Abstract
Various transportation services exist, such as ride-sharing or shared taxis, in which customers receive services in a batch of flexible sizes and share fees. In this study, we conducted an equilibrium analysis of a variable batch service model in which customers who observe no waiting customers in an incomplete batch can strategically select a batch size to maximize the individual utilities. We formulated this model as a three-dimensional Markov chain and created a book-type transition diagram. To consider the joining/balking dilemma of customers for this model, we proposed an effective algorithm to construct a necessary and sufficient size of state space for the Markov chain provided that all customers adopt the threshold-type equilibrium strategy. Moreover, we proved that the best batch size is a non-decreasing function for i if the reward for the completion of batch service with size l is an increasing function of l assuming that a tagged customer observes i complete batches in the system upon arrival; in other words, the fee decreases as the batch becomes larger. We then derive several performance measures, such as throughput, social welfare, and monopolist’s revenue. Throughout the numerical experiment, a comparison between the present variable batch service model and regular batch service model in which customers were served in a constant batch, was discussed. It was demonstrated that the three performance measures can be optimized simultaneously in the variable batch service model, as long as the fee was set relatively high.
Keywords:
queues with strategic customers; nash equilibrium; batch service; variable batch size; strategic choice of batch size; social optimization; revenue management MSC:
90B22; 60K25; 60K30
1. Introduction
Batch service queueing systems have frequently appeared in recent transportation services. Examples are shared taxis or ride-sharing services, such as Uber or Lyft. In these systems, customers typically form a group, ride in the same vehicle, and share a move. Then, the concern over the ‘best’ batch size has risen. Customers generally share fees with other customers in a batch; therefore, the financial burden on a customer decreases as the batch size increases. However, customers must experience longer waiting times to create a larger batch, that is, to wait for the arrival of other customers. Therefore, to determine the ideal batch size, constructing a model that considers both financial and time costs is necessary.
In the field of queueing theory, many studies that consider the behavior of strategic customers have been conducted to discuss systems from an economic viewpoint. Regarding batch service queueing systems, some studies have been conducted on models in which strategic customers are served in a batch with a constant batch size. However, to the best of our knowledge, a model in which customers strategically select a batch size to maximize their individual utility based on the state of the system has never been studied. In this study, we analyzed such a dynamic batch service queueing system with strategic customers (see the detailed explanation in Section 2). From a managerial perspective, for modern transportation systems, a scope for discussion regarding the effect of the strategic choice of batch size on both social welfare and administrator revenue still exists. In addition, the analysis of this model is challenging from a modeling perspective. The arrival interval of complete batches to the system depends on the congestion level in the present model, whereas the arrival process in the constant batch size model can be expressed by the Erlang distribution with a rate equivalent to the arrival rate of customers and shape, which is determined by the batch size.
The batch service queueing model was pioneered by Bailey [1], and many studies have been conducted for more than half a century. We refer to the thorough survey in [2] and only cite the research that handles a non-constant batch size:
- General bulk-service (GBS) queues. The GBS rule (or -rule) is explained as follows. The server will start to provide service only when at least ‘a’ customers are in the queue, and the maximum service capacity is ‘b’. This type of queue has been studied extensively (see, e.g., [3,4,5,6,7,8,9,10,11,12,13]). As finite buffer models, a few studies have been conducted (see, e.g., [14,15,16,17,18,19]). In addition, the models of batch-size-dependent service have been studied [13,18].
- Batch service queue with a random batch size. The models where the size of a batch service follows an arbitrary distribution have been conducted [20,21]. In addition, the model of batch-size-dependent service has been studied [22].
Queues with strategic customers were first investigated by Naor [23], who studied the joining/balking dilemma in an observable M/M/1 queue. Many studies have been conducted on the game-theoretical analysis of queues (see surveys [24,25]). Previous studies on batch service queueing systems can be summarized as follows:
- Regular batch service. Several studies have considered the system in which the service is conducted by a batch of constant batch size. The observable and unobservable models [26] as well as the partially observable models [27,28] have been studied. A simple extension to the multiple server model of the observable case has also been conducted [29]. Furthermore, an equilibrium analysis of a batch service queueing system considering the limitation for the number of service facilities (e.g., cars in the application of real life) has been studied [30].
- Clearing system. Some research has been conducted on the clearing system in which the service facilities periodically remove all present customers. The clearing system with strategic customers was first studied in [31], which assumes an alternative environment scheme. Moreover, a clearing system with bounded rationality was considered [32]. Furthermore, many policies of information disclosure levels were compared (see, e.g., [33,34,35]). The analysis of a transportation system with constant intervisit time and heterogeneous customers was also conducted [36].
- Choice among multiple capacity services. Several studies have been conducted on the strategic choice among infinite server systems with regular batches and single-server systems of single service [37,38,39,40,41]. These studies showed interesting Downs–Thompson and Braess-type paradoxes through the equilibrium analyses of this type of model. Some recent studies considered the routing problems in a parallel clearing system [42] and the strategical choice between a single service and batch service with size two on the basis of waiting time cost [43].
This study is related to pricing control among different types of services. The aforementioned study on clearing systems [34] also considered the pricing scheme. Additionally, we cite the following papers:
- Priority queues. One fundamental method of pricing control is the introduction of priorities. In priority queues, customers can buy the priorities with the additional fee and replace the ordinary (not buying priority) customers, saving the waiting time (see, e.g., Chapter 4 in [24] and [44,45]). Both social optimization and revenue maximization were considered in [44].
In this study, we proposed a new type of observable batch service queueing system. This mechanism can be briefly explained as follows: If no complete batch exists when a new customer arrives in the system, he can decide the size of his batch to be served (or balking the system) based on the expected utility, which depends on the expected sojourn time and fee. A new customer, who finds any waiting customers in an incomplete batch, decides to join the batch or balk the system based on expected utility. This model corresponds to the recent shared-taxi or ride-sharing system, where customers create a group of favorable size based on the shared fee and the expected time cost, which is influenced by the arrival rate of customers and the congestion state of the road.
From a technical perspective, we extended the two-dimensional Markov chain in the regular batch service model [26] to a three-dimensional Markov chain that considers the batch size of an incomplete batch. We found that our Markov chain forms the ‘book-type’ state space. By leveraging this form, we calculated the expected sojourn time for a tagged customer. To consider the joining/balking dilemma of customers for this model, we proposed an effective algorithm to construct a necessary and sufficient size of state space for the Markov chain provided that all customers adopt the threshold-type equilibrium strategy. Furthermore, we proved that the best batch size (for the first-arriving customer who observes zero waiting customers in an incomplete batch), provided that a tagged customer observes i complete batches in the system upon arrival, is a non-decreasing function for i if the reward for the completion of a batch service with size l is an increasing function of l; in other words, the fee decreases as the batch becomes larger.
We conducted various numerical experiments on throughput, social welfare, and revenue. In the experiment, we introduced the notions of ‘fixed fee’ and ‘sharing fee’. A fixed fee refers to the fee that all customers pay to receive the service, regardless of their batch size. The sharing fee refers to the fee for a batch, that is, the fee for a person is the sharing fee divided by the batch size. In this setting, we observed customer behavior by considering the trade-off between time and money.
The proposed model encompasses Naor’s model [23] and the observable regular batch service model [26]. Throughout the numerical experiment, we demonstrated some performance measures: throughput, social welfare, monopolist’s revenue, and expected sojourn time in the variable batch service model show more stable performance than the regular batch service model if both sharing and fixed fees are set to some extent.
In summary, the important messages of this study from the application point of view are as follows: the system where the administrator enables customers to form the favorable size of the batch to maximize their utility is meaningful, particularly when the fixed and sharing fees are relatively high. The proposed model does not show extremely bad results for any arrival rate as long as both fees are set in a well-balanced manner compared to the regular batch size model. This indicates that the proposed model is a robust model for the fluctuation of customer demand. In addition, the introduction of the variable batch service model can lead to optimizing all of the throughput, social welfare, and monopolist’s revenue, simultaneously, compared to the regular batch service model under a high setting of the fees. On the other hand, the variable batch service model shows bad performance when the fees are set low.
2. Modeling
This section describes the model settings in detail. Customers arrive at the queue according to a Poisson process at a rate one-by-one and receive the service as a batch. The (single) server service time for a batch follows an exponential distribution of the parameter regardless of the batch size. The reward for receiving a service is defined by R and the customer fee for a service with batch size l is denoted by . Therefore, the reward for receiving a service in a batch of size l can be regarded as . Furthermore, becomes a function of l with upper bound R. We assume that all customers are rational and have a common knowledge of the aforementioned information. Moreover, we assume that the system is observable; that is, customers can observe the number of complete batches in the system, the number of waiting customers in an incomplete batch, and the size of the incomplete batch (when it will become full) at the time of their arrival.
If a customer finds no waiting customers in the incomplete batch (i.e., all batches in the system are complete batches and he cannot join them) and i complete batches in the system, he decides to adopt the best batch size according to the following definition:
and
where denotes the expected sojourn time for a tagged customer who observes zero waiting customers in an incomplete batch, under the condition that the number of complete batches is i at the arrival time point, and the customer adopts batch size l. Here, note that stands for the maximum element (batch size) in set . If no incentive exists to join the system for any batch size, we let be 0.
If a tagged customer finds i complete batches, customer(s) in the incomplete batch, and the batch size that he receives from the service is l at his arrival time point, they join the system with probability as follows:
where represents the expected sojourn time (if he joins) under the condition that the number of complete batches and the number of customers in the incomplete batch are i and k, respectively, at his arrival time point with batch size of l.
We assume that not all customers are allowed to change their decisions (best batch size, join/balk) after deciding. For simplicity, we assume that customers are in favor of joining a larger batch; that is, when they are indifferent between joining and balking, they choose to join, and when they are indifferent among multiple batch sizes, they choose the largest batch, similar to that in [26].
Let , , and denote the number of complete batches, number of waiting customers in the incomplete batch, and the size of the incomplete batch when it becomes full, respectively, at time t. Then, becomes an irreducible three-dimensional Markov chain with state space , where
Notably, is a special case because accepts 1 automatically whenever holds, because of the aforementioned definition. Here, we let , L denote the random variables in the steady state, that is, the variables under .
