respectively. The output of the final layer,
, is the feature representation of the input
x.
GN divides the channels into
G groups and normalizes the activations within each group separately. The mean and variance used to normalize the activations are computed only over the channels within each group. The GN operation is defined as:
where
and
are the mean and variance of the activations within group
g, and
,
, and
are learnable parameters that control the scaling and shifting of the activations.
The GN is a remarkable technique that has become increasingly popular in deep learning due to its many advantages. One significant benefit of GN is that it can drastically reduce the reliance on the mini-batch size during training. Unlike other normalization techniques, GN normalizes the activations within each group separately, which can make it more suitable for small batch sizes or when the batch size fluctuates during training.
Additionally, GN can lead to a more isotropic feature space than other normalization techniques, such as BN. This is because GN normalizes the activations with respect to groups of channels, which can effectively minimize the impact of the channel dimension on the normalization process. Consequently, GN is particularly beneficial for models with deep or wide architectures, where the channel dimension may be large.
Normalization methods play a significant role in deep learning to enhance the performance of models by rescaling activations in the feature space. This section covered three representative normalization methods in deep learning, including BN, LN, and GN, and provided their mathematical formulas and descriptions. BN rescales activations in the feature space with respect to mini-batch mean and variance, while LN rescales activations with respect to layer mean and variance. In contrast, GN rescales activations with respect to groups of channels, which can make it more suitable for small batch sizes or deep and wide architectures.
Table 2 provides a summary of the key features of these normalization methods. Choosing the most appropriate normalization method depends on the nature of the data and the specific deep learning task at hand.
3. Feature Space Geometry in Deep Learning
3.1. Relationships between Feature Space and Activation Functions in Deep Learning
The selection of an activation function can have a profound impact on the geometry of the feature space, dictating vital aspects such as the shape of the decision boundary, the sparsity or smoothness of the feature space, and the curvature of the feature space. To elucidate the mathematical underpinnings of these relationships, a detailed analysis shall be provided on the effects of various activation functions on the feature space geometry. In particular, the effect of the activation function on the decision boundary can be succinctly captured by the gradient of the output with respect to the input:
For the ReLU activation function, the gradient is piecewise constant:
This piecewise constant gradient leads to a fragmented and disconnected feature space, as some regions of the input space may be completely separated from others.
For the sigmoid activation function, the gradient is smooth and can be expressed as:
This smooth gradient leads to a more connected feature space, as points that are nearby in the input space are likely to have similar feature representations.
For the tanh activation function, the gradient is also smooth and can be expressed as:
The tanh function can lead to a feature space with negative curvature, as its gradient is nonmonotonic and can change sign depending on the input value. This negative curvature allows the model to learn more complex decision boundaries.
The curvature of the feature space can be further analyzed by computing the Hessian matrix, which is the matrix of second-order partial derivatives of the output with respect to the input:
The eigenvalues of the Hessian matrix determine the local curvature of the feature space. For example, if all eigenvalues are positive, the feature space has a positive curvature, while if some eigenvalues are negative, the feature space has a negative curvature.
For the GELU activation function, the gradient is smooth and can be expressed as:
The GELU function presents a smooth approximation to the ReLU function, combining the smoothness of sigmoid and tanh functions with the sparsity of ReLU. This leads to a feature space that can balance the trade-off between connectivity and fragmentation, thereby improving the model’s ability to learn complex patterns and generalize to unseen data.
For the ELU activation function, the gradient is smooth and can be expressed as:
With its smooth gradient, the ELU function can be easier to optimize using gradient-based methods compared to the ReLU function. The curvature of the feature space induced by the ELU function depends on the value of the hyperparameter and the input value x.
For the SWISH activation function, the gradient is smooth and can be expressed as:
The SWISH function possesses a gating mechanism that dynamically adjusts the slope of the function based on the input, making it more adaptable to different types of input data. The curvature of the feature space induced by the SWISH function depends on the trainable parameter
and the input value
x.
Figure 1 illustrates the activation functions and their gradients.
Table 3 summarizes the effects of commonly used activation functions on the geometry of the feature space in deep learning. The ReLU activation function introduces sparsity into the model, resulting in a fragmented and disconnected feature space. Sigmoid activation function leads to a smooth and connected feature space, while the tanh activation function can produce a feature space with negative curvature. GELU activation function combines smoothness with sparsity, resulting in a smooth and balanced feature space. ELU activation function aims to be more robust to the vanishing gradient problem, resulting in a smooth feature space with curvature depending on its parameter
and the input. Finally, the Swish activation function possesses a gating mechanism that dynamically adjusts the slope of the function, resulting in an adaptable feature space with curvature depending on its parameter
and the input. These insights can be useful in selecting the appropriate activation function for a given deep learning problem.
3.2. Relationships between Feature Space and Normalization Methods in Deep Learning
Normalization methods play an instrumental role in shaping the geometry of the feature space. In this section, a comprehensive discussion will be delved intoregarding the impact of various normalization methods on the rescaling of activations in the feature space, as well as the examination of their effects on the isotropy and connectivity of the feature space. The discourse will be reinforced with a plethora of mathematical notations and equations.
Normalization methods are adept at rescaling activations in the feature space, which can be succinctly encapsulated by a transformation function
. The effect of normalization methods on the feature space can be lucidly characterized by the gradient of the transformed output with respect to the input:
Given a transformation function
, the transformed output of the
i-th layer can be described as:
Now, the Jacobian matrix of the transformed output with respect to the input is considered:
The Jacobian matrix provides insights into how the transformed output varies with respect to the input. A bounded Jacobian matrix indicates that the transformation function preserves the local structure of the feature space.
To demonstrate that the Jacobian matrix is likely bounded, the Frobenius norm of the matrix will be analyzed, which provides a measure of the matrix’s overall magnitude. The Frobenius norm of the Jacobian matrix
can be defined as:
where
is the number of units in the
i-th layer and
D is the dimension of the input space.
