


Traffic-Sign-Detection Algorithm Based on SK-EVC-YOLO
Abstract
:1. Introduction
2. Related Work
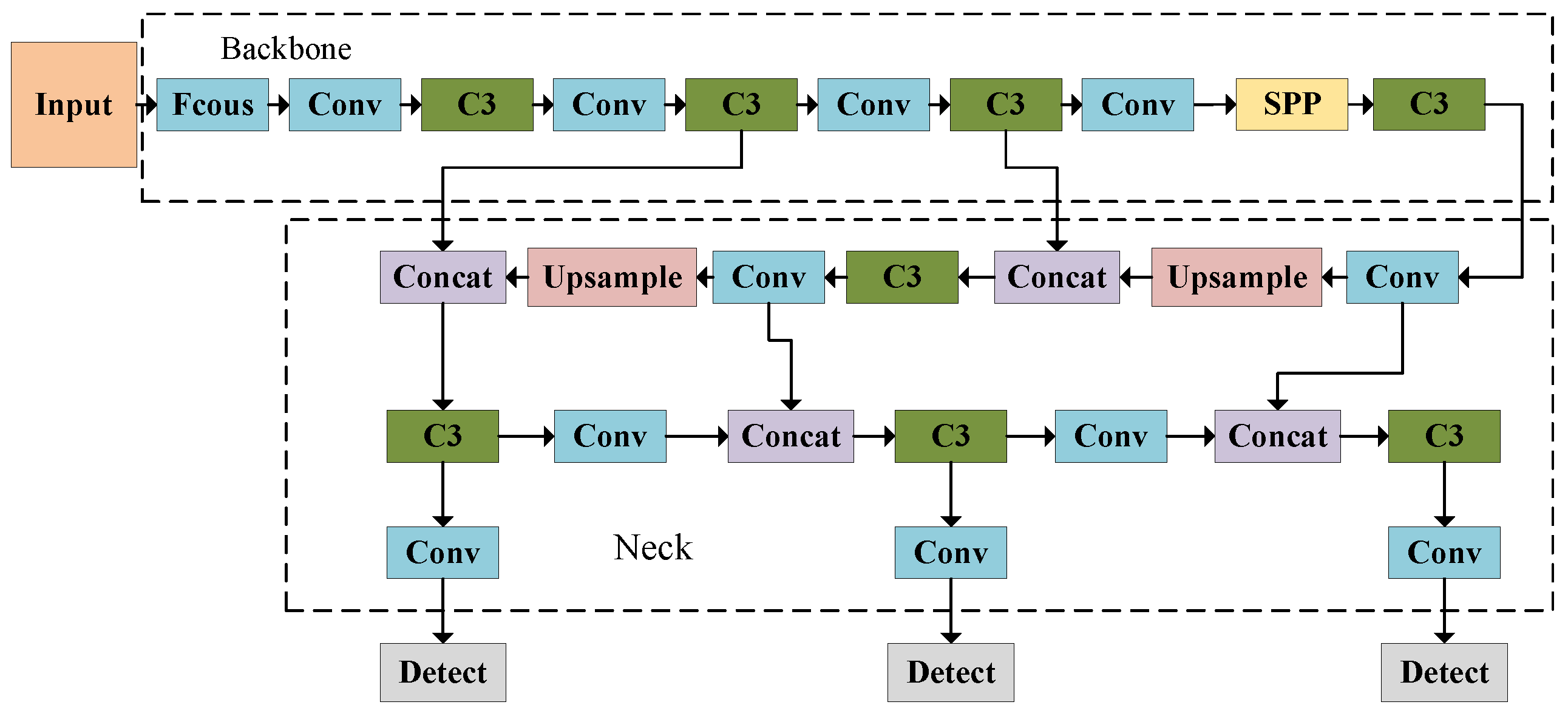
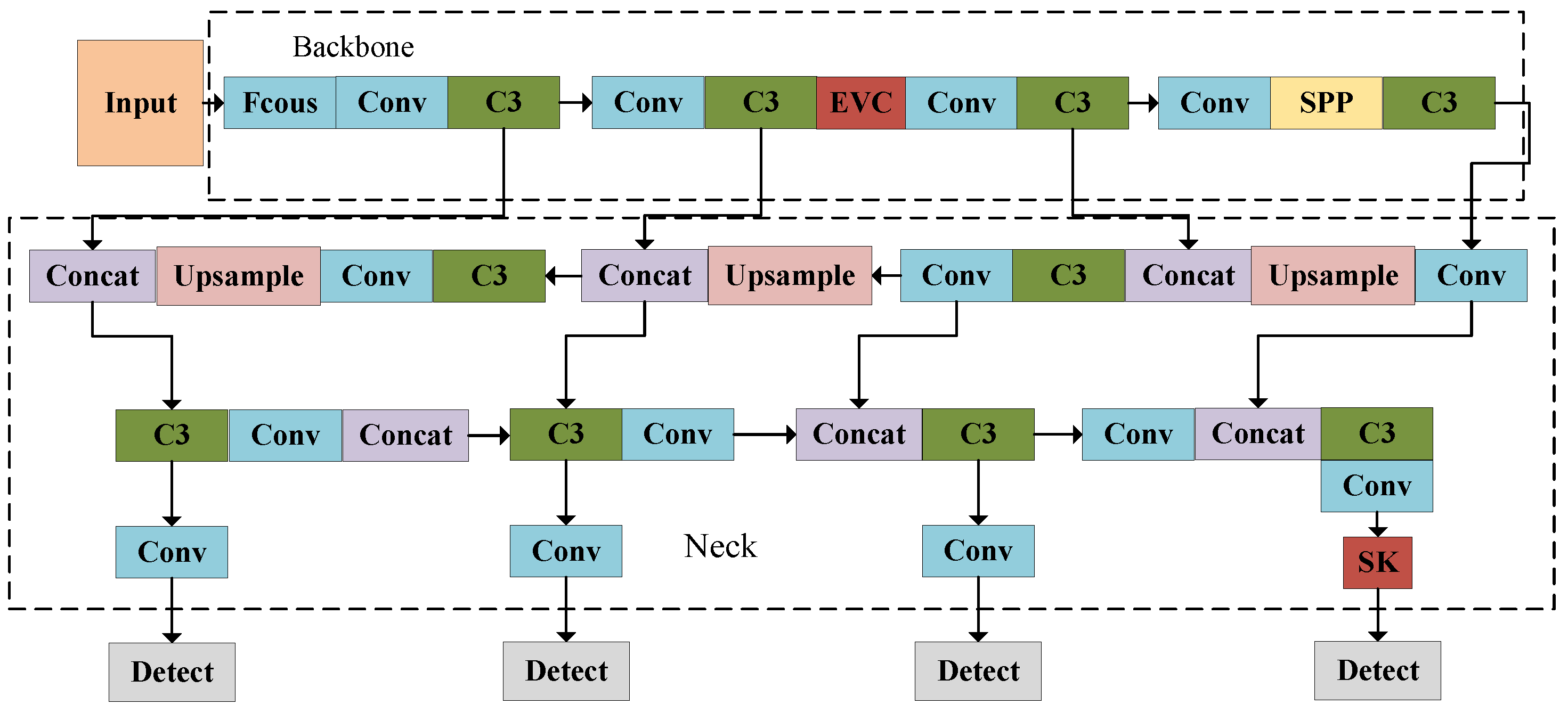
3. Improved YOLOv5 Model
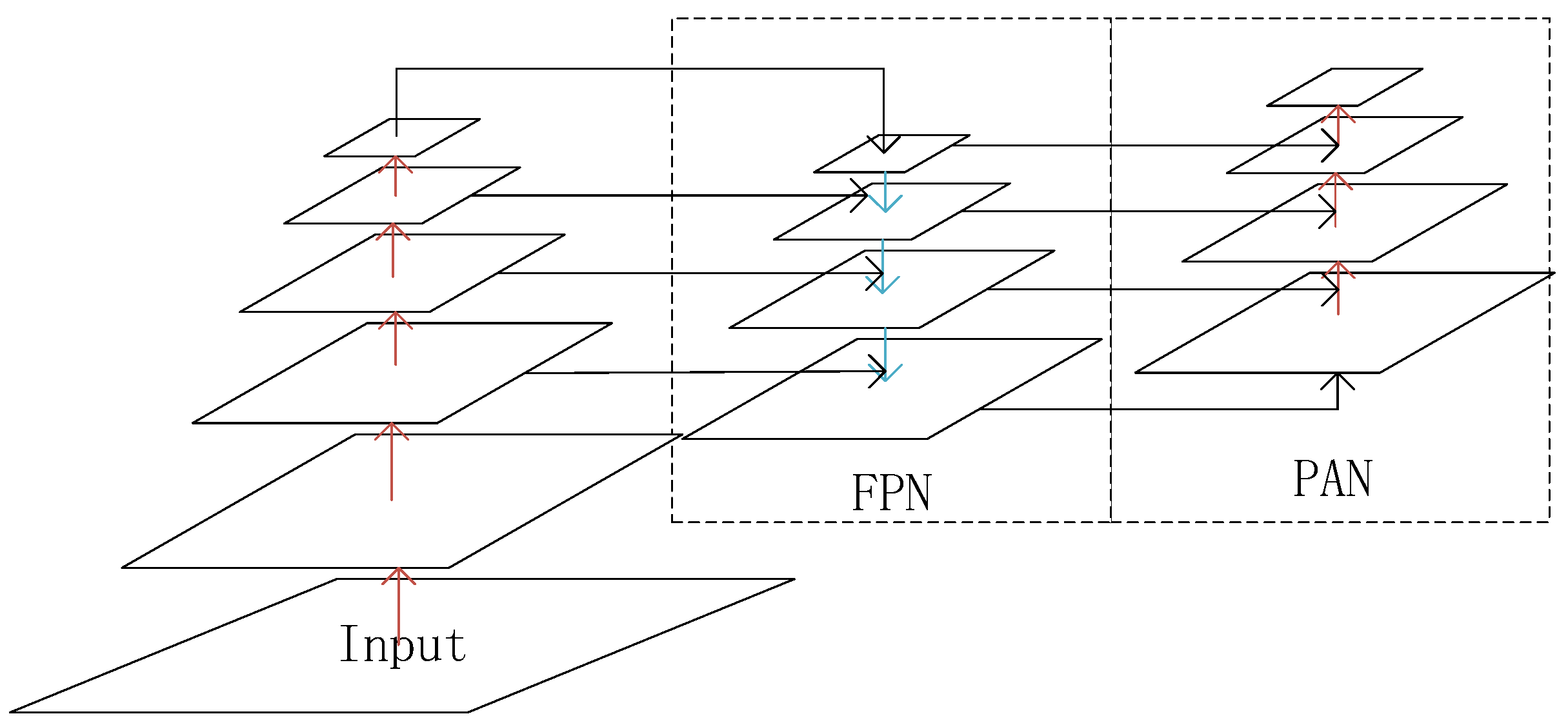
3.1. Small Target Detection Layer
3.2. SK Attention Mechanism
3.3. Explicit Visual Center
4. Experiment and Analysis
4.1. Dataset
4.2. Experiment Environment and Parameters
4.3. Evaluation Indicators
4.4. Comparison with Other Algorithms
4.5. Comparison of Different Attention Mechanisms
4.6. Ablation Experiments
4.7. Visualization of Test Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; Zhang, Z. Research on a traffic sign recognition method under small sample conditions. Sensors 2023, 23, 5091. [Google Scholar] [CrossRef] [PubMed]
- Garg, T.; Kaur, G. A systematic review on intelligent transport systems. J. Comput. Cogn. Eng. 2023, 2, 175–188. [Google Scholar] [CrossRef]
- Li, W.; Li, X.; Qin, Y.; Song, W.; Cui, W. Application of Improved LeNet-5 Network in Traffic Sign Recognition. In Proceedings of the ICVIP 2019: 2019 the 3rd International Conference on Video and Image Processing, Shanghai, China, 20–23 December 2019. [Google Scholar]
- Li, D.; Su, Z.; Liu, Y. Road traffic sign recognition based on improved YOLOv4. Opt. Precis. Eng. 2023, 31, 1366–1378. [Google Scholar] [CrossRef]
