1. Introduction
Lightweighting 3D deep neural networks is a popular method and an important research topic for deploying large 3D models on edge devices, particularly in the field of video recognition [
1]. Most action recognition models based on deep neural networks are obtained by extending two-dimensional image classification networks to include a time dimension and replacing 2D convolution with 3D convolution, such as [
2,
3]. Though these models effectively capture spatiotemporal features, the increase in the number of parameters results in a significant increase in computational requirements. To reduce the computational burden of directly using 3D convolution, R(2+1)D [
4] decomposes 3D convolution into 2D spatial convolution and 1D temporal convolution. Although this approach reduces the number of parameters by half, the amount of computation does not decrease, but instead increases. The SlowFast model [
5] extracts spatiotemporal features through dual-branch fast and slow channels, achieving remarkable results while reducing both the model size and computational requirements through its architecture.
However, this approach still relies on 3D convolution to directly extract features, which requires high computational performance during deployment. One method to accelerate 3D ConvNets is by pruning redundant convolutional filters while preserving the discriminative power of the networks [
6]. However, the effectiveness of this lightweighting approach is limited. Directly expanding classic lightweight networks to three dimensions through dilation can significantly reduce the number of parameters and computational cost, but at the expense of a significant loss in accuracy. In recent years, there has been a trend towards building models by combining ViTs with convolution. This hybrid approach allows the model to benefit from the inductive bias unique to convolution that ViTs lack, while also leveraging the global perception capabilities of ViTs. However, compared to classic lightweight networks, MobileViT is still somewhat bloated.
Inspired by [
7], we aim to improve the ability to deploy 3D convolution-based action recognition models on edge devices by combining advanced lightweight models with 3D convolutions. We classify different lightweight methods according to their principles, including (1) the network model based on 3D depthwise separable convolution, (2) the network model based on 3D dilated convolution, and (3) the hybrid model based on the combination of 3DCNNs and ViTs (Vision Transform). We conducted a comparative analysis of the advantages and disadvantages of these lightweight 3D convolution methods and evaluated their ability to capture first-person and third-person perspectives on EgoGesture and Jester datasets, as well as their ability to capture actions related to background information on the UCF-101 dataset. Through a large number of comparative experiments, we compare the performance of various lightweight models from multiple perspectives.
Finally, we proposed the 3D-ShuffleViT, a high-performance hybrid model that combines 3DCNN with ViTs, to balance the number of parameters and accuracy. To further integrate convolution and self-attention mechanisms, we introduced the lightweight ACISA module, which significantly improves the accuracy of the model while maintaining its overall lightness. Our overall goal is to achieve a good balance between speed and accuracy in action recognition tasks so that it can be easily deployed on edge devices. The research presented in this paper provides a valuable reference for improving the deployment of online action recognition models under edge devices.
2. Related Work
The field of video action recognition has seen slower development compared to image recognition. Many video action recognition networks, such as I3D and C3D, are based on 3D convolutional networks derived from image classification models. These networks replace 2D convolution kernels with 3D convolution kernels and 2D pooling with 3D pooling, and are trained on large-scale datasets. Experimental results have shown that 3D convolution is more effective than 2D convolution for recognizing action sequences [
8], but it results in a high computational cost due to the added dimension. For example, a 3D-ResNet network model extended in the time dimension requires 27 times more floating-point calculations than an image ResNet [
1]. The Transformer model [
9] has demonstrated that its self-attention mechanism can effectively extract long-time sequence features, which is crucial for tasks involving time-series information such as action recognition. Although Transformer-based models [
10] have greatly improved accuracy, they require larger datasets to achieve comparable performance to 3D convolutional networks. The AIM model [
11] proposes a novel method to adapt pre-trained image models for efficient video understanding by freezing the pre-trained image model and adding lightweight adapters for spatial, temporal, and joint adaptation, gradually equipping the image model with spatiotemporal reasoning capabilities. However, the Transformers have a larger number of parameters and floating-point calculations compared to 3D convolutional networks, making it less suitable for real-time tasks or deployment on edge devices.
To reduce the large number of parameters and computational cost associated with the Transformer, some research has focused on reducing computational pressure through the design of the self-attention calculation structure. For example, ISA [
12] employs an interlaced sparse self-attention method to effectively capture dense long-range dependencies while reducing the consumption of computational resources. The attention design in Shuffle Transformer [
13] and MaxViT [
14] is generally consistent with ISA. Both methods achieve the goal of obtaining a global receptive field by alternately using attention that operates on local windows and attention that operates on equidistant position pixels.