A bounded Jacobian matrix implies that the Frobenius norm of the matrix is bounded by some constant
:
Given the transformed output of the
i-th layer:
The Lipschitz continuity of the transformation function
with respect to the input
x can be analyzed. If
is Lipschitz continuous with Lipschitz constant
, the following inequality holds for any
:
By using the Lipschitz continuity of
, an upper bound for the Frobenius norm of the Jacobian matrix can be derived. For any
with
:
Since the Jacobian matrix is continuous with respect to the input
x, the extreme value theorem implies that the Frobenius norm of the Jacobian matrix is likely bounded:
where
. This bounded Frobenius norm indicates that the transformation function
preserves the local structure of the feature space, as a bounded Jacobian matrix implies that the rate of change of the transformed output with respect to the input remains limited.
Furthermore, insights into the isotropy and connectivity of the feature space can be gained by analyzing the eigenvalues of the Jacobian matrix. Let be an eigenvalue of the Jacobian matrix . If the eigenvalues are distributed uniformly and have similar magnitudes, the feature space is isotropic, meaning that the optimization landscape is smooth and well-conditioned.
Suppose the ratio between the maximum and minimum eigenvalues, known as the condition number, is bounded by a constant
:
A bounded condition number implies that the transformation function does not distort the feature space excessively, leading to better optimization and generalization properties of the deep learning model. Furthermore, it suggests that the connectivity of the feature space is preserved, as the gradients do not vanish or explode during training.
Table 4 summarizes the relationships between feature space and normalization methods in deep learning. The transformation function rescales the activations in the feature space, while the Jacobian matrix represents how the transformed output varies with respect to the input. The Frobenius norm measures the overall magnitude of the Jacobian matrix, and Lipschitz continuity indicates that the transformation function preserves the local structure of the feature space. The condition number represents the isotropy and connectivity of the feature space, which have implications for the optimization and generalization properties of deep learning models.
Isotropy and Connectivity of Feature Space with Normalization Methods
Normalization methods not only influence the boundedness of the feature space but also impact its isotropy and connectivity. Isotropy refers to the uniformity of the feature space, while connectivity refers to the ability of the neural network to establish connections between different regions of the feature space. In this section, the effects of BN, LN, and GN on isotropy and connectivity in deep learning models will be discussed using mathematical descriptions.
Let
be a normalization method, and let
and
be the mean and variance computed by the normalization method. The isotropy condition can be expressed as:
BN ensures isotropy by normalizing the feature space across the mini-batch. The mean
and variance
are computed as follows:
This rescaling of the mean and variance results in a uniform feature space. BN can also improve the connectivity of the feature space by reducing the internal covariate shift, which refers to the change in the distribution of the inputs to a given layer during training. This reduction in internal covariate shift smooths the loss landscape, making it easier for the neural network to establish connections between different regions of the feature space. Other normalization methods such as GN and LN constitute feature space in a similar manner to BN.
Normalization methods have been found to be particularly effective in improving the isotropy and connectivity of the feature space in residual networks. Residual networks contain skip connections, which facilitate gradient flow and enable the network to learn identity mappings. Let
be the residual block at layer
i, and let
and
be the input and output of this block, respectively. The residual block can be expressed as:
Here,
is a composite function, including a normalization method, activation function, and linear transformation. Specifically, let
be a normalization method used in the residual block, and let
f be an activation function. Then, an example of
can be represented as:
Considering the residual block expressed in Equation (
41), the isotropy condition for the output
can be analyzed as follows:
Since
and
are hypothetically independent after the blocks of layers in
, their expected values can be separated:
Under the assumption that the activation function f is zero-centered, meaning , where is a pre-activation vector, the isotropy condition for the output can be further analyzed as follows:
First, consider the expected value of
:
Since the normalization method
enforces isotropy, it is known that
. Thus, the pre-activation vector
has zero mean. Under the assumption that
f is zero-centered:
This result can be substituted into the equation for the expected value of
:
This result indicates that the expected value of the output is equal to the expected value of the input . If the input is isotropic, meaning , then the output will also be isotropic, satisfying . This demonstrates how normalization methods, combined with a zero-centered activation function, can preserve isotropy in deep learning models, particularly in residual networks.
Table 5 summarizes the isotropy and connectivity of feature space with normalization methods. The isotropy condition ensures the uniformity of the feature space, and BN rescales the mean and variance accordingly. The residual block represents the residual connection in deep learning models, with a composite function that incorporates normalization, activation, and linear transformation. Isotropy preservation demonstrates that the expected value of the output is equal to the input, preserving the isotropy of the feature space in residual networks.
3.3. Synergistic Integration of ReLU-Inspired Activation Functions and Normalization Techniques
In this section, a comprehensive analysis is presented on the collective influence of ReLU-inspired activation functions and normalization techniques on the boundedness of the feature space. Activation functions such as ReLU, GELU, and ELU, which exhibit unbounded characteristics, can attain a bounded output when seamlessly integrated with normalization methodologies. This complementary interplay has propelled the widespread adoption of ReLU-inspired activation functions in contemporary deep learning research.
Initially, let us consider the ReLU, GELU, and ELU activation functions, which can be articulated using Equations (
12), (
15) and (
16). Subsequently, the transformation functions for BN, LN, and GN are represented as
,
, and
, respectively. When fused with ReLU-inspired activations, the transformations within the feature space can be expressed as:
Corresponding transformations can be delineated for GELU and ELU activations, as well as LN and GN. Building on this foundation, the investigation proceeds to analyze the boundedness of these intricate combinations.
As ReLU-inspired activations manifest as nonlinear functions, the Lipschitz constants of the merged transformations cannot be directly ascertained by multiplying the Lipschitz constants of each individual function. Nevertheless, a thorough analysis of the boundedness of these hybrid transformations can be offered by scrutinizing the output range of the combined transformational processes.
For ReLU-BN, ReLU-LN, and ReLU-GN, the ReLU activation function clips negative values to zero, resulting in a lower bound of 0 for the output. Furthermore, since the normalization methods rescale the feature space such that the mean is 0 and the variance is 1, the upper bound of the output is constrained by a constant factor, ensuring the boundness of the combined transformations.
Similarly, for GELU and ELU activations combined with normalization methods, the lower bound of the output is determined by the minimum of the activation functions (with a lower bound of ≈ for GELU and for ELU, where is a positive constant and denotes the minimum value in the rescaled feature space). The upper bound of the output for these combinations is also determined by a constant factor, as the normalization methods rescale the feature space to have zero mean and unit variance. Consequently, the output of the GELU and ELU activation functions combined with normalization methods is also bounded.
