
Indexing of US Counties with Overdispersed Incidences of COVID-19 Deaths
 ,
,  , and
, and
Abstract
:1. Introduction
2. Incidence-Rate-Restricted Poisson Model with a Complementary Indexing
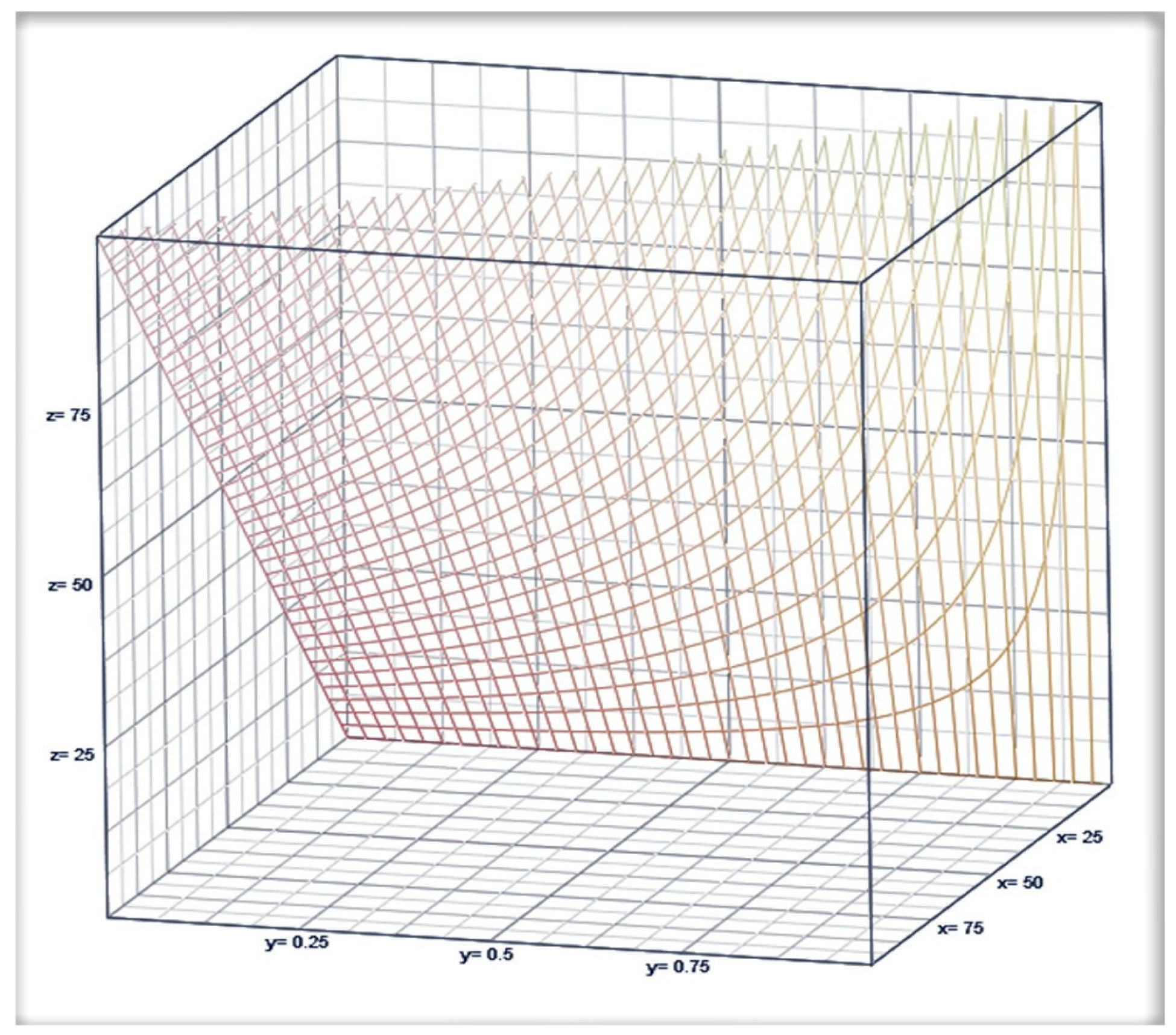
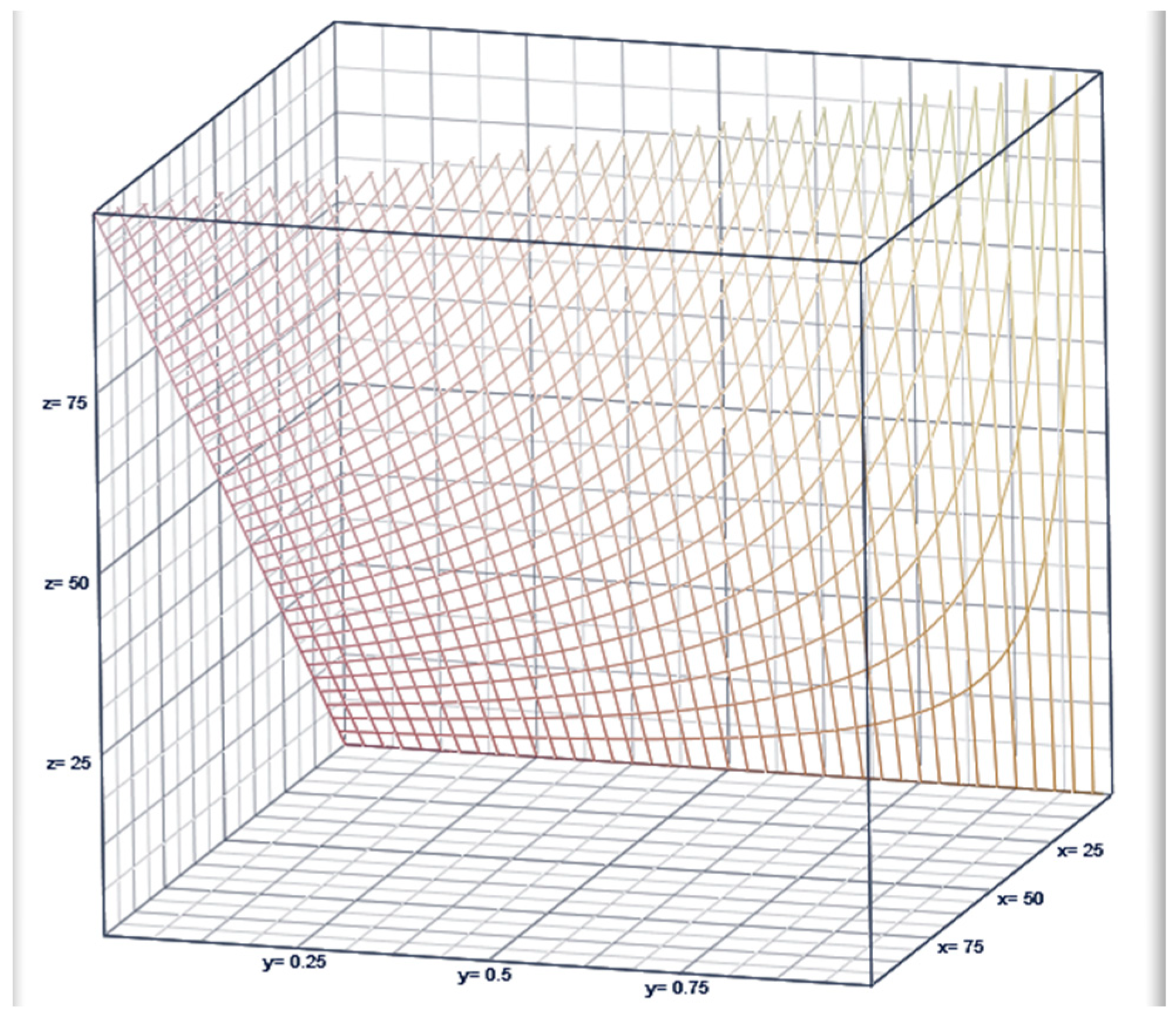
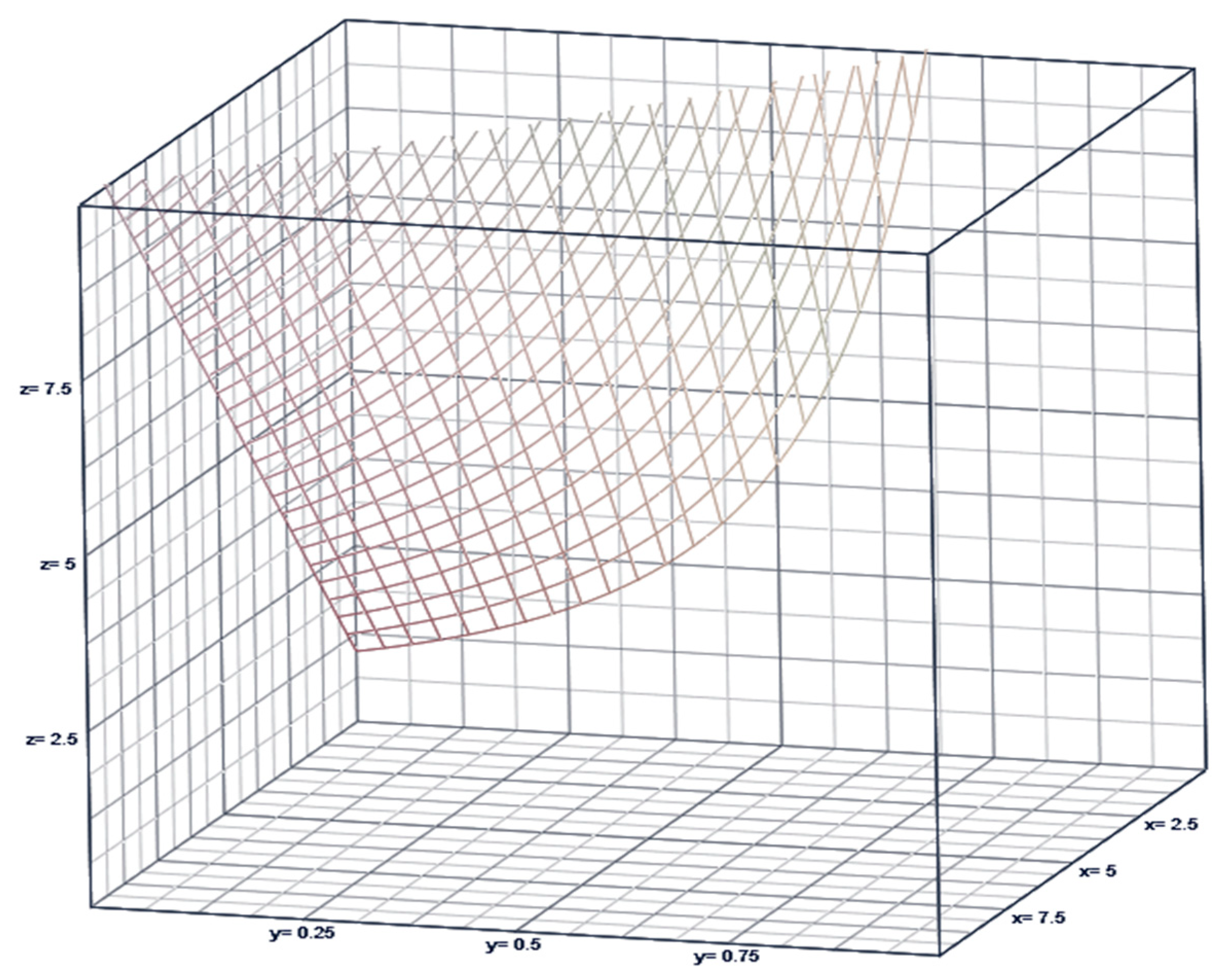
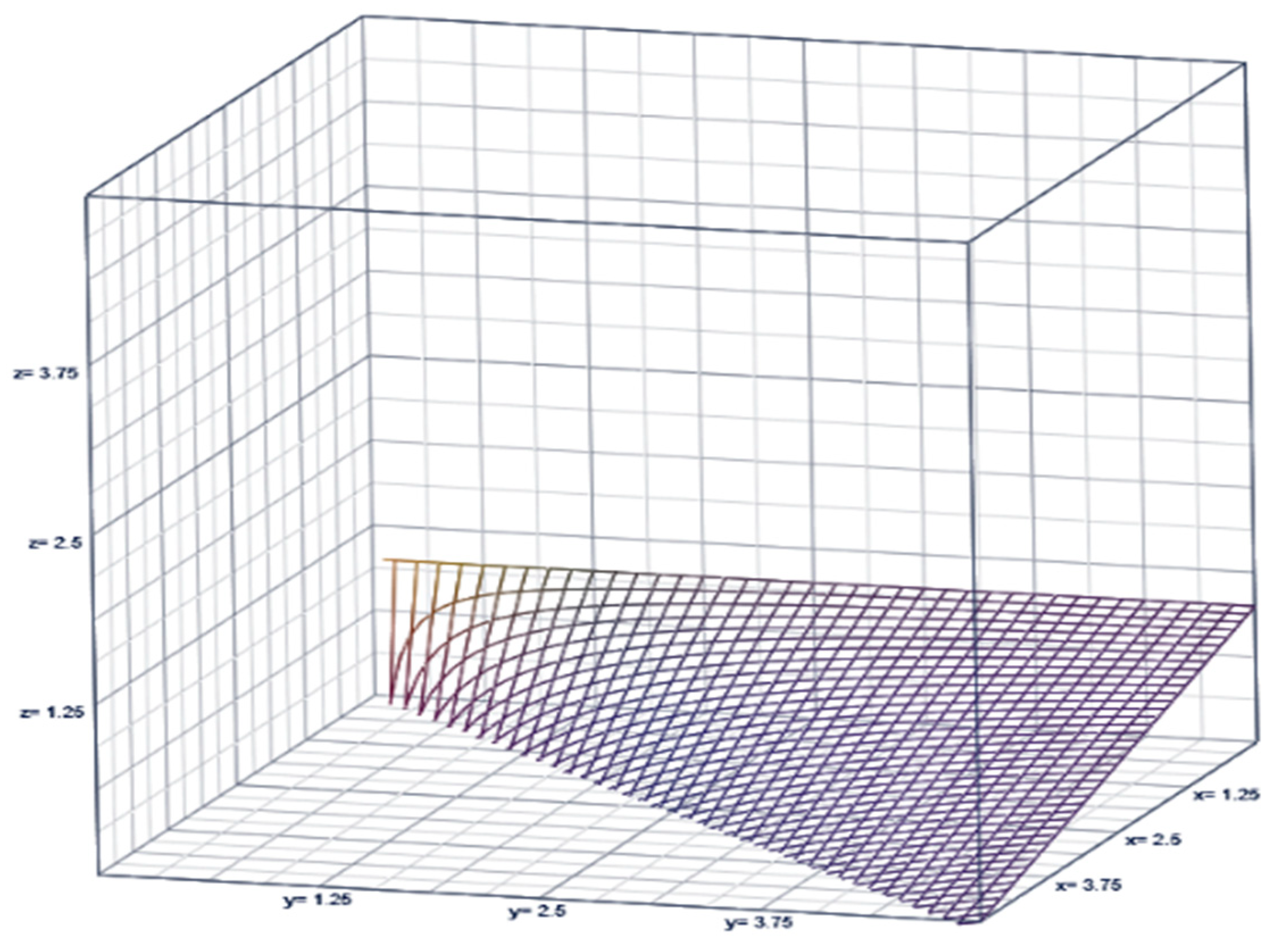
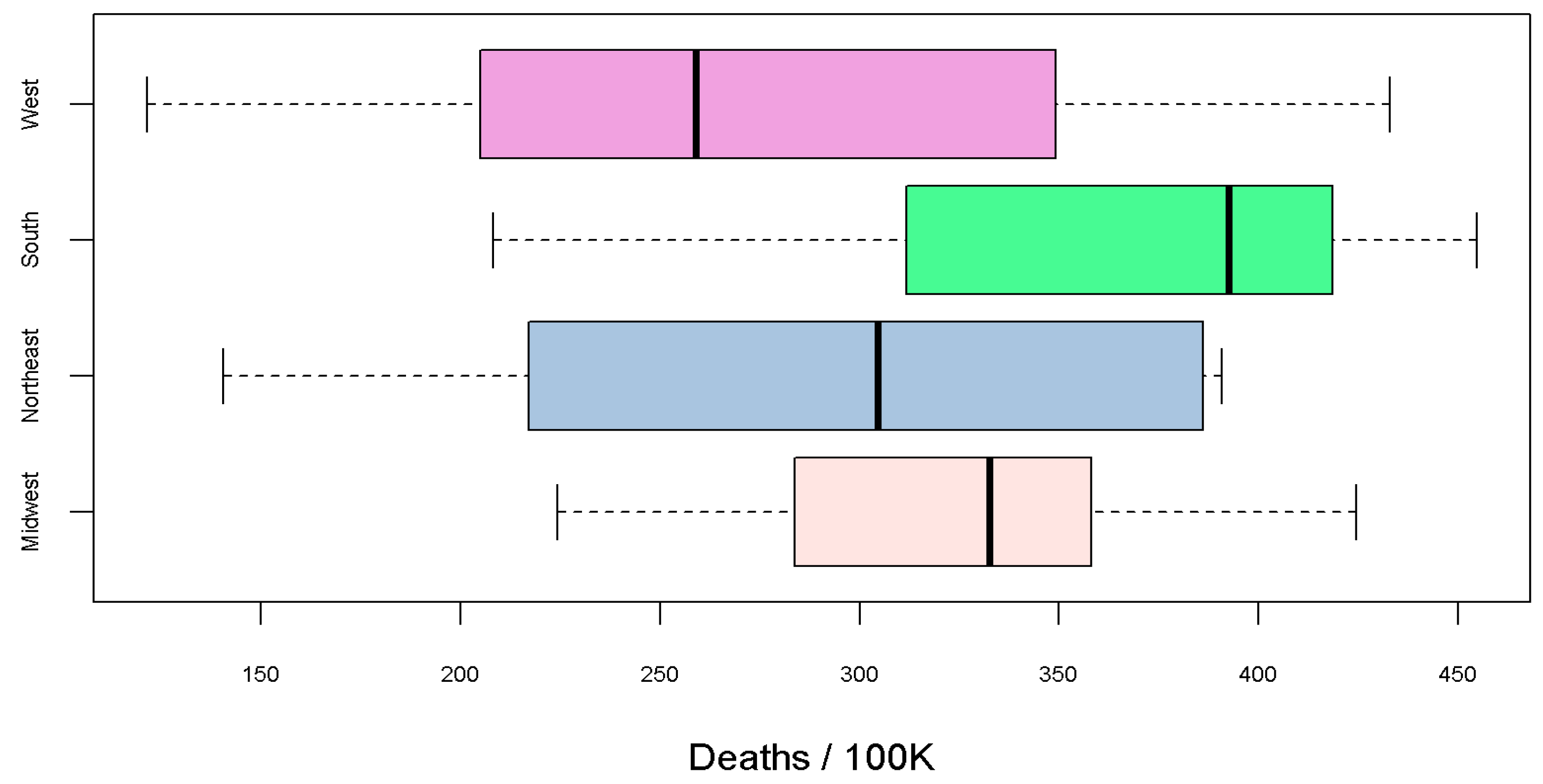
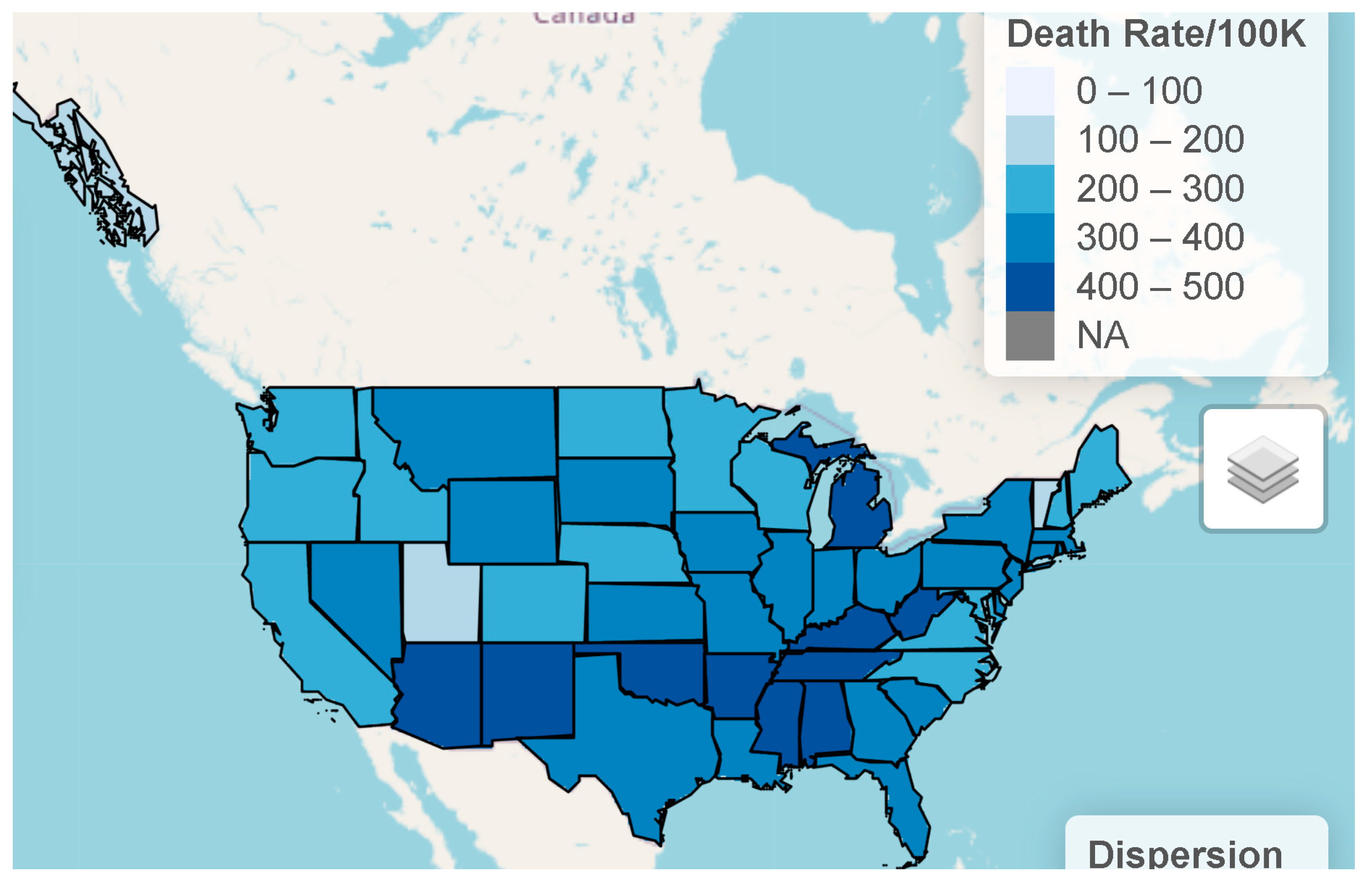
3. Complementary Index of the COVID-19 Pandemic in Overdispersed/Volatile Scenarios Is Illustrated in Table 1 for Total US and in Table 2 for each US State
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shanmugam, R.; Fulton, L.; Betancourt, J.; Pacheco, G.J. Indexing Inefficacy of Efforts to Stop Escalation of COVID Mortality. Mathematics 2022, 10, 4646. [Google Scholar] [CrossRef]
- Shanmugam, R. Incidence rate restricted Poissonness. Sankhyā Indian J. Stat. Ser. B 1991, 531, 191–201. [Google Scholar]
- Shanmugam, R. Size biased incidence rate restricted Poissonness and its application in international terrorism. Appl. Manag. Sci. 1993, 7, 41–49. [Google Scholar]
- Pisl, V.; Vevera, J.; Štěpánek, L.; Volavka, J. Changes in ambulance departures for assault calls during COVID-19 pandemic restrictions. Aggress. Behav. 2023, 49, 76–84. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.; Wagle, N.S.; Jemal, A. Cancer statistics, 2023. CA Cancer J. Clin. 2023, 73, 17–48. [Google Scholar] [CrossRef]
