

Dynamic Extraction of Initial Behavior for Evasive Malware Detection
 , ,
, ,  , and
, and
Abstract
1. Introduction
- A feature extraction scheme based on a dynamic initial evasion behaviors determination (DIEBD) technique was proposed to extract the features by which the initial evasion behaviors were presented by effectively identifying the boundaries between the initial evasion behaviors and the unrepresentative behaviors in each instance.
- A malware detection model was developed using state-of-the-art machine-learning techniques to validate and evaluate the proposed scheme, conducting an in-depth comparative analysis between the proposed DIEBD-based feature extraction scheme and the recent related feature extraction schemes in terms of the obtained classification accuracy and other detection metrics.
- A comprehensive experimental evaluation was carried out demonstrate the improvement that the DIEBD-based feature extraction scheme had made.
2. Related Work
3. Evasive Malware Behaviors
4. The Framework
4.1. Raw Data Collection
4.2. Data Pre-Processing
4.2.1. Sliding Window-Based Entropy
4.2.2. Change Detection-Based Behavioral
4.3. Feature Extraction and Representation
4.4. The Detection
5. Experimental Design
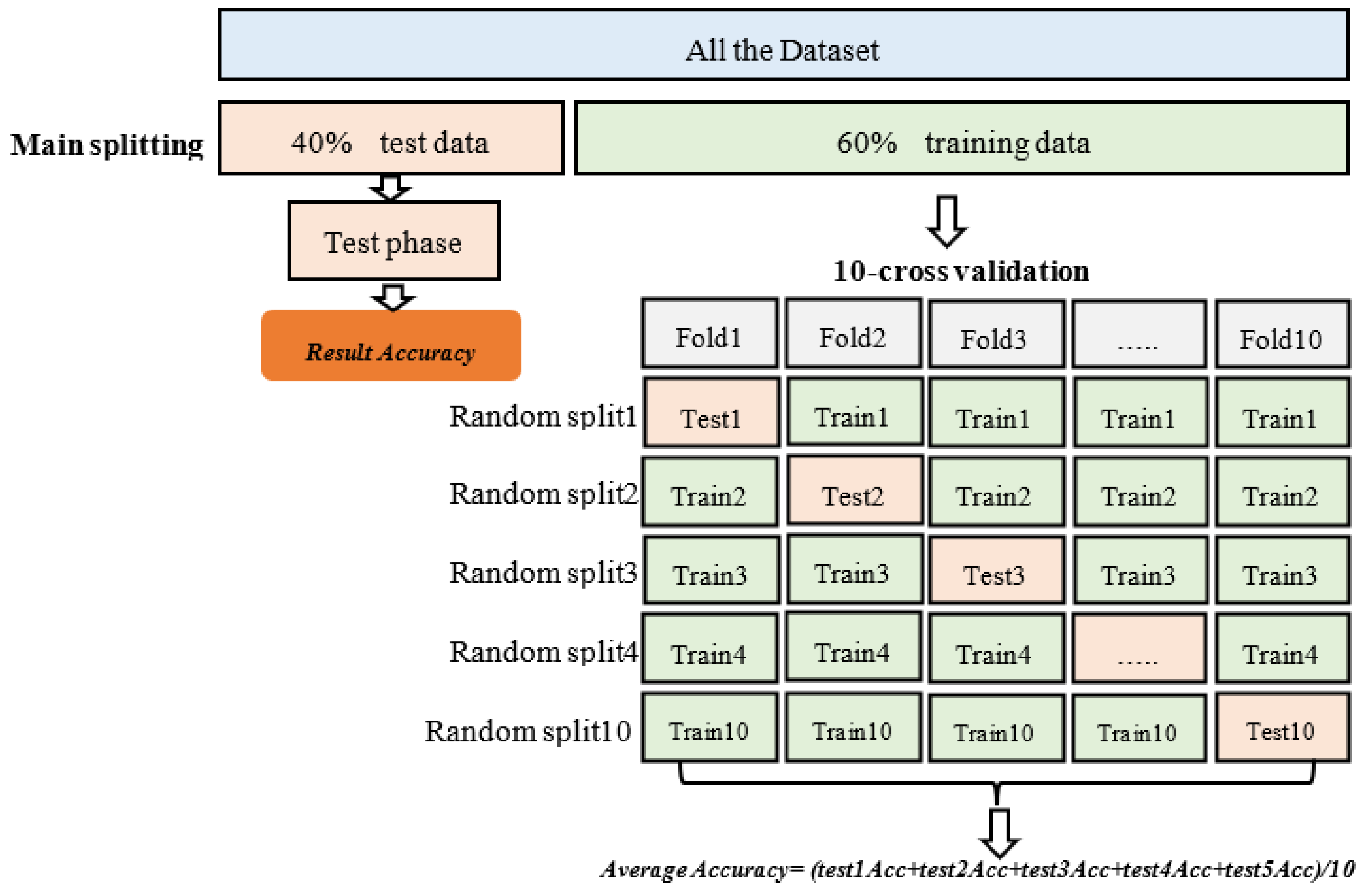
5.1. Experiment Environment Setup
5.2. The Dataset
5.3. Performance Measures
6. Results Analysis and Discussion
6.1. Selecting the K Value
6.2. The Comparison with Existing Work
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, A.; Handa, A.; Kumar, N.; Shukla, S.K. Malware classification using image representation. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2019; Volume 11527, pp. 75–92. [Google Scholar] [CrossRef]
- Kaspersky Security. Kaspersky Security Bulletin. Available online: https://go.kaspersky.com/rs/802-IJN-240/images/KSB_statistics_2018_eng_final.pdf (accessed on 25 August 2022).
- H. Sciences. Internet security Threat Report 2017. 2017. Available online: https://docs.broadcom.com/doc/istr-22-2017-en (accessed on 12 August 2022).
- Morgan, S. Cybercrime Damages $6 Trillion By 2021. 2017. Available online: https://cybersecurityventures.com/hackerpocalypse-cybercrime-report-2016/ (accessed on 18 August 2022).
- Sahay, S.K.; Sharma, A.; Rathore, H. Evolution of Malware and Its Detection Techniques. In Advances in Intelligent Systems and Computing; Springer: Singapore, 2020; Volume 933, pp. 139–150. [Google Scholar] [CrossRef]