To provide a more formal proof of the boundness, the definition of Lipschitz continuity can be used. Recall that a function f is Lipschitz continuous if there exists a constant . In the case of the combined transformations, let . To prove the boundness of , it is necessary to show the existence of a constant that satisfies the Lipschitz condition for all in the domain of .
Given that the ReLU activation clips negative values to zero, and the normalization methods rescale the feature space such that the mean is 0 and the variance is 1, the maximum value of is upper-bounded by a constant factor. This implies that there exists a constant that satisfies the Lipschitz condition, thus proving the boundness of the combined transformations.
Analogous arguments can be made for the GELU and ELU activation functions combined with normalization methods, and the proof follows similar steps. Since the lower and upper bounds of the output for these combinations are determined by constant factors, the existence of Lipschitz constants for these cases can be established, which in turn demonstrates the boundness of these combined transformations.
4. Recent Studies of Feature Space Geometry in Deep Learning
Recent studies have increasingly focused on exploring the manifold structure of feature space geometry in deep learning models. This is due to the significant impact that feature space geometry has on the model’s performance and generalization capabilities. Non-Euclidean spaces, such as hyperbolic space, have been recently explored for modeling complex data distributions. These spaces can better capture the intrinsic geometric structure of the data, thereby enhancing the model’s ability to learn meaningful representations and generalize to new data. Transfer learning is another area of interest where recent studies have examined the impact of feature space geometry. Specifically, these studies investigate the adaptation of a model trained on one task to a new task by analyzing the feature space geometry. Through a systematic analysis of these recent studies, a comprehensive understanding of the current state of research on feature space geometry in deep learning can be provided, and promising directions for future research can be identified.
4.1. Manifold Structure of Deep Learning
The manifold hypothesis [
28,
29,
30] posits that high-dimensional data often lies on or near a lower-dimensional manifold. Understanding the manifold structure of the feature space can provide insights into the model’s ability to learn meaningful representations and generalize to new data.
Let
be the manifold in the feature space. The manifold can be locally approximated using tangent spaces
, where
. In deep learning, the model can be designed to learn the manifold structure by minimizing the reconstruction error on the tangent spaces:
where
denotes the model parameters, and
and
are the encoding and decoding functions, respectively.
To quantify the manifold structure, one can use the manifold’s reach, which measures the largest distance from a point in the ambient space to the manifold:
The manifold structure in deep learning has been recognized as a significant factor contributing to the success of various applications [
31,
32,
33]. Manifold learning allows deep learning models to capture the underlying structure and relationships within data, leading to improved performance in tasks such as scene recognition, face-pose estimation, dynamic MRI, and hyperspectral imagery feature extraction.
Brahma et al. [
28] offered measurable validation to support the theory that deep learning works by flattening manifold-shaped data in higher neural network layers. The authors created a range of measures to quantify manifold entanglement under certain assumptions, with their experiments on both synthetic and real-world data confirming the flattening hypothesis. To tackle scene recognition, Yuan et al. [
31] proposed a manifold-regularized deep architecture, which leverages the structural information of data to establish mappings between visible and hidden layers. The deep architecture learns high-level features for scene recognition in an unsupervised manner, surpassing existing state-of-the-art scene recognition methods. Hong et al. [
32] introduced a multitask manifold deep learning (M2DL) framework for face-pose estimation by using multimodal data. They employed improved CNNs for feature extraction and applied multitask learning with incoherent sparse and low-rank learning to integrate different face representation modalities. The M2DL framework exhibited better performance on three challenging benchmark datasets.
Ke et al. [
34] proposed a deep manifold learning approach for dynamic MRI reconstruction, called Manifold-Net, which is an unrolled neural network on a fixed low-rank tensor (Riemannian) manifold to capture the strong temporal correlations of dynamic signals. The experimental results demonstrated superior reconstruction compared to conventional and state-of-the-art deep learning-based methods. For feature extraction of hyperspectral imagery, Li et al. [
35] developed a graph-based deep learning model known as deep locality preserving neural network (DLPNet). DLPNet initializes each network layer by exploring the manifold structure in hyperspectral data and employs a deep-manifold learning joint loss function during network optimization. The experiments on real-world HSI datasets indicated that DLPNet outperforms state-of-the-art methods in feature extraction.
Table 6 summarizes various deep learning approaches incorporating manifold learning for different applications. These approaches include measures to quantify manifold entanglement, manifold-regularized deep architectures, multitask manifold deep learning, Manifold-Net, and deep locality preserving neural networks. The applications of these methods span from validating the flattening hypothesis in deep learning to scene recognition, face-pose estimation, dynamic MRI reconstruction, and hyperspectral imagery feature extraction.
The manifold hypothesis, which suggests that high-dimensional data often lies on or near a lower-dimensional manifold, has been explored to understand the model’s ability to learn meaningful representations and generalize to new data. Tangent spaces can be used to locally approximate the manifold, and manifold learning allows deep learning models to capture the underlying structure and relationships within data. Recent studies have explored the use of hyperbolic space to better capture the intrinsic geometric structure of data and transfer learning to analyze the adaptation of a model trained on one task to a new task. Quantitative evidence from experiments on synthetic and real-world data confirms that deep learning works due to the flattening of manifold-shaped data in higher layers of neural networks. Different deep learning models have been proposed to extract features for various applications, including scene recognition, face-pose estimation, dynamic MRI, and hyperspectral imagery feature extraction. The manifold structure in deep learning has been recognized as a significant factor contributing to the success of these applications.
4.2. Curvature of Feature Space Geometry
The curvature of the feature space geometry is essential for understanding the model’s ability to adapt to the data’s local structure. In the context of deep learning, the curvature can be influenced by the choice of activation functions and the architecture of the model. A popular measure of curvature in the feature space is the sectional curvature, which is defined for two-dimensional tangent planes.
Let
be the manifold in the feature space, and
be the tangent space at point
. For any two linearly independent tangent vectors
, the sectional curvature
is defined as:
where
is the Riemann curvature tensor and
is the inner product in the tangent space.
In deep learning, activation functions such as ReLU, sigmoid, and tanh can induce specific geometric properties in the feature space, including curvature. For instance, the ReLU activation function can lead to piecewise linear manifolds, while sigmoid and tanh activation functions can result in smooth curved manifolds.
