
Risk Analysis of the Chinese Financial Market with the Application of a Novel Hybrid Volatility Prediction Model
Abstract
:1. Introduction
2. Materials and Methods
2.1. Realized Volatility
2.2. Models
2.2.1. GARCH and EGARCH
2.2.2. LSTM
2.2.3. Proposed Hybrid Models
2.2.4. Variables
3. Results
3.1. Data
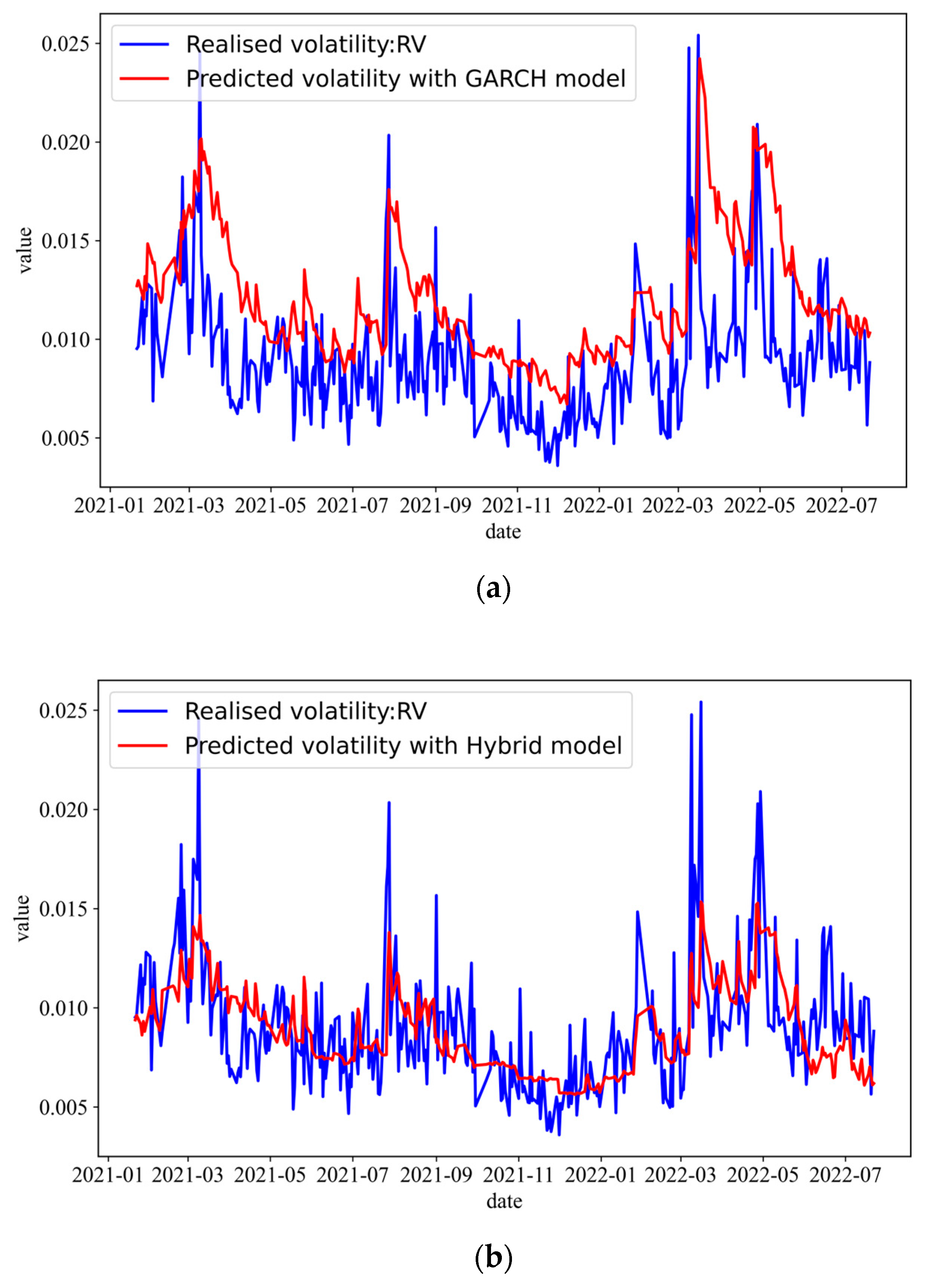
3.2. Volatility Prediction
4. Discussion
4.1. VaR Analysis
4.2. Robustness Tests
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Engle, R. Autoregressive conditional heteroskedasticity with estimates of the variance of U.K. inflation. Econometrica 1982, 50, 987–1008. [Google Scholar] [CrossRef]
- Andersen, T.G.; Bollerslev, T. Answering the Skeptics: Yes, Standard Volatility Models Do Provide Accurate Forecasts. Int. Econ. Rev. 1998, 39, 885. [Google Scholar] [CrossRef]
- Nelson, D.B. Conditional heteroskedasticity in asset returns: A new approach. Econom. J. Econom. Soc. 1991, 59, 347–370. [Google Scholar] [CrossRef]
- Baruník, J.; Křehlík, T. Combining high frequency data with non-linear models for forecasting energy market volatility. Expert Syst. Appl. 2016, 55, 222–242. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Zhou, Y.; Dai, F. A LSTM-based method for stock returns prediction: A case study of China stock market. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 2823–2824. [Google Scholar]
- Kim, H.Y.; Won, C.H. Forecasting the volatility of stock price index: A hybrid model integrating LSTM with multiple GARCH-type models. Expert Syst. Appl. 2018, 103, 25–37. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- D’amato, V.; Levantesi, S.; Piscopo, G. Deep learning in predicting cryptocurrency volatility. Phys. A Stat. Mech. Appl. 2022, 596, 127158. [Google Scholar] [CrossRef]
- Tapia, S.; Kristjanpoller, W. Framework based on multiplicative error and residual analysis to forecast bitcoin intra-day-volatility. Phys. A Stat. Mech. Appl. 2022, 589, 126613. [Google Scholar] [CrossRef]
- Amirshahi, B.; Lahmiri, S. Hybrid deep learning and GARCH-family models for forecasting volatility of cryptocurrencies. Mach. Learn. Appl. 2023, 12, 100465. [Google Scholar] [CrossRef]
- Kristjanpoller, R.W.; Hernández, P.E. Volatility of main metals forecasted by a hybrid ANN-GARCH model with regressors. Expert Syst. Appl. 2017, 84, 290–300. [Google Scholar] [CrossRef]
- Vidal, A.; Kristjanpoller, W. Gold volatility prediction using a CNN-LSTM approach. Expert Syst. Appl. 2020, 157, 113481. [Google Scholar] [CrossRef]
