
Surrogate-Based Physics-Informed Neural Networks for Elliptic Partial Differential Equations †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Surrogate-Based Physics-Informed Neural Networks
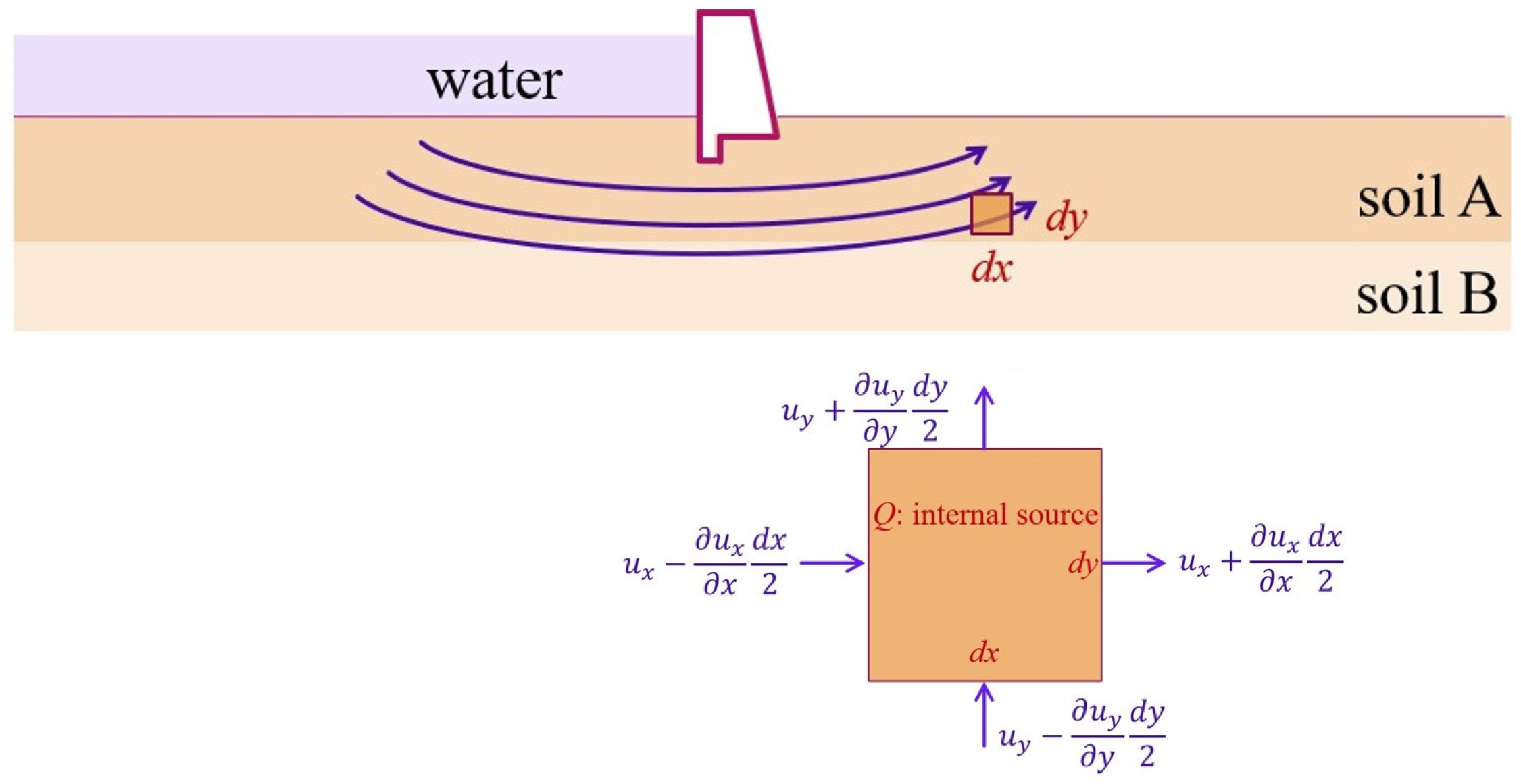
2.1. Conventional Finite Element Method
2.2. Artificial Neural Networks
2.3. Surrogate-Based Physics-Informed Neural Networks (PINNs)
3. Numerical Experiments
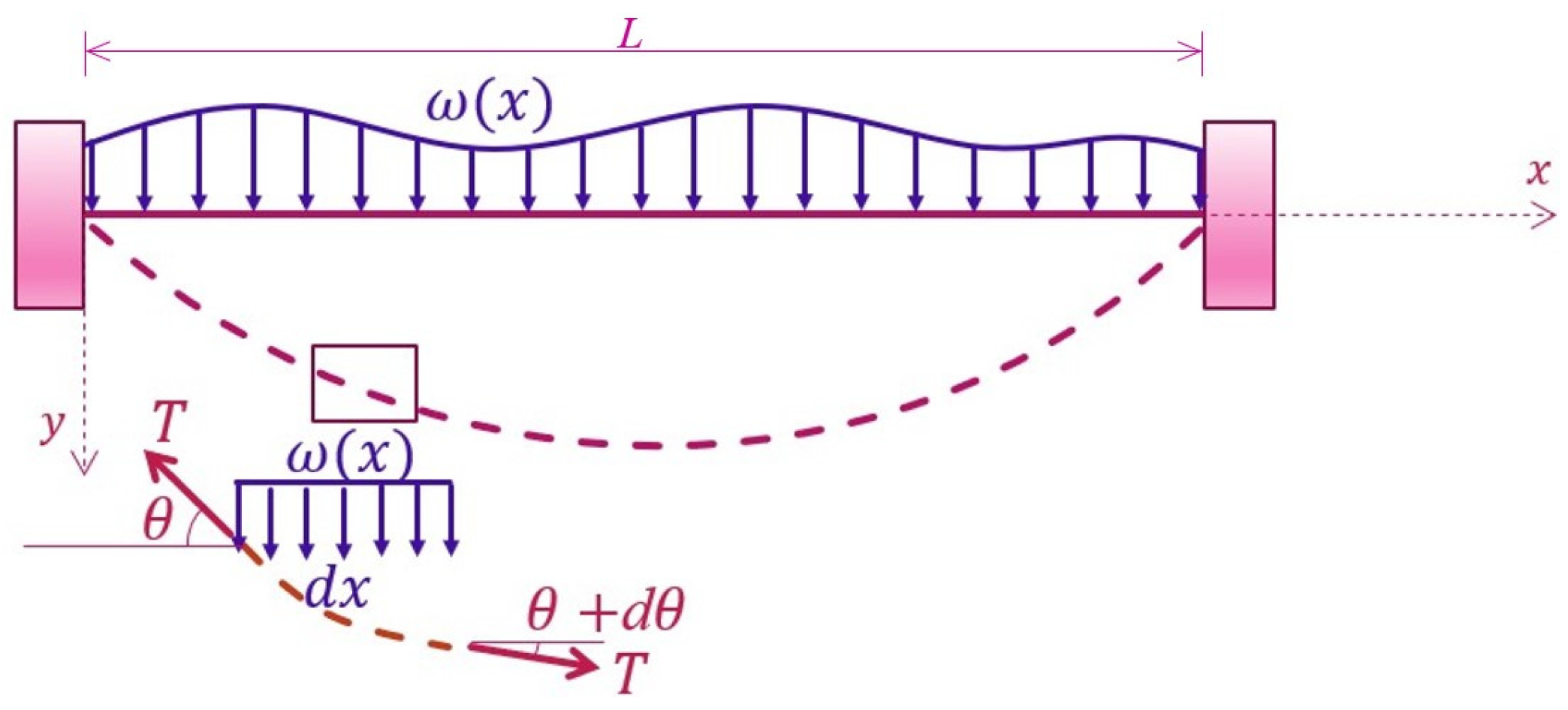
3.1. Tightly Stretched Wire under Loading
3.1.1. Problem Statement
3.1.2. The Finite Element Model
3.1.3. The Surrogate-Based PINN
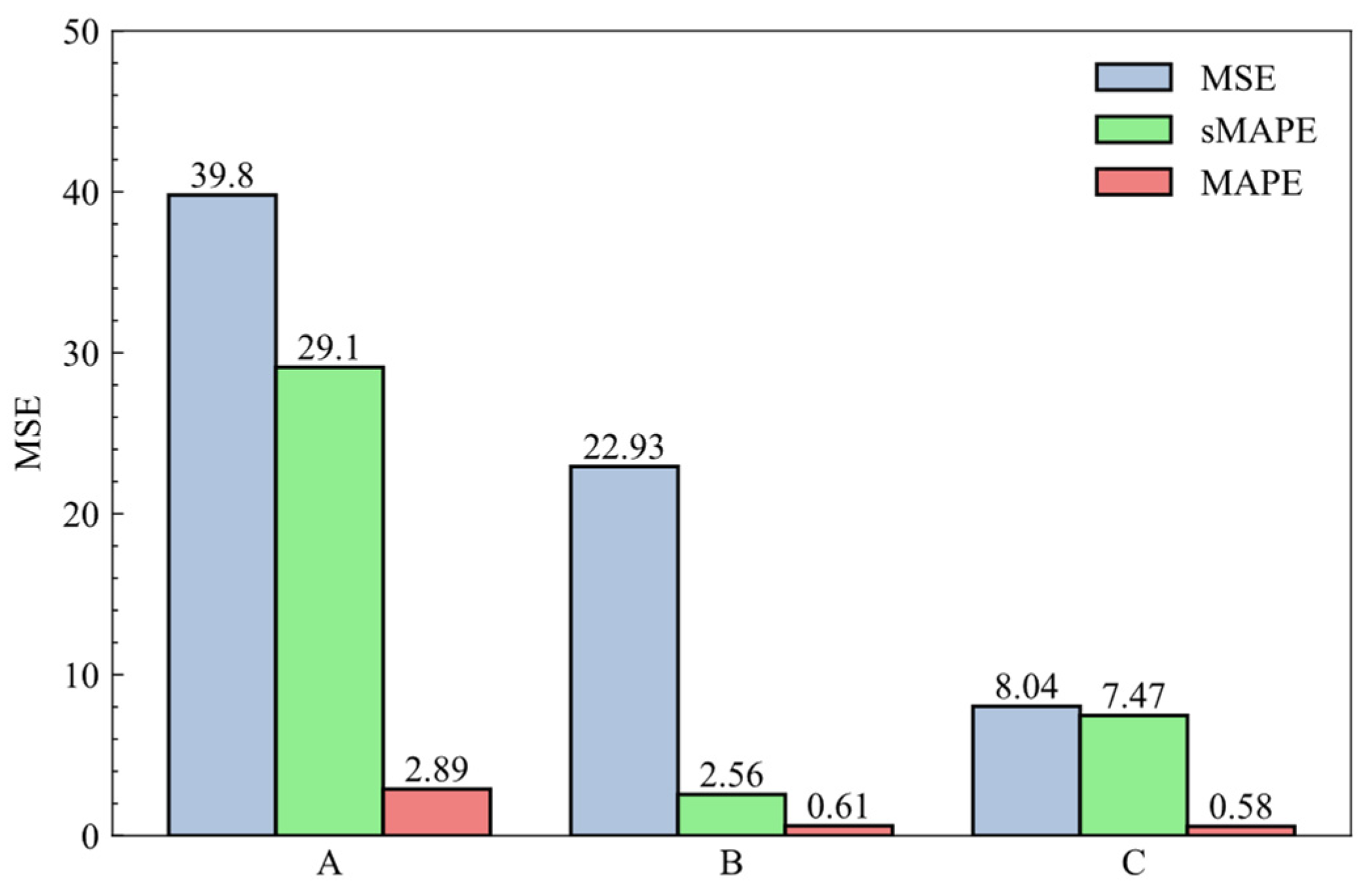
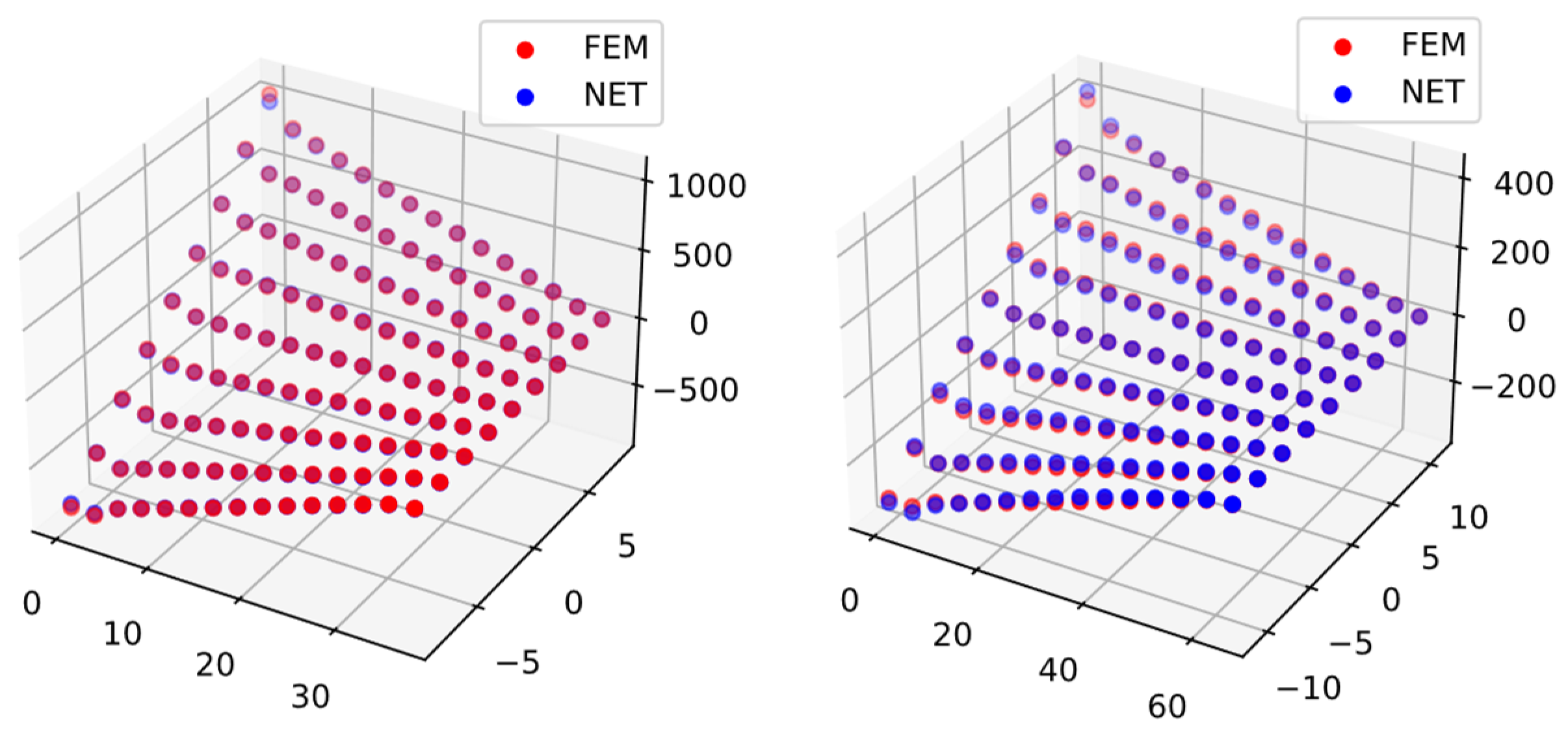
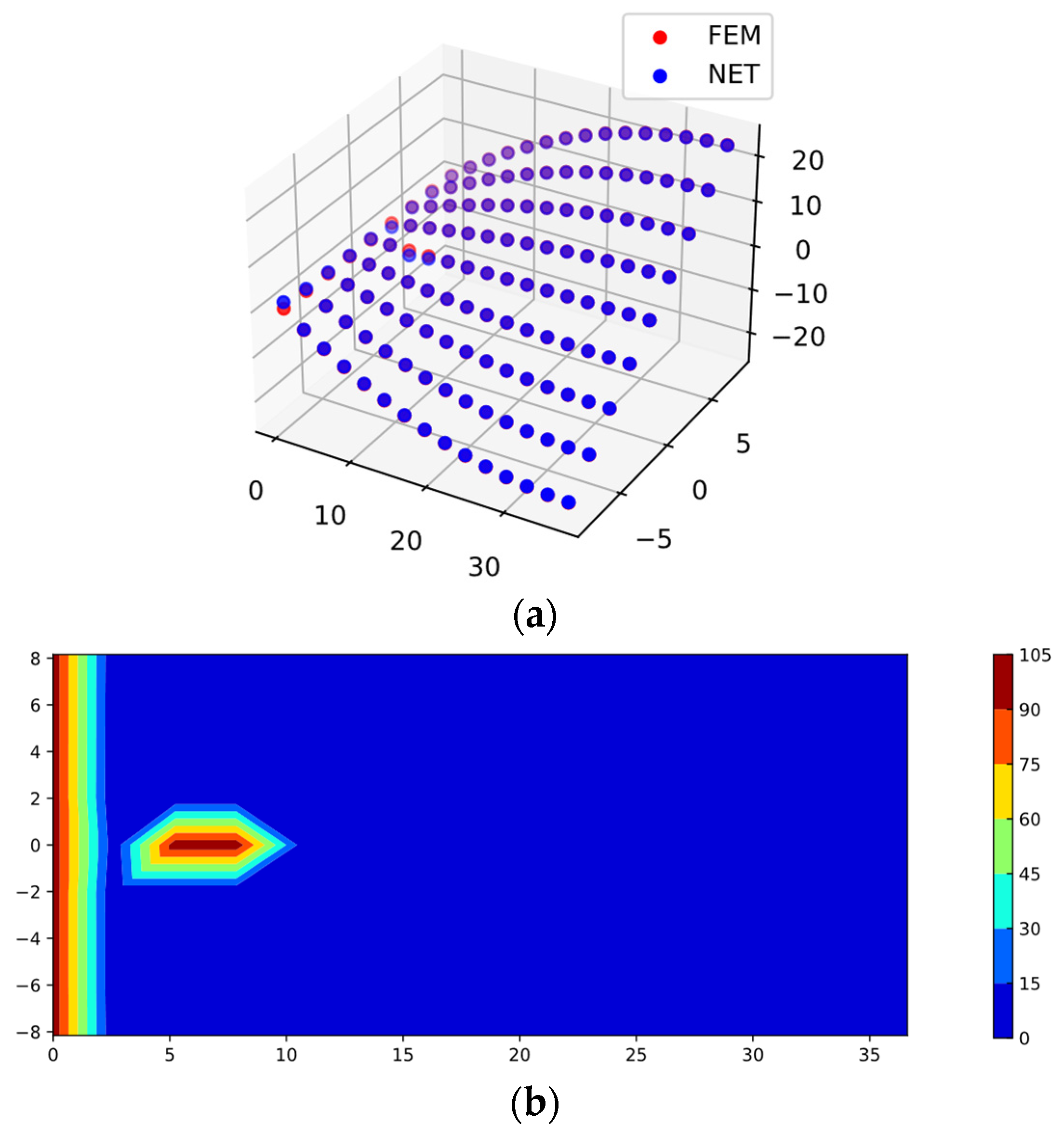
3.1.4. Results and Discussions
3.2. Flow through Porous Media
3.2.1. Problem Statement
3.2.2. The Finite Element Model
3.2.3. The Surrogate-Based PINN
3.2.4. Results and Discussions
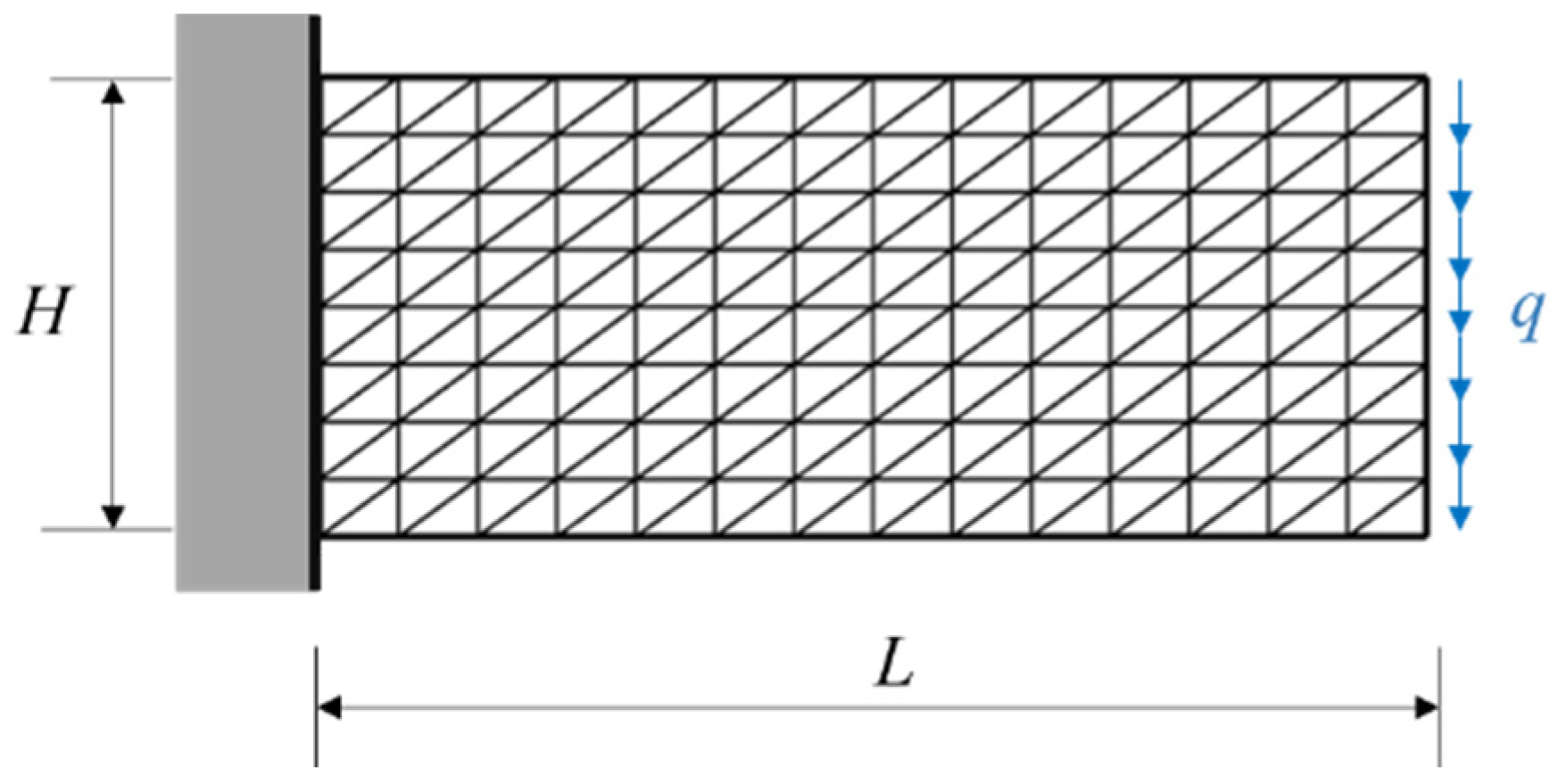
3.3. A Plane Cantilever Beam
3.3.1. Problem Statement
3.3.2. The Finite Element Model
3.3.3. The Surrogate-Based PINN
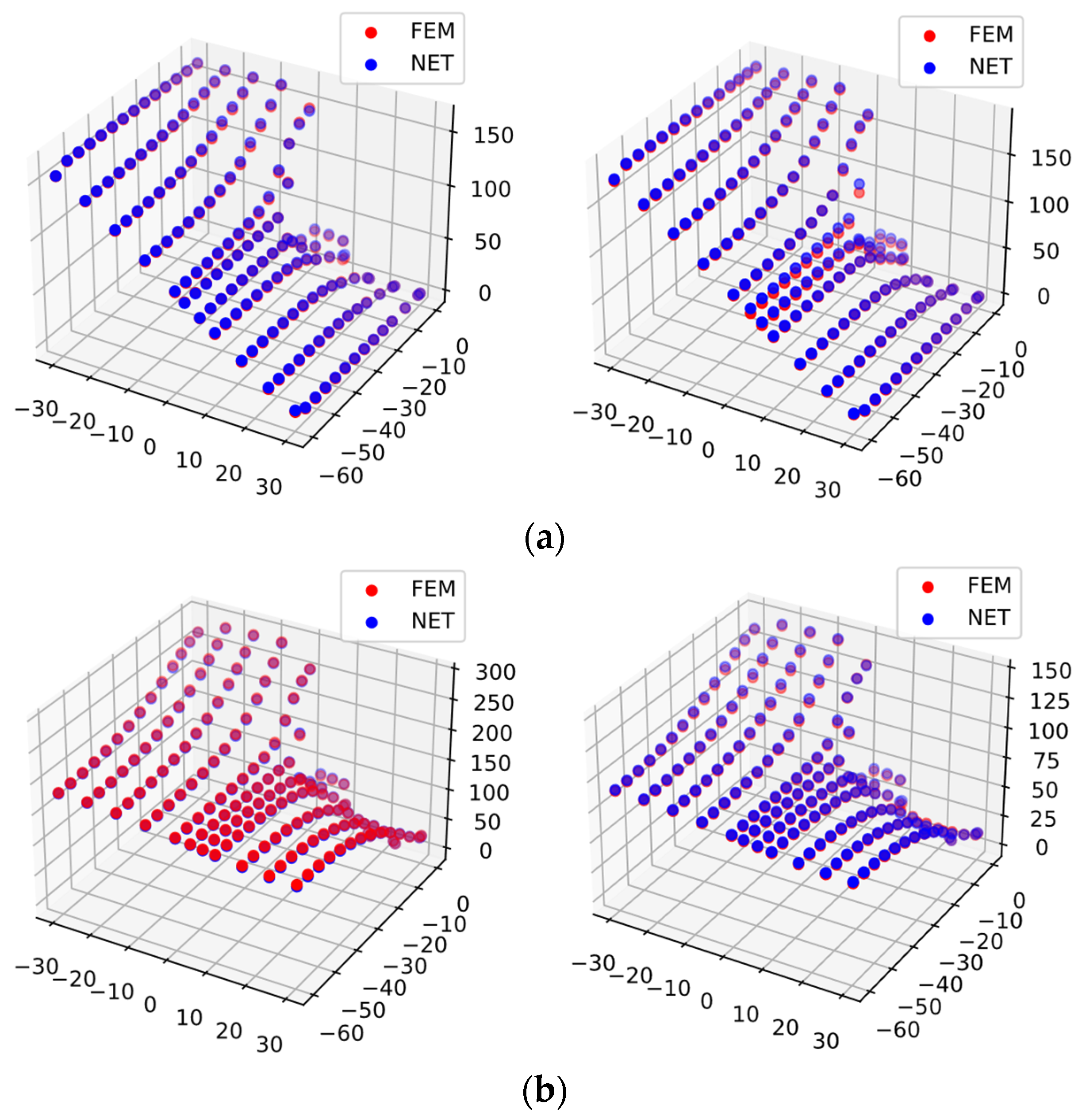
3.3.4. Results and Discussions
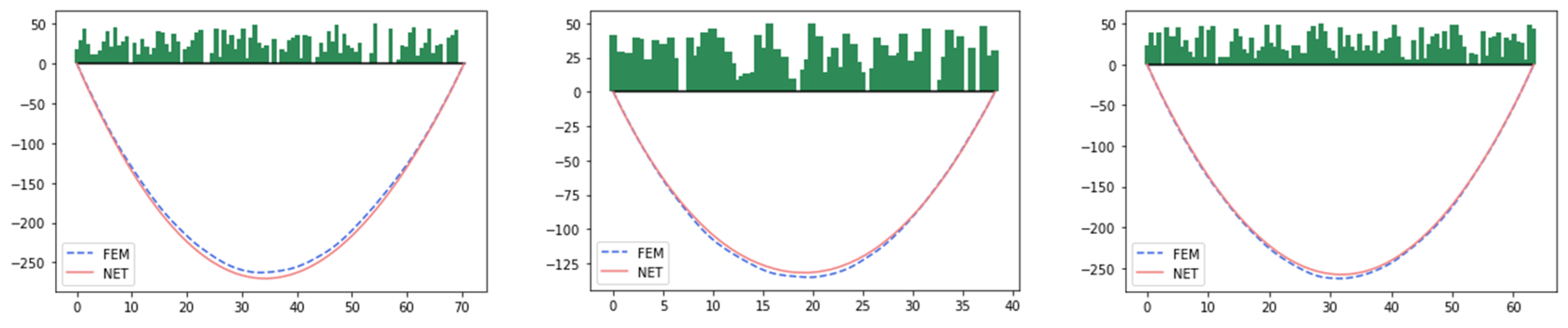
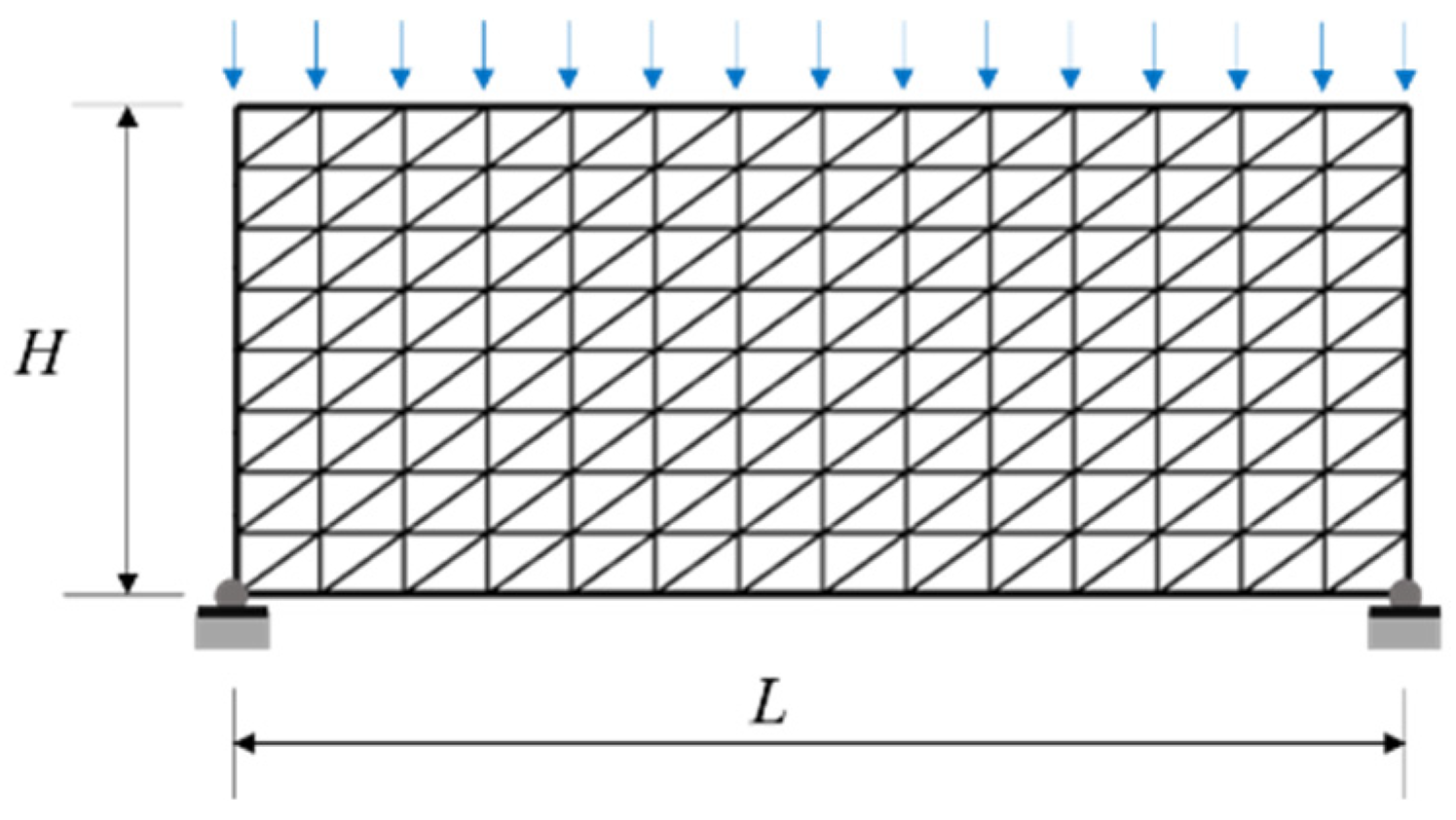
