

An Inconvenient Truth about Forecast Combinations
Abstract
:1. Introduction
2. Econometric Environment
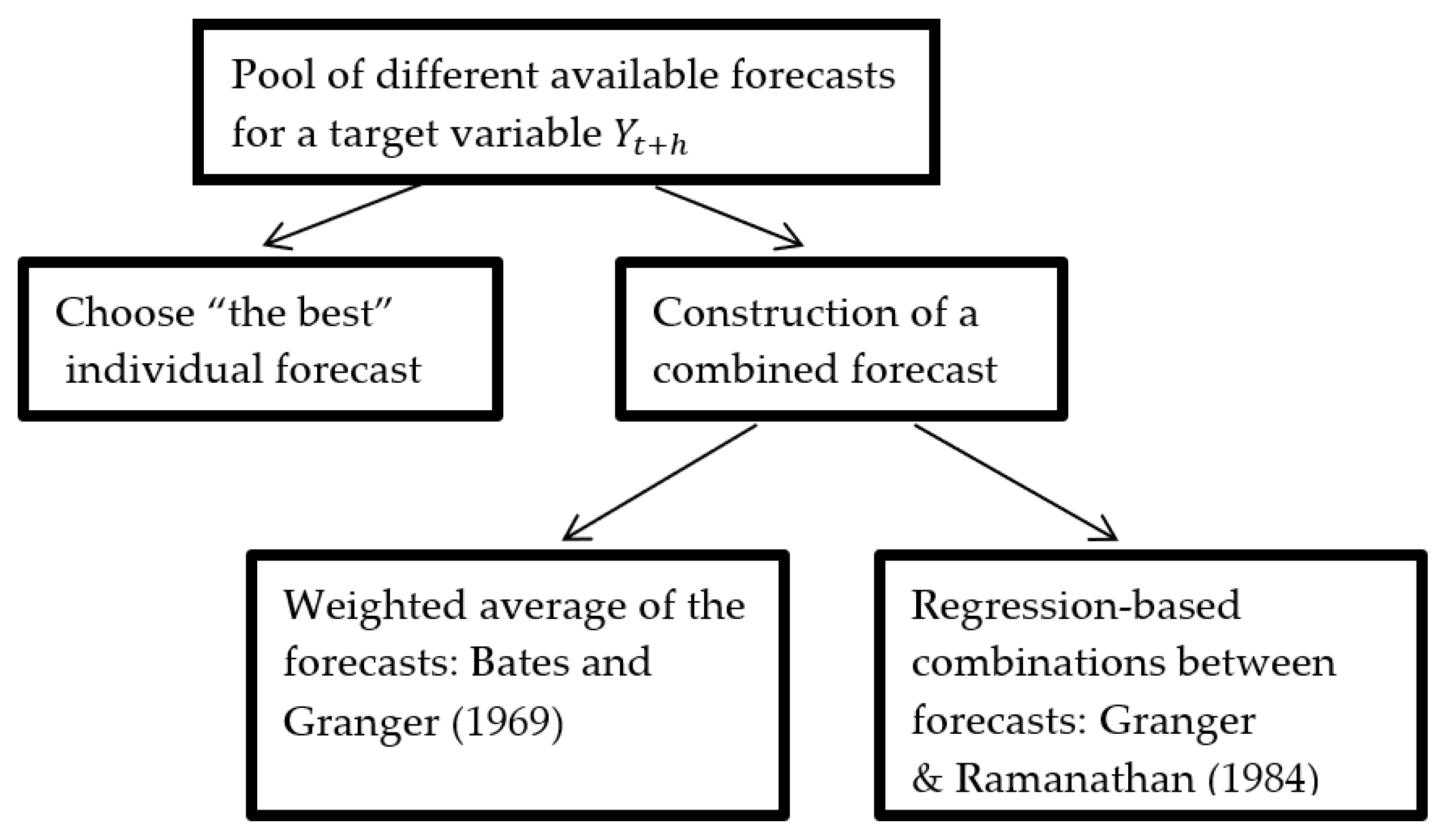
2.1. The Combined Forecast
2.2. Combination Gains
2.3. Auto-Efficiency
- (1)
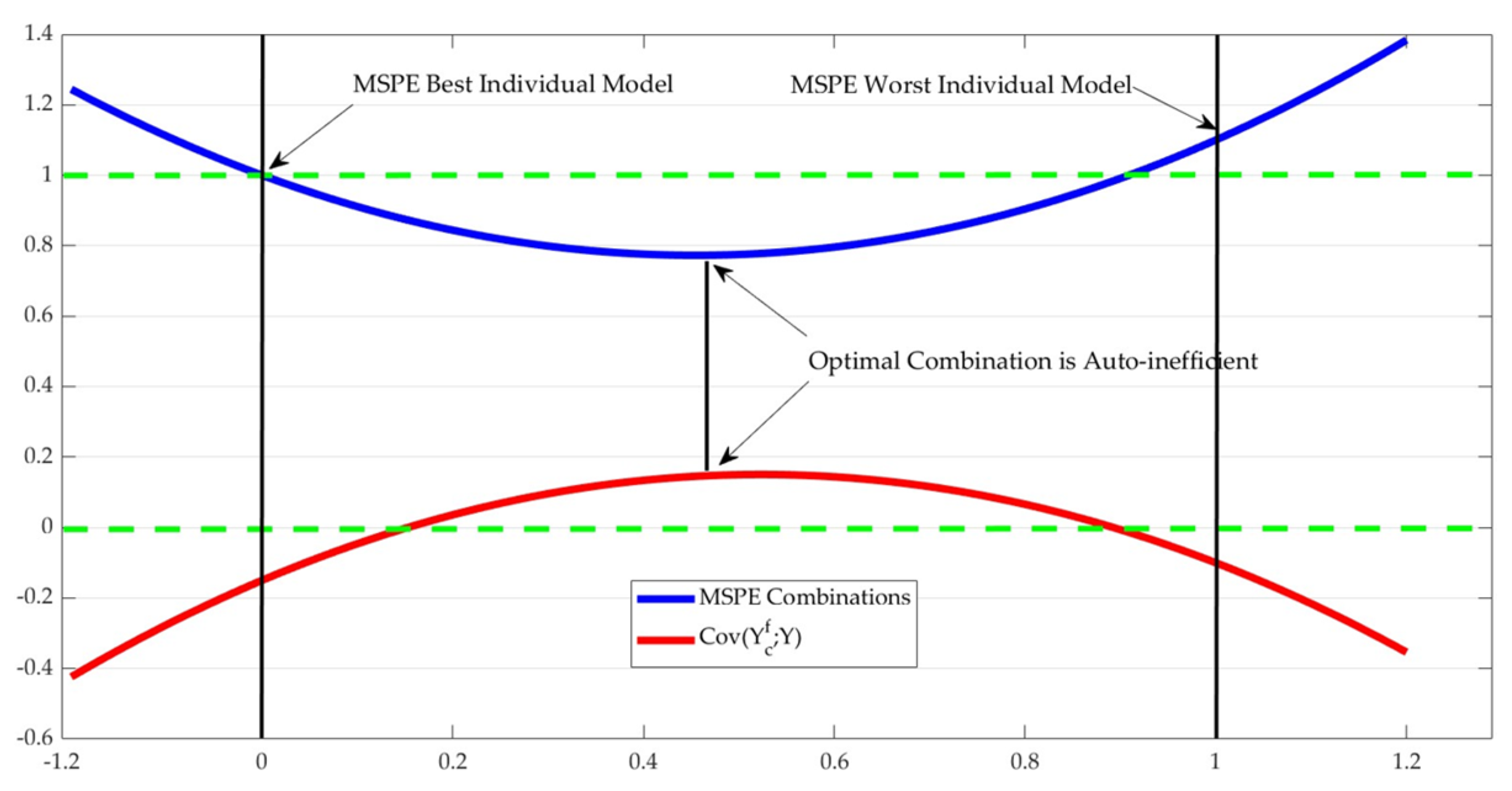
