1. Introduction
In most machine learning problems, several objectives are aggregated as one objective function. Therefore, the design of machine learning systems can generally be considered a Multi-objective Optimization Problem (MOP) [
1]. In the multi-objective optimization form of classification problem, appropriate trade-offs must be found between several objective functions, for example, between model complexity and accuracy, sensitivity and specificity, the sum of distances of misclassified points to the separating hyperplanes and the distance between the two bounding planes that generate the separating plane or the number of misclassified training data and the number of non-zero elements of separating hyperplane [
1,
2]. In various research, it has been shown that multi-objective machine learning algorithms are more powerful in improving generalization and knowledge extraction ability compared to single-objective learning, especially in topics such as Feature Selection, sparsity, and clustering [
1,
3].
Optimization algorithms, when there are a large number of variables or constraints, could account for most of the computation time. So far, various sparse matrices that arise in optimization have been investigated [
4]. In many fields of linear systems, such as engineering problems, science, and signal and image processing, a search for sparse solutions is required. Mathematical optimization plays an essential role in the development of numerical algorithms for searching the sparsity in solutions [
5].
Support vector machines (SVMs) use a hyperplane to separate samples into one of two classes. It is mentioned in [
6] that it is convenient to combine the SVM problem with a set theory for set-based particle swarm optimization (SBPSO) to be used to find the optimal separator hyperplane. This method is called SBPSO-SVM [
6].
In many MOPs, conflicting objective functions must be optimized [
7,
8]. These problems are used when the optimal decision to adopt two or more objectives is interdependent, for example, in economics, logistics, and many engineering and scientific problems [
6]. In this case, the optimization problem has no single solution representing the optimal solution for all objectives simultaneously [
9,
10,
11]. In MOPs, a solution with the most appropriate trade-off between objectives is found in which no objective is improved without worsening at least one other objective [
12,
13]. This solution is known as the Pareto optimal solution [
14]. The set of all Pareto optimal solutions is known as the Pareto set or Pareto frontier [
15,
16].
Although single-objective machine learning problems have been well studied [
17,
18,
19,
20,
21,
22,
23], there are fewer studies on multi-objective machine learning problems. Multi-objective machine learning is an approach to determining an appropriate trade-off between generally conflicting objectives [
24,
25,
26]. In multi-objective machine learning approaches, the main advantage is that you can obtain a deeper insight into the learning problem by analyzing the produced Pareto frontier [
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41]. In some multi-objective approaches, two objectives are simultaneously considered: minimizing the classification error and the norm of the weight vectors [
42].
This article presents multi-objective classification problems to obtain Pareto-optimal solutions (Pareto frontier). In these multi-objective optimization problems, one objective is used to minimize the classification error, and another objective is used to minimize the number of non-zero elements of the separator hyperplane.
The rest of the article is organized as follows. In
Section 2, some basic concepts and notations, including binary classification, support vector machine classification methods, sparse optimization, and multi-objective optimization problems, are given. In
Section 3, multi-objective reformulation of support vector machine models is presented. The results of several numerical experiments are presented in
Section 4. Conclusions are devoted to
Section 5.
4. Numerical Experiments
The results of models mentioned in the previous sections on some numerical experiments are presented in this section. To compare the results, all these models are solved as single-objective and multi-objective forms. To solve the test problems, we used “GlobalSolve” in the Global Optimization package in MAPLE version 18.01. The Global Optimization Toolbox uses global search algorithms that systematically search the entire feasible region for a global extremum [
63]. The algorithms in the Global Optimization toolbox are global search methods, which systematically search the entire feasible region for a global extremum [
65]. The global solver minimizes a merit function and considers a penalty term for the constraints. In this method, the global search phase is followed by a series of local searches to refine solutions. This solver is designed to search the specified region for a general solution, especially in non-convex optimization problems [
66].
We solved all single-objective models (models (6), (7), (11), and (12)) for and . However, only the results of have been reported because the error of some of these models for was not equal to zero.
We have implemented all the multi-objective models to obtain 100 Pareto optimal solutions. That is, the algorithm ends after 100 repetitions, and this is the stopping criterion of the algorithm. Since the second objective functions are different in models (17) to (20), we have used the projection of Pareto solutions in the objective function space of model (17) to better compare the Pareto optimal solutions of these models.
Since the minimization of the number of non-zero components of the normal vector of the separator hyperplane and the minimization of the classification error at the same time are two goals of different SVM models, the test problems are specifically designed to challenge the number of non-zero components of the normal vector of the separator hyperplane.