- Jang, S.; Li, S.; Sung, Y. FastText-Based Local Feature Visualization Algorithm for Merged Image-Based Malware Classification Framework for Cyber Security and Cyber Defense. Mathematics 2020, 8, 460. [Google Scholar] [CrossRef]
- Galloro, N.; Polino, M.; Carminati, M.; Continella, A.; Zanero, S. A Systematical and longitudinal study of evasive behaviors in windows malware. Comput. Secur. 2021, 113, 102550. [Google Scholar] [CrossRef]
- Singh, J.; Singh, J. Detection of malicious software by analyzing the behavioral artifacts using machine learning algorithms. Inf. Softw. Technol. 2020, 121, 106273. [Google Scholar] [CrossRef]
- Yoo, S.; Kim, S.; Kim, S.; Kang, B.B. AI-HydRa: Advanced hybrid approach using random forest and deep learning for malware classification. Inf. Sci. 2020, 546, 420–435. [Google Scholar] [CrossRef]
- Shijo, P.V.; Salim, A. Integrated Static and Dynamic Analysis for Malware Detection. Procedia Comput. Sci. 2015, 46, 804–811. [Google Scholar] [CrossRef]
- Darshan, S.L.S.; Jaidhar, C.D. Windows malware detection system based on LSVC recommended hybrid features. J. Comput. Virol. Hacking Tech. 2018, 15, 127–146. [Google Scholar] [CrossRef]
- Sihwail, R.; Omar, K.; Ariffin, K.A.Z.; Al Afghani, S. Malware Detection Approach Based on Artifacts in Memory Image and Dynamic Analysis. Appl. Sci. 2019, 9, 3680. [Google Scholar] [CrossRef]
- Mills, A.; Legg, P. Investigating Anti-Evasion Malware Triggers Using Automated Sandbox Reconfiguration Techniques. J. Cybersecur. Priv. 2020, 1, 19–39. [Google Scholar] [CrossRef]
- Jha, S.; Prashar, D.; Long, H.V.; Taniar, D. Recurrent neural network for detecting malware. Comput. Secur. 2020, 99, 102037. [Google Scholar] [CrossRef]
- Lin, W.-C.; Yeh, Y.-R. Efficient Malware Classification by Binary Sequences with One-Dimensional Convolutional Neural Networks. Mathematics 2022, 10, 608. [Google Scholar] [CrossRef]
- Noor, M.; Abbas, H.; Bin Shahid, W. Countering cyber threats for industrial applications: An automated approach for malware evasion detection and analysis. J. Netw. Comput. Appl. 2018, 103, 249–261. [Google Scholar] [CrossRef]
- Caviglione, L.; Choras, M.; Corona, I.; Janicki, A.; Mazurczyk, W.; Pawlicki, M.; Wasielewska, K. Tight Arms Race: Overview of Current Malware Threats and Trends in Their Detection. IEEE Access 2020, 9, 5371–5396. [Google Scholar] [CrossRef]
- Galal, H.S.; Mahdy, Y.B.; Atiea, M.A. Behavior-based features model for malware detection. J. Comput. Virol. Hacking Tech. 2015, 12, 59–67. [Google Scholar] [CrossRef]
