1. Introduction
Evaluating the accomplishments of students holds a central position within educational processes [
1]. This evaluation serves as a vital feedback mechanism for educators, students, parents, institutions, and policymakers, shedding light on the effectiveness of instruction quality [
2]. A significant role in this assessment landscape, driving educational reforms and policy changes, is played by large-scale assessments of students’ knowledge [
3]. Among these, national assessments have a pivotal role in shaping a country’s educational reforms [
4]. In this context, the focus of this discussion narrows down to the national assessments of mathematical knowledge. For the aforementioned reasons, it becomes of paramount importance to fully understand which factors might influence students’ achievements.
By conducting predictive investigations, it becomes feasible to furnish strategic insights concerning the quality of teaching and learning. Such studies offer the means to assess the degree to which variables forecast educational results [
5,
6]. Notably, predictive studies serve as valuable tools for comprehending the impact of factors such as school atmosphere, teaching methodologies, and individual student attributes (such as gender, socio-economic status, etc. [
5]). The findings yielded by predictive studies hold potential utility for policymakers, informing their decisions within educational policies [
6].
Despite the significance of predictive studies aimed at comprehending the factors influencing students’ achievements in mathematics, it should be noted that the matter of how to assess students’ knowledge remains unresolved. For example, policymakers might focus solely on students’ performance in standardized (national) assessments of knowledge, or conversely, on teacher-assigned grades. To gain a more comprehensive understanding of students’ competencies and knowledge, the literature has suggested merging these two evaluations [
7,
8]. However, combining them might introduce an additional challenge, as teacher-assigned grades, despite usually being represented as numerical values, essentially entail verbal and linguistic descriptions of students’ knowledge levels, often lacking clarity. To address this, the literature has recommended the utilization of the mathematical framework of fuzzy logic, designed precisely for handling ambiguous, verbal data [
9,
10,
11,
12,
13,
14,
15,
16,
17]. Consequently, this paper employed methodologies rooted in fuzzy logic to combine (1) students’ performance in the national assessment of mathematical knowledge and (2) teacher-assigned mathematics grades.
Hence, employing fuzzy logic may offer educators a more comprehensive perspective on students’ knowledge and competencies. Nonetheless, it is essential to acknowledge that even with the suggested improvements concerning students’ achievements, predictive studies commonly rely on traditional statistical methodologies, such as linear and multiple regressions [
18]. These conventional tools might not be apt for accurately predicting large volumes of data, which is often the case when analyzing national and large-scale assessments [
19,
20]. Therefore, the current study focused on utilizing a specific machine learning technique to analyze data from the Italian National Assessment of Mathematical Knowledge, INVALSI, specifically through Random Forest (RF) regression analysis [
19,
21]. Therefore, the objective of this paper is to comprehensively examine the influence of multiple factors on various aspects of students’ educational outcomes using modern machine learning methodology.
1.1. The Italian Context
1.1.1. Teacher-Given Grades and the INVALSI Test
In Italian secondary education, comprising middle school (grades 6–8) and high school (grades 9–13), teachers assign numerical grades that range from a minimum of 1 to a maximum of 10, with 10 representing the highest grade. Grades below 6 are considered “failing grades”, while grades equal to or greater than 6 are considered “passing grades”. Teachers propose students’ final grades. However, it is the responsibility of the class councils (comprising all schoolteachers teaching a particular class) to approve or modify the proposed grades.
Each subject’s assessment can occur in one of three ways: (1) through written and oral evaluations, (2) solely written evaluations, or (3) only oral evaluations. Written evaluations entail more intricate written tests, while oral evaluations involve assessments such as oral exams, homework, projects, exercises, or shorter written tests. The preferred assessment method is determined by high school class councils, resulting in students receiving either one (oral or written) or two grades (both oral and written) in each subject. In contrast, middle school students receive only a single grade on their report cards (either oral or written). In the present research, we decided to focus on students’ oral grades since they might contain a more multifaceted picture of students’ knowledge and competencies.
Every academic year, the INVALSI institute assesses the entire population of Italian students in the 2nd (with an average age of 7 years), 5th (10 years old), 8th (13 years old), 10th (15 years old), and starting from the 2018–2019 school year, also in the 13th (18 years old) grades. Consequently, students are obligated to participate in the mandatory nationwide standardized assessment of mathematical proficiency [
22]. This standardized evaluation gauges students’ comprehension of mathematical concepts outlined in the National curriculum guidelines. These documents encompass the topics that math educators are required to teach in secondary and high school settings [
22].
