
Modeling Asymmetric Volatility: A News Impact Curve Approach

 ,
,  , , , and
, , , and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. The ARCH and GARCH Models
2.2. EGARCH Model
2.3. GJR-GARCH Model
2.4. APARCH Model
2.5. ARCH-in-Mean
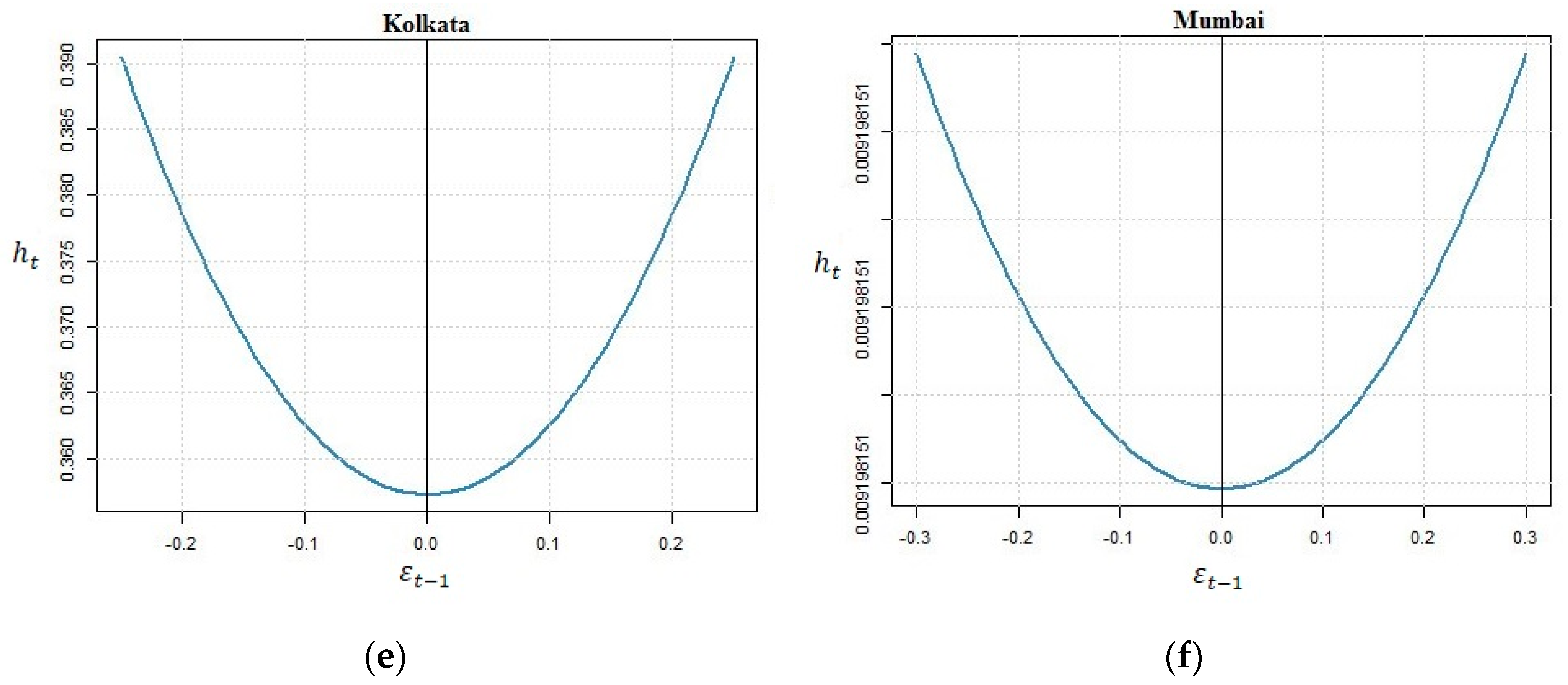
2.6. The News Impact Curve (NIC)
2.7. Data Description
2.8. Criteria for Selecting Order of ARMA Model
2.9. Validation of Forecasts
3. Results and Discussion
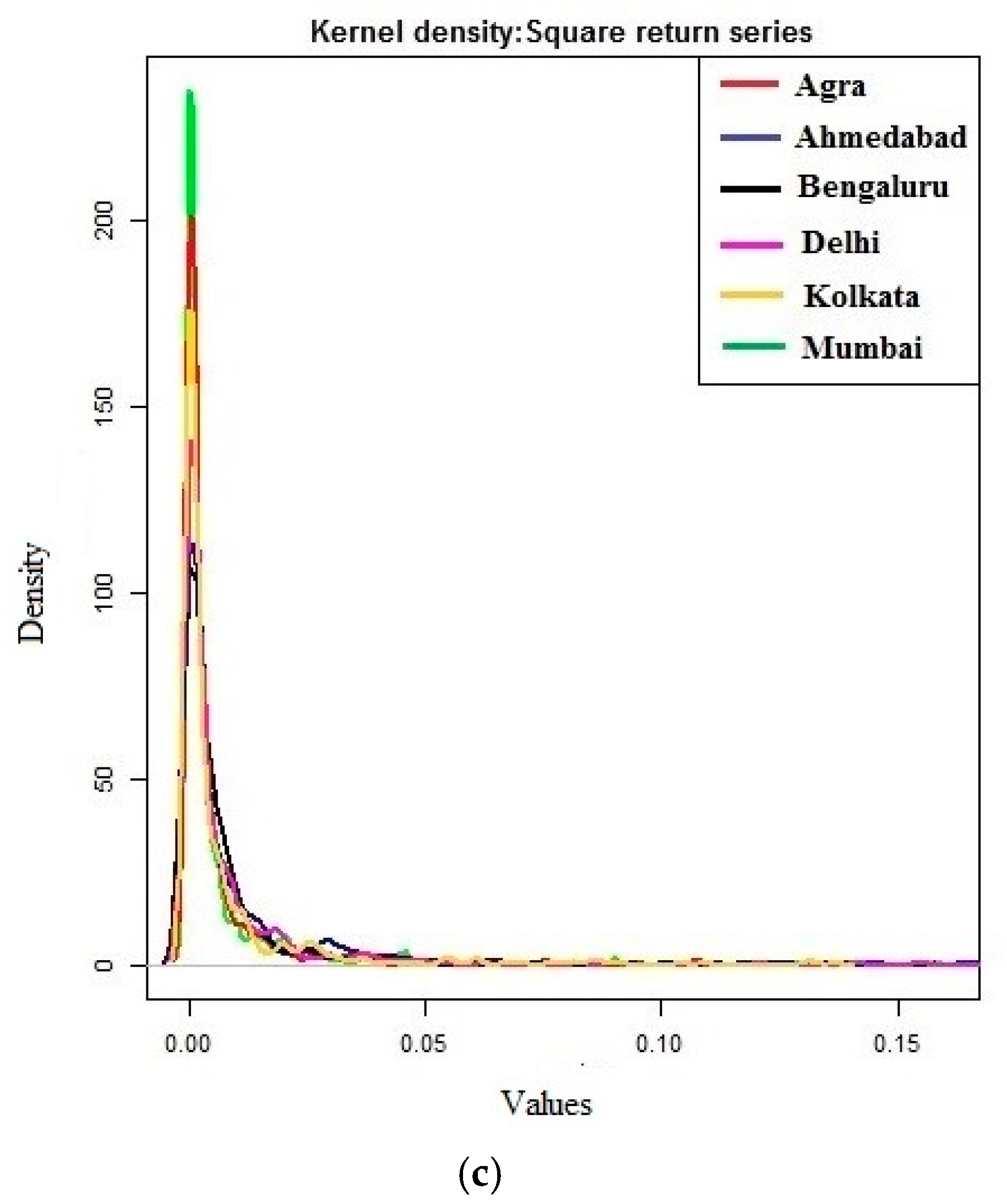
3.1. Descriptive Statistics
3.2. Test for Normality
3.3. Test for Stationarity
3.4. Autocorrelation Function (ACF) and Partial Autocorrelation Function (PACF)
3.5. Fitting of Models
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wijesinha-Bettoni, R.; Mouillé, B. The Contribution of Potatoes to Global Food Security, Nutrition and Healthy Diets. Am. J. Potato Res. 2019, 96, 139–149. [Google Scholar] [CrossRef]
- Burlingame, B.; Mouillé, B.; Charrondière, R. Nutrients, Bioactive Non-Nutrients and Anti-Nutrients in Potatoes. J. Food Compos. Anal. 2009, 22, 494–502. [Google Scholar] [CrossRef]
- Islam, M.M.; Naznin, S.; Naznin, A.; Uddin, M.N.; Amin, M.N.; Rahman, M.M.; Tipu, M.M.H.; Alsuhaibani, A.M.; Gaber, A.; Ahmed, S. Dry Matter, Starch Content, Reducing Sugar, Color and Crispiness Are Key Parameters of Potatoes Required for Chip Processing. Horticulturae 2022, 8, 362. [Google Scholar] [CrossRef]
- Karali, B.; Thurman, W.N. Components of grain futures price volatility. J. Agric. Resour. Econ. 2010, 35, 167–182. [Google Scholar]