3.4. A Simply Supported Beam
3.4.1. Problem Statement
3.4.2. The Finite Element Model
3.4.3. The Surrogate-Based PINN
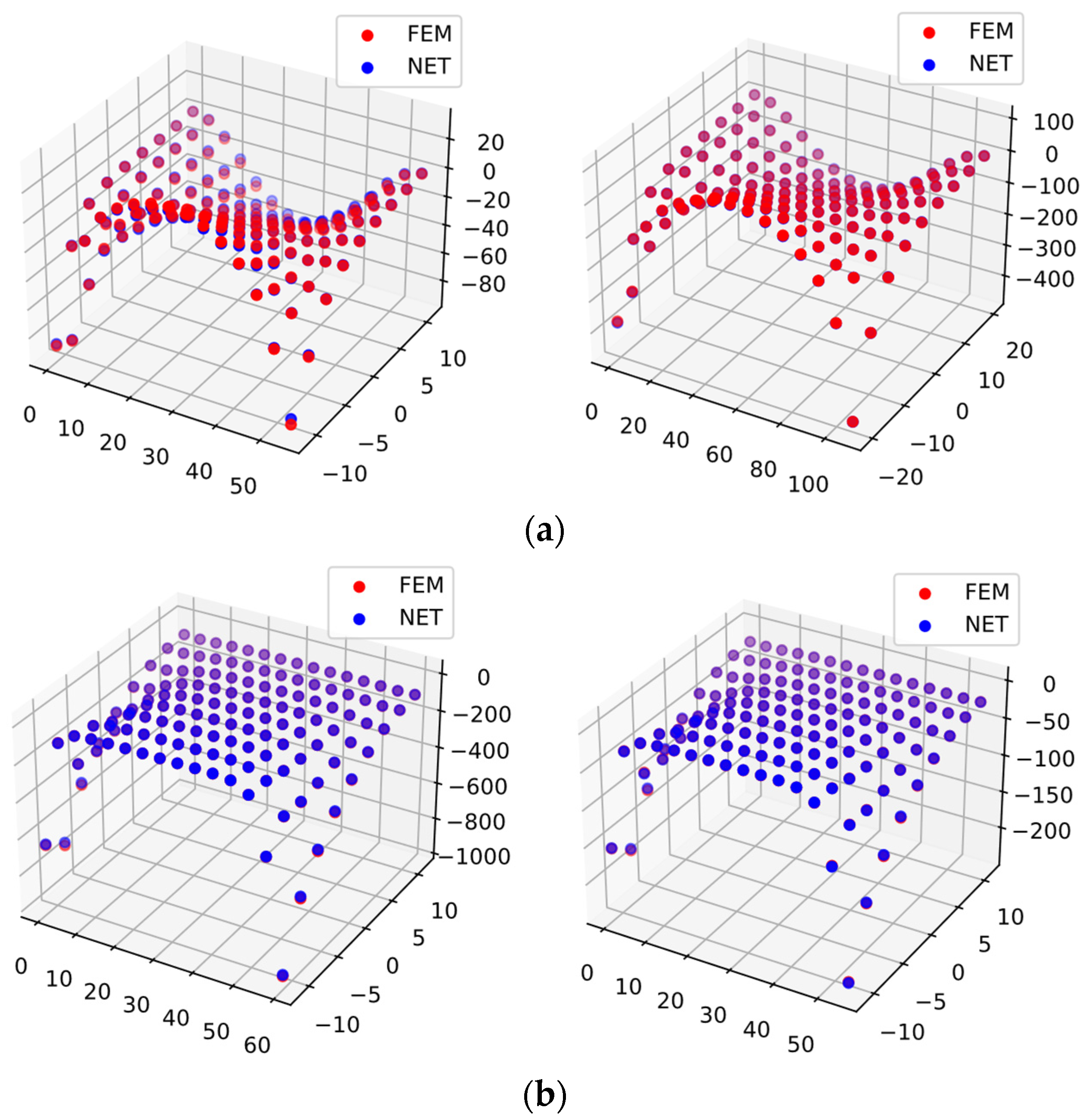
3.4.4. Results and Discussions
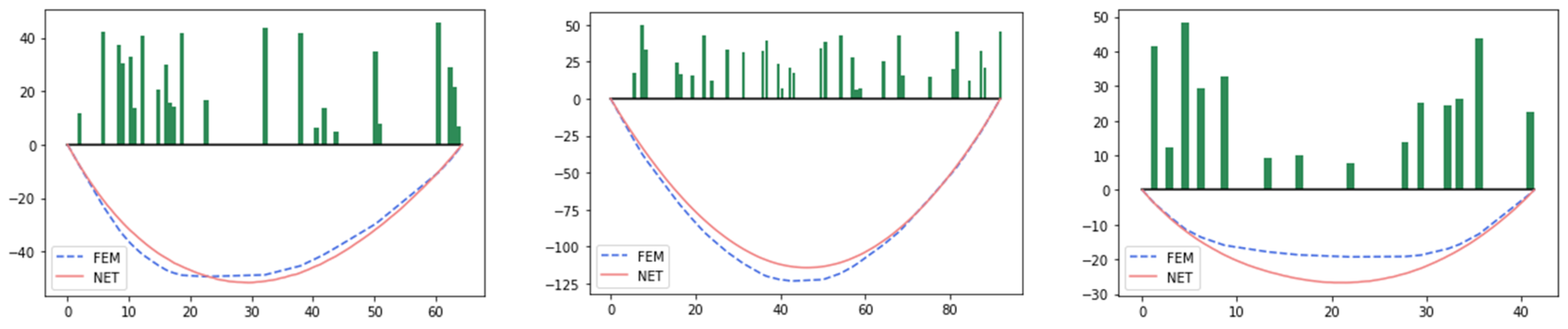
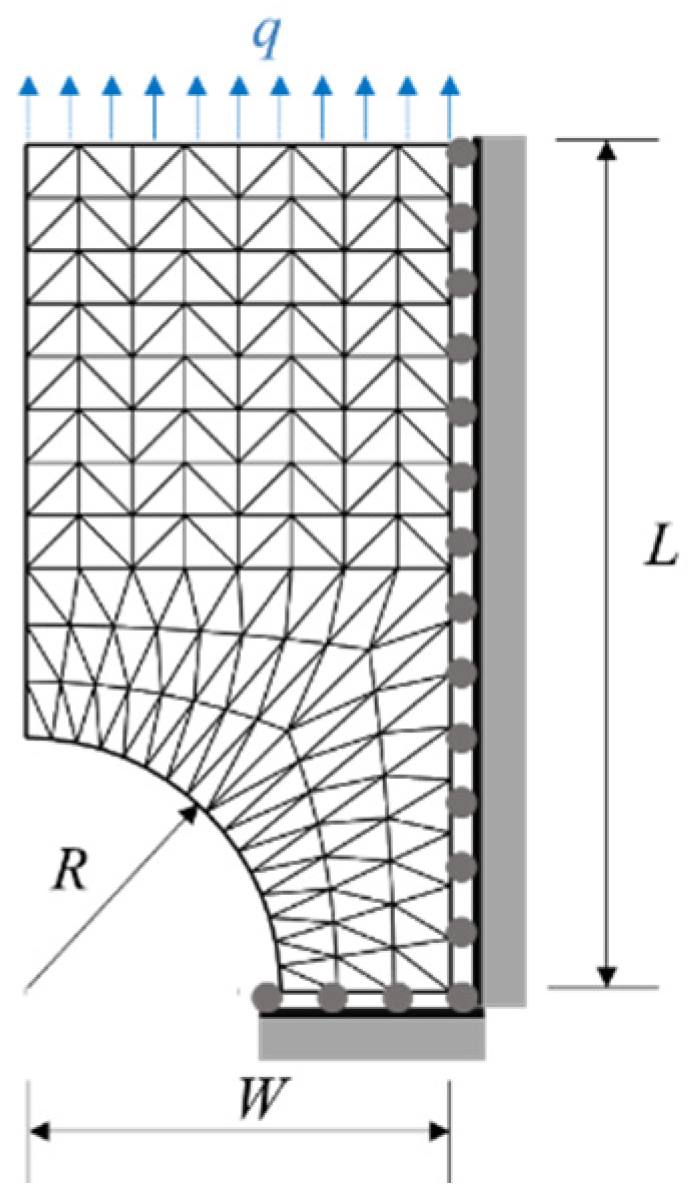
3.5. A Plate with Notch
3.5.1. Problem Statement
3.5.2. The Finite Element Model
3.5.3. The Surrogate-Based PINN
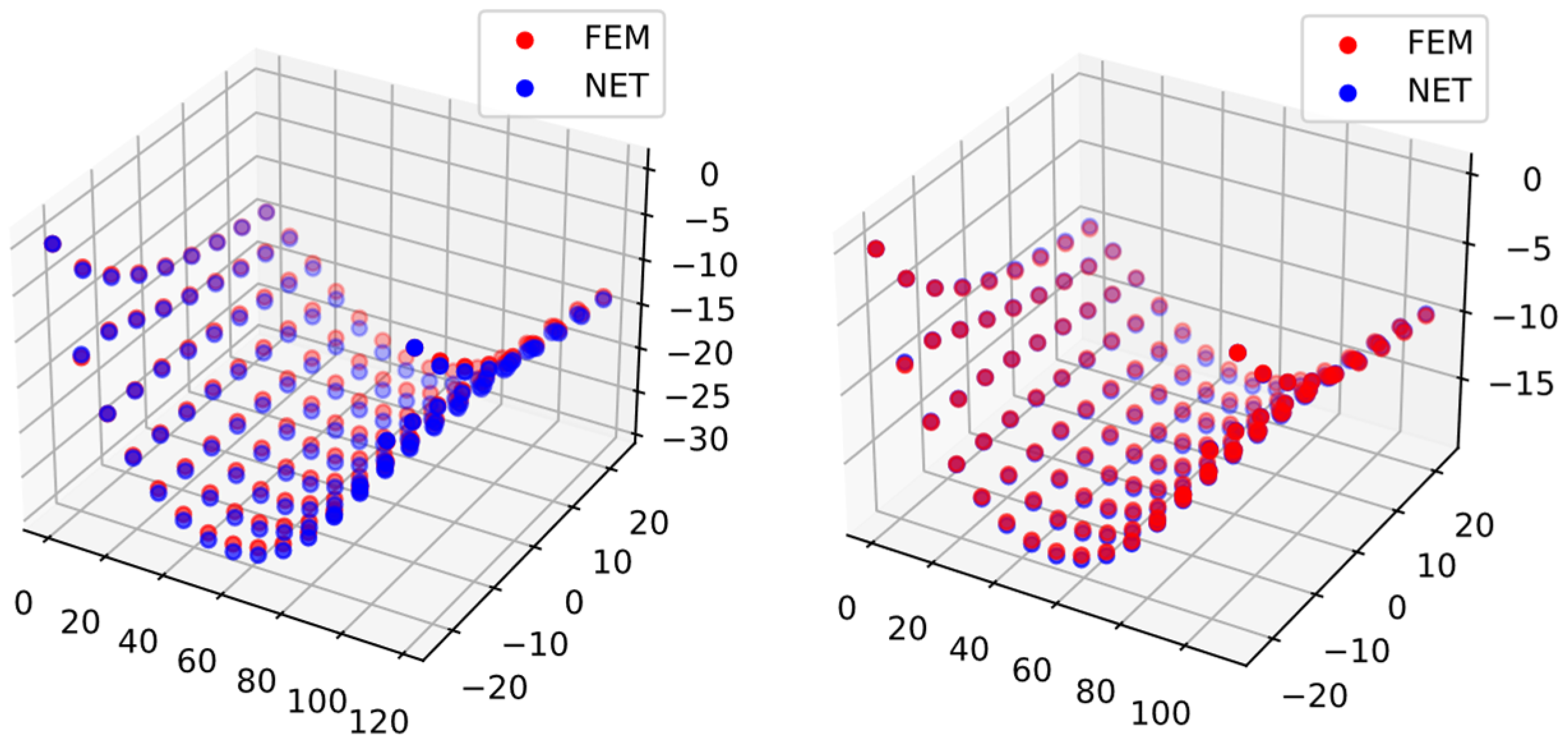
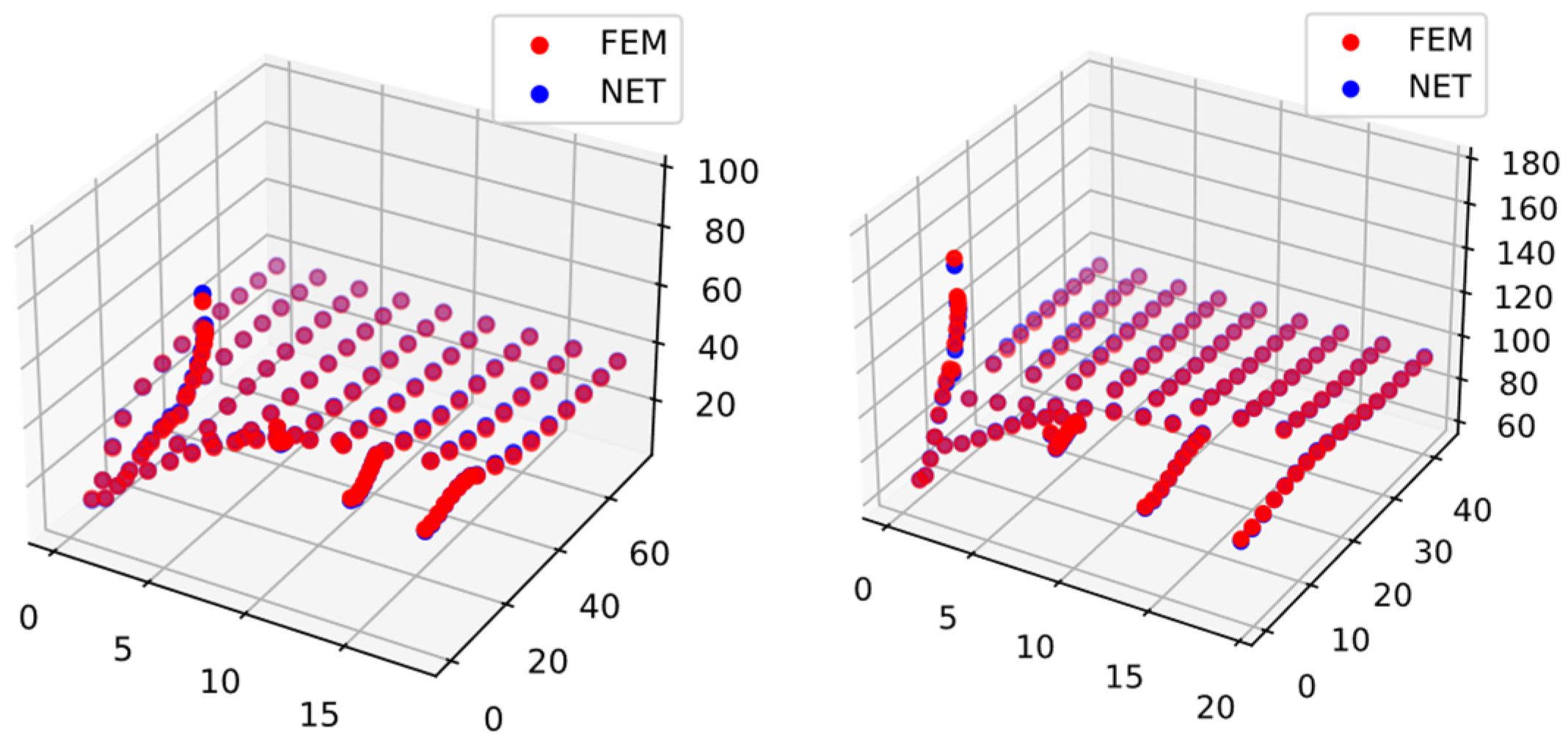
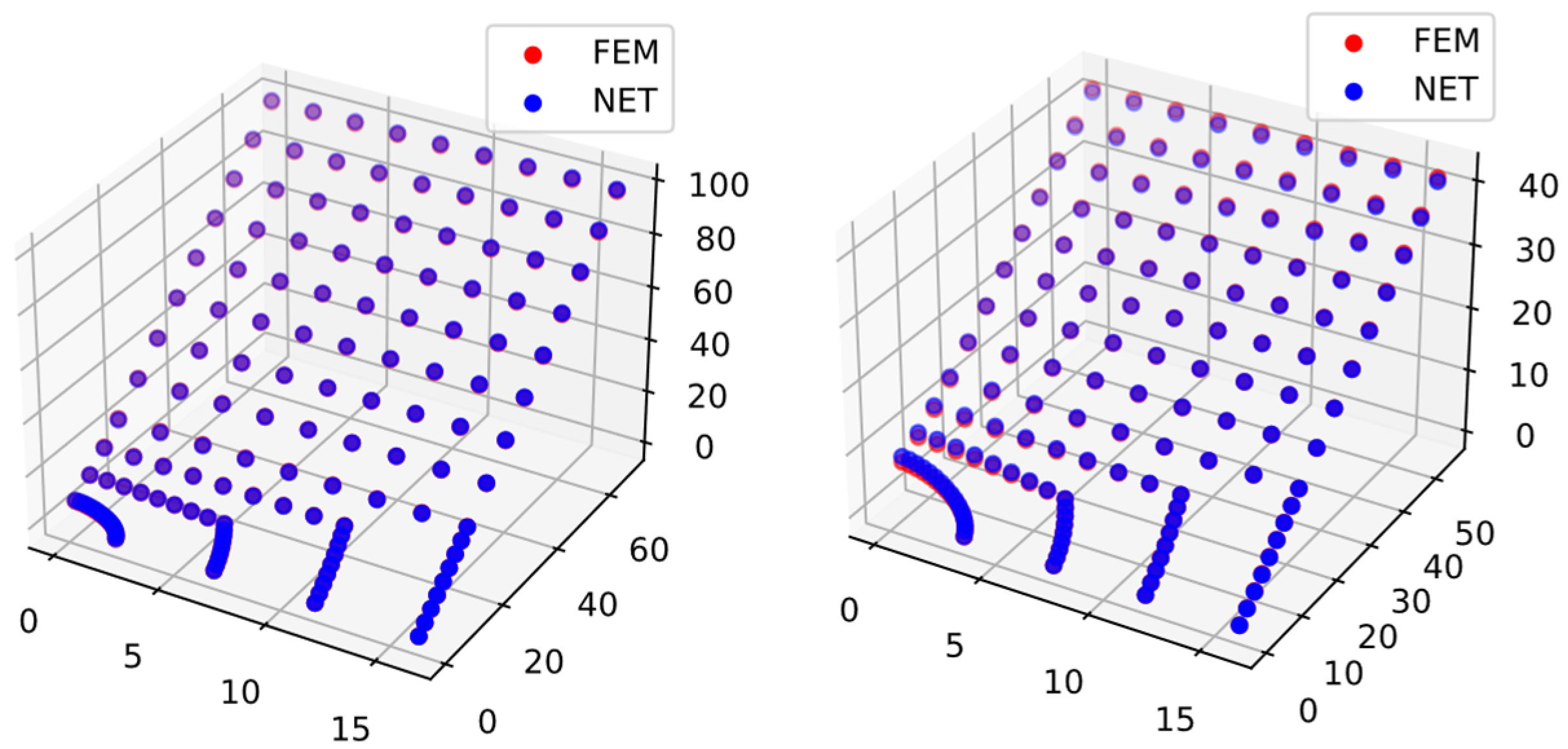
3.5.4. Results and Discussions
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhi, P.; Wu, Y. Finite element quantitative analysis and deep learning qualitative estimation in structural engineering. In Proceedings of the WCCM-XV, APCOM-VIII, Virtual Congress, 31 July 2022. [Google Scholar]
- Wu, Y.; Xiao, J. Implementation of the multiscale stochastic finite element method on elliptic PDE problems. Int. J. Comput. Methods 2017, 14, 1750003. [Google Scholar] [CrossRef]
- Wu, Y.; Xiao, J. The multiscale spectral stochastic finite element method for chloride diffusion in recycled aggregate concrete. Int. J. Comput. Methods 2018, 15, 1750078. [Google Scholar] [CrossRef]