The national assessment INVALSI comprises several questions that vary each year (typically ranging from 30 to 45 items), encompassing both closed and open-ended formats. Students in grades 8, 10, and 13 undertake the computerized version of the test [
22]. Additionally, questions are chosen automatically and at random from a question database, thereby minimizing the potential for academic dishonesty. As the selected questions share equal difficulty, the tests are deemed equivalent and comparable [
22]. The results obtained by students in the INVALSI test are quantitatively measured on a Rasch scale, where the mean is set at 200 and the standard deviation at 40.
The Rasch scale is a mathematical model used for the analysis of data from standardized tests and other measurement instruments. It helps in understanding and interpreting test results. The Rasch model is based on Item Response Theory (IRT) and is used to estimate the abilities or traits of individuals and the difficulty levels of test items on a common interval scale [
23,
24]. In particular, a standardized test comprises a set of items that are designed to measure a specific trait or ability, in our case it is mathematical proficiency. Each item has a set of response options (e.g., multiple-choice answers or rating scales). Individuals’ responses to these items are scored, typically assigning a score of 1 for a correct response and 0 for an incorrect response. The Rasch model estimates two key parameters: (1) person parameters (which represent the abilities or traits of the individuals being assessed; they are expressed on a log-odds scale), and (2) item parameters (which represent the difficulty levels of the test items; they are expressed on a log-odds scale). The model calculates the probability that an individual with a certain ability level will answer a particular item correctly [
24]. This probability depends on the difference between the individual’s ability and the item’s difficulty. The Rasch model then transforms the raw scores (e.g., the number of correct answers) into interval scale measures. This transformation ensures that the measures are on a consistent scale across different items and tests. The main advantage of the Rasch scale is the ability to compare individuals’ abilities and item difficulties on the same scale, which simplifies the interpretation of test results [
23,
24]. In the Italian context, students’ achievements on the INVALSI tests are expressed as a continuous variable that has been obtained using the Rasch model.
1.1.2. Factors Influencing Students’ Achievements on the INVALSI Test
While serving as essential tools to gauge the quality of the education system, national assessments of students’ mathematical knowledge are influenced by various factors [
25]. Gender, for instance, emerges as a significant determinant in national mathematics assessments, as indicated in the literature [
26,
27,
28]. Specifically, there is a consistent pattern of boys achieving higher scores on these assessments, notably in Italy, where the gender disparity in mathematical achievement becomes evident from the early years of primary schooling [
27,
28,
29].
Furthermore, the socio-economic, cultural, and familial backgrounds of students (Economic, Social, and Cultural Status, ESCS) exhibit a strong correlation with their academic achievements [
25]. Higher ESCS consistently corresponds to better performance in mathematics, a trend that holds true even within the Italian context [
28,
30,
31,
32]. These factors, in turn, display regional variations across Italy, with northern regions generally demonstrating higher ESCS compared to their southern counterparts [
33]. Additionally, disparities in achievement levels are observed across different Italian macroregions in the context of national assessments of mathematical knowledge [
31,
32,
34], with students from northern Italy typically outperforming those from the southern regions and islands.
Another critical consideration involves the variety of school types in Italy, each offering specialized education tailored to distinct career trajectories [
27]. Lyceums (L) provide a comprehensive educational experience encompassing liberal arts, languages, and sciences. Among them, Scientific Lyceums (SL) place a strong emphasis on science and mathematics, preparing students for future careers in fields such as engineering, medicine, or research. Technical schools (TS) deliver focused training in areas such as mechanics, electronics, or tourism, equipping students with practical skills relevant to specific industries. Vocational schools (VS), on the other hand, prioritize technical and professional education, gearing students towards careers in domains such as catering, fashion, or administration. Available research indicates that students from distinct school types exhibit differing performance levels on the INVALSI math test, with those from SL showcasing the highest achievements, while students from VS show comparatively lower results [
34].
Furthermore, the origin of students significantly influences their test outcomes. Research underscores that children of immigrants tend to attain lower scores [
35,
36,
37,
38], often linked to the language spoken at home and the socio-economic and cultural status of their families [
39].
1.2. Research Aims
Although the international and Italian literature acknowledges the substantial impact of factors such as gender, regional disparities, differences in ESCS, school type, and students’ origin on standardized mathematics test outcomes, the precise significance of each factor in predicting (1) performance in national assessments, (2) teacher-given grades, and (3) the fuzzy combinations of the both remains relatively unexplored. This knowledge gap exists due to the absence of a dedicated statistical methodology designed to address this question [
18].
In recent years, machine learning methods have gained traction for analyzing extensive educational assessment data, estimating the influence of individual factors, and constructing predictive models [
40]. Among these techniques, the RF approach has been proposed to assess the significance of individual factors in predicting outcomes [
18,
19,
21]. For instance, RF can be applied to identify key variables for predicting students’ mathematics achievements by incorporating student, teacher, and school-related factors [
18].