To assess the curvature properties of a deep learning model, one can compute the eigenvalues of the Hessian matrix, which represents the second-order partial derivatives of the model’s loss function with respect to the model parameters. High eigenvalues suggest regions of high curvature, while low eigenvalues indicate regions of low curvature.
where
L is the loss function, and
and
are elements of the model parameters vector
.
The analysis of the curvature in feature space geometry of deep learning models has become an area of great interest due to the insights it offers into the intrinsic properties of these models, as well as their potential to improve performance in various applications. Researchers have proposed several innovative models in this field. For example, He et al. [
36] developed CurvaNet, a geometric deep learning model for 3D shape analysis that uses directional curvature filters to learn direction-sensitive 3D shape features. Bachmann et al. [
37] introduced Constant Curvature Graph Convolutional Networks (CC-GCNs) that can be applied to node classification and distortion minimization tasks in non-Euclidean geometries. Additionally, Ma et al. [
38] proposed a curvature regularization approach to address the issue of model bias caused by curvature imbalance in deep neural networks. Other researchers, such as Lin et al. [
39] and Arvanitidis et al. [
40], examined the curvature of deep generative models and developed new architectures and approaches to improve their performance.
Table 7 presents a summary of different curvature-based approaches in deep learning, including CurvaNet, CC-GCNs, curvature regularization, CAD-PU, and latent space curvature analysis. These approaches are applied to various applications such as 3D shape analysis, node classification, distortion minimization, addressing model bias, point cloud upsampling, and generative models. The study of curvature in deep learning models provides valuable insights into their intrinsic properties and helps improve their performance across different applications.
The curvature of feature space geometry is critical in understanding how well a deep learning model can adapt to the local structure of data. The choice of activation functions and the model’s architecture influence the curvature of the feature space. The sectional curvature, which is defined for two-dimensional tangent planes, is a popular measure of curvature in the feature space. The study of curvature in the feature space geometry of deep learning models has gained significant attention, as it offers insights into the intrinsic properties of these models and helps improve their performance in various applications. Many recent studies have explored the relationship between curvature and deep learning models, including CurvaNet, CC-GCNs, curvature regularization, CAD-PU, and examining the curvature of deep generative models. These studies aim to understand and leverage the curvature properties of deep learning models for better performance and generalization capabilities.
4.3. Wide Neural Networks and Gaussian Process
A notable line of research has focused on the relationship between wide neural networks and Gaussian processes. In the limit of infinitely wide hidden layers, deep neural networks with independent random initializations converge to Gaussian processes, as shown by Lee et al. [
41]. This convergence can be described by the following kernel function:
where
n is the width of the hidden layers, and
and
are the feature vectors of inputs
x and
, respectively. This result implies that wide neural networks exhibit a simpler geometry in their feature space, which can be characterized by a Gaussian process.
Expanding upon the relationship between wide neural networks and Gaussian processes, it is essential to understand the intricacies of this convergence and its implications for deep learning models. The convergence of wide neural networks to Gaussian processes can be further explored in terms of the Neural Tangent Kernel (NTK) [
42], which characterizes the training dynamics of these networks in the infinite-width limit.
The NTK is defined as follows:
where
is the output of the neural network for input
x with parameters
. For wide neural networks, the NTK converges to a constant matrix during training, implying that the training dynamics can be described as a linear model with respect to the NTK [
42]:
where
, and
t denotes the training iteration.
The convergence of wide neural networks to Gaussian processes can be further illustrated by analyzing the feature space geometry. For a wide neural network with a single hidden layer, the feature vector
can be expressed as:
where
W is the weight matrix,
b is the bias vector, and
is the activation function. As the width of the hidden layer (
n) tends to infinity, the feature vectors become isotropic in the feature space, and their inner product converges to the kernel function:
This convergence is governed by the Central Limit Theorem (CLT), as the sum of a large number of independent random variables converges to a Gaussian distribution. Consequently, the geometry of the feature space in wide neural networks can be characterized by a Gaussian process with the kernel function .
Recent research has uncovered significant links between wide neural networks and Gaussian processes, leading to new insights into the behavior and theoretical properties of deep learning models. The work of Matthews et al. [
43] showed that random fully connected feedforward networks with multiple hidden layers, when wide enough, converge to Gaussian processes with a recursive kernel definition. Yang [
44,
45] introduced straightline tensor programs, which established the convergence of random neural networks to Gaussian processes for a wide range of architectures, including recurrent, convolutional, residual networks, attention mechanisms, and their combinations. Pleiss and Cunningham [
46] investigated the limitations of large width in neural networks, demonstrating that large width can be detrimental to hierarchical models, and found that there is a sweet spot that maximizes test performance before the limiting GP behavior prevents adaptability. Meanwhile, other researchers have explored various aspects of the convergence of wide neural networks to Gaussian processes, such as the behavior of Bayesian neural networks [
47], the evolution of wide neural networks of any depth under gradient descent [
41], the convergence rates of wide neural networks to Gaussian processes based on activation functions [
48], the effects of increasing depth on the emergence of Gaussian processes [
49], and the equivalence between neural networks and deep sparse Gaussian process models [
50].
Table 8 summarizes various research contributions in the area of wide neural networks and Gaussian processes. The table highlights the approaches and contributions of these studies, such as the convergence of wide neural networks to Gaussian processes, characterizing training dynamics using the Neural Tangent Kernel, the recursive kernel definition for random fully connected networks, and the convergence of various architectures using straightline tensor programs. Additionally, researchers have investigated the limitations of large width, the behavior of Bayesian neural networks, convergence rates based on activation functions, the effects of increasing depth on the emergence of Gaussian processes, and the equivalence between neural networks and deep sparse Gaussian process models.
Research has explored the relationship between wide neural networks and Gaussian processes, showing that as the hidden layers’ width tends to infinity, deep neural networks converge to Gaussian processes. This convergence is described by the kernel function, which characterizes the simpler geometry of wide neural networks’ feature space. The study of this convergence has been extended to the NTK, which characterizes the training dynamics of these networks in the infinite-width limit. The feature space geometry can be analyzed to illustrate this convergence and its implications for deep learning models. The relationship between wide neural networks and Gaussian processes has also been explored in various architectures, including Bayesian neural networks, fully connected feedforward networks, recurrent, convolutional, residual networks, attention mechanisms, and their combinations, providing insights into the theoretical properties and behavior of deep learning models.
