1. Introduction and Formulation of the Problem
Whether there is another principle that can generate power-law dependencies without the use of non-integer operators, or whether power-law dependencies follow from the models that have non-integer operators are important questions that require a solution. Fractional calculus is now the most advanced area in mathematics. The characteristics of non-integer operators are the subject of many excellent monographs. These operators make it possible to resolve some difficult mathematical physical properties. Here, we would like to draw attention to Yu. I. Babenko’s monograph [
1], in which he first employed a unique technique for splitting (extraction of the square root) from diffusion equation containing integer operators and nonhomogeneous coefficients. Thanks to this original technique, he was able to find analytical solutions that were not known earlier. It is also appropriate to mention the monographs of Prof. V.V. Uchaikin [
2] and the capital monograph of Prof. S.G. Samko with co-authors [
3], which open a door in new mathematics to young researches. Specialized journals, such as
Fractional Calculus and Applied Analysis (FCAA), have determined the basic trend in the development of this field of mathematics. The development of materials has made it possible to implement non-integer operations such as differentiation and integration in a range of fractional elements [
4]. However, there is currently a weakness in this area of mathematics: there is no justification for the physical/geometrical meaning of these operators in comparison to integer operators, such as the area under the curve and the slope value produced by the first derivative. One should recall the attempts made by RRN, one of the authors of this study, to design a method for averaging a smoothed function over a Cantor (fractal) set. This results in the Riemann–Liouville-type fractional integral [
5,
6]; however, the interpretation of the significance of the various fractional integral types [
7] is far from an explicit and justified interpretation.
Another problem is related to the question formulated above. This problem was formulated also in the papers of J. Sabatier [
8,
9,
10], who noticed that it is necessary to generate a difference between the fractal models generated by non-integer operators and the power-law dependencies that exist irrespective of these proposed models. In a book [
11] written by one of the authors, the way in which the fractional calculus could be naturally associated with fractional-order signal processing was shown.
This study aims to demonstrate that the self-similar principle does in fact produce power-law dependencies and complex conjugated addings. We only have the complex-conjugated addings for the unit root. We also wish to demonstrate that any randomly generated curve with a clearly defined trend that is compressed in ξ times maintains its self-invariance. This finding enables the fitting function to be derived, and it actually creates a new “information space” or platform, in addition to the Fourier transformation and the z-transform, two operations that are frequently applied in the field of current signal processing. When the fitting function produced from a simple model is absent, this self-similarity principle enables the fitting of a large variety of random functions.
The content of the paper is organized as follows. In the second chapter, we develop the general theory of the fractional power-law elements when some roots are degenerated. In
Section 3, we show the algorithm for the treatment of the functions that exhibit the self-similar property. Two examples are considered. In the conclusion of the final section, we discuss the obtained results and outline the perspectives of further research.
2. General Theory of the Fractional Power-Law Elements, The Influence of the Degenerated Terms
It is well known from the grounds of fractal geometry [
12] that the Weierstrass–Mandelbrot function for different values of scales and the range of the fractal dimension 1 <
D < 2 is self-similar. This function
W(
t) for further purposes is convenient to generalize and represent in the following form:
Here,
is a complex value and the newly defined parameter
b in the second line can accept any arbitrary value (positive, negative or even complex). Parameter ξ defines a scaling parameter and ϕ is the phase of a complex value, t is a temporal variable. Here, the sum
S(
z) is defined for any variable, including time, frequency, etc. The complex function
f(
z) figuring in (1) has the following asymptotic decompositions:
Considering the conditions imposed above, one can obtain the following relationship from (1):
This sum was analyzed in paper [
13]. Four cases (when the two last terms in (3) become negligible) are possible:
Case (a) when b, ξ > 1. The contribution of the two terms in (3) becomes negligible when ξ > b.
Case (b) when b, ξ < 1. The contribution of the two terms in (3) becomes negligible when ξ < b.
Case (c) when b > 1, ξ < 1. For this case, it is necessary that bξ < 1.
Case (d) when b < 1, ξ > 1. For this case, it is necessary that bξ > 1.
For
b = 1, the contribution of the last two terms is valid also, if the function
f(
z) keeps its limiting values in accordance with the decompositions (2). The numerical verification of the real part of the function
S(
z) was realized also in paper [
13]. Therefore, one can approximately write the following:
Let us highlight the case in which
b = 1. In this case, we obtain the simplest functional equation using the solution expressed in the form of log-periodic decomposition:
Here, Pr(lnz) determines the solution of the functional Equation (4) expressed in the form of a log-periodic function at b = 1.