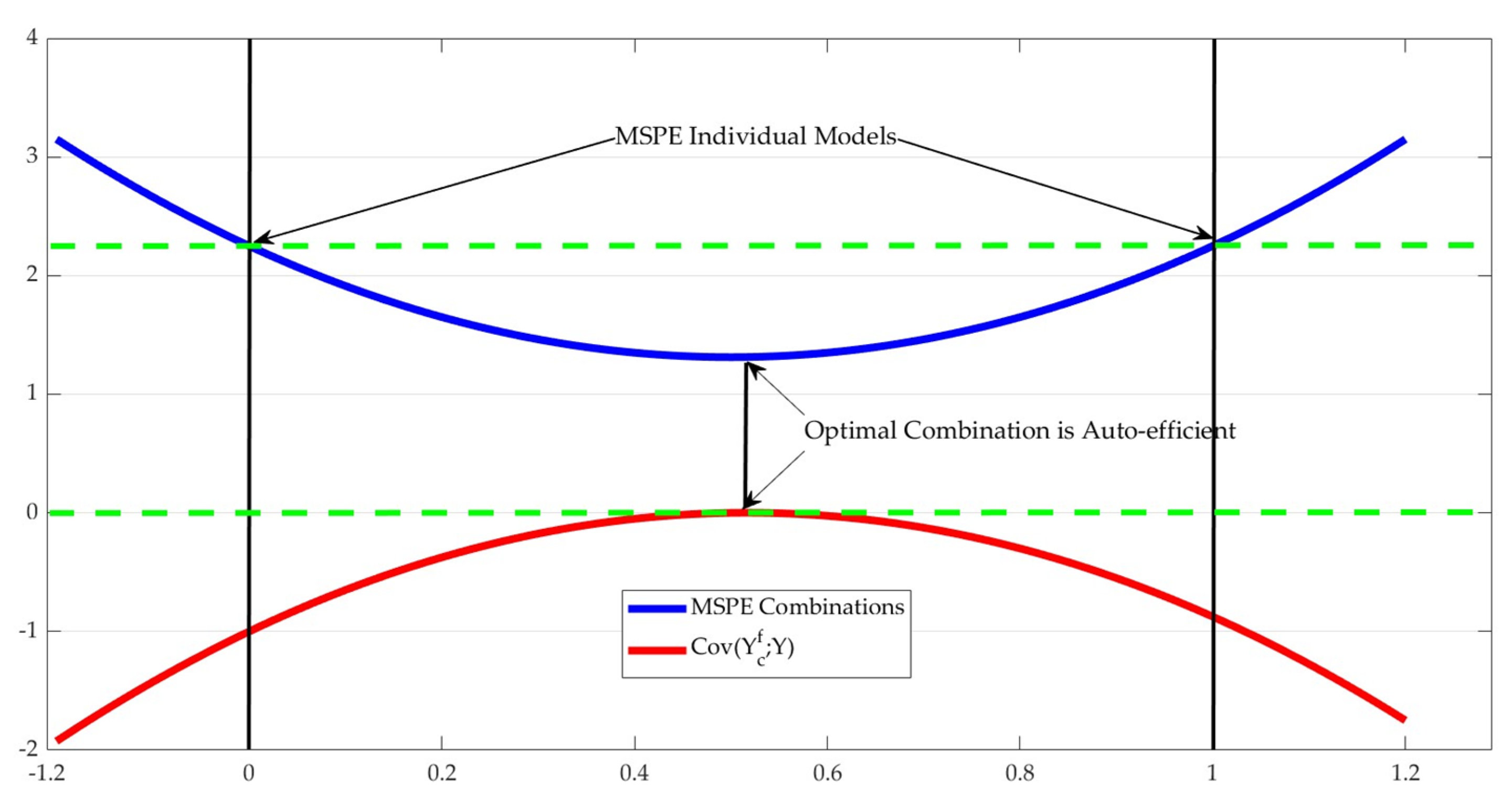
- When forecasts are unbiased, auto-inefficiency compromises the inverse relationship between the MSPE and the explained variance of the forecast.
- (2)
- Violations of auto-efficiency, in theory, allow for a simple modification of the forecast to produce a new revised forecast with fewer MSPE than .
2.4. Assumptions
- One target variable .
- Two forecasts and , such that
- Combination gains do exist in a region of the open set (0, 1). In other words,We also make use of the following assumption.