- Watson, A.M.; Haraldsdottir, K.; Biese, K.M.; Goodavish, L.; Stevens, B.; McGuine, T.A. The association of COVID-19 incidence with sport and face mask use in United States high school athletes. J. Athl. Train. 2023, 58, 29–36. [Google Scholar] [CrossRef]
- Udayana, S.; Dyah Wulan, S.R. The influence of local culture on mothers during pregnancy on stunting incidence. J. Posit. Psychol. Wellbeing 2022, 6, 2172–2180. [Google Scholar]
- Kersten, J.M.; van Veen, M.; van Houten, M.A.; Wieringa, J.; Noordzij, J.G.; Bekhof, J.; Kruizinga, M.D. Adverse effects of lockdowns during the COVID-19 pandemic: Increased incidence of pediatric crisis admissions due to eating disorders and adolescent intoxications. Eur. J. Pediatr. 2023, 182, 1137–1142. [Google Scholar] [CrossRef]
- Bisen, S.S.; Zeiser, L.B.; Boyarsky, B.; Werbel, W.; Snyder, J.; Garonzik-Wang, J.; Massie, A.B. Transplantation Amid a Pandemic: The Fall and Rise of Kidney Transplantation in the United States. Transplant. Direct 2023, 9, e1423. [Google Scholar] [CrossRef]
- Doti, J.L. A model to explain statewide differences in COVID-19 death rates. SSRN 2020, 3731803. [Google Scholar] [CrossRef]
- Riley, P.; Riley, A.; Turtle, J.; Ben-Nun, M. COVID-19 deaths: Which explanatory variables matter the most? PLoS ONE 2022, 17, e0266330. [Google Scholar] [CrossRef] [PubMed]
- Castro, M.C.; Gurzenda, S.; Turra, C.M.; Kim, S.; Andrasfay, T.; Goldman, N. Research notes: COVID-19 is not an independent cause of death. Demography 2023, 60, 343–349. [Google Scholar] [CrossRef] [PubMed]
- Almohaimeed, A.; Einbeck, J.; Qarmalah, N.; Alkhidhr, H. Using Random Effect Models to Produce Robust Estimates of Death Rates in COVID-19 Data. Int. J. Environ. Res. Public Health 2022, 19, 14960. [Google Scholar] [CrossRef]
