Note that this model contains six parameters. In both illustrations, the GA population consists of = 100 chromosomes. To evaluate performance efficiency, we compared the optimal designs generated with our GA (denoted as GA designs) with those from NSGA-II (denoted as NSGA designs) produced via Design-Expert 11 software (denoted as DX designs). The GA and NSGA designs were generated using a MATLAB program developed by the author, whereas all DX designs were produced using the Design-Expert 11 software. The latter utilized the best search algorithm based on the D-criterion and supplemented by an additional model point option. This algorithm combined Point Exchange and Coordinate Exchange searches to explore the design space comprehensively. In our study, to ensure a balanced comparison, we maintained identical genetic parameters for both our GA and NSGA designs, only differing in their respective selection processes. Our GA methodology utilized a combination of non-dominated sorting and random pair selection, offering advantages in its straightforwardness and ease of implementation. This simplicity translates to a less computationally intensive process, making it an advantageous choice when dealing with limited computational resources. Contrastingly, the NSGA designs deployed a more complex approach, comprising non-dominated sorting, crowding distance, and tournament selection. While this approach might require more computational resources, NSGA-II has the upper hand when dealing with more intricate multi-objective problems. Its ability to uphold diversity in the population while averting premature convergence positions it as an effective solution in these scenarios. The determination of the most effective method largely hinges on the specifics of the problem. While the NSGA-II shows strength in complexity, our GA shines in simpler scenarios or those restricted by computational resources. Therefore, we put forth a comparative analysis of our GA’s performance against NSGA-II to provide more context-dependent insights. Researchers who are interested in obtaining the code for our genetic algorithm are welcome to contact the corresponding author for assistance and support.
6.1. Example 1: Sugar Formulation
We examined an example from Spanemberg et al. [
45]. The objective of the experiment was to identify the optimal sugar formulation that maximized the shelf life and critical moisture content of hard candy. Sugar composition comprises three components: sucrose
, high-maltose corn syrup
, and 40 DE corn syrup
. The range of constraints for the sugar mixture are presented below:
The boundary under consideration comprised four vertices. Prior to implementing the GA, we conducted a comprehensive investigation into the selection of GA parameter values and determined the suitable number of generations needed to achieve convergence. We set a limit of 1500 generations. Furthermore, we established the following ranges for the genetic parameter values:
where
and
represent the blending rate, between-parent crossover rate, within-parent crossover rate, extreme rate, and mutation rate, respectively. The genetic parameter values were initially set to their maximum levels and then systematically reduced to lower levels after 400 generations.
The performance of the competing designs was evaluated by considering those with 7 to 10 runs.
Figure 1 illustrates the Pareto front of our GA (highlighted in gray) and NSGAII (highlighted in yellow) which showcases a well-distributed set of optimal GA and optimal NSGA designs derived from thinning a rich Pareto front using ε-dominance. The designs GA
.1, GA
.2, GA
.3, and GA
.4 are represented by red, blue, black, and magenta dots, respectively. The color representations for the NSGA designs follow those of the GA designs. For
= 7, the gap between the highest and the lowest D-efficiency of GA was approximately 0.0137, and the gap between the highest and lowest minimum D-efficiency due to a missing observation of GA was around 0.008. NSGA7 presented only a few solutions, with their D-efficiencies closely aligned. Similarly, the minimum D-efficiencies due to missing observations showed tight congruence. However, this marked contrast in GA lessened significantly for
= 8 to 10. In this range, the gap between the highest and lowest D-efficiency was below 0.0001, and the difference between the highest and lowest minimum D-efficiency due to a missing observation was under 0.002. For
= 8, the difference between the highest and lowest D-efficiency of NSGA was approximately 0.0014. Meanwhile, the gap between the highest and lowest minimum D-efficiency due to a missing observation in NSGA was less than 0.0001. For
= 9, the discrepancy between the highest and lowest D-efficiency of NSGA was approximately 0.0002, while for
= 10 it was 0.003. For
= 9 and 10, the gaps in the highest and lowest minimum D-efficiency due to a missing observation in NSGA were around 0.0015 and 0.008, respectively. For
= 8 and 9, NSGAII solutions outperformed those of our GA based on the minimum D-efficiency due to missing observations. Yet, when assessing D-efficiency alone, our GA outperforms NSGAII. For
= 10, our GA’s solutions surpassed NSGAII’s based on both objectives. The Pareto fronts of our GA and NSGA exhibited distinct distribution patterns, as depicted in
Figure 1.
