A Comprehensive Review and Analysis of Deep Learning-Based Medical Image Adversarial Attack and Defense

 ,
, 
 , , , and
, , , and 
Abstract
:1. Introduction
- This review article presents a, to date, comprehensive analysis of adversarial attack and defense strategies in the context of medical image analysis including the type of attack and defense tactics together with a cutting-edge medical analysis model for adversarial attack and defense.
- In addition, a comprehensive experiment was carried out to support the findings of this survey including classification and segmentation tasks.
- We conclude by identifying current issues and offering insightful recommendations for future research.
2. Review Background
2.1. Medical Image Analysis
2.2. Adversarial Attack and Defense
3. Overview of Medical Image Adversarial Attack and Defense
- A.
- Medical Image Adversarial Attack and Defense Classification Task
- B.
- Medical Image Adversarial Attack and Defense Segmentation Task
- C.
- Medical Image Adversarial Attack and Defense Detection Task
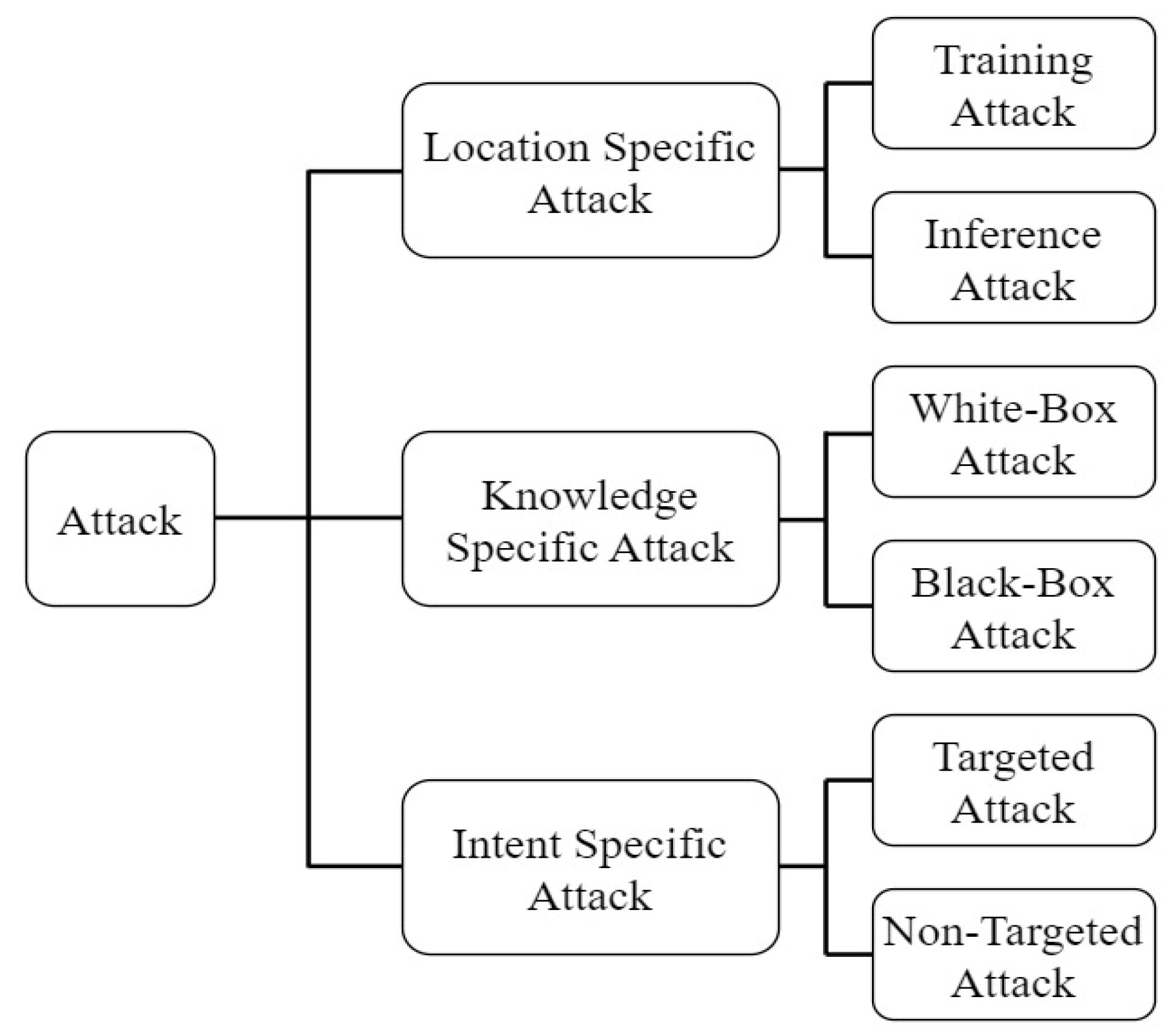
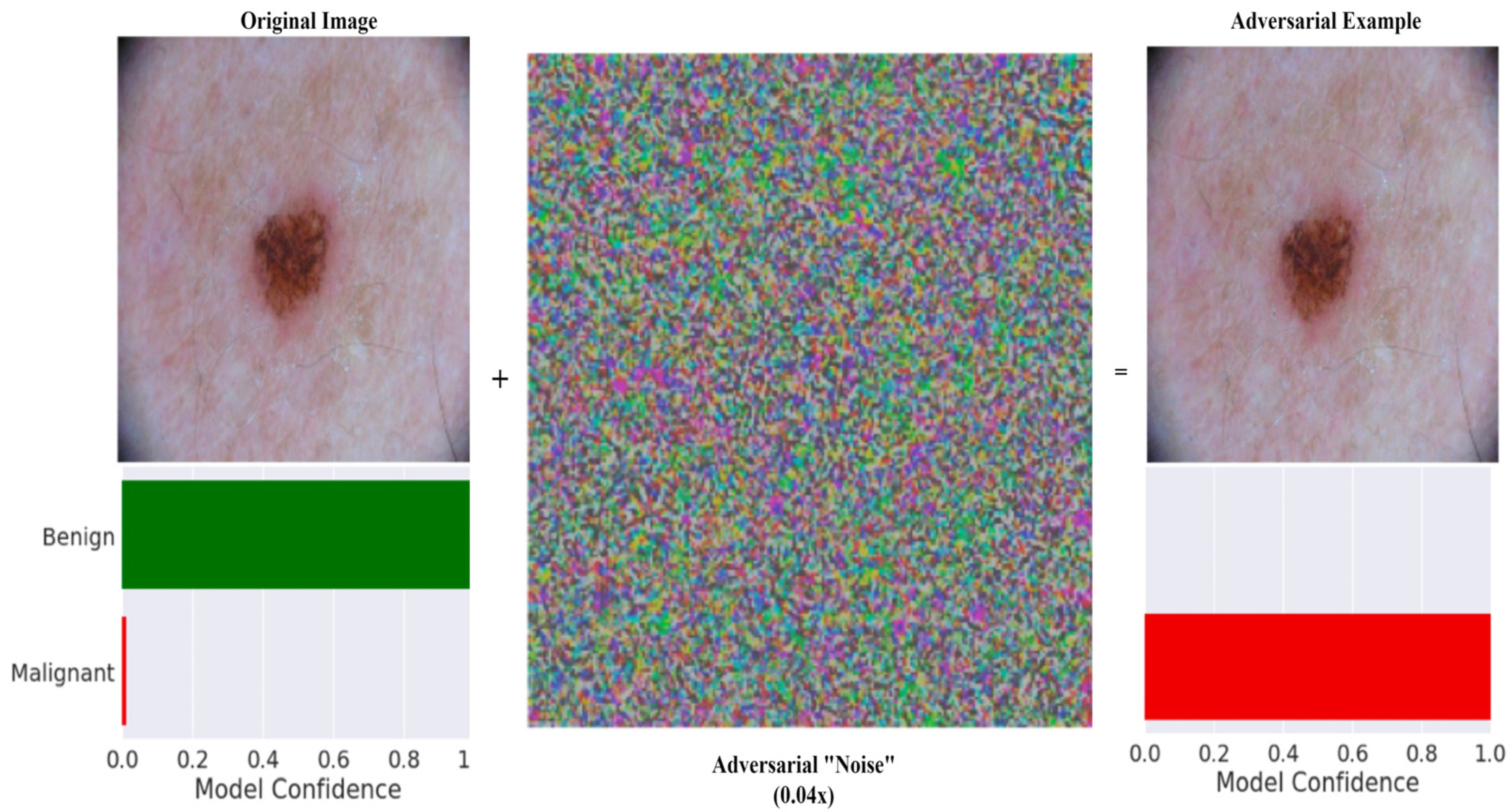
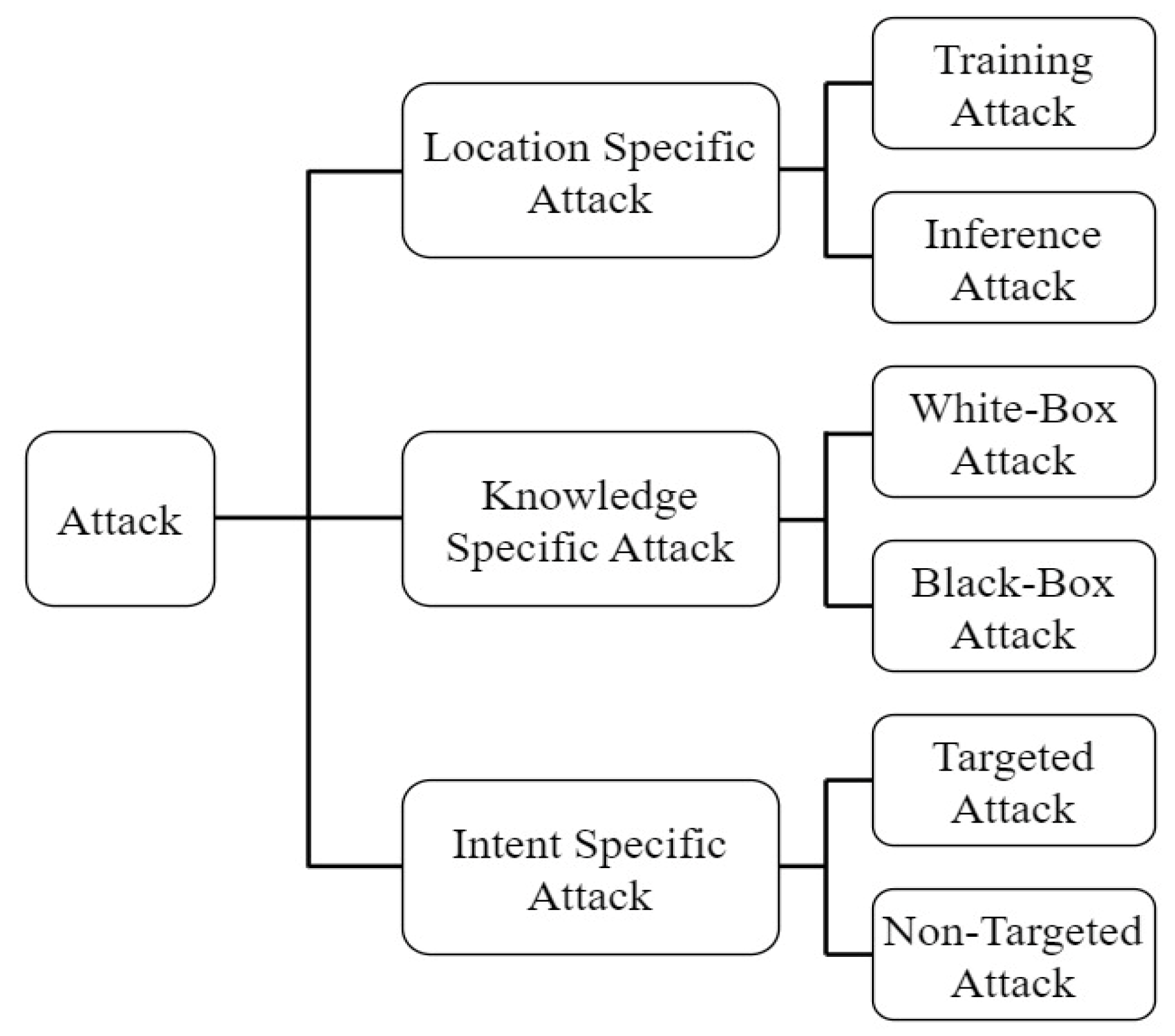
3.1. Medical Imaging Adversarial Attacks
3.1.1. White Box Attacks
3.1.2. Black-Box Attacks
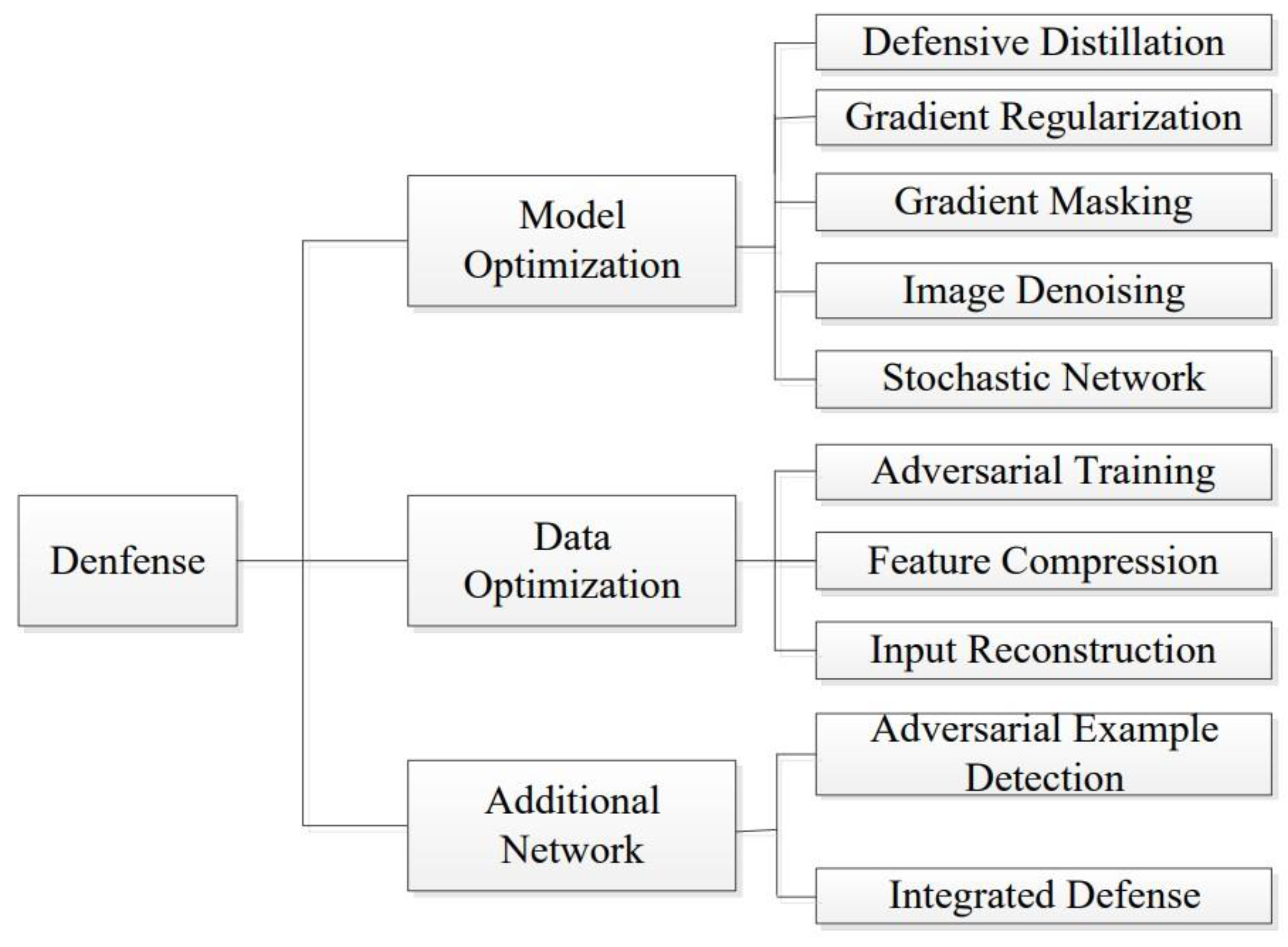
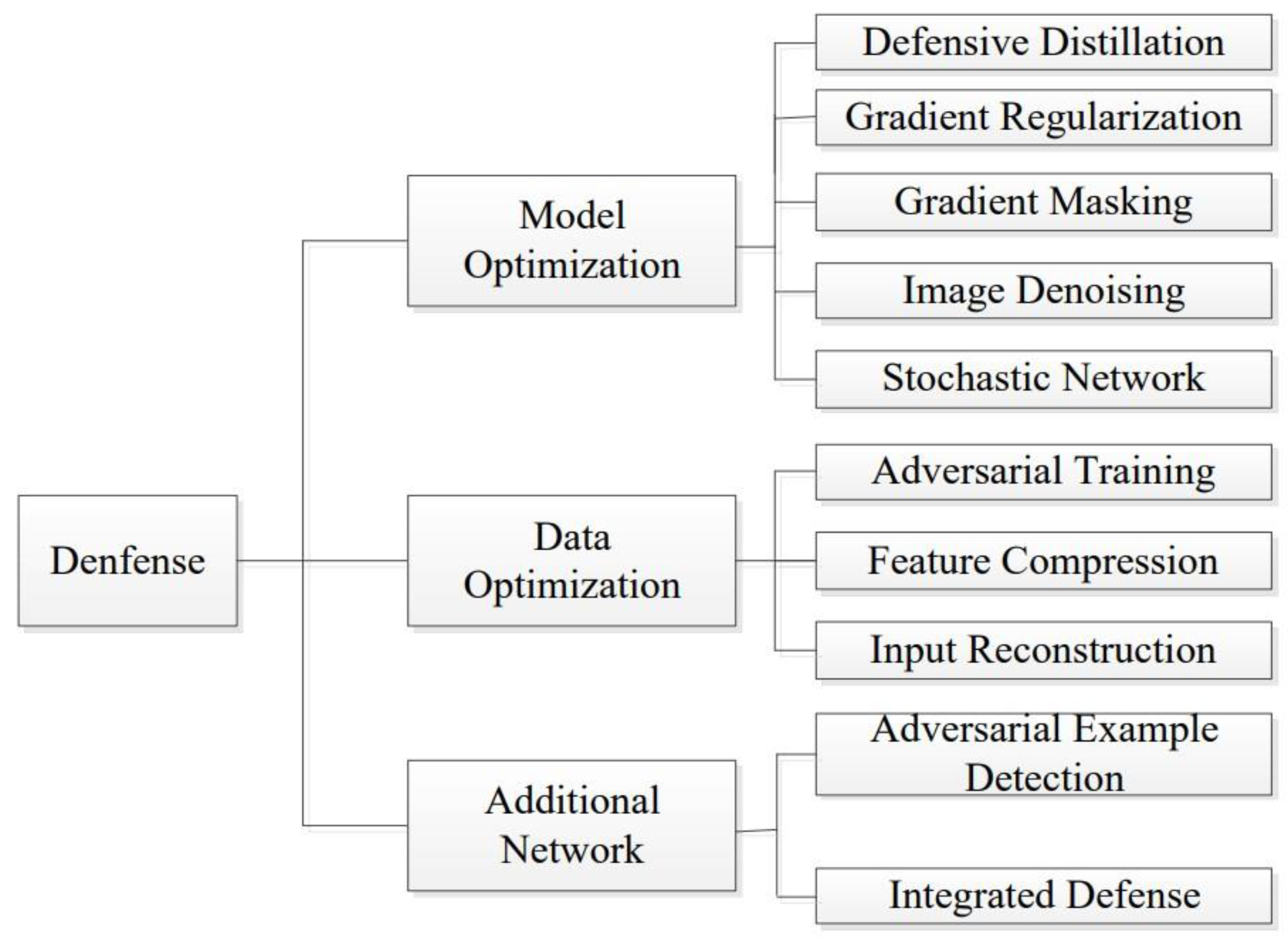
3.2. Medical Adversarial Defense
3.2.1. Image Level Preprocessing
3.2.2. Feature Enhancement
3.2.3. Adversary Training
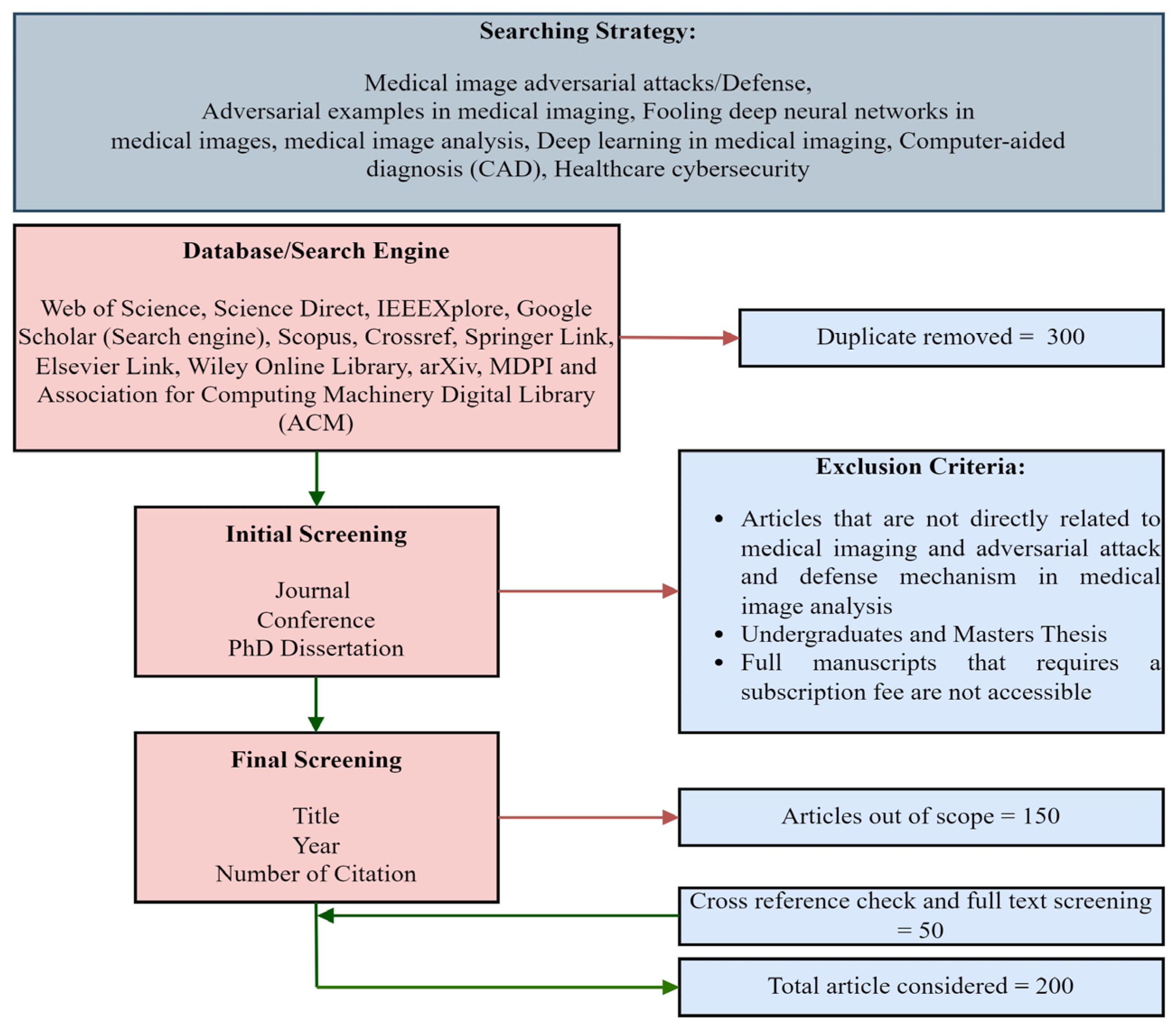
4. Experiment
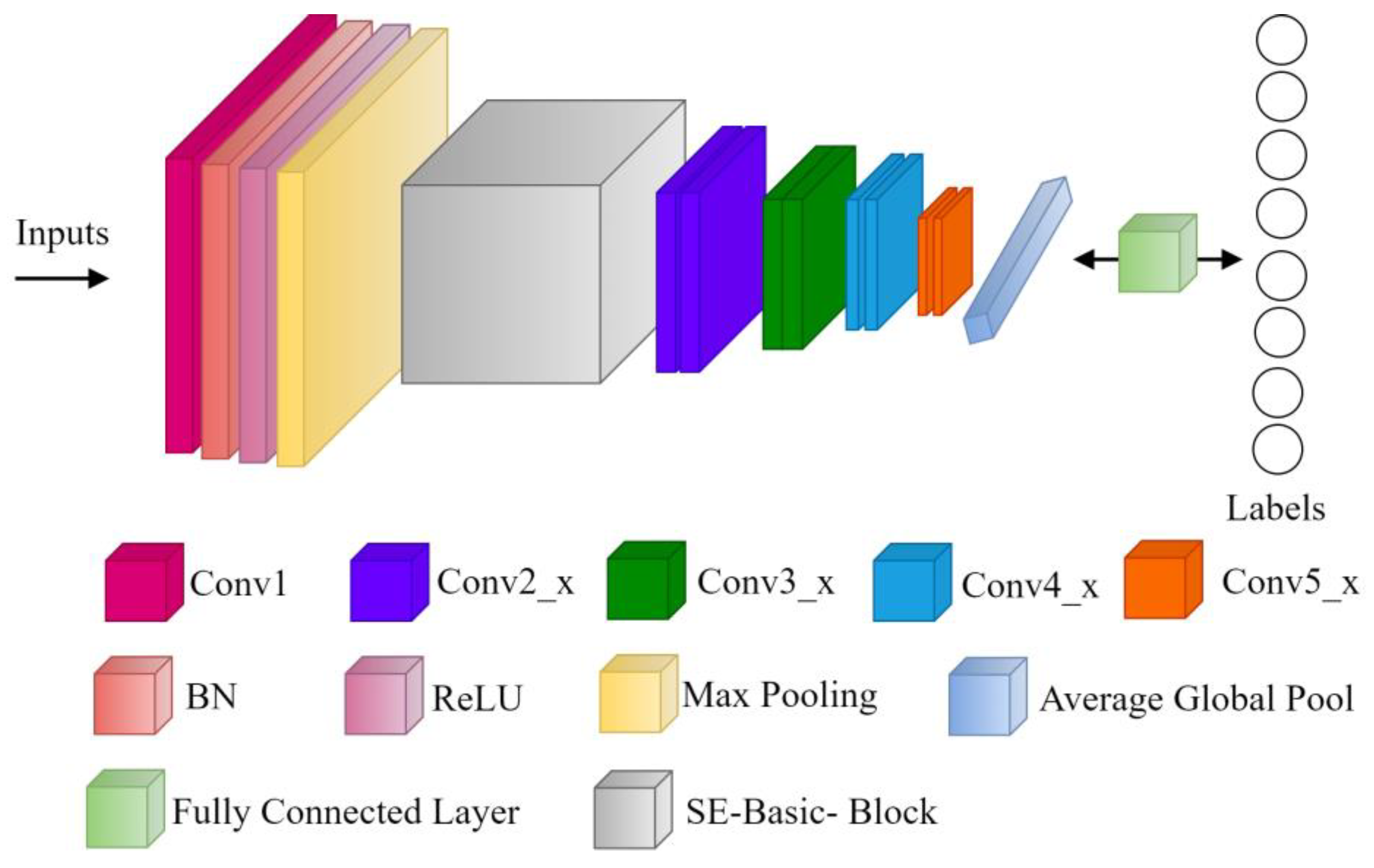
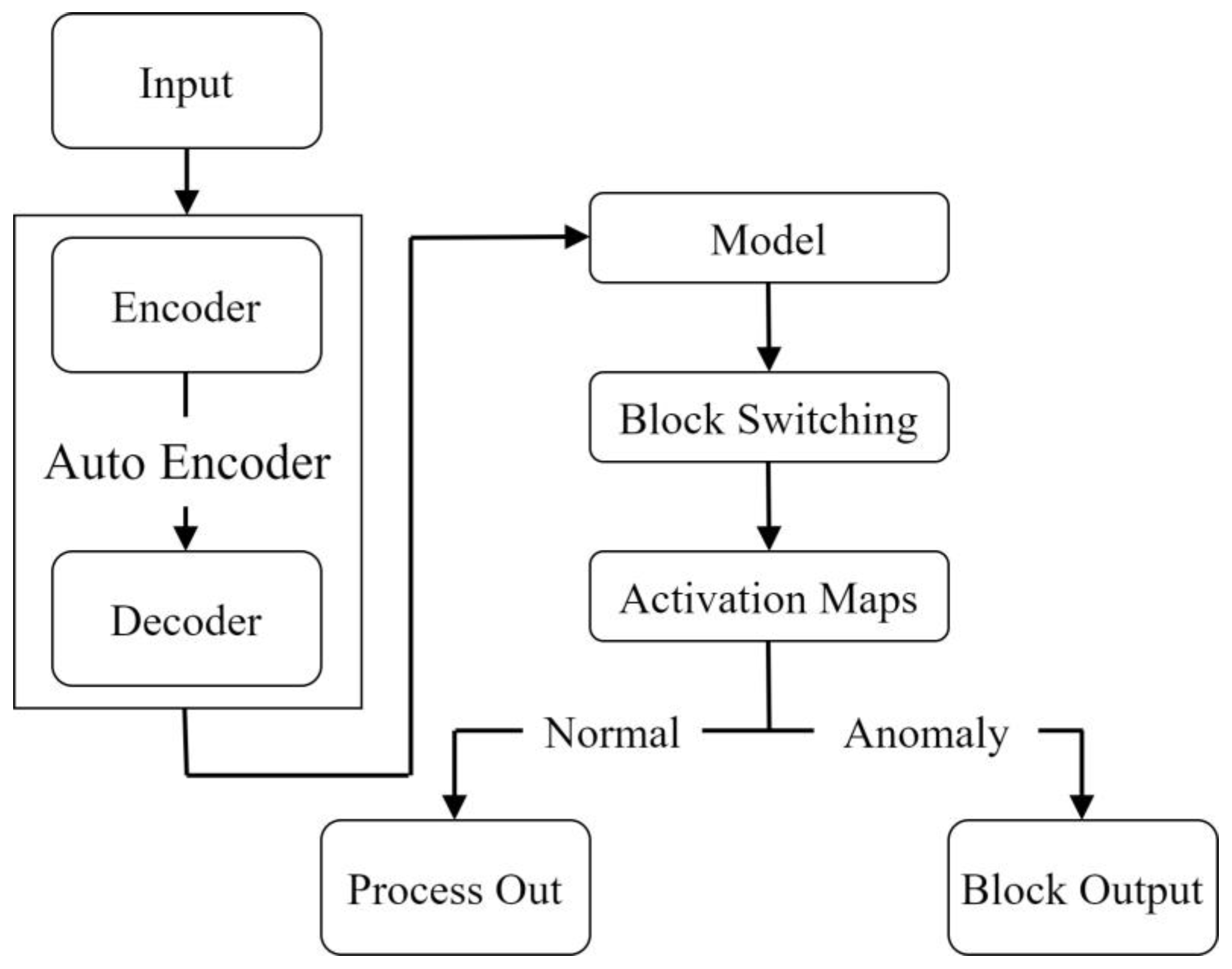
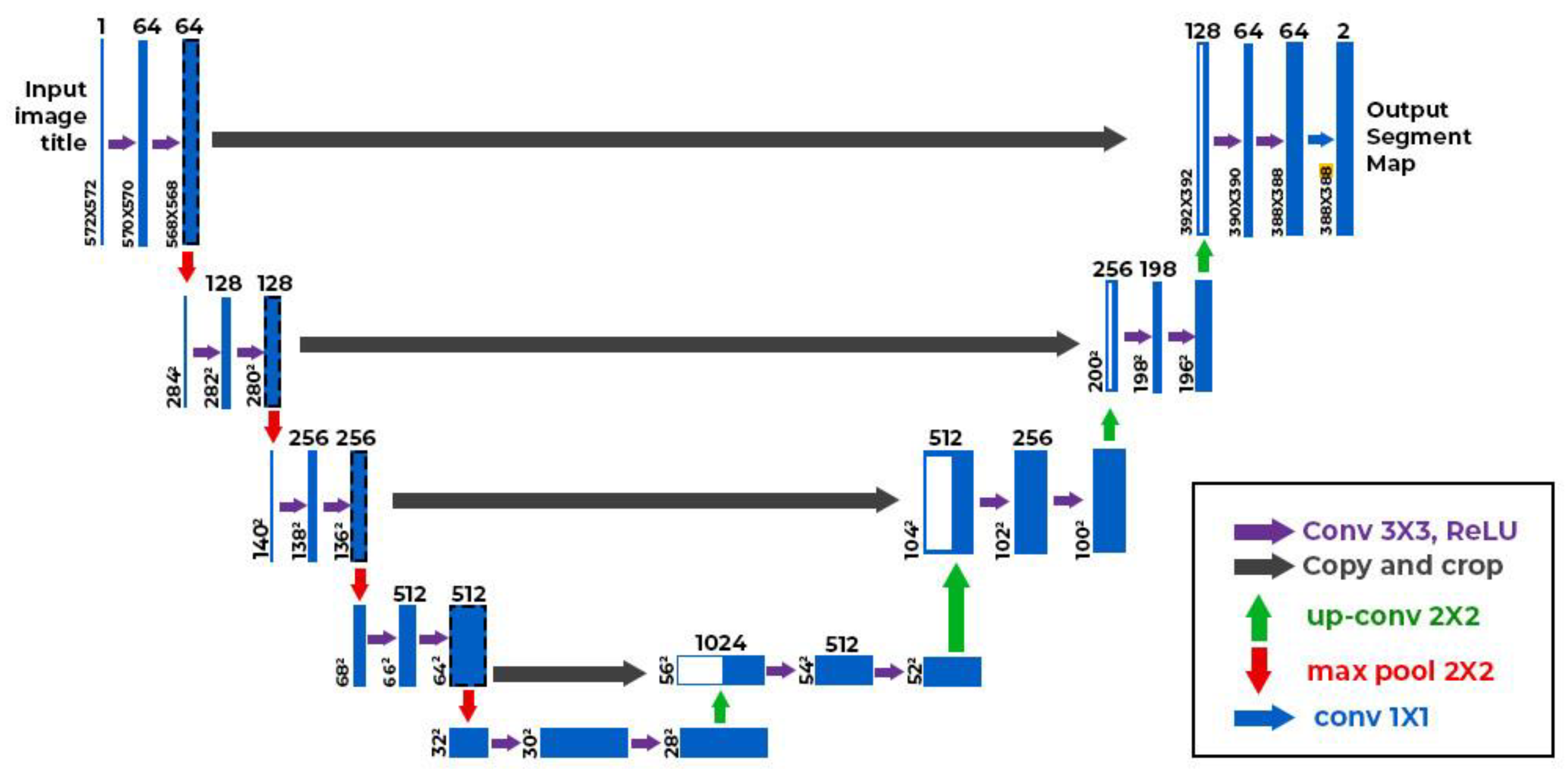
4.1. Implemented Attack and Defense Model
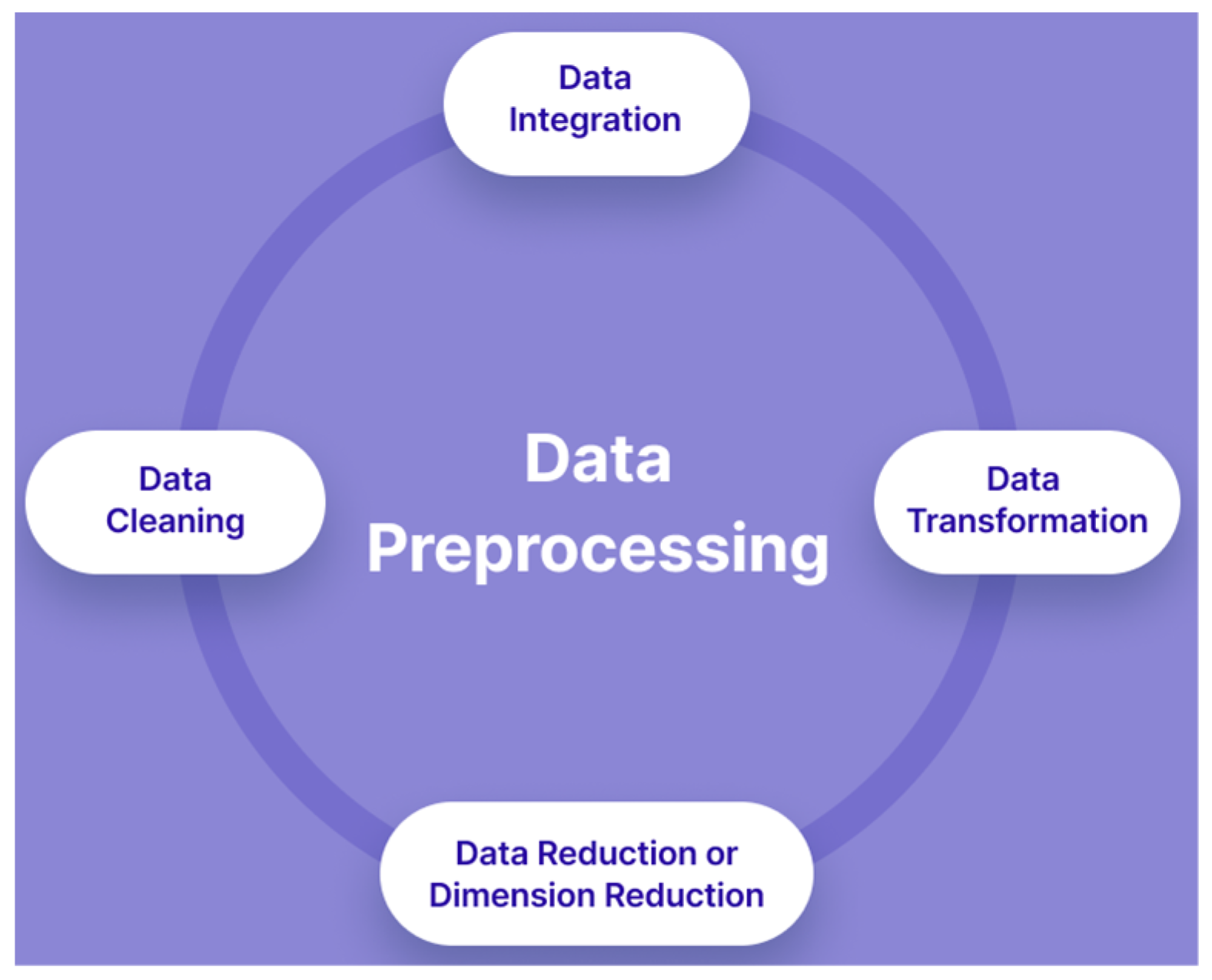
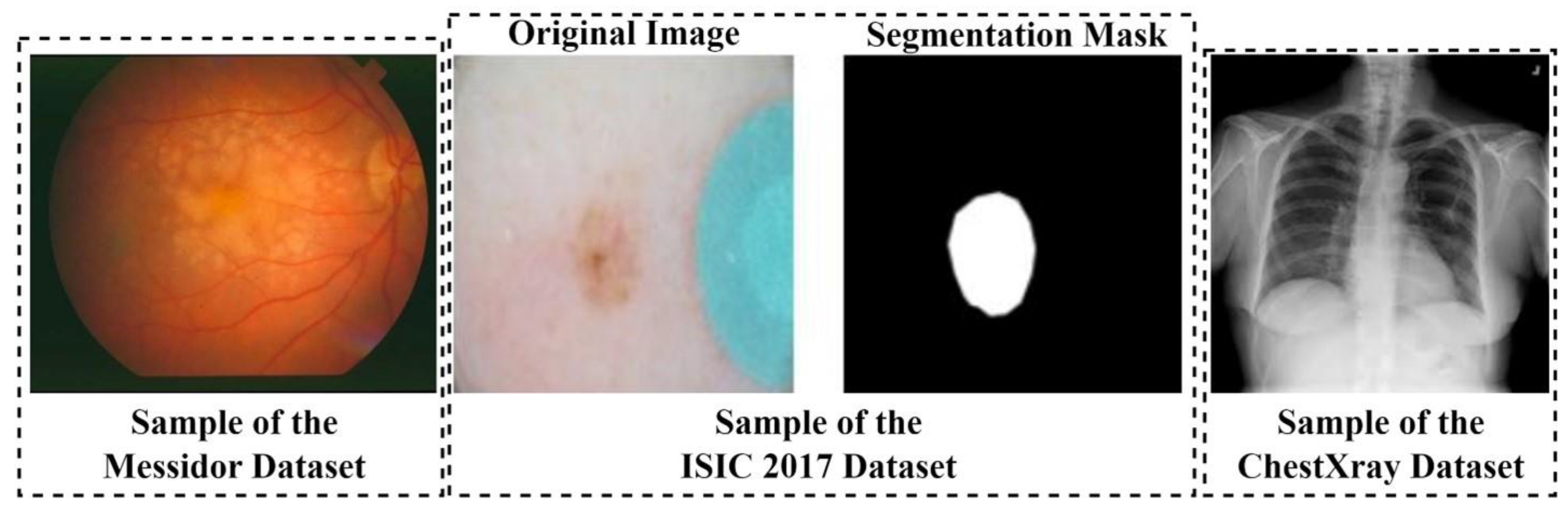
4.2. Dataset and Data Preprocessing
4.3. Evaluation Metrics
4.4. Results and Analysis
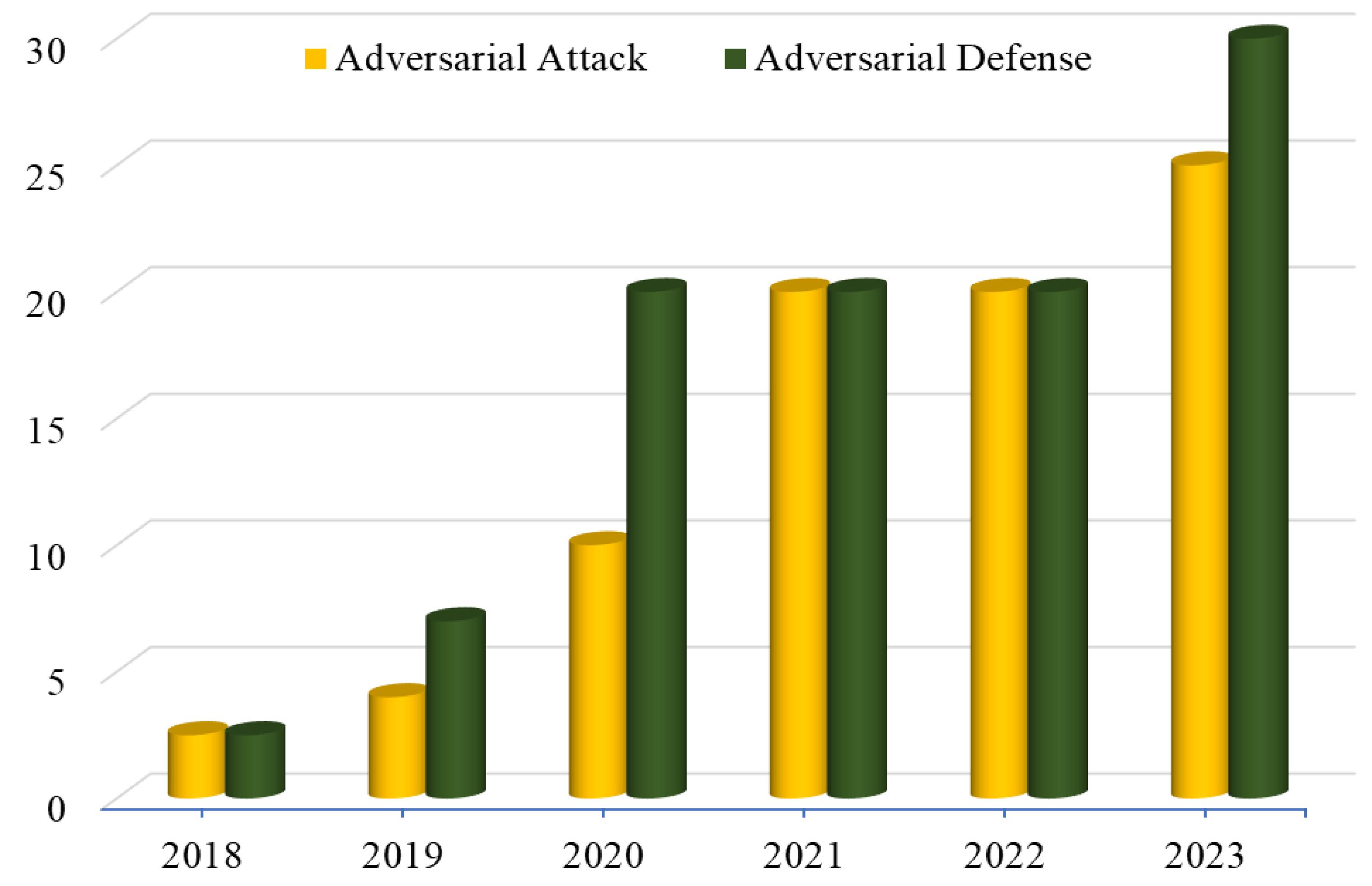
4.4.1. Adversary Attack Experimental Results
4.4.2. Adversary Defense Experimental Results
5. Discussion
- A.
- Dataset and Labeling
- B.
- Computational Resources
- C.
- Robustness against Target Attacks
- D.
- Evaluation of Transferability and Adaptability
- E.