- Bohl, M.T.; Siklos, P.L.; Wellenreuther, C. Speculative activity and returns volatility of Chinese agricultural commodity futures. J. Asian Econ. 2018, 54, 69–91. [Google Scholar] [CrossRef]
- Haase, M.; Zimmermann, Y.S.; Zimmermann, H. Permanent and transitory price shocks in commodity futures markets and their relation to speculation. Empir. Econ. 2019, 56, 1359–1382. [Google Scholar] [CrossRef]
- Bandyopadhyay, A.; Bhowmik, S.; Rajib, P. Wavelet-based analysis of guar futures in India: Did we kill the golden goose? J. Agribus. Dev. Emerg. Econ. 2020, 12, 104–125. [Google Scholar] [CrossRef]
- Staugaitis, A.J.; Vaznonis, B. Short-Term Speculation Effects on Agricultural Commodity Returns and Volatility in the European Market Prior to and during the Pandemic. Agriculture 2022, 12, 623. [Google Scholar] [CrossRef]
- Saxena, R.; Singh, N.P.; Balaji, S.J.; Ahuja, U.; Kumar, R.; Joshi, D. Doubling Farmers’ Income in India by 2022-23: Sources of Growth and Approaches. Agric. Econ. Res. Rev. 2017, 30, 265–277. [Google Scholar] [CrossRef] [Green Version]
- Algieri, B. Fast & furious: Do psychological and legal factors affect commodity price volatility? World Econ. 2020, 44, 980–1017. [Google Scholar]
- Box, G.E.P.; Jenkins, G. Time Series Analysis, Forecasting and Control; Holden-Day: San Francisco, CA, USA, 1970. [Google Scholar]
- Paul, R.K.; Prajneshu; Ghosh, H. GARCH Nonlinear Time Series Analysis for Modeling and Forecasting of India’s Volatile Spices Export Data. J. Indian Soc. Agric. Stat. 2009, 63, 123–131. [Google Scholar]
- Paul, R.K.; Ghosh, H.; Prajneshu. Development of out-of-sample forecast formulae for ARIMAX-GARCH model and their application. J. Indian Soc. Agric. Stat. 2014, 68, 85–92. [Google Scholar]