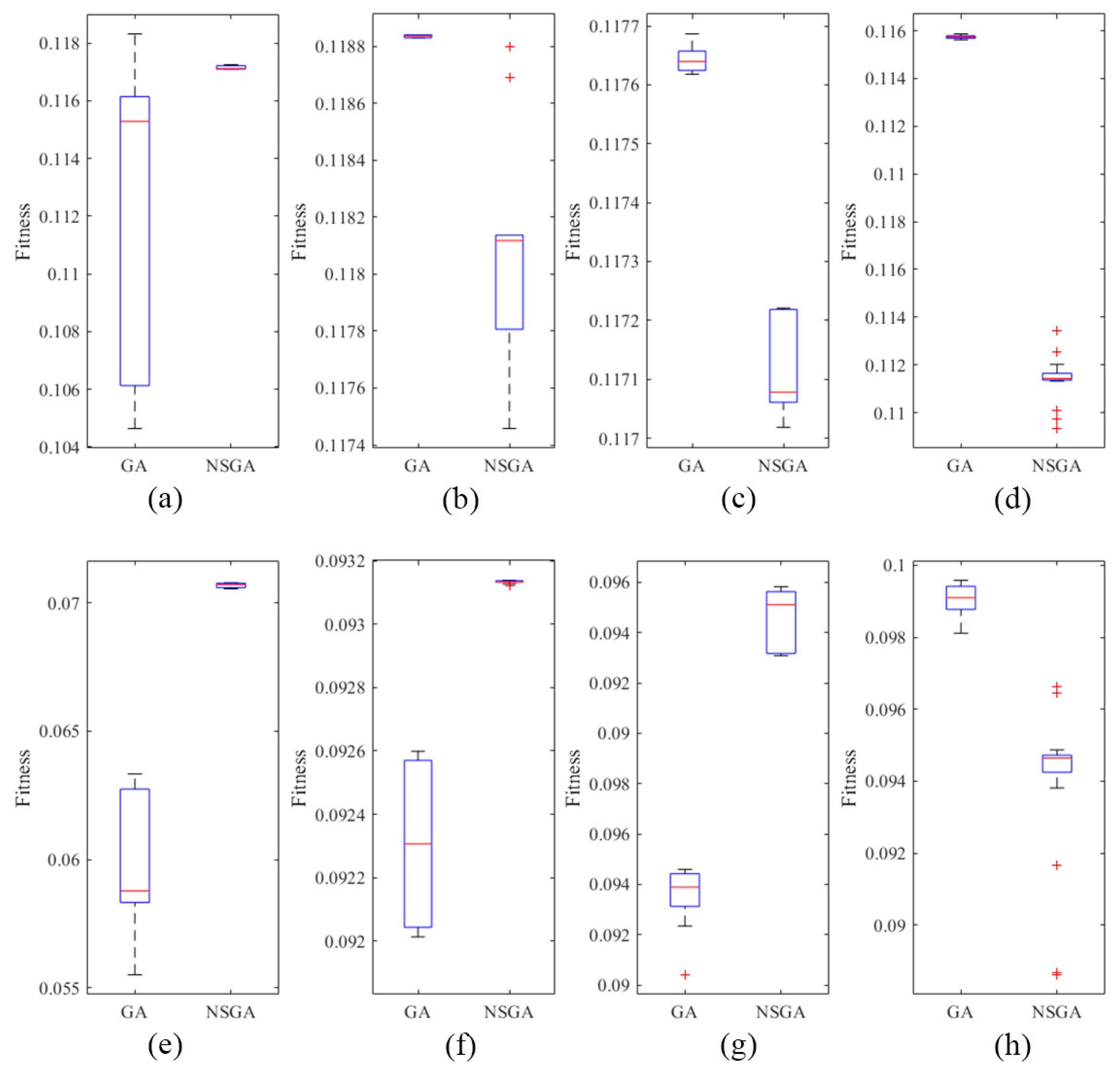
The performance of the solutions from our GA and NSGA was assessed using boxplot behavior analysis, the Wilcoxon rank-sum test, and performance metrics, as depicted in
Figure 2,
Table 1 and
Table 2, respectively. In the boxplot analysis shown in
Figure 2b–d,g, the data spread for GA was noticeably narrower than for NSGA. This observation suggested that GA outperformed NSGA in terms of data distribution for D-efficiency when
= 8 to 10, and in terms of minimum D-efficiency due to missing observations for
= 9. For
n = 10, GA and NSGA exhibited similar performances in terms of minimum D-efficiency resulting from missing observations, as illustrated in
Figure 2h. Based on the Wilcoxon rank-sum test, as detailed in
Table 1, the results indicated that (1) there was no difference in D-efficiency between GA7 and NSGA7; however, there was a difference in minimum D-efficiency due to missing observation between GA7 and NSGA7, (2) there is a difference in D-efficiency between GA and NSGA for
= 8 to 10, and (3) there was a difference in minimum D-efficiency due to missing observations between GA and NSGA for
= 10. For
= 8 to 9, the D-efficiency of GA outperformed that of NSGA. For
= 10, the minimum D-efficiency of GA due to missing observations was superior to that of NSGA. These outcomes aligned with the observations from
Figure 2. Based on the quantitative performance metrics that were outlined in
Table 2, our GA had exhibited the highest HV value for
= 7 and 9. However, for
= 8, the HV values of both GA and NSGA had been comparable. In terms of spacing values, GA’s values had generally been lower than those of NSGA, with the exception of