- Interpretability and Explainability
- F.
- Real-time Detection and Response
- G.
- Adversarial Attacks in Multi-modal Fusion
- H.
- Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition; Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Zemskova, V.E.; He, T.L.; Wan, Z.; Grisouard, N. A deep-learning estimate of the decadal trends in the Southern Ocean carbon storage. Nat. Commun. 2022, 13, 4056. [Google Scholar] [CrossRef] [PubMed]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Anaam, A.; Al-antari, M.A.; Hussain, J.; Abdel Samee, N.; Alabdulhafith, M.; Gofuku, A. Deep Active Learning for Automatic Mitotic Cell Detection on HEp-2 Specimen Medical Images. Diagnostics 2023, 13, 1416. [Google Scholar] [CrossRef]
- Ge, Z.; Demyanov, S.; Chakravorty, R.; Bowling, A.; Garnavi, R. Skin disease recognition using deep saliency features and multimodal learning of dermoscopy and clinical images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention−MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; pp. 250–258. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Y.; Xia, Y.; Shen, C. Attention Residual Learning for Skin Lesion Classification. IEEE Trans. Med. Imaging 2019, 38, 2092–2103. [Google Scholar] [CrossRef] [PubMed]
- Pereira, S.; Pinto, A.; Alves, V.; Silva, C.A. Brain tumor segmentation using convolutional neural networks in MRI images. IEEE Trans. Med. Imaging 2016, 35, 1240–1251. [Google Scholar] [CrossRef] [PubMed]
- Muhammad, K.; Khan, S.; Del Ser, J.; Albuquerque, V.H.C.D. Deep Learning for Multigrade Brain Tumor Classification in Smart Healthcare Systems: A Prospective Survey. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 507–522. [Google Scholar] [CrossRef] [PubMed]
- Retinal Physician—Artificial Intelligence for the Screening of Diabetic Retinopathy. Available online: https://www.retinalphysician.com/issues/2022/november-december-2022/artificial-intelligence-for-the-screening-of-diabe (accessed on 20 August 2023).
- Koohi-Moghadam, M.; Wang, H.; Wang, Y.; Yang, X.; Li, H.; Wang, J.; Sun, H. Predicting disease-associated mutation of metal-binding sites in proteins using a deep learning approach. Nat. Mach. Intell. 2019, 1, 561–567. [Google Scholar] [CrossRef]