- Shanmugam, R.; Fulton, L.; Ramamonjiarivelo, Z.; Betancourt, J.; Beauvais, B.; Kruse, C.S.; Brooks, M.S. A Report Card on Prevention Efforts of COVID-19 Deaths in US. Healthcare 2021, 9, 1175. [Google Scholar] [CrossRef] [PubMed]
- Shanmugam, R. Restricted prevalence rates of COVID-19′s infectivity, hospitalization, recovery, mortality in the USA and their implications. J. Healthc. Inform. Res. 2021, 5, 133–150. [Google Scholar] [CrossRef] [PubMed]
- Shanmugam, R.; Ledlow, G.; Singh, K.P. Predicting COVID-19 cases with unknown homogeneous or heterogeneous resistance to infectivity. PLoS ONE 2021, 16, e0254313. [Google Scholar] [CrossRef] [PubMed]
- Tian, T.; Tan, J.; Luo, W.; Jiang, Y.; Chen, M.; Yang, S.; Wang, X. The effects of stringent and mild interventions for coronavirus pandemic. J. Am. Stat. Assoc. 2021, 116, 481–491. [Google Scholar] [CrossRef]
- Stuart, A.; Ord, K. Kendall’s Advanced Theory of Statistics, Distribution Theory; John Wiley & Sons: Hoboken, NJ, USA, 2010; Volume 1. [Google Scholar]
- Shanmugam, R.; Singh, R. Testing of Poisson incidence rate restriction. Int. J. Reliab. Appl. 2001, 2, 263–268. [Google Scholar]
- USA Facts. US COVID-19 Cases and Deaths by State. 2022. Available online: https://usafacts.org/visualizations/coronavirusCOVID-19-spread-map (accessed on 2 November 2022).
- Fulton, L. Rpubs Code. 2022. Available online: https://rpubs.com/R-Minator/Ram22 (accessed on 2 November 2022).