- Huang, K. Traditional methods and machine learning-based methods for traffic sign detection. In Proceedings of the Third International Conference on Intelligent Computing and Human-Computer Interaction, Guangzhou, China, 12–14 August 2022. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Proceedings, Part I 14, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Computer Society, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; p. 28. [Google Scholar]
- Gao, B.; Jiang, Z.; Zhang, J. Traffic Sign Detection based on SSD. In Proceedings of the 2019 4th International Conference, Guilin, China, 19–21 July 2019; pp. 1–6. [Google Scholar]
- Lin, Y.; Chen, L.; Wang, G.; Sheng, Y.; Sun, L. Improved YOLOv3 Traffic Sign Recognition Algorithm. Sci. Technol. Eng. 2022, 22, 12030–12037. [Google Scholar]
- Wang, J.; Chen, Y.; Dong, Z.; Gao, M. Improved YOLOv5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 2022, 35, 7853–7865. [Google Scholar] [CrossRef]
- Jiang, L.; Liu, H.; Zhu, H.; Zhang, G. Improved YOLO v5 with balanced feature pyramid and attention module for traffic sign detection. MATEC Web Conf. Edp Sci. 2022, 355, 03023. [Google Scholar] [CrossRef]
- Yuan, X.; Wang, G.; Wang, Y.; Wang, Y.; Sun, H. Traffic sign recognition method based on improved convolutional neural network. Electron. Sci. Technol. 2019, 32, 28–32. [Google Scholar]
