

ATC-YOLOv5: Fruit Appearance Quality Classification Algorithm Based on the Improved YOLOv5 Model for Passion Fruits

Abstract
:1. Introduction
2. Related Work
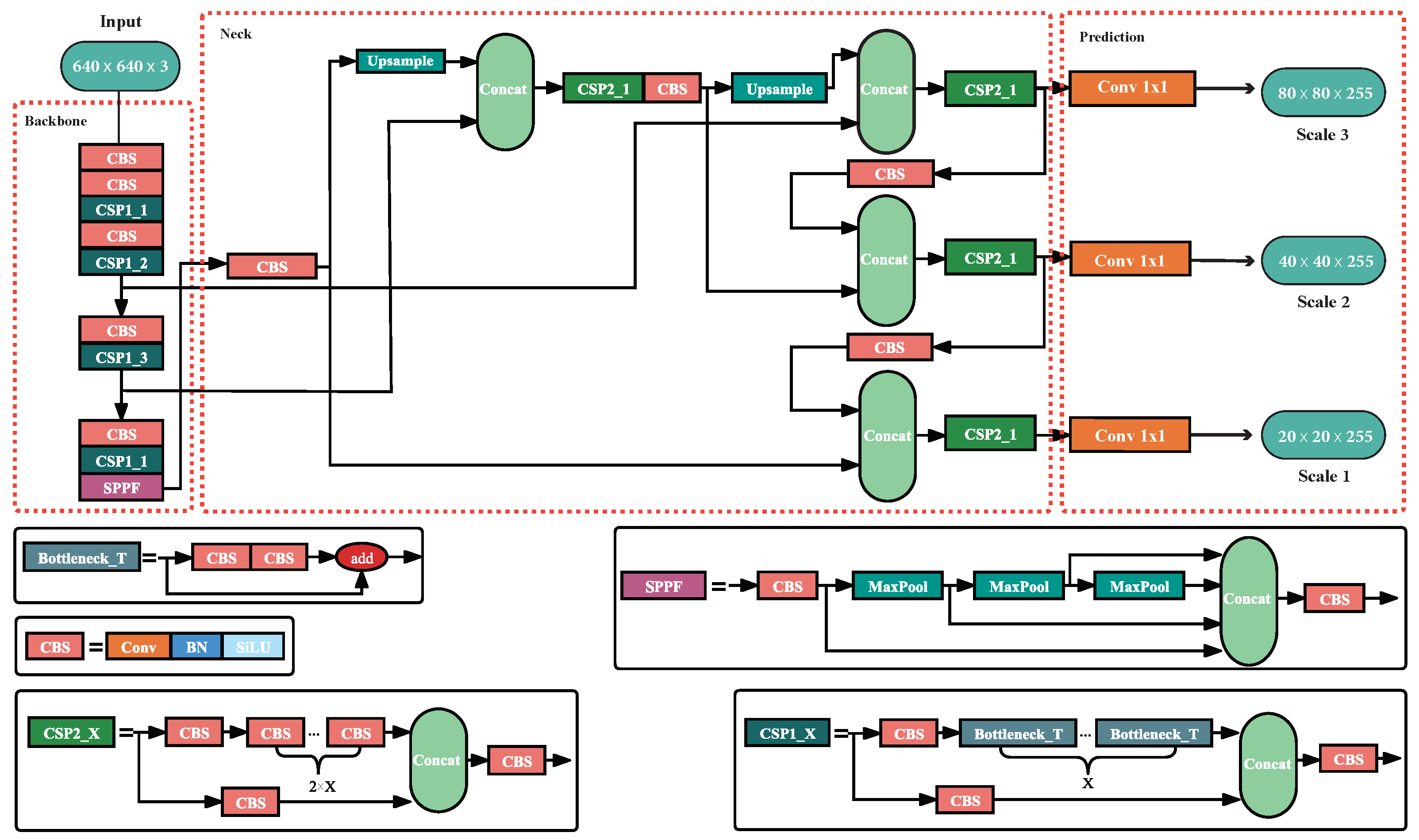
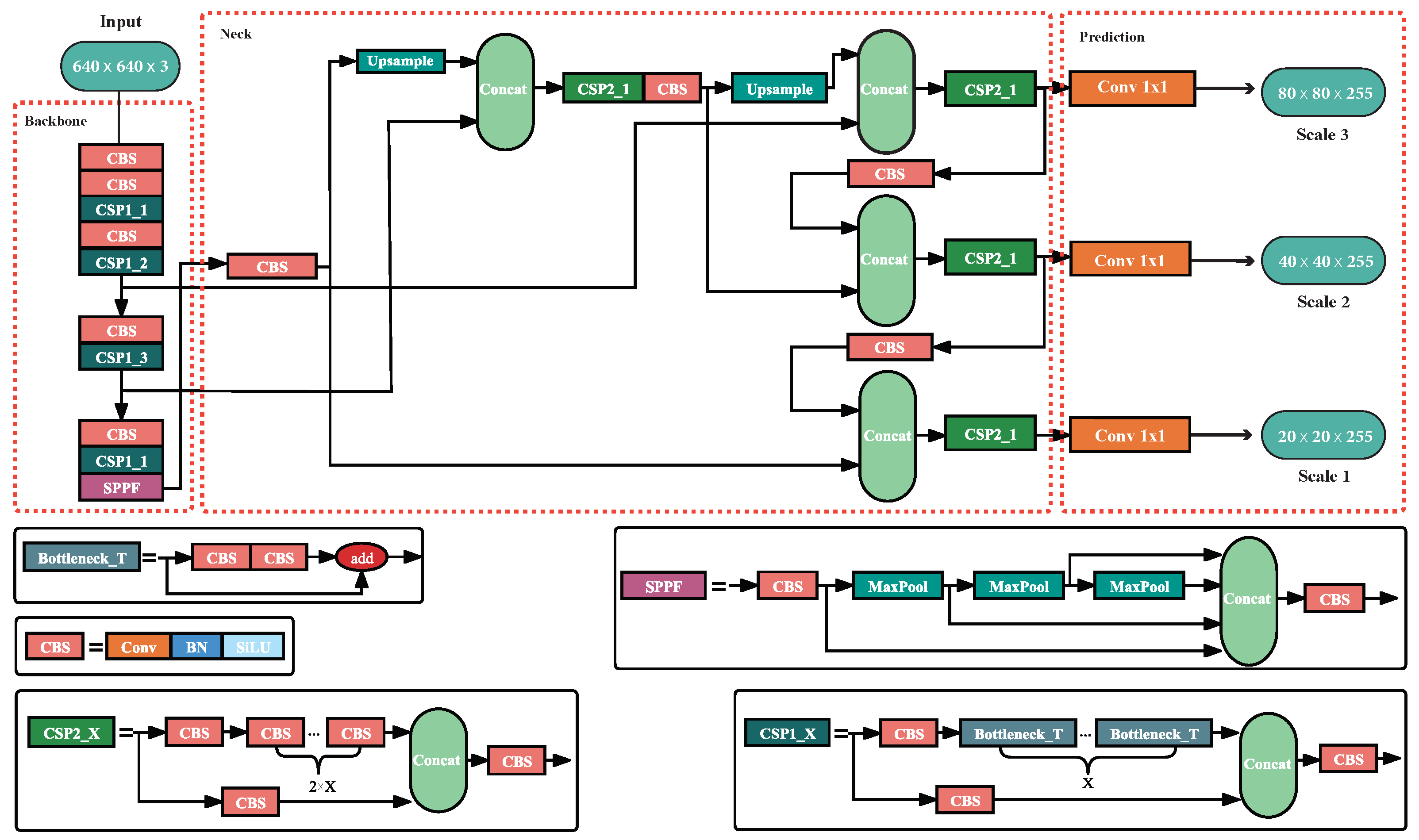
2.1. YOLOv5
2.2. Data Augmentation
2.3. Coordinate Attention Blocks
2.4. Bottleneck Transformer Blocks
3. Methods
3.1. Overview of ATC-YOLOv5
3.2. Improved Feature Pyramid Network Based on AFPN
3.3. Improved CSP Model Based on MHSA Bottleneck
3.4. Coordinate Attention Module in Neck
4. Results and Discussion
4.1. Dataset Details
4.2. Experimental Settings
4.3. Evaluation Indicator
4.4. Reasons for Data-Augmentation Applications
4.5. Ablation Studies
4.6. Performance Comparison and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bhargava, A.; Bansal, A. Fruits and vegetables quality evaluation using computer vision: A review. J. King Saud Univ. Comput. Inf. 2021, 33, 243–257. [Google Scholar] [CrossRef]
- Wang, C.; Liu, S.; Wang, Y.; Xiong, J.; Zhang, Z.; Zhao, B.; Luo, L.; Lin, G.; He, P. Application of convolutional neural network-based detection methods in fresh fruit production: A comprehensive review. Front. Plant Sci. 2022, 13, 868745. [Google Scholar] [CrossRef] [PubMed]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Li, K.; Wang, J.; Jalil, H.; Wang, H. A fast and lightweight detection algorithm for passion fruit pests based on improved YOLOv5. Comput. Electron. Agric. 2023, 204, 107534. [Google Scholar] [CrossRef]
- Sharma, A.K.; Nguyen, H.H.C.; Bui, T.X.; Bhardwa, S.; Van Thang, D. An Approach to Ripening of Pineapple Fruit with Model Yolo V5. In Proceedings of the 2022 IEEE 7th International conference for Convergence in Technology (I2CT), Pune, India, 7–9 April 2022; pp. 1–5. [Google Scholar]
- Bortolotti, G.; Mengoli, D.; Piani, M.; Grappadelli, L.C.; Manfrini, L. A computer vision system for in-field quality evaluation: Preliminary results on peach fruit. In Proceedings of the 2022 IEEE Workshop on Metrology for Agriculture and Forestry (MetroAgriFor), Perugia, Italy, 3–5 November 2022; pp. 180–185. [Google Scholar]