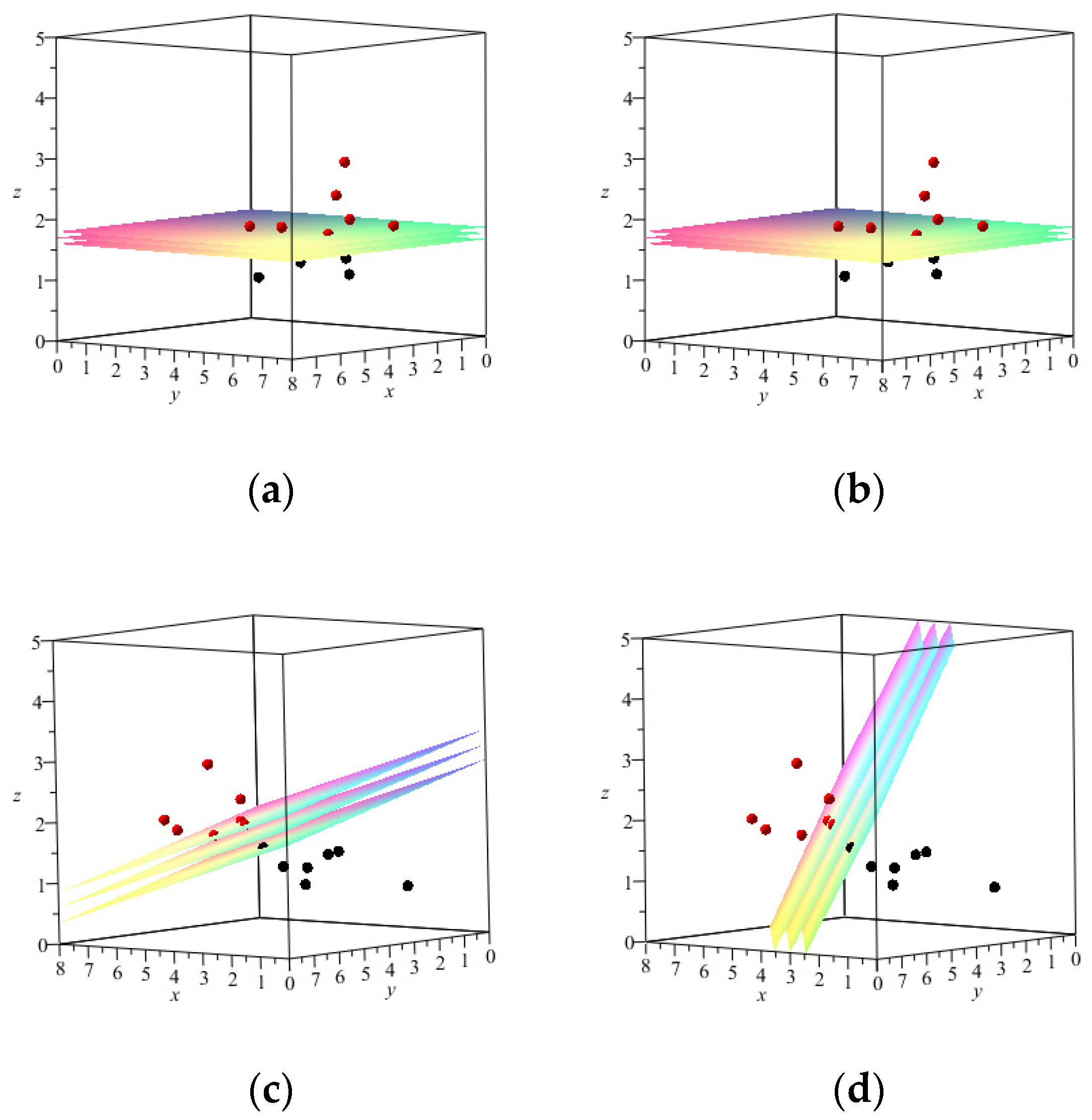
Test Problem 1. The number of samples is 14, and the number of features is 3 in this test problem. Suppose that we have two sets as follows:
The single-objective models all provide the correct set separator (that is, the error of all these models is zero). The vector
returned by BM-SVM and SVM
0 methods has just one non-zero component, but
and
return a vector
where components are all non-zero. The results of these single-objective models are depicted in
Table 1 and
Figure 1.