- Wong, Y.L. COVID-Related Research on Singapore: A Review. Singapore: Academies. 2023. Available online: https://www.academia.sg/covid19-literature-review (accessed on 10 January 2020).
- Wu, R.; Pisani, D.; Donoghue, P.C. The unbearable uncertainty of panarthropod relationships. Biol. Lett. 2023, 19, 20220497. [Google Scholar] [CrossRef]
- Borisov, D. Mathematical modeling and multicriteria optimization of the ceramic indicators of the refractory linings of steel foundry ladles. J. Chem. Technol. Metall. 2023, 58, 208–216. [Google Scholar]
- Salekshahrezaee, Z.; Leevy, J.L.; Khoshgoftaar, T.M. The effect of feature extraction and data sampling on credit card fraud detection. J. Big Data 2023, 10, 6. [Google Scholar] [CrossRef]
- Chekouo, T.; Safo, S.E. Bayesian integrative analysis and prediction with application to atherosclerosis cardiovascular disease. Biostatistics 2023, 24, 124–139. [Google Scholar] [CrossRef] [PubMed]
- Ringwald, W.R.; Forbes, M.K.; Wright, A.G. Meta-analysis of structural evidence for the Hierarchical Taxonomy of Psychopathology (HiTOP) model. Psychol. Med. 2023, 53, 533–546. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 50 States and D.C. | SD | Median | Minimum | Maximum | |
|---|---|---|---|---|---|
| Deaths | 21,554.196 | 23,740.585 | 14,194.000 | 910.000 | 101,344.000 |
| Variances | 3933.398 | 6888.156 | 639.521 | 7.430 | 33,823.205 |
| 18.235 | 20.085 | 12.008 | 0.770 | 85.739 | |
| biased | 33.599 | 31.943 | 21.726 | 2.898 | 118.403 |
| nbiased | 600.980 | 177.813 | 610.000 | 170.000 | 911.000 |
| 0.971 | 0.031 | 0.980 | 0.841 | 0.999 | |
| 0.210 | 0.129 | 0.202 | 0.020 | 0.598 | |