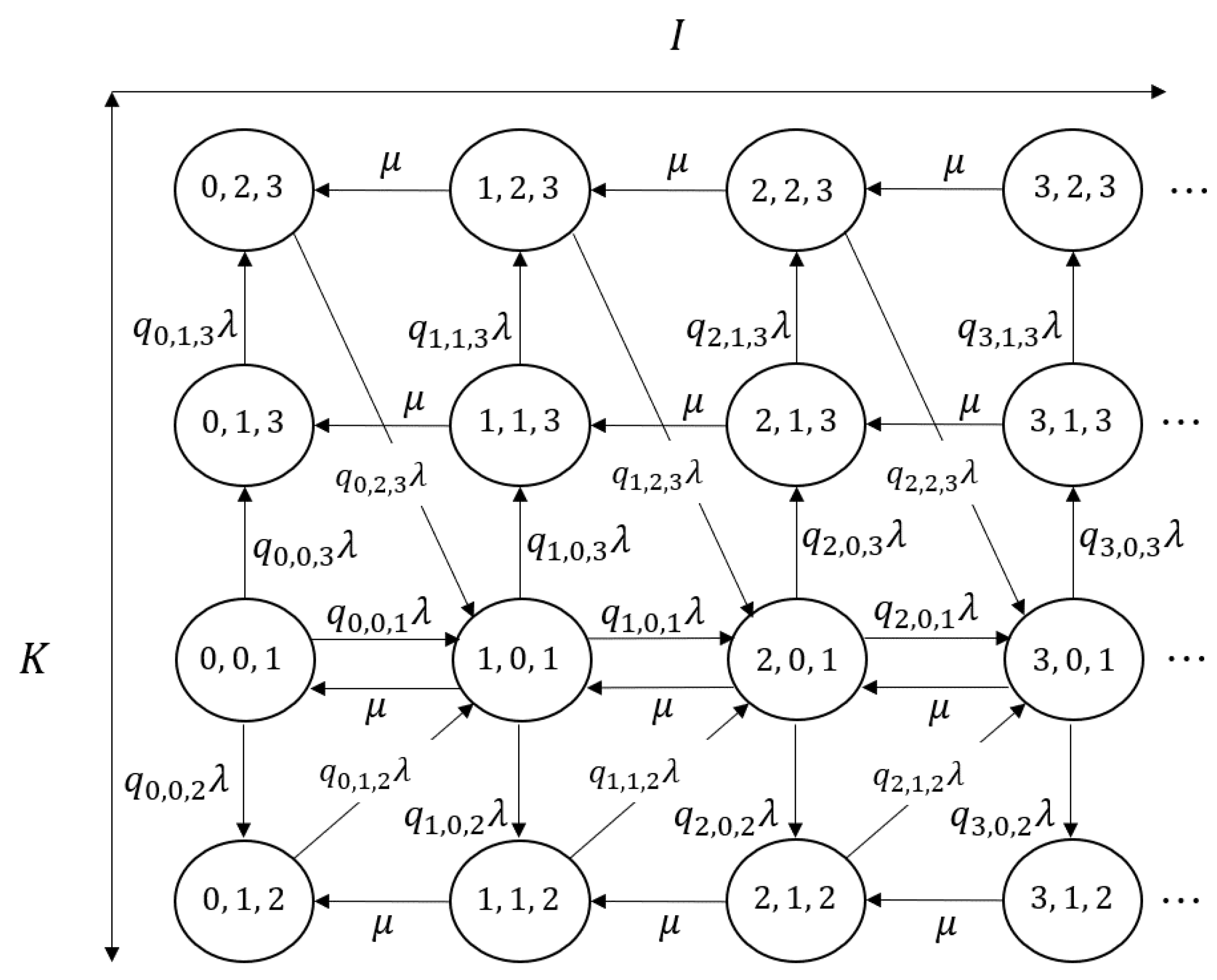
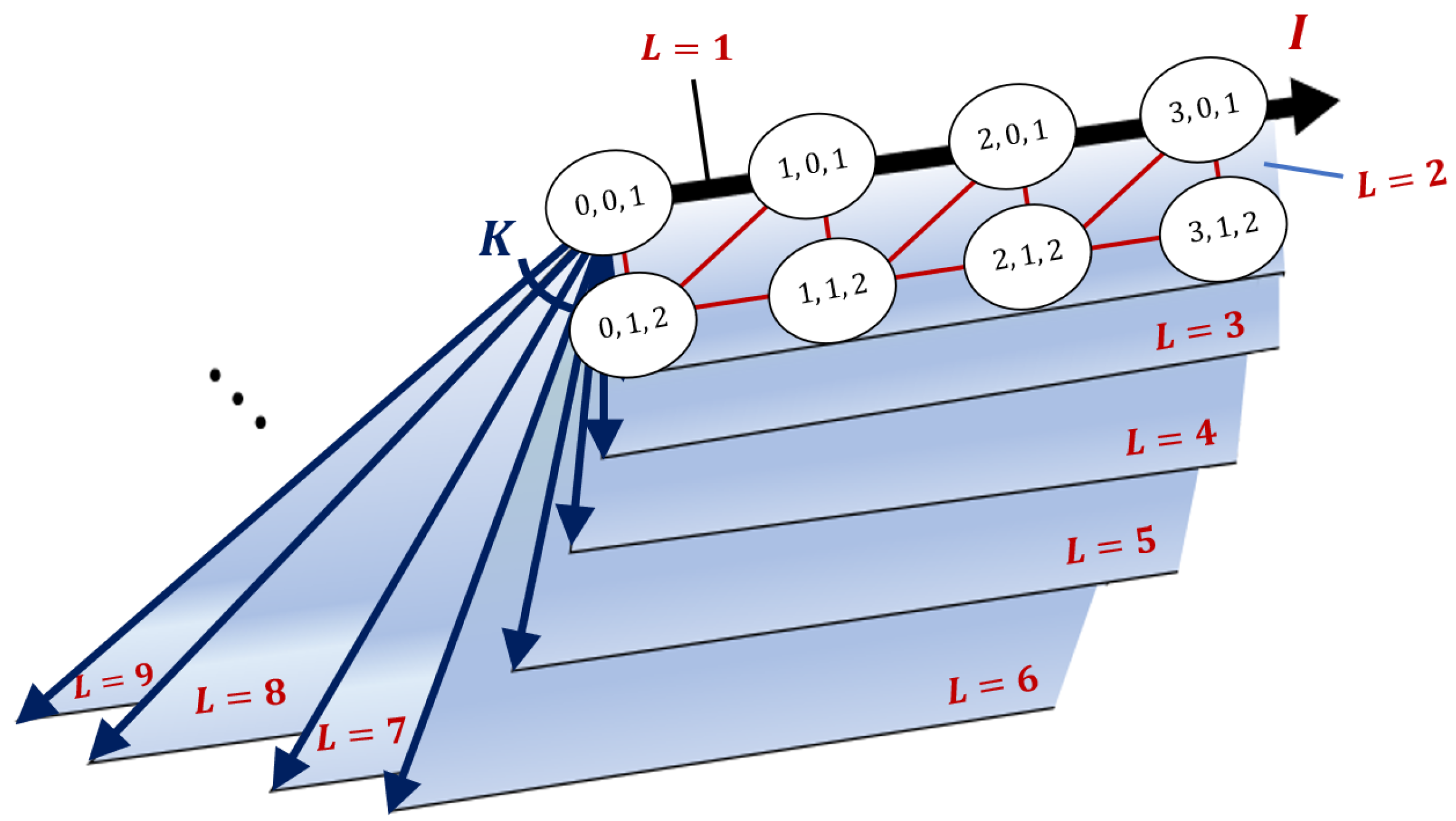
We refer to the transition diagram () in Figure 1 and schematic of the overall transition structure in Figure 2. Let in the diagram denote the probability that a tagged customer who observes i complete batches and 0 customers in the incomplete batch chooses batch size l, similar to that in (2). Notably, Figure 2 shapes ‘book type’ form in which the axis corresponds to the states where any incomplete batch does not exist, and the pages correspond to the other state. In other words, the axis corresponds to the special case of . Based on this three-dimensional Markov chain, we propose algorithmic procedures for analyzing the model in Section 3.
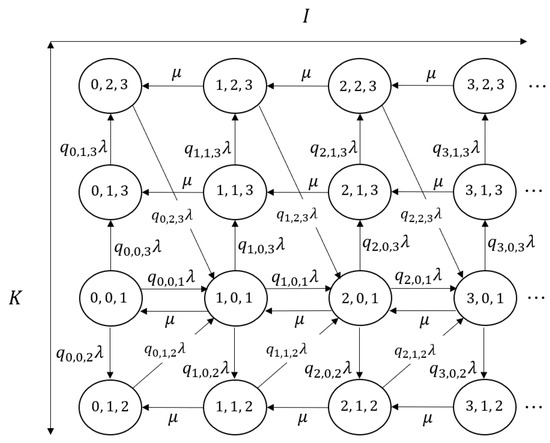
Figure 1.
The transition diagram ().
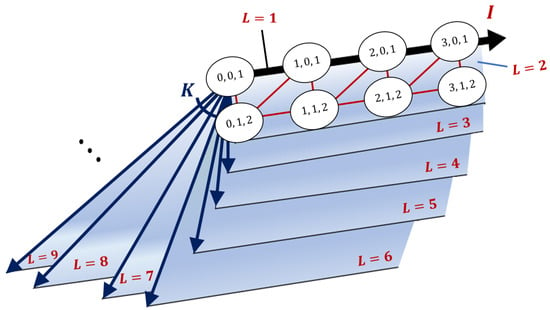
Figure 2.
Schematic of the transition diagram.
The proposed model encompasses Naor’s model [23] (observable M/M/1 model), where we set and for and a regular batch service model [26] with batch size K, where we set and for . A comparison of these three models is presented in Section 4.
The application of this model is as follows. There are sufficient cars at the boarding station on the transportation platform, such as ride-sharing or shared taxis. Customers with the same destination arrive at this platform according to a Poisson process. A customer who observes no waiting customers at his arrival point can decide the size of his group to share the service (or abandon the service), whereas other customers decide whether to join the collecting group. When a group is completed, the customers in the group ride the car and instantly depart from the boarding station. The car then joins a ‘service station’ [46] on the road. A service station is a single-server queue representing a road segment. We refer to this method to express traffic congestion on roads in terms of the queueing model proposed in [46]. The proposed model enables us to study strategic customers’ behavior by considering the trade-off between waiting time, traffic congestion, and cost.
3. Analysis
This section presents an analysis of the proposed model. We change the notation of in (1) in Section 2 to to emphasize the dependency on i. In addition, we refer to as the ‘best batch size’ when a tagged customer observes i complete batches. Furthermore, we introduce several notations. Let denote the maximum i such that it satisfies ; that is,
In addition, we let and denote the maximum and minimum i, respectively, such that they satisfy ; that is,
We also define a set that stands for the set of all possible best batch sizes where as follows:
One technical point in the analysis of this model is the derivation of the expected sojourn time for a tagged customer, which is related to his decision. As described in Section 2, this model constitutes a three-dimensional Markov chain; therefore, deriving the expected sojourn time depending on the three simultaneous states is necessary.
This can be calculated using a recursive procedure similar to that of the regular batch service model [26] by leveraging the book type form of the transition diagram in Figure 2; the states, wherein the number of customers in the incomplete batches is 0, are depicted as the black axis, and other states (i.e., some waiting customers exist in an incomplete batch) are expressed as pages that correspond to the batch sizes, and each page is connected to the axis. We can then easily determine that the transition on each page is equivalent to a regular batch service model [26] except for that each arrival rate is multiplied by the joining probability .
Lemmas 1 and 2 are implied from Theorems 4.1 and 4.2 in [26]. Here for the readability, we rewrite them and their proofs in our notations. We show Lemma 1 as follows:
Lemma 1.
A unique equilibrium strategy () exists, as
where .
Proof.
If an arriving customer who observes state joins the system, his sojourn time clearly becomes the sum of exponential distributions with parameter . This is because his decision is dominant; that is, his decision is not affected by the decisions of other customers. Therefore, we obtain
where
Subsequently, we consider an arriving customer who observes the state . Clearly, if . This is because the expected sojourn time of an arriving customer who observes state is longer than that of an arriving customer who observes state because the customer must wait for the next customer to arrive. In addition, we find that is an increasing function of i and tends to ∞ as (as we will describe in Lemma 3). Therefore, a unique exists such that . Based on the aforementioned discussion, we obtain the equilibrium joining probability as follows:
where
To calculate the threshold , we must derive the expected sojourn time conditional on each state. The procedure for deriving the expected sojourn time is provided in Lemma 2.
Lemma 2.
Proof.
Notably, when the batch size for the next batch is determined, it cannot be modified until the batch becomes complete. In addition, the expected sojourn time of a tagged arriving customer depends only on the number of complete batches and the number of waiting customers of an incomplete batch and is not affected by the batch sizes, except for the incomplete batch. Therefore, this lemma becomes equivalent to Theorem 4.2 in [26] when we regard l as a constant batch size K.
Specifically, (5)–(7) can be shown naturally in the first-step analysis. For (8), can be expressed as follows:
where and are Erlang-i and Erlang- independent random variables with rates and , corresponding to the total service time of the present complete batches and the completion time of the current incomplete batch, respectively, as described in [26]. Then, we obtain the following transformation:
where represents the number of Poisson events with a rate during Erlangi time, that is, with rate . We can observe that
holds based on tedious calculations. □
Based on Lemma 2, the following lemmas hold:
Lemma 3.
Regarding in Lemma 2, the following properties hold:
- (i)
- is a strictly increasing function of i.
- (ii)
- is a strictly decreasing function of k.
- (iii)
- is a strictly increasing function of l.
- (iv)
- .
