
Linguistic Multiple-Attribute Decision Making Based on Regret Theory and Minimax-DEA

Pittsburgh Institute, Sichuan University, Chengdu 610207, China
Mathematics 2023, 11(20), 4259; https://doi.org/10.3390/math11204259
Submission received: 28 August 2023
/
Revised: 2 October 2023
/
Accepted: 5 October 2023
/
Published: 12 October 2023
Abstract
:Given that most current linguistic multiattribute decision-making methods do not consider the optimal efficiency of decision-making units and the psychological behavior of decision makers, a linguistic multiattribute decision-making method based on regret theory, data envelopment analysis, and the minimax reference point method is proposed. First, based on the decision-maker psychology of regret and avoidance, the perceived utility value of each decision-making unit was calculated using the language regret–joy value function. The subjective and optimal efficiency values of each decision-making unit were obtained using the subjective weighting and data envelopment analysis methods, respectively. Next, we considered the best efficiency as the reference point and the subjective efficiency as the decision preference to establish a minimax reference point model. By solving the model, a set of public weights that minimizes the difference between the efficiency values of all decision-making units and their optimal efficiency values can be obtained to sort the decision-making units and select the best. The feasibility of the method was verified using an example of employee evaluation and selection; the effectiveness of the method was demonstrated through comparative analysis with other methods.
Keywords:
regret theory; data envelopment analysis; minimax reference point approach; multiple-attribute decision makingMSC:
90B501. Introduction
Multiattribute decision making refers to the ranking or selection of limited schemes that consider several attributes. In recent years, multiattribute decision making has been widely used in enterprise development and social decision making. However, owing to the complexity of objective things and the ambiguity of human thinking, it is difficult to fully express the decision-maker cognition of objective things only with precise numbers. For some attributes, it is difficult for decision makers to express quantitative values; qualitative language information is preferred to describe them [1,2]. For example, when evaluating and selecting employees, decision makers may say, “the employee’s work style is good, but the expression ability is poor” or other language-evaluation information. The solution of linguistic multiattribute decision-making problems is a worthwhile topic.
In language-based multiattribute decision-making problems, researchers have obtained fruitful results. From the literature on language-based multiattribute decision-making methods, research focuses mainly on three areas: (1) Measurement research based on linguistic information, where researchers have discussed the expression form of linguistic information in depth. Zadeh [3] defined language set S, which was used to qualitatively describe evaluation information. Xu [4] proposed a subscription-symmetric additivity set for language terms. (2) The second area involves integrated research based on language information. Lin et al. [5] applied TOPSIS and VIKOR to the Probabilistic Linguistic Term Set (PLTS) to enhance applicability. Cheng et al. [6] improved the linguistic intuition fuzzy-set distance measure and proposed a new similarity measure defined by a nonlinear Gaussian diffusion model. Zhu et al. [7] argued that decision makers have their confidence values in the decision-making process and proposed a model of group decision making with confident linguistic preferences. (3) The third area is application research based on language information. Researchers have widely used language-based multiattribute decision-making methods in project management [8], elderly care institution evaluation [9], and technology financing [10].
Taken together, the research provides a theoretical reference and design ideas for solving the linguistic multiattribute decision-making problem; however, the research has some deficiencies. First, most studies are based on the expected utility theory, which assumes that decision makers are perfectly rational. The influence of decision-maker psychological behavior on decision-making results has received considerable attention. Among the many methods based on bounded rationality, prospect and regret theories are the most widely used. Regret theory is better than prospect theory for describing and explaining the reflection effect, preference reversal, and other phenomena in actual behavior, and it also assumes fewer constraints; thus, it is increasingly used in multiattribute decision-making problems [11,12].
Second, the construction of weighted composite indicators is not sufficiently comprehensive in the calculation of weights. It is known that a reasonable distribution of weights is key to multiattribute decision-making problems. Currently, the methods for determining weights include subjective, objective, and combined weighting methods [13]. The subjective weighting method is a method of weighting according to the subjective judgment of decision-making experts and can better reflect the subjective wishes of decision makers. Representative methods include the AHP [14] and Delphi methods [15]. The objective weighting rule determines the weight according to actual information reflected by the attribute, generally ignoring the subjective intention of the decision maker. When the data change, the weight also changes; thus, the stability of the objective weight is poor. Data envelopment analysis [16], entropy value [17], and principal component analysis [18] methods are used. Given the limitations of these methods, many researchers have begun to focus on subjective and objective combination weighting methods [19,20,21]. After synthesizing subjective and objective approaches, Alexei et al. proposed a participatory goal-based weighting scheme that constructed a composite indicator more relevant to the conceptual meaning of the multidimensional phenomenon to ensure its external validity, they and determined the weights of the subindicators while respecting expert opinions [22]. The combined weighting method was significantly improved compared to the single weighting method.
The aggregation is also not sufficiently comprehensive; the weights assigned to a variable are not directly interpreted as a measure of the importance of that variable, but they also consider the way in which aggregation is performed [23]. Three types of aggregation methods are commonly used: linear, geometric, and multicriteria. As there is no perfect weighting scheme, there is no perfect case for aggregation; each method has advantages and disadvantages in different applications [24]. Thus, a specific analysis of the problem is required, and the effect of aggregation on the weighting of comprehensive indicators cannot be ignored.