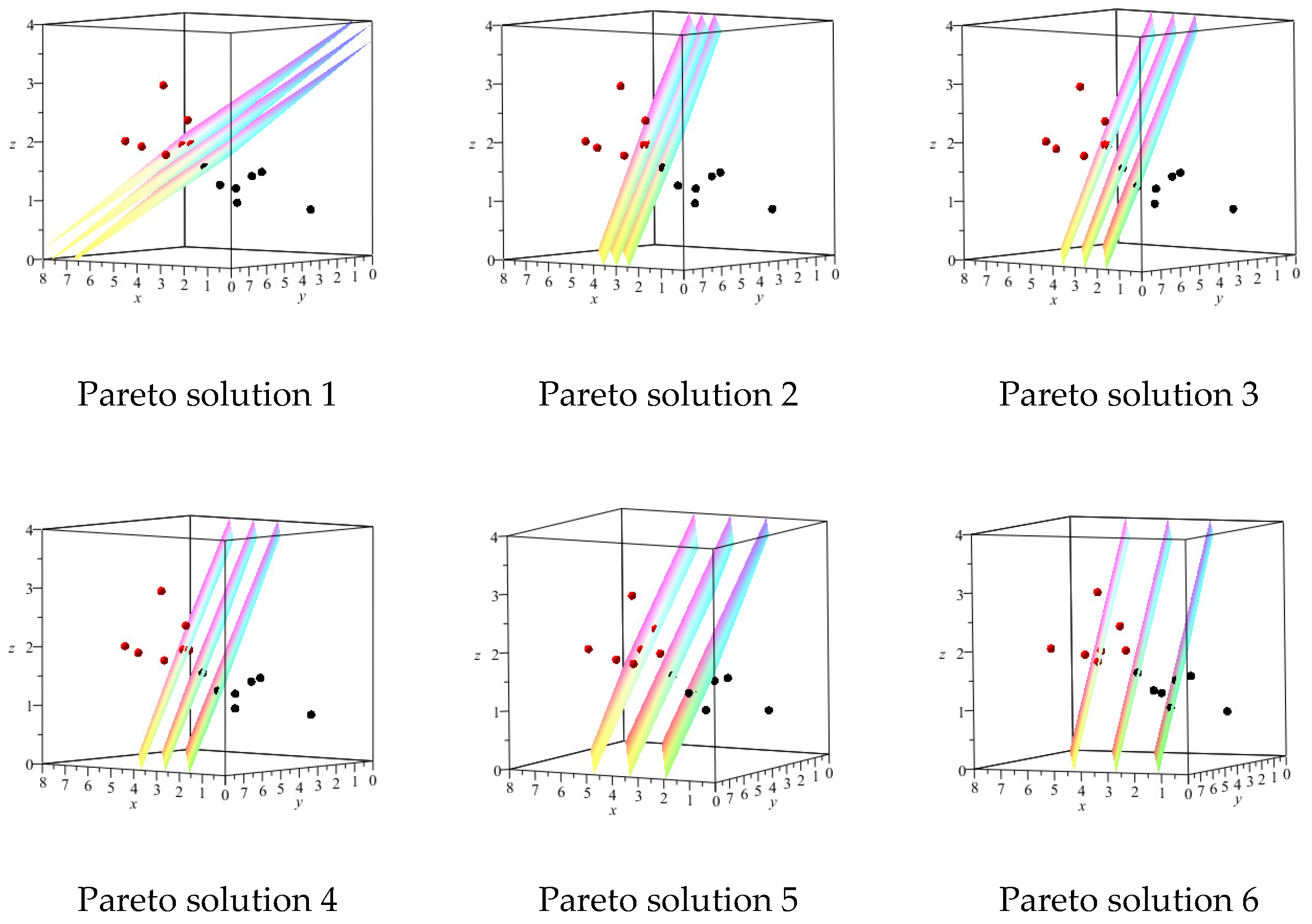
We used the dataset for our MOP models to obtain 100 Pareto solutions. We have considered 6 Pareto solutions out of 100 Pareto solutions obtained for each MOP for further investigation. In
Figure 2,
Figure 3,
Figure 4 and
Figure 5, we have considered a suitable viewing angle for each specific sample (6 Pareto solutions) to have a better view of the separating hyperplanes for MOP models. Additionally, in
Table 2,
Table 3,
Table 4 and
Table 5, the results obtained for the same Pareto optimal solutions are displayed.
In
Table 2 for the
MOP, the value of
gradually decreases in the solutions while the error value increases.