- Piloto, L.S.; Weinstein, A.; Battaglia, P.; Botvinick, M. Intuitive physics learning in a deep-learning model inspired by developmental psychology. Nat. Hum. Behav. 2022, 6, 1257–1267. [Google Scholar] [CrossRef]
- Paschali, M.; Conjeti, S.; Navarro, F.; Navab, N. Generalizability vs. robustness: Investigating medical imaging networks using adversarial examples. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2018; Springer: Cham, Switzerland, 2018; Volume 11070, pp. 493–501. [Google Scholar] [CrossRef]
- Finlayson, S.G.; Bowers, J.D.; Ito, J.; Zittrain, J.L.; Beam, A.L.; Kohane, I.S. Adversarial attacks on medical machine learning. Science 2019, 363, 1287–1289. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199v4. [Google Scholar]
- Wang, Z.; Shu, X.; Wang, Y.; Feng, Y.; Zhang, L.; Yi, Z. A Feature Space-Restricted Attention Attack on Medical Deep Learning Systems. IEEE Trans. Cybern. 2022, 53, 5323–5335. [Google Scholar] [CrossRef] [PubMed]
- Tian, B.; Guo, Q.; Juefei-Xu, F.; Le Chan, W.; Cheng, Y.; Li, X.; Xie, X.; Qin, S. Bias Field Poses a Threat to Dnn-Based X-Ray Recognition. In Proceedings of the 2021 IEEE International Conference on Multimedia and Expo (ICME), Shenzhen, China, 5–9 July 2021. [Google Scholar] [CrossRef]
- Ma, X.; Niu, Y.; Gu, L.; Wang, Y.; Zhao, Y.; Bailey, J.; Lu, F. Understanding adversarial attacks on deep learning based medical image analysis systems. Pattern Recognit. 2021, 110, 107332. [Google Scholar] [CrossRef]
- Vatian, A.; Gusarova, N.; Dobrenko, N.; Dudorov, S.; Nigmatullin, N.; Shalyto, A.; Lobantsev, A. Impact of Adversarial Examples on the Efficiency of Interpretation and Use of Information from High-Tech Medical Images. In Proceedings of the 24th Conference of Open Innovations Association, Moscow, Russia, 8–12 April 2019. [Google Scholar] [CrossRef]
- Zhou, H.-Y.; Wang, C.; Li, H.; Wang, G.; Zhang, S.; Li, W.; Yu, Y. SSMD: Semi-Supervised Medical Image Detection with Adaptive Consistency and Heterogeneous Perturbation. 2021. Available online: http://arxiv.org/abs/2106.01544 (accessed on 20 August 2023).