In recent years, several lightweight action recognition networks have been proposed, including SlowFast [
1,
5]. SlowFast simulates the human brain’s process of recognizing motion information and extracts temporal and spatial information from video through fast and slow channels, respectively. X3D achieves an ultra-lightweight video recognition model through a grid search approach. However, both models still require high computational power, making it challenging to deploy them on edge devices. The TSM model [
15] facilitates interaction between adjacent frames by introducing a temporal displacement module. Notably, 3D convolution can effectively extract spatiotemporal features. Models such as P3D [
16] and R(2+1)D break down 3D convolution to reduce the number of parameters in the model. Other approaches, such as those proposed in [
17,
18], use 2D skeletal data for action recognition and judgment. Though Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) can effectively model long sequences over time, they do not benefit from spatial information. Approaches such as those proposed in [
19,
20] use RGB-D depth information to improve accuracy, but this requires devices capable of detecting depth information, limiting their applicability in most scenarios. This paper focuses solely on analyzing and comparing action recognition models that utilize only RGB video image frames as input.
Lightweight networks can be obtained either by compressing a trained model or by directly training a lightweight network. The MobileNet series [
21,
22,
23], a classic example of lightweight networks, has been widely used in industry since its inception. Its depthwise separable convolution has been shown to greatly reduce the number of parameters and floating-point operations. The Inception series [
24,
25] extracts features in parallel using multi-scale convolution kernels. The ShuffleNet series [
26,
27] reduces the number of parameters through grouped convolution and fuses channel information through channel rearrangement. As the number of channels increases while maintaining the same computational power, the smaller the network becomes, and the more pronounced the effect of channel rearrangement. Both depthwise separable convolution and grouped convolution reduce the number of parameters and floating-point operations in the network model, and cross-channel information on the input data is fused to reduce the number of parameters without unduly affecting the model’s accuracy. In addition to spatial feature information, information across time channels is also essential for video data. Dilated convolutions [
28] can provide similar compression benefits as depthwise separable convolutions. Another lightweight network approach that has emerged in recent years is to combine Transformer with CNN, where CNN is used to compensate for Transformer’s lack of inductive bias and difficulty in training [
29].
By combining the concept of a lightweight network with 3D convolution, a natural approach is to employ deep separable convolution, which has demonstrated excellent performance in lightweight networks, for 3D convolution. This results in a lightweight 3D deep separable convolution, which can significantly reduce the computational cost [
7]. Building on this approach, this paper further expands the lightweight 3D convolutional network proposed in [
7]. ACMix [
30] cleverly combines the self-attention mechanism with convolution. However, in practical use, we found that it consumes a lot of memory and its actual inference speed is not particularly efficient. When extending it to 3D, this phenomenon is particularly evident. The Unfold operation of its self-attention branch makes it difficult for the features to complete long-distance spatiotemporal modeling, and the 3D Unfold operation will consume a lot of runtime. To this end, we proposed the ACISA Block, which effectively solves the problems existing in ACMix. The contributions of this research are as follows:
(1) By converting 2D convolution kernels to 3D convolution kernels, 2D pooling operations to 3D pooling operations, and transforming more advanced lightweight networks into 3D structures, such as 3D-ESPNetV2, 3D-GHostNet, 3D-MobileVit, as well as our own proposed 3D-ShuffleViT inspired by MobileVit, we classify and compare improved advanced lightweight models based on their lightweight design principles.
(2) We proposed a 3D version of the ACMix module and, through further research, organically combined ACMix with the ISABlock to propose the ACISA module. This greatly reduced the computational cost of the module and improved its inference speed. Combining it with our proposed 3D-ShuffleViT significantly improved the accuracy of the model.
(3) We deployed our model on mobile devices to test and compare the real performance of various models on devices with limited computing power. Our proposed 3D-ShuffleViT achieved the best balance between accuracy and speed compared to lightweight networks of the same order.
3. Model Principle Analysis and Method
This section compares and analyzes the models based on the composition principle of the lightweight idea. The main tasks include: (1) further expanding the advanced lightweight 3D convolutional networks based on depthwise separable convolution methods, such as MobileNetV3, ShuffleNetV2+, GHostNet, etc. (2) The lightweight network model 3D-ESPNetV2 based on 3D grouped dilated convolution is analyzed. (3) We analyzed the 3D versions of hybrid models, such as 3D-MobileViT and the 3D-ShuffleViT network, which were inspired by and improved upon 3D-MobileViT. In
Section 3.4, we provide a detailed description of our proposed ACISA module, which deeply integrates self-attention with convolution.