- Wu, Y.; Xiao, J. Digital-image-driven stochastic homogenization for recycled aggregate concrete based on material microstructure. Int. J. Comput. Methods 2019, 16, 1850104. [Google Scholar] [CrossRef]
- Zhi, P.; Wu, Y. On the stress fluctuation in the smoothed finite element method for 2D elastoplastic problems. Int. J. Comput. Methods 2021, 18, 2150010. [Google Scholar] [CrossRef]
- Dissanayake, M.W.M.G.; Phan-Thien, N. Neural-network-based approximations for solving partial differential equations. Commun. Numer. Methods Eng. 1994, 10, 195–201. [Google Scholar] [CrossRef]
- Lagaris, I.E.; Likas, A.; Fotiadis, D.I. Artificial neural networks for solving ordinary and partial differential equations. IEEE Trans Neural. Netw. 1998, 9, 987–1000. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Poggio, T.; Mhaskar, H.; Rosasco, L. Why and when can deep-but not shallow-networks avoid the curse of dimensionality: A review. Int. J. Autom. Comput. 2017, 14, 503–519. [Google Scholar] [CrossRef] [Green Version]
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Raissi, M. Deep hidden physics models: Deep learning of nonlinear partial differential equations. J. Mach Learn Res. 2018, 19, 1–24. [Google Scholar]