This paper aims to investigate the influence of students’ gender, regional background, school type, socio-economic status (ESCS), and origin on their performance in the Italian National Assessment of Mathematical Knowledge (INVALSI), as well as their teacher-assigned mathematics grades and the composite fuzzy grades derived from their performance on the INVALSI mathematics test and teacher-assigned grades. To achieve this, the Random Forest (RF) methodology was applied to a sample of grade 13 students who participated in the INVALSI test during the 2018–2019 academic year (prior to the COVID-19 pandemic). Thus, the research questions addressed in this study are as follows:
RQ1: What is the extent of the predictive influence of gender, students’ ESCS, macroregion, school type, ESCS, and students’ origin on teacher-assigned mathematics grades?
RQ2: How much do gender, students’ ESCS, macroregion, school type, ESCS, and students’ origin contribute to predicting students’ achievements on the INVALSI mathematics test?
RQ3: What is the degree of predictive power exerted by gender, students’ ESCS, macroregion, school type, ESCS, and students’ origin on students’ fuzzy grades, which amalgamate both their INVALSI test results and teacher-assigned grades?
5. Discussion
To offer educators reliable and accurate data concerning the education system’s quality, pinpointing potential systematic variations in scores among diverse student categories, national assessments could fulfill this objective [
1,
3,
4,
7]. Large-scale assessments and national evaluations of knowledge generate substantial amounts of data, necessitating appropriate statistical methodologies for analysis and accurate interpretation. Existing literature recommends the utilization of machine learning techniques, such as Random Forest (RF) regression analysis, enabling researchers to gain a more comprehensive understanding of the variables that potentially influence students’ achievements across multiple assessments [
5,
6,
18,
19,
20]. Furthermore, research proposes the combination of students’ grades with their performance in standardized tests [
7,
8], an approach that could provide educators with a more lucid and comprehensive understanding of students’ knowledge and competencies. The literature advocates for the application of fuzzy logic methodologies, which are adept at handling ambiguous, linguistic data such as teacher-assigned grades [
9,
41]. Fuzzy logic presents an enhanced approach for merging diverse assessments [
9,
10,
11,
12,
14,
15,
16,
39,
56]. Hence, the objective of this study was to employ RF regression analysis to examine students’ fuzzy grades, aiming to ascertain the demographic factor that potentially influences them.
Initial analyses were conducted to investigate potential differences in teacher-assigned grades, students’ achievements on the INVALSI test, and fuzzy grades across five demographic factors: students’ gender, school typology, students’ origin, ESCS, and schools’ macroregion. By employing the Mann–Whitney
U test and the Kruskal–Wallis test, we demonstrated that girls generally exhibit higher teacher-assigned grades, but lower performance than boys on the national mathematics assessment. These findings align with previous research studies [
26,
27,
28,
29]. Furthermore, there are disparities in students’ achievements across the four school types. Specifically, students from OL attained the highest teacher-assigned grades, though they ranked third in achievements on the INVALSI test. In terms of INVALSI scores, students from SL performed the best, whereas those from VS demonstrated the lowest achievements. Notably, students in SL also achieved the highest fuzzy grades. Our findings align with those from earlier research studies [
34]. Furthermore, distinctions in students’ achievements emerged among the five Italian macroregions. In line with existing literature, our study corroborated that students from Northern Italy achieve higher scores (teacher-assigned grades, achievements on the INVALSI test, and fuzzy grades) compared to their counterparts from Southern Italy [
31,
32,
34]. The results also validated the notion that students with higher ESCS typically achieve better on the INVALSI test and obtain higher fuzzy grades, which is in accordance with previous studies [
32,
33,
35]. However, the correlation between ESCS and teacher-assigned grades was relatively moderate, possibly stemming from teachers (unintentionally) assigning grades in alignment with the regional or school average ESCS. Furthermore, our investigation highlighted that native Italian students tend to achieve higher results than both first- and second-generation immigrant students, with the latter achieving higher than first-generation students. This observation is consistent with existing literature [
36,
37,
38,
39] and can potentially be elucidated by examining the interplay between origin and ESCS.