- Shao, X.D.; Yin, L.Q. The study on financial market risk measures in China based on realized range and realized volatility. J. Financ. Res. 2008, 6, 109–121. [Google Scholar]
- Kuster, K. Value-at-Risk Prediction: A Comparison of Alternative Strategies. J. Financ. Econom. 2006, 4, 53–89. [Google Scholar] [CrossRef]
- Kristjanpoller, W.; Minutolo, M.C. A hybrid volatility forecasting framework integrating GARCH artificial neural network, technical analysis and principal components analysis. Expert Syst. Appl. 2018, 109, 1–11. [Google Scholar] [CrossRef]
- Ramos-Pérez, E.; Alonso-González, P.J.; Núñez-Velázquez, J.J. Forecasting volatility with a stacked model based on a hybridized Artificial Neural Network. Expert Syst. Appl. 2019, 129, 1–9. [Google Scholar] [CrossRef]
- Liu, Y. Novel volatility forecasting using deep learning–Long Short Term Memory Recurrent Neural Networks. Expert Syst. Appl. 2019, 132, 99–109. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econ. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Maknickienė, N.; Maknickas, A. Application of neural network for forecasting of exchange rates and forex trading. In Proceedings of the 7th International Scientific Conference Business and Management, Vilnius, Lithuania, 10–11 May 2012; pp. 10–11. [Google Scholar]
- Roh, T.H. Forecasting the volatility of stock price index. Expert Syst. Appl. 2007, 33, 916–922. [Google Scholar] [CrossRef]
- Wang, Y.-H. Nonlinear neural network forecasting model for stock index option price: Hybrid GJR–GARCH approach. Expert Syst. Appl. 2009, 36, 564–570. [Google Scholar] [CrossRef]
- Hajizadeh, E.; Seifi, A.; Zarandi, M.F.; Turksen, I.B. A hybrid modeling approach for forecasting the volatility of S&P 500 index return. Expert Syst. Appl. 2012, 39, 431–436. [Google Scholar]
- Kristjanpoller, W.; Fadic, A.; Minutolo, M.C. Volatility forecast using hybrid Neural Network models. Expert Syst. Appl. 2014, 41, 2437–2442. [Google Scholar] [CrossRef]
- Kristjanpoller, W.; Minutolo, M.C. Forecasting volatility of oil price using an artificial neural network-GARCH model. Expert Syst. Appl. 2016, 65, 233–241. [Google Scholar] [CrossRef]
- Fuertes, A.-M.; Izzeldin, M.; Kalotychou, E. On forecasting daily stock volatility: The role of intraday information and market conditions. Int. J. Forecast. 2009, 25, 259–281. [Google Scholar] [CrossRef]
- Oliveira, N.; Cortez, P.; Areal, N. The impact of microblogging data for stock market prediction: Using Twitter to predict returns, volatility, trading volume and survey sentiment indices. Expert Syst. Appl. 2017, 73, 125–144. [Google Scholar] [CrossRef]