- Mirhaji, H.; Soleymani, M.; Asakereh, A.; Mehdizadeh, S.A. Fruit detection and load estimation of an orange orchard using the YOLO models through simple approaches in different imaging and illumination conditions. Comput. Electron. Agric. 2021, 191, 106533. [Google Scholar] [CrossRef]
- Naranjo-Torres, J.; Mora, M.; Hernández-García, R.; Barrientos, R.J.; Fredes, C.; Valenzuela, A. A review of convolutional neural network applied to fruit image processing. Appl. Sci. 2020, 10, 3443. [Google Scholar] [CrossRef]
- Goyal, K.; Kumar, P.; Verma, K. AI-based fruit identification and quality detection system. Multimed. Tools Appl. 2022, 82, 24573–24604. [Google Scholar] [CrossRef]
- Cheng, Y.H.; Tseng, C.Y.; Nguyen, D.M.; Lin, Y.D. YOLOv4-Driven Appearance Grading Filing Mechanism: Toward a High-Accuracy Tomato Grading Model through a Deep-Learning Framework. Mathematics 2022, 10, 3398. [Google Scholar] [CrossRef]
- Shankar, K.; Kumar, S.; Dutta, A.K.; Alkhayyat, A.; Jawad, A.J.M.; Abbas, A.H.; Yousif, Y.K. An automated hyperparameter tuning recurrent neural network model for fruit classification. Mathematics 2022, 10, 2358. [Google Scholar] [CrossRef]
- Gururaj, N.; Vinod, V.; Vijayakumar, K. Deep grading of mangoes using Convolutional Neural Network and Computer Vision. Multimed. Tools Appl. 2022, 1–26. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.; Wang, Z.; McCarthy, C. Deep learning for real-time fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Patil, P.U.; Lande, S.B.; Nagalkar, V.J.; Nikam, S.B.; Wakchaure, G. Grading and sorting technique of dragon fruits using machine learning algorithms. J. Agric. Food Res. 2021, 4, 100118. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Xu, F.; Jin, Y.Q. Complex-Valued Convolutional Neural Network and Its Application in Polarimetric SAR Image Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7177–7188. [Google Scholar] [CrossRef]
- Hearst, M.; Dumais, S.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef]
- Tu, S.; Xue, Y.; Zheng, C.; Qi, Y.; Wan, H.; Mao, L. Detection of passion fruits and maturity classification using Red-Green-Blue Depth images. Biosyst. Eng. 2018, 175, 156–167. [Google Scholar] [CrossRef]
- Tu, S.; Pang, J.; Liu, H.; Zhuang, N.; Chen, Y.; Zheng, C.; Wan, H.; Xue, Y. Passion fruit detection and counting based on multiple scale faster R-CNN using RGB-D images. Precis. Agric. 2020, 21, 1072–1091. [Google Scholar] [CrossRef]