- Paul, R.K.; Bhardwaj, S.P.; Singh, D.R.; Kumar, A.; Arya, P.; Singh, K.N. Price Volatility in Food Commodities in India- An Empirical Investigation. Int. J. Agric. Stat. Sci. 2015, 11, 395–401. [Google Scholar]
- Paul, R.K. ARIMAX-GARCH-WAVELET model for forecasting volatile data. Model Assist. Stat. Appl. 2015, 10, 243–252. [Google Scholar] [CrossRef]
- Statnik, J.-C.; Verstraete, D. Price dynamics in agricultural commodity markets: A comparison of European and US markets. Empir. Econ. 2015, 48, 1103–1117. [Google Scholar] [CrossRef]
- Baur, D.G.; Dimpfl, T. The asymmetric return-volatility relationship of commodity prices. Energy Econ. 2018, 76, 378–387. [Google Scholar] [CrossRef]
- da Silveira, R.L.F.; dos Santos Maciel, L.; Mattos, F.L.; Ballini, R. Volatility persistence and inventory effect in grain futures markets: Evidence from a recursive model. Rev. Adm. 2017, 52, 403–418. [Google Scholar] [CrossRef]
- Ghosh, H.; Paul, R.K.; Prajneshu. The GARCH and EGARCH Nonlinear Time-Series Models for Volatile Data: An Application. J. Stat. Appl. 2010, 5, 177–193. [Google Scholar]
- Paul, R.K.; Das, T.; Panwar, S.; Paul, A.K.; Bhar, L.M. Volatility and spillover in onion prices in major markets of Karnataka, India. Indian J. Agric. Mark. 2019, 33, 65–76. [Google Scholar]
- Paul, R.K.; Rana, S.; Saxena, R. Effectiveness of price forecasting techniques for capturing asymmetric volatility for onion in selected markets of Delhi. Indian J. Agric. Sci. 2016, 86, 303–309. [Google Scholar]
- Rakshit, D.; Paul, R.K.; Panwar, S. Asymmetric Price Volatility of Onion in India. Indian J. Agric. Econ. 2021, 76, 245–260. [Google Scholar]