Attentive analysis shows that scaling Equation (4) is the
K-th fold degenerated. Let us write this equation in the following form:
Here, for convenience, we introduce the scaling operator Dξ. Let us explain the meaning of Equation (6).
If we neglect the existing error between both sides of (4), then it implies that the error of the first order ε
1 equals zero. What happens if we take into account the error of the first order (ε
1 ≠ 0) and neglect the error of the second order ε
2 = 0? In this case, we have to continue the scaling property and write two equations in the first line of (6). If these small remnant values ε
2 in (6) equal each other, then one can write the following scaling equation for the sum
S(
z)
Continuing these scaling manipulations in Equation (6), one can conclude that the simple Equation (4) is equivalent to the scaling equation
and that, therefore, it is the
K-th fold degenerated. Here, we introduce the fluctuations in the
K-th-order ε
K. Usually, many researchers, in attempts to detect the power-law fractal element, limit themselves by the simplest case (4) and take into account the fluctuations in the first-order ε
1. However, the solution of the functional Equation (8) prompts some essential corrections. The solution of the functional Equation (8) for the
K-th-fold degenerated case can be written in the following form [
14]:
For practical purposes, it is sufficient to take into account at least the case
K = 2 and the fluctuations in the second-order ε
2. Log-periodic function Pr(lnz) is defined by Equation (5).
Equation (10) determines an important correction for the single power-law fractal element that has not been taken into account by many researchers working in this area. Attentive analysis shows that solution (10) admits further generalization. Let us rewrite (10) in the following form:
The substitution of this solution into Equation (7) and the requirement that there is only one root equal to
r = ν leads to the following condition:
where
d coincides with any arbitrary number
d ≠ 0. Equation (10) represents a partial case when
b1 = 1 and
d = 3. Condition (12) for any
K looks cumbersome and, therefore, is not given. Solution (11) for the root ν ≠ 1 and
K = 2 can be used as the generalized fitting function for the detection of possible corrections in the fitting of measured data related to the detection of the power-law fractal element, when the fluctuations in the second-order ε
2 become important. Below, this function will be used for the case of ν = 1 for the fitting of a wide class of random functions that have a clearly expressed trend. These preliminary evaluations allow other important steps to be undertaken and more complex cases to be considered. Let us consider now two independent sums similar to those written in (1). We suppose also that the similar evaluations made above allow the following combinations to be written:
By excluding unknown sums
S1,2(
z) from the first two lines and substituting them into equation
we obtain the following functional equation:
Using the scaling operator
Dξ defined above, one can represent the functional Equation (15) in a more compact form with the corresponding solution:
However, the calculations show clearly that solution (16) is not complete. This solution does not take into account the degeneration of the corresponding roots
r1,2. With the help of scaling operator
Dξ, it is very easy to take into account the influence of the degeneration effect and the corresponding fluctuations/corrections
of the (
K1 +
K2) order. Because of the linearity of the corresponding functional equations, one can write a more general functional equation:
This solution takes into account the degeneration effect that has a place for two roots
ν1 and ν
2. For practical purposes, it is useful to write down the case
K1,2 = 2. Taking into account Equation (11), one can approximately write the following:
Solution (18) takes into account the fluctuations in the second order and can be used for fitting purposes related to the detection of a linear combination of a couple of power-law exponents. These calculations allow the general expressions to be written for a combination of the roots
r1,
r2, …,
rs, which have different degeneration degrees. Collecting all the calculations made above for different partial cases, one can write the following and homogeneous (when the right-hand of this equation equals zero) functional equation:
This is written for the case in which each root
rl (
l = 1, 2, …,
s) has its own degree of degeneration
Kl. The solution of the functional equation for the degeneration case can be written in the complete analogy using Equation (17), as follows:
In the conclusion of this section, one can notice the tight analogy between the sums figuring in (1) and the product:
In the contrast of the previous asymptotic behavior (2), we suppose that the function
f(
z) has the following decompositions for small and large values of
z:
Therefore, for different values of ξ, we obtain the following from (21):
Equation (23) is similar to Equation (4), and, therefore, all mathematical manipulations applied earlier to (4) are valid also to Equation (23). A more detailed consideration of the product (21), especially the linear combination of similar products, such as (13), merits separate research. Unfortunately, we do not have real experimental data related to the verification of the proposed theory that is outlined in this section.
The tentative results obtained in this theoretical section enable more general conclusions that can be propagated for any fitting purposes to be made. Let us represent the conventional regression problem in the following form:
Following the roots of quantum mechanics, the second line in (24) is represented in the operator form.