- (v)
- .
- (vi)
- is a strictly decreasing function of i for .
Proof.
In this lemma, (i), (ii), and (iv) correspond to (i)–(iii) in Theorem 4.2 in [26]. As shown, (ii)–(v) hold true for (8). The definition in (9) immediately yields (i). Regarding (vi), we obtain the following relationship from (9)–(11):
Owing to the definition of in the proof of Lemma 2, we show that is a strictly decreasing function of i for any l, which supports (vi). □
Lemma 4.
The thresholds in Lemma 1 are
Proof.
The monotonicity of for i–that is, (i) in Lemma 3 yields the result. □
Next, we derive the best batch size, that is, . We show Lemma 5.
Lemma 5.
holds if .
Proof.
For any l such that , and , that is, and clearly hold from the definition. Considering the monotonicity of with respect to i ((vi) in Lemma 3), it is clear for that holds, i.e., holds.
Similarly, for any l such that , and that is, and clearly hold from the definition. Therefore, based on the monotonicity of (vi) in Lemma 3, holds true for .
By combining the aforementioned discussions, we obtain Lemma 5. This lemma becomes important for the proofs of Theorem 1 and Lemma 6. □
Based on Lemma 5, Theorem 1 can be shown as follows:
Theorem 1.
can be calculated by Algorithm 1.
| Algorithm 1: Calculate . |
| Input: (from Lemma 2) Output: calculate :
|
Proof.
A brief explanation of Algorithm 1 is as follows: From lines 1 to 21, , and are calculated in ascending order from . First, in the while statement in lines 3 to 6, the values of for each l are memorized. Notably, definitely exceeds the upper bound R in some i because of in Lemma 5; therefore, the while statement is guaranteed to finish in a finite number of times. Subsequently, the best batch size, conditional on i is determined by the definition of (1) in lines 8 and 16. The minimum i with the best batch size is ; that is, accepts 0 (as in line 10). Whenever holds, and are determined (lines 12, 13, and 18) by Lemma 5, which guarantees that discontinuous i do not accept the same best batch size. The maximum i that satisfies , , is calculated when reaches 0, as shown in line 17. Finally, from lines 22 to 25, the set of all the possible best batches where , i.e., , is determined in descending order from . □
Additionally, for the best batch sizes conditional on i, the following lemma holds:
Lemma 6.
If is a strictly increasing function of l, becomes a non-decreasing function of i (except when , that is, the customer balks).
Proof.
This fact is demonstrated based on (vi) in Lemmas 3 and 5. It follows from the definition that , evidently, holds for . Considering is positive because of the assumption that is a strictly increasing function of l, is also a strictly decreasing function of i. Therefore, always holds for (C is a constant). Therefore, is never the best batch size, conditional on . Additionally, holds if from Lemma 5. Therefore, this lemma holds. This lemma is mentioned in the numerical experiment part in Section 4. □
In general shared-type transportation, customers in the same vehicle (batch) share the fee; therefore, it is natural that is a strictly increasing function (i.e., is a strictly decreasing function). Lemma 6 suggests that it is individually optimal for customers to make larger batches as they find a larger number of complete batches upon arrival. Lemma 6 will be mentioned in the numerical experiment part, in Remark 1, and the intuitive insight for this result in connection with the shared-type transportation examples will be described.
Based on the outputs from Algorithm 1, we can reconstruct the Markov chain for this model with reduced state space as the following theorem:
Theorem 2.
Provided that all customers adopt the threshold-type equilibrium strategy in Lemma 4, the Markov chain of our model can be defined under the reduced state space , where
and the transition rate from the state to , which is denoted by , is defined as
Proof.
We can construct the reduced state space, , by using the results of , and from Algorithm 1. Once a batch is completed (the capacity is satisfied), the batch has to stay in the system only for the length of Erlang distribution of rate and shape which is determined by the number of complete batches in the system at the moment the batch is completed (since any interruption is not allowed in this model). Hence, the state such that and the state for are never reached; therefore, we can remove them from the analysis. It should be noted that the state , i.e., , is a special state since definitely holds if holds because of the aforementioned definition.
The definition of can be explained as follows. The set stands for the set of all the possible best batch sizes within from the definition. The transition , i.e., the arrival of the first customer for a batch, is possible only within , by rate , from Lemma 5. The arrival of customers except for first-arriving customers to the state under can occur for . The batch completion, i.e., the transition , can occur as well. Finally, the service completion with rate occurs where , i.e., . □
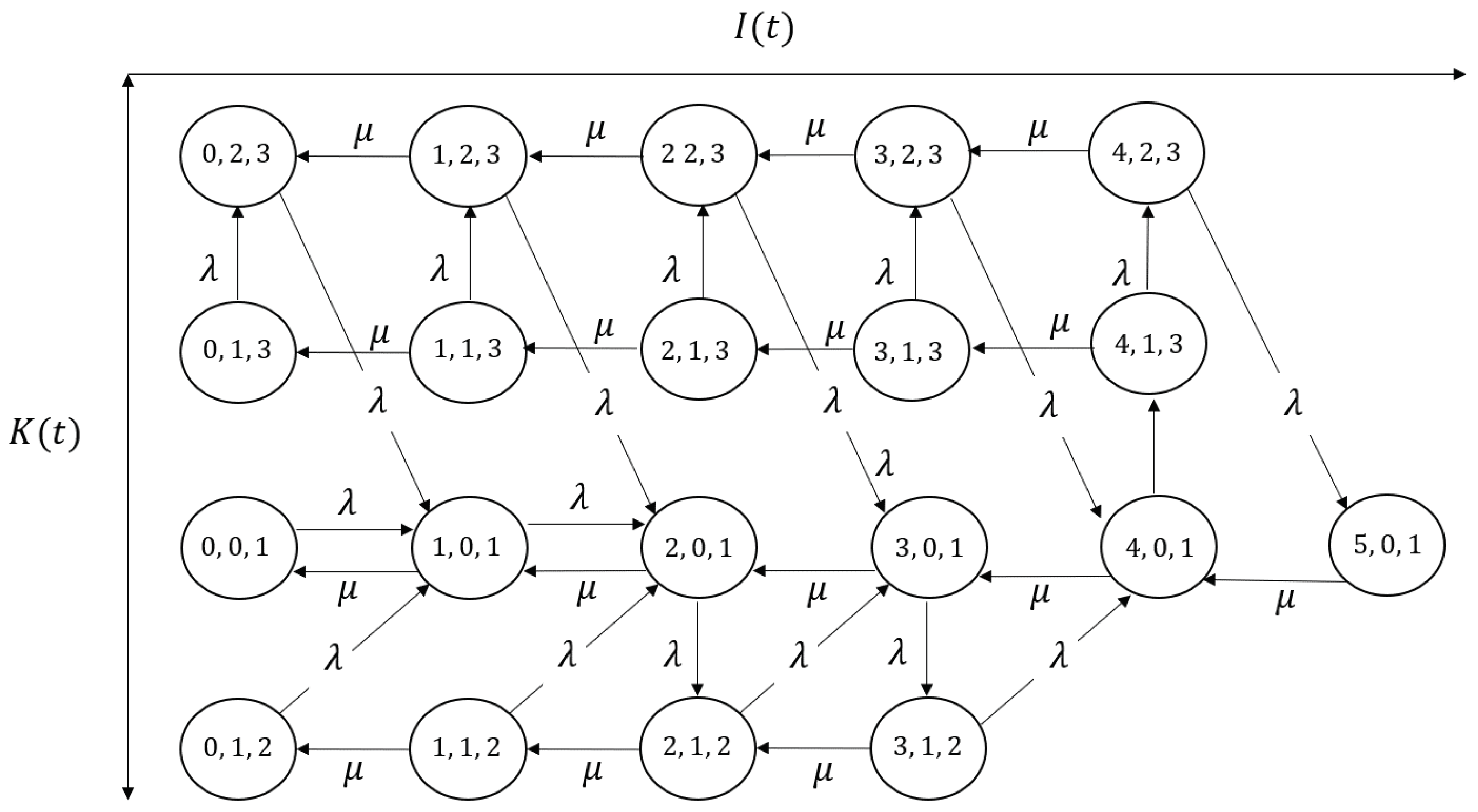
We here show some examples for the reconstructed transition diagrams with the state space as follows:
Figure 3 shows the transition diagram in which , and (thus, , , ).
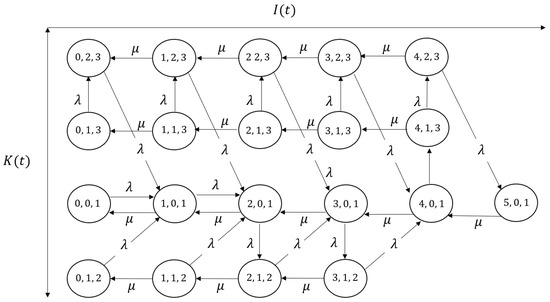
Figure 3.
The reduced transition diagram for , , .
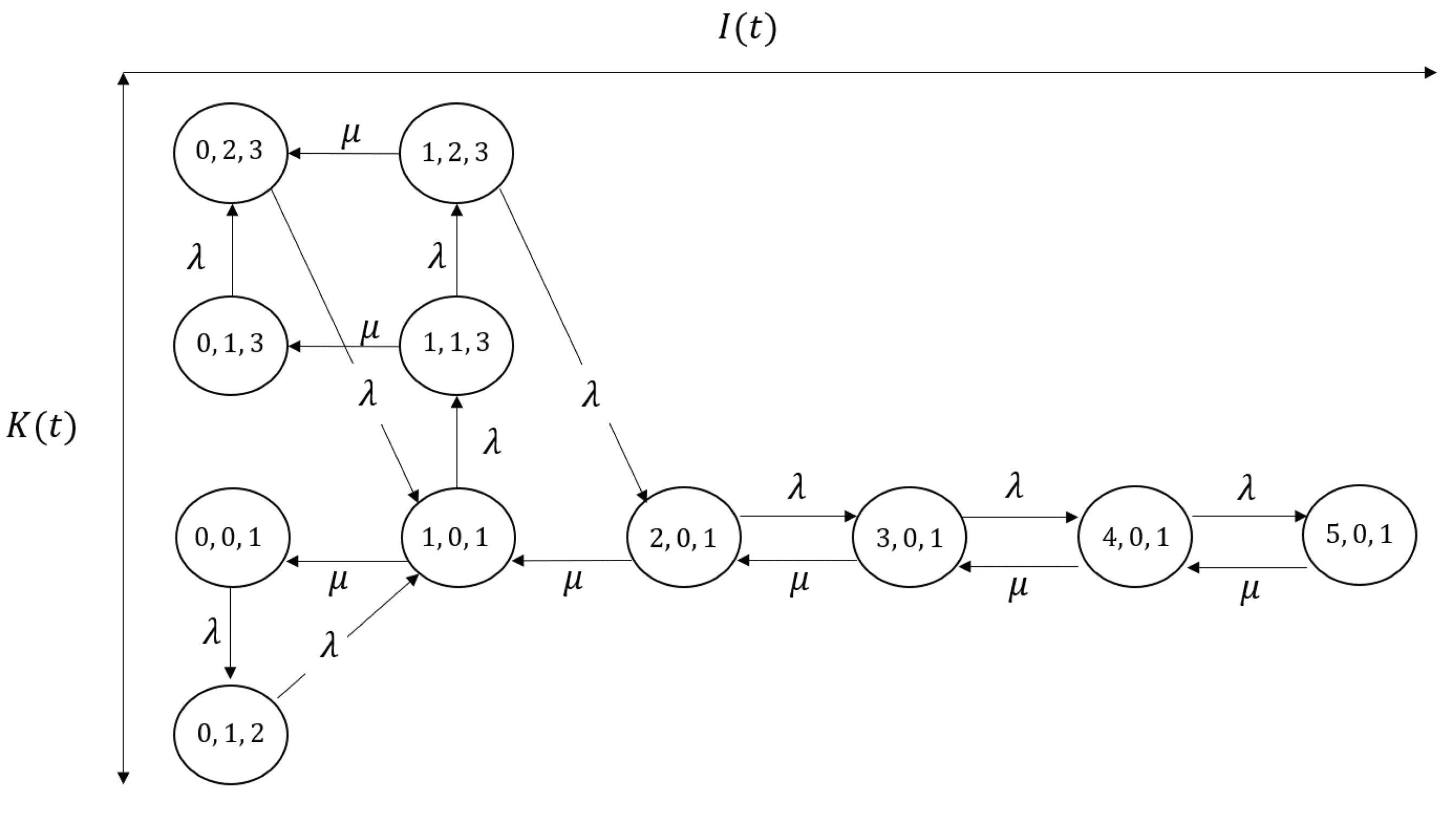
Figure 4 shows the transition diagram in which , and (thus, , , ).