- Engle, R.F. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef] [Green Version]
- Taylor, S.J. Modeling Financial Time Series; John Wiley & Sons: Chichester, UK, 1986. [Google Scholar]
- Nelson, D.B. Conditional heteroskedasticity in asset returns: A new approach. Econometrica 1991, 59, 347–370. [Google Scholar] [CrossRef]
- Glosten, L.R.; Jagannathan, R.; Runkle, D.E. On the relation between the expected value and the volatility of the nominal excess return on stocks. J. Financ. 1993, 48, 1779–1801. [Google Scholar] [CrossRef]
- Ding, Z.; Granger, C.W.J.; Engle, R.F. A long memory property of stock market returns and a new model. J. Empir. Financ. 1993, 1, 83–106. [Google Scholar] [CrossRef]
- Engle, R.F.; Lilien, D.M.; Robins, R.P. Estimating time varying risk premia in the term structure: The ARCH-M model. Econometrica 1987, 55, 391–407. [Google Scholar] [CrossRef]
- Manera, M.; Nicolini, M.; Vignati, I. Modelling futures price volatility in energy markets: Is there a role for financial speculation? Energy Econ. 2016, 53, 220–229. [Google Scholar] [CrossRef]
- Du, X.; Dong, F. Responses to market information and the impact on price volatility and trading volume: The case of Class III milk futures. Empir. Econ. 2016, 50, 661–678. [Google Scholar] [CrossRef]
- Engle, R.F.; Ng, V.K. Measuring and testing the impact of news on volatility. J. Financ. 1993, 48, 1749–1778. [Google Scholar] [CrossRef]
- Agmarknet. Available online: https://agmarknet.gov.in/PriceAndArrivals/CommodityDailyStateWise.aspx (accessed on 31 July 2021).
