
Statistical Inference for Partially Linear Varying Coefficient Spatial Autoregressive Panel Data Model



Abstract
:1. Introduction
2. Model Estimation
3. Asymptotic Properties
- (C1)
- are independent and identically distributed, and for all , . Moreover, there exists a positive constant such that , , and
- (C2)
- The matrix is nonsingular with , and the row and column sums of the matrices W and are bounded uniformly in absolute value for any . Moreover, for the matrix , there exists a constant such that is positive semidefinite.
- (C3)
- Let the internal knots of the spline be , . Also, letting and , there exists a constant such that
- (C4)
- , where denotes the set of functions with the mth bounded continuous derivatives on the interval .
- (C5)
- For the knot number , it is assumed that , and , where means that the ratio is bounded away from zero and infinity.
- (C6)
- converges in probability to a positive definite matrix , where and .
- (C7)
- For the matrix there exists a constant such that is positive semidefinite.
- (C8)
- The density function of , , is bounded away from zero and infinity on . Furthermore, we assume that is continuously differentiable on .
- (C9)
- Denote and . We assume that is a nonsingular constant matrix.
4. Simulation Study
5. A Real Data Example
6. Conclusions and Discussion
7. Proof of the Main Results
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cliff, A.; Ord, J.K. Spatial Autocorrelation; Pion: London, UK, 1973. [Google Scholar]
- Anselin, L. Spatial Econometrics: Methods and Models; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1988. [Google Scholar]
- Lee, L.F. Best spatial two-stage least squares estimators for a spatial autoregressive model with autoregressive disturbances. Econom. Rev. 2003, 22, 307–335. [Google Scholar] [CrossRef]
- Lee, L.F.; Yu, J.H. A spatial dynamic panel data model with both time and individual fixed effects. Econom. Theory 2007, 26, 564–597. [Google Scholar] [CrossRef]
- Su, L.J.; Jin, S.N. Profile quasi-maximum likelihood estimation of partially linear spatial autoregressive models. J. Econom. 2010, 157, 18–33. [Google Scholar] [CrossRef]
- Su, L.J. Semiparametric GMM estimation of spatial autoregressive models. J. Econom. 2012, 167, 543–560. [Google Scholar] [CrossRef]
- Malikov, E.; Sun, Y.G. Semiparametric estimation and testing of smooth coefficient spatial autoregressive models. In Working Paper; University of Guelph: Guelph, ON, Canada, 2015. [Google Scholar]