- Li, Z.; Zhang, N. A lightweight YOLOv5 traffic sign identification method. Telecommun. Technol. 2022, 62, 1201–1206. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze and extension networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Hu, J.; Wang, Z.; Chang, M.; Xie, L.; Xu, W.; Chen, N. PSG-Yolov5: A Paradigm for Traffic Sign Detection and Recognition Algorithm Based on Deep Learning. Symmetry 2022, 14, 2262. [Google Scholar] [CrossRef]
- Wei, Q.; Hu, X.; Zhao, H. Improving the Traffic Sign Detection Method of YOLOv5. Comput. Eng. Appl. 2023, 59, 229–237. [Google Scholar]
- Lang, B.; Lv, B.; Wu, J.; Wu, R. A Traffic Sign Detection Model Based on CA-BIFPN. J. Shenzhen Univ. (Sci. Eng. Ed.) 2023, 4014, 335–343. [Google Scholar]
- Li, K.; Wang, X.; Lin, H.; Li, L.; Yang, Y.; Meng, C.; Gao, J. Review of Single-stage Small Target Detection Methods in Deep Learning. Comput. Sci. Explor. 2022, 16, 41. [Google Scholar]
- Wang, P.; Huang, H.; Wang, M. Complex Road Object Detection Algorithm for Improved YOLOv5. J. Comput. Eng. Appl. 2022, 58, 81–92. [Google Scholar]
- Mao, Z.; Ren, Y.; Chen, X.; Ren, K.; Zhao, Y. An improved multi-scale object detection algorithm for YOLOv5s. J. Sens. Technol. 2023, 36, 267–274. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized Feature Pyramid for Object Detection. arXiv 2022, arXiv:2210.02093. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2110–2118. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6105–6114. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Liu, Y.; Shao, Z.; Teng, Y.; Hoffmann, N. NAM: Normalization-based attention module. arXiv 2021, arXiv:2111.12419. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. Simam: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Wang, H.; Zhang, X.; Jiang, S. A laboratory and field universal estimation method for tire–pavement interaction noise (TPIN) based on 3D image technology. Sustainability 2022, 14, 12066. [Google Scholar] [CrossRef]
- Li, Z.; Kong, Y.; Jiang, C. A Transfer Double Deep Q Network Based DDoS Detection Method for Internet of Vehicles. IEEE Trans. Veh. Technol. 2023, 72, 5317–5331. [Google Scholar] [CrossRef]
- Xu, J.; Pan, S.; Sun, P.Z.; Park, S.H.; Guo, K. Human-factors-in-driving-loop: Driver identification and verification via a deep learning approach using psychological behavioral data. IEEE Trans. Intell. Transp. Syst. 2022, 24, 3383–3394. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Parameters |
|---|---|
| System | Windows10 |
| CPU | Intel core i9-10980 |
| GPU | Nvidia RTX 3090 |
| Video memory | 24 G |
| Memory | 256 G |
| CUDA | 11.7 |
| CUDNN | 8.5.0 |
| Pytorch | 1.13.0 |
| Parameter Name | Parameter Value |
|---|---|
| Epochs | 250 |
| Batchsize | 16 |
| Learning rate | 0.01 |
| Input image size | 640 × 640 |
| Model | mAP |
|---|---|
| SSD | 0.537 |
| Faster RCNN | 0.743 |
| YOLOv3 | 0.684 |
| YOLOv4 | 0.762 |
| YOLOv5 | 0.839 |
| EfficientNet | 0.663 |
| Swin Transformer | 0.705 |
| YOLOX | 0.804 |
| Ours | 0.885 |
| Model | Precision | Recall | mAP |
|---|---|---|---|