- Xu, M.; Zhang, T.; Zhang, D. MedRDF: A Robust and Retrain-Less Diagnostic Framework for Medical Pretrained Models Against Adversarial Attack. IEEE Trans. Med. Imaging 2022, 41, 2130–2143. [Google Scholar] [CrossRef] [PubMed]
- Taghanaki, S.A.; Abhishek, K.; Azizi, S.; Hamarneh, G. A Kernelized Manifold Mapping to Diminish the Effect of Adversarial Perturbations. 2019. Available online: http://arxiv.org/abs/1903.01015 (accessed on 20 August 2023).
- Xu, M.; Zhang, T.; Li, Z.; Liu, M.; Zhang, D. Towards evaluating the robustness of deep diagnostic models by adversarial attack. Med. Image Anal. 2021, 69, 101977. [Google Scholar] [CrossRef]
- Marinovich, M.L.; Wylie, E.; Lotter, W.; Lund, H.; Waddell, A.; Madeley, C.; Pereira, G.; Houssami, N. Artificial intelligence (AI) for breast cancer screening: BreastScreen population-based cohort study of cancer detection. eBioMedicine 2023, 90, 104498. [Google Scholar] [CrossRef]
- Family Members Awarded $16.7 Million after Radiologist Missed. Available online: https://www.reliasmedia.com/articles/21632-family-members-awarded-16-7-million-after-radiologist-missed-evidence-of-lung-cancer (accessed on 27 September 2023).
- Zbrzezny, A.M.; Grzybowski, A.E. Deceptive Tricks in Artificial Intelligence: Adversarial Attacks in Ophthalmology. J. Clin. Med. 2023, 12, 3266. [Google Scholar] [CrossRef]
- Biggest Healthcare Data Breaches Reported This Year, So Far. Available online: https://healthitsecurity.com/features/biggest-healthcare-data-breaches-reported-this-year-so-far (accessed on 27 September 2023).
- Kumar, A.; Kumar, D.; Kumar, P.; Dhawan, V. Optimization of Incremental Sheet Forming Process Using Artificial Intelligence-Based Techniques. Nat.-Inspired Optim. Adv. Manuf. Process Syst. 2020, 8, 113–130. [Google Scholar] [CrossRef]
- Mukherjee, A.; Sumit; Deepmala; Dhiman, V.K.; Srivastava, P.; Kumar, A. Intellectual Tool to Compute Embodied Energy and Carbon Dioxide Emission for Building Construction Materials. J. Phys. Conf. Ser. 2021, 1950, 012025. [Google Scholar] [CrossRef]
- Phogat, M.; Kumar, A.; Nandal, D.; Shokhanda, J. A Novel Automating Irrigation Techniques based on Artificial Neural Network and Fuzzy Logic. J. Phys. Conf. Ser. 2021, 1950, 012088. [Google Scholar] [CrossRef]
- Ukwuoma, C.C.; Hossain, M.A.; Jackson, J.K.; Nneji, G.U.; Monday, H.N.; Qin, Z. Multi-Classification of Breast Cancer Lesions in Histopathological Images Using DEEP_Pachi: Multiple Self-Attention Head. Diagnostics 2022, 12, 1152. [Google Scholar] [CrossRef]
- Ukwuoma, C.C.; Qin, Z.; Agbesi, V.K.; Ejiyi, C.J.; Bamisile, O.; Chikwendu, I.A.; Tienin, B.W.; Hossin, M.A. LCSB-inception: Reliable and effective light-chroma separated branches for Covid-19 detection from chest X-ray images. Comput. Biol. Med. 2022, 150, 106195. [Google Scholar] [CrossRef]
- Ukwuoma, C.C.; Qin, Z.; Heyat, M.B.B.; Akhtar, F.; Smahi, A.; Jackson, J.K.; Furqan Qadri, S.; Muaad, A.Y.; Monday, H.N.; Nneji, G.U. Automated Lung-Related Pneumonia and COVID-19 Detection Based on Novel Feature Extraction Framework and Vision Transformer Approaches Using Chest X-ray Images. Bioengineering 2022, 9, 709. [Google Scholar] [CrossRef] [PubMed]
- Ukwuoma, C.C.; Qin, Z.; Agbesi, V.K.; Cobbinah, B.M.; Yussif, S.B.; Abubakar, H.S.; Lemessa, B.D. Dual_Pachi: Attention-based dual path framework with intermediate second order-pooling for COVID-19 detection from chest X-ray images. Comput. Biol. Med. 2022, 151, 106324. [Google Scholar] [CrossRef] [PubMed]
- Ritter, F.; Boskamp, T.; Homeyer, A.; Laue, H.; Schwier, M.; Link, F.; Peitgen, H.O. Medical image analysis. IEEE Pulse 2011, 2, 60–70. [Google Scholar] [CrossRef] [PubMed]
- Phogat, M.; Kumar, D.; Phogat, M.; Kumar, D. Classification of Complex Diseases using an Improved Binary Cuckoo Search and Conditional Mutual Information Maximization. Comput. Sist. 2020, 24, 1121–1129. [Google Scholar] [CrossRef]
- Ker, J.; Wang, L.; Rao, J.; Lim, T. Deep Learning Applications in Medical Image Analysis. IEEE Access 2017, 6, 9375–9379. [Google Scholar] [CrossRef]
- Ukwuoma, C.C.; Cai, D.; Gati, E.S.; Agbesi, V.K.; Deribachew, G.; Yobsan Bayisa, L.; Abu, T. Attention-Based End-to-End Hybrid Ensemble Model for Breast Cancer Multi-Classification. Off. Publ. Direct Res. J. Public Health Environ. Technol. 2023, 8, 22–39. [Google Scholar]
- Anaam, A.; Al-antari, M.A.; Gofuku, A. A deep learning self-attention cross residual network with Info-WGANGP for mitotic cell identification in HEp-2 medical microscopic images. Biomed. Signal Process. Control 2023, 86, 105191. [Google Scholar] [CrossRef]
- Fraiwan, M.; Audat, Z.; Fraiwan, L.; Manasreh, T. Using deep transfer learning to detect scoliosis and spondylolisthesis from X-ray images. PLoS ONE 2022, 17, e0267851. [Google Scholar] [CrossRef]
- Abdel-Monem, A.; Abouhawwash, M. A Machine Learning Solution for Securing the Internet of Things Infrastructures. Sustain. Mach. Intell. J. 2022, 1. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 39–57. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the 3rd International Conference on Learning Representations ICLR 2015, San Diego, CA, USA, 7–9 May 2014; pp. 1–11. [Google Scholar]
- Pranava Raman, B.M.S.; Anusree, V.; Sreeratcha, B.; Preeti Krishnaveni, R.A.; Dunston, S.D.; Rajam, M.A.V. Analysis of the Effect of Black Box Adversarial Attacks on Medical Image Classification Models. In Proceedings of the Third International Conference on Intelligent Computing Instrumentation and Control Technologies (ICICICT), Kannur, India, 11–12 August 2022; pp. 528–531. [Google Scholar] [CrossRef]
- Tripathi, A.M.; Mishra, A. Fuzzy Unique Image Transformation: Defense Against Adversarial Attacks on Deep COVID-19 Models. arXiv 2020, arXiv:2009.04004. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of the 6th International Conference on Learning Representations ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2017; Available online: https://arxiv.org/abs/1706.06083v4 (accessed on 18 April 2023).
- Kansal, K.; Krishna, P.S.; Jain, P.B.; Surya, R.; Honnavalli, P.; Eswaran, S. Defending against adversarial attacks on Covid-19 classifier: A denoiser-based approach. Heliyon 2022, 8, e11209. [Google Scholar] [CrossRef] [PubMed]
- Paul, R.; Schabath, M.; Gillies, R.; Hall, L.; Goldgof, D. Mitigating Adversarial Attacks on Medical Image Understanding Systems. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging, Iowa City, IA, USA, 3–7 April 2020; pp. 1517–1521. [Google Scholar] [CrossRef]
- Abdelhafeez, A.; Ali, A.M. DeepHAR-Net: A Novel Machine Intelligence Approach for Human Activity Recognition from Inertial Sensors. Sustain. Mach. Intell. J. 2022, 1. [Google Scholar] [CrossRef]
- Abdelhafeez, A.; Aziz, A.; Khalil, N. Building a Sustainable Social Feedback Loop: A Machine Intelligence Approach for Twitter Opinion Mining. Sustain. Mach. Intell. J. 2022, 1. [Google Scholar] [CrossRef]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust Physical-World Attacks on Deep Learning Visual Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognitio, Seattle, WA, USA, 14–19 June 2018; pp. 1625–1634. [Google Scholar] [CrossRef]
- Ozbulak, U.; Van Messem, A.; De Neve, W. Impact of Adversarial Examples on Deep Learning Models for Biomedical Image Segmentation. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2019; Springer: Cham, Switzerland, 2019; Volume 11765, pp. 300–308. [Google Scholar] [CrossRef]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar] [CrossRef]
- Papernot, N.; Mcdaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy, Saarbrucken, Germany, 21–26 March 2016; pp. 372–387. [Google Scholar] [CrossRef]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial Examples for Semantic Segmentation and Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Finlayson, S.G.; Chung, H.W.; Kohane, I.S.; Beam, A.L. Adversarial Attacks Against Medical Deep Learning Systems. arXiv 2018, arXiv:1804.05296. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. In Proceedings of the 5th International Conference on Learning Representations ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Asgari Taghanaki, S.; Das, A.; Hamarneh, G. Vulnerability analysis of chest X-ray image classification against adversarial attacks. In Understanding and Interpreting Machine Learning in Medical Image Computing Applications; Springer: Cham, Switzerland, 2018; Volume 11038, pp. 87–94. [Google Scholar] [CrossRef]
- Yilmaz, I. Practical Fast Gradient Sign Attack against Mammographic Image Classifier. 2020. Available online: https://arxiv.org/abs/2001.09610v1 (accessed on 28 August 2023).
- Ukwuoma, C.C.; Qin, Z.; Belal Bin Heyat, M.; Akhtar, F.; Bamisile, O.; Muaad, A.Y.; Addo, D.; Al-antari, M.A. A hybrid explainable ensemble transformer encoder for pneumonia identification from chest X-ray images. J. Adv. Res. 2023, 48, 191–211. [Google Scholar] [CrossRef]
- Ukwuoma, C.C.; Cai, D.; Heyat, M.B.B.; Bamisile, O.; Adun, H.; Al-Huda, Z.; Al-antari, M.A. Deep learning framework for rapid and accurate respiratory COVID-19 prediction using chest X-ray images. J. King Saud Univ.Comput. Inf. Sci. 2023, 35, 101596. [Google Scholar] [CrossRef]
- Rao, C.; Cao, J.; Zeng, R.; Chen, Q.; Fu, H.; Xu, Y.; Tan, M. A Thorough Comparison Study on Adversarial Attacks and Defenses for Common Thorax Disease Classification in Chest X-rays. 2020. Available online: https://arxiv.org/abs/2003.13969v1 (accessed on 20 August 2023).
- Rahman, A.; Hossain, M.S.; Alrajeh, N.A.; Alsolami, F. Adversarial Examples—Security Threats to COVID-19 Deep Learning Systems in Medical IoT Devices. IEEE Internet Things J. 2021, 8, 9603. [Google Scholar] [CrossRef]
- Cheng, G.; Ji, H. Adversarial Perturbation on MRI Modalities in Brain Tumor Segmentation. IEEE Access 2020, 8, 206009–206015. [Google Scholar] [CrossRef]
- Chen, C.; Qin, C.; Qiu, H.; Ouyang, C.; Wang, S.; Chen, L.; Tarroni, G.; Bai, W.; Rueckert, D. Realistic adversarial data augmentation for mr image segmentation. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2020; Springer: Cham, Switzerland, 2020; Volume 12261, pp. 667–677. [Google Scholar] [CrossRef]
- Bertels, J.; Leuven, K.U.; Eelbode, T.; Vandermeulen, D.; Maes, F.; Berman, M.; Bisschops, R.; Blaschko, M.B. Optimizing the Dice Score and Jaccard Index for Medical Image Segmentation: Theory & Practice Opportunistic Screening for Vertebral Compression Fractures in CT View Project Endoscopic and Transmural Evaluation of Healing in IBD and the Impact on Clinical. Available online: https://www.researchgate.net/publication/337048291 (accessed on 28 August 2023).
- Feinman, R.; Curtin, R.R.; Shintre, S.; Gardner, A.B. Detecting Adversarial Samples from Artifacts. Available online: http://github.com/rfeinman/detecting-adversarial-samples (accessed on 28 August 2023).
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.M.; Wijewickrema, S.; Schoenebeck, G.; Song, D.; Houle, M.E.; Bailey, J. Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality. In Proceedings of the 6th International Conference on Learning Representations ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018; Available online: https://arxiv.org/abs/1801.02613v3 (accessed on 28 August 2023).
- Lu, J.; Issaranon, T.; Lu, T.; Forsyth, D. SafetyNet: Detecting and Rejecting Adversarial Examples Robustly. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, X.; Zhu, D. Robust Detection of Adversarial Attacks on Medical Images. Available online: https://github.com/xinli0928/MGM (accessed on 25 August 2023).
- Li, X.; Pan, D.; Zhu, D. Defending against adversarial attacks on medical imaging ai system, classification or detection? In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging, Nice, France, 13–16 April 2021; pp. 1677–1681. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, Y.; Qian, C. Fooling Examples: Another Intriguing Property of Neural Networks. Sensors 2023, 23, 6378. [Google Scholar] [CrossRef]
- Liu, C. Evaluating Robustness Against Adversarial Attacks: A Representational Similarity Analysis Approach. In Proceedings of the International Joint Conference on Neural Networks 2023, Gold Coast, Australia, 18–23 June 2023. [Google Scholar] [CrossRef]
- Ren, K.; Zheng, T.; Qin, Z.; Liu, X. Adversarial Attacks and Defenses in Deep Learning. Engineering 2020, 6, 346–360. [Google Scholar] [CrossRef]
- Sen, J.; Dasgupta, S. Adversarial Attacks on Image Classification Models: FGSM and Patch Attacks and their Impact. arXiv 2023, arXiv:2307.02055. [Google Scholar] [CrossRef]
- Shah, A.; Lynch, S.; Niemeijer, M.; Amelon, R.; Clarida, W.; Folk, J.; Russell, S.; Wu, X.; Abramoff, M.D. Susceptibility to misdiagnosis of adversarial images by deep learning based retinal image analysis algorithms. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 1454–1457. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, J.; Jog, V.; Loh, P.L.; McMillan, A.B. Robustifying Deep Networks for Medical Image Segmentation. J. Digit. Imaging 2021, 34, 1279. [Google Scholar] [CrossRef]
- Chen, L.; Bentley, P.; Mori, K.; Misawa, K.; Fujiwara, M.; Rueckert, D. Intelligent image synthesis to attack a segmentation CNN using adversarial learning. In Simulation and Synthesis in Medical Imaging: 4th International Workshop, SASHIMI 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, 13 October 2019, Proceedings 4; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11827, pp. 90–99. [Google Scholar] [CrossRef]
- Kovalev, V.; Voynov, D. Influence of Control Parameters and the Size of Biomedical Image Datasets on the Success of Adversarial Attacks. 2019. Available online: https://arxiv.org/abs/1904.06964v1 (accessed on 25 August 2023).
- Cheng, Y.; Juefei-Xu, F.; Guo, Q.; Fu, H.; Xie, X.; Lin, S.-W.; Lin, W.; Liu, Y. Adversarial Exposure Attack on Diabetic Retinopathy Imagery. 2020. Available online: https://arxiv.org/abs/2009.09231v1 (accessed on 25 August 2023).