The data envelopment analysis method proposed by Charnes et al. [25] can obtain the optimal efficiency value of each decision-making unit, which is an important means for solving multiattribute decision-making problems. Wang et al. [26] used the DEA-TOPSISI method for multiattribute decision making to improve the recycling efficiency of end-of-life vehicles. The attribute weights obtained by the traditional data envelopment analysis method are not uniform, resulting in a lack of basis for a horizontal comparison of decision-making results. Moreover, in actual decision making, it is sometimes necessary to incorporate subjective expert preferences in the decision-making process. At this point, the general DEA model is no longer applicable. As a method for solving multiobjective programming, the minimax reference point approach [27] can assign subjective preferences of decision-making experts to the objective function in the form of preference coefficients and minimize the gap between each objective function and its optimal value. Thus, it is widely used in many fields, such as supplier selection [28] and quality risk assessment [29].
Based on this analysis, this study proposes a language-based multiattribute decision-making method based on regret theory and minimax DEA. The main contributions of our method are presented as follows:
- (1)
- We considered the influence of decision-maker psychological factors on decision making and incorporated decision-maker attitudes toward regret and avoidance into the language-based multiattribute decision-making method, making the decision-making results more realistic.
- (2)
- Compared to general combinatorial assignment methods, the method in this study simultaneously considers both the subjective tendency of the decision maker and the best intention of each decision unit. We used the minimal–extremely large reference point method to aggregate subjective and objective information to find the most eclectic solution as the public weight of the attributes recommended by all decision units, fairly and simultaneously considering the interests of all decision units.
The remainder of this paper is organized as follows: Section 2 introduces the basic concepts of language assessment scales and regret theory. Section 3 introduces the data envelopment analysis and minimax reference point methods. Section 4 proposes a language-based multiattribute decision-making method based on regret theory and minimax DEA and details the specific decision-making steps. Section 5 verifies the feasibility of the proposed method through an example and compares it with other methods. Section 6 summarizes the proposed approach and provides an outlook for future research.
2. Relevant Theoretical Basis
2.1. Language Assessment Scale
When decision makers use language terms for evaluation, they must generally choose an appropriate language evaluation scale. Compared to the uniform language scale, the non-uniform language evaluation scale is more in line with human thinking habits, and the consistency of the conclusions is higher [30]. Based on the analysis, this study used a non-uniform language evaluation scale.
In Equation (1), represents the language term, and is a positive integer. When , the language term set is
When , the language term set is
For example, when , the granularity of the linguistic term set is 7.
Regret Theory
The core idea of regret theory is that decision makers consider the outcome of their choice and compare it with the outcomes of other options. If the other options are better, there is regret. Regret theory was first proposed by Bell [31] and Loomes and Sugden [32]. Initially, it was used to solve a selection problem with two schemes. It was later extended to solve selection problems with multiple schemes [33]. Bleichrodt et al. [34] proposed a calculation method for the regret–joy value based on the decision information of exact numbers. Based on regret theory, Tang et al. [35] and Wang et al. [36] used interval and fuzzy numbers, respectively, to characterize the uncertainty of decision-making information. However, in an actual decision-making process, the attribute values of the DMUs are more likely to be presented in the form of language terms. Thus, it is particularly important to calculate regret–joy values based on linguistic information.
Definition 1.
Let be the language evaluation term and be the subscript conversion function of the language term [37]. Using this function, any language term can be converted to an exact number.
Definition 2.
Let be the subscript conversion function of the language term . The language utility function of the language term is
Definition 3.
Let be the decision-maker linguistic judgment values for the currently selected option and ideal option , respectively, and be the classical regret–joy function of the exact number . , , and . is said to be the linguistic regret–joy function of the decision-maker selection of option and the abandonment of ideal option .
In Equation (6), when , the value of the linguistic judgment of the positive ideal scheme can be calculated; the result computed by the function is the regret value.
when , the value of the linguistic judgment of the positive ideal scheme can be calculated; the result computed by the function is the regret value.
Definition 4.
When the decision maker chooses option , the language-aware utility value is
Equation (9) can be used to calculate the language-perceived utility value of any scheme, which also means that any language evaluation term can be converted into an exact number using the formula for effective decision making.
3. Methodology
3.1. Data Envelopment Analysis
Data envelopment analysis is used to evaluate the relative efficiency of decision-making units. From the perspective of inputs and outputs, efficiency is maximized by flexibly assigning weights to each decision-making unit. In the DEA model, decision-making efficiency is defined as the ratio of the weighted output index to the weighted input index. An effective way to identify whether the evaluation index is an input or output is described as follows: if the index value of an attribute is as small as possible, it is the output of the input index and is an output indicator.
However, in practical applications, there are many multiattribute decision-making problems that do not require a consideration of input indicators, such as evaluating the scientific research strength of EU countries [38] and evaluating and selecting employees and cadres. At this point, traditional data envelopment analysis methods are no longer applicable. Adolphson et al. [39] first proposed the input-free DEA model. Liu et al. [40] systematically studied this type of model and referred to it as the data envelopment analysis model without explicit input (DEA-WEI model). Yang et al. [41] studied a DEA-WEI model with quadratic terms from the perspective of extended utility. In general, DEA-WEI does not reflect the technical efficiency of the decision unit input–output system as a classical DEA does. They investigated the link between the DEA-WEI model and multiattribute utility theory. The form of the objective function is similar to that of a classical utility function. Unlike the classic utility theory, only the functional form of the objective function is determined by decision-makers to reflect a subjective emphasis on evaluation. In turn, the decision unit determines the coefficients of the function through deal-style programming to ensure that it receives the most favorable evaluation.