- Nunes, M.; Burnap, P.; Rana, O.; Reinecke, P.; Lloyd, K. Getting to the root of the problem: A detailed comparison of kernel and user level data for dynamic malware analysis. J. Inf. Secur. Appl. 2019, 48, 102365. [Google Scholar] [CrossRef]
- Ali, M.; Shiaeles, S.; Bendiab, G.; Ghita, B. MALGRA: Machine Learning and N-Gram Malware Feature Extraction and Detection System. Electronics 2020, 9, 1777. [Google Scholar] [CrossRef]
- Catak, F.O.; Yazı, A.F.; Elezaj, O.; Ahmed, J. Deep learning based Sequential model for malware analysis using Windows exe API Calls. PeerJ Comput. Sci. 2020, 6, e285. [Google Scholar] [CrossRef]
- Zhang, J.; Gu, Z.; Jang, J.; Kirat, D.; Stoecklin, M.; Shu, X.; Huang, H. Scarecrow: Deactivating Evasive Malware via Its Own Evasive Logic. In Proceedings of the 50th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, Valencia, Spain, 29 June–2 July 2020; pp. 76–87. [Google Scholar] [CrossRef]
- Branco, R.; Barbosa, G.N.; Drimel, P. Scientific But Not Academical Overview of Malware Anti-Debugging, Anti-Disassembly and Anti-VM Technologies. J. Chem. Inf. Model. 2012, 53, 1689–1699. [Google Scholar] [CrossRef]
- Chen, P.; Huygens, C.; Desmet, L.; Joosen, W. Advanced or Not? A Comparative Study of the Use of Anti-Debugging and Anti-VM Techniques in Generic and Targeted Malware. In IFIP Advances in Information and Communication Technology; Springer: Berlin/Heidelberg, Germany, 2016; Volume 471, pp. 323–336. [Google Scholar]
- Ali, M.; Shiaeles, S.; Papadaki, M.; Ghita, B.V. Agent-based Vs Agent-less Sandbox for Dynamic Behavioral Analysis. In Proceedings of the 2018 Global Information Infrastructure and Networking Symposium, GIIS 2018, Thessaloniki, Greece, 23–25 October 2018. [Google Scholar] [CrossRef]
- Alaeiyan, M.; Parsa, S.; Conti, M. Analysis and classification of context-based malware behavior. Comput. Commun. 2019, 136, 76–90. [Google Scholar] [CrossRef]
- Kirat, D.; Vigna, G.; Kruegel, C.; Vigna, G.; Kruegel, C. BareCloud: Bare-Metal Analysis-Based Evasive Malware Detection. In Proceedings of the 23rd USENIX Security Symposium, San Diego, CA, USA, 20–22 August 2014; Available online: https://www.usenix.org/system/files/conference/usenixsecurity14/sec14-paper-kirat.pdf (accessed on 2 September 2022).
- Banin, S.; Dyrkolbotn, G.O. Multinomial malware classification via low-level features. Digit. Investig. 2018, 26, S107–S117. [Google Scholar] [CrossRef]
- Banin, S.; Shalaginov, A.; Franke, K. Memory access patterns for malware detection. Nor. Nor. Inf. 2016, 96–107. Available online: http://hdl.handle.net/11250/2455297 (accessed on 5 September 2022).