| 0.217 | 0.135 | 0.211 | 0.020 | 0.648 | |
| Biased | 0.782 | 0.094 | 0.801 | 0.526 | 0.912 |
| Biased | 1.536 | 0.480 | 1.415 | 0.824 | 2.947 |
| Biased | 1.972 | 0.571 | 1.853 | 0.906 | 3.453 |
| Rate 100K | 320.740 | 86.544 | 335.487 | 121.480 | 454.672 |
| Region | State | Deaths | Deaths/100K | nbiased | biased | biased | biased | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Midwest | IA | 10,538 | 330 | 487 | 8.910 | 21.640 | 0.987 | 0.642 | 0.059 | 0.973 | 0.063 | 1.515 |
| Midwest | IL | 39,381 | 310 | 784 | 33.320 | 51.040 | 0.990 | 0.835 | 0.244 | 1.312 | 0.248 | 1.571 |
| Midwest | IN | 25,959 | 381 | 710 | 21.960 | 36.560 | 0.994 | 0.773 | 0.360 | 1.512 | 0.372 | 1.955 |
| Midwest | KS | 10,167 | 346 | 390 | 8.600 | 26.330 | 0.990 | 0.868 | 0.209 | 1.582 | 0.211 | 1.822 |
| Midwest | MI | 42,613 | 425 | 572 | 36.050 | 74.510 | 0.992 | 0.910 | 0.361 | 1.066 | 0.362 | 1.171 |
| Midwest | MN | 12,806 | 224 | 674 | 10.830 | 19.000 | 0.965 | 0.787 | 0.256 | 1.285 | 0.261 | 1.632 |
| Midwest | MO | 20,708 | 336 | 598 | 17.520 | 35.870 | 0.998 | 0.810 | 0.190 | 1.112 | 0.194 | 1.373 |
| Midwest | ND | 2232 | 287 | 399 | 1.890 | 5.600 | 0.945 | 0.556 | 0.187 | 1.452 | 0.222 | 2.612 |
| Midwest | NE | 4827 | 246 | 500 | 4.080 | 9.920 | 0.984 | 0.669 | 0.162 | 1.238 | 0.172 | 1.852 |
| Midwest | OH | 42,073 | 358 | 500 | 35.590 | 85.540 | 0.997 | 0.910 | 0.161 | 0.824 | 0.161 | 0.906 |
| Midwest | SD | 3214 | 359 | 348 | 2.720 | 9.260 | 0.954 | 0.880 | 0.094 | 1.590 | 0.094 | 1.807 |