- Lu, Y.; Wang, R.; Hu, T.; He, Q.; Chen, Z.S.; Wang, J.; Liu, L.; Fang, C.; Luo, J.; Fu, L.; et al. Nondestructive 3D phenotyping method of passion fruit based on X-ray micro-computed tomography and deep learning. Front. Plant Sci. 2023, 13, 1087904. [Google Scholar] [CrossRef]
- Duangsuphasin, A.; Kengpol, A.; Rungsaksangmanee, P. The Design of a Deep Learning Model to Classify Passion Fruit for the Ageing Society. In Proceedings of the 2022 Research, Invention, and Innovation Congress: Innovative Electricals and Electronics (RI2C), Virtual, 4–5 August 2022; pp. 15–19. [Google Scholar]
- Behera, S.K.; Rath, A.K.; Sethy, P.K. Fruits yield estimation using Faster R-CNN with MIoU. Multimed. Tools Appl. 2021, 80, 19043–19056. [Google Scholar] [CrossRef]
- Maheswari, P.; Raja, P.; Apolo-Apolo, O.E.; Pérez-Ruiz, M. Intelligent fruit yield estimation for orchards using deep learning based semantic segmentation techniques—A review. Front. Plant Sci. 2021, 12, 684328. [Google Scholar] [CrossRef]
- Renjith, P.N.; Muthulakshmi, A. Comprehensive Systematic Review on Fruit Maturity Detection Technique. In Proceedings of the 2021 Second International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 4–6 August 2021; pp. 1234–1240. [Google Scholar]
- Tan, K.; Lee, W.S.; Gan, H.; Wang, S. Recognising blueberry fruit of different maturity using histogram oriented gradients and colour features in outdoor scenes. Biosyst. Eng. 2018, 176, 59–72. [Google Scholar] [CrossRef]
- Adak, M.F.; Yumusak, N. Classification of E-Nose Aroma Data of Four Fruit Types by ABC-Based Neural Network. Sensors 2016, 16, 304. [Google Scholar] [CrossRef] [PubMed]
- Gill, H.S.; Khalaf, O.I.; Alotaibi, Y.; Alghamdi, S.; Alassery, F. Fruit Image Classification Using Deep Learning. CMC-Comput. Mater. Contin. 2022, 71, 5135–5150. [Google Scholar] [CrossRef]
- Joseph, J.L.; Kumar, V.A.; Mathew, S.P. Fruit Classification Using Deep Learning. In Innovations in Electrical and Electronic Engineering; Springer: Berlin/Heidelberg, Germany, 2021; pp. 617–626. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Koo, Y.; Kim, S.; Ha, Y.g. OpenCL-Darknet: Implementation and optimization of OpenCL-based deep learning object detection framework. World Wide Web 2021, 24, 1299–1319. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9–10. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Neural Activation Function. arXiv 2019, arXiv:abs/1908.08681. [Google Scholar]