- Yao, Y.; Zhai, J.; Cao, Y.; Ding, X.; Liu, J.; Luo, Y. Data analytics enhanced component volatility model. Expert Syst. Appl. 2017, 84, 232–241. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Variables | Symbol | Definition |
|---|---|---|
| Dependent variable | RV | See Equation (1). |
| Macro variables | RATE | Interbank offered (lending) rate (monthly). |
| CPI | Consumer price index (monthly). | |
| CSI | Consumer sentiment index (monthly). | |
| GROWTH | National industrial growth rate (monthly). | |
| Market price | denotes the i-th 5 min close price of CSI300 Index on the t-th day. | |
| Market return | denotes the daily return of CSI300 Index on the t-th day. | |
| denotes the i-th 5 min return of CSI300 Index on the t-th day. |
| Variables | Mean | Std. | Min. | Max. |
|---|---|---|---|---|
| RV | 0.8167 | 0.3532 | 0.2535 | 2.9588 |
| Return | 0.0166 | 1.2006 | −8.2087 | 5.7774 |
| Model | MAE | RMSE | MAPE |
|---|---|---|---|
| GARCH | 0.0035 | 0.0043 | 0.4483 |
| EGARCH | 0.0041 | 0.0048 | 0.5183 |
| GED-EGARCH | 0.0040 | 0.0047 | 0.5153 |
| Hybrid model (adding macro variables) | 0.0020 | 0.0027 | 0.2233 |
| VaR Confidence Level | Our Model | RV | CSI300 |
|---|---|---|---|
| 99% | −0.0142 | −0.1898 | −0.228 |
| 90% | −0.2075 | −0.2494 | −0.228 |
| Model | MAE | RMSE | MAPE |
|---|---|---|---|
| GARCH | 0.0041 | 0.0048 | 0.5433 |
| EGARCH | 0.0045 | 0.0051 | 0.6015 |
| GED-EGARCH | 0.0045 | 0.0051 | 0.6101 |
| Hybrid model (adding macro variables) | 0.0025 | 0.0031 | 0.3382 |
| Model | MAE | RMSE | MAPE |
|---|---|---|---|
| GARCH | 0.0045 | 0.0054 | 0.5341 |
| EGARCH | 0.0048 | 0.0055 | 0.5762 |
| GED-EGARCH | 0.0048 | 0.0054 | 0.5762 |
| Hybrid model (adding macro variables) | 0.0025 | 0.0035 | 0.2495 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Wu, Y. Risk Analysis of the Chinese Financial Market with the Application of a Novel Hybrid Volatility Prediction Model. Mathematics 2023, 11, 3937. https://doi.org/10.3390/math11183937
Wang W, Wu Y. Risk Analysis of the Chinese Financial Market with the Application of a Novel Hybrid Volatility Prediction Model. Mathematics. 2023; 11(18):3937. https://doi.org/10.3390/math11183937
Chicago/Turabian StyleWang, Weibin, and Yao Wu. 2023. "Risk Analysis of the Chinese Financial Market with the Application of a Novel Hybrid Volatility Prediction Model" Mathematics 11, no. 18: 3937. https://doi.org/10.3390/math11183937
APA StyleWang, W., & Wu, Y. (2023). Risk Analysis of the Chinese Financial Market with the Application of a Novel Hybrid Volatility Prediction Model. Mathematics, 11(18), 3937. https://doi.org/10.3390/math11183937