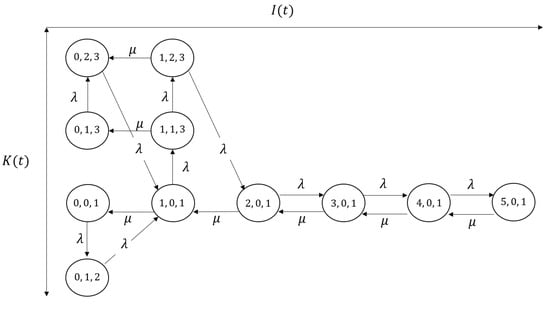
Figure 4.
The reduced transition diagram for , , .
It should be mentioned that our algorithm in Theorem 1 enables us to consider the necessary and sufficient size of the transition diagram. We can also consider the Markov chain only by deriving and the maximum best batch size as well; however, by utilizing Theorem 2, we can remove the unnecessary states (i.e., all the states such that are removed in ), for example, in Figure 3 and and in Figure 4. The number of states decreases from 21 to 20 in Figure 3 and from 21 to 11 in Figure 4. It is expected that the state space in our Markov chain becomes extreme large as becomes larger. Therefore, the calculation of in Algorithm 1 is crucial from the perspective of the calculation cost (especially for preventing memory error). In addition, the rigorous proof in Lemma 5 also improves computational tractability. We can construct and consider the corresponding transition rates between the states only by , and ; therefore, we do not consider whether the transition occurs for every i after deriving all . When is large and the differences between become larger, Lemma 5 is effective to construct easily.
The Markov chain has a finite state space. Therefore, we can easily obtain the numerical values of the steady state probabilities:
which are utilized to calculate the performance measures. First, we present Theorem 3.
Theorem 3.
Let denote the random variables for the batch size of a newly generated batch. Then, and its probability function are expressed by
where
respectively.
Proof.
A new batch is generated when a customer joins the state according to the Poisson process at rate . Therefore, the total number of newly generated batches per unit time can be calculated as , which is equivalent to the total rate of the transition from state to . Additionally, the total number of customers served per unit time is calculated by . The latter divided by the former can clearly be the expected batch size. Similarly, the probability function is derived. □
In addition, we present the following theorem:
Theorem 4.
Let V denote a random variable for the number of newly generated batches per unit time. Then, is given by
Proof.
The total throughput for the transition in the number of waiting customers is equivalent to . □
Notably, reflects traffic congestion on the road. Subsequently, we present Theorem 5.
Theorem 5.
The expected number of customers in the system is given as follows:
Proof.
The batch size of each position is not i.i.d. distributed (because the best batch sizes are state-dependent values on i); therefore, calculating the expected number of customers is difficult in the system directly. However, the Poisson arrivals see time averages (PASTA) property holds because customers arrive at the system according to a Poisson process. We can then calculate the expected sojourn time of customers by conditioning , using the steady state probabilities of joining customers as follows:
By applying Little’s law, the results are clear. □
Based on the aforementioned discussion, we consider several performance measures in Theorem 6.
Theorem 6.
The throughput (TH), social welfare (SW), and monopolist’s revenue (MR) are given by
Here, , , and are the expected number of customers served per unit time, the difference between the generated reward and time cost per unit time, and the sum of fees that the monopolist (administrator) can obtain per unit time, respectively.
The flow of the analysis in this section can be summarized as follows. First, the equilibrium strategy of the proposed model is given by Lemma 1. Specifically, the equilibrium strategy can be calculated by using the results of Lemmas 2 and 4. Lemma 3, i.e., the properties of , is used to prove Lemmas 4 and 5. Lemma 5 provides an important property of the best batch size (and it will be mentioned in Remark 6 with intuitive interpretations in the numerical experiment section). Then, Theorem 2 gives the reconstructed Markov chain, which has the necessary and sufficient number of the states, for the proposed model provided that every customer adopts the equilibrium strategy by using the outputs of Algorithm 1 in Theorem 1. Finally, some performance measures for the reconstructed Markov chain are derived in Theorems 3–6.
4. Numerical Experiments
This section presents numerical results on the performance measures in the previous section and discusses the behavior of the proposed model. Here, we introduce the notions of ‘fixed fee’ and ‘sharing fee’. A fixed fee refers to the fee that all customers pay to receive the service, regardless of their batch size. The sharing fee refers to the fee for a batch, that is, the fee for a person is the sharing fee divided by the batch size. Let f and s denote fixed and sharing fees, respectively. In addition, the maximum batch size (corresponding to the capacity of cars in ride-sharing and shared taxis) is assumed to be m. Then, if customers belong to a batch of size l, they must pay (). Considering these settings, the reward for a batch service of size l is given by
In this section, the detailed parameter settings are presented in the captions of each graph. We compared the proposed model (referred to as the variable batch service model in the following section to clarify the distinction) with the regular (i.e., fixed) batch size model [26] of size K. If , this becomes equivalent to Naor’s model [23]. As mentioned in Section 3, the variable batch service model encompasses Naor’s and the regular batch service models.
Notably, if no customers join the system according to the parameter settings, we assume that , , and become 0. First, we note the following remark from Lemma 6:
Remark 1.
becomes a non-decreasing function (except for the case of ; that is, the customer balks in the setting of fees, that is, .
Table 1 summarizes the numerical results for the best batch size conditional on i, that is, the number of complete batches in the system when a tagged first-arriving customer arrives. Notably, 0 indicates that the best option for the customer is to balk. Clearly, the best batch size increases as i increases, as mentioned in Remark 1. This result leads us to presume that to prevent more serious traffic congestion, it is individually optimal for customers to tend to create large batches while sharing fees with other customers if the system is crowded.

Table 1.
Best batch sizes conditional on i under , .
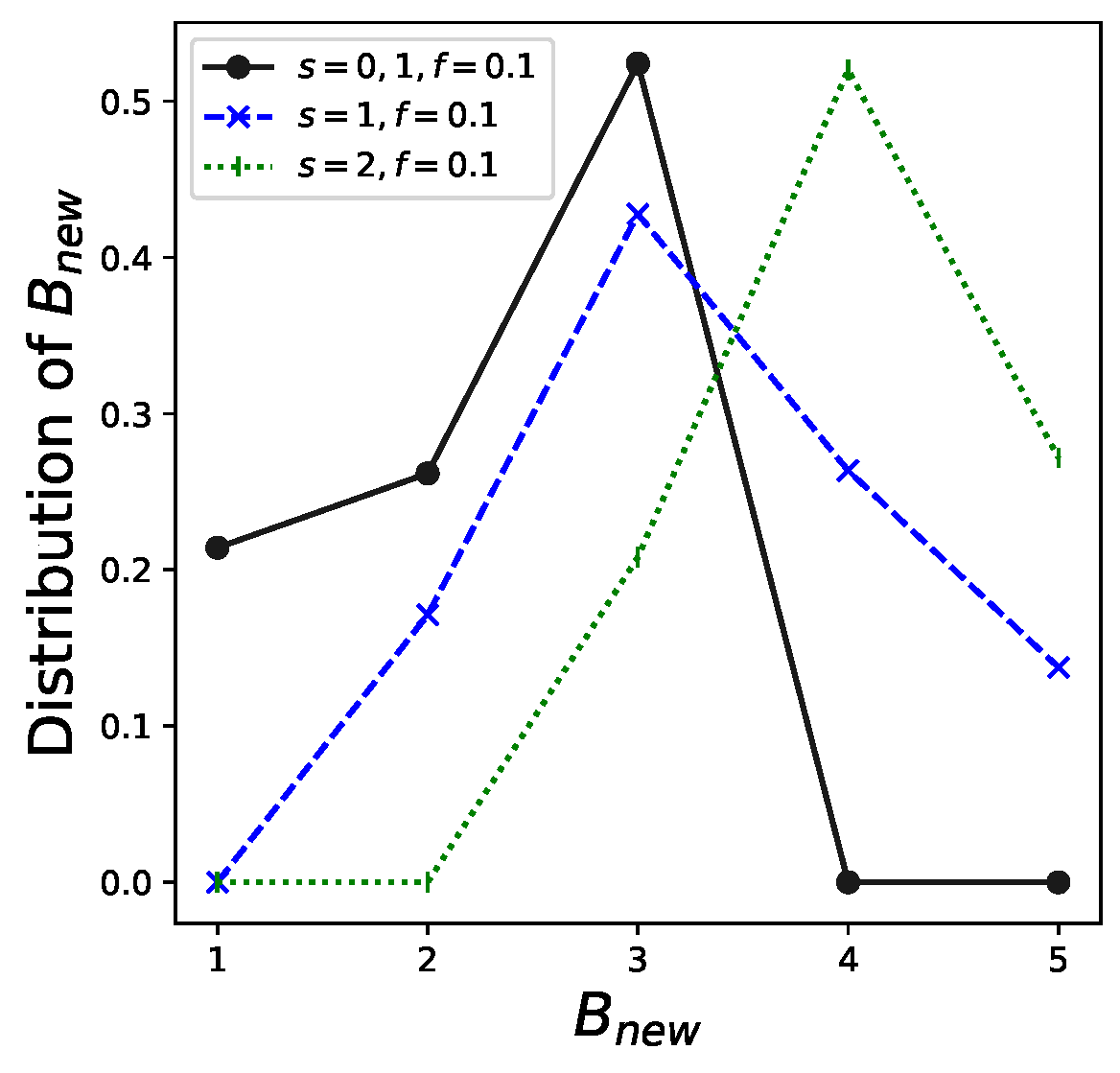
In addition, the distribution of , that is , which is given by Theorem 3, is shown in Figure 5. We depict examples of and . The other parameter settings are the same as those in the example in Table 1. These results can be utilized for real-world management of this system. For example, the probabilities that are 0 when and . Therefore, three is sufficient for the capacity of cars, although the current setting for the maximum capacity of cars is . This finding enables the system administrator to reduce excessive costs.
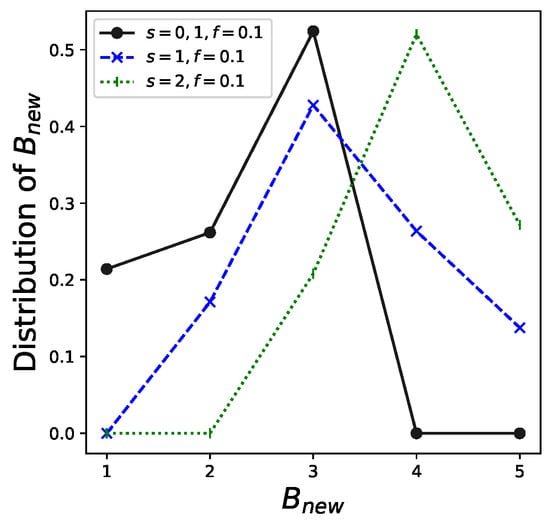
Figure 5.
Distribution of under , .