- Fang, Z.; Zhan, J. Deep physical informed neural networks for metamaterial design. IEEE Access 2019, 8, 24506–24513. [Google Scholar] [CrossRef]
- Raissi, M.; Yazdani, A.; Karniadakis, G.E. Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science 2020, 367, 1026–1030. [Google Scholar] [CrossRef]
- Yang, L.; Meng, X.; Karniadakis, G.E. B-PINNs: Bayesian physics-informed neural networks for forward and inverse PDE problems with noisy data. J. Comput. Phys. 2021, 425, 109913. [Google Scholar] [CrossRef]
- Leung, W.T.; Lin, G.; Zhang, Z. NH-PINN: Neural homogenization-based physics-informed neural network for multiscale problems. J. Comput. Phys. 2022, 470, 111539. [Google Scholar] [CrossRef]
- Pang, G.; Lu, L.; Karniadakis, G.E. fPINNs: Fractional Physics-Informed Neural Networks. SIAM J. Sci. Comput. 2019, 41, A2603–A2626. [Google Scholar] [CrossRef] [Green Version]
- Pang, G.; D’Elia, M.; Parks, M.; Karniadakis, G.E. nPINNs: Nonlocal physics-informed neural networks for a parametrized nonlocal universal Laplacian operator. Algorithms and applications. J. Comput. Phys. 2020, 422, 109760. [Google Scholar] [CrossRef]