- Denzer, T.; Shalaginov, A.; Dyrkolbotn, G.O. Intelligent Windows Malware Type Detection based on Multiple Sources of Dynamic Characteristics. Nis. J. 2019, 12, 1–16. [Google Scholar]
- Finder, I.; Sheetrit, E.; Nissim, N. Time-interval temporal patterns can beat and explain the malware. Knowl.-Based Syst. 2022, 241, 108266. [Google Scholar] [CrossRef]
- Tran, T.K.; Sato, H. NLP-based approaches for malware classification from API sequences. In Proceedings of the 2017 21st Asia Pacific Symposium on Intelligent and Evolutionary Systems (IES), Hanoi, Vietnam, 15–17 November 2017; pp. 101–105. [Google Scholar] [CrossRef]
- Aboaoja, F.A.; Zainal, A.; Ghaleb, F.A.; Al-Rimy, B.A.S.; Eisa, T.A.E.; Elnour, A.A.H. Malware Detection Issues, Challenges, and Future Directions: A Survey. Appl. Sci. 2022, 12, 8482. [Google Scholar] [CrossRef]
- Veerappan, C.S.; Keong, P.L.K.; Tang, Z.; Tan, F.; Veerappan, C.S.; Keong, P.L.K.; Tang, Z.; Tan, F. Taxonomy on malware evasion countermeasures techniques. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018; Volume 2018, pp. 558–563. [Google Scholar] [CrossRef]
- Or-Meir, O.; Nissim, N.; Elovici, Y.; Rokach, L. Dynamic Malware Analysis in the Modern Era—A State of the Art Survey. ACM Comput. Surv. 2019, 52, 1–48. [Google Scholar] [CrossRef]
- Bulazel, A.; Yener, B. A survey on automated dynamic malware analysis evasion and counter-evasion: PC, Mobile, and Web. In ACM International Conference Proceeding Series; ACM: New York, NY, USA, 2017. [Google Scholar] [CrossRef]
- Afianian, A.; Niksefat, S.; Sadeghiyan, B. Malware Dynamic Analysis Evasion Techniques: A Survey. ACM Comput. Surv. 2019, 52, 1–28. [Google Scholar] [CrossRef]
- Lau, B.; Svajcer, V. Measuring virtual machine detection in malware using DSD tracer. J. Comput. Virol. 2008, 6, 181–195. [Google Scholar] [CrossRef]
- Miramirkhani, N.; Appini, M.P.; Nikiforakis, N.; Polychronakis, M. Spotless Sandboxes: Evading Malware Analysis Systems Using Wear-and-Tear Artifacts. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–24 May 2017; pp. 1009–1024. [Google Scholar] [CrossRef]
- O’Ree, A.; Obaidat, M.S. A dynamic malware analyzer against virtual machine aware malicious software. Secur. Commun. Netw. 2012, 5, 422–437. [Google Scholar]
- Singh, J.; Singh, J. Challenges of Malware Analysis: Obfuscation Techniques. Int. J. Inf. Secur. Sci. 2018, 7, 100–110. Available online: http://www.ijiss.org (accessed on 16 September 2022).
- Ehteshamifar, S.; Barresi, A.; Gross, T.R.; Pradel, M. Easy to Fool? Testing the Anti-Evasion Capabilities of PDF Malware Scanners. Available online: http://arxiv.org/abs/1901.05674 (accessed on 3 August 2022).
- Küchler, A.; Mantovani, A.; Han, Y.; Bilge, L.; Balzarotti, D. Does Every Second Count? Time-Based Evolution of Malware Behavior in Sandboxes. In Proceedings of the 2021 Network and Distributed System Security Symposium, virtually, 21–25 February 2021; Available online: https://www.ndss-symposium.org/wp-content/uploads/ndss2021_4C-5_24475_paper.pdf (accessed on 8 August 2022).