- Byra, M.; Styczynski, G.; Szmigielski, C.; Kalinowski, P.; Michalowski, L.; Paluszkiewicz, R.; Ziarkiewicz-Wroblewska, B.; Zieniewicz, K.; Nowicki, A. Adversarial attacks on deep learning models for fatty liver disease classification by modification of ultrasound image reconstruction method. In Proceedings of the 2020 IEEE International Ultrasonics Symposium 2020, Las Vegas, NV, USA, 7–11 September 2020. [Google Scholar] [CrossRef]
- Yao, Q.; He, Z.; Han, H.; Zhou, S.K. Miss the Point: Targeted Adversarial Attack on Multiple Landmark Detection. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020, Proceedings, Part IV 23; Springer International Publishing: Cham, Switzerland, 2020; Volume 12264, pp. 692–702. [Google Scholar] [CrossRef]
- Yoo, T.K.; Choi, J.Y. Outcomes of Adversarial Attacks on Deep Learning Models for Ophthalmology Imaging Domains. JAMA Ophthalmol. 2020, 138, 1213. [Google Scholar] [CrossRef] [PubMed]
- Hirano, H.; Minagi, A.; Takemoto, K. Universal adversarial attacks on deep neural networks for medical image classification. BMC Med. Imaging 2021, 21, 1–13. [Google Scholar] [CrossRef]
- Joel, M.Z.; Umrao, S.; Chang, E.; Choi, R.; Yang, D.; Omuro, A.; Herbst, R.; Krumholz, H.; Aneja, S. Adversarial Attack Vulnerability of Deep Learning Models for Oncologic Images. medRxiv 2021. [Google Scholar] [CrossRef]
- Chen, J.; Qian, L.; Urakov, T.; Gu, W.; Liang, L. Adversarial Robustness Study of Convolutional Neural Network for Lumbar Disk Shape Reconstruction from MR Images. 2021. Available online: https://arxiv.org/abs/2102.02885v1 (accessed on 25 August 2023).
- Qi, G.; Gong, L.; Song, Y.; Ma, K.; Zheng, Y. Stabilized Medical Image Attacks. arXiv 2021, arXiv:2103.05232. [Google Scholar]
- Bortsova, G.; Dubost, F.; Hogeweg, L.; Katramados, I.; de Bruijne, M. Adversarial Heart Attack: Neural Networks Fooled to Segment Heart Symbols in Chest X-ray Images. 2021. Available online: https://arxiv.org/abs/2104.00139v2 (accessed on 25 August 2023).
- Kovalev, V.A.; Liauchuk, V.A.; Voynov, D.M.; Tuzikov, A.V. Biomedical Image Recognition in Pulmonology and Oncology with the Use of Deep Learning. Pattern Recognit. Image Anal. 2021, 31, 144–162. [Google Scholar] [CrossRef]
- Pal, B.; Gupta, D.; Rashed-Al-mahfuz, M.; Alyami, S.A.; Moni, M.A. Vulnerability in Deep Transfer Learning Models to Adversarial Fast Gradient Sign Attack for COVID-19 Prediction from Chest Radiography Images. Appl. Sci. 2021, 11, 4233. [Google Scholar] [CrossRef]
- Shao, M.; Zhang, G.; Zuo, W.; Meng, D. Target attack on biomedical image segmentation model based on multi-scale gradients. Inf. Sci. 2021, 554, 33–46. [Google Scholar] [CrossRef]
- Wang, X.; Lv, S.; Sun, J.; Wang, S. Adversarial Attacks Medical Diagnosis Model with Generative Adversarial Networks. Lect. Notes Data Eng. Commun. Technol. 2022, 89, 678–685. [Google Scholar] [CrossRef]
- Minagi, A.; Hirano, H.; Takemoto, K. Natural Images Allow Universal Adversarial Attacks on Medical Image Classification Using Deep Neural Networks with Transfer Learning. J. Imaging 2022, 8, 38. [Google Scholar] [CrossRef] [PubMed]
- Patel, P.; Bhadla, M.; Upadhyay, J.; Suthar, D.; Darji, D. Predictive COVID-19 Risk and Virus Mutation isolation with CNN based Machine learning Technique. In Proceedings of the 2022 2nd International Conference on Innovative Practices in Technology and Management, Pradesh, India, 23–25 February 2022; pp. 424–428. [Google Scholar] [CrossRef]
- Levy, M.; Amit, G.; Elovici, Y.; Mirsky, Y. The Security of Deep Learning Defences for Medical Imaging. arXiv 2022, arXiv:2201.08661. [Google Scholar]
- Kwon, H.; Jeong, J. AdvU-Net: Generating Adversarial Example Based on Medical Image and Targeting U-Net Model. J. Sensors 2022, 2022, 4390413. [Google Scholar] [CrossRef]
- Júlio de Aguiar, E.; Marcomini, K.D.; Antunes Quirino, F.; Gutierrez, M.A.; Traina, C.; Traina, A.J.M. Evaluation of the impact of physical adversarial attacks on deep learning models for classifying COVID cases. In Medical Imaging 2022: Computer-Aided Diagnosis; SPIE: Bellingham, WA, USA, 2022; p. 122. [Google Scholar] [CrossRef]
- Apostolidis, K.D.; Papakostas, G.A. Digital Watermarking as an Adversarial Attack on Medical Image Analysis with Deep Learning. J. Imaging 2022, 8, 155. [Google Scholar] [CrossRef]
- Wei, C.; Sun, R.; Li, P.; Wei, J. Analysis of the No-sign Adversarial Attack on the COVID Chest X-ray Classification. In Proceedings of the 2022 International Conference on Image Processing and Media Computing (ICIPMC 2022), Xi’an, China, 27–29 May 2022; pp. 73–79. [Google Scholar] [CrossRef]
- Selvakkumar, A.; Pal, S.; Jadidi, Z. Addressing Adversarial Machine Learning Attacks in Smart Healthcare Perspectives. Lect. Notes Electr. Eng. 2022, 886, 269–282. [Google Scholar] [CrossRef]
- Ahmed, S.; Dera, D.; Hassan, S.U.; Bouaynaya, N.; Rasool, G. Failure Detection in Deep Neural Networks for Medical Imaging. Front. Med. Technol. 2022, 4, 919046. [Google Scholar] [CrossRef]
- Li, S.; Huang, G.; Xu, X.; Lu, H. Query-based black-box attack against medical image segmentation model. Futur. Gener. Comput. Syst. 2022, 133, 331–337. [Google Scholar] [CrossRef]
- Morshuis, J.N.; Gatidis, S.; Hein, M.; Baumgartner, C.F. Adversarial Robustness of MR Image Reconstruction Under Realistic Perturbations. In International Workshop on Machine Learning for Medical Image Reconstruction; Springer: Cham, Switzerland, 2022; Volume 13587, pp. 24–33. [Google Scholar] [CrossRef]
- Bharath Kumar, D.P.; Kumar, N.; Dunston, S.D.; Rajam, V.M.A. Analysis of the Impact of White Box Adversarial Attacks in ResNet While Classifying Retinal Fundus Images. In International Conference on Computational Intelligence in Data Science; Springer: Cham, Switzerland, 2022; Volume 654, pp. 162–175. [Google Scholar]
- Purohit, J.; Attari, S.; Shivhare, I.; Surtkar, S.; Jogani, V. Adversarial Attacks and Defences for Skin Cancer Classification. arXiv 2022, arXiv:2212.06822. [Google Scholar] [CrossRef]
- Li, Y.; Liu, S. The Threat of Adversarial Attack on a COVID-19 CT Image-Based Deep Learning System. Bioengineering 2023, 10, 194. [Google Scholar] [CrossRef]
- Dai, Y.; Qian, Y.; Lu, F.; Wang, B.; Gu, Z.; Wang, W.; Wan, J.; Zhang, Y. Improving adversarial robustness of medical imaging systems via adding global attention noise. Comput. Biol. Med. 2023, 164, 107251. [Google Scholar] [CrossRef] [PubMed]
- Joel, M.Z.; Avesta, A.; Yang, D.X.; Zhou, J.G.; Omuro, A.; Herbst, R.S.; Krumholz, H.M.; Aneja, S. Comparing Detection Schemes for Adversarial Images against Deep Learning Models for Cancer Imaging. Cancers 2023, 15, 1548. [Google Scholar] [CrossRef] [PubMed]
- Niu, Z.H.; Yang, Y. Bin Defense Against Adversarial Attacks with Efficient Frequency-Adaptive Compression and Reconstruction. Pattern Recognit. 2023, 138, 109382. [Google Scholar] [CrossRef]
- Bountakas, P.; Zarras, A.; Lekidis, A.; Xenakis, C. Defense strategies for Adversarial Machine Learning: A survey. Comput. Sci. Rev. 2023, 49, 100573. [Google Scholar] [CrossRef]
- Laykaviriyakul, P.; Phaisangittisagul, E. Collaborative Defense-GAN for protecting adversarial attacks on classification system. Expert Syst. Appl. 2023, 214, 118957. [Google Scholar] [CrossRef]
- Chen, F.; Wang, J.; Liu, H.; Kong, W.; Zhao, Z.; Ma, L.; Liao, H.; Zhang, D. Frequency constraint-based adversarial attack on deep neural networks for medical image classification. Comput. Biol. Med. 2023, 164, 107248. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security 2017, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar] [CrossRef]
- Ilyas, A.; Engstrom, L.; Athalye, A.; Lin, J. Black-Box Adversarial Attacks with Limited Queries and Information. PMLR; pp. 2137–2146. Available online: https://proceedings.mlr.press/v80/ilyas18a.html (accessed on 26 August 2023).
- Wicker, M.; Huang, X.; Kwiatkowska, M. Feature-Guided Black-Box Safety Testing of Deep Neural Networks. In Tools and Algorithms for the Construction and Analysis of Systems: 24th International Conference, TACAS 2018, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2018, Thessaloniki, Greece, 14–20 April 2018, Proceedings, Part I 24; Springer: Cham, Switzerland, 2017; Volume 10805, pp. 408–426. [Google Scholar] [CrossRef]
- Andriushchenko, M.; Croce, F.; Flammarion, N.; Hein, M. Square Attack: A Query-Efficient Black-Box Adversarial Attack via Random Search. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; Volume 12368, pp. 484–501. [Google Scholar] [CrossRef]
- Ilyas, A.; Santurkar, S.; Tsipras, D.; Engstrom, L.; Tran, B.; Madry, A. Adversarial Examples Are Not Bugs, They Are Features. Adv. Neural Inf. Process. Syst. 2019, 32, 125–136. [Google Scholar]
- Yao, Q.; He, Z.; Zhou, S.K. Medical Aegis: Robust Adversarial Protectors for Medical Images. November 2021. Available online: https://arxiv.org/abs/2111.10969v4 (accessed on 20 August 2023).
- Liao, F.; Liang, M.; Dong, Y.; Pang, T.; Hu, X.; Zhu, J. Defense against Adversarial Attacks Using High-Level Representation Guided Denoiser. Available online: https://github.com/lfz/Guided-Denoise (accessed on 20 August 2023).
- Daanouni, O.; Cherradi, B.; Tmiri, A. NSL-MHA-CNN: A Novel CNN Architecture for Robust Diabetic Retinopathy Prediction Against Adversarial Attacks. IEEE Access 2022, 10, 103987–103999. [Google Scholar] [CrossRef]
- Han, T.; Nebelung, S.; Pedersoli, F.; Zimmermann, M.; Schulze-Hagen, M.; Ho, M.; Haarburger, C.; Kiessling, F.; Kuhl, C.; Schulz, V.; et al. Advancing diagnostic performance and clinical usability of neural networks via adversarial training and dual batch normalization. Nat. Commun. 2021, 12, 1–11. [Google Scholar] [CrossRef]
- Chen, L.; Zhao, L.; Chen, C.Y.C. Enhancing adversarial defense for medical image analysis systems with pruning and attention mechanism. Med. Phys. 2021, 48, 6198–6212. [Google Scholar] [CrossRef]
- Xue, F.F.; Peng, J.; Wang, R.; Zhang, Q.; Zheng, W.S. Improving Robustness of Medical Image Diagnosis with Denoising Convolutional Neural Networks. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2019: 22nd International Conference, Shenzhen, China, 13–17 October 2019, Proceedings, Part VI 22; Springer: Cham, Switzerland, 2019; Volume 11769, pp. 846–854. [Google Scholar] [CrossRef]
- Xie, C.; Tan, M.; Gong, B.; Wang, J.; Yuille, A.; Le, Q. V Adversarial Examples Improve Image Recognition. Available online: https://github.com/tensorflow/tpu/tree/ (accessed on 25 August 2023).
- Carannante, G.; Dera, D.; Bouaynaya, N.C.; Fathallah-Shaykh, H.M.; Rasool, G. SUPER-Net: Trustworthy Medical Image Segmentation with Uncertainty Propagation in Encoder-Decoder Networks. arXiv 2021, arXiv:2111.05978. [Google Scholar]
- Stimpel, B.; Syben, C.; Schirrmacher, F.; Hoelter, P.; Dörfler, A.; Maier, A. Multi-modal Deep Guided Filtering for Comprehensible Medical Image Processing. IEEE Trans. Med. Imaging 2019, 39, 1703–1711. [Google Scholar] [CrossRef] [PubMed]
- He, X.; Yang, S.; Li, G.; Li, H.; Chang, H.; Yu, Y. Non-local context encoder: Robust biomedical image segmentation against adversarial attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8417–8424. [Google Scholar] [CrossRef]
- Joel, M.Z.; Umrao, S.; Chang, E.; Choi, R.; Yang, D.X.; Duncan, J.S.; Omuro, A.; Herbst, R.; Krumholz, H.M.; Aneja, S. Using Adversarial Images to Assess the Robustness of Deep Learning Models Trained on Diagnostic Images in Oncology. JCO Clin. Cancer Inform. 2022, 6, e2100170. [Google Scholar] [CrossRef] [PubMed]
- Hu, L.; Zhou, D.W.; Guo, X.Y.; Xu, W.H.; Wei, L.M.; Zhao, J.G. Adversarial training for prostate cancer classification using magnetic resonance imaging. Quant. Imaging Med. Surg. 2022, 12, 3276–3287. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zou, D.; Yi, J.; Bailey, J.; Ma, X.; Gu, Q. Improving Adversarial Robustness Requires Revisiting Misclassified Examples. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–14. [Google Scholar]
- Liu, S.; Setio, A.A.A.; Ghesu, F.C.; Gibson, E.; Grbic, S.; Georgescu, B.; Comaniciu, D. No Surprises: Training Robust Lung Nodule Detection for Low-Dose CT Scans by Augmenting with Adversarial Attacks. IEEE Trans. Med. Imaging 2021, 40, 335–345. [Google Scholar] [CrossRef] [PubMed]
- Lal, S.; Rehman, S.U.; Shah, J.H.; Meraj, T.; Rauf, H.T.; Damaševičius, R.; Mohammed, M.A.; Abdulkareem, K.H. Adversarial Attack and Defence through Adversarial Training and Feature Fusion for Diabetic Retinopathy Recognition. Sensors 2021, 21, 3922. [Google Scholar] [CrossRef]
- Almalik, F.; Yaqub, M.; Nandakumar, K. Self-Ensembling Vision Transformer (SEViT) for Robust Medical Image Classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer Nature: Cham, Switzerland, 2022; Volume 13433, pp. 376–386. [Google Scholar] [CrossRef]
- Huang, Y.; Würfl, T.; Breininger, K.; Liu, L.; Lauritsch, G.; Maier, A. Some Investigations on Robustness of Deep Learning in Limited Angle Tomography. Inform. Aktuell 2019, 17, 21. [Google Scholar] [CrossRef]
- Ren, X.; Zhang, L.; Wei, D.; Shen, D.; Wang, Q. Brain MR Image Segmentation in Small Dataset with Adversarial Defense and Task Reorganization. In Machine Learning in Medical Imaging: 10th International Workshop, MLMI 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, 13 October 2019, Proceedings 10; Springer Nature: Cham, Switzerland, 2019; Volume 11861, pp. 1–8. [Google Scholar] [CrossRef]
- Thite, M.; Kavanagh, M.J.; Johnson, R.D. Evolution of human resource management & human resource information systems: The role of information technology. In Human Resource Information Systems: Basics; Kavanagh, M.J., Thite, M., Johnson, R.D., Eds.; Applications & Directions: Thousand Oaks, CA, USA, 2012; pp. 2–34. Available online: https://www.researchgate.net/publication/277249737_Thite_M_Kavanagh_MJ_Johnson_R_D_2012_Evolution_of_human_resource_management_human_resource_information_systems_The_role_of_information_technology_In_Kavanagh_MJ_Thite_M_Johnson_R_D_Eds_Human_Resource_ (accessed on 30 May 2023).