- Jagtap, A.D.; Karniadakis, G.E. Extended physics-informed neural networks (XPINNs): A Generalized Space-Time Domain Decomposition Based Deep Learning Framework for Nonlinear Partial Differential Equations. Commun. Comput. Phys. 2020, 28, 2002–2041. [Google Scholar]
- Haghighat, E.; Raissi, M.; Moure, A. A physics-informed deep learning framework for inversion and surrogate modeling in solid mechanics. Comput. Methods Appl. Mech. Eng. 2021, 379, 113741. [Google Scholar] [CrossRef]
- Lu, L.; Meng, X.; Mao, Z.; Karniadakis, G.E. DeepXDE: A deep learning library for solving differential equations. SIAM Rev. 2021, 63, 208–228. [Google Scholar] [CrossRef]
- Sirignano, J.; Spiliopoulos, K. DGM: A deep learning algorithm for solving partial differential equations. J. Comput. Phys. 2018, 375, 1339–1364. [Google Scholar] [CrossRef] [Green Version]
- Samaniego, E.; Anitescu, C.; Goswami, S. An energy approach to the solution of partial differential equations in computational mechanics via machine learning: Concepts, implementation and applications. Comput. Methods Appl. Mech. Eng. 2020, 362, 112790. [Google Scholar] [CrossRef] [Green Version]
