
A Decentralized Federated Learning Based on Node Selection and Knowledge Distillation
 ,
,
Abstract
:1. Introduction
- We proposed a decentralized federated learning method, which is using a common peer-to-peer model to select neighboring nodes through a node selection mechanism. In this article, local model performance and local dataset size for the current round are considered for important metrics to reflect data quality differences and resource heterogeneity across devices.
- We added a knowledge distillation mechanism to the method. The stability and running time of the method are guaranteed with less loss of precision.
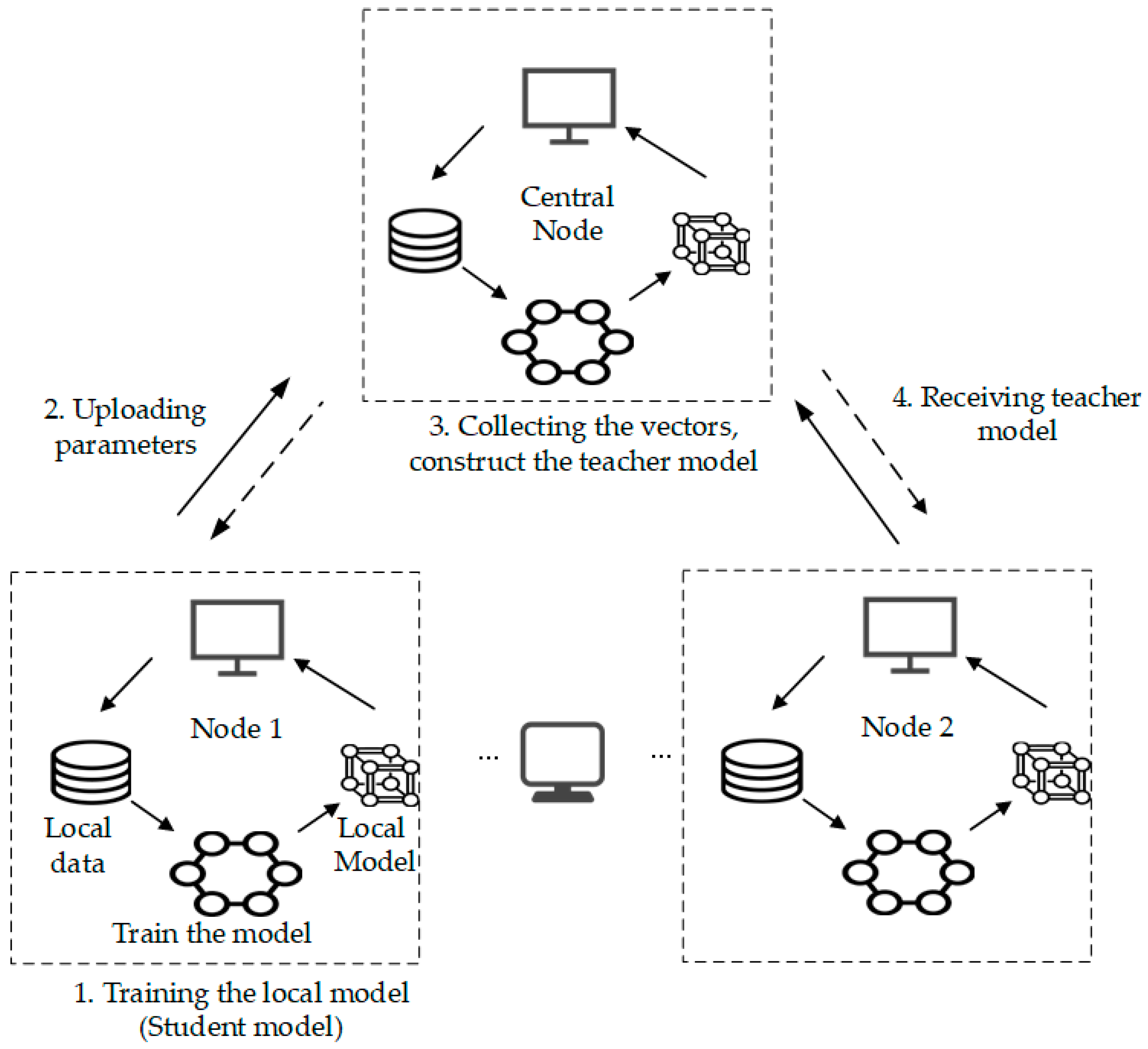
2. Materials and Methods
2.1. System Model
2.2. The Decentralized Federated Learning
| Algorithm 1 Center Aggregation Algorithm |
| Input: node set , label set , maximum number of global model iterations . for to do for in do Average Logits of the node k for in do // Accumulate Logits of other nodes end end for in do for in do end Sending Model Logits end end |
2.3. Knowledge Distillation Mechanism
2.4. Node Selection
2.5. Complexity Analysis
3. Results and Discussion
3.1. Experimental Environment and Evaluation Index
3.2. Experimental Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Tedeschini, B.C.; Savazzi, S.; Stoklasa, R.; Barbieri, L.; Stathopoulos, I.; Nicoli, M.; Serio, L. Decentralized federated learning for healthcare networks: A case study on tumor segmentation. IEEE Access 2022, 10, 8693–8708. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Federated learning for data privacy preservation in vehicular cyber-physical systems. IEEE Netw. 2020, 34, 50–56. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Artificial Intelligence and Statistics; JMLR: Norfolk, MA, USA, 2017; pp. 1273–1282. [Google Scholar]
- Zheng, L.; Huang, Y.; Zhang, W.; Yang, L. Unsupervised Recurrent Federated Learning for Edge Popularity Prediction in Privacy-Preserving Mobile-Edge Computing Networks. IEEE Internet Things J. 2022, 9, 24328–24345. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Zhang, J.; Chen, J.; Wu, D.; Chen, B.; Yu, S. Poisoning attack in federated learning using generative adversarial nets. In Proceedings of the 2019 18th IEEE International Conference on Trust, Security and Privacy in Computing and Communications/13th IEEE International Conference on Big Data Science and Engineering (TrustCom/BigDataSE), Rotorua, New Zealand, 5–8 August 2019; pp. 374–380. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Zhao, S. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Chen, X.; Lan, P.; Zhou, Z.; Zhao, A.; Zhou, P.; Sun, F. Toward Federated Learning With Byzantine and Inactive Users: A Game Theory Approach. IEEE Access 2023, 11, 34138–34149. [Google Scholar] [CrossRef]
- Lian, X.; Zhang, C.; Zhang, H.; Hsieh, C.J.; Zhang, W.; Liu, J. Can decentralized algorithms outperform centralized algorithms? a case study for decentralized parallel stochastic gradient descent. In Advances in Neural Information Processing Systems; NIPS Foundation: La Jolla, CA, USA, 2017; Volume 30, pp. 5336–5446. [Google Scholar]