- Li, Y.; Zhu, Z.; Zhou, Y.; Xia, Y.; Shen, W.; Fishman, E.K.; Yuille, A.L. Volumetric Medical Image Segmentation: A 3D Deep Coarse-to-Fine Framework and Its Adversarial Examples. In Deep Learning and Convolutional Neural Networks for Medical Imaging and Clinical Informatics; Springer Nature: Cham, Switzerland, 2019; pp. 69–91. [Google Scholar] [CrossRef]
- Park, H.; Bayat, A.; Sabokrou, M.; Kirschke, J.S.; Menze, B.H. Robustification of Segmentation Models Against Adversarial Perturbations in Medical Imaging. In Predictive Intelligence in Medicine: Third International Workshop, PRIME 2020, Held in Conjunction with MICCAI 2020, Lima, Peru, 8 October 2020, Proceedings 3; Springer Nature: Cham, Switzerland, 2020; Volume 12329, pp. 46–57. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, H.; Bermudez, C.; Chen, Y.; Landman, B.A.; Vorobeychik, Y. Anatomical Context Protects Deep Learning from Adversarial Perturbations in Medical Imaging. Neurocomputing 2020, 379, 370–378. [Google Scholar] [CrossRef]
- Wu, D.; Liu, S.; Ban, J. Classification of Diabetic Retinopathy Using Adversarial Training. IOP Conf. Ser. Mater. Sci. Eng. 2020, 806, 012050. [Google Scholar] [CrossRef]
- Anand, D.; Tank, D.; Tibrewal, H.; Sethi, A. Self-Supervision vs. Transfer Learning: Robust Biomedical Image Analysis against Adversarial Attacks. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging, Iowa City, IA, USA, 3–7 April 2020; pp. 1159–1163. [Google Scholar] [CrossRef]
- Ma, L.; Liang, L. Increasing-Margin Adversarial (IMA) training to Improve Adversarial Robustness of Neural Networks. Comput. Methods Programs Biomed. 2023, 240, 107687. [Google Scholar] [CrossRef]
- Cheng, K.; Calivá, F.; Shah, R.; Han, M.; Majumdar, S.; Pedoia, V. Addressing The False Negative Problem of Deep Learning MRI Reconstruction Models by Adversarial Attacks and Robust Training 2020, PMLR, 21 September 2020; pp. 121–135. Available online: https://proceedings.mlr.press/v121/cheng20a.html (accessed on 21 September 2023).
- Raj, A.; Bresler, Y.; Li, B. Improving Robustness of Deep-Learning-Based Image Reconstruction 2020; pp. 7932–7942. Available online: https://proceedings.mlr.press/v119/raj20a.html (accessed on 25 August 2023).
- Huq, A.; Pervin, T. Analysis of Adversarial Attacks on Skin Cancer Recognition. In Proceedings of the 2020 International Conference on Data Science and Its Applications (ICoDSA), Bandung, Indonesia, 5–6 August 2020. [Google Scholar] [CrossRef]
- Liu, Q.; Jiang, H.; Liu, T.; Liu, Z.; Li, S.; Wen, W.; Shi, Y. Defending Deep Learning-Based Biomedical Image Segmentation from Adversarial Attacks: A Low-Cost Frequency Refinement Approach. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, 4–8 October 2020, Proceedings, Part IV 23; Springer Nature: Cham, Switzerland, 2020; Volume 12264, pp. 342–351. [Google Scholar] [CrossRef]
- Watson, M.; Al Moubayed, N. Attack-agnostic adversarial detection on medical data using explainable machine learning. In Proceedings of the 2020 25th International Conference on Pattern Recognition, Milan, Italy, 10–15 January 2021; pp. 8180–8187. [Google Scholar] [CrossRef]
- Pervin, M.T.; Tao, L.; Huq, A.; He, Z.; Huo, L. Adversarial Attack Driven Data Augmentation for Accurate And Robust Medical Image Segmentation. 2021. Available online: http://arxiv.org/abs/2105.12106 (accessed on 25 August 2023).
- Uwimana1, A.; Senanayake, R. Out of Distribution Detection and Adversarial Attacks on Deep Neural Networks for Robust Medical Image Analysis. 2021. Available online: http://arxiv.org/abs/2107.04882 (accessed on 25 August 2023).
- Daza, L.; Pérez, J.C.; Arbeláez, P. Towards Robust General Medical Image Segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021, Proceedings, Part III 24; Springer Nature: Cham, Switzerland, 2021; Volume 12903, pp. 3–13. [Google Scholar] [CrossRef]
- Gupta, D.; Pal, B. Vulnerability Analysis and Robust Training with Additive Noise for FGSM Attack on Transfer Learning-Based Brain Tumor Detection from MRI. Lect. Notes Data Eng. Commun. Technol. 2022, 95, 103–114. [Google Scholar] [CrossRef]
- Yang, Y.; Shih, F.Y.; Roshan, U. Defense Against Adversarial Attacks Based on Stochastic Descent Sign Activation Networks on Medical Images. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2254005. [Google Scholar] [CrossRef]
- Alatalo, J.; Sipola, T.; Kokkonen, T. Detecting One-Pixel Attacks Using Variational Autoencoders. In Proceedings of the World Conference on Information Systems and Technologies, Budva, Montenegro, 12–14 April 2022; Volume 468, pp. 611–623. [Google Scholar] [CrossRef]
- Rodriguez, D.; Nayak, T.; Chen, Y.; Krishnan, R.; Huang, Y. On the role of deep learning model complexity in adversarial robustness for medical images. BMC Med. Inform. Decis. Mak. 2022, 22, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Liang, L. Adaptive Adversarial Training to Improve Adversarial Robustness of DNNs for Medical Image Segmentation and Detection. 2022. Available online: https://arxiv.org/abs/2206.01736v2 (accessed on 25 August 2023).
- Xie, Y.; Fetit, A.E. How Effective is Adversarial Training of CNNs in Medical Image Analysis? In Annual Conference on Medical Image Understanding and Analysis; Springer: Cham, Switzerland, 2022; Volume 13413, pp. 443–457. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Shen, Z. Fight Fire with Fire: Reversing Skin Adversarial Examples by Multiscale Diffusive and Denoising Aggregation Mechanism. arXiv 2022, arXiv:2208.10373. [Google Scholar] [CrossRef]
- Ghaffari Laleh, N.; Truhn, D.; Veldhuizen, G.P.; Han, T.; van Treeck, M.; Buelow, R.D.; Langer, R.; Dislich, B.; Boor, P.; Schulz, V.; et al. Adversarial attacks and adversarial robustness in computational pathology. Nat. Commun. 2022, 13, 1–10. [Google Scholar] [CrossRef]
- Maliamanis, T.V.; Apostolidis, K.D.; Papakostas, G.A. How Resilient Are Deep Learning Models in Medical Image Analysis? The Case of the Moment-Based Adversarial Attack (Mb-AdA). Biomedicines 2022, 10, 2545. [Google Scholar] [CrossRef]
- Sun, S.; Xian, M.; Vakanski, A.; Ghanem, H. MIRST-DM: Multi-instance RST with Drop-Max Layer for Robust Classification of Breast Cancer. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2022; Volume 13434, pp. 401–410. [Google Scholar] [CrossRef]
- Pandey, P.; Vardhan, A.; Chasmai, M.; Sur, T.; Lall, B. Adversarially Robust Prototypical Few-Shot Segmentation with Neural-ODEs. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2022; Volume 13438, pp. 77–87. [Google Scholar] [CrossRef]
- Roh, J. Impact of Adversarial Training on the Robustness of Deep Neural Networks. In Proceedings of the 2022 IEEE 5th International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 23–25 September 2020; pp. 560–566. [Google Scholar] [CrossRef]
- Le, L.D.; Fu, H.; Xu, X.; Liu, Y.; Xu, Y.; Du, J.; Zhou, J.T.; Goh, R. An Efficient Defending Mechanism Against Image Attacking on Medical Image Segmentation Models. In MICCAI Workshop on Resource-Efficient Medical Image Analysis; Springer: Cham, Switzerland, 2022; Volume 13543, pp. 65–74. [Google Scholar] [CrossRef]
- Chen, C.; Qin, C.; Ouyang, C.; Li, Z.; Wang, S.; Qiu, H.; Chen, L.; Tarroni, G.; Bai, W.; Rueckert, D. Enhancing MR image segmentation with realistic adversarial data augmentation. Med. Image Anal. 2022, 82, 102597. [Google Scholar] [CrossRef]
- Shi, X.; Peng, Y.; Chen, Q.; Keenan, T.; Thavikulwat, A.T.; Lee, S.; Tang, Y.; Chew, E.Y.; Summers, R.M.; Lu, Z. Robust convolutional neural networks against adversarial attacks on medical images. Pattern Recognit. 2022, 132, 108923. [Google Scholar] [CrossRef]
- Sitawarin, C. DARTS: Deceiving Autonomous Cars with Toxic Signs. CoRR 2018, abs/1802.06430. Available online: http://arxiv.org/abs/1802.06430 (accessed on 28 August 2023).
- Su, J.; Vargas, D.V.; Sakurai, K. One Pixel Attack for Fooling Deep Neural Networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Croce, F.; Hein, M. Reliable Evaluation of Adversarial Robustness with an Ensemble of Diverse Parameter-free Attacks. In Proceedings of the International Conference on Machine Learning, virtual, 12–18 July 2020. [Google Scholar]
- Decencière, E.; Zhang, X.; Cazuguel, G.; Lay;, B.; Cochener, B.; Trone, C.; Gain, P.; Ordóñez-Varela, J.R.; Massin, P.; Erginay, A.; et al. Feedback On a Publicly Distributed Image Database: The Messidor Database. Image Anal. Stereol. 2014, 33, 231–234. [Google Scholar] [CrossRef]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M.; et al. Skin Lesion Analysis Toward Melanoma Detection 2018: A Challenge Hosted by the International Skin Imaging Collaboration (ISIC). 2019. Available online: https://arxiv.org/abs/1902.03368v2 (accessed on 28 August 2023).
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. ChestX-ray8: Hospital-scale Chest X-ray Database and Benchmarks on Weakly-Supervised Classification and Localization of Common Thorax Diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3462–3471. [Google Scholar] [CrossRef]
- Chowdhury, M.E.H.; Rahman, T.; Khandakar, A.; Mazhar, R.; Kadir, M.A.; Mahbub, Z.B.; Islam, K.R.; Khan, M.S.; Iqbal, A.; Al-Emadi, N.; et al. Can AI help in screening Viral and COVID-19 pneumonia? IEEE Access 2020, 8, 132665–132676. [Google Scholar] [CrossRef]
- Gonzalez, T.F. Handbook of Approximation Algorithms and Metaheuristics; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Available online: https://arxiv.org/abs/1409.1556v6 (accessed on 29 August 2023).
- Bortsova, G.; González-Gonzalo, C.; Wetstein, S.C.; Dubost, F.; Katramados, I.; Hogeweg, L.; Liefers, B.; van Ginneken, B.; Pluim, J.P.W.; Veta, M.; et al. Adversarial attack vulnerability of medical image analysis systems: Unexplored factors. Med. Image Anal. 2021, 73, 102141. [Google Scholar] [CrossRef] [PubMed]
- Han, C.; Rundo, L.; Murao, K.; Nemoto, T.; Nakayama, H. Bridging the Gap Between AI and Healthcare Sides: Towards Developing Clinically Relevant AI-Powered Diagnosis Systems. In Proceedings of the 16th IFIP WG 12.5 International Conference, Neos Marmaras, Greece, 5–7 June 2020; pp. 320–333. [Google Scholar] [CrossRef]
- Saeed, W.; Omlin, C. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowl. Based Syst. 2023, 263, 110273. [Google Scholar] [CrossRef]
- Busnatu, Ștefan; Niculescu, A.G.; Bolocan, A.; Petrescu, G.E.D.; Păduraru, D.N.; Năstasă, I.; Lupușoru, M.; Geantă, M.; Andronic, O.; Grumezescu, A.M.; et al. Clinical Applications of Artificial Intelligence—An Updated Overview. J. Clin. Med. 2022, 11, 2265. [Google Scholar] [CrossRef]
- Paul, M.; Maglaras, L.; Ferrag, M.A.; Almomani, I. Digitization of healthcare sector: A study on privacy and security concerns. ICT Express 2023, 9, 571–588. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, T.; Li, S.; Yuan, X.; Ni, W.; Hossain, E.; Poor, H.V. Adversarial Attacks and Defenses in Machine Learning-Powered Networks: A Contemporary Survey. 2023. Available online: https://arxiv.org/abs/2303.06302v1 (accessed on 27 September 2023).
- Ding, C.; Sun, S.; Zhao, J. Multi-Modal Adversarial Example Detection with Transformer. In Proceedings of the 2022 International Joint Conference on Neural Networks, Padua, Italy, 18–23 July 2022. [Google Scholar] [CrossRef]
- Cao, H.; Zou, W.; Wang, Y.; Song, T.; Liu, M. Emerging Threats in Deep Learning-Based Autonomous Driving: A Comprehensive Survey. 2022. Available online: https://arxiv.org/abs/2210.11237v1 (accessed on 27 September 2023).