3.1. 3D Depthwise Separable Convolutional Network Model
Depthwise separable convolution is still the most commonly used lightweight method in the industry, as it reduces the number of parameters and floating-point calculations required for training and inference. In the case of action recognition using 3D convolutions, the main difference from traditional 2D methods is the inclusion of a third temporal dimension. This requires performing depthwise convolution and pointwise convolution not only in the channel dimension, but also in the time dimension to achieve separable convolution. By first extracting features from each dimension of the video frame and then using pointwise convolution for information fusion in the channel dimension, 3D deep separable convolution can effectively extract spatiotemporal features with fewer parameters and floating-point operations. To better understand how 3D depthwise separable convolution achieves this reduction, it is helpful to analyze its numerical computation in more detail.
Comparison of computation amount between 3D depth-separable convolution structure and standard 3D convolution multiplication:
Suppose the input is , the size of the convolution kernel is , and the output is .
Standard 3D convolution multiplication calculation amount:
The multiplication calculation amount of one convolution is
, and each number of the output feature map is obtained by one convolution, so the standard 3D convolution multiplication calculation amount is shown in Equation (
1):
3D depthwise separable convolution multiplication computation: the multiplication calculation amount of the 3D DepthWise convolution part is shown in Equation (
2):
The multiplication calculation amount of the 3D PointWise convolution part is shown in Equation (
3):
Therefore, the multiplication calculation amount of the 3D depthwise separable convolution is shown in Equation (
4):
Comparing the multiplication calculation of 3D depthwise separable convolution with that of standard 3D convolution, the result is shown in Equation (
5):
is the number of channels input to the network, which is usually a large number when performing separable convolution. K is the size of the convolution kernel, usually 3 or 5, so using a 3D depthwise separable convolution structure can greatly reduce the amount of floating-point operations in the network.
Comparison of 3D depthwise separable convolution structure and standard 3D convolution parameters:
The parameter quantity of standard 3D convolution is as shown in Equation (
6):
The parameter quantity of the 3D DepthWise convolution part is shown in Equation (
7):
The parameters of the 3D PointWise convolution part are shown in Equation (
8):
Therefore, the parameter amount of the 3D depthwise separable convolution is shown in Equation (
9):
Comparing the multiplication calculation of the 3D depthwise separable convolution with that of the standard 3D convolution, the result is shown in Equation (
10):
is the number of output channels of the network, so the 3D depthwise separable convolution structure also greatly reduces the amount of parameters.
The parameter amount and floating-point calculation amount of the model using the 3D depthwise separable convolution are nearly of the standard convolution structure under the same framework. Therefore, based on the 3D depthwise separable convolution structure, the parameter amount and calculation amount of the model can be greatly reduced, thereby achieving a lightweight effect.
3.1.1. 3D-MobileNetV3
MobileNetV3 inherits the depthwise separable convolution structure of MobileNetV1, and inherits the inverse residual structure with the linear bottleneck of MobileNetV2. On this basis, it introduces the SE channel attention mechanism and uses HardSwish to replace the original ReLU activation function [
23], which further improves the accuracy. In terms of time-consuming structural design, MobileNetV3 reduces the number of convolutional layers of the first convolutional input from 32 to 16 in the v1 and v2 versions. This operation does not affect the accuracy and reduces the amount of calculation. In the v2 version, before the global average pooling, the number of channels is expanded from 320 to 1280 through a 1 × 1 convolution, so as to obtain higher-dimensional features, so that there are richer features during prediction, but, at the same time, the introduced additional computational cost and latency. In version v3, this 1 × 1 convolutional layer is placed after global average pooling, which is faster because it works on smaller feature maps and has almost no change in accuracy. The 3D-MobileNetV3 used in this paper is similar to the expansion operation of MobileNetV3 in [
31]. In order to retain as many temporal features as possible, the downsampling operation of the temporal dimension is not performed during the initial convolution operation.
3.1.2. 3D-GHostNet
The MobileNet and ShuffleNet series achieved good performance with less floating-point computation (for 2D image classification tasks), but the correlation and redundancy between feature maps were not well utilized. In the feature maps extracted by mainstream deep neural networks, rich and even redundant information usually ensures the model has a comprehensive understanding of the input data [
32]. GHostNet does not avoid redundant feature maps, but prefers to use a low cost and high efficiency to accept them in a cost-effective way. The Ghost module first generates a feature map without redundancy through ordinary convolution, and then generates a complete feature map through identity and cheap linear operations (depth separable convolution). Inspired by I3D and the expandable lightweight network [
7], we replaced the core Ghost module of GHostNet with a 3D structure to obtain the 3D-GHostNet network because the core of reducing the number of parameters and floating-point calculation in its 3D-Ghost module is still to use depth-separable convolution. Therefore, 3D-GHostNet is classified into the lightweight methods of 3D depth-separable convolution, and the 3D-Ghost module is shown in
Figure 1.