For example, in the first and second Pareto solutions, a smaller value for the
(with an error value equal to zero) has been achieved compared to the results of the single-objective
, presented in
Table 1. In the sixth Pareto solution, one of the components of the vector
is equal to zero, but the error has increased.
In
Table 3 for the
MOP model, in the first and second Pareto solutions, a smaller value for the
has been achieved (with an error value equal to zero) compared to the results of the single-objective
problem, presented in
Table 1.
In
Table 4 for the BM-SVM MOP model, in the third Pareto solution, two components of the vector
are non-zero (with an error value equal to zero) while compared to the results of the single-objective model, presented in
Table 1, a smaller value for the
has been achieved.
For the SVM
0 MOP model, as shown in
Figure 5 and
Table 5, in the third Pareto solution, two components of the vector
are non-zero (with an error value equal to zero) while compared to the results of the single-objective model, presented in
Table 1, a smaller value for the
has been achieved.
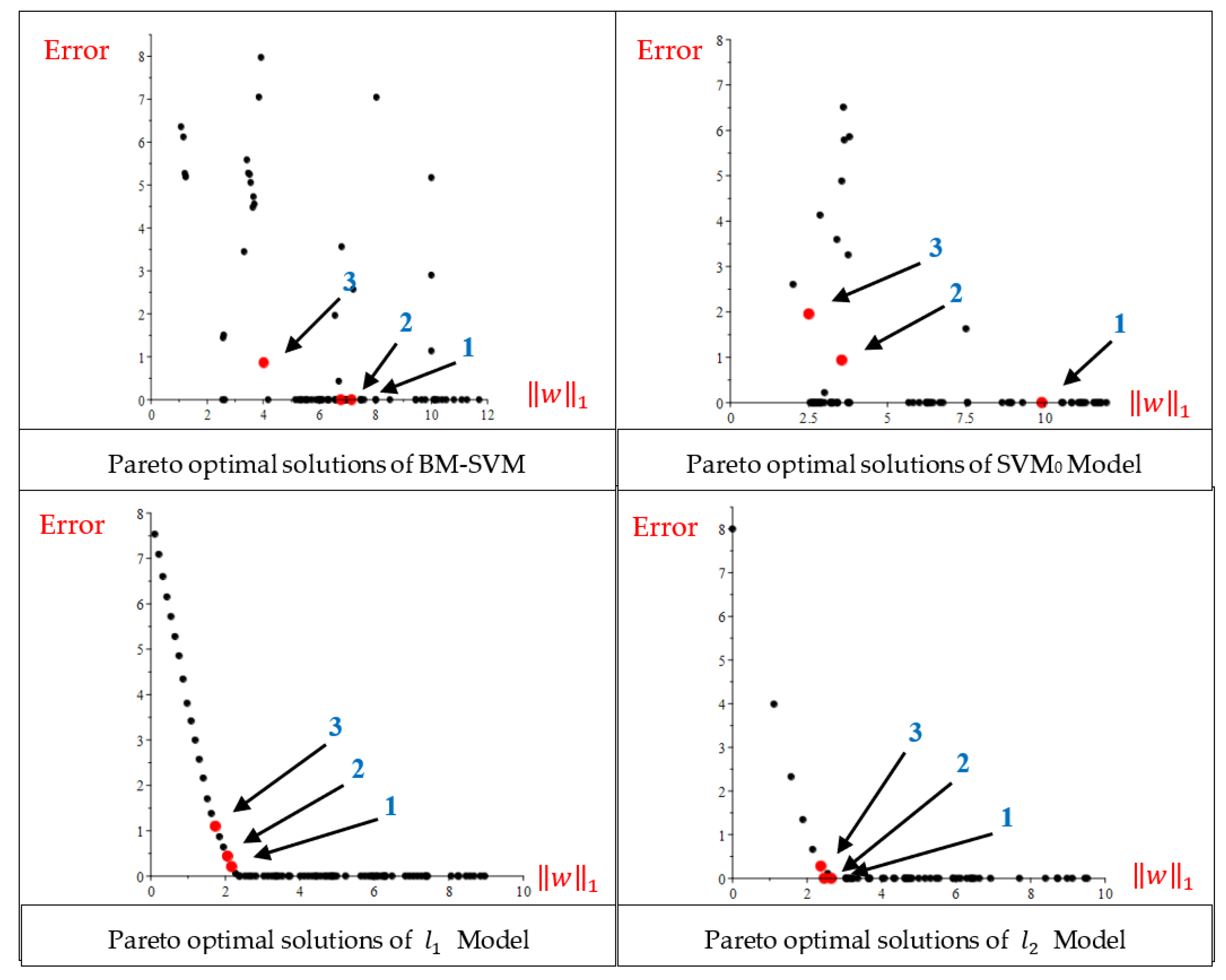
The projection of all Pareto solutions (in the space of Error (Vertical axis) and
norm (Horizontal axis)) obtained from multi-objective models (BM-SVM, SVM
0,
,
) are shown in
Figure 6. Additionally, the run time (second) of
,
, BM-SVM and SVM
0 multi-objective models, respectively, are 227.906, 269.468, 901.235, and 1236.515 for obtaining 100 Pareto optimal solutions. The lowest run time was related to model
, but as the results of the previous tables, models BM-SVM and SVM
0 have performed better in terms of the minimum number of non-zero components of the normal vector of the separator hyperplane.