On the right-hand side, we define again ε
1 as the errors/remnants of the first order. If we want to take into account the errors of the second order, it is necessary to apply the left-side operator twice, taking into account the fact that operators
y and
f do not commute with each other. It is easy to see that the commutator [
y,
f](
x) =
y(
f(
x)) −
f(
y(
x) ≠ 0. Therefore, we obtain the following:
Opening these operators, one can present (25) in the conventional form:
Therefore, in order to take into account more accurate fluctuations in the second order, it is necessary to make measurements presented by two terms in (26), while the other two terms can be evaluated theoretically. This new Formula (25) allows the remnant fluctuations in the
K-th order to be taken into account if one rewrites (25) in the following form:
The authors do hope that this new and important aspect of regression analysis can find wide application in attempts to fit important experiments when the remnant functions or errors of the second, third, etc., play an important role.
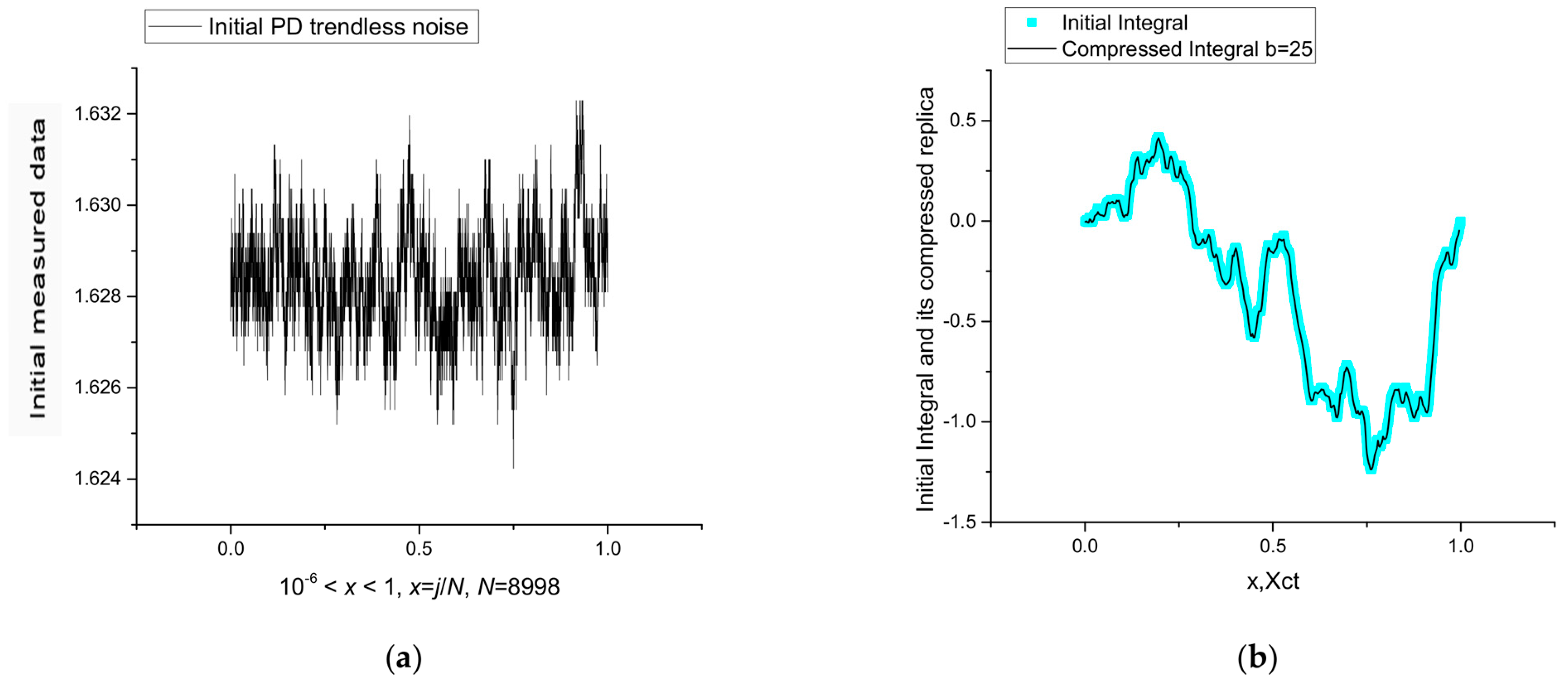
In the next section, we want to prove that many random curves (do not have the proposed model for their fitting) with, however, a clearly expressed trend are self-similar and that they can be accurately fitted using the fitting Function (11), when the influence of the degeneration terms, at least for K = 2, becomes essential.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}