- Kim, M.; Cho, H.; Hyun, J.; Member, Y.I. Large-Scale Analysis on Anti-Analysis Techniques in Real-World Malware. IEEE Access 2022, 10, 75802–75815. [Google Scholar] [CrossRef]
- Zhou, J.; Hirose, M.; Kakizaki, Y.; Inomata, A. Evaluation to Classify Ransomware Variants Based on Correlations between APIs. In Proceedings of the 6th International Conference on Information Systems Security and Privacy, Valletta, Malta, 25–27 February 2020; pp. 465–472. [Google Scholar] [CrossRef]
- Al-Rimy, B.A.S.; Maarof, M.A.; Shaid, S.Z.M. Crypto-ransomware early detection model using novel incremental bagging with enhanced semi-random subspace selection. Futur. Gener. Comput. Syst. 2019, 101, 476–491. [Google Scholar] [CrossRef]
- Pektaş, A.; Acarman, T. Classification of malware families based on runtime behaviors. J. Inf. Secur. Appl. 2017, 37, 91–100. [Google Scholar] [CrossRef]
- Hwang, J.; Kim, J.; Lee, S.; Kim, K. Two-Stage Ransomware Detection Using Dynamic Analysis and Machine Learning Techniques. Wirel. Pers. Commun. 2020, 112, 2597–2609. [Google Scholar] [CrossRef]
- Du, D.; Sun, Y.; Ma, Y.; Xiao, F. A Novel Approach to Detect Malware Variants Based on Classified Behaviors. IEEE Access 2019, 7, 81770–81782. [Google Scholar] [CrossRef]
- Oyama, Y. Trends of anti-analysis operations of malwares observed in API call logs. J. Comput. Virol. Hacking Tech. 2017, 14, 69–85. [Google Scholar] [CrossRef]
- Oyama, Y. Investigation of the Diverse Sleep Behavior of Malware. J. Inf. Process. 2018, 26, 461–476. [Google Scholar] [CrossRef]
- Ling, Y.T.; Sani, N.F.M.; Abdullah, M.T.; Hamid, N.A.W.A. Nonnegative matrix factorization and metamorphic malware detection. J. Comput. Virol. Hacking Tech. 2019, 15, 195–208. [Google Scholar] [CrossRef]
- Pektaş, A.; Acarman, T. Malware classification based on API calls and behaviour analysis. IET Inf. Secur. 2018, 12, 107–117. [Google Scholar] [CrossRef]
- Ghaleb, F.A.; Maarof, M.A.; Zainal, A.; Rassam, M.A.; Saeed, F.; Alsaedi, M. Context-aware data-centric misbehaviour detection scheme for vehicular ad hoc networks using sequential analysis of the temporal and spatial correlation of the consistency between the cooperative awareness messages. Veh. Commun. 2019, 20, 100186. [Google Scholar] [CrossRef]
- Li, X.; Qiu, K.; Qian, C.; Zhao, G. An Adversarial Machine Learning Method Based on OpCode N-grams Feature in Malware Detection. In Proceedings of the 2020 IEEE Fifth International Conference on Data Science in Cyberspace (DSC), Hong Kong, China, 27–30 July 2020; pp. 380–387. [Google Scholar] [CrossRef]
- Zhang, H.; Xiao, X.; Mercaldo, F.; Ni, S.; Martinelli, F.; Sangaiah, A.K. Classification of ransomware families with machine learning based onN-gram of opcodes. Futur. Gener. Comput. Syst. 2018, 90, 211–221. [Google Scholar] [CrossRef]
- Fuyong, Z.; Tiezhu, Z. Malware Detection and Classification Based on N-Grams Attribute Similarity. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; Volume 1, pp. 793–796. [Google Scholar] [CrossRef]
- Yang, L.; Liu, J. TuningMalconv: Malware Detection with Not Just Raw Bytes. IEEE Access 2020, 8, 140915–140922. [Google Scholar] [CrossRef]
- Zhang, W.; Yoshida, T.; Tang, X. A comparative study of TF*IDF, LSI and multi-words for text classification. Expert Syst. Appl. 2011, 38, 2758–2765. [Google Scholar] [CrossRef]
- Al-Hashmi, A.A.; Ghaleb, F.A.; Al-Marghilani, A.; Yahya, A.E.; Ebad, S.A.; Muhammad Saqib, M.S.; Darem, A.A. Deep-Ensemble and Multifaceted Behavioral Malware Variant Detection Model. IEEE Access 2022, 10, 42762–42777. [Google Scholar] [CrossRef]
- Chen, P.-H.; Zafar, H.; Galperin-Aizenberg, M.; Cook, T. Integrating Natural Language Processing and Machine Learning Algorithms to Categorize Oncologic Response in Radiology Reports. J. Digit. Imaging 2017, 31, 178–184. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J. Clement: Machine learning methods for malware recognition based on semantic behaviours. In Proceedings of the 2020 International Conference on Computer Information and Big Data Applications, CIBDA 2020, Guiyang, China, 17–19 April 2020; pp. 233–236. [Google Scholar] [CrossRef]
- Kumar, H.; Chawla, N.; Mukhopadhyay, S. Towards Improving the Trustworthiness of Hardware based Malware Detector using Online Uncertainty Estimation. arXiv 2021, arXiv:2103.11519. Available online: http://arxiv.org/abs/2103.11519 (accessed on 13 August 2022).