- Foret, P.; Kleiner, A.; Mobahi, H.; Neyshabur, B. Sharpness-Aware Minimization for Efficiently Improving Generalization. arXiv 2020, arXiv:2010.01412. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Dropblock: A regularization method for convolutional networks. Adv. Neur. 2018, 31. [Google Scholar]
- Jocher, G.; Nishimura, K.; Mineeva, T.; Vilariño, R. YOLOv5 (2020). GitHub Repository. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 July 2023).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Mumuni, A.; Mumuni, F. Data augmentation: A comprehensive survey of modern approaches. Array 2022, 100258. [Google Scholar] [CrossRef]
- Kandel, I.; Castelli, M.; Manzoni, L. Brightness as an augmentation technique for image classification. Emerg. Sci. J. 2022, 6, 881–892. [Google Scholar] [CrossRef]
- Gedraite, E.S.; Hadad, M. Investigation on the effect of a Gaussian Blur in image filtering and segmentation. In Proceedings of the ELMAR-2011, Zadar, Croatia, 14–16 September 2011; pp. 393–396. [Google Scholar]
- Hussain, Z.; Gimenez, F.; Yi, D.; Rubin, D. Differential data augmentation techniques for medical imaging classification tasks. In Proceedings of the AMIA Annual Symposium Proceedings, American Medical Informatics Association, Washington, DC, USA, 4–8 November 2017; Volume 2017, p. 979. [Google Scholar]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Huber, J.F. Mobile next-generation networks. IEEE Multimed. 2004, 11, 72–83. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 20–25 June 2021; pp. 16519–16529. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6409–6418. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vision 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. arXiv 2023, arXiv:2306.15988. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 2736–2746. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neur. 2015, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Alimentarius, C. Standard for passion fruit Codex Stan 316-2014. In Proceedings of the Codex Committee on Fresh Fruits and Vegetables (18th Session), Phuket, Thailand, 24–28 February 2014. [Google Scholar]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLO by Ultralytics. GitHub Repository. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 August 2023).