- Liang, L.; Liu, M.; Martin, C.; Sun, W. A deep learning approach to estimate stress distribution: A fast and accurate surrogate of finite-element analysis. J. R. Soc. Interface 2018, 15, 20170844. [Google Scholar] [CrossRef] [Green Version]
- Nourbakhsh, M.; Irizarry, J.; Haymaker, J. Generalizable surrogate model features to approximate stress in 3D trusses. Eng. Appl. Artif. Intell. 2018, 71, 15–27. [Google Scholar] [CrossRef]
- Abueidda, D.W.; Almasri, M.; Ammourah, R. Prediction and optimization of mechanical properties of composites using convolutional neural networks. Compos Struct. 2019, 227, 111264. [Google Scholar] [CrossRef] [Green Version]
- Nie, Z.; Jiang, H.; Kara, L.B. Stress field prediction in cantilevered structures using convolutional neural networks. J. Comput. Inf. Sci. Eng. 2020, 20, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Jiang, H.; Nie, Z.; Yeo, R. StressGAN: A generative deep learning model for two-dimensional stress distribution prediction. J. Appl. Mech 2021, 88, 1–9. [Google Scholar] [CrossRef]
- Lin, S.; Zheng, H.; Han, C. Evaluation and prediction of slope stability using machine learning approaches. Front. Struct. Civ. Eng. 2021, 15, 821–833. [Google Scholar] [CrossRef]