- The following vector
3. Main Theoretical Results
3.1. Auto-Inefficiency of Forecast Combinations
3.2. Size of the Auto-Inefficiency in the Forecast Combinations
3.3. Simulated Examples
4. Empirical Illustration
5. Summary and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Proof of Expressions (27) and (28) in Section 3
Appendix A.2. Empirical Illustration with an Extended Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Austria | Belgium | Canada | Colombia | Czech Republic | Denmark | Estonia | |
|---|---|---|---|---|---|---|---|
| λ* | 0.255 | 0.281 | 0.490 | 0.059 | 0.443 | 0.164 | 0.330 |
| MSPE (International) | 0.094 | 0.229 | 0.213 | 0.102 | 0.364 | 0.106 | 0.872 |
| MSPE (Core) | 0.111 | 0.276 | 0.214 | 0.271 | 0.408 | 0.139 | 0.934 |
| Ratio MSPEopt/MSPEint | 0.976 | 0.963 | 0.928 | 0.994 | 0.793 | 0.987 | 0.977 |
| MSPE Optimal Combination | 0.092 | 0.220 | 0.198 | 0.101 | 0.288 | 0.104 | 0.852 |
| Inefficiencies (Opt. Combination) | −0.145 ** | −0.633 *** | −0.134 | −0.384 *** | −0.476 * | −0.364 *** | −4.300 *** |
| Finland | France | Germany | Greece | Ireland | Israel | Korea | |
| λ* | 0.141 | 0.134 | 0.321 | 0.307 | 0.195 | 0.170 | 0.405 |
| MSPE (International) | 0.128 | 0.084 | 0.173 | 0.384 | 0.248 | 0.209 | 0.161 |
| MSPE (Core) | 0.172 | 0.204 | 0.200 | 0.533 | 0.519 | 0.725 | 0.172 |
| Ratio MSPEopt/MSPEint | 0.991 | 0.965 | 0.954 | 0.906 | 0.932 | 0.892 | 0.943 |
| MSPE Optimal Combination | 0.127 | 0.081 | 0.165 | 0.348 | 0.231 | 0.187 | 0.152 |
| Inefficiencies (Opt. Combination) | −0.293 *** | −0.157 *** | −0.164 ** | −1.286 *** | −0.931 *** | −0.246 ** | −0.102 |
| Latvia | Luxembourg | Mexico | Netherlands | Norway | Poland | Slovak Republic | |
| λ* | 0.062 | 0.368 | 0.075 | 0.086 | 0.236 | 0.221 | 0.193 |
| MSPE (International) | 0.517 | 0.257 | 0.138 | 0.312 | 0.275 | 0.233 | 0.205 |
| MSPE (Core) | 1.908 | 0.373 | 0.611 | 0.430 | 0.320 | 0.266 | 0.625 |
| Ratio MSPEopt/MSPEint | 0.988 | 0.768 | 0.977 | 0.997 | 0.983 | 0.988 | 0.876 |
| MSPE Optimal Combination | 0.511 | 0.197 | 0.135 | 0.311 | 0.270 | 0.230 | 0.180 |
| Inefficiencies (Opt. Combination) | −1.923 ** | −0.237 ** | −0.063 | −0.708 ** | −0.247 ** | −1.021 *** | -0.400 ** |
| Slovenia | Spain | Sweden | Switzerland | United Kingdom | United States | ||
| λ* | 0.210 | 0.210 | 0.085 | 0.069 | 0.310 | 0.318 | |
| MSPE (International) | 0.371 | 0.308 | 0.170 | 0.089 | 0.085 | 0.246 | |
| MSPE (Core) | 0.475 | 0.431 | 0.298 | 0.266 | 0.098 | 0.278 | |
| Ratio MSPEopt/MSPEint | 0.979 | 0.970 | 0.993 | 0.989 | 0.960 | 0.963 | |
| MSPE Optimal Combination | 0.363 | 0.299 | 0.169 | 0.088 | 0.081 | 0.237 | |
| Inefficiencies (Opt. Combination) | −0.703 *** | −0.601 *** | 0.004 | −0.150 *** | −0.338 *** | −0.292 ** | |
References
- Elliot, G.; Timmermann, A. Economic Forecasting. J. Econ. Lit. 2008, 46, 3–56. [Google Scholar] [CrossRef]
- Bates, J.; Granger, C. The combination of forecasts. Oper. Res. Q. 1969, 20, 451–468. [Google Scholar] [CrossRef]
- Granger, C.; Newbold, P. Some Comments on the Evaluation of Economic Forecasts. Appl. Econ. 1973, 5, 35–47. [Google Scholar] [CrossRef]