= 9. Based on our analysis, we could infer that our GA had been comparable to NSGA-II in terms of convergence accuracy and statistical significance for most benchmark functions.
Figure 3,
Figure 4,
Figure 5 and
Figure 6 display the distribution point patterns of all GA designs, all NSGA designs and the DX design for a range of design points from 7 to 10, respectively.
Figure 7 illustrates the FDS plot for all GA designs, all NSGA designs and the DX design in the context of a complete design, whereas
Figure 8 showcases the FDS plot for all GA designs, all GA designs and the DX design when the most impactful observation point was omitted.
Table 3 shows the D, A, G, and IV-efficiency and the maximum loss of D, A, G, and IV-efficiency due to a single missing observation. In
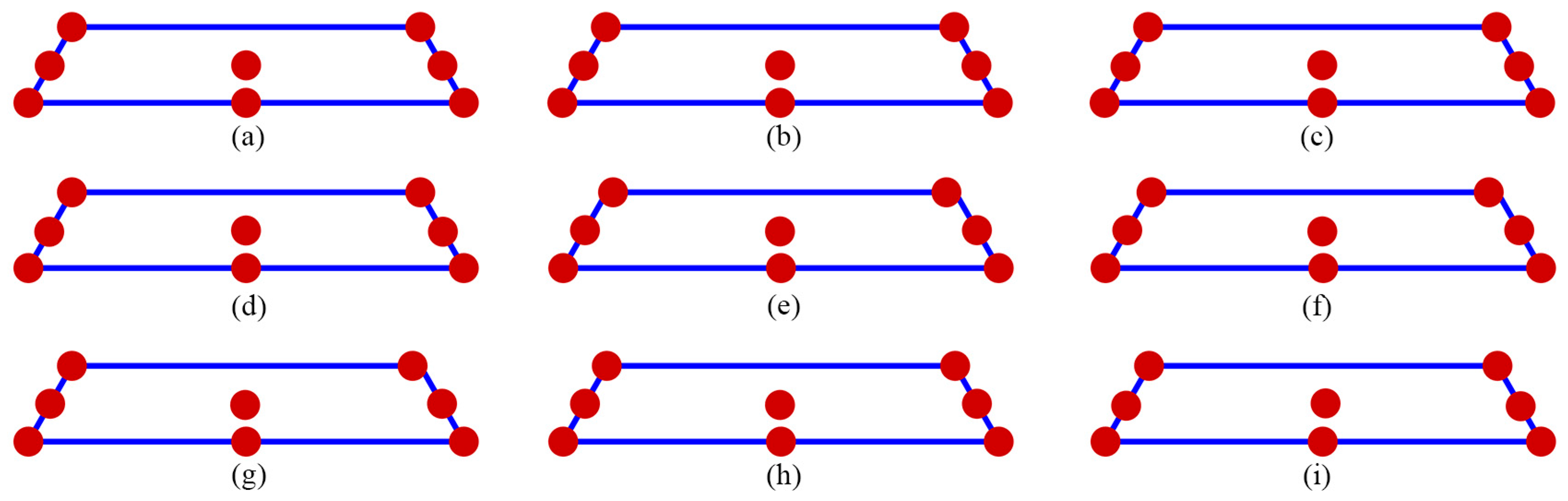
Figure 3, for
= 7, the distribution point patterns of all GA, NSGA and DX designs tended to occupy all vertices or locations near them, as well as positions close to two edge centroid points and near the overall centroid. The distribution point patterns of GA7.1, GA7.2, and GA7.3 designs were distinct, and they differed from those of the GA7.4 and DX7 designs. The GA7.4 and DX7 designs exhibited slight differences on the edge centroid points and overall centroid point, with other points being similar. In contrast, both the GA7.4 and DX7 designs varied from the NSAG7.1 design, particularly where their edge centroid points were located on different sides. Consequently, GA7.4 and DX7 designs demonstrated comparable performance in terms of D, A, G, and IV-efficiency as well as the maximum loss