| Midwest | WI | 16,486 | 280 | 911 | 13.950 | 18.270 | 0.977 | 0.630 | 0.148 | 1.290 | 0.164 | 2.047 |
| Northeast | CT | 11,034 | 305 | 483 | 9.340 | 22.910 | 0.980 | 0.805 | 0.112 | 1.134 | 0.113 | 1.409 |
| Northeast | MA | 21,035 | 301 | 678 | 17.800 | 36.910 | 0.999 | 0.716 | 0.262 | 1.415 | 0.278 | 1.975 |
| Northeast | ME | 2989 | 217 | 578 | 2.530 | 5.180 | 0.924 | 0.853 | 0.333 | 2.947 | 0.336 | 3.453 |
| Northeast | NH | 2972 | 214 | 545 | 2.510 | 5.790 | 0.979 | 0.836 | 0.130 | 2.095 | 0.131 | 2.506 |
| Northeast | NJ | 35,774 | 386 | 730 | 30.270 | 49.070 | 0.997 | 0.824 | 0.089 | 0.966 | 0.090 | 1.173 |
| Northeast | NY | 77,403 | 390 | 811 | 65.480 | 97.670 | 0.997 | 0.817 | 0.234 | 1.757 | 0.238 | 2.151 |
| Northeast | PA | 50,860 | 391 | 755 | 43.030 | 67.370 | 0.990 | 0.801 | 0.361 | 2.472 | 0.370 | 3.087 |
| Northeast | RI | 3897 | 355 | 407 | 3.300 | 9.630 | 0.973 | 0.836 | 0.024 | 2.129 | 0.024 | 2.546 |
| Northeast | VT | 910 | 141 | 314 | 0.770 | 2.900 | 0.919 | 0.783 | 0.219 | 1.855 | 0.223 | 2.369 |
| South | AL | 21,133 | 418 | 655 | 17.880 | 32.270 | 0.986 | 0.641 | 0.192 | 1.119 | 0.208 | 1.746 |
| South | AR | 13,062 | 431 | 779 | 11.050 | 16.810 | 0.967 | 0.885 | 0.271 | 2.035 | 0.273 | 2.300 |
| South | DC | 1392 | 208 | 412 | 1.180 | 3.390 | 0.841 | 0.776 | 0.375 | 2.023 | 0.389 | 2.607 |
| South | DE | 3371 | 335 | 513 | 2.850 | 6.570 | 0.943 | 0.848 | 0.032 | 0.877 | 0.032 | 1.035 |
| South | FL | 87,141 | 399 | 819 | 73.720 | 110.830 | 0.998 | 0.792 | 0.310 | 1.895 | 0.318 | 2.392 |
| South | GA | 42,348 | 393 | 715 | 35.830 | 65.490 | 0.997 | 0.676 | 0.236 | 1.271 | 0.255 | 1.879 |