- Tabarsa, A.; Latifi, N.; Osouli, A.; Bagheri, Y. Unconfined compressive strength prediction of soils stabilized using artificial neural networks and support vector machines. Front. Struct. Civ. Eng. 2021, 15, 520–536. [Google Scholar] [CrossRef]
- Le, H.Q.; Truong, T.T.; Dinh-Cong, D.; Nguyen-Thoi, T. A deep feed-forward neural network for damage detection in functionally graded carbon nanotube-reinforced composite plates using modal kinetic energy. Front. Struct. Civ. Eng. 2021, 15, 1453–1479. [Google Scholar] [CrossRef]
- Savino, P.; Tondolo, F. Automated classification of civil structure defects based on convolutional neural network. Front. Struct. Civ. Eng. 2021, 15, 305–317. [Google Scholar] [CrossRef]
- Bekdaş, G.; Yücel, M.; Nigdeli, S.M. Estimation of optimum design of structural systems via machine learning. Front. Struct. Civ. Eng. 2021, 15, 1441–1452. [Google Scholar] [CrossRef]
- Carbas, S.; Artar, M. Comparative seismic design optimization of spatial steel dome structures through three recent metaheuristic algorithms. Front. Struct. Civ. Eng. 2022, 16, 57–74. [Google Scholar] [CrossRef]
- Kellouche, Y.; Ghrici, M.; Boukhatem, B. Service life prediction of fly ash concrete using an artificial neural network. Front. Struct. Civ. Eng. 2021, 15, 793–805. [Google Scholar] [CrossRef]