4.4. Critical Points and Loss Landscape
The loss landscape of neural networks, particularly its critical points and curvature, has been an area of significant research interest. Understanding the properties of critical points can offer insights into the optimization process and the performance of deep learning models.
A critical point in the loss landscape is a point where the gradient of the loss function with respect to the network parameters is zero:
where
denotes the network parameters, and
is the loss function. The Hessian matrix at a critical point provides information about the curvature of the loss landscape:
The eigenvalues of the Hessian matrix, , can be used to classify critical points. If all the eigenvalues are positive, the critical point corresponds to a local minimum; if all the eigenvalues are negative, it corresponds to a local maximum. If the Hessian matrix has both positive and negative eigenvalues, the critical point is a saddle point.
The second-order Taylor expansion of the loss function around a critical point
is given by:
This approximation indicates that the behavior of the loss function in the vicinity of a critical point is determined by the eigenvalues and eigenvectors of the Hessian matrix.
Researchers have been exploring the landscape of the loss function in deep learning models to better understand their optimization properties and performance. Chaudhari et al. [
51] introduced Entropy-SGD, an optimization algorithm that utilizes local entropy to discover wide minima that are associated with better generalization performance. Nguyen and Hein [
52] investigated the impact of depth and width on the optimization landscape and expressivity of deep CNNs, demonstrating that sufficiently wide CNNs produce linearly independent features and provided necessary and sufficient conditions for global minima with zero training error. Geiger et al. [
53] proposed the concept of phase transition to analyze the loss landscape of fully connected deep neural networks, observing the independence of fitting random data and depth, and delimiting the over- and under-parametrized regimes. Kunin et al. [
54] studied the loss landscapes of regularized linear autoencoders, while Simsek et al. [
55] explored the impact of permutation symmetries on overparameterized neural networks. Zhou and Liang [
56] provided a full characterization of the analytical forms for the critical points of various neural networks, revealing landscape properties of their loss functions. Zhang et al. [
57] established an embedding principle for the loss landscape of deep neural networks, showing that wider DNNs contain all the critical points of narrower DNNs, with potential implications for regularization during training.
Table 9 provides a summary of research contributions related to critical points and the loss landscape of deep learning models. The table presents the approaches and contributions of these studies, including the Entropy-SGD algorithm for discovering wide minima, the investigation of depth and width effects on the optimization landscape and expressivity of deep CNNs, the concept of phase transition for analyzing loss landscapes in fully connected DNNs, and the study of loss landscapes in regularized linear autoencoders. Other research has explored the impact of permutation symmetries on overparameterized neural networks, the analytical forms of critical points for revealing landscape properties of loss functions, and the embedding principle to analyze critical points in wider and narrower DNNs.
The critical points and loss landscape of neural networks have been studied to understand their optimization properties and performance. A critical point is where the gradient of the loss function is zero, and the Hessian matrix provides curvature information. Various techniques, such as Entropy-SGD and phase transition, have been used to analyze the loss landscape in deep learning models. Researchers have also studied regularized linear autoencoders and the impact of permutation symmetries on overparameterized neural networks. The analytical forms for the critical points of various neural networks have been characterized, and the embedding principle has implications for regularization during training.
4.5. Singular Value Spectrum of the Feature Space
Another property that offers insights into the geometry and expressivity of neural networks is the singular value spectrum of the feature space. The singular value decomposition (SVD) of a feature space matrix
is given by:
where
and
are orthogonal matrices, and
is a diagonal matrix containing the singular values
.
The singular values provide valuable information about the geometry of the feature space, such as the dimensionality and the distribution of the feature vectors. Moreover, they can be used to characterize the capacity of a neural network to learn low-dimensional manifolds.
One approach to analyze the singular value spectrum is to examine the behavior of the singular values as a function of the depth of the network. Let
denote the feature map at layer
l for input
, and
be the matrix of feature maps at layer
l for
n input samples. The singular value spectrum of the feature space at layer
l can be computed as:
where
and
are orthogonal matrices, and
is a diagonal matrix containing the singular values
.
The ratio of successive singular values, also known as the singular value gap, can be used to estimate the effective dimensionality of the feature space:
A large gap indicates a significant drop in the singular values and suggests a low-dimensional structure in the feature space. The effective dimensionality of the feature space can be estimated by finding the index
at which the gap is maximized:
Recent studies have investigated the singular value spectrum of deep neural networks, as it provides insights into their geometry and expressivity. Oymak and Soltanolkotabi [
58] demonstrated that deep ReLU networks can implicitly learn low-dimensional manifolds, while Jia et al. [
59] proposed Singular Value Bounding (SVB) and Bounded BN (BBN) techniques to constrain the weight matrices in the orthogonal feasible set during network training. Bermeitinger et al. [
60] established a connection between SVD and multi-layer neural networks, showing that the singular value spectrum can be beneficial for initializing and training deep neural networks. Schwab et al. [
61] developed a data-driven regularization method for photoacoustic image reconstruction using truncated SVD coefficients recovered by a deep neural network. Sedghi et al. [
62] characterized the singular values of 2D multi-channel convolutional layers and proposed an algorithm for projecting them onto an operator-norm ball, effectively improving the test error of a deep residual network using BN on CIFAR-10.
Table 10 summarizes research contributions related to the singular value spectrum of the feature space in deep learning models. The table presents the approaches and contributions of these studies, including the investigation of deep ReLU networks’ ability to implicitly learn low-dimensional manifolds, the use of SVB and BBN techniques to constrain weight matrices in the orthogonal feasible set, the connection between SVD and multi-layer networks, and the development of data-driven regularization methods. Other research has characterized the singular values of 2D multi-channel convolutional layers and proposed an algorithm for projecting them onto an operator-norm ball, effectively improving test error. These studies contribute to a better understanding of the singular value spectrum in deep neural networks and its implications for the geometry and expressivity of these models.
As shown in these studies, the singular values can estimate the effective dimensionality of the feature space and help understand a network’s capacity to learn low-dimensional manifolds. Recent studies have investigated the singular value spectrum, including methods for constraining weight matrices, establishing connections with multi-layer networks, and proposing data-driven regularization methods.