| YOLOv5 + CBAM | 0.851 | 0.81 | 0.833 |
| YOLOv5 + CA | 0.853 | 0.82 | 0.844 |
| YOLOv5 + ECA | 0.849 | 0.801 | 0.834 |
| YOLOv5 + NAM | 0.867 | 0.808 | 0.847 |
| YOLOv5 + SIMAM | 0.851 | 0.82 | 0.845 |
| YOLOv5 + SK | 0.852 | 0.83 | 0.848 |
| Model | Small Object Detection Layer | SK | EVC | Precision | Recall | mAP |
|---|---|---|---|---|---|---|
| 1 | 0.876 | 0.788 | 0.839 | |||
| 2 | ✓ | 0.859 | 0.83 | 0.867 | ||
| 3 | ✓ | 0.852 | 0.83 | 0.848 | ||
| 4 | ✓ | 0.847 | 0.827 | 0.86 | ||
| 5 | ✓ | ✓ | 0.875 | 0.824 | 0.875 | |
| 6 | ✓ | ✓ | 0.868 | 0.827 | 0.876 | |
| 7 | ✓ | ✓ | 0.88 | 0.841 | 0.88 | |
| 8 | ✓ | ✓ | ✓ | 0.872 | 0.843 | 0.885 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, F.; Zu, H.; Li, Y.; Song, Y.; Liao, J.; Zheng, C. Traffic-Sign-Detection Algorithm Based on SK-EVC-YOLO. Mathematics 2023, 11, 3873. https://doi.org/10.3390/math11183873
Zhou F, Zu H, Li Y, Song Y, Liao J, Zheng C. Traffic-Sign-Detection Algorithm Based on SK-EVC-YOLO. Mathematics. 2023; 11(18):3873. https://doi.org/10.3390/math11183873
Chicago/Turabian StyleZhou, Faguo, Huichang Zu, Yang Li, Yanan Song, Junbin Liao, and Changshuo Zheng. 2023. "Traffic-Sign-Detection Algorithm Based on SK-EVC-YOLO" Mathematics 11, no. 18: 3873. https://doi.org/10.3390/math11183873
APA StyleZhou, F., Zu, H., Li, Y., Song, Y., Liao, J., & Zheng, C. (2023). Traffic-Sign-Detection Algorithm Based on SK-EVC-YOLO. Mathematics, 11(18), 3873. https://doi.org/10.3390/math11183873