3.2. 3D Dilated Convolutional Network Model
By using grouped convolutions, the number of parameters and floating-point calculations required by the network can be reduced [
27]. When grouping reaches its extreme, where a separate convolution kernel is applied to each feature layer, grouped convolution evolves into depthwise separable convolution. The changes in the number of parameters and floating-point calculations are shown in Equations (5) and (10) in
Section 3.1. Although the effect of using depthwise separable convolution to reduce the weight of the model is not as good as using grouped convolution alone, it can still reduce the number of parameters and floating-point calculations required by the model. On the other hand, when using dilated convolution, the size and scale of the convolution kernel do not change, so the number of parameters remains unchanged. However, due to the presence of an expansion coefficient, the same feature layer convolution operation can be completed with less computation. This section focuses on the grouped dilated convolutional network 3D-ESPNetV2.
The ESPNet series, including ESPNetV2 [
28] and ESPNet [
33], is another lightweight network method that differs from depthwise separable convolution. By using grouped dilated convolution, ESPNet can achieve a larger receptive field with less consumption. ESPNetV2 decomposes standard convolution into pointwise convolution and a dilated convolution pyramid through its EESP module, which is expanded into 3-dimensional grouped dilated convolution. The structure is shown in
Figure 2. The pointwise 1 × 1 × 1 convolution maps the input to a low-dimensional feature space, and the dilated convolution pyramid uses K groups of n × n × n dilated convolutions to simultaneously sample low-dimensional features. The dilated convolutions have different expansion rates, resulting in different receptive fields. The feature pyramids extracted through different receptive fields are then fused, effectively compensating for the information loss caused by the dilation rate of dilated convolution.
Based on 3D-ESPNet [
34], the improved 3D-ESPNetV2 presented in this paper modifies the final model output according to different task types and replaces the 3D-ESP structure in 3D-ESPNet with the 3D-EESP structure. The overall network structure uses the structure design of ESPNetV2 to obtain the 3D-ESPNetV2 network model used in this paper. By using grouped atrous convolution, the model can capture the same receptive field with less floating-point computation, reduce the number of parameters through grouping, and more effectively extract temporal features through multi-scale feature fusion. As a result, it is more cost-effective than 3D depthwise separable convolutions.
3.3. 3D Convolution and ViTs Hybrid Model
ViTs learn the relationships between patches by encoding global information. However, this causes the model to lose its image-specific inductive bias and requires more parameters to learn visual representations. As a result, ViTs-based models are generally deep and wide. By incorporating CNNs to compensate for the inductive bias lost by ViTs and exploiting the global processing power of ViTs, it is possible to design shallow and narrow structures, making the overall model more lightweight.
MobileViT [
29] combines the advantages of CNNs and ViTs to build a lightweight network for mobile devices. The inductive bias of CNNs complements the shortcomings of ViTs, allowing the model to be improved into an action recognition network structure.
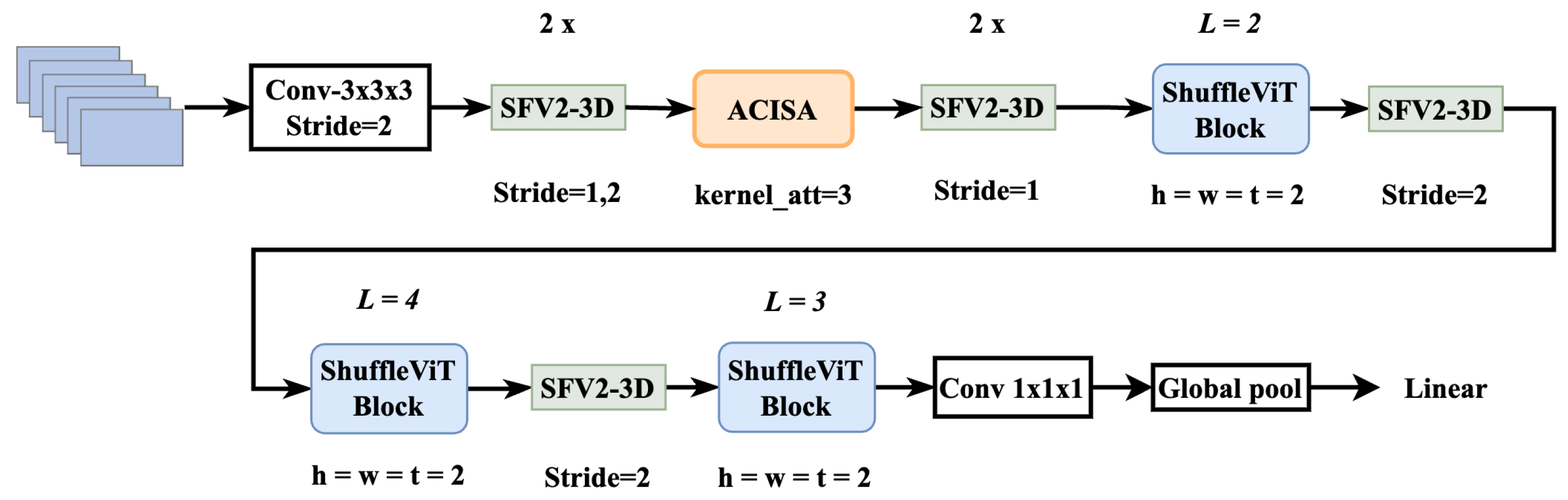
Inspired by MobileViT, we try to replace the MV2Block in MobileViT with the basic module and downsampling module of ShuffleNetV2 to obtain the ShuffleViT network. In order to adapt to the action recognition task, the structure is expanded into 3D structure, which is the same as the operation method in
Section 3.1.1, that is, it is only necessary to replace the MV3Block3D with SFV2Block3D. The specific 3D-ShuffleViT network structure is shown in
Figure 3. The ShuffleViT module and the MobileViT module are generally similar in that they aggregate features from equally spaced pixel positions into the same group and then perform self-attention operations within the group. Local information modeling is achieved through continuous SFV2Block3D modules, and the two are alternately mixed to perform local and global temporal modeling. The main difference from MobileViT’s self-attention calculation method is that not only are patches split in the H and W dimensions, but also in the T dimension, allowing it to obtain temporal information and model temporal sequences. As can be seen from the analysis of 3D depthwise separable convolution in