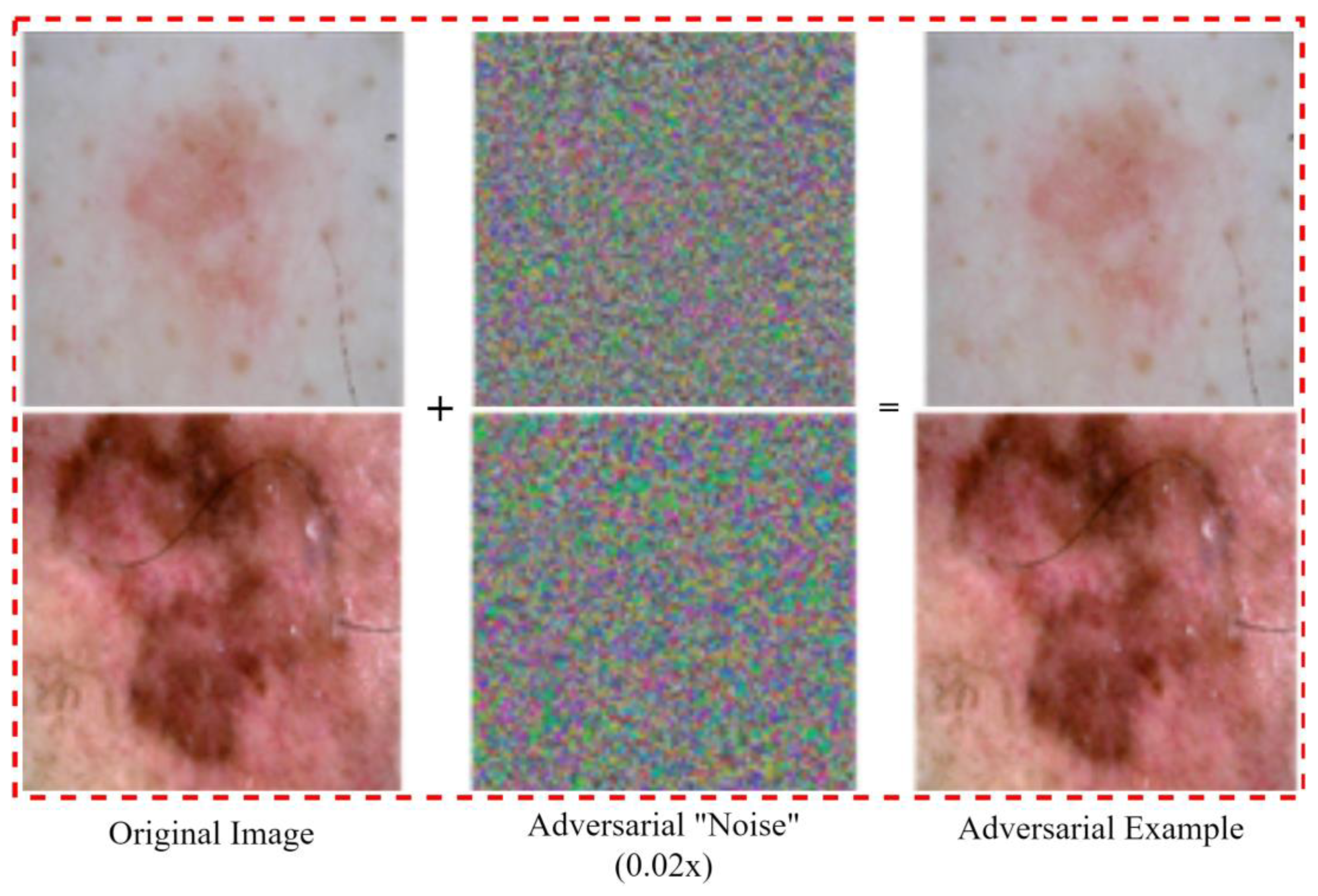













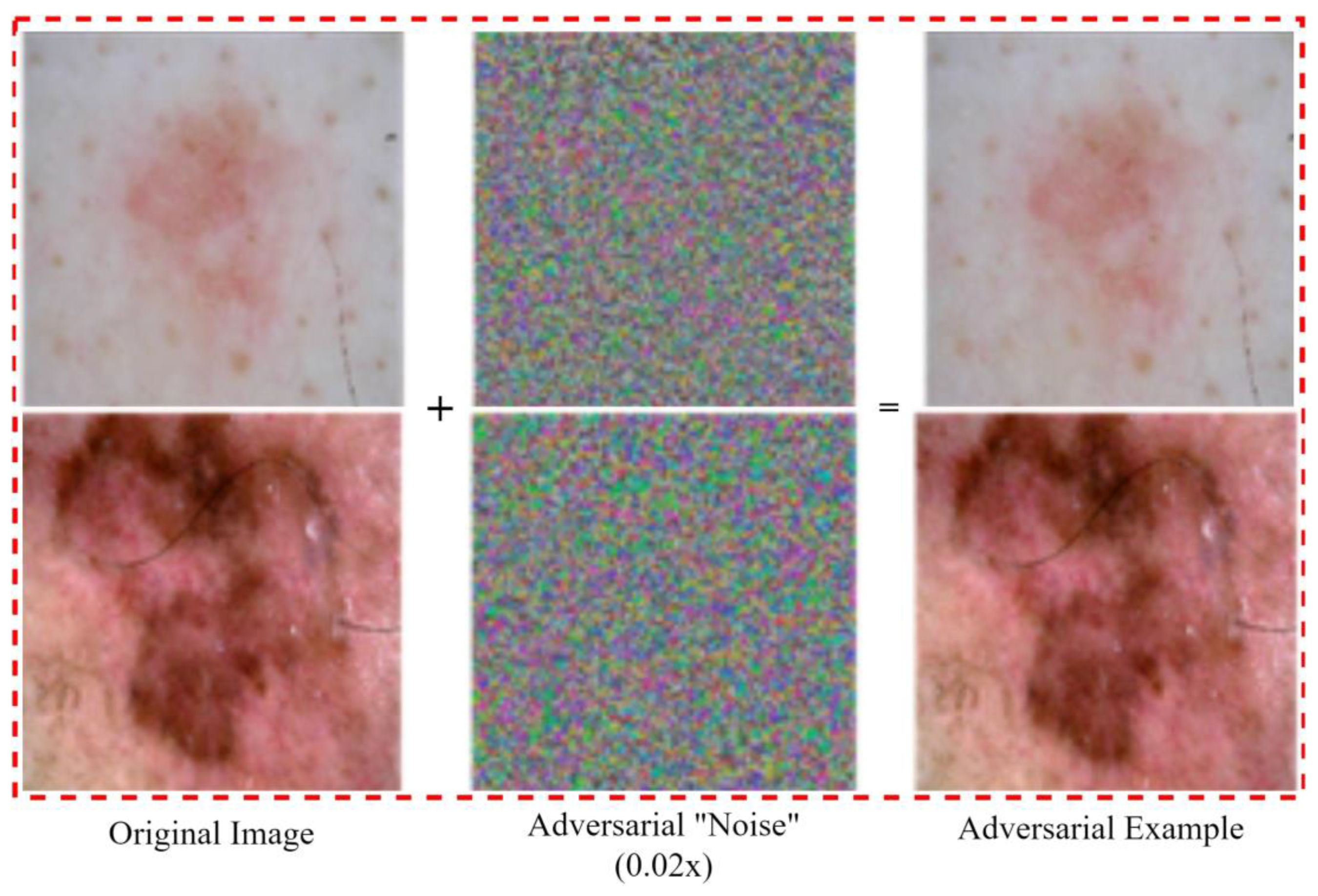{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref./Year | Adversarial Attack Type | Task | Image Modality |
|---|---|---|---|
| [12]/2018 | FGSM, Deep pool, JSMA | Classification/segmentation | MRI, Dermoscopy |
| [75]/2018 | FGSM | Classification | Fundoscopy |
| [13]/2018 | PGD, AdvPatch | Classification | Fundoscopy, X-ray, Dermoscopy |
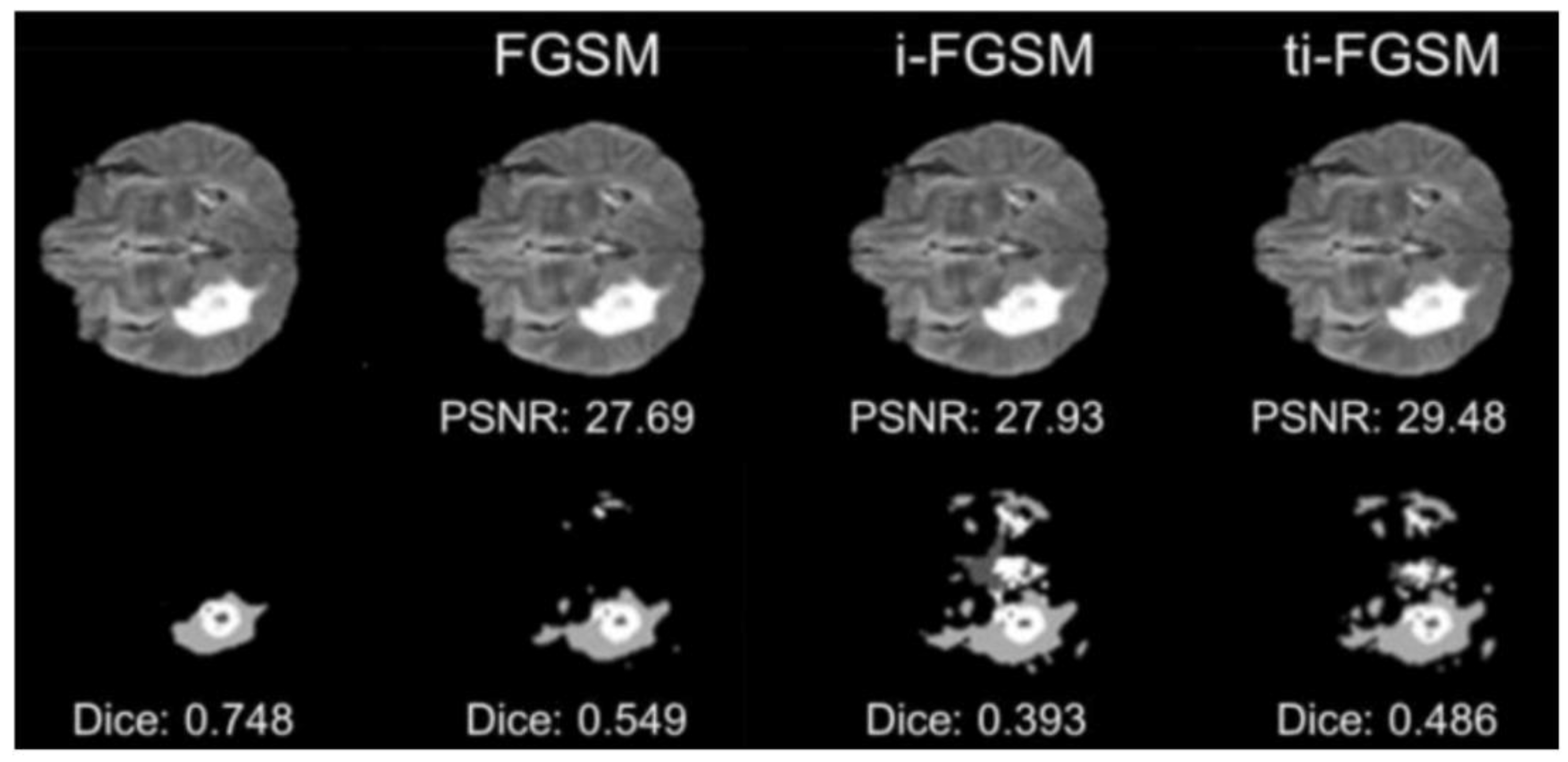
| [76]/2019 | FGSM, I-FGSM, TI-FGSM | Segmentation | MRI |
| [77]/2019 | Multi-task VAE | Segmentation | CT |
| [51]/2019 | Adaptive segmentation mask Attack | Segmentation | Fundoscopy, Dermoscopy |
| [78]/2019 | PDG | Classification | X-ray, Histology |
| [61]/2020 | FGSM, PGD, MI-FGSM, DAA, DII-FGSM | Classification | X-Ray |
| [79]/2020 | Adversarial exposure attack | Classification | Fundoscopy |
| [62]/2020 | BIM, L-BFGS, PGD, JSMA | Classification, Object detection | CT, X-ray |
| [80]/2020 | Zoo | Classification | Ultrasound |
| [81]/2020 | Adaptive targeted I-FGSM | Landmark detection | MRI, X-ray |
| [82]/2020 | FGSM | Classification | Fundoscopy |
| [83]/2021 | UAP | Classification | OCT, X-ray, Dermoscopy |
| [84]/2021 | FGSM, BIM, PGD | Classification | CT, MRI, X-ray |
| [85]/2021 | IND and OOD Attacks | Segmentation | MRI |
| [86]/2021 | Stabilized medical image attack | Classification, Segmentation | CT, Endoscopy, Fundoscopy |
| [87]/2021 | PGD | Segmentation | X-Ray |
| [88]/2021 | CW | Classification | CT, X-ray, Microscopy |
| [89]/2021 | FGSM | Classification | CT, X-ray |
| [90]/2021 | Multi-scale attack | Segmentation | Fundoscopy, Dermoscopy |
| [91]/2022 | AmdGAN | Classification | CT, OCT, X-ray, Fundoscopy, Dermoscopy, Ultrasound, Microscopy |
| [92]/2022 | UAP | Classification | X-ray, Fundoscopy, Dermoscopy |
| [93]/2022 | Attention-based I-FGSM | Classification | CT |
| [94]/2022 | Modified FGSM with with tricks to break defenses | Classification, Segmentation | CT, MRI, X-ray, Dermoscopy, Fundoscopy |
| [95]/2022 | FGSM | Segmentation | Microscopy |
| [96]/2022 | FGSM | Classification | X-ray |
| [97]/2022 | Digital watermarking | Classification | CT, MRI, X-ray |
| [98]/2022 | FGSM, BIM, PGD, No-sign operation | Classification | X-Ray |
| [99]/2022 | FGSM | Classification | Fundoscopy |
| [100]/2022 | FGSM, PGD, CW | Classification | CT, Dermoscopy, Microscopy |
| [101]/2022 | Improved adaptive square attack | Segmentation | X-Ray |
| [43]/2022 | FGSM, BIM, PGD, MI-FGSM | Classification | CT, Fundoscopy |
| [102]/2022 | Adversarial k-space noise, Adversarial rotation | Reconstruction | MRI |
| [103]/2022 | FGSM, L-BFGS | Classification | Fundoscopy |
| [15]/2022 | Feature space-restricted attention attack | Classification | X-ray, Fundoscopy, Dermoscopy |
| [104]/2023 | FGSM, PGD | Classification | Classification |
| [105]/2023 | FGSM | Classification | CT |
| [106]/2023 | PGD, FGSM, BIM, GN | Segmentation | CT, MRI |
| [107]/2023 | PGD, BIM, FGSM | Classification, Detection | CT, MRI |
| [108]/2023 | PDG, CW, BIM | Classification | X-ray, Fundoscopy, Dermoscopy |
| [109]/2023 | FGSM, MI-FGSM, PDG, CW | Reconstruction | X-ray, Fundoscopy |
| [110]/2023 | L-BFGS, FGSM, PDG, CW | Classification, Reconstruction | MNIST |
| [111]/2023 | FGSM, PGD, MIM, CW | Classification, Segmentation | X-Ray, CT, Ultrasound |
| Ref./Year | Evaluation Metrics | Defense Model | Task | Image Modality |
|---|---|---|---|---|
| [57]/2018 | FGSM, PGD, BIM, L-BFGS, DeepFool | Feature enhancement | Classification | X-ray |
| [133]/2018 | FGSM, BIM | Adversarial training | Reconstruction | CT |
| [134]/2019 | FGSM | Adversarial training | Segmentation | MRI |
| [135]/2019 | FGSM, I-FGSM, CW | Feature enhancement | Classification | X-ray, Dermoscopy |
| [21]/2019 | FGSM, CW, PGD, BIM, GN, SPSA, MI-FGSM | Feature enhancement | Classification, Segmentation, Object Detection | X-ray, Dermoscopy |
| [18]/2019 | GN | Adversarial training | Classification | CT, MRI |
| [126]/2019 | I-FGSM | Feature enhancement | Segmentation | X-ray, Dermoscopy |
| [136]/2019 | FGSM, I-FGSM | Adversarial training | Segmentation | CT |
| FGSM | Adversarial training | Classification | MRI | |
| [125]/2019 | Optimization-based attack | Feature enhancement | Low-level vision | X-ray, MRI |
| [137]/2020 | DAG | Adversarial detection | Segmentation | MRI |
| [138]/2020 | FGSM, I-FGSM | Feature enhancement | Regression | MRI |
| [61]/2020 | FGSM, PGD, DAA, MI-FGSM, DII-FGSM | Adversarial Training, Pre-processing | Classification | X-ray |
| [47]/2020 | OPA, FGSM | Adversarial training | Classification | CT |
| [139]/2020 | PGD | Adversarial training | Classification | Fundoscopy |
| [140]/2020 | PGD, FGSM | Adversarial training | Classification, Segmentation | X-ray, MRI |
| [141]/2020 | PGD, I-FGSM | Adversarial training | Classification, Segmentation | CT, MRI |
| [142]/2020 | False-negative adversarial feature | Adversarial training | Reconstruction | MRI |
| [143]/2020 | GAN-based attack | Adversarial training | Reconstruction | CT, X-ray |
| [144]/2020 | PGD, FGSM | Adversarial training | Classification | Dermoscopy |
| [44]/2020 | PGD, BIM, CW, FGSM, DeepFool, | Pre-processing | Classification | CT, X-ray |
| [130]/2020 | PGD | Adversarial training | Classification | CT |
| [64]/2020 | Adversarial bias attack | Adversarial training | Segmentation | MRI |
| [145]/2020 | ASMA | Pre-processing | Segmentation | Fundoscopy, Dermoscopy |
| [131]/2020 | FGSM, Deep Fool, Speckle noise attack | Adversarial training, feature enhancement | Classification | X-ray, Fundoscopy |
| [17]/2021 | FGSM, BIM, PGD, CW | Adversarial detection | Classification | X-ray, Fundoscopy, Dermoscopy |
| [146]/2021 | PGD, CW | Adversarial detection | Classification | X-ray |
| [124]/2021 | PGD, FGSM | Feature enhancement | Segmentation | CT, MRI |
| [83]/2021 | UAP | Adversarial training | Classification | OCT, X-ray, Dermoscopy |
| [70]/2021 | FGSM, PGD, CW | Adversarial training, adversarial detection | Classification | OCT |
| [70]/2021 | PGD, GAP | Adversarial training | Classification | X-ray, Fundoscopy, Dermoscopy |
| [131]/2021 | FGSM, Deep fool, Speckle noise attack | Adversarial training, feature enhancement | Classification | X-ray, Fundoscopy |
| [147]/2021 | FGSM | Adversarial training | Segmentation | CT |
| [148]/2021 | FGSM, BIM, CW, Deep Fool | Adversarial detection | Classification | Microscopy |
| [120]/2021 | PGD | Feature enhancement | Classification | CT, MRI, X-ray |
| [19]/2021 | FGSM | Adversarial training | Object Detection | CT, Microscopy |
| [76]/2021 | FGSM, I-FGSM, TI-FGSM | Distillation | Segmentation | MRI |
| [149]/2021 | PGD, AA | Feature enhancement, adversarial training | Segmentation | CT, MRI |
| [150]/2022 | FGSM | Adversarial training | Classification | MRI |
| [46]/2022 | FGSM, PGD | Pre-processing | Classification | X-ray |
| [151]/2022 | Hop skip jump attack | Adversarial detection | Classification | MRI, X-ray, Microscopy |
| [20]/2022 | I-FGSM, PGD, CW | Pre-processing | Classification | X-ray, Dermoscopy |
| [127]/2022 | FGSM, PGD, BIM | Adversarial training | Classification | CT, MRI, X-ray |
| [152]/2022 | OPA | Adversarial detection | Classification | Microscopy |
| [128]/2022 | DDN | Adversarial training | Classification | MRI |