- Chauhan, N.K.; Singh, K. A review on conventional machine learning vs deep learning. In Proceedings of the 2018 International Conference on Computing, Power and Communication Technologies, GUCON 2018, Greater Noida, India, 28–29 September 2018; pp. 347–352. [Google Scholar] [CrossRef]
- Sun, Y.; Bashir, A.K.; Tariq, U.; Xiao, F. Effective malware detection scheme based on classified behavior graph in IIoT. Ad. Hoc. Netw. 2021, 120, 102558. [Google Scholar] [CrossRef]
- Usman, N.; Usman, S.; Khan, F.; Jan, M.A.; Sajid, A.; Alazab, M.; Watters, P. Intelligent Dynamic Malware Detection using Machine Learning in IP Reputation for Forensics Data Analytics. Futur. Gener. Comput. Syst. 2021, 118, 124–141. [Google Scholar] [CrossRef]
- García, D.E.; DeCastro-García, N. Optimal feature configuration for dynamic malware detection. Comput. Secur. 2021, 105, 102250. [Google Scholar] [CrossRef]
- Revision, C.F. «Docs» Installation, Cuckoo Foundation Revision a665d2a6. 2022. Available online: https://cuckoo.readthedocs.io/en/latest/installati (accessed on 16 August 2022).
- Kirat, D.; Vigna, G. MalGene: Automatic extraction of malware analysis evasion signature. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022; pp. 769–780. [Google Scholar] [CrossRef]
- Wei, C.; Li, Q.; Guo, D.; Meng, X. Toward Identifying APT Malware through API System Calls. Secur. Commun. Netw. 2021, 2021, 1–14. [Google Scholar] [CrossRef]
- Darshan, S.L.S.; Jaidhar, C.D. An empirical study to estimate the stability of random forest classifier on the hybrid features recommended by filter based feature selection technique. Int. J. Mach. Learn. Cybern. 2019, 11, 339–358. [Google Scholar] [CrossRef]
- Rostamy, A.A.A.; Khosroanjom, D.; Niknafs, A.; Rostamy, A.A. Fuzzy AHP models for the evaluation of IT capability, data quality, knowledge management systems implementation and data security dimensions. Int. J. Oper. Res. 2015, 22, 194. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Evasion Techniques | Number | Source |
|---|---|---|---|
| malware | Hardware id-based evasion | 82 | [69] |
| Bios-based evasion | 6 | [69] | |
| Processor feature-based evasion | 134 | [69] | |
| Exception-based evasion | 197 | [69] | |
| Timing-based evasion | 689 | [69] | |
| Wait for keyboard | 3 | [69] | |
| Not available | 6096 | [7] | |
| Malware Total Number | 7208 | ||
| Benign | 2000 | Win7 | |
| Benign | 1848 | [70] | |
| Benign Total Number | 3848 | ||
| Classifier | Accuracy | Detection Rate | Precision | F1 | FPR | FNR |
|---|---|---|---|---|---|---|
| KNN | 0.915 | 0.924 | 0.945 | 0.934 | 0.101 | 0.076 |
| CART | 0.936 | 0.948 | 0.954 | 0.951 | 0.086 | 0.052 |
| NB | 0.759 | 0.671 | 0.945 | 0.785 | 0.074 | 0.329 |
| SVM | 0.952 | 0.964 | 0.962 | 0.963 | 0.071 | 0.036 |
| ANN | 0.962 | 0.970 | 0.972 | 0.971 | 0.053 | 0.030 |