- Sun, Y.G. Functional-coefficient spatial autoregressive models with nonparametric spatial weights. J. Econom. 2016, 195, 134–153. [Google Scholar] [CrossRef]
- Du, J.; Sun, X.Q.; Cao, R.Y.; Zhang, Z.Z. Statistical inference for partially linear additive spatial autoregressive models. Spat. Stat. 2018, 25, 52–67. [Google Scholar] [CrossRef]
- Arellano, M. Panel Data Econometrics; Oxford University Press: New York, NY, USA, 2003. [Google Scholar]
- Baltagi, B.H. Econometric Analysis of Panel Data, 5th ed.; Wiley: New York, NY, USA, 2013. [Google Scholar]
- Lee, L.F.; Yu, J.H. Estimation of spatial autoregressive panel data models with fixed effects. J. Econom. 2010, 154, 165–185. [Google Scholar] [CrossRef]
- Zhang, Y.Q.; Shen, D.M. Estimation of semi-parametric varying-coefficient spatial panel data models with random-effects. J. Stat. Plan. Inference 2015, 159, 64–80. [Google Scholar] [CrossRef]
- Ai, C.R.; Zhang, Y.Q. Estimation of partially specified spatial panel data models with fixed-effects. Econom. Rev. 2017, 36, 6–22. [Google Scholar] [CrossRef]
- Li, K.P. Fixed-effects dynamic spatial panel data models and impulse response analysis. J. Econom. 2017, 198, 102–121. [Google Scholar] [CrossRef]
- Sun, Y.G.; Malikov, E. Estimation and inference in functional-coefficient spatial autoregressive panel data models with fixed effects. J. Econom. 2018, 203, 359–378. [Google Scholar] [CrossRef]
- He, B.Q.; Hong, X.J.; Fan, G.L. Empirical likelihood for semi-varying coefficient models for panel data with fixed effects. J. Korean Stat. Soc. 2016, 45, 395–408. [Google Scholar] [CrossRef]
- Li, D.G.; Chen, J.; Gao, J.T. Nonparametric time-varying coefficient panel data models with fixed effects. Econom. J. 2011, 14, 387–408. [Google Scholar] [CrossRef]
- Rodriguez-Poo, J.M.; Soberon, A. Nonparametric estimation of fixed effects panel data varying coefficient models. J. Multivar. Anal. 2015, 133, 95–122. [Google Scholar] [CrossRef]
- Feng, S.Y.; He, W.Q.; Li, F. Model detection and estimation for varying coefficient panel data models with fixed effects. Comput. Stat. Data Anal. 2020, 152, 107054. [Google Scholar] [CrossRef]
- Kelejian, H.H.; Prucha, I.R. A generalized spatial two-stage least squares procedure for estimating a spatial autoregressive model with autoregressive disturbances. J. Real Estate Financ. Econ. 1998, 17, 99–121. [Google Scholar] [CrossRef]