- Teng, S.; Chen, G.; Wang, S. Digital image correlation-based structural state detection through deep learning. Front. Struct. Civ. Eng. 2022, 16, 45–56. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhi, P.; Wu, Y.; Qi, C.; Zhu, T.; Wu, X.; Wu, H. Surrogate-Based Physics-Informed Neural Networks for Elliptic Partial Differential Equations. Mathematics 2023, 11, 2723. https://doi.org/10.3390/math11122723
Zhi P, Wu Y, Qi C, Zhu T, Wu X, Wu H. Surrogate-Based Physics-Informed Neural Networks for Elliptic Partial Differential Equations. Mathematics. 2023; 11(12):2723. https://doi.org/10.3390/math11122723
Chicago/Turabian StyleZhi, Peng, Yuching Wu, Cheng Qi, Tao Zhu, Xiao Wu, and Hongyu Wu. 2023. "Surrogate-Based Physics-Informed Neural Networks for Elliptic Partial Differential Equations" Mathematics 11, no. 12: 2723. https://doi.org/10.3390/math11122723
APA StyleZhi, P., Wu, Y., Qi, C., Zhu, T., Wu, X., & Wu, H. (2023). Surrogate-Based Physics-Informed Neural Networks for Elliptic Partial Differential Equations. Mathematics, 11(12), 2723. https://doi.org/10.3390/math11122723