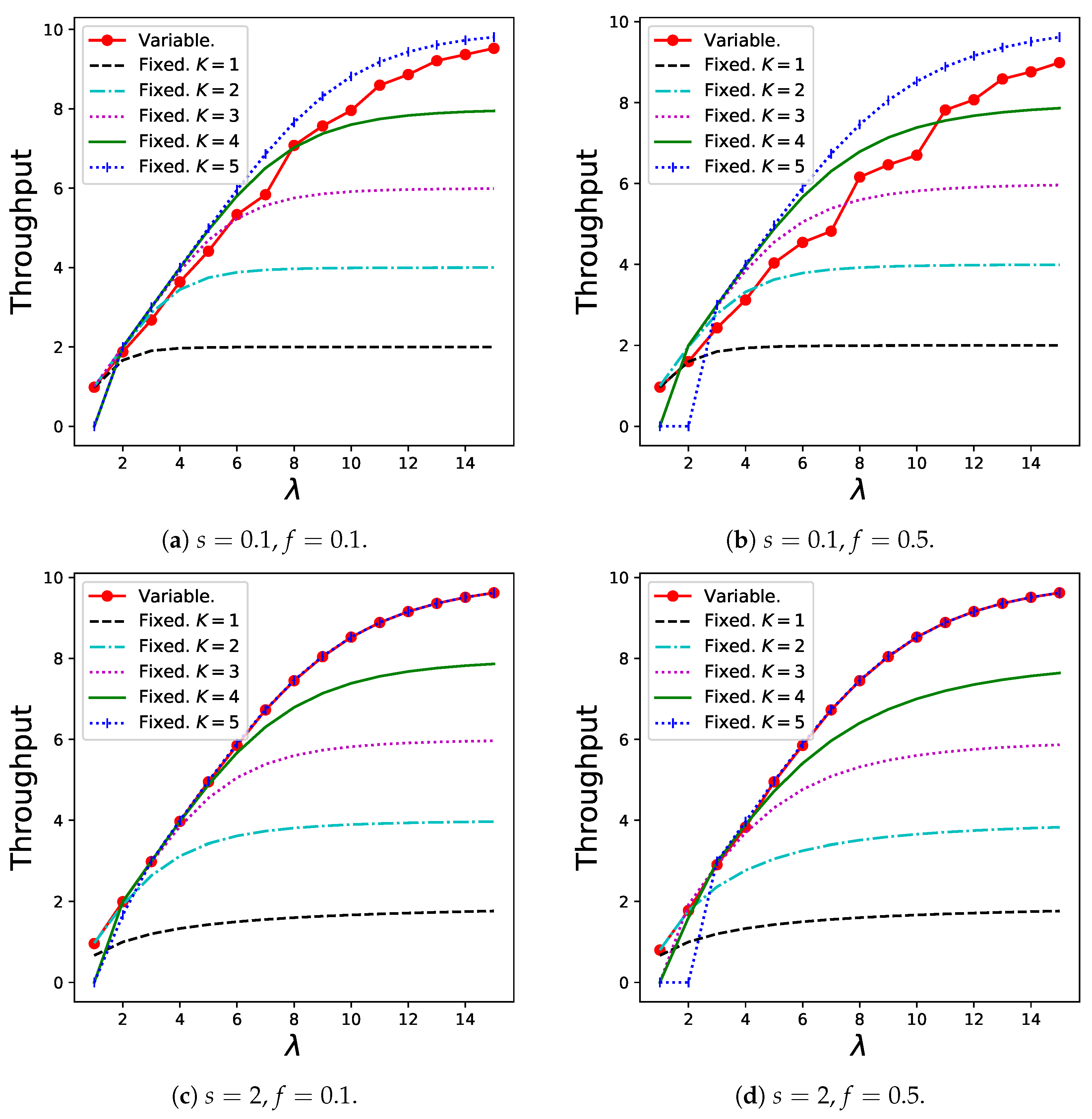
The results for the throughput in Theorem 6 are shown in Figure 6. Generally, the variable batch service model shows the best results for any arrival rate unless s is not extremely small because customers can choose the ideal batch sizes depending on , which prevents excessively long waiting times or traffic congestion that results in customers joining the system. Thus, the variable model is more robust to changing customer demands than the regular batch service model.
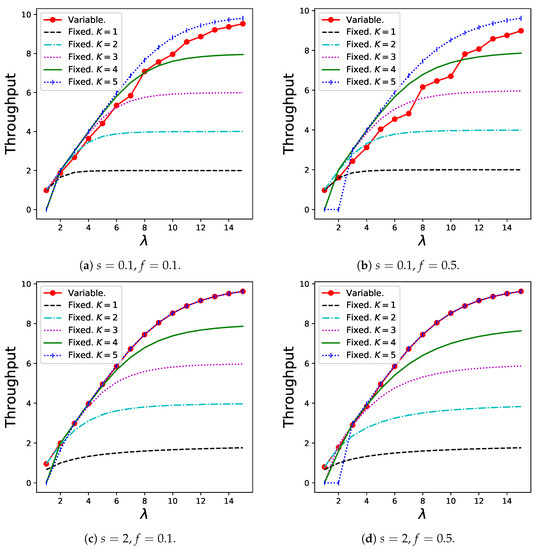
Figure 6.
Throughput for the variable batch service model under , , and that for the regular batch service model under , .
The reason for the poor performance of the variable batch service model when s is relatively low (Figure 6a,b) can be explained as follows: Customers tend to create small batches because the sharing fee that can be saved by creating a larger batch is less compared to the long expected waiting time in this case. This trend is presented in Table 1. However, if a considerably large number of small batches are generated, the congestion in the queue becomes serious, resulting in the balking of many customers. Therefore, a relatively large K (for example, ) is more desirable in these graphs from the throughput viewpoint.
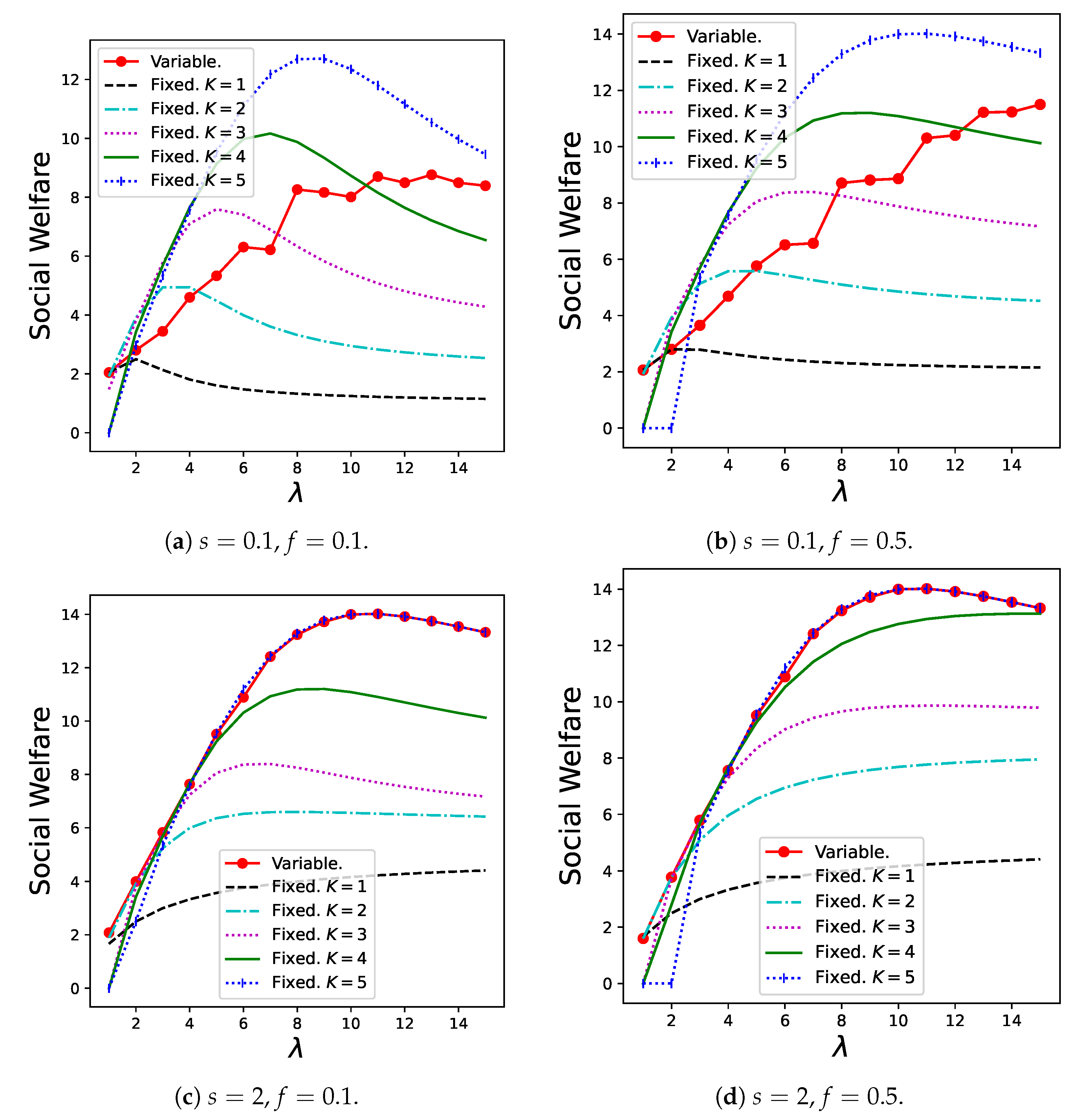
Figure 7 shows the results for social welfare, , in Theorem 6. The variable batch service model exhibited the best performance when s as well as are relatively high. When , the variable batch service model shows stable performance for any , whereas the regular batch service model with small batch sizes always shows poor performance, and the regular batch service model with large batch sizes shows poor results within the low zone. Therefore, the variable batch service model can be considered robust against demand fluctuations when s is large.
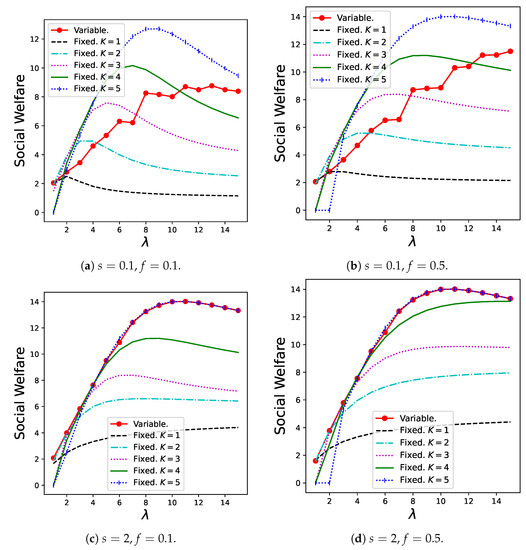
Figure 7.
Social welfare for the variable batch service model under , , and that for the regular batch service model under , .
However, we note that the variable batch service model shows very poor performance when s is low, because batches are generated excessively and induce congestion in the system. In other words, a system where customers behave individually does not necessarily lead to a socially optimal state. Therefore, as a practical message, it is important for an administrator to set s to a relatively high value to avoid this situation.