Suppose that there are decision-making units, . Each decision-making unit has attributes, , among which attributes are input indicators and attributes are output indicators. represents the measured value of the input indicator for the decision-making unit. represents the measured value of the output indicator for the decision-making unit. represents the weight assigned to the input indicator. represents the weight assigned to the output.
Based on the analysis, for a multiattribute decision-making problem with input and output indicators, the traditional CCR model can be expressed as
For multiattribute decision-making problems without input indicators, the DEA-WEI model proposed by Yang et al. [38] was used
where the subscript “0” refers to the DMU of interest.
Minimax Reference Point Approach
In management and engineering, most decision-making problems involve potentially conflicting goals; research has focused on the effective coordination of these goals. Yang [27] proposed the minimax reference point method. The basic idea of this method is that it assumes that all objective functions have their optimal values; with the existing constraints, it is not possible to make all objective functions reach optimal values at the same time. Thus, a set of solutions must be found such that all combined deviations between the objective function value and its optimal value are the smallest. In other words, the optimal solution should be obtained when all objective function values are closest to their optimal values. The specific solutions are described as follows:
Suppose a multiobjective programming problem can be expressed as
refers to the objective function; represents the decision variable; represents the constraints of the decision variable , and and represent the inequality and equality constraints of the decision variable , respectively.
Before solving this multiobjective programming problem, each objective function was solved separately, and the optimal value of was obtained. The mini-maximization method was used to make all objective functions as close as possible to their optimal values. Thus, the multiobjective programming problem can be transformed into a single-objective programming problem.
The solution to the multiobjective programming problem can be obtained by solving Equation (13).
4. Linguistic Multiple-Attribute Decision Making Based on Regret Theory and Minmax-DEA
4.1. Determination of Attribute Weights
A reasonable distribution of weights is key to multiattribute decision-making problems. To consider the decision-maker psychology of regret and avoidance and reflect the best intentions of each decision-making unit and the decision-maker subjective tendency, this study proposes a weight determination method for linguistic multiattribute decision-making problems. The specific steps are presented as follows:
Suppose there are candidates for the linguistic multiattribute decision-making problem , where represents the solution, and attributes , where represents the attribute, linguistic multiattribute evaluation matrix , where represents the decision-maker linguistic evaluation of option with respect to attribute .
Step 1: According to the rich knowledge and experience of decision-making experts and using the language evaluation scale in Equation (4), the language-type multiattribute evaluation matrix is obtained.
Step 2: The language term subscript conversion function I of Definition 1 is used to convert the linguistic evaluation matrix x in Step 1 into an exact number-based evaluation matrix . Considering decision-maker regret avoidance, Equations (5)–(9) are used to process the matrix to obtain the perceived utility matrix .
Step 3: Based on the perceived utility matrix , Equations (10) and (11) are used to calculate the optimal efficiency value for each decision-making unit. The data envelopment analysis method can flexibly assign weights to each decision-making unit to maximize its efficiency; thus, the efficiency value represents the best of each decision-making unit.
Step 4: In Step 3, an optimal efficiency value is obtained for each decision-making unit. However, the weights are not uniform, and the decision-making results lack a basis for horizontal comparison. Thus, it is particularly important to determine a set of public weights that satisfies all decision-making units. Thus, we constructed a minimax-DEA model based on the data envelopment analysis method and minimax reference point methods. By solving the model, a set of common weights can be found that minimizes the gap between the efficiency values of all decision-making units and their optimal values.
It is assumed that not all decision-making units contain input indicators; thus, the following model is established based on
In Equation (14), represents the optimal efficiency value of each decision-making unit. represents the difference between the efficiency value of each decision-making unit and its optimal efficiency value with weight .
A set of common weights is obtained by solving the model. However, these weights only consider the optimal efficiency value of each decision-making unit at the objective level and not at the subjective level. It is known that a reasonable weight distribution should reflect the actual data and the subjective intentions of decision makers. To consider the best intentions of each decision-making unit and the subjective inclinations of decision makers, a new variable is introduced based on multiobjective planning. It represents the “speak” of each decision-making unit.
represents the subjective weight of each decision-making unit; represents the subjective efficiency value of each decision-making unit. The subjective weight and subjective efficiency value of each attribute can be calculated using any subjective weighting method. Here, the analytic hierarchy process from the literature [14] is used to calculate. Li et al. [21] showed that the order of the size of each attribute in the subjective weight can better reflect the importance of the attribute itself and is the expression of the intention of the decision maker. Thus, to ensure that the order of the combined weights is consistent with the order of the subjective weights, it is necessary to add a constraint set based on the model. For example, if the subjective weight has three attributes, then . Thus, the final weighting model is
According to the model, if the subjective efficiency value of a certain decision-making unit is larger, then is larger. In multiobjective planning, more consideration is given to the gap between the decision-making unit and its optimal efficiency value, which also means that it has more “speak” than other decision-making units. Thus, when using a multiobjective programming model for weight allocation, the willingness of the decision-making unit to assign weights increases.