- Granger, C.; Newbold, P. Forecasting Economic Time Series, 2nd ed.; Academic Press: Orlando, FL, USA, 1986. [Google Scholar]
- Chong, Y.; Hendry, D. Econometric Evaluation of Linear Macroeconomic Models. Rev. Econ. Stud. 1986, 53, 671–690. [Google Scholar] [CrossRef]
- Clements, M.; Hendry, D. On the Limitations of Comparing Mean Square Forecast Errors. J. Forecast. 1993, 12, 617–637. [Google Scholar] [CrossRef]
- Newbold, P.; Granger, C. Experience With Forecasting Univariate Time Series and the Combination of Forecasts. J. R. Stat. Soc. Ser. A 1974, 137, 131–165. [Google Scholar] [CrossRef]
- Granger, C.; Ramanathan, R. Improved methods of combining forecasts. J. Forecast. 1984, 3, 197–204. [Google Scholar] [CrossRef]
- Clemen, R. Linear constraints and the efficiency of combined forecasts. J. Forecast. 1986, 5, 31–38. [Google Scholar] [CrossRef]
- Diebold, F. Serial correlation and the combination of forecasts. J. Bus. Econ. Stat. 1988, 6, 105–111. [Google Scholar]
- Batchelor, R.; Dua, P. Forecaster diversity and the benefits of combining forecasts. Manag. Sci. 1995, 41, 68–75. [Google Scholar] [CrossRef]
- Harvey, D.; Leybourne, S.; Newbold, P. Tests for Forecast Encompassing. J. Bus. Econ. Stat. 1998, 16, 54–259. [Google Scholar]
- Stock, J.; Watson, M. Combination forecasts of output growth in a seven-country data set. J. Forecast. 2004, 23, 405–430. [Google Scholar] [CrossRef]
- Aiolfi, M.; Timmermann, A. Persistence in Forecasting Performance and Conditional Combination Strategies. J. Econom. 2006, 135, 31–53. [Google Scholar] [CrossRef]
- Hansen, B. Least Squares Forecast Averaging. J. Econom. 2008, 146, 342–350. [Google Scholar] [CrossRef]
- Capistrán, C.; Timmermann, A. Forecast Combination with Entry and Exit of Experts. J. Bus. Econ. Stat. 2009, 27, 429–440. [Google Scholar] [CrossRef]
- Clements, M.; Harvey, D. Combining Probability Forecasts. Int. J. Forecast. 2011, 27, 208–223. [Google Scholar] [CrossRef]
- Poncela, P.; Rodriguez, J.; Sánchex-Mangas, R.; Senra, E. Forecast combinations through dimension reduction techniques. Int. J. Forecast. 2011, 27, 224–237. [Google Scholar] [CrossRef]
- Kolassa, S. Combining exponential smoothing forecasts using Akaike weights. Int. J. Forecast. 2011, 27, 238–251. [Google Scholar] [CrossRef]
- Costantini, M.; Kunst, R. Combining forecasts based on multiple encompassing tests in a macroeconomic core system. J. Forecast. 2011, 30, 579–596. [Google Scholar] [CrossRef]
- Cheng, X.; Hansen, B. Forecasting with factor-augmented regression: A frequentist model averaging approach. J. Econom. 2015, 186, 280–293. [Google Scholar] [CrossRef]
- Wang, X.; Hyndman, R.; Li, F.; Kang, Y. Forecast combinations: An over 50-year review. Int. J. Forecast. 2022, in press. [Google Scholar] [CrossRef]
- Wright, J. Bayesian Model Averaging and exchange rate forecasts. J. Econom. 2008, 146, 329–341. [Google Scholar] [CrossRef]
- Chowell, G.; Luo, R.; Sun, K.; Roosa, K.; Tariq, A.; Viboud, C. Real-time forecasting of epidemic trajectories using computational dynamic ensembles. Epidemics 2020, 30, 100379. [Google Scholar] [CrossRef]