of D, A, G, and IV-efficiency due to a single missing observation. However, both GA7.4 and DX7 designs surpassed NSAG7.1 in measures of D, A, G, and IV-efficiency, and especially in the maximum loss of A-efficiency due to a single missing observation, as detailed in
Table 1. Additionally, both GA7.4 and DX7 designs had identical FDS curves for the complete design and demonstrated better performance in terms of prediction variance, as shown in
Figure 7a. However, when considering the FDS plot that omits the most impactful observation point, as illustrated in
Figure 8a, the FDS curves of NSGA7.1 design appeared lower and flatter compared to the other designs. Meanwhile, the FDS curves of GA7.4 and DX7 designs were comparable, except at the boundary of the design region. As depicted in
Figure 4, for
= 8, the distribution point patterns of all GA, all NSGA and DX designs bore resemblance to those of
= 7, but they tend to be closer to three edge centroid points, rather than two. In the case of
= 9, as depicted in
Figure 5, the point distribution patterns of all GA, NSGA, and DX designs resembled those of
= 8. However, there was an additional replicated point at a vertex for both GA and DX designs, while the NSGA designs featured a point on the long edge centroid. Lastly, for
= 10, the distribution point patterns of all GA and DX designs, as displayed in
Figure 6, mirrored those for
= 9, but with an added replicated point at two vertices. In contrast, the NSGA10 designs included an additional replicated point at one vertex, setting them apart from the GA10 and DX10 designs. Moreover, they did not mirror the patterns observed for
= 9.