- Yu, J.; Miao, W.; Zhang, G.; Li, K.; Shi, Y.; Liu, L. Target Positioning and Sorting Strategy of Fruit Sorting Robot Based on Image Processing. Trait. Signal. 2021, 38, 797–805. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Grade | Requirements for Each Grade |
|---|---|
| Extra Class (superior quality) | Must be free of defects; only very slight superficial defects are acceptable. |
| Class I (good quality) | The following slight defects are acceptable: 1. a slight defect in shape. 2. slight defects of the skin such as scratches, not exceeding more than 10% of the total surface area of the fruit. 3. slight defects in colouring. (The defects must not, in any case, affect the flesh of the fruit) |
| Class II (average quality) | Satisfy the minimum requirements (2) but do not qualify for inclusion in the higher classes. The following defects are allowed: 1. defects in shape, including an extension in the zone of the stalk. 2. defects of the skin such as scratches or rough skin, not exceeding more than 20% of the total surface area of the fruit. 3. defects in colouring. (The passion fruits must retain their essential characteristics as regards the quality, keeping quality, and presentation) |
| “Bad” class (NOT ready for sale) | A passion fruit will be classified as this grade if it does not meet any of the minimum requirements (2) |
| Classification Details |
|---|
| fresh in appearance (without rotting) |
| clean, free of any visible foreign matter |
| practically free of pests and damage caused by them affecting the general appearance |
| free of abnormal external moisture |
| the stem/stalk should be present |
| free of cracking |
| Parameter | Configuration |
|---|---|
| CPU | Intel (R) Xeon (R) Platinum 8358P |
| GPU | NVIDIA RTX3090 |
| CUDA version | Cuda 11.3 |
| Python version | Python 3.8 |
| Deep learning framework | PyTorch 1.11.0 |
| Operating system | ubuntu 20.04 |
| Scheme | AFPN | Improved AFPN | Coordinate Attention Module | TRCSP |