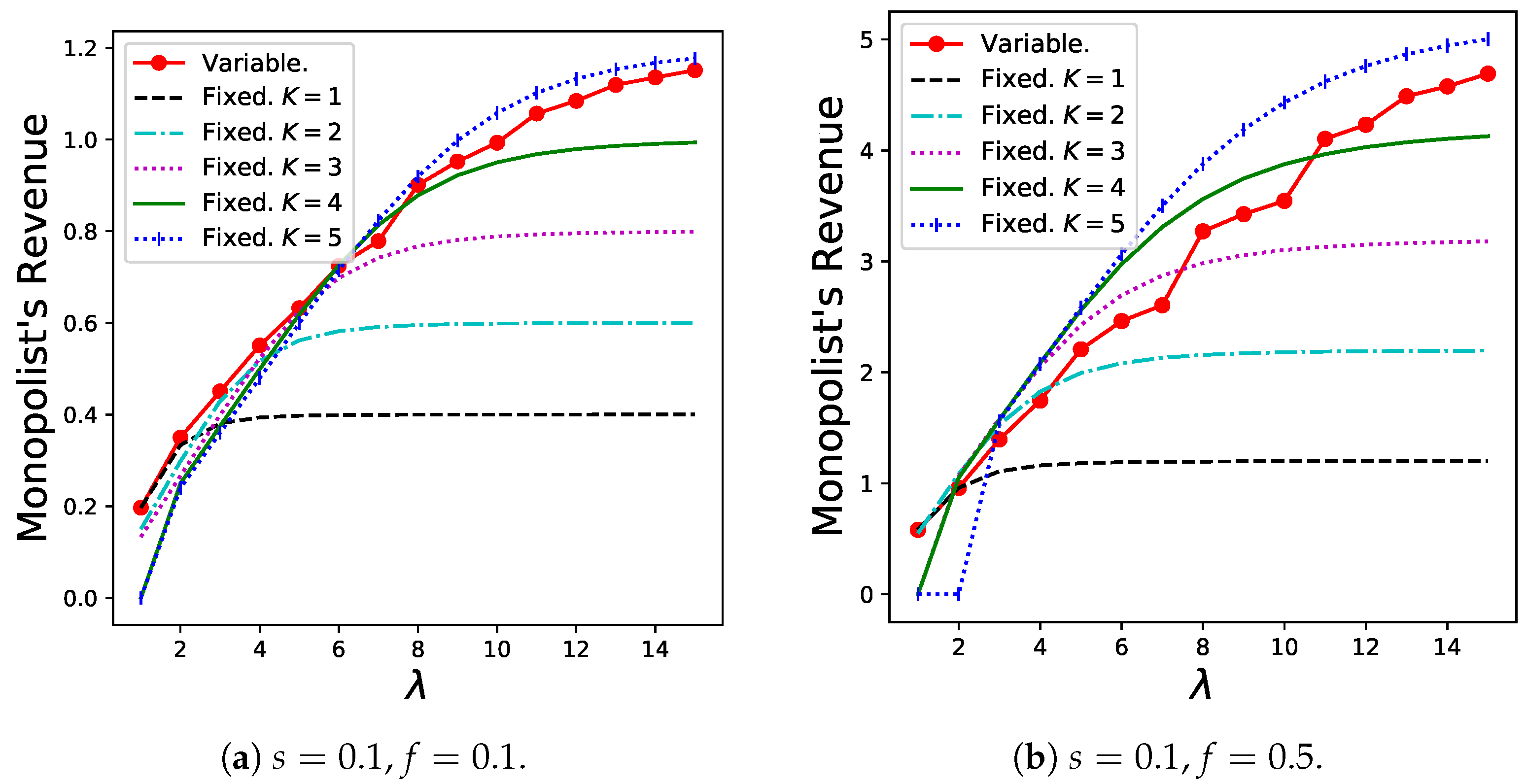
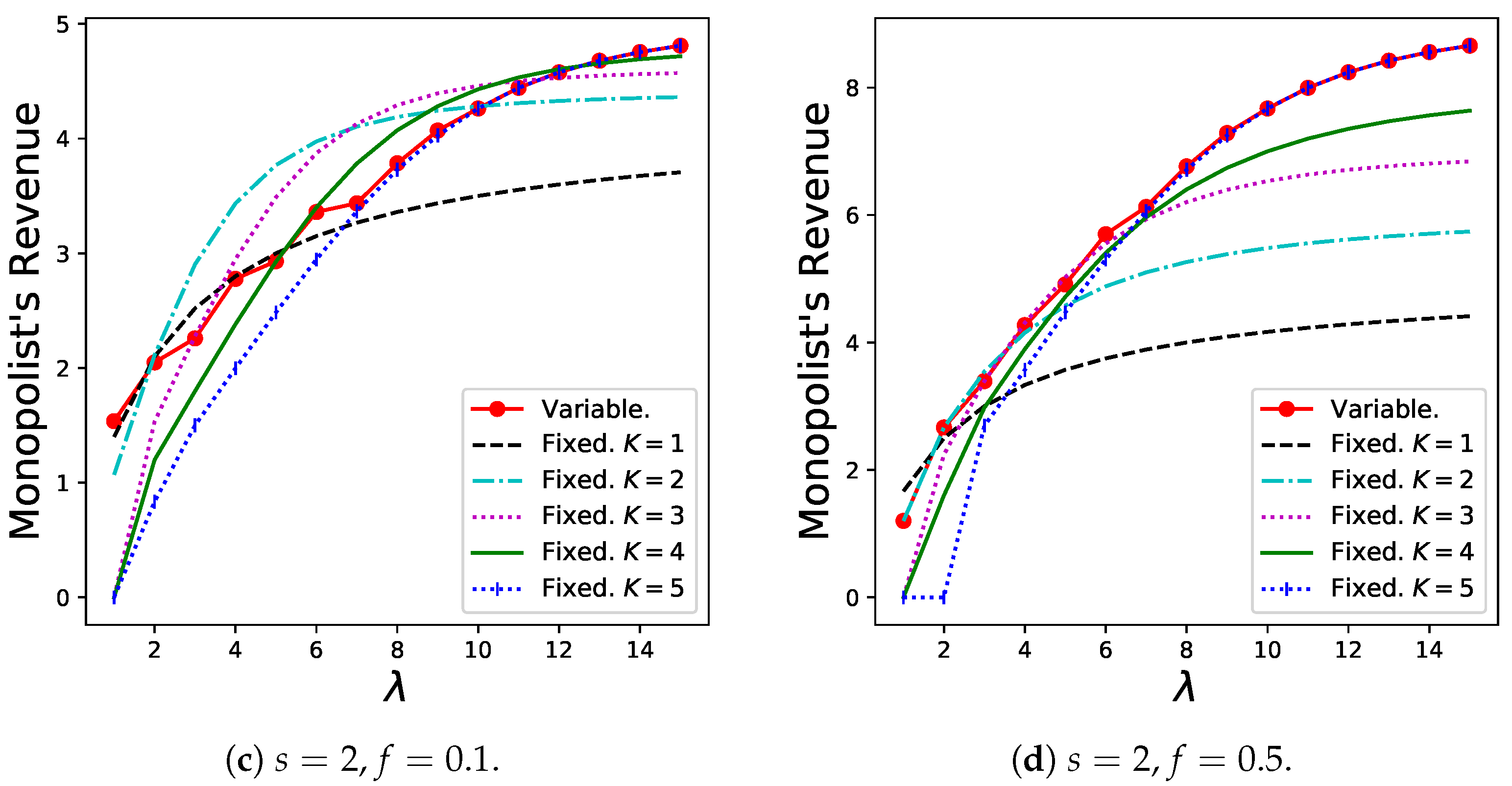
The results for the monopolist’s revenue, , are shown in Figure 8. The variable batch service model exhibits good performance as long as both s and f are relatively high (as in Figure 8d). However, especially when f is extremely small, the revenue of the variable batch service model decreases slightly.
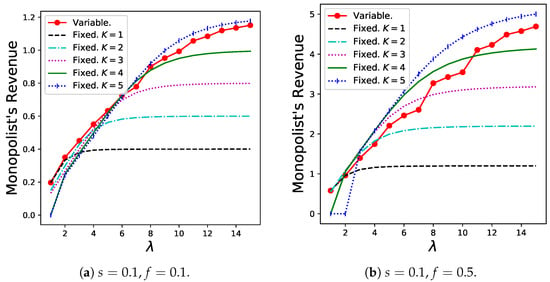
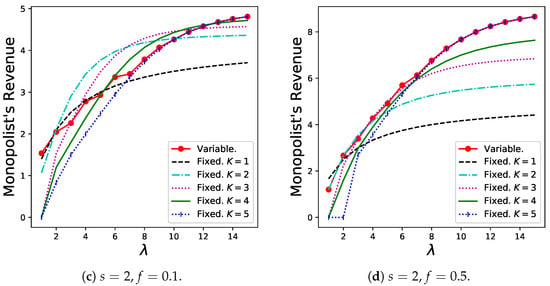
Figure 8.
Monopolist’s revenue for the variable batch service model under , , and that for the regular batch service model under , .
The reasons for these results are as follows: In the variable batch-service model (compared with the regular batch service model), the following two effects were observed:
- (i)
- The increase in the throughput.
- (ii)
- The decrease in the number of batches in the system.
Effect (i) is presented in Table 1. Effect (ii) occurs because customers create larger batches if many batches already exist in the system to prevent serious congestion in the queue. When the fixed fee is low, the dominance of the total revenue is based only on the number of batches in the system that corresponds to the sharing fee. Specifically, the numerical results for the number of newly generated batches per unit time for the same parameters are shown in Figure 9. Therefore, in this case, effect (ii) increases, and revenue decreases. When a fixed fee is imposed to some extent, effect (i) increases as the arrival rate increases, and the total amount of fixed fees, which is proportional to the throughput, increases. Therefore, the administrator must set f as well as s to some high value.
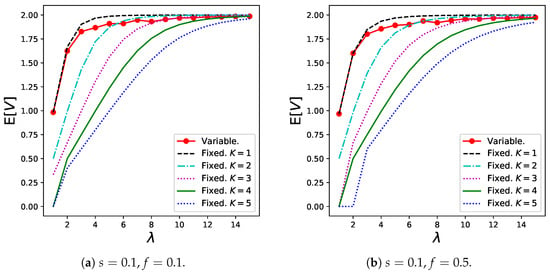
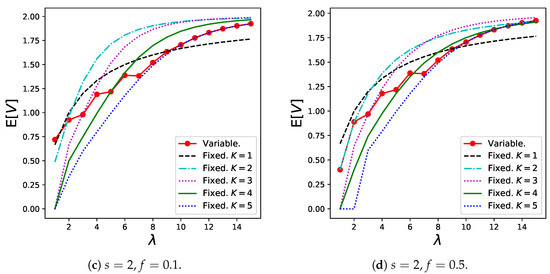
Figure 9.
for the variable batch service model under , , and that for the regular batch service model under , .
Furthermore, it is worth noting that the variable batch service model is more suitable to optimize all of , , , simultaneously, compared to the regular batch service model, when the fees are properly set high ( and in this example). See Figure 6d, Figure 7d, and Figure 8d. For and , the variable batch service model and the regular batch service model with show the best performances when . For , the variable batch service model and the regular batch service model with also show the best performances when . On the other hand, when , the variable batch service model and the regular batch service model with take better values in than that of the regular batch service model with . These results for the regular batch service model imply that the monopolist should set the batch size K smaller to maximize compared to the batch size which maximizes and . However, as has been shown, the variable batch service model enables all , , and to be the best values simultaneously as long as the fees are set high properly.