- Atiya, A. Why does forecast combination work so well? Int. J. Forecast. 2020, 36, 197–200. [Google Scholar] [CrossRef]
- Timmermannn, A. Forecast Combinations. In Handbook of Economic Forecasting; Elliott, G., Granger, C., Timmermannn, A., Eds.; Elsevier: Amsterdam, The Netherlands, 2006; pp. 135–194. [Google Scholar]
- Aiolfi, M.; Capistrán, C.; Timmermann, A. Forecast Combinations. In The Oxford Handbook of Economic Forecasting; Clements, M., Hendry, D., Eds.; OUP: New York, NY, USA, 2011. [Google Scholar]
- Mincer, J.; Zarnowitz, V. The Evaluation of Economic Forecasts. In Economic Forecasts and Expectations; Mincer, J., Ed.; National Bureau of Economic Research: New York, NY, USA, 1969. [Google Scholar]
- Patton, A.; Timmermann, A. Forecast Rationality Tests Based on Multi-Horizon Bounds. J. Bus. Econ. Stat. 2012, 30, 1–17. [Google Scholar] [CrossRef]
- White, H. A Reality Check for Data Snooping. Econometrica 2000, 68, 1097–1126. [Google Scholar] [CrossRef]
- Pincheira, P. Shrinkage Based Tests of Predictability. J. Forecast. 2013, 32, 307–332. [Google Scholar]
- Pincheira, P.; Hardy, N. Correlation Based Tests of Predictability; MPRA Paper 112014; University Library of Munich: München, Germany, 2022. [Google Scholar]
- Bermingham, C. How useful is core inflation for forecasting Headline inflation? Econ. Soc. Rev. 2007, 38, 355–377. [Google Scholar]
- Song, L. Do underlying measures of inflation outperform headline rates? Evidence from Australian data. Appl. Econ. 2005, 37, 339–345. [Google Scholar] [CrossRef]
- Pincheira, P.; Selaive, J.; Nolazco, J.L. Forecasting inflation in Latin America with core measures. Int. J. Forecast. 2019, 35, 1060–1071. [Google Scholar] [CrossRef]
- Ciccarelli, M.; Mojon, B. Global Inflation. Rev. Econ. Stat. 2010, 92, 524–535. [Google Scholar] [CrossRef]
- Pincheira, P. A power booster factor for out-of-sample tests of predictability. Economía 2022, 45, 150–183. [Google Scholar] [CrossRef]
- Medel, C.; Pedersen, M.; Pincheira, P. The Elusive Predictive Ability of Global Inflation. Int. Financ. 2016, 19, 120–146. [Google Scholar] [CrossRef]
- Hamilton, J.D. Why you should never use the Hodrick-Prescott filter. Rev. Econ. Stat. 2018, 100, 831–843. [Google Scholar] [CrossRef]
- Dritsaki, M.; Dritsaki, C. Comparison of HP Filter and the Hamilton’s Regression. Mathematics 2022, 10, 1237. [Google Scholar] [CrossRef]
- Jönsson, K. Cyclical dynamics and trend/cycle definitions: Comparing the HP and Hamilton filters. J. Bus. Cycle Res. 2020, 16, 151–162. [Google Scholar] [CrossRef]
- Jönsson, K. Real-time US GDP gap properties using Hamilton’s regression-based filter. Empir. Econ. 2020, 59, 307–314. [Google Scholar] [CrossRef]
- Ravn, M.O.; Uhlig, H. On adjusting the Hodrick-Prescott filter for the frequency of observations. Rev. Econ. Stat. 2002, 84, 371–376. [Google Scholar] [CrossRef]
- Niu, Z.; Wang, C.; Zhang, H. Forecasting stock market volatility with various geopolitical risks categories: New evidence from machine learning models. Int. Rev. Financ. Anal. 2023, 89, 102738. [Google Scholar] [CrossRef]