Section 3.1, using separable convolution can greatly reduce the number of parameters and computational complexity. Therefore, the 3D convolution in our hybrid structure adopts the SFV2Block3D module. As can be seen from subsequent experiments, by combining SFV2Block3D and ShuffleViT Block, the problem of slow inference speed caused by the large amount of memory access in practical use of MobileViT is avoided and the number of model parameters and calculations are reduced. Our improved model is more lightweight compared to 3D-MobileViT.
3.4. ACISA Module
We expanded ACMix to 3D through dilation, that is, not only performing convolution on the H and W dimensions, but also continuing convolution on the T dimension, making it suitable for three-dimensional data tasks. In order to solve the problem of large memory consumption and low inference speed of 3D ACMix and the inability of the Unfold operation of its attention branch to perform long-distance spatiotemporal modeling, we further combined ACMix with the ISABlock idea. By deeply integrating convolution and self-attention mechanisms, we were able to compensate for the shortcomings of using only convolution or only self-attention mechanisms. As shown in
Figure 4, it is worth noting that we did not use the Unfold operation in the self-attention branch of ACMix. When we expanded ACMix to 3D convolution, we found that it occupied a large amount of memory and computational consumption on the GPU or CPU. Therefore, after obtaining Q, K, and V through the 1 × 1 × 1 convolution operation, we used the staggered sparse self-attention method to reduce the amount of computation. By sparsely connecting tokens, we first grouped the tokens and interacted between groups, and then interacted within groups to indirectly achieve the effect of a global self-attention mechanism interaction. We named our proposed module that deeply integrates convolution and attention mechanisms as ACISA. In the attention calculation branch, we use the 3D version of positional encoding to provide position information for each position of the feature map. We conducted ablation experiments on whether to use 3D positional encoding. In subsequent experiments, it can be found that using ACISA with 3D positional encoding significantly improves performance.
The attention calculation in our ACISA module is illustrated in
Figure 5. Firstly, we employ the permute method to systematically shuffle the 3D feature map. Then, we divide it into blocks and perform self-attention operations to capture long-range information. Subsequently, we carry out another permute operation and self-attention to capture short-range information. By continuously decomposing short-range and long-range information, we can indirectly achieve global information interaction. In contrast to ISA [
12], our attention calculation branch’s initial features are provided by the ACISA module’s 1 × 1 × 1 convolution mapping into Q, K, and V. This means that during the first attention calculation, each patch is provided by Q, K, and V instead of coming from the same feature. The initial 1 × 1 × 1 mapping layer shares weights with the convolution branch, reducing a linear mapping and, thus, appropriately lowering the number of parameters and computational cost.
Through the above operations, we have deeply integrated the self-attention mechanism with convolutional operations, improving the overall efficiency of the module and reducing memory usage. By combining our extended 3D-ShuffleViT model with the above module, we have achieved significant accuracy improvements on the UCF101, Jester, and EgoGesture video action recognition datasets while using fewer computational and parameter resources.
Compared to our 3D-ACMix module obtained through dilation, our model uses an additional 1 × 1 × 1 convolution to decompose the long-range self-attention mechanism into Query, Key, and Value during short-range self-attention calculation. As shown in
Figure 6, the number of parameters in our proposed module is slightly higher than that of the 3D-ACMix module. However, thanks to the optimization of the attention branch, the overall floating-point computation of our proposed module is less than that of the latter. In a test on a CPU with an input tensor of dimensions (1, 3, 16, 56, 56) passing through our proposed module and the 3D-ACMix module, our speed was about one-tenth that of the latter. Therefore, overall, our method is more efficient.