It is clear that model (17) is equivalent to model (18).
Step 5: However, the weight at this time does not necessarily satisfy . Thus, after normalization, the final public weight is obtained as
4.2. Decision Steps and Processes
The steps of the linguistic multiattribute decision-making method based on regret theory and minimax DEA are presented as follows:
Step 1: Considering decision-maker regret avoidance, the linguistic multiattribute evaluation matrix is processed according to Equations (5)–(9) and the perceived utility matrix is obtained.
Step 2: The optimal efficiency value of each decision-making unit according to Equations (10) and (11) are calculated. The analytic hierarchy process is used to perform subjective weighting to obtain the subjective weight and subjective efficiency value .
Step 3: Using LINGO software, the public weight of each attribute is calculated according to Equations (15)–(19).
Step 4: The comprehensive perceptual utility value of each decision-making unit is calculated through the perceptual utility matrix and the public weight ; the ranking is based on this.
5. Case Analysis
When a unit was evaluating and selecting cadres, experts evaluated 15 candidates according to work responsibility ability , scientific research assistance ability , project completion ability , thesis writing ability , awards , and academic communication ability . The chosen language evaluation scale was
The corresponding decision information is shown in Table 1.
5.1. Decision Step
Step 1: According to Equations (5)–(8), the language-type multiattribute evaluation matrix is processed, and the perceptual utility matrix is obtained, as shown in Table 2, where [42].
Step 2: Because the multiattribute decision-making problem does not contain input indicators, Lingo software was used to solve it according to Equation (10), and the optimal efficiency value of each decision-making unit was obtained. Using the analytic hierarchy process, the subjective weight of each decision-making unit was calculated as
Step 3: According to Equations (14)–(19), Lingo software was used to solve the problem, and the optimal public weight of each attribute was obtained as
Step 4: According to the perceptual utility matrix and public weight , the comprehensive perceptual utility value of each decision-making unit and its ranking can be obtained, as is presented in Table 3. The comprehensive perceived utility value of DMU4 was the largest, and the comprehensive perceived utility value of DMU3 was the smallest. Thus, considering decision-maker regret and avoidance psychology, the minimax-DEA model proposed in this study was used to determine DMU4 as the optimal solution.
5.2. Comparison of Methods
To further illustrate the effectiveness of the method, it was compared with methods used in other studies. The decision-making methods in the literature can be divided into two categories. Without considering the psychological factors of the decision-makers, the hesitant fuzzy language TOPSIS decision method proposed by Wu et al. [43] was used to analyze the examples in this study. The method proposed by Li et al. [21] was used to analyze the examples in this study using AHP and subjective and objective combination weighting.
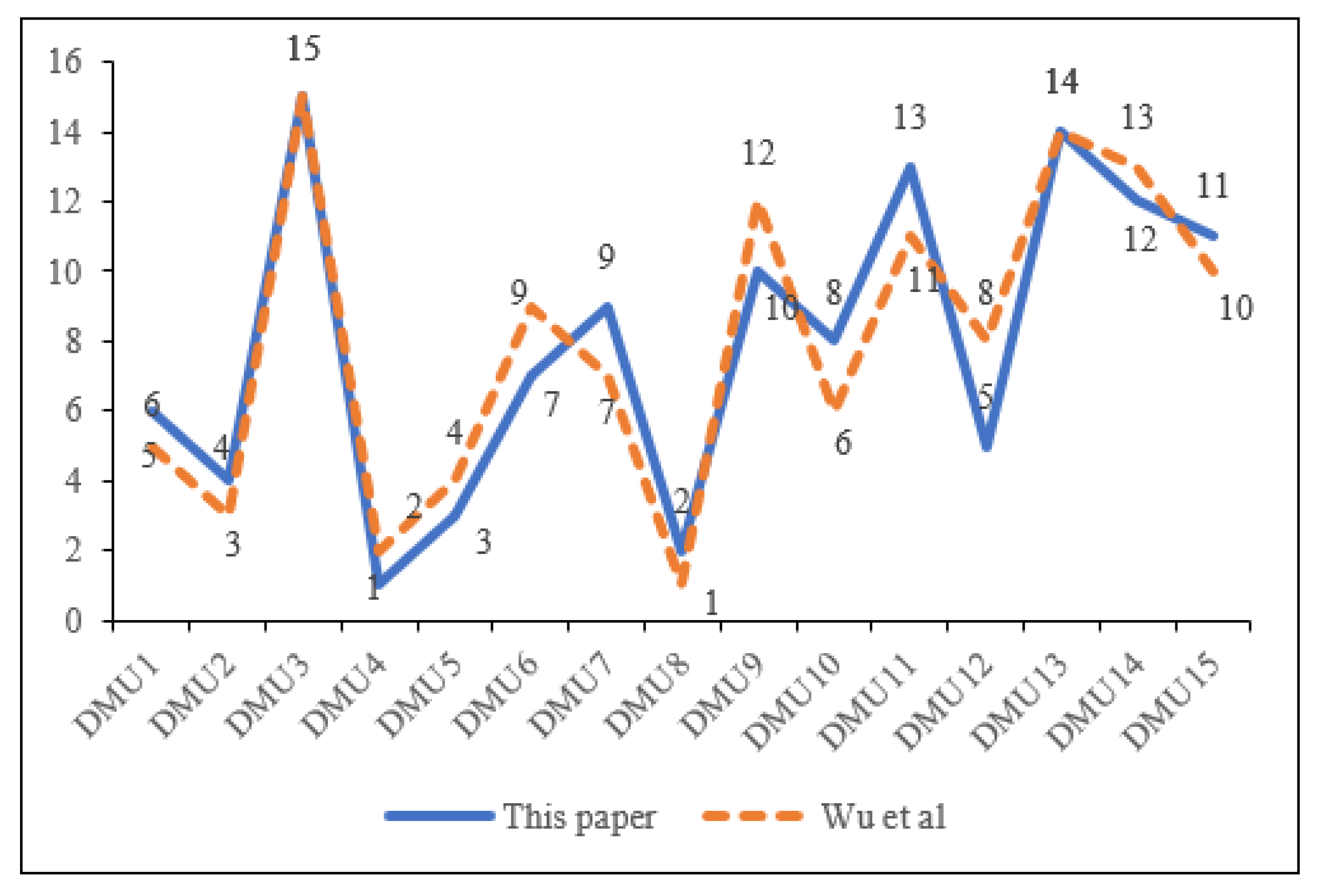
The sorting results of the method used in this study were compared with those of Wu et al. [43]. The sorting results are shown in Figure 1. Although the overall ranking results of the two methods slightly differed, the ranking of each decision did not significantly change. This is because Wu et al. [43] assumed that the decision maker was completely rational in the decision-making process, unlike the reality of decision-making to a certain extent. The method in this study considers the psychology of decision-maker regret and avoidance and simulates decision-making judgments based on the subjective psychological characteristics and objective preference information of decision makers in an actual environment for more realistic decision-making results.