As a result, the GA and DX design demonstrate similar performance in terms of (1) D-, A-, G-, and IV-efficiency, and (2) the FDS curves for both the complete design and scenarios where the most impactful observation point is omitted, as indicated in
Table 3 and
Figure 7 and
Figure 8. Based on D-efficiency, the GA and DX designs surpassed the NSAG designs. For A-efficiency, the GA, NSGA, and DX designs were comparable to each other. With respect to G-efficiency, the GA and DX designs were superior to the NSAG designs, except for
= 9. However, in terms of IV-efficiency, the three designs—GA, NSGA, and DX—were closely matched, with the exception of
= 9. Notably, most NSAG designs surpassed the GA and DX designs when considering the maximum efficiency loss due to a single missing observation. However, most GA designs outperformed the DX design when considering the maximum loss of D-, A-, G-, and IV-efficiency due to a single missing observation. As indicated in
Table 3, the GA7.4 design neither possessed the highest D-, A-, G-, and IV-efficiency nor did it have the lowest maximum loss of D-, A-, G-, and IV-efficiency due to a single missing observation. Instead, it maintained a middle level for all these values, which was considered desirable. As demonstrated in
Figure 7a and
Figure 8a, the GA7.4 design, when compared to other GA7 designs, displayed robustness against missing observations in terms of prediction variance. On the other hand, the NSGA7.1 design emerged as the most robust against missing observations with respect to prediction variance. This distinction for the NSGA7.1 design was particularly evident in its FDS curves. They were notably flatter and lower in both the complete design and scenarios involving the omission of more impactful observations. For
= 8, the FDS curves, depicted in
Figure 7b and
Figure 8b, revealed similar trends across all evaluated designs, whether considering the complete design or those scenarios that excluded key observations. For
= 9, as showcased in
Figure 7c and
Figure 8c, the GA and DX designs maintained similar levels of robustness against missing observations for prediction variance. However, the NSGA designs demonstrated greater robustness in this aspect than the GA designs. Regarding
n = 10, the FDS curves of all designs, with the exception of the NSGA10.4, were consistent when viewing the complete design and the scenarios that omitted significant observations, as seen in
Figure 7d and
Figure 8d. Nevertheless, when influential observations were excluded, the FDS curves for DX10 and NSGA10.4 became less competitive at the boundary of the design region, as indicated in
Figure 8d.
From our analysis, it became evident that the designs generated by our Genetic Algorithm (GA) seemed to exhibit robust properties against missing observation in terms of prediction variance. Our algorithm focused on creating robust designs that performed well not only in terms of D-efficiency but also in terms of minimum D-efficiency due to missing observation. Our GA designs successfully achieved these objectives. Furthermore, they also provided commendable A-, G-, and IV-efficiency, as well as manageable maximum losses of A-, G-, and IV-efficiency due to a single missing observation.