Preliminary analyses indeed confirmed that the considered factors may contribute to explaining a portion of the variance in students’ achievements. To investigate this relationship, we employed RF regression analysis. As our research demonstrates, the most influential determinant in predicting students’ achievements, particularly in terms of fuzzy grades, is the type of school students attend. Those enrolled in SL receive a more comprehensive mathematical education and possess enhanced problem-solving skills. Notably, despite the distinct emphases of the four school types—leading to divergent perceptions of mathematics as either an integral part of scientific culture in SL or a tool for addressing real-world problems in TS and VS—students undoubtedly receive varying levels of mathematical instruction. This discrepancy could potentially lead to disparities in opportunities within the job market and higher education. Consequently, policymakers should factor in this reality while devising future reforms and policy adjustments.
Secondly, schools’ macroregion and students’ ESCS are influential factors in predicting students’ outcomes and fuzzy grades. Addressing the disparities between Northern and Southern Italy [
31,
32], as well as socio-economic inequalities [
32,
33], is crucial to ensure a more equitable and sustainable education for all students. Notably, these factors also exert a significant impact on fuzzy grades. Lastly, students’ gender and their origin emerge as the least influential factors. While students’ origin is related to their ESCS [
38], which might partly explain the reduced significance in predicting students’ outcomes, the fact that gender holds less importance in predicting students’ achievements is surprising considering the outcomes reported in the literature [
26,
27,
28]. The literature has shown a relatively substantial impact of gender on students’ achievements. This unexpected result could potentially be attributed to the influence of social and educational policies that have aimed to alleviate gender disparities in mathematics achievements. Nevertheless, it is noteworthy that gender-based differences in achievements persist within the utilized sample. As a result, further research is necessary to comprehensively fathom the underlying factors contributing to this phenomenon.
The analysis using RF indicated that the demographic factors under consideration have limited predictive capability for teacher-assigned grades, as evidenced by the notably low fit coefficient. This could be attributed to the fact that teachers are closely attuned to the local context of their schools, adjusting their grading standards in response to student motivation (which is influenced by the choice of school), personal background (ESCS, gender, and origin), and even the socioeconomic dynamics of the region (macroregion). On the other hand, the scenario is different when it comes to the INVALSI tests, which offer a more objective means of evaluating students’ knowledge. Here, the demographic factors exhibit a stronger predictive capacity for students’ INVALSI test outcomes. Fuzzy grades, being a fusion of the two aforementioned assessments, also display sensitivity to demographic factors, and these factors predict them relatively effectively (with the fit coefficient acting as an intermediary between the two aforementioned coefficients). Consequently, if fuzzy grades are potentially employed in the future to comprehensively evaluate students’ knowledge through a composite of assessments, educators and policymakers should recognize that these evaluations are influenced by various non-cognitive factors. Nonetheless, their dependence on demographic factors is less pronounced compared to national assessments, suggesting that fuzzy grades could provide a relatively more objective and less demographic-dependent insight into students’ knowledge.
While the RF analysis has demonstrated the significance of the considered demographic factors in predicting students’ fuzzy grades, the examination of the
R2 coefficient has revealed a relatively low model fit. These findings align with those of previous studies conducted in Italy [
61,
62]. The reason for the limited model fit could be attributed to the possibility that there are other factors that serve as stronger predictors of students’ academic achievement, specifically in the case of fuzzy grades. These additional factors may include students’ math anxiety, test anxiety, their relationships with teachers, and so on [
63]. Consequently, further research is warranted to gain a more comprehensive understanding of the role played by the analyzed factors in predicting students’ fuzzy grades, as well as to identify which factors exert the greatest influence on these grades.
Moreover, some previous studies that have employed the usage of RF in education [
64,
65,
66] have shown that the results of the RF might help educators identify students at risk of failure or dropout. Nevertheless, these studies mainly employed the RF classification algorithm instead of the RF regression, as employed in the present paper. Therefore, additional studies are needed to fully understand how Machine Learning algorithms might assist educators in predicting students’ grades, especially when fuzzy logic methods are also applied to determine students’ final grades.