Test Problem 2. The number of samples is 12, and the number of features is 4 in this test problem. Suppose that we have two sets as follows: The results are shown in
Table 6. The single-objective models all provide the correct set separator (that is, the error of all these models is zero). The vector
returned by BM-SVM and SVM
0 methods has just one non-zero component, but
and
return a vector
where all components are non-zero.
Pareto optimal solutions obtained from MOP models are depicted in
Figure 7. In this figure, the horizontal axis represents the value of
norm of vector
, and the vertical axis represents the error level. To clarify the discussion, in
Figure 8a, the Pareto frontier of the BM-SVM multi-objective model is displayed in the space of the objective functions of this model for Test Problem 2. In
Figure 8b the projection of this Pareto frontier in the space of Error (vertical axis) and
-norm (horizontal axis) is displayed.
We have considered only three Pareto solutions out of the 100 Pareto optimal solutions obtained for each MOP model that seemed more interesting for consideration. The results are displayed in
Table 7,
Table 8,
Table 9 and
Table 10.
For the BM-SVM MOP model, as shown in
Table 7, for all Pareto solutions that are considered, three components of vector
is equal to zero, and in each solution, the smaller value for
has been achieved, but the errors are not equal to zero.
As shown in
Table 8 for the SVM
0 MOP model, in the first Pareto solution, two components of vector
is equal to zero, and in the two other Pareto solutions, three components of vector
is equal to zero, but the error value is non-zero.
As shown in
Table 9, in the
MOP model, for all Pareto solutions, one component of the vector
is equal to zero but with non-zero error.
As shown in
Table 10 for the
MOP model, in all Pareto solutions which are considered, all components of the vector
are non-zero.
The run time (second) of , , BM-SVM and SVM0 multi-objective models, respectively, are 885.031, 418.578, 133.594, and 546.472 for obtaining 100 Pareto optimal solutions. The lowest run time was related to model BM-SVM. Additionally, as the results of the previous tables, models BM-SVM and SVM0 have performed better in terms of the minimum number of non-zero components of the normal vector of the separator hyperplane.
Test Problem 3. The number of samples is 8, and the number of features is 5 in this test problem. Suppose that we have two sets as follows: All single-objective models provide the correct separator. The vector
returned by BM-SVM and SVM
0 has just one non-zero component, but the
and
return a vector
where components are all non-zero. The results are depicted in
Table 11.
Pareto solutions obtained from MOP models are shown in
Figure 9. We have considered only three Pareto solutions that seemed more interesting out of the 100 Pareto optimal solutions obtained for each MOP model. The results are shown in
Table 12,
Table 13,
Table 14 and
Table 15.
For BM-SVM MOP, as shown in
Table 12, for the first and second Pareto solutions, four components of vector
are equal to zero, and the error values are zero. Additionally, compared to the results of the single-objective model, a smaller value for the
has been achieved.
For the SVM
0 MOP model, as shown in
Table 13, for the first Pareto solution, four components of vector
are equal to zero, and the error value is equal to zero, for the second and third Pareto solutions, while the error value is non-zero, four components of vector
are equal to zero.
For the
MOP model, as shown in
Table 14, one component of vector
is equal to zero, with a non-zero error.
For the MOP model, as shown in, for all Pareto solutions, all components of vector are non-zero.
The run time (second) of , , BM-SVM, and SVM0 multi-objective models, respectively, are 102.500, 134.188, 239.953, and 576.343 for obtaining 100 Pareto optimal solutions. The lowest run time was related to model. Additionally, as the results of the previous tables, models BM-SVM and SVM0 have performed better in terms of the minimum number of non-zero components of the normal vector of the separator hyperplane.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}