Following the strong performance of our GA in generating optimal mixture designs, we provided four GA designs as a reference to help experimenters understand their performance and balance requirements. This assisted in assessing how well these designs aligned with user priorities and their robustness in handling missing observation. An assessment was performed using the desirability function based on the geometric mean,
.
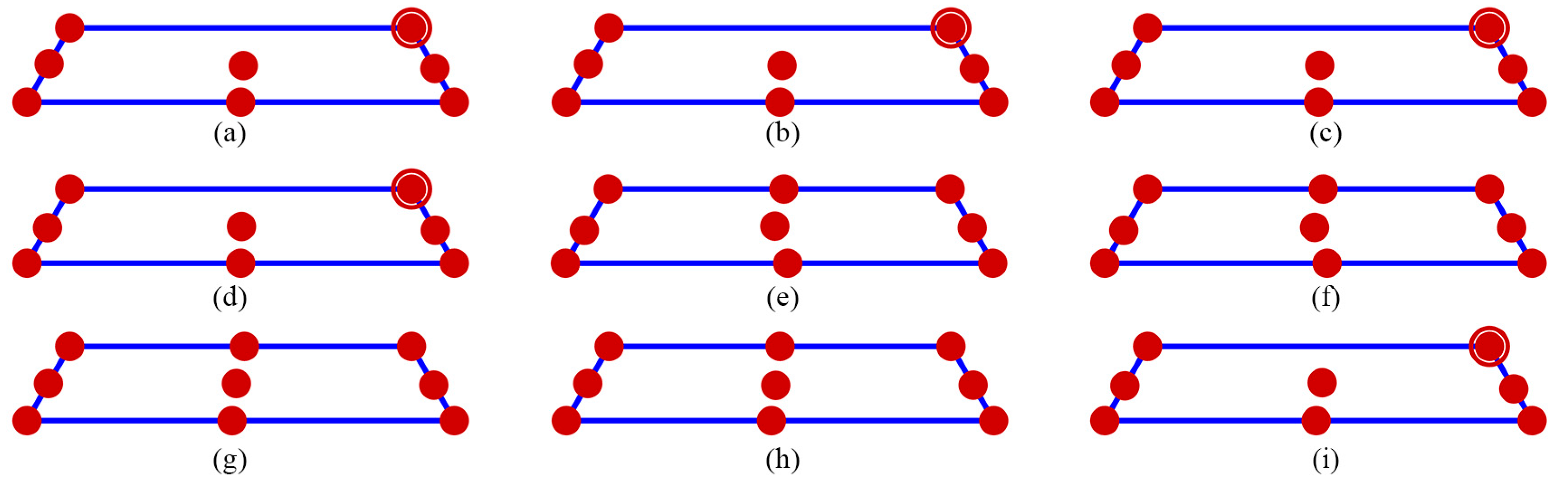
Figure 9 showed the desirability function based on the geometric mean. The numbers displayed in
Figure 8 corresponded to the numbers following the dots in the GA designs. The GA
.1 design was the optimal choice when the weight was 0, indicating that it was the optimal design based on the minimum D-efficiency due to missing observation. Conversely, the GA
.4 design was the optimal choice when the weight was 1, indicating that it was the optimal design based on the D-efficiency. The GA
.2 and GA
.3 designs became optimal when the weight ranged from 0.1 to 0.9, representing a trade-off between the minimum D-efficiency due to the missing observations and the D-efficiency. As illustrated in
Figure 9, for
= 7 and 9, the GA
.2 design was the optimal choice when the weight fell between 0.1 and 0.2. However, the GA
.3 design became the optimal choice when the weight was in the range of 0.3 to 0.9. For
= 8, the GA8.2 design was optimal when the weight ranged from 0.1 to 0.5, and the GA8.3 design was optimal when the weight ranged from 0.6 to 0.9. Interestingly, for
= 9, the GA9.2 design was the optimal choice when the weight was between 0.1 and 0.3, while the GA9.3 design became optimal for weights from 0.4 to 0.9. The
can serve as a tool, enabling experimenters to select the most robust optimal design based on their individual priorities. Therefore, in practice, if the primary focus of the experimenter was on minimizing the D-efficiency loss due to missing observations, the GA
.1 design would be preferred. However, if the emphasis was on the D-efficiency, the GA
.4 design would be more suitable. In cases where the experimenter wished to balance both criteria, the GA
.2 and GA
.3 designs would be the preferred choices.
6.2. Example 2: Mixture Problem as Presented in Myers et al. [2]
For our second example, we considered a mixture problem as presented by Myers et al. [
2]. The lower and upper proportion constraints for this problem are as follows:
The boundary in this case consists of six vertices. Even though this example has the same number of components as the first example, the shape of the experimental region differs. Similar to the first example, we thoroughly examined the selection of GA parameter values before implementing the GA. We determined an appropriate number of generations for convergence, setting a limit of 1500 generations. Consequently, the genetic parameter values in this example differ from those in the first example. Furthermore, we established the following ranges for the genetic parameter values:
Initially, the genetic parameter values are set to their maximum levels, and then systematically decreased to lower levels after 500 generations. In this example, the performance of the competing designs, encompassing 7 to 10 runs, is demonstrated.