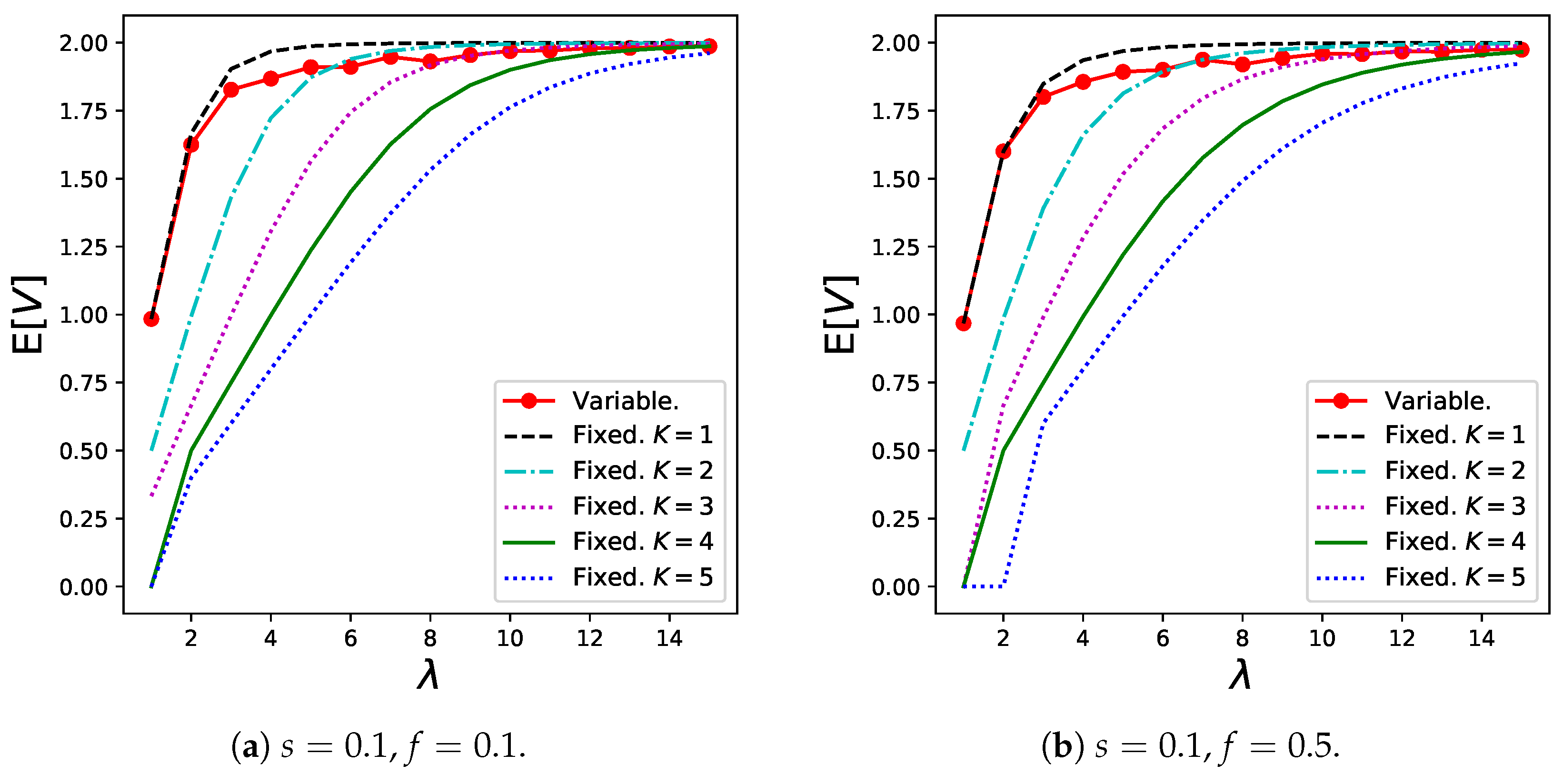
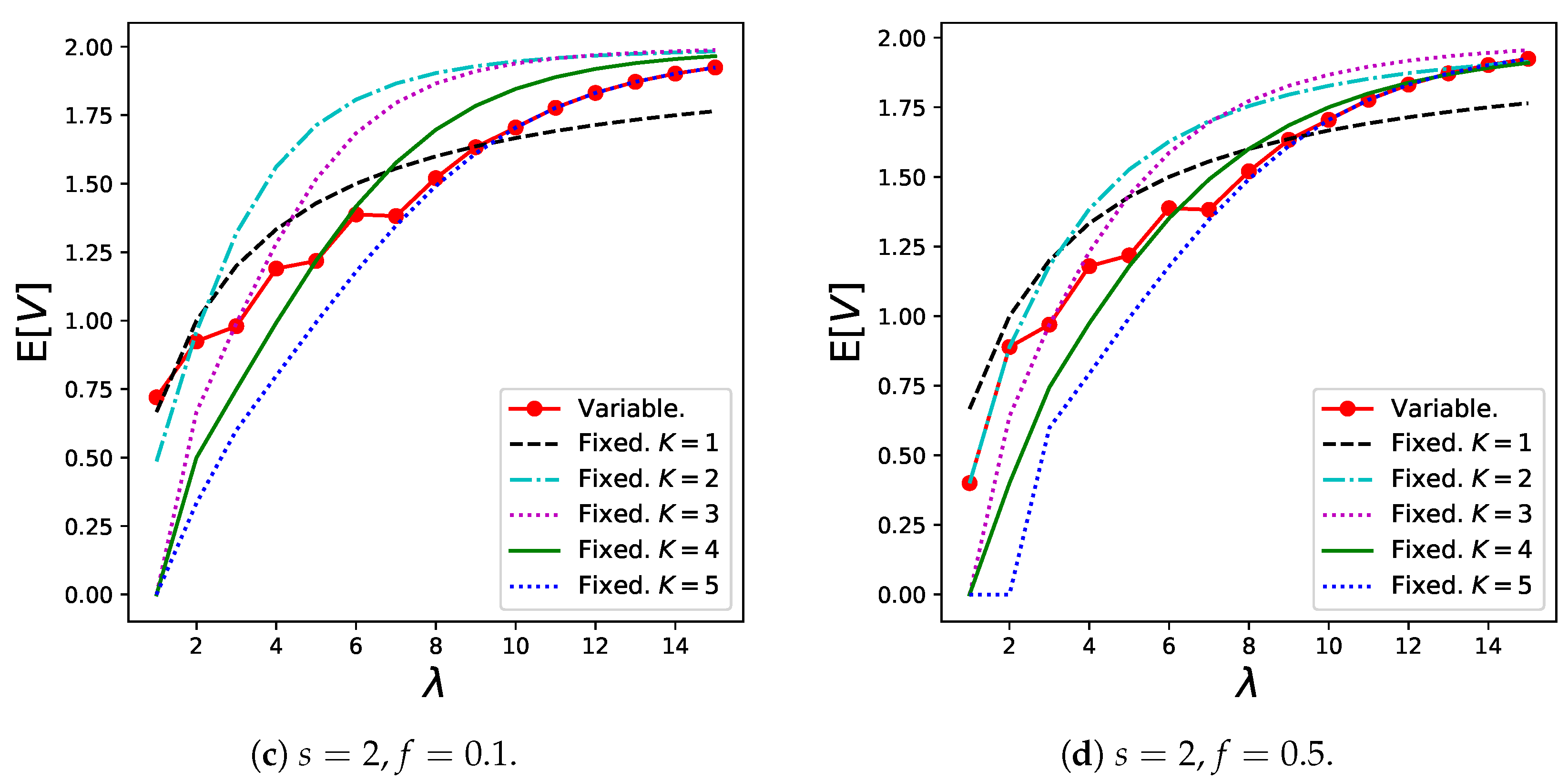
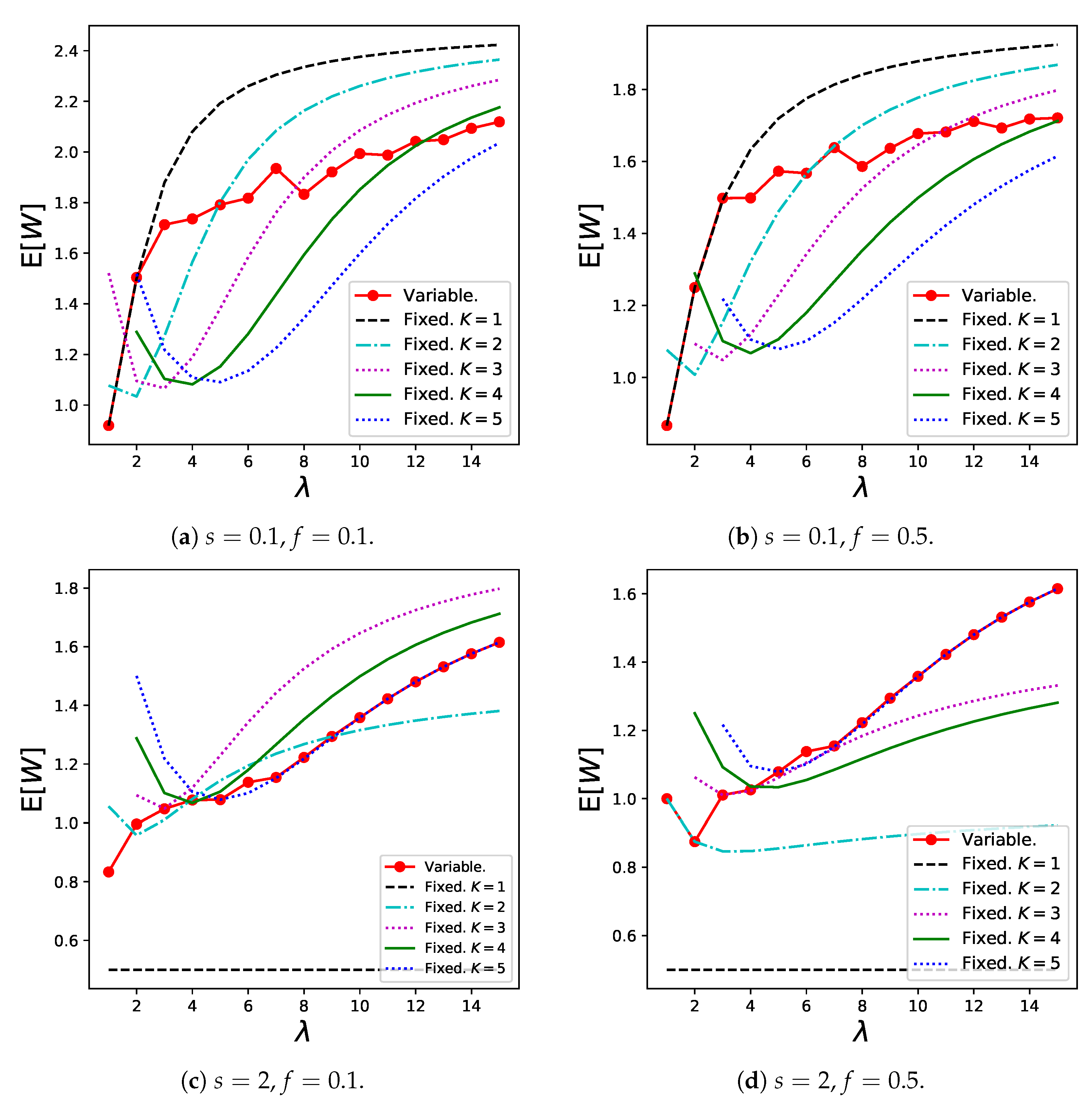
In addition, Figure 10 shows the numerical results for , which are given by (16). The results for the variable batch service model generally increase as increases, whereas most results for the regular batch service model have minimum points. This is because customers can reduce their batch sizes to prevent extremely long waiting times when the arrival rate is low.
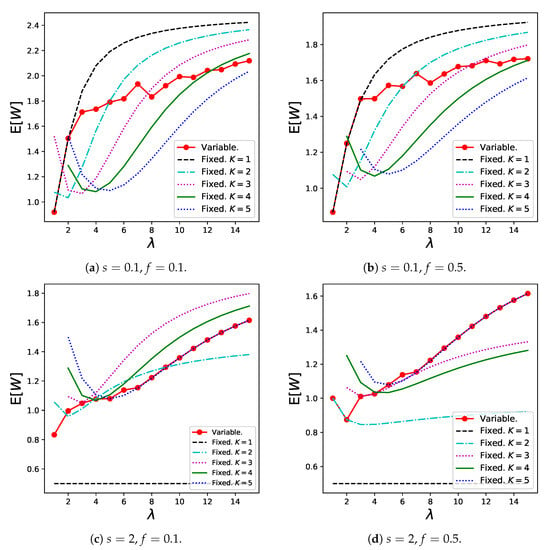
Figure 10.
for the variable batch service model under , , and that for the regular batch service model under , .
Notably, in the variable batch service model is lower than that in the regular batch service model in which and are close to those in the variable batch service model under the specific parameter setting, for example, when in Figure 6d, Figure 7d, and Figure 10d, respectively. Therefore, from the waiting time perspective, a variable batch service model is preferred in this case as well. On the contrary, the regular batch service model with shows the best performance when from the perspective of and the other three performance measures.