Considering decision-maker regret avoidance, a comparative analysis was carried out according to the determination methods of different attribute weights. The final ranking results for the different decision-making methods are presented in Table 4.
It is observed from the table that the overall ranking results of the three methods are slightly different, but the optimal and least optimal schemes are consistent. We refer to a change in the ordering of more than three as a large change. Compared with the AHP, the decision-making units that underwent large changes were DMU1 and DMU9. The main reason for this is that AHP has strong subjective randomness and ignores the objective information of attributes, which leads to the ranking of DMU9 at the top and the low ranking of DMU6. The method used in this study was consistent with the ranking results of the subjective and objective combination weighting methods proposed by Li et al. [21]. Subjective arbitrariness was reduced, and decision-making preferences were considered; thus, the ranking results are more reasonable. In addition, the method used in this study considers the best intentions of each decision-making unit in the decision-making process, which makes the decision-making results more realistic.
In summary, the method proposed in this study incorporates decision-maker regret and avoidance psychology into the decision-making process, considers decision-maker subjective tendencies and the best intentions of each decision-making unit, and ensures weight calculation rationality, making the decision-making results more reliable.
6. Conclusions
For a multiattribute decision-making problem whose attribute value is language evaluation information, this study proposes a language-based multiattribute decision-making method based on regret theory and minimax-DEA. First, based on the decision-maker psychology of regret and avoidance, the perceived utility value of each decision-making unit was calculated using the language regret–joy value function. The subjective weighting and data envelopment analysis methods were used to calculate the subjective and optimal efficiency values of each decision-making unit, respectively. We considered the best efficiency as the reference point and the subjective efficiency as the decision preference to establish a minimax reference point model. By solving the model, a set of public weights that minimizes the difference between the efficiency values of all DMUs and their optimal efficiency values can be obtained, and the decision-making units can be sorted and selected.
The main features of the method are as follows: (1) the regret avoidance of the decision maker is incorporated into the linguistic multiattribute decision-making method, which considers the influence of decision-maker psychological factors on decision making and, to a certain extent, makes the decision-making results more realistic. (2) Regret theory is effectively cross-fertilized using the data envelopment analysis method and the minimal–extremely large reference point method, and a new type of linguistic multiattribute decision-making method is proposed that provides a new path for weight determination in multiattribute decision-making problems. (3) A new goal-planning model is constructed based on the data envelopment analysis method and the minimal–extremely large reference point method, considering the subjective tendency of the decision maker and the best intentions of all decision units, ensuring the rationality of the weight calculation and producing more reliable decision results.
This study only considered a single-person decision-making problem with attribute values in linguistic terms. Multiattribute group decision-making problems with uncertain data including attribute values, fuzzy numbers, and interval numbers will be our next research focus.
Funding
This research received no external funding.
Data Availability Statement
All data used to support the study are available from the corresponding author upon request.
Conflicts of Interest
The authors have no conflict of interest.