Figure 10 features the Pareto front, emphasized in gray, and illustrates a well-distributed set of optimal GA and optimal NSGA designs. These designs resulted from the application of a thinning technique to a rich Pareto front using
-dominance. The five GA designs chosen from the Pareto front, namely GAM
.1, GAM
.2, GAM
.3, GAM
.4, and GAM
.5, are denoted by red, blue, black, magenta, and cyan dots, respectively. The three NSGA designs chosen from the Pareto front, namely NSGAM
.1, NSGAM
.2, and NSGAM
.3, are denoted by red, magenta, and cyan dots, respectively.
As evidenced in the initial example, the gap between the highest and lowest D-efficiency, as well as the gap between the highest and lowest minimum D-efficiency due to a missing observation, were greater for
= 7 compared to
= 8 to 10 in the GA. Conversely, these gaps were generally smaller for NSGA than for GA, except in the cases of
= 9. Moreover, the distribution patterns of the Pareto front for GA and NSGA exhibited distinct differences, as illustrated in
Figure 10. The performance of the solutions from our GA and NSGA was assessed using boxplot behavior analysis, the Wilcoxon rank-sum test, and performance metrics, as depicted in
Figure 11,
Table 4 and
Table 5, respectively. In the boxplot analysis presented in
Figure 11, the data spread for GA was notably wider than that for NSGA, although the range of the y-axis was quite small. Upon considering the Wilcoxon rank-sum test presented in
Table 4, the results indicated that (1) there was no significant difference in D-efficiency and minimum D-efficiency due to missing observations between GA8 and NSGA8, (2) there was no significant difference in minimum D-efficiency due to missing observations between GA9 and NSGA9, (3) there was a significant difference in D-efficiency and minimum D-efficiency due to missing observations between GA and NSGA for
n = 7 and 10, and (4) there was a notable difference in D-efficiency between GA9 and NSGA9. These results are consistent with the findings from the boxplot analysis. Based on the quantitative performance metrics presented in
Table 5, our GA demonstrated superior performance by achieving the highest HV value and lower or comparable spacing across all design points. From this analysis, we can infer that our GA generally outperforms or is at least comparable to the NSGA-II in terms of convergence accuracy and statistical significance for the majority of benchmark functions.
As depicted in
Figure 12, for
= 7, the distribution point patterns of all GA and DX designs tended to be positioned on or near all vertices, as well as close to the overall centroid. In contrast, the distribution patterns of all points in NSGA7 were primarily near the overall centroid but did not necessarily align with or near all vertices. In the case of
= 8, illustrated in
Figure 13, the distribution point patterns of all GA and DX designs resembled those of
= 7, but with an additional point near the edge centroid. The distribution patterns of all points in NSGA8 resembled those of the GA and DX designs. For
= 9, as shown in
Figure 14, the distribution point patterns of all GA and DX designs mirrored those of
= 8, but they were located near two edge centroid points instead of one. On the other hand, the distribution patterns of all points in NSGA9 differed from those of NSGA8, including a point on the face and an edge centroid on the opposite side. Finally, when
= 10, as depicted in
Figure 15, the distribution point patterns of the GA and DX designs differed. However, the distribution patterns of the points for GA and NSGA designs exhibited similarities. The GA and NSGA designs tended to be located on or near all vertices, close to three edge centroid points and the overall centroid point. On the other hand, the DX designs were positioned on or near all vertices, at two replicated vertices, near an edge centroid point and the overall centroid point.
Figure 16 presents the FDS plot for all GA designs, all NSGA designs and the DX design for a complete design, while
Figure 17 depicts the FDS plot for all GA designs, all NSGA designs and the DX design when the most impactful observation point is omitted.