- Lv, W.; Qi, J. Stock market return predictability: A combination forecast perspective. Int. Rev. Financ. Anal. 2022, 84, 102376. [Google Scholar] [CrossRef]
- Safari, A.; Davallou, M. Oil price forecasting using a hybrid model. Energy 2018, 148, 49–58. [Google Scholar] [CrossRef]
- Capek, J.; Cuaresma, J.C.; Hauzemberger, N. Macroeconomic forecasting in the euro area using predictive combinations of DSGE models. Int. J. Forecast. 2022, in press. [Google Scholar] [CrossRef]



| Austria | Belgium | Czech Republic | Denmark | Estonia | Germany | Greece | United Kingdom | |
|---|---|---|---|---|---|---|---|---|
| λ* | 0.255 | 0.281 | 0.443 | 0.164 | 0.330 | 0.321 | 0.307 | 0.310 |
| MSPE (International) | 0.094 | 0.229 | 0.364 | 0.106 | 0.872 | 0.173 | 0.384 | 0.085 |
| MSPE (Core) | 0.111 | 0.276 | 0.408 | 0.139 | 0.934 | 0.200 | 0.533 | 0.098 |
| MSPE Optimal Combination | 0.092 | 0.220 | 0.288 | 0.104 | 0.852 | 0.165 | 0.348 | 0.081 |
| Ratio MSPEopt/MSPEint | 0.976 | 0.963 | 0.793 | 0.987 | 0.977 | 0.954 | 0.906 | 0.960 |
| Inefficiency (Optimal Combination) | −0.145 ** | −0.633 *** | −0.476 * | −0.364 *** | −4.300 *** | −0.164 ** | −1.286 *** | −0.338 *** |
| Austria | Belgium | Czech Republic | Denmark | Estonia | Germany | Greece | United Kingdom | |
|---|---|---|---|---|---|---|---|---|
| λ* | 0.199 | 0.977 | 0.673 | 0.146 | 0.726 | 0.648 | 0.642 | 0.241 |
| MSPE (International) | 0.094 | 0.229 | 0.364 | 0.106 | 0.872 | 0.173 | 0.384 | 0.085 |
| MSPE (Output Gap) | 0.114 | 0.205 | 0.353 | 0.109 | 0.790 | 0.163 | 0.363 | 0.098 |
| MSPE Optimal Combination | 0.093 | 0.205 | 0.350 | 0.105 | 0.777 | 0.159 | 0.353 | 0.083 |
| Ratio MSPEopt/MSPE (Best Model) | 0.986 | 1.000 | 0.990 | 0.999 | 0.983 | 0.974 | 0.973 | 0.983 |
| Inefficiencies (Opt. Combination) | −0.160 ** | −0.441 *** | −1.815 *** | −0.366 *** | −2.893 ** | −0.059 | −1.193 ** | −0.349 *** |
| Austria | Belgium | Czech Republic | Denmark | Estonia | Germany | Greece | United Kingdom | |
|---|---|---|---|---|---|---|---|---|
| λ* | 0.139 | 0.752 | 0.621 | 0.130 | 0.853 | 0.643 | 0.585 | 0.093 |
| MSPE (International) | 0.094 | 0.229 | 0.364 | 0.106 | 0.872 | 0.173 | 0.384 | 0.085 |
| MSPE (Output Gap) | 0.118 | 0.214 | 0.355 | 0.111 | 0.769 | 0.163 | 0.371 | 0.109 |
| MSPE Optimal Combination | 0.093 | 0.213 | 0.350 | 0.105 | 0.766 | 0.159 | 0.356 | 0.084 |
| Ratio MSPEopt/MSPE (Best Model) | 0.993 | 0.992 | 0.986 | 0.999 | 0.996 | 0.973 | 0.962 | 0.997 |
| Inefficiencies (Opt. Combination) | −0.158 ** | −0.551 *** | −1.849 *** | −0.366 *** | −3.001 ** | −0.075 | −1.249 ** | −0.375 *** |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pincheira-Brown, P.; Bentancor, A.; Hardy, N. An Inconvenient Truth about Forecast Combinations. Mathematics 2023, 11, 3806. https://doi.org/10.3390/math11183806
Pincheira-Brown P, Bentancor A, Hardy N. An Inconvenient Truth about Forecast Combinations. Mathematics. 2023; 11(18):3806. https://doi.org/10.3390/math11183806
Chicago/Turabian StylePincheira-Brown, Pablo, Andrea Bentancor, and Nicolás Hardy. 2023. "An Inconvenient Truth about Forecast Combinations" Mathematics 11, no. 18: 3806. https://doi.org/10.3390/math11183806