References
- Li, T.; Zhang, L. Multiple-attribute group decision-making method based on intuitionistic multiplicative linguistic information. Comput. Appl. Math. 2022, 41, 209. [Google Scholar] [CrossRef]
- Xue, W.; Xu, Z.; Mi, X. Solving hesitant fuzzy linguistic matrix game problems for multiple attribute decision making with prospect theory. Comput. Ind. Eng. 2021, 161, 107619. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Xu, Z. Uncertain linguistic aggregation operators based approach to multiple attribute group decision making under uncertain linguistic environment. Inf. Sci. 2004, 168, 171–184. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Z.; Xu, Z.; Gou, X.; Herrera, F. Score function based on concentration degree for probabilistic linguistic term sets: An application to TOPSIS and VIKOR. Inf. Sci. 2021, 551, 270–290. [Google Scholar] [CrossRef]
- Cheng, Y.; Li, Y.; Yang, J. Multi-attribute decision-making method based on a novel distance measure of linguistic intuitionistic fuzzy sets. J. Intell. Fuzzy Syst. 2021, 40, 1147–1160. [Google Scholar] [CrossRef]
- Zhu, S.; Huang, J.; Xu, Y. A consensus model for group decision making with self-confident linguistic preference relations. Int. J. Intell. Syst. 2021, 36, 6360–6386. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, H.; Cheng, Y.; Qin, L. Project evaluation method using non-formatted text information based on multi-granular linguistic labels. Inf. Fusion 2015, 24, 93–107. [Google Scholar] [CrossRef]
- Li, P.; Peng, H. A Novel IVPLTS Decision Method Based on Regret Theory and Cobweb Area Model. Math. Probl. Eng. 2020, 2020, 5649525. [Google Scholar] [CrossRef]
- Mao, X.; Wu, M.; Dong, J.; Wan, S.; Jin, Z. A new method for probabilistic linguistic multi-attribute group decision making: Application to the selection of financial technologies. Appl. Soft Comput. 2019, 77, 155–175. [Google Scholar] [CrossRef]
- Somasundaram, J.; Diecidue, E. Regret theory and risk attitudes. J. Risk Uncertain. 2018, 55, 147–175. [Google Scholar] [CrossRef]
- Wang, H.; Pan, X.; Yan, J.; Yao, J.; He, S. A projection-based regret theory method for multi-attribute decision making under interval type-2 fuzzy sets environment. Inf. Sci. 2020, 512, 108–122. [Google Scholar] [CrossRef]
- Xu, Q.; Zhang, Y.; Zhang, J.; Lv, X. Improved TOPSIS Model and its Application in the Evaluation of NCAA Basketball Coaches. Mod. Appl. Sci. 2015, 9, 259. [Google Scholar] [CrossRef]
- Solangi, Y.; Cheng, L.; Shah, S. Assessing and overcoming the renewable energy barriers for sustainable development in Pakistan: An integrated AHP and fuzzy TOPSIS approach. Renew. Energy 2021, 173, 209–222. [Google Scholar] [CrossRef]
- Belton, I.; MacDonald, A.; Wright, G.; Hamlin, I. Improving the practical application of the Delphi method in group-based judgment: A six-step prescription for a well-founded and defensible process. Technol. Forecast. Soc. Change 2019, 147, 72–82. [Google Scholar] [CrossRef]
- Omrani, H.; Alizadeh, A.; Naghizadeh, F. Incorporating decision makers’ preferences into DEA and common weight DEA models based on the best-worst method (BWM). Soft Comput. 2020, 24, 3989–4002. [Google Scholar] [CrossRef]
- Duo, T.; Guo, J.; Wu, F.; Zhai, R. Application of entropy-based multi-attribute decision-making method to structured selection of settlement. J. Vis. Commun. Image Represent. 2019, 58, 220–232. [Google Scholar]
- Dettmar, B.; Peltier, C.; Schlich, P. Beyond principal component analysis (PCA) of product means: Toward a psychometric view on sensory profiling data. J. Sens. Stud. 2019, 35, e12555. [Google Scholar] [CrossRef]
- Shuang, Y.; Ding, Y. Combination Weighting Method of Engineering Disciplines Evaluation Index Based on Soft Computing. IETE J. Res. 2022. [Google Scholar] [CrossRef]
- Merigo, J.; Palacios-Marques, D.; Zeng, S. Subjective and objective information in linguistic multi-criteria group decision making. Eur. J. Oper. Res. 2016, 248, 522–531. [Google Scholar] [CrossRef]
- Li, G.; Li, J.; Sun, X.; Wu, D. Research on a combined method of subjective-objective weighting based on the ordered information and intensity information. Chin. J. Manag. Sci. 2017, 25, 179–187. [Google Scholar]
- Correa Machado, A.M.; Ekel, P.I.; Libório, M.P. Goal-based participatory weighting scheme: Balancing objectivity and subjectivity in the construction of composite indicators. Qual. Quant. 2022, 57, 4387–4407. [Google Scholar] [CrossRef]
- Becker, W.; Saisana, M.; Paruolo, P.; Vandecasteele, I. Weights and importance in composite indicators: Closing the gap. Ecol. Indic. 2017, 80, 12–22. [Google Scholar] [CrossRef] [PubMed]