|---|---|---|---|---|
| YOLOv5s (baseline) | ||||
| AFPN-YOLOv5s | √ | |||
| iAFPN-YOLOv5s | √ | |||
| iAFPN-CA-YOLOv5s | √ | √ | ||
| iAFPN-TRCSP-YOLOv5s | √ | √ | ||
| ATC-YOLOv5 (ours) | √ | √ | √ |
| Algorithms | mAP50/% | F1/% | P/% | R/% | Param */M | mDT/ms | GFLOPs |
|---|---|---|---|---|---|---|---|
| YOLOv5s (baseline) | 90.53 | 86.55 | 86.63 | 86.48 | 7.02 | 3.6 | 15.8 |
| AFPN-YOLOv5s | 91.88 | 87.55 | 86.53 | 88.6 | 6.37 | 3.6 | 15 |
| iAFPN-YOLOv5s | 93.12 | 87.74 | 87.62 | 87.86 | 6.46 | 3.7 | 15.1 |
| iAFPN-CA-YOLOv5s | 93.67 | 89.00 | 90.19 | 87.85 | 6.47 | 3.3 | 15.1 |
| iAFPN-TRCSP-YOLOv5s | 94.88 | 87.32 | 85.22 | 89.52 | 6.26 | 3.1 | 14.9 |
| ATC-YOLOv5 (ours) | 95.36 | 89.30 | 87.88 | 90.76 | 6.28 | 3.2 | 14.9 |
| Algorithms | Input Size | mAP50/% | F1/% | P/% | R/% | Param */M | mDT/ms | GFLOPs |
|---|---|---|---|---|---|---|---|---|
| YOLOv3 [33] | 480 × 640 | 80.96 | 81.48 | 79.34 | 83.37 | 97.34 | 8.4 | 116.0 |
| Darknet-YOLOv4 [34] | 480 × 640 | 81.56 | 83.67 | 79.61 | 86.85 | 140.09 | 10.08 | 105.8 |
| YOLOv6-s [63] | 640 × 640 | 82.91 | 79.10 | 87.42 | 75.22 | 18.5 | 7.38 | 45.2 |
| YOLOv7-tiny [64] | 640 × 640 | 70.38 | 69.45 | 69.63 | 69.32 | 6.01 | 5.8 | 13.0 |
| YOLOv8-s [65] | 640 × 640 | 87.75 | 79.98 | 78.60 | 81.40 | 11.13 | 8.00 | 28.4 |
| SSD300 [28] | 300 × 300 | 75.24 | 60.45 | 87.78 | 46.17 | 24.1 | 8.26 | 15.3 |
| ATC-YOLOv5 (ours) | 640 × 640 | 95.36 | 89.30 | 87.88 | 90.76 | 6.28 | 3.2 | 14.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Lin, W.; Feng, Y.; Guo, Z.; Xie, Z. ATC-YOLOv5: Fruit Appearance Quality Classification Algorithm Based on the Improved YOLOv5 Model for Passion Fruits. Mathematics 2023, 11, 3615. https://doi.org/10.3390/math11163615
Liu C, Lin W, Feng Y, Guo Z, Xie Z. ATC-YOLOv5: Fruit Appearance Quality Classification Algorithm Based on the Improved YOLOv5 Model for Passion Fruits. Mathematics. 2023; 11(16):3615. https://doi.org/10.3390/math11163615
Chicago/Turabian StyleLiu, Changhong, Weiren Lin, Yifeng Feng, Ziqing Guo, and Zewen Xie. 2023. "ATC-YOLOv5: Fruit Appearance Quality Classification Algorithm Based on the Improved YOLOv5 Model for Passion Fruits" Mathematics 11, no. 16: 3615. https://doi.org/10.3390/math11163615