| RF | 0.952 | 0.972 | 0.955 | 0.964 | 0.086 | 0.028 |
| LR | 0.929 | 0.954 | 0.939 | 0.946 | 0.118 | 0.046 |
| XGBoost | 0.962 | 0.974 | 0.967 | 0.971 | 0.062 | 0.026 |
| Classifier | Accuracy | Detection Rate | Precision | F1 | FPR | FNR |
|---|---|---|---|---|---|---|
| KNN | 0.890 | 0.888 | 0.941 | 0.914 | 0.105 | 0.112 |
| CART | 0.932 | 0.937 | 0.958 | 0.947 | 0.078 | 0.063 |
| NB | 0.792 | 0.728 | 0.939 | 0.821 | 0.089 | 0.272 |
| SVM | 0.943 | 0.948 | 0.964 | 0.956 | 0.066 | 0.052 |
| ANN | 0.957 | 0.963 | 0.970 | 0.967 | 0.055 | 0.037 |
| RF | 0.947 | 0.962 | 0.957 | 0.959 | 0.082 | 0.038 |
| LR | 0.922 | 0.944 | 0.937 | 0.940 | 0.120 | 0.056 |
| XGBoost | 0.967 | 0.971 | 0.978 | 0.975 | 0.040 | 0.029 |
| Classifier | Accuracy | Detection Rate | Precision | F1 | FPR | FNR |
|---|---|---|---|---|---|---|
| KNN | 0.877 | 0.884 | 0.922 | 0.903 | 0.134 | 0.116 |
| CART | 0.924 | 0.944 | 0.938 | 0.941 | 0.112 | 0.056 |
| NB | 0.766 | 0.707 | 0.910 | 0.795 | 0.126 | 0.293 |
| SVM | 0.924 | 0.937 | 0.945 | 0.941 | 0.098 | 0.063 |
| ANN | 0.952 | 0.962 | 0.963 | 0.962 | 0.067 | 0.038 |
| RF | 0.932 | 0.961 | 0.935 | 0.948 | 0.120 | 0.039 |
| LR | 0.912 | 0.944 | 0.921 | 0.932 | 0.146 | 0.056 |
| XGBoost | 0.955 | 0.970 | 0.961 | 0.965 | 0.072 | 0.030 |
| Classifier | Accuracy | Detection Rate | Precision | F1 | FPR | FNR |
|---|---|---|---|---|---|---|
| KNN | 0.876 | 0.866 | 0.941 | 0.902 | 0.104 | 0.134 |
| CART | 0.916 | 0.928 | 0.944 | 0.936 | 0.106 | 0.072 |
| NB | 0.777 | 0.723 | 0.922 | 0.810 | 0.118 | 0.277 |
| SVM | 0.920 | 0.919 | 0.958 | 0.938 | 0.077 | 0.081 |
| ANN | 0.948 | 0.958 | 0.962 | 0.960 | 0.072 | 0.042 |
| RF | 0.929 | 0.949 | 0.944 | 0.946 | 0.109 | 0.051 |
| LR | 0.908 | 0.923 | 0.937 | 0.930 | 0.120 | 0.077 |
| XGBoost | 0.958 | 0.967 | 0.969 | 0.968 | 0.060 | 0.033 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aboaoja, F.A.; Zainal, A.; Ali, A.M.; Ghaleb, F.A.; Alsolami, F.J.; Rassam, M.A. Dynamic Extraction of Initial Behavior for Evasive Malware Detection. Mathematics 2023, 11, 416. https://doi.org/10.3390/math11020416
Aboaoja FA, Zainal A, Ali AM, Ghaleb FA, Alsolami FJ, Rassam MA. Dynamic Extraction of Initial Behavior for Evasive Malware Detection. Mathematics. 2023; 11(2):416. https://doi.org/10.3390/math11020416
Chicago/Turabian StyleAboaoja, Faitouri A., Anazida Zainal, Abdullah Marish Ali, Fuad A. Ghaleb, Fawaz Jaber Alsolami, and Murad A. Rassam. 2023. "Dynamic Extraction of Initial Behavior for Evasive Malware Detection" Mathematics 11, no. 2: 416. https://doi.org/10.3390/math11020416
APA StyleAboaoja, F. A., Zainal, A., Ali, A. M., Ghaleb, F. A., Alsolami, F. J., & Rassam, M. A. (2023). Dynamic Extraction of Initial Behavior for Evasive Malware Detection. Mathematics, 11(2), 416. https://doi.org/10.3390/math11020416