- Greco, S.; Ishizaka, A.; Tasiou, M.; Torrisi, G. On the Methodological Framework of Composite Indices: A Review of the Issues of Weighting, Aggregation, and Robustness. Soc. Indic. Res. 2019, 141, 61–94. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.; Rhodes, E. Measuring the efficiency of decision making units. Eur. J. Oper. Res. 1978, 2, 429–444. [Google Scholar] [CrossRef]
- Wang, Z.; Hao, H.; Gao, F.; Zhang, Q.; Zhang, J.; Zhou, Y. Multi-attribute decision making on reverse logistics based on DEA-TOPSIS: A study of the Shanghai End-of-life vehicles industry. J. Clean. Prod. 2019, 214, 730–737. [Google Scholar] [CrossRef]
- Yang, J. Minimax reference point approach and its application for multiobjective optimisation. Eur. J. Oper. Res. 2000, 126, 541–556. [Google Scholar] [CrossRef]
- Memon, M.; Lee, Y.; Mari, S. Group multi-criteria supplier selection using combined grey systems theory and uncertainty theory. Expert Syst. Appl. 2015, 42, 7951–7959. [Google Scholar] [CrossRef]
- Song, W.; Zhu, J. Three-reference-point decision-making method with incomplete weight information considering independent and interactive characteristics. Inf. Sci. 2019, 503, 148–168. [Google Scholar] [CrossRef]
- Zhou, W.; Xu, Z. Generalized asymmetric linguistic term set and its application to qualitative decision making involving risk appetites. Eur. J. Oper. Res. 2016, 254, 610–621. [Google Scholar] [CrossRef]
- Bell, D. Regret in decision making under uncertainty. Oper. Res. 1982, 30, 961–981. [Google Scholar] [CrossRef]
- Loomes, G.; Sugden, R. Regret theory: An alternative theory of rational choice under uncertainty. Econ. J. 1982, 125, 513–532. [Google Scholar] [CrossRef]
- Quiggin, J. Regret theory with general choice sets. J. Risk Uncertainy 1994, 8, 153–165. [Google Scholar] [CrossRef]
- Bleichrodt, H.; Cillo, A.; Diecidue, E. A Quantitative Measurement of Regret Theory. Manag. Sci. 2010, 56, 161–175. [Google Scholar] [CrossRef]
- Tang, G.; Long, J.; Gu, X.; Chiclana, F.; Liu, P.; Wang, F. Interval type-2 fuzzy programming method for risky multicriteria decision-making with heterogeneous relationship. Inf. Sci. 2021, 584, 184–211. [Google Scholar] [CrossRef]
- Wang, W.; Tian, G.; Zhang, T.; Jabarullah, N.; Li, F.; Fathollahi-Fard, A. Scheme selection of design for disassembly (DFD) based on sustainability: A novel hybrid of interval 2-tuple linguistic intuitionistic fuzzy numbers and regret theory. J. Clean. Prod. 2021, 281, 124724. [Google Scholar] [CrossRef]
- Xu, Z. Linguistic Decision Making: Theory and Methods; Science Press: Beijing, China, 2012. [Google Scholar]
- Yang, G.; Yang, J.; Xu, D. A three-stage hybrid approach for weight assignment in MADM. Omega-Int. J. Manag. Sci. 2017, 71, 93–105. [Google Scholar] [CrossRef]
- Adolphson, D.; Cornia, G.; Walters, L. A United Frame Work for Classifying DEA Models; Pergamon Press: New York, NY, USA, 1991. [Google Scholar]
- Liu, W.; Zhang, D.; Meng, W.; Li, X.; Xu, F. A study of DEA models without explicit inputs. Omega-Int. J. Manag. Sci. 2011, 39, 472–480. [Google Scholar] [CrossRef]
- Yang, J.; Xu, D. Interactive minimax optimisation for integrated performance analysis and resource planning. Comput. Oper. Res. 2014, 46, 78–90. [Google Scholar] [CrossRef]
- Liao, H.; Zhang, Z.; Xu, Z.; Banaitis, A. A Heterogeneous Regret-Theory-Based Method with Choquet Integral to Multiattribute Reverse Auction. IEEE Trans. Eng. Manag. 2022, 69, 2248–2259. [Google Scholar] [CrossRef]
- Wu, P.; Wu, Q.; Zhou, L. Hesitant fuzzy linguistic TOPSIS decision making method based on multi-objective attribute weight optimization. Oper. Res. Manag. Sci. 2021, 30, 42–47. [Google Scholar]
Figure 1.
The sorting results of both methods [43].
Figure 1.
The sorting results of both methods [43].

{kind=link}
Table 1.
Linguistic multiattribute evaluation matrix.
| Personnel | Evaluation Metrics | |||||
|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | |
| DMU1 | S4/3 | S4/3 | S−1/2 | S−1/2 | S−1/2 | S1/2 |
| DMU2 | S4/3 | S1/2 | S1/2 | S4/3 | S−4/3 | S−1/2 |
| DMU3 | S0 | S1/2 | S−4/3 | S−4/3 | S1/2 | S−4/3 |
| DMU4 | S4/3 | S1/2 | S4/3 | S1/2 | S−1/2 | S−1/2 |
| DMU5 | S4/3 | S4/3 | S1/2 | S−4/3 | S1/2 | S0 |
| DMU6 | S4/3 | S−1/2 | S0 | S0 | S1/2 | S−4/3 |
| DMU7 | S4/3 | S0 | S−1/2 | S0 | S0 | S−1/2 |
| DMU8 | S4/3 | S4/3 | S1/2 | S−1/2 | S−1/2 | S4/3 |
| DMU9 | S1/2 | S0 | S4/3 | S−4/3 | S−4/3 | S−1/2 |
| DMU10 | S4/3 | S1/2 | S0 | S−1/2 | S−1/2 | S−1/2 |
| DMU11 | S4/3 | S1/2 | S0 | S−4/3 | S−4/3 | S0 |
| DMU12 | S4/3 | S0 | S4/3 | S−4/3 | S−4/3 | S0 |
| DMU13 | S4/3 | S−1/2 | S−1/2 | S−4/3 | S−1/2 | S−1/2 |
| DMU14 | S4/3 | S−1/2 | S0 | S−4/3 | S−1/2 | S0 |
| DMU15 | S4/3 | S0 | S1/2 | S−4/3 | S−4/3 | S0 |
Table 2.