4.6. Exploring the Geometry of Feature Spaces in Convolutional Neural Networks
CNNs have demonstrated remarkable results in a wide range of computer vision applications. To gain a deeper understanding of their generalization abilities, recent research has delved into the geometry of CNN feature spaces. A key discovery is the presence of translation-equivariant representations within these feature spaces [
63]. This characteristic can be formulated as:
where
represents the feature space transformation,
is a translation operator acting upon input
x, and
is the corresponding translation operator within the feature space. This translation-equivariant attribute allows CNNs to learn spatially invariant features, which is vital for their success in a variety of vision tasks.
Aside from translation-equivariant representations, researchers have also examined the feature space of CNNs for rotation-equivariant properties [
64]. Mathematically, this can be expressed as:
where
is a rotation operator acting on input
x with angle
, and
is the corresponding rotation operator in the feature space. By incorporating rotation-equivariant properties, CNNs can effectively learn to identify objects at various orientations.
In recent studies, researchers have explored the concept of equivariance in CNNs and its potential applications. Singh et al. [
65] proposed a positional encoding method that uses orthogonal polar harmonic transforms to achieve equivariance to rotation, reflection, and translation in CNN architectures. On the other hand, McGreivy and Hakim [
66] clarified that CNNs are equivariant to discrete shifts, but not continuous translations. Aronsson et al. [
67] developed lattice gauge equivariant CNNs that maintain gauge symmetry under global lattice symmetries. Zhdanov et al. [
68] proposed using implicit neural representation via multi-layer perceptrons to parameterize G-steerable kernels in steerable CNNs, leading to significant performance improvements. Toft et al. [
69] characterized the equivariant linear operators on the space of square-integrable functions on the sphere with respect to azimuthal rotations and demonstrated their potential applications in improving the performance of state-of-the-art pipelines.
Another area of investigation has concentrated on the link between the Lipschitz constant and the generalization of CNNs [
70]. Let
denote a function representing a CNN, with
and
signifying input and output spaces, respectively. The Lipschitz constant
L for the function
f is defined as:
where
denotes the norm. A lower Lipschitz constant indicates that the function is less susceptible to minor disturbances in the input, which can improve the generalization performance of the CNN. This observation has led to the development of regularization techniques based on the Lipschitz constant, such as spectral normalization [
71].
Recently, estimating the Lipschitz constant has emerged as a critical factor in understanding the robustness and generalization ability of CNNs. Pauli et al. [
72] developed a dissipativity-based method for estimating the Lipschitz constant of 1D CNNs, which focused on analyzing dissipativity properties in convolutional, pooling, and fully connected layers. By using incremental quadratic constraints and a semidefinite program derived from dissipativity theory, they demonstrated the advantages of their method in terms of accuracy and scalability. In a separate work, Pauli et al. [
73] established a layer-wise parameterization for 1D CNNs with built-in end-to-end robustness guarantees using the Lipschitz constant as a measure of robustness.
In addition, a deeper understanding of the geometry of feature spaces in CNNs can be achieved by examining the invariance and equivariance properties of features concerning specific transformation groups [
63]. Let
represent a group of transformations acting on the input space
. A feature space transformation
is considered to be
-invariant if:
and
-equivariant if:
where
is a representation of the group element
g in the feature space. Gaining insights into these invariance and equivariance properties can offer valuable information about the structure of the feature space, ultimately aiding in the development of architectures with enhanced generalization capabilities.
Furthermore, recent research has explored the role of scale-equivariant representations in the feature space of CNNs [
74]. This property can be described mathematically as:
where
is a scale operator acting on the input
x with scaling factor
, and
is the corresponding scale operator in the feature space. By incorporating scale-equivariant properties, CNNs can learn to recognize objects at various scales, enhancing their performance in diverse vision tasks.
Table 11 provides a summary of research contributions related to the geometry of feature spaces in convolutional neural networks. These studies explore various aspects of the geometry, including translation-equivariant, rotation-equivariant, and scale-equivariant properties, as well as the Lipschitz constant and its implications for robustness and generalization. They contribute to a deeper understanding of the characteristics of CNN feature spaces and provide insights that can be utilized to develop more effective and generalizable network architectures.
Recent research on CNNs has delved into the geometry of their feature spaces, particularly the translation- and rotation-equivariant properties that allow CNNs to learn spatially invariant and orientation-invariant features, respectively. Researchers have explored the concept of equivariance in CNNs, leading to proposed methods for achieving equivariance to rotation, reflection, and translation, as well as developing lattice gauge equivariant CNNs that maintain gauge symmetry under global lattice symmetries. Estimating the Lipschitz constant has also emerged as a critical factor in understanding the robustness and generalization ability of CNNs, leading to the development of regularization techniques based on the Lipschitz constant, such as spectral normalization. Gaining insights into the invariance and equivariance properties of features concerning specific transformation groups can offer valuable information about the structure of the feature space, ultimately aiding in the development of architectures with enhanced generalization capabilities. Finally, recent research has also explored the role of scale-equivariant representations in the feature space of CNNs.
4.7. Adversarial Robustness and Feature Space Geometry
Adversarial robustness has emerged as an essential aspect of deep learning models. Recent studies have investigated the relationship between the feature space geometry and adversarial robustness. One such study by Fawzi et al. [
75] revealed that adversarial examples lie near the decision boundaries of the classifier in the feature space, and their existence is related to the curvature of the decision boundary.
The robustness of a classifier can be characterized by the margin around the decision boundary:
where
denotes the data distribution,
is the classifier output, and
y is the true label. A larger margin
corresponds to increased robustness against adversarial examples.
Another recent study by Tsipras et al. [
76] examined the trade-off between standard accuracy and adversarial robustness. They analyzed the linear approximation of the classifier loss function,
, around a data point
, and derived the adversarial perturbation,
, as follows:
where
is a small constant determining the maximum allowed perturbation. This adversarial perturbation causes a decrease in the margin around the decision boundary, implying a trade-off between standard accuracy and adversarial robustness.
In a different study, Hein et al. [
77] introduced a geometric perspective on adversarial robustness by defining the concept of robustness certificates. They proposed a measure called the cross-Lipschitz regularization (CLR) that quantifies the robustness of a classifier,
, as follows:
where
is the input space. A smaller CLR value indicates a more robust classifier. This measure captures the sensitivity of the classifier output to input perturbations and is related to the Lipschitz constant of the classifier.