4. Comparative Analysis of Model Experiments
4.1. Dataset Selection and Experimental Details
This paper selects the EgoGesture dataset [
35], Jester dataset [
36], and UCF-101 dataset [
37] for experiments.
The EgoGesture dataset is a large-scale gesture recognition dataset for egocentric interactions with wearable devices. It contains first-person gesture actions recorded from a VR perspective, with 83 static and dynamic gestures collected from six different indoor and outdoor scenes. The dataset contains a total of 24,161 gesture samples and 2,953,224 frames. The Jester dataset, on the other hand, focuses on gesture recognition in static scenes, with people performing pre-defined gestures in front of a laptop camera or webcam. Its action categories are less related to background information and the dataset contains more than 140,000 videos with 27 types of actions. The UCF-101 dataset is a classic action recognition dataset with 101 action categories, including 13,320 videos with a large diversity in actions. Each video clip is about 10 s long and the action categories are mainly divided into five types: human–object interaction, human body movements only, human–human interaction, playing musical instruments, and sports. The UCF-101 dataset also contains actions that can only be recognized by combining scene information.
Compared to the UCF-101 dataset, the EgoGesture and Jester datasets focus more on extracting features from gesture actions themselves, without relying on environmental information. As a result, the EgoGesture and Jester datasets can be used to evaluate a model’s ability to capture motion, whereas the UCF-101 dataset can be used to evaluate a model’s ability to capture actions that are related to background information.
A low resolution can affect the accuracy of a model. To compare the performance of different models, this paper uses a default resolution of 224 × 224 for all networks being compared and randomly crops 16 frames as input to the network. The initial learning rate is set to 0.1 and is decayed to 0.1 of its original value at rounds 40, 55, 65, 70, 80, and 90. The network is trained using SGD with standard classification cross-entropy loss, with a weight decay coefficient of , a momentum coefficient of 0.9, and a damping coefficient of 0.9. During training, all models are trained from scratch without using any pre-trained models to compare their ability to capture spatio-temporal actions from scratch. A total of 120 epochs are trained. The network is implemented in PyTorch and trained on a single RTX 3090 card.
4.2. Selection of Evaluation Criteria
4.2.1. Floating-Point Calculations and Parameters of the Model
The number of floating-point calculations and parameters are used to measure the time and space complexity of a model, respectively. The number of floating-point calculations can affect the inference speed of the model. If this number is too high, it can result in longer training and prediction times. On the other hand, if the number of parameters is too high, the model will occupy a large amount of disk space and result in a large exported APK (Android application package). Microsoft’s NNI open source toolkit can be used to calculate and compare the number of floating-point calculations and parameters for models with the same input and output.
4.2.2. Accuracy
The core of action recognition is the multi-classification task, so this paper mainly evaluates the model from the classification accuracy.
4.2.3. Memory Access and Speed
The number of parameters and floating-point calculations in a model are not the only factors that determine its inference speed. The inference speed is also affected by the model’s memory access requirements, which refers to the model’s demand for hardware memory bandwidth. This can have a significant impact on the final inference speed, as memory access can sometimes exceed the time required for calculation. Therefore, it is important to compare the memory access requirements of different models when evaluating their performance. However, other papers on lightweight models often overlook this aspect of model performance.
This paper focuses on research into lightweight action recognition. As such, it is important to test and compare the inference speed performance of each model in the same real-world testing environment, such as the frame rate achieved when performing inference on the same GPU or CPU. To measure the actual inference speed of the model, we first test the frame rate that can be achieved by the model on a desktop GPU (GTX1050Ti) and CPU (Intel i5-8300H 2.3 GHz). We then deploy the model to an Android mobile device (XiaoMi10 with a Qualcomm Snapdragon 865 CPU). To ensure the reliability of the inference data, we close all other irrelevant software during testing and perform 1000 inferences to obtain relatively reliable inference speed data.
4.3. Experimental Results
In order to compare the pros and cons of the above models fairly and comprehensively, we control the input of the above models in the Jester dataset to be
, and the inputs in the EgoGesture and UCF-101 datasets are both
. The image width of
is not used here because a resolution that is too small will affect the accuracy of the model [
20], and the original video frame size in the Jester dataset is only more than 100, so only the resolution of
can be used. The performance of each model is comprehensively compared from the following five aspects.