- Shapiro, S.S.; Wilk, M.B. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Dickey, D.A.; Fuller, W.A. Distribution of the estimators for autoregressive time series with a unit root. J. Am. Stat. Assoc. 1979, 74, 427–431. [Google Scholar]
- Kwiatkowski, D.; Phillips, P.C.B.; Schmidt, P.; Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]
- Phillips, P.C.B.; Perron, P. Testing for a unit root in time series regression. Biometrika 1988, 75, 335–346. [Google Scholar] [CrossRef]
- Gyamerah, S.A.; Ngare, P.; Ikpe, D. Hedging Crop Yields Against Weather Uncertainties—A Weather Derivative Perspective. Math. Comput. Appl. 2019, 24, 71. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Market | Agra | Ahmedabad | Bengaluru | Delhi | Kolkata | Mumbai |
|---|---|---|---|---|---|---|
| Mean (Rs./q) | 886.09 | 916.22 | 1351.24 | 1022.60 | 1096.54 | 1277.03 |
| Median (Rs./q) | 783.57 | 816.07 | 1278.57 | 890.86 | 981.43 | 1203.57 |
| Minimum (Rs./q) | 305.00 | 212.14 | 475.00 | 313.14 | 290.00 | 496.43 |
| Maximum (Rs./q) | 2957.14 | 2857.14 | 3500.00 | 3023.43 | 3845.71 | 3300.00 |
| S.D. (Rs./q) | 489.88 | 487.28 | 465.85 | 540.91 | 581.27 | 474.13 |
| C.V. (%) | 55.29 | 53.18 | 34.48 | 52.90 | 53.01 | 37.13 |
| Skewness | 1.46 | 1.23 | 1.34 | 1.36 | 1.46 | 1.24 |
| Kurtosis | 2.55 | 1.65 | 2.83 | 1.93 | 2.88 | 2.36 |
| Market | Agra | Ahmedabad | Bengaluru | |||
|---|---|---|---|---|---|---|
| Series | Price | Price Return | Price | Price Return | Price | Price Return |
| Test statistic | 0.874 | 0.933 | 0.904 | 0.940 | 0.907 | 0.840 |
| p-value | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 |
| Market | Delhi | Kolkata | Mumbai | |||
| Series | Price | Price return | Price | Price return | Price | Price return |
| Test statistic | 0.882 | 0.935 | 0.880 | 0.929 | 0.921 | 0.931 |
| p-value | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 | <0.001 |
| Test | Agra | Ahmedabad | Bengaluru | Delhi | Kolkata | Mumbai |
|---|---|---|---|---|---|---|
| ADF | −6.66 | −6.54 | −8.14 | −5.98 | −7.07 | −7.21 |
| (0.01) | (0.01) | (0.01) | (0.01) | (0.01) | (0.01) | |
| KPSS | 0.03 | 0.03 | 0.02 | 0.03 | 0.02 | 0.02 |
| (0.10) | (0.10) | (0.10) | (0.10) | (0.10) | (0.10) | |
| PP | −16.02 | −18.05 | −22.80 | −16.61 | −14.25 | −24.09 |
| (0.01) | (0.01) | (0.01) | (0.01) | (0.01) | (0.01) |
| Market | Agra | Ahmedabad | Bengaluru | Delhi | Kolkata | Mumbai |
|---|---|---|---|---|---|---|
| Model | ARMA (1,1)—EGARCH-M (1,1) | ARMA (1,0)—EGARCH-M (1,1) | ARMA (0,0)—EGARCH-M (1,1) | ARMA (1,0)—GJR-GARCH-M (1,1) | ARMA (1,0)—GARCH-M (1,1) | ARMA (2,1)—GARCH-M (1,1) |
| Mean Model | ||||||
| Constant | 0. 010 | 0.002 | 0.001 | 0.034 | 0.012 | 0.021 |
| (0.010) | (0.009) | (0.000) * | (0.014) ** | (0.011) | (0.008) *** | |
| AR (1) | 0.743 | 0.159 | 0.316 | 0.447 | 0.976 | |
| (0.044) *** | (0.048) *** | (0.055) *** | (0.050) *** | (0.002) *** | ||
| AR (2) | 0.008 | |||||
| (0.009) | ||||||
| MA (1) | −0.463 | −0.987 | ||||
| (0.064) *** | (0.000) *** | |||||