Perceived utility matrix P.
| Personnel | Evaluation Metrics | |||||
|---|---|---|---|---|---|---|
| C1 | C2 | C3 | C4 | C5 | C6 | |
| DMU1 | 0.811 | 0.834 | 0.413 | 0.413 | 0.455 | 0.669 |
| DMU2 | 0.811 | 0.630 | 0.669 | 0.871 | 0.230 | 0.413 |
| DMU3 | 0.479 | 0.630 | 0.187 | 0.187 | 0.708 | 0.187 |
| DMU4 | 0.811 | 0.630 | 0.871 | 0.669 | 0.455 | 0.413 |
| DMU5 | 0.811 | 0.834 | 0.669 | 0.187 | 0.708 | 0.543 |
| DMU6 | 0.811 | 0.373 | 0.543 | 0.543 | 0.708 | 0.187 |
| DMU7 | 0.811 | 0.503 | 0.413 | 0.543 | 0.583 | 0.413 |
| DMU8 | 0.811 | 0.834 | 0.669 | 0.413 | 0.455 | 0.871 |
| DMU9 | 0.606 | 0.503 | 0.871 | 0.187 | 0.230 | 0.413 |
| DMU10 | 0.811 | 0.630 | 0.543 | 0.413 | 0.455 | 0.413 |
| DMU11 | 0.811 | 0.630 | 0.543 | 0.187 | 0.230 | 0.543 |
| DMU12 | 0.811 | 0.503 | 0.871 | 0.187 | 0.230 | 0.543 |
| DMU13 | 0.811 | 0.373 | 0.413 | 0.187 | 0.455 | 0.413 |
| DMU14 | 0.811 | 0.373 | 0.543 | 0.187 | 0.455 | 0.543 |
| DMU15 | 0.811 | 0.503 | 0.669 | 0.187 | 0.230 | 0.543 |
Table 3.
Comprehensive perceived utility value and ranking results.
| Personnel | Subjective Efficiency Value | Voice | Comprehensive Utility Value | Rank |
|---|---|---|---|---|
| Oi | gi | P * | ||
| DMU1 | 0.523 | 0.064 | 0.558 | 6 |
| DMU2 | 0.686 | 0.084 | 0.610 | 4 |
| DMU3 | 0.286 | 0.035 | 0.352 | 15 |
| DMU4 | 0.728 | 0.090 | 0.671 | 1 |
| DMU5 | 0.569 | 0.070 | 0.614 | 3 |
| DMU6 | 0.553 | 0.068 | 0.542 | 7 |
| DMU7 | 0.524 | 0.065 | 0.532 | 9 |
| DMU8 | 0.642 | 0.079 | 0.662 | 2 |
| DMU9 | 0.557 | 0.069 | 0.516 | 10 |
| DMU10 | 0.538 | 0.066 | 0.537 | 8 |
| DMU11 | 0.481 | 0.059 | 0.486 | 13 |
| DMU12 | 0.602 | 0.074 | 0.569 | 5 |
| DMU13 | 0.422 | 0.052 | 0.444 | 14 |
| DMU14 | 0.485 | 0.060 | 0.501 | 12 |
| DMU15 | 0.524 | 0.065 | 0.512 | 11 |
Table 4.
The sorting results of both methods.
| Personnel | This Study | Li et al. [21] | AHP |
|---|---|---|---|
| DMU1 | 6 | 6 | 11 |
| DMU2 | 4 | 2 | 2 |
| DMU3 | 15 | 15 | 15 |
| DMU4 | 1 | 1 | 1 |
| DMU5 | 3 | 4 | 5 |
| DMU6 | 7 | 5 | 7 |
| DMU7 | 9 | 8 | 9 |
| DMU8 | 2 | 3 | 3 |
| DMU9 | 10 | 10 | 6 |
| DMU10 | 8 | 9 | 8 |
| DMU11 | 13 | 12 | 13 |
| DMU12 | 5 | 7 | 4 |
| DMU13 | 14 | 14 | 14 |
| DMU14 | 12 | 13 | 12 |
| DMU15 | 11 | 11 | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hu, J. Linguistic Multiple-Attribute Decision Making Based on Regret Theory and Minimax-DEA. Mathematics 2023, 11, 4259. https://doi.org/10.3390/math11204259
AMA Style
Hu J. Linguistic Multiple-Attribute Decision Making Based on Regret Theory and Minimax-DEA. Mathematics. 2023; 11(20):4259. https://doi.org/10.3390/math11204259
Chicago/Turabian StyleHu, Jinyi. 2023. "Linguistic Multiple-Attribute Decision Making Based on Regret Theory and Minimax-DEA" Mathematics 11, no. 20: 4259. https://doi.org/10.3390/math11204259
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.