4.3.1. Accuracy
We conducted accuracy tests on three classic video action recognition datasets: EgoGester, Jester, and UCF101. The training and test sets were split using the official dataset partitioning method. All models were trained from scratch without using any pre-trained models to test their ability to capture motion information. As shown in
Table 1, the accuracy loss of 3D lightweight convolutional networks, which are directly based on depthwise separable convolution structures, is quite severe on these three datasets. In the 3D-MobileNet series, 3D-MobileNetV2 performs better due to its inverse residual block containing more depth convolution filters, resulting in better performance in capturing dynamic motion. However, this also leads to higher memory access and slower inference speed. Although network models based on three-dimensional dilated convolution rely on their structure to reduce computation and achieve optimal inference speed when deployed on mobile devices, their accuracy suffers greatly and cannot be directly applied.
As shown in the table, the 3D-MobileViT model, which combines 3D CNN with ViTs, effectively compensates for accuracy loss and performs well on various datasets with no significant model bias. The three-dimensional convolutional model combined with ViT outperforms the three-dimensional convolutional model based on well-known lightweight networks. This demonstrates the advantages of using a hybrid model that integrates three-dimensional convolution and ViT. Specifically, three-dimensional convolution can extract temporal features, whereas the self-attention mechanism of ViT can model long-term sequence information. Our proposed 3D-ShuffleViT achieves excellent results on three different types of video action recognition datasets. Compared to lightweight networks of the same level, it achieves the best accuracy performance on the Jester and UCF101 datasets. On the EgoGester dataset, it surpasses most lightweight networks of the same level.
4.3.2. Parameter and Floating-Point Calculation
The floating-point arithmetic amount and parameter quantity of each model under different inputs are tested under different models. It can be seen from
Table 2 that under the lightweight 3D convolution in three ways, the size of the model is smaller than that of the traditional standard 3D convolution structure C3D and I3D. The ESPNetV2-3D network using 3D dilated convolution achieves relatively small consumption in both floating-point computation and parameters. The use of ViTs will generally lead to a surge in the amount of parameters, etc., but through the hybrid model, the use of 3D convolution to learn the inductive paranoia missing from ViTs achieves the purpose of reducing the amount of parameters and floating-point calculations. Compared with the improved 3D action recognition network directly using well-known lightweight models, as shown in
Table 1, this hybrid model has good performance in accuracy. Compared to 3D-MobileViT, our 3D-ShuffleViT is more compact and lightweight, and can compete with networks such as MobileNet and ShuffleNet. This further reduces the difficulty of model deployment.
4.3.3. Memory Access and Speed
The speed test is the inference speed of the GPU and CPU under PC devices and the inference speed of mobile devices.
(1) The amount of memory access of the model and the inference speed of the GPU and CPU under the PC device. In
Table 3, the measurement of the amount of memory access required by each model in the inference process and the computational density (FLOPs/Byte) of each model, which indicates how many floating-points each Byte is used for memory swaps, can be seen. Computing, the greater the computing density, the higher the memory usage efficiency. In the model using the 3D depthwise separable convolution method, although the 3D-MobileNetV2 in the 3D-MobileNet series has achieved excellent performance in the amount of floating-point calculations, the amount of parameters, and even the accuracy, it does not perform well in the inference process. The amount of memory access is significantly higher than other models, which also causes its inference speed to be slow, which is significantly higher than the inference delay of other models on both GPU and CPU. Under the action of the HardSwish and SE attention mechanism, 3D-MobileNetV3 is superior to 3D-MobileNetV1 in three aspects (parameter amount, floating-point calculation amount, memory access amount), so its reasoning speed on the GPU and CPU is higher than 3D-MobileNetV1.
Compared with C3D, it can be seen that the computational density of the model using standard 3D convolution is relatively high. After using 3D depthwise separable convolution, the amount of floating-point computation is greatly reduced and the decrease of memory access is relatively small, so the computational density of the model will be reduced, that is, the memory usage efficiency of the lightweight network using 3D depthwise separable convolutions will be reduced.
From
Table 3, it can be found that the inference speed of the model is improved after the amount of floating-point calculations, parameters, and memory access decreases. At the same time, it can be seen that the inference speed of the model is not only related to these three because in the same tested on the GPU, the speed of C3D is even higher than that of GHostNet, but GHostNet is significantly smaller than C3D in terms of parameters, floating-point calculations, and memory access. We think this is because GPUs are good at handling large-scale data, such as matrix inner products, whereas CPUs are good at performing serial computations on data. When the GPU computing power is large enough, one parallel calculation can be performed on each layer of the model, so the main influence on the inference time is the depth of the network, and for the CPU that is not good at processing parallel operations, the main influence on its inference speed is the amount of calculation. The depthwise separable convolution is to divide a convolution into a depthwise convolution and a point-by-point convolution. Under the same amount of calculations and parameters, the depth of the network can be deepened and the nonlinear expression ability can be improved. On the other hand, the CUDNN library [
38] optimizes standard convolution, so when tested on the GPU, the number of layers is less and C3D reasoning based on standard convolution has faster performance. However, at the same time, it can be seen from the data in the table that in the CPU test with limited computing power, the inference speed of using depthwise separable convolution is faster and the advantage is relatively more significant. Overall, the amount of floating-point calculations, parameters, and memory access still play an important role in inference speed.