Recent studies have focused on enhancing the adversarial robustness of deep learning models by investigating the geometry of the feature space. Various methods have been proposed, including the defense layer by Goel et al. [
78] that aims to prevent the generation of adversarial noise and Dual Manifold Adversarial Training (DMAT) introduced by Lin et al. [
79], which exploits the underlying manifold information of data to achieve comparable robustness to standard adversarial training against
attacks. Additionally, Chen and Liu [
80] provided a comprehensive overview of adversarial robustness research methods for deep learning models, while Gavrikov and Keuper [
81] investigated the properties of convolution filters in adversarially trained models. Moreover, Ghaffari Laleh et al. [
82] studied the susceptibility of CNNs and vision transformers (ViTs) to white- and black-box adversarial attacks in clinically relevant weakly-supervised classification tasks, demonstrating ViTs’ higher robustness to such attacks attributed to their more robust latent representation of clinically relevant categories compared to CNNs.
Table 12 provides a summary of research contributions related to adversarial robustness and feature space geometry. These studies investigate various aspects of adversarial robustness, including the relationship between adversarial examples and decision boundary curvature, the trade-off between standard accuracy and robustness, and the development of robustness certificates. They contribute to a better understanding of the geometry of the feature space in the context of adversarial robustness and provide insights for developing more robust and reliable deep learning models.
Adversarial attacks are a major concern for the reliability and safety of deep learning models. Recent research has explored the relationship between adversarial robustness and the geometry of the feature space. Adversarial examples tend to lie near the decision boundaries of the classifier, and their existence is related to the curvature of the decision boundary. The margin around the decision boundary is a measure of the robustness of a classifier, with a larger margin indicating increased robustness. There is a trade-off between standard accuracy and adversarial robustness, and the sensitivity of the classifier output to input perturbations can be quantified using the cross-Lipschitz robustness measure.
4.8. Feature Space Geometry and Transfer Learning
Transfer learning is a widely-used technique in deep learning, in which pre-trained models are fine-tuned on a new task. The feature space geometry plays a crucial role in the success of transfer learning. A study by Yosinski et al. [
83] found that the feature spaces of lower layers in neural networks tend to be more general and transferable than those of higher layers.
The transferability of a feature space can be quantified by measuring the similarity between the feature spaces of the source and target tasks:
where
and
denote the feature spaces of the source and target tasks, respectively, and
measures the cosine similarity between the feature spaces. A high similarity score indicates that the feature space is more transferable between the tasks.
Several recent studies have focused on exploring the transferability of features between different domains of time series data, real-time crash risk models, and image classification tasks. Otović et al. [
84] investigated the transferability of features in time series data and found that transfer learning is likely to improve or not negatively affect the model’s predictive performance or its training convergence rate. Man et al. [
85] proposed a method combining Wasserstein Generative Adversarial Network and transfer learning to address the spatio-temporal transferability issue of real-time crash risk models. Their findings show that transfer learning can improve model transferability under extremely imbalanced settings, resulting in models that are transferable temporally, spatially, and spatio-temporally. Pándy et al. [
86] proposed a novel method, Gaussian Bhattacharyya Coefficient, for quantifying transferability between a source model and a target dataset. Their results showed that GBC outperforms state-of-the-art transferability metrics on most evaluation criteria in semantic segmentation settings and performs well on dataset transferability and architecture selection problems for image classification.
The feature space geometry has continued to be a significant area of research in transfer learning, with several studies exploring different aspects of this relationship. Xu et al. [
87] investigated the connection between the similarity of feature spaces and the performance of transfer learning. They proposed a task similarity measure based on the normalized mutual information (NMI) between the feature space distributions of the source and target tasks:
where
denotes the mutual information and
denotes the entropy. This measure quantifies the degree of dependence between the source and target feature spaces, and higher values of NMI indicate a stronger relationship, leading to better transfer learning performance.
Xie et al. [
88] studied the importance of feature alignment in transfer learning. They introduced a feature alignment loss, which aims to minimize the distance between the source and target feature space distributions:
where
n is the number of samples and
is the
i-th sample. By optimizing this loss, the feature spaces become more aligned, resulting in improved transfer learning performance.
Raghu et al. [
89] proposed a method called Transfusion to enhance transfer learning by selectively transferring features. They introduced a transfer matrix
, which maps the source feature space to the target feature space:
where the transfer matrix
is learned during the fine-tuning process. This approach allows for selective transfer of features, which can improve the transferability and adaptability of pre-trained models.
Zamir et al. [
90] explored the task structure in transfer learning and introduced the concept of taskonomy, which models the relationships between tasks using a directed graph. They proposed an optimization problem to find the optimal transfer learning strategy:
where
is the task graph,
is the set of tasks, and the cost function represents the performance of transfer learning. By solving this optimization problem, they found the optimal task relationships that yield the best transfer learning performance.
Table 13 provides a summary of research contributions related to feature space geometry and transfer learning. These studies investigate various aspects of transfer learning, such as the transferability of lower layers in neural networks, the transferability of features between different domains, and the development of novel methods to quantify transferability. Additionally, they explore techniques to improve transfer learning performance, such as feature alignment, selective transfer, and optimizing task relationships.
Transfer learning is a widely-used technique in deep learning that involves fine-tuning pre-trained models on a new task. The feature space geometry plays a crucial role in the success of transfer learning. Several recent studies have explored the transferability of features between different domains of time series data, real-time crash risk models, and image classification tasks. The findings indicate that transfer learning can improve model transferability and result in models that are transferable temporally, spatially, and spatio-temporally. Additionally, recent research has focused on different aspects of the feature space geometry and transfer learning, including the connection between the similarity of feature spaces and the performance of transfer learning, the importance of feature alignment in transfer learning, and selective transfer of features to improve adaptability. Moreover, task structure has been explored to model the relationships between tasks using a directed graph and find the optimal task relationships that yield the best transfer learning performance.
4.9. Disentangled Representations in Feature Space
Disentangled representations are a desirable property in deep learning models, as they facilitate the separation of underlying explanatory factors in the data. The geometry of the feature space can provide insights into the degree of disentanglement achieved by a model. Mathematically, a disentangled representation can be characterized by the independence between the latent factors:
where
is a latent representation vector and
represents individual latent factors. The geometry of the feature space in disentangled representation learning has been investigated in various studies, such as the
-VAE [
91] and InfoGAN [
92].