| [153]/2022 | FGSM, PGD | Adversarial training | Classification | OCT, X-ray, Dermoscopy |
| [154]/2022 | PGD, I-FGSM | Adversarial training | Segmentation, Object Detection, Landmark Detection | MRI, X-ray, Microscopy |
| [155]/2022 | FGSM, PGD, BIM | Adversarial training | Classification | CT, MRI, X-ray |
| [156]/2022 | FGSM, BIM, CW, PGD, AA, DI-FGSM | Pre-processing | Classification | Dermoscopy |
| [157]/2022 | FGSM, PGD, FAB, Square attack | Feature enhancement | Classification | Microscopy |
| [158]/2022 | FGSM, PGD, Square attack, Moment-based adversarial attack | Adversarial training | Classification, Segmentation | X-ray, Microscopy |
| [132]/2022 | FGSM, PGD, BIM, Auto PGD | Adversarial detection, feature enhancement | Classification | X-ray, Fundoscopy |
| [159]/2022 | FGSM, PGD, CW | Adversarial training, feature enhancement | Classification | Ultrasound |
| [160]/2022 | FGSM, PGD, SMA | Feature enhancement | Segmentation | CT |
| [103]/2022 | L-BFGS, FGSM | Adversarial training, distillation | Classification | Fundoscopy |
| [161]/2022 | FGSM | Adversarial training | Classification | Microscopy |
| [119]/2022 | FGSM | Feature enhancement | Classification | Fundoscopy |
| [162]/2022 | DAG, I-FGSM | Pre-processing | Segmentation | MRI, X-ray, Fundoscopy |
| [163]/2022 | PGD | Adversarial training | Segmentation | MRI |
| [164]/2022 | FGSM, PGD | Feature enhancement | Classification | X-ray, Fundoscopy |
| [104]/2023 | FGSM, PGD | Adversarial training | Classification | Dermoscopy |
| [105]/2023 | FGSM | Adversarial training | Classification | CT |
| [106]/2023 | PDG, FGSM, BIM, GN | Adversarial training | Segmentation | MRI |
| [107]/2023 | PGD, BIM, FGSM | Adversarial training | Classification, Detection | CT, MRI |
| [108]/2023 | PDG, CW, BIM | Feature enhancement | Classification | X-ray, Fundoscopy, Dermoscopy |
| [109]/2023 | FGSM, MI-FGSM, PDG, CW | Adversarial training, feature distillation | Reconstruction | X-ray, Fundoscopy |
| [110]/2023 | L-BFGS, FGSM, PDG, CW | Adversarial training | Classification, Reconstruction | MNIST |
| [111]/2023 | FGSM, PGD, MIM, CW | Adversarial training | Classification, Segmentation | X-Ray, CT, Ultrasound |
| Resnet-18 Architecture | |
| Input size | 224 × 224 |
| Weight decay | 1 × 10−4 |
| momentum | 0.9 |
| Mini batch | 256 |
| Optimizer | Adams optimizer |
| Initial learning rate | 0.1 |
| Reduction in learning rate | 10 per 30 epochs |
| Iterations—number of epoch | 100 |
| Loss function | Categorical Cross-Entropy |
| Batch size | 4 |
| UNET Architecture for Segmentation | |
| Input size | 256 × 256 × 3 |
| Filters per convolutional layer | 64, 128, 256, 512, 1024 |
| Optimizer | Adams Optimizer |
| Training loss | Binary cross entropy (BCE) and Dice loss |
| Cosine annealing learning rate scheduler/learning rate | 1 × 10−4 |
| momentum | 0.9 |
| Epoch | 400 |
| Batch size | 8 |
| Adversarial attack perturbations | 1, 2, 4, 6, 8 |
| Auto Encoder-Block Switching Architecture | |
| Input size | 224 × 224 × 3 |
| Weight decay | 1 × 10−4 |
| Optimizer | Adams optimizer |
| learning rate | 0.002 |
| Number of epoch | 150 |
| Loss function | Mean Square Error |
| Batch size | 4 |
| Input size | 224 × 224 |
| Adversarial attack perturbations | 1, 2, 4, 6, 8 |
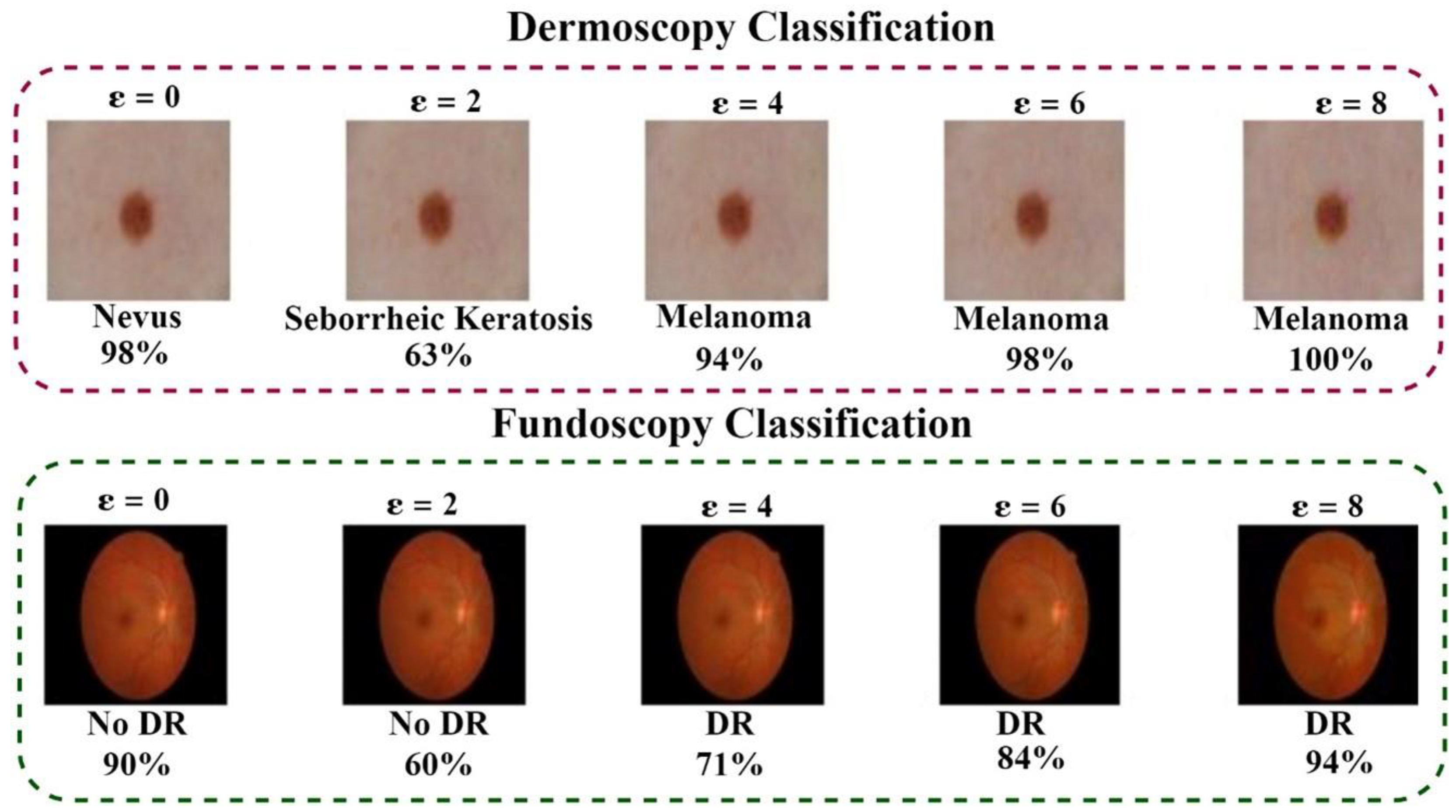
| Adversarial Attack Type | ε | Dermoscopy | Fundoscopy | ||
|---|---|---|---|---|---|
| Binary (%) | Multi-Class (%) | Binary (%) | Multi-Class (%) | ||
| Clean Image | 0 | 71.3 | 50.0 | 64.9 | 60.0 |
| AA [167] | 2/255 | 22.1 | 2.4 | 3.8 | 2.5 |
| 4/255 | 8.4 | 0.8 | 0.0 | 0.0 | |
| 6/255 | 4.5 | 0.3 | 0.0 | 0.0 | |
| 8/255 | 1.6 | 0.1 | 0.0 | 0.0 | |
| CW [41] | 2/255 | 22.5 | 2.5 | 7.1 | 6.7 |
| 4/255 | 9.3 | 0.9 | 1.3 | 2.1 | |
| 6/255 | 5.2 | 0.7 | 0.0 | 0.0 | |
| 8/255 | 2.1 | 0.4 | 0.0 | 0.0 | |
| FGSM [42] | 2/255 | 37.6 | 4.8 | 38.8 | 13.8 |
| 4/255 | 35.7 | 4.5 | 27.9 | 9.2 | |
| 6/255 | 36.2 | 6.1 | 25.7 | 15.3 | |
| 8/255 | 34.5 | 8.0 | 24.2 | 20.4 | |
| PGD [45] | 2/255 | 22.8 | 2.6 | 8.8 | 4.6 |
| 4/255 | 12.5 | 0.8 | 1.7 | 0.4 | |
| 6/255 | 11.9 | 0.6 | 0.2 | 0.0 | |
| 8/255 | 12.8 | 0.4 | 0.0 | 0.0 | |
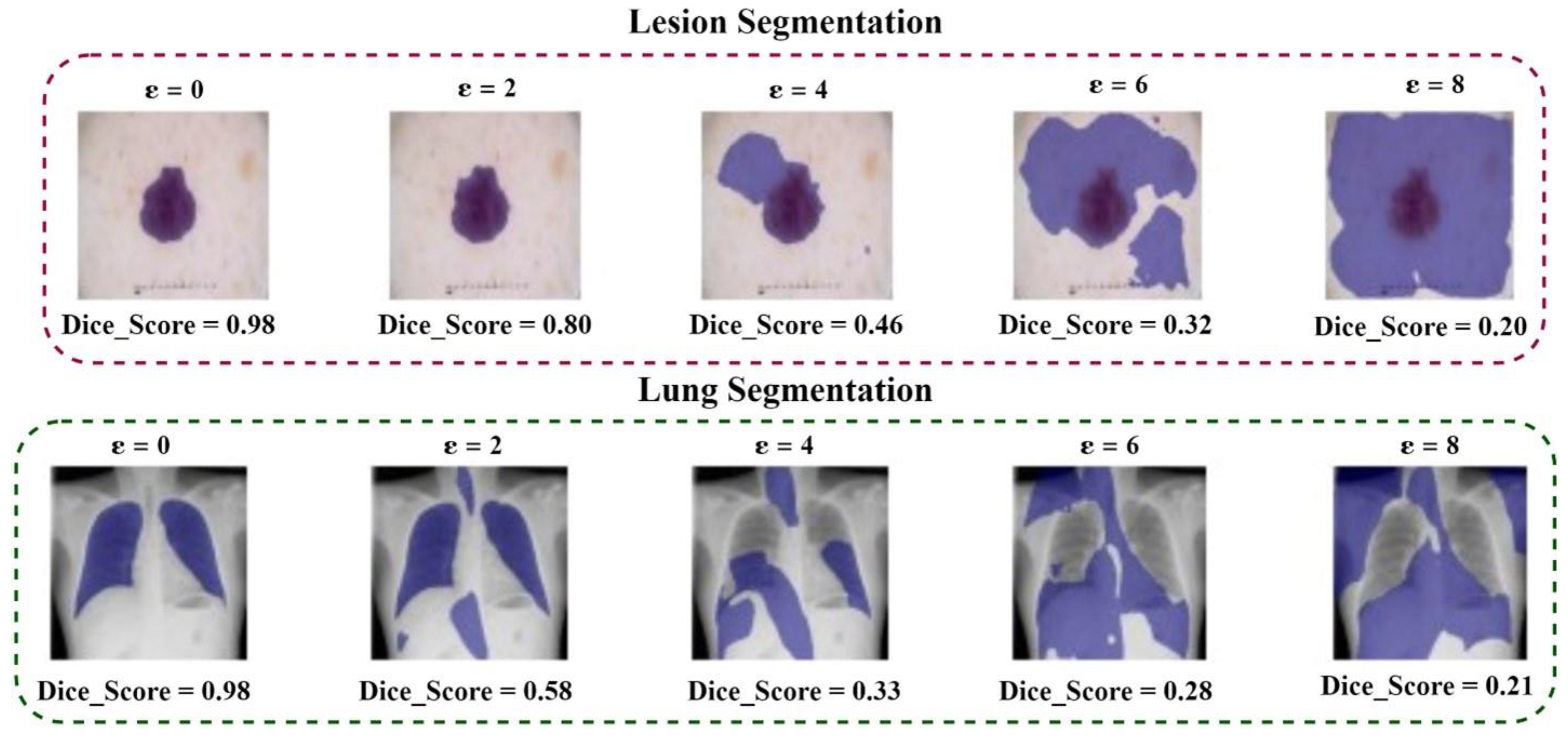
| Adversarial Loss | ε | COVID-19 | Dermoscopy | ||
|---|---|---|---|---|---|
| mIOU | Dice | mIOU | Dice | ||
| None | 0 | 0.976 | 0.982 | 0.801 | 0.875 |
| BCE | 2/255 | 0.559 | 0.690 | 0.405 | 0.517 |
| 4/255 | 0.355 | 0.492 | 0.248 | 0.354 | |
| 6/255 | 0.200 | 0.412 | 0.198 | 0.301 | |
| 8/255 | 0.230 | 0.350 | 0.167 | 0.255 | |
| Dice | 2/255 | 0.473 | 0.610 | 0.340 | 0.450 |
| 4/255 | 0.265 | 0.391 | 0.158 | 0.243 | |
| 6/255 | 0.213 | 0.332 | 0.102 | 0.198 | |
| 8/255 | 0.152 | 0.246 | 0.082 | 0.140 | |
| Adversarial Attack Type | ε | Dermoscopy | Fundoscopy | ||
|---|---|---|---|---|---|
| Binary (%) | Multi-Class (%) | Binary(%) | Multi-Class (%) | ||
| Clean Image | 0 | 61.2 | 52 | 64.9 | 60 |
| AA [167] | 2/255 | 55.6 | 43.7 | 55.2 | 41.3 |
| 4/255 | 48.4 | 35.5 | 52.3 | 35 | |
| 6/255 | 41.6 | 26 | 36.2 | 31.9 | |
| 8/255 | 34.8 | 20.9 | 42.1 | 28.3 | |
| CW [41] | 2/255 | 55.6 | 43.6 | 56.4 | 42.3 |
| 4/255 | 48.5 | 36.2 | 53.6 | 34.9 | |
| 6/255 | 42.5 | 29.4 | 48 | 31.6 | |
| 8/255 | 36.8 | 23.3 | 43.5 | 28.8 | |
| FGSM [42] | 2/255 | 55.6 | 44.5 | 55.6 | 44.5 |
| 4/255 | 49.2 | 38.2 | 53.6 | 40 | |
| 6/255 | 44.3 | 32.3 | 49.3 | 38.2 | |
| 8/255 | 39.5 | 25.5 | 45.5 | 36.4 | |
| PGD [45] | 2/255 | 57.9 | 48 | 56.4 | 41.6 |
| 4/255 | 48.2 | 36.2 | 53.2 | 36.4 | |
| 6/255 | 42.4 | 29.7 | 48.2 | 33.8 | |
| 8/255 | 35.1 | 22.4 | 43.6 | 31.2 | |
| Adversarial Loss | ε | COVID-19 | Dermoscopy | ||
|---|---|---|---|---|---|
| mIOU (%) | Dice (%) | mIOU (%) | Dice (%) | ||
| None | 0 | 0.976 | 0.982 | 0.801 | 0.875 |
| BCE | 2/255 | 0.931 | 0.962 | 0.773 | 0.842 |
| 4/255 | 0.890 | 0.940 | 0.733 | 0.810 | |
| 6/255 | 0.854 | 0.912 | 0.684 | 0.705 | |
| 8/255 | 0.812 | 0.887 | 0.601 | 0.700 | |
| Dice | 2/255 | 0.923 | 0.958 | 0.767 | 0.838 |
| 4/255 | 0.880 | 0.932 | 0.723 | 0.803 | |
| 6/255 | 0.832 | 0.894 | 0.669 | 0.750 | |
| 8/255 | 0.774 | 0.860 | 0.594 | 0.694 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muoka, G.W.; Yi, D.; Ukwuoma, C.C.; Mutale, A.; Ejiyi, C.J.; Mzee, A.K.; Gyarteng, E.S.A.; Alqahtani, A.; Al-antari, M.A. A Comprehensive Review and Analysis of Deep Learning-Based Medical Image Adversarial Attack and Defense. Mathematics 2023, 11, 4272. https://doi.org/10.3390/math11204272
Muoka GW, Yi D, Ukwuoma CC, Mutale A, Ejiyi CJ, Mzee AK, Gyarteng ESA, Alqahtani A, Al-antari MA. A Comprehensive Review and Analysis of Deep Learning-Based Medical Image Adversarial Attack and Defense. Mathematics. 2023; 11(20):4272. https://doi.org/10.3390/math11204272
Chicago/Turabian StyleMuoka, Gladys W., Ding Yi, Chiagoziem C. Ukwuoma, Albert Mutale, Chukwuebuka J. Ejiyi, Asha Khamis Mzee, Emmanuel S. A. Gyarteng, Ali Alqahtani, and Mugahed A. Al-antari. 2023. "A Comprehensive Review and Analysis of Deep Learning-Based Medical Image Adversarial Attack and Defense" Mathematics 11, no. 20: 4272. https://doi.org/10.3390/math11204272
APA StyleMuoka, G. W., Yi, D., Ukwuoma, C. C., Mutale, A., Ejiyi, C. J., Mzee, A. K., Gyarteng, E. S. A., Alqahtani, A., & Al-antari, M. A. (2023). A Comprehensive Review and Analysis of Deep Learning-Based Medical Image Adversarial Attack and Defense. Mathematics, 11(20), 4272. https://doi.org/10.3390/math11204272