As shown in
Table 3, our 3D-ShuffleViT model has a much higher inference speed on both the CPU and GPU compared to 3D-MobileViT. Among all models, its running speed on GPU is second only to the classic lightweight network 3D-ShuffleNetV2. This can be attributed to the small memory access of our model. Overall, our model effectively addresses the issue of significant loss caused by directly using depthwise separable convolution. By combining 3D depthwise separable convolution with ViTs and utilizing the lightweight ACISA module, our model achieves a superior balance between speed and accuracy compared to other network models, resulting in remarkable performance in all aspects.
(2) Inference speed on mobile devices. As shown in
Figure 7, dilated convolution based on 3D grouping is the fastest on mobile devices, but its accuracy performance is not ideal. The closer to the upper left corner of the figure, the better the model, and it can be seen from the figure that 3D-ShuffleViT has the best balance in accuracy and speed. The large amount of memory access of 3D-MobileNetV2 also causes its inference speed to be too slow on the mobile side of devices with limited computing power compared to other models. This phenomenon is increasingly evident from GPUs and CPUs to edge devices.
4.4. Ablation Experiment
As can be seen from
Table 4, after adding our proposed 3D-ShuffleViT network to the 3D-ACMix module, the accuracy can be significantly improved. However, in actual use, it has high memory usage. This is because the 3D Unfold operation limits the overall efficiency. To avoid the problems with 3D-ACMix, we further propose the 3D-ACISA module. When not using 3D positional encoding, we found that compared to the baseline, performance can be improved to a certain extent, but it is slightly lower than when the 3D-ACMix module is added. After introducing 3D positional encoding, the performance was greatly improved. From the perspective of parameter and computational complexity, the introduction of the 3D-ACISA module resulted in a slight increase in parameters and computational complexity. However, as can be seen from
Table 2, our 3D-ShuffleViT is still able to maintain its status as a lightweight network. After incorporating the ACISA module following the first SFV2-3D module, the larger dimensions of shallow features in terms of height and width resulted in an increase in computational demand. As indicated by our results, this led to a further improvement in accuracy. However, given that this comes at the expense of an increased number of parameters, our primary focus in this paper is on achieving efficient video action recognition on mobile devices with limited computational capabilities. As such, we have not adopted this approach.
In order to further demonstrate the effectiveness of our proposed ACISA module in enhancing the ability of models to extract temporal information and mitigate the accuracy loss associated with lightweight networks, we have integrated the ACISA module into other models. Given that the ACISA module is designed as a plug-and-play component, it can be readily incorporated into other architectures. As shown in
Table 5, the incorporation of the ACISA module resulted in a significant improvement in accuracy for other models, with only a negligible increase in the number of parameters and a slight increase in computational demand.
5. Conclusions
In this paper, we first expand the classic lightweight network to three dimensions through dilation, making it suitable for video action recognition tasks that contain temporal information. Starting from the theoretical analysis of each model, and through comprehensive experimental testing to compare the performance of each model, we propose our lightweight 3D-ShuffleViT network that integrates convolution and attention mechanisms. In order to further improve the performance of the model, we further propose the ACISA module. Experiments show that our proposed module avoids the problems of slow real inference speed, large memory occupation, and difficulty in long-distance temporal modeling in the 3D-ACMix module, and further improves the performance of the 3D-ShuffleViT network.
Our research results show that the 3D-ShuffleViT, which deeply integrates 3D CNNs and attention mechanisms, can compensate for the accuracy loss of 3D convolutional networks directly expanded based on lightweight networks to a certain extent, while maintaining its light weight. It performs well in both action recognition related to environmental information and action recognition unrelated to environmental information, achieving the best balance between accuracy and speed among lightweight networks of the same level. It further enhances the possibility of deploying and using neural network-based action recognition as an input for edge device interaction. In addition, our 3D-ShuffleViT and ACISA modules not only perform well in video action recognition tasks, but also show transferability in a wider range of three-dimensional tasks. It is worth noting that ACISA, as a general plug-and-play module, can show good adaptability and effectiveness in various three-dimensional tasks. Furthermore, we believe that there is still room for further optimization and lightweighting of the self-attention branch of the ACISA module in 3D-ShuffleViT. In our future work, we will continue to explore ways to better harness this potential in order to further enhance the performance of the model.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}