| South | KY | 18,094 | 402 | 652 | 15.310 | 27.750 | 0.985 | 0.852 | 0.198 | 2.454 | 0.200 | 2.880 |
| South | LA | 18,136 | 392 | 695 | 15.340 | 26.100 | 0.976 | 0.649 | 0.103 | 1.180 | 0.109 | 1.819 |
| South | MD | 15,578 | 252 | 802 | 13.180 | 19.710 | 0.983 | 0.725 | 0.064 | 1.123 | 0.065 | 1.549 |
| South | MS | 13,097 | 444 | 610 | 11.080 | 21.730 | 0.972 | 0.652 | 0.054 | 1.209 | 0.055 | 1.853 |
| South | NC | 28,945 | 274 | 615 | 24.490 | 47.290 | 0.992 | 0.864 | 0.094 | 1.364 | 0.094 | 1.578 |
| South | OK | 18,147 | 455 | 176 | 15.350 | 118.400 | 0.999 | 0.715 | 0.598 | 1.898 | 0.648 | 2.653 |
| South | SC | 17,869 | 344 | 599 | 15.120 | 29.860 | 0.981 | 0.790 | 0.256 | 1.653 | 0.262 | 2.094 |
| South | TN | 28,113 | 403 | 703 | 23.780 | 40.040 | 0.996 | 0.898 | 0.202 | 2.382 | 0.202 | 2.654 |
| South | TX | 92,159 | 312 | 840 | 77.970 | 109.800 | 0.993 | 0.893 | 0.096 | 1.946 | 0.096 | 2.180 |
| South | VA | 23,718 | 274 | 825 | 20.070 | 28.820 | 0.985 | 0.912 | 0.020 | 1.175 | 0.020 | 1.288 |
| South | WV | 8083 | 453 | 656 | 6.840 | 12.750 | 0.969 | 0.753 | 0.305 | 1.335 | 0.318 | 1.772 |
| West | AK | 1441 | 196 | 298 | 1.220 | 4.960 | 0.951 | 0.882 | 0.411 | 1.560 | 0.415 | 1.769 |
| West | AZ | 29,852 | 411 | 564 | 25.250 | 53.510 | 0.992 | 0.723 | 0.089 | 1.079 | 0.091 | 1.493 |
| West | CA | 101,344 | 259 | 909 | 85.740 | 112.930 | 0.996 | 0.823 | 0.283 | 1.739 | 0.289 | 2.111 |
| West | CO | 14,194 | 244 | 773 | 12.010 | 18.450 | 0.979 | 0.719 | 0.126 | 1.064 | 0.132 | 1.480 |