- Owen, A.B. Empirical likelihood ratio confidence intervals for a single functional. Biometrika 1988, 75, 237–249. [Google Scholar] [CrossRef]
- Xue, L.G.; Zhu, L.X. Empirical likelihood-based inference in a partially linear model for longitudinal data. Sci. China Ser. A Math. 2008, 51, 115–130. [Google Scholar] [CrossRef]
- Li, G.R.; Lin, L.; Zhu, L.X. Empirical likelihood for a varying coefficient partially linear model with diverging number of parameters. J. Multivar. Anal. 2012, 105, 85–111. [Google Scholar] [CrossRef]
- Schumaker, L.L. Spline Functions; Wiley: New York, NY, USA, 1981. [Google Scholar]
- Allen, J.; Gregory, A.W.; Shimotsu, K. Empirical likelihood block bootstrapping. J. Econom. 2011, 161, 110–121. [Google Scholar] [CrossRef]
- Stone, C.J. Optimal global rates of convergence for nonparametric regression. Ann. Stat. 1982, 10, 1348–1360. [Google Scholar] [CrossRef]
- Case, A.C. Spatial patterns in household demand. Econometrica 1991, 59, 953–965. [Google Scholar] [CrossRef]
- Munnell, A.H. Why has productivity growth declined? Productivity and public investment. N. Engl. Econ. Rev. 1990, 30, 3–22. [Google Scholar]
- Baltagi, B.H.; Pinnoi, N. Public capital stock and state productivity growth: Further evidence from an error components model. Empir. Econ. 1995, 20, 351–359. [Google Scholar] [CrossRef]
- Feng, S.Y.; Li, G.R.; Tong, T.J.; Luo, S.H. Testing for heteroskedasticity in two-way fixed effects panel data models. J. Appl. Stat. 2020, 47, 91–116. [Google Scholar] [CrossRef]
- Xu, Y.H.; Yang, Z.L. Specification tests for temporal heterogeneity in spatial panel data models with fixed effects. Reg. Sci. Urban Econ. 2020, 81, 103488. [Google Scholar] [CrossRef]
- Zhang, R.Q.; Lu, Y.Q. Varying-Coefficient Model; Science Press: Beijing, China, 2004. [Google Scholar]
- Zhao, P.X.; Xue, L.G. Empirical likelihood inferences for semiparametric varying-coefficient partially linear models with longitudinal data. Commun. Stat. Theory Methods 2010, 39, 1898–1914. [Google Scholar] [CrossRef]
- Cai, Z.W.; Xiong, H.Y. Partially varying coefficient instrumental variables models. Stat. Neerl. 2012, 66, 85–110. [Google Scholar] [CrossRef]
- Wilkinson, J.H. The Algebraic Eigenvalue Problem; Clarendon: Oxford, UK, 1965. [Google Scholar]
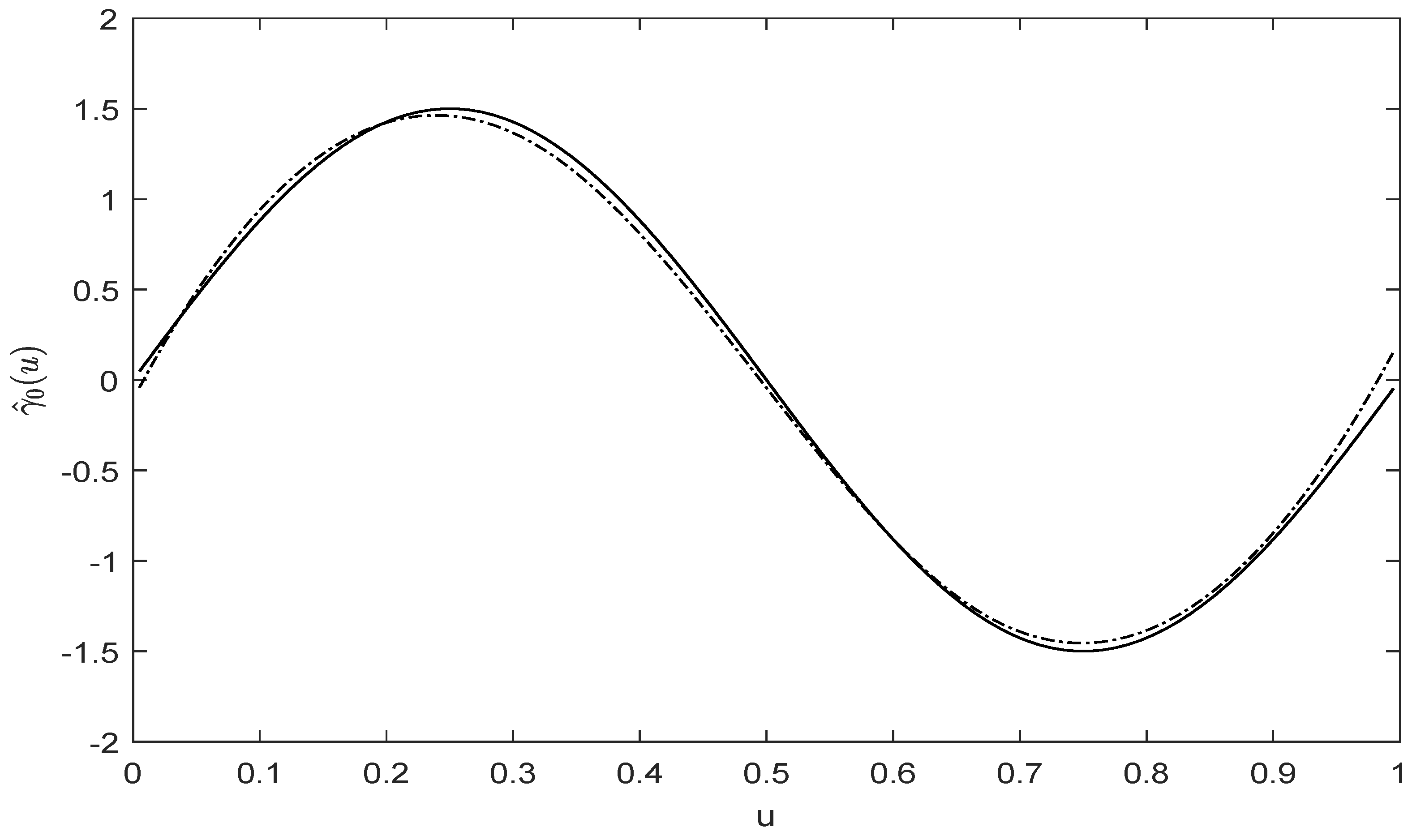