The pursuit of disentangled representations has led to numerous recent studies proposing various mathematical frameworks and models to achieve a higher degree of disentanglement.
Locatello et al. [
93] introduced a fairness-aware framework for disentangled representations. They proposed a regularization term to encourage fairness by minimizing the mutual information between the sensitive attribute
s and the disentangled latent factors
:
where
denotes the mutual information. By minimizing this loss, the learned representations become more disentangled with respect to the sensitive attribute, leading to fairer representations.
Achille et al. [
94] studied the relationship between the information bottleneck principle and disentangled representations. They derived an upper bound on the mutual information between the input data
and the disentangled latent factors
:
where
is the entropy,
is a trade-off parameter, and
is the information bottleneck loss. This result suggests that optimizing the information bottleneck objective can lead to the emergence of disentangled representations.
Kim and Mnih [
95] introduced a method called Disentangling by Factorizing (DF) to learn disentangled representations in a purely unsupervised manner. They proposed a factorized variational autoencoder (FVAE) that models the joint distribution of data
and latent factors
as:
where
is the likelihood and
are the prior distributions over latent factors. They also introduced a structured inference network
to approximate the true posterior
. The model is trained by optimizing the evidence lower bound (ELBO):
where
denotes the Kullback–Leibler divergence. By optimizing this objective, the model learns disentangled representations that separate the underlying factors of variation in the data.
Table 14 provides a summary of research contributions related to disentangled representations in feature space. These studies investigate various aspects of disentangled representations, such as balancing reconstruction and disentanglement, using mutual information for unsupervised disentanglement, and incorporating fairness-aware frameworks. They contribute to a better understanding of the geometry of the feature space in the context of disentangled representations and provide insights for developing models that can separate the underlying explanatory factors in the data.
The pursuit of disentangled representations in deep learning has led to various studies exploring the geometry of the feature space and proposing models to achieve a higher degree of disentanglement. Disentangled representations facilitate the separation of underlying explanatory factors in the data and are characterized by the independence between the latent factors. Recent studies have proposed various mathematical frameworks and models to achieve a higher degree of disentanglement.
6. Conclusions
The multifaceted nature of the geometry of feature space in deep learning models has been elucidated in this comprehensive review. By delving into the intricate relationships between feature spaces and various aspects of deep learning models, such as activation functions, normalization methods, and model architectures, a panoramic view of the current state of the field has been provided in this review. Furthermore, recent studies have been examined, which have contributed significantly to the understanding of manifold structures, curvature, critical points, adversarial robustness, and transfer learning, among other topics.
Throughout this paper, the importance of comprehending the geometric properties of feature spaces has been underscored, as such understanding can lead to the development of novel and efficient deep learning architectures, optimization techniques, and regularization methods. The discussion of challenges and future directions in this paper has shed light on several pertinent research areas, including overparameterized models, unsupervised and semi-supervised learning, interpretable feature space geometry, topological analysis, and multimodal and multi-task learning.
In conclusion, the study of the geometry of feature space in deep learning models is a vast and multidimensional domain that interweaves diverse theoretical and practical perspectives. A profound comprehension of the geometric underpinnings of deep learning models has the potential to pave the way for groundbreaking advancements in artificial intelligence and machine learning. By integrating topological, set-theoretic, and real number analysis methods, researchers can delve deeper into the complexities of feature space geometry and unlock hitherto unexplored facets of deep learning. As the exploration of the frontiers of deep learning continues, it is believed that a holistic understanding of the geometry of feature space will serve as a cornerstone for shaping the future of this dynamic field.



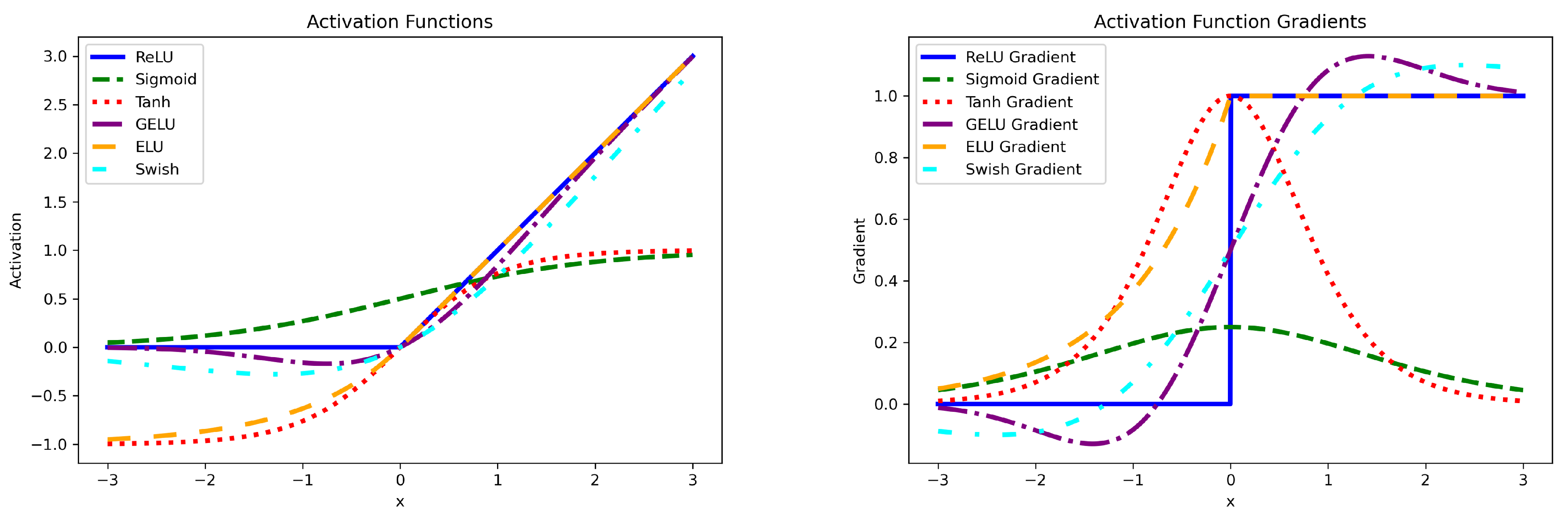

{kind=link}