| West | HI | 1758 | 121 | 346 | 1.490 | 5.110 | 0.900 | 0.850 | 0.084 | 1.358 | 0.084 | 1.597 |
| West | ID | 5463 | 287 | 553 | 4.620 | 9.950 | 0.943 | 0.906 | 0.520 | 1.682 | 0.523 | 1.856 |
| West | MT | 3705 | 335 | 529 | 3.130 | 7.020 | 0.925 | 0.698 | 0.379 | 1.645 | 0.414 | 2.357 |
| West | NM | 9164 | 433 | 828 | 7.750 | 11.090 | 0.923 | 0.816 | 0.292 | 2.072 | 0.296 | 2.539 |
| West | NV | 11,976 | 381 | 591 | 10.130 | 20.280 | 0.975 | 0.526 | 0.063 | 1.496 | 0.068 | 2.843 |
| West | OR | 8726 | 205 | 652 | 7.380 | 13.380 | 0.959 | 0.805 | 0.287 | 2.365 | 0.293 | 2.937 |
| West | UT | 5341 | 160 | 586 | 4.520 | 9.140 | 0.916 | 0.791 | 0.325 | 1.032 | 0.332 | 1.304 |
| West | WA | 16,013 | 207 | 611 | 13.550 | 26.840 | 0.979 | 0.750 | 0.210 | 1.239 | 0.216 | 1.651 |
| West | WY | 2023 | 349 | 170 | 1.710 | 12.320 | 0.968 | 0.751 | 0.055 | 1.078 | 0.056 | 1.436 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shanmugam, R.; Fulton, L.; Betancourt, J.; Pacheco, G.J.; Sen, K. Indexing of US Counties with Overdispersed Incidences of COVID-19 Deaths. Mathematics 2023, 11, 3112. https://doi.org/10.3390/math11143112
Shanmugam R, Fulton L, Betancourt J, Pacheco GJ, Sen K. Indexing of US Counties with Overdispersed Incidences of COVID-19 Deaths. Mathematics. 2023; 11(14):3112. https://doi.org/10.3390/math11143112
Chicago/Turabian StyleShanmugam, Ramalingam, Lawrence Fulton, Jose Betancourt, Gerardo J. Pacheco, and Keya Sen. 2023. "Indexing of US Counties with Overdispersed Incidences of COVID-19 Deaths" Mathematics 11, no. 14: 3112. https://doi.org/10.3390/math11143112