| −0.103 | −0.009 | −0.015 | −0.386 | −0.272 | −0.160 | |
| (0.144) | (0.118) | (0.008) * | (0.197) ** | (0.187) | (0.066) ** | |
| Variance Model | ||||||
| Constant | −2.530 | −0.311 | −1.396 | 0.001 | 0.001 | 0.000 |
| (0.770) *** | (0.134) ** | (0.416) *** | (0.000) ** | (0.001) | (0.000) ** | |
| −0.055 | −0.126 | −0.334 | 0.049 | 0.532 | 0.000 | |
| (0.097) | (0.058) ** | (0.113) *** | (0.056) | (0.130) *** | (0.000) | |
| 0.501 | 0.933 | 0.681 | 0.620 | 0.467 | 0.992 | |
| (0.152) *** | (0.028) *** | (0.085) *** | (0.101) *** | (0.120) *** | (0.001) *** | |
| 0.882 | 0.456 | 0.957 | 0.597 | |||
| (0.211) *** | (0.105) *** | (0.218) *** | (0.199) *** | |||
| Shape | 2.950 | 4.131 | 2.714 | 3.943 | 3.196 | 2.493 |
| (0.503) *** | (0.880) *** | (0.380) *** | (0.707) *** | (0.363) *** | (0.300) *** | |
| Market | Model | RMSE | MAE | MAPE (%) |
|---|---|---|---|---|
| Agra | ARMA (1,1)—GARCH-M (1,1) | 64.557 | 39.498 | 5.097 |
| ARMA (1,1)—EGARCH-M (1,1) | 64.224 | 39.421 | 5.096 | |
| ARMA (1,1)—GJRGARCH-M (1,1) | 64.408 | 39.440 | 5.094 | |
| ARMA (1,1)—APARCH-M (1,1) | 64.627 | 39.556 | 5.101 | |
| Ahmedabad | ARMA (1,0)—GARCH-M (1,1) | 83.371 | 54.457 | 7.191 |
| ARMA (1,0)—EGARCH-M (1,1) | 82.964 | 54.130 | 7.134 | |
| ARMA (1,0)—GJRGARCH-M (1,1) | 83.184 | 54.301 | 7.169 | |
| ARMA (1,0)—APARCH-M (1,1) | 82.984 | 54.135 | 7.136 | |
| Bengaluru | ARMA (0,0)—GARCH-M (1,1) | 129.786 | 82.658 | 6.544 |
| ARMA (0,0)—EGARCH-M (1,1) | 128.825 | 82.176 | 6.503 | |
| ARMA (0,0)—GJRGARCH-M (1,1) | 128.803 | 82.351 | 6.517 | |
| ARMA (1,2)—APARCH-M (1,1) | 131.525 | 83.705 | 6.564 | |
| Delhi | ARMA (1,0)—GARCH-M (1,1) | 76.020 | 50.833 | 5.629 |
| ARMA (1,0)—EGARCH-M (1,1) | 75.594 | 50.635 | 5.617 | |
| ARMA (1,0)—GJRGARCH-M (1,1) | 75.468 | 50.602 | 5.612 | |
| ARMA (1,0) APARCH-M (1,1) | 75.683 | 50.666 | 5.624 | |
| Kolkata | ARMA (1,0)—GARCH-M (1,1) | 80.157 | 48.394 | 4.865 |
| ARMA (1,0)—EGARCH-M (1,1) | 80.968 | 48.691 | 4.899 | |
| ARMA (1,0)—GJRGARCH-M (1,1) | 80.159 | 48.400 | 4.866 | |
| ARMA (1,0)—APARCH-M (1,1) | 82.115 | 49.317 | 4.967 | |
| Mumbai | ARMA (2,1)—GARCH-M (1,1) | 92.732 | 61.649 | 5.267 |
| ARMA (0,0)—EGARCH-M (1,1) | 93.021 | 61.896 | 5.273 | |
| ARMA (0,0)—GJRGARCH-M (1,1) | 93.052 | 61.896 | 5.271 | |
| ARMA (0,0)—APARCH-M (1,1) | 93.185 | 61.937 | 5.277 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rakshit, D.; Paul, R.K.; Yeasin, M.; Emam, W.; Tashkandy, Y.; Chesneau, C. Modeling Asymmetric Volatility: A News Impact Curve Approach. Mathematics 2023, 11, 2793. https://doi.org/10.3390/math11132793
Rakshit D, Paul RK, Yeasin M, Emam W, Tashkandy Y, Chesneau C. Modeling Asymmetric Volatility: A News Impact Curve Approach. Mathematics. 2023; 11(13):2793. https://doi.org/10.3390/math11132793
Chicago/Turabian StyleRakshit, Debopam, Ranjit Kumar Paul, Md Yeasin, Walid Emam, Yusra Tashkandy, and Christophe Chesneau. 2023. "Modeling Asymmetric Volatility: A News Impact Curve Approach" Mathematics 11, no. 13: 2793. https://doi.org/10.3390/math11132793