We note that the tendency of the results of does not necessarily coincide with that of in Figure 7. This is because does not reflect information of balking customers. For example, the results for within high zone in Figure 7d show extremely small values because the dominant customers abandon the service (as can be confirmed in Figure 6d). Therefore, a small does not always imply superiority from a system point of view. However, the results for are valuable from a customer’s perspective. The proposed model is useful in obtaining numerous performance measures from various perspectives.
5. Conclusions
In this study, we proposed a variable batch service model in which first-arriving customers can select the batch size flexibly to maximize their individual utility. We formulated this model as a three-dimensional Markov chain and created a book-type transition diagram. We then demonstrated several properties of the sojourn time of a tagged customer and the best batch sizes, conditional on the number of complete batches in the system. Based on these properties, we proposed an effective algorithm to construct a necessary and sufficient size of state space for the Markov chain provided that all customers adopt the threshold-type equilibrium strategy.
Furthermore, we proved that the best batch size, provided that a tagged customer observes i complete batches in the system upon arrival, is a non-decreasing function for i if the reward for the completion of a batch service with size l is an increasing function of l; in other words, the fee decreases as the batch becomes larger. This implies that to prevent more serious traffic congestion, creating large batches while sharing fees with other customers is individually optimal for customers if the system is crowded.
In the numerical experiment, we showed several results on performance measures, throughput, social welfare, monopolist’s revenue, and expected sojourn time, and compared them with the regular batch service model [26]. The proposed model showed better performance when the fixed and sharing fees were relatively high. In addition, the proposed model does not show extremely poor results for any arrival rate as long as both fees are set in a well-balanced manner compared to the regular batch size model. This indicates that the present model is a robust model for the fluctuation of customer demand. Moreover, we showed that the introduction of the variable batch service model can lead to optimizing all of the throughput, social welfare, and monopolist’s revenue, simultaneously, compared to the regular batch service model when the fees were relatively high.
However, the proposed model performed poorly when fees were low. Therefore, a system in which customers select optimal batch sizes individually does not necessarily lead to a socially optimal state. Thus, it is important to set both fixed and sharing fees to some extent for the administrator in this system.
Further studies of the variable batch service model must consider the mechanism by which all customers (including non-first-arriving customers) can freely select their batch sizes. Analysis of this model is difficult; however, the change in performance is intriguing.
Author Contributions
Conceptualization, A.N. and T.P.-D.; methodology, A.N. and T.P.-D.; software, A.N.; validation, A.N. and T.P.-D.; investigation, A.N. and T.P.-D.; writing—original draft preparation, A.N.; writing—review and editing, T.P.-D.; supervision, T.P.-D.; project administration, T.P.-D.; funding acquisition, A.N. and T.P.-D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by JSPS KAKENHI Nos. 21K11765, 18K18006, and 23KJ0249, JST SPRING No. JPMJSP2124. In addition, this study was also funded by F-MIRAI: R&D Center for Frontiers of MIRAI in Policy and Technology, the University of Tsukuba, and Toyota Motor Corporation collaborative R&D center.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bailey, N.T. On queueing processes with bulk service. J. R. Stat. Soc. Ser. B 1954, 16, 80–87. [Google Scholar] [CrossRef]
- Sasikala, S.; Indhira, K. Bulk service queueing models-a survey. Int. J. Pure Appl. Math. 2016, 106, 43–56. [Google Scholar]
- Chaudhry, M.; Templeton, J.G. First Course in Bulk Queues; Wiley: Hoboken, NJ, USA, 1983. [Google Scholar]
- Dshalalow, J.H. On modulated random measures. J. Appl. Math. Stoch. Anal. 1991, 4, 305–312. [Google Scholar] [CrossRef]
- Dshalalow, J.H. A single-server queue with random accumulation level. J. Appl. Math. Stoch. Anal. 1991, 4, 203–210. [Google Scholar] [CrossRef]
- Neuts, M.F. A general class of bulk queues with Poisson input. Ann. Math. Stat. 1967, 38, 759–770. [Google Scholar] [CrossRef]
- Medhi, J. Waiting time distribution in a Poisson queue with a general bulk service rule. Manag. Sci. 1975, 21, 777–782. [Google Scholar] [CrossRef]
- Borthakur, A. A Poisson queue with a general bulk service rule. J. Assam Sci. Soc. 1971, 14, 162–167. [Google Scholar]
- Easton, G.; Chaudhry, M. The queueing system Ek/M(a,b)/1 and its numerical analysis. Comput. Oper. Res. 1982, 9, 197–205. [Google Scholar] [CrossRef]
- Medhi, J. Recent Developments in Bulk Queueing Models; Wiley Eastern: Mumbai, India, 1984. [Google Scholar]
- Powell, W.B. Stochastic Delays in Transportation Terminals: New Results in the Theory and Application of Bulk Queues. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 1981. [Google Scholar]
- Chaudhry, M.L.; Madill, B.; Briere, G. Computational analysis of steady-state probabilities of M/G(a,b)/1 and related nonbulk queues. Queueing Syst. 1987, 2, 93–114. [Google Scholar] [CrossRef]
- Pradhan, S.; Gupta, U. Analysis of an infinite-buffer batch-size-dependent service queue with Markovian arrival process. Ann. Oper. Res. 2019, 277, 161–196. [Google Scholar] [CrossRef]
- Cosmetatos, G.P. Closed-form equilibrium results for the M/M(a,∞)/N queue. Eur. J. Oper. Res. 1983, 12, 203–204. [Google Scholar] [CrossRef]
- Sim, S.; Templeton, J. Computational procedures for steady-state characteristics of unscheduled multi-carrier shuttle systems. Eur. J. Oper. Res. 1983, 12, 190–202. [Google Scholar] [CrossRef]
- Sim, S.; Templeton, J.G.C. Further results for the M/M(a,∞)/N batch-service system. Queueing Syst. 1990, 6, 277–286. [Google Scholar] [CrossRef]
- Chaudhry, M.L.; Gupta, U.C. Modelling and analysis of M/G(a,b)/1/N queue–a simple alternative approach. Queueing Syst. 1999, 31, 95–100. [Google Scholar] [CrossRef]
- Banerjee, A.; Gupta, U.C.; Chakravarthy, S.R. Analysis of a finite-buffer bulk-service queue under Markovian arrival process with batch-size-dependent service. Comput. Oper. Res. 2015, 60, 138–149. [Google Scholar] [CrossRef]
- Chaudhry, M.; Abhijit, D.B.; Sitaram, B.; Veena, G. A novel computational procedure for the waiting-time distribution (in the queue) for bulk-service finite-buffer queues with poisson input. Mathematics 2023, 11, 1142. [Google Scholar] [CrossRef]
- Briere, G.; Chaudhry, M. Computational analysis of single-server bulk-service queues, M/GY/1. Adv. Appl. Probab. 1989, 21, 207–225. [Google Scholar]
- Nakamura, A.; Phung-Duc, T. A moment approach for a conditional central limit theorem of infinite-server queue: A case of M/MX/∞ queue. Mathematics 2023, 11, 2088. [Google Scholar] [CrossRef]
- Pradhan, S.; Gupta, U.; Samanta, S. Queue-length distribution of a batch service queue with random capacity and batch size dependent service: M//1. Opsearch 2016, 53, 329–343. [Google Scholar] [CrossRef]
- Naor, P. The regulation of queue size by levying tolls. Econom. J. Econom. Soc. 1969, 37, 15–24. [Google Scholar] [CrossRef]
- Hassin, R.; Haviv, M. To Queue or Not to Queue: Equilibrium Behavior in Queueing Systems; Springer Science & Business Media: New York, NY, USA, 2003; Volume 59. [Google Scholar]
- Hassin, R. Rational Queueing; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Bountali, O.; Economou, A. Equilibrium joining strategies in batch service queueing systems. Eur. J. Oper. Res. 2017, 260, 1142–1151. [Google Scholar] [CrossRef]
- Bountali, O.; Economou, A. Equilibrium threshold joining strategies in partially observable batch service queueing systems. Ann. Oper. Res. 2019, 277, 231–253. [Google Scholar] [CrossRef]
- Bountali, O.; Economou, A. Strategic customer behavior in a two-stage batch processing system. Queueing Syst. 2019, 93, 3–29. [Google Scholar] [CrossRef]
- Nakamura, A.; Phung-Duc, T. Strategic customer behaviors in observable multi-server batch service queueing systems with shared fee and server maintenance cost. In Proceedings of the Performance Evaluation Methodologies and Tools, Online, 16–18 November 2022; Springer: Cham, Switzerland, 2023; pp. 3–13. [Google Scholar]
- Wang, Z.; Liu, L.; Shao, Y.; Chai, X.; Chang, B. Equilibrium joining strategy in a batch transfer queuing system with gated policy. Methodol. Comput. Appl. Probab. 2020, 22, 75–99. [Google Scholar] [CrossRef]
- Manou, A.; Economou, A. Equilibrium balking strategies for a clearing queueing system in alternating environment. Ann. Oper. Res. 2013, 208, 489–514. [Google Scholar]
- Canbolat, P.G. Bounded rationality in clearing service systems. Eur. J. Oper. Res. 2020, 282, 614–626. [Google Scholar] [CrossRef]
- Manou, A.; Economou, A.; Karaesmen, F. Strategic customers in a transportation station: When is it optimal to wait? Oper. Res. 2014, 62, 910–925. [Google Scholar] [CrossRef]
- Manou, A.; Canbolat, P.G.; Karaesmen, F. Pricing in a transportation station with strategic customers. Prod. Oper. Manag. 2017, 26, 1632–1645. [Google Scholar] [CrossRef]
- Logothetis, D.; Economou, A. The impact of information on transportation systems with strategic customers. Prod. Oper. Manag. 2023, 32, 2189–2206. [Google Scholar] [CrossRef]
- Czerny, A.I.; Guo, P.; Hassin, R. Shall firms withhold exact waiting time information from their customers? A transport example. Transp. Res. Part B Methodol. 2022, 166, 128–142. [Google Scholar] [CrossRef]
- Calvert, B. The Downs-Thomson effect in a Markov process. Probab. Eng. Inf. Sci. 1997, 11, 327–340. [Google Scholar] [CrossRef]
- Afimeimounga, H.; Solomon, W.; Ziedins, I. The Downs-Thomson paradox: Existence, uniqueness and stability of user equilibria. Queueing Syst. 2005, 49, 321–334. [Google Scholar] [CrossRef]
- Afimeimounga, H.; Solomon, W.; Ziedins, I. User equilibria for a parallel queueing system with state dependent routing. Queueing Syst. 2010, 66, 169–193. [Google Scholar] [CrossRef]
- Chen, Y.; Holmes, M.; Ziedins, I. Monotonicity properties of user equilibrium policies for parallel batch systems. Queueing Syst. 2012, 70, 81–103. [Google Scholar] [CrossRef]
- Wang, A.; Ziedins, I. Probabilistic selfish routing in parallel batch and single-server queues. Queueing Syst. 2018, 88, 389–407. [Google Scholar] [CrossRef]
- Logothetis, D.; Economou, A. Routing of strategic passengers in a transportation station. In Proceedings of the Performance Engineering and Stochastic Modeling, Online, 9–10 and 13–14 December 2021; Springer: Cham, Switzerland, 2021; pp. 308–324. [Google Scholar]
- Nguyen, Q.H.; Phung-Duc, T. To wait or not to wait: Strategic behaviors in an observable batch-service queueing system. Oper. Res. Lett. 2022, 50, 343–346. [Google Scholar] [CrossRef]
- Afeche, P.; Mendelson, H. Pricing and priority auctions in queueing systems with a generalized delay cost structure. Manag. Sci. 2004, 50, 869–882. [Google Scholar] [CrossRef]
- Li, Q.; Guo, P.; Wang, Y. Equilibrium analysis of unobservable M/M/n priority queues with balking and homogeneous customers. Oper. Res. Lett. 2020, 48, 674–681. [Google Scholar] [CrossRef]
- Van Woensel, T.; Vandaele, N. Modeling traffic flows with queueing models: A review. Asia-Pac. J. Oper. Res. 2007, 24, 435–461. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).