- He, C.; Tan, C.; Tang, H.; Qiu, S.; Liu, J. Central server free federated learning over single-sided trust social networks. arXiv 2019, arXiv:1910.04956. [Google Scholar]
- Yubo, S.O.N.G.; Jingkai, Z.H.U.; Lingqi, Z.H.A.O.; Aiqun, H.U. Centralized federated learning model based on model accuracy. J. Tsinghua Univ. Sci. Technol. 2022, 62, 832–841. [Google Scholar]
- Caldarola, F.; d’Atri, G.; Zanardo, E. Neural Fairness Blockchain Protocol Using an Elliptic Curves Lottery. Mathematics 2022, 10, 3040. [Google Scholar] [CrossRef]
- Qiao, S.; Lin, Y.; Han, N.; Yang, G.; Li, H.; Yuan, G.; Mao, R.; Yuan, C.; Gutierrez, L.A. Decentralized Federated Learning Framework Based on Proof-of-contribution Consensus Mechanism. J. Softw. 2023, 34, 1148–1167. (In Chinese) [Google Scholar]
- Zhou, W.; Wang, C.; Xu, J.; Hu, K.; Wang, J. Privacy-Preserving and Decentralized Federated Learning Model Based on the Blockchain. J. Comput. Res. Dev. 2022, 59, 2423–2436. [Google Scholar]
- Ren, J.; He, Y.; Wen, D.; Yu, G.; Huang, K.; Guo, D. Scheduling for cellular federated edge learning with importance and channel awareness. IEEE Trans. Wirel. Commun. 2020, 19, 7690–7703. [Google Scholar] [CrossRef]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications (ICC), Shanghai, China, 21–23 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Ma, J.; Sun, X.; Xia, W.; Wang, X.; Chen, X.; Zhu, H. Client selection based on label quantity information for federated learning. In Proceedings of the 2021 IEEE 32nd Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Helsinki, Finland, 13–16 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Huang, T.; Lin, W.; Wu, W.; He, L.; Li, K.; Zomaya, A.Y. An efficiency-boosting client selection scheme for federated learning with fairness guarantee. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1552–1564. [Google Scholar] [CrossRef]
- Zhou, Y.; Pu, G.; Ma, X.; Li, X.; Wu, D. Distilled one-shot federated learning. arXiv 2020, arXiv:2009.07999. [Google Scholar]
- Zhu, Z.; Hong, J.; Zhou, J. Data-free knowledge distillation for heterogeneous federated learning. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 18–24 July 2021; pp. 12878–12889. [Google Scholar]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3400–3413. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yuan, X.; Zhang, K.; Zhang, Y. Selective Federated Learning for Mobile Edge Intelligence. In Proceedings of the 2021 13th International Conference on Wireless Communications and Signal Processing (WCSP), Changsha, China, 20–22 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Liu, Y.; Chen, H.; Liu, Y.; Li, C. Privacy- Preserving Strategies Sin Federated Learning. J. Softw. 2022, 33, 1057–1092. (In Chinese) [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Caldas, S.; Duddu, S.M.K.; Wu, P. Leaf: A benchmark for federated settings. arXiv 2018, arXiv:1812.01097. [Google Scholar]
- Jeong, E.; Oh, S.; Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data. arXiv 2018, arXiv:1811.11479. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description | Symbol | Description |
|---|---|---|---|
| the total number of nodes | the set of labeled Logits output of tags t | ||