Table 6 shows the D, A, G, and IV-efficiency as well as the maximum loss of D-, A-, G-, and IV-efficiency due to a single missing observation. The GA design and DX design exhibited comparable performance in terms of prediction variance, with the exception of the GAM7.1 design, which showed inferior performance at the boundary, as illustrated in
Figure 16a and
Figure 17a. Both the GAM7.2 and GMM7.3 designs demonstrated similar FDS curves in the complete design and when the most impactful observation point was omitted. Consequently, these designs appeared to possess robust properties against missing observations. The NSGAM7 designs, however, did not appear to have such robust properties against missing observations, as illustrated in
Figure 16a and
Figure 17a. The GAM7 and DXM7 designs were largely equivalent in terms of D-, A-, G-, and IV-efficiency, but the DXM7 design fell short when considering the maximum loss of D-, A-, G-, and IV-efficiency due to a single missing observation, as detailed in
Table 6. Nonetheless, the NSGA7 designs demonstrated good performance in terms of the maximum loss of efficiency due to a single missing observation. For
= 8 and 9, the FDS curves for the complete design of the NSGA designs were lower than those of the GA and DX designs, though they were comparable at the design space boundary.
The FDS curves displayed notable similarity across all competing designs when the most impactful observation point was omitted. As a result, the GA, NSGA and DX designs seemed to exhibit robust properties in the face of missing observation. The GAM8.3, GAM8.4, GAM8.5, NSGAM8.1, NSGAM8.2 and DXM8 designs were quite comparable in terms of D-, A-, G-, and IV-efficiency, as well as the maximum loss of D, A, G, and IV-efficiency due to a single missing observation. Meanwhile, for
= 9, the GAM9 and DXM9 designs showed a similar comparison in terms of D-, A-, G-, and IV-efficiency, and also in the maximum loss of these efficiencies due to a single missing observation. However, the NSGA9 designs did not perform well in terms of D-efficiency. For
= 10, as illustrated in
Figure 16d and
Figure 17d, the FDS curves of the GA and NSGA designs outperformed the DX design for both the complete design and when the most impactful observation point was omitted. The FDS curves of the GA and NSGA designs were identical in both the complete design and when the most impactful observation point was omitted. The GAM10 and NSGAM10 designs outperformed in terms of D-, A-, G-, and IV-efficiency, and also showed a smaller maximum loss of these efficiencies due to a single missing observation. Consequently, the GAM10 and NSGAM10 designs appeared to possess strong robustness properties when faced with missing observations. These observations emphasize that even though designs may appear comparable based on prediction variance, it does not necessarily imply comparability on other criteria. When comparing the robustness of designs due to missing observation, experimenters should consider multiple criteria. Based on these results, we can conclude that our GA exhibited the ability to generate an optimal mixture design despite missing observations.
Upon demonstrating the effectiveness of our GA in creating optimal mixture designs, we made available four reference GA designs. This allowed experimenters to assess their performance and effectively balance their requirements.
Figure 18 displays the desirability function based on the geometric mean, which helps assess how well these designs align with user priorities and their robustness in handling missing observations. The GAM
.1 design emerged as the optimal choice when the weight was 0, indicating its optimal performance based on the minimum D-efficiency due to missing observation. Conversely, the GAM
.5 design was the optimal choice when the weight was 1, signifying its superiority based on D-efficiency. The GAM7.2 design became optimal for weights ranging from 0.1 to 0.6, whereas the GAM7.3 design took precedence for weights between 0.7 and 0.9. The GAM8.2 design was optimal for weights ranging from 0.1 to 0.8, while the GAM8.3 design stood out when the weight was 0.9. For
= 9, the GAM9.2 design was the optimal choice for weights between 0.1 and 0.3. The GAM9.3 design became optimal for weights between 0.4 and 0.7, and the GAM9.4 design excelled for weights between 0.8 and 0.9. Finally, for
= 10, the GAM10.2 design was optimal for weights between 0.1 and 0.3. The GAM10.3 design took the lead for weights between 0.4 and 0.5, and the GAM10.4 design was optimal for weights ranging from 0.6 to 0.9. In practice, if an experimenter aims to balance both the D-efficiency and the minimum D-efficiency loss due to missing observations, the GA designs optimal for each weight may serve as good choices. This is because they can facilitate trade-offs between the two criteria and demonstrate robustness against missing observations. Their performance is measured based on prediction variance, optimality criteria, and loss of efficiency.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}