6. Conclusions
The present research is not without limitations. Firstly, due to the initial sample filtering, the sample size has been reduced, raising questions about the potential impact on the generalizability of the results. Secondly, while RF offers numerous advantages, its application is not devoid of limitations. Although RF can provide insights into variable importance, the intricate ensemble nature of the model can pose challenges in interpretation. Furthermore, RF is less suited for extrapolating beyond the range of the training data. Thirdly, the selection of membership functions, fuzzification and defuzzification methods, and inference rules were determined by the researchers based on their expertise [
41] and previous studies [
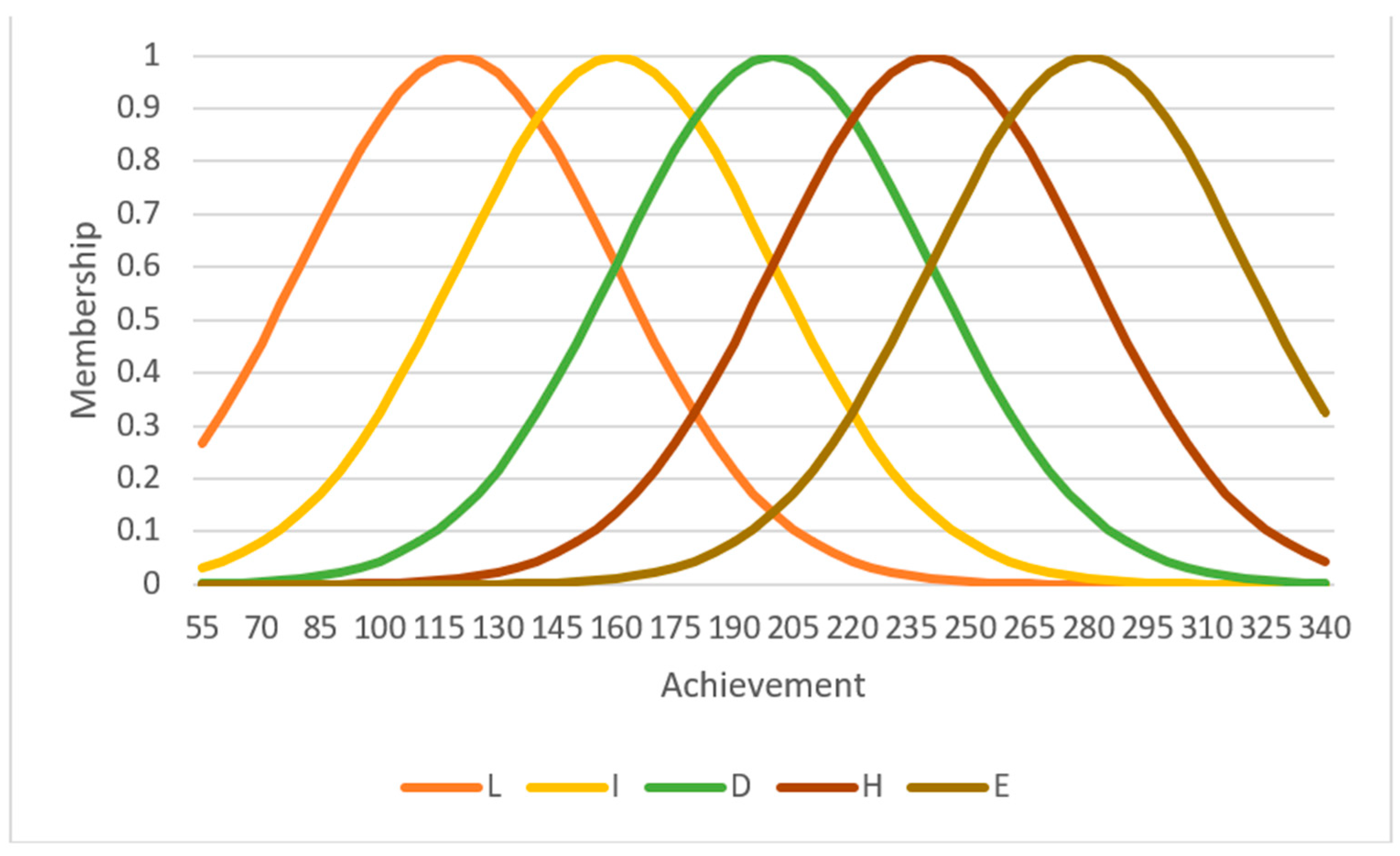
42]. Consequently, alternative choices within the fuzzy process could yield divergent outcomes. Despite these recognized limitations, our study is pioneering in its integration of fuzzy logic techniques in education with machine learning algorithms for predictive analysis.
Future research endeavors could expand on our work by experimenting with different parameters within the fuzzy process and employing different regression analyses. Our study underscores that several demographic factors impact fuzzy grades, although to a lesser extent than students’ achievements on national assessments. Consequently, fuzzy grades offer a promising foundation for educators and policymakers to inform forthcoming decisions and reforms based on extensive data. We encourage educators to diversify approaches to assessing students’ knowledge beyond traditional teacher-given grades and standardized test scores, using the aid of fuzzy logic. Additionally, we advocate for policymakers to embrace machine learning methods and exploit the potential of big data analytics to scrutinize substantial datasets.
Furthermore, we propose that policymakers explore the feasibility of implementing the fuzzy logic assessment approach. This could potentially mitigate bias stemming from demographic factors in national assessments, while simultaneously enhancing teacher-assigned grades with more objective indicators of students’ knowledge.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}