| learning rate | the total loss of knowledge distillation | ||
| gradient operator | the loss between the student model and the teacher model | ||
| batch size | the local dataset of node k | ||
| the model parameters of node k | vector of hard labels | ||
| loss function | the class probability | ||
| set of nodes | logical units of the teacher model output |
| Nodes | Model Type | 1st Conv Layer Filters | 2nd Conv Layer Filters | 3rd Conv Layer Filters | Dropout Rate |
|---|---|---|---|---|---|
| node1 | 2-layer | 128 | 256 | None | 0.2 |
| node2 | 2-layer | 128 | 384 | None | 0.2 |
| node3 | 2-layer | 128 | 512 | None | 0.2 |
| node4 | 2-layer | 256 | 256 | None | 0.3 |
| node5 | 2-layer | 256 | 512 | None | 0.4 |
| node6 | 3-layer | 64 | 128 | 256 | 0.2 |
| node7 | 3-layer | 64 | 128 | 192 | 0.2 |
| node8 | 3-layer | 64 | 192 | 256 | 0.2 |
| node9 | 3-layer | 128 | 128 | 128 | 0.3 |
| node10 | 3-layer | 128 | 128 | 192 | 0.5 |
| Dataset | Method | 10 Rounds Accuracy | 30 Rounds Accuracy | 50 Rounds Accuracy |
|---|---|---|---|---|
| MNIST-IID | CFL | 53.26% | 76.26% | 78.34% |
| FD | 57.32% | 78.22% | 79.23% | |
| BD | 68.21% | 86.41% | 88.46% | |
| FP | 54.13% | 76.33% | 78.56% | |
| The proposed method | 64.47% | 83.75% | 87.59% | |
| CIFAR-10-IID | CFL | 58.36% | 73.05% | 85.03% |
| FD | 61.33% | 79.36% | 86.72% | |
| BD | 74.66% | 89.72% | 93.71% | |
| FP | 60.12% | 77.83% | 85.42% | |
| The proposed method | 71.37% | 87.32% | 91.36% | |
| FEMNIST-IID | CFL | 52.42% | 77.26% | 81.12% |
| FD | 58.74% | 81.65% | 83.36% | |
| BD | 62.13% | 85.43% | 90.42% | |
| FP | 54.26% | 79.41% | 83.26% | |
| The proposed method | 61.33% | 83.97% | 89.15% |
| Dataset | Method | 10 Rounds Accuracy | 30 Rounds Accuracy | 50 Rounds Accuracy |
|---|---|---|---|---|
| MNIST-Non-IID | CFL | 47.25% | 67.16% | 70.23% |
| FD | 48.17% | 68.73% | 70.84% | |
| BD | 49.96% | 78.05% | 84.12% | |
| FP | 47.63% | 67.92% | 70.51% | |
| The proposed method | 49.93% | 76.84% | 81.18% | |
| CIFAR-10-Non-IID | CFL | 58.33% | 73.35% | 76.53% |
| FD | 57.92% | 75.84% | 80.72% | |
| BD | 63.47% | 82.16% | 85.23% | |
| FP | 59.71% | 74.29% | 78.85% | |
| The proposed method | 61.39% | 78.95% | 82.65% | |
| FEMNIST-Non-IID | CFL | 54.95% | 68.73% | 82.43% |
| FD | 65.43% | 73.58% | 85.30% | |
| BD | 72.45% | 79.67% | 89.08% | |
| FP | 61.22% | 71.55% | 84.18% | |
| The proposed method | 69.21% | 77.93% | 85.39% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Z.; Sun, F.; Chen, X.; Zhang, D.; Han, T.; Lan, P. A Decentralized Federated Learning Based on Node Selection and Knowledge Distillation. Mathematics 2023, 11, 3162. https://doi.org/10.3390/math11143162
Zhou Z, Sun F, Chen X, Zhang D, Han T, Lan P. A Decentralized Federated Learning Based on Node Selection and Knowledge Distillation. Mathematics. 2023; 11(14):3162. https://doi.org/10.3390/math11143162
Chicago/Turabian StyleZhou, Zhongchang, Fenggang Sun, Xiangyu Chen, Dongxu Zhang, Tianzhen Han, and Peng Lan. 2023. "A Decentralized Federated Learning Based on Node Selection and Knowledge Distillation" Mathematics 11, no. 14: 3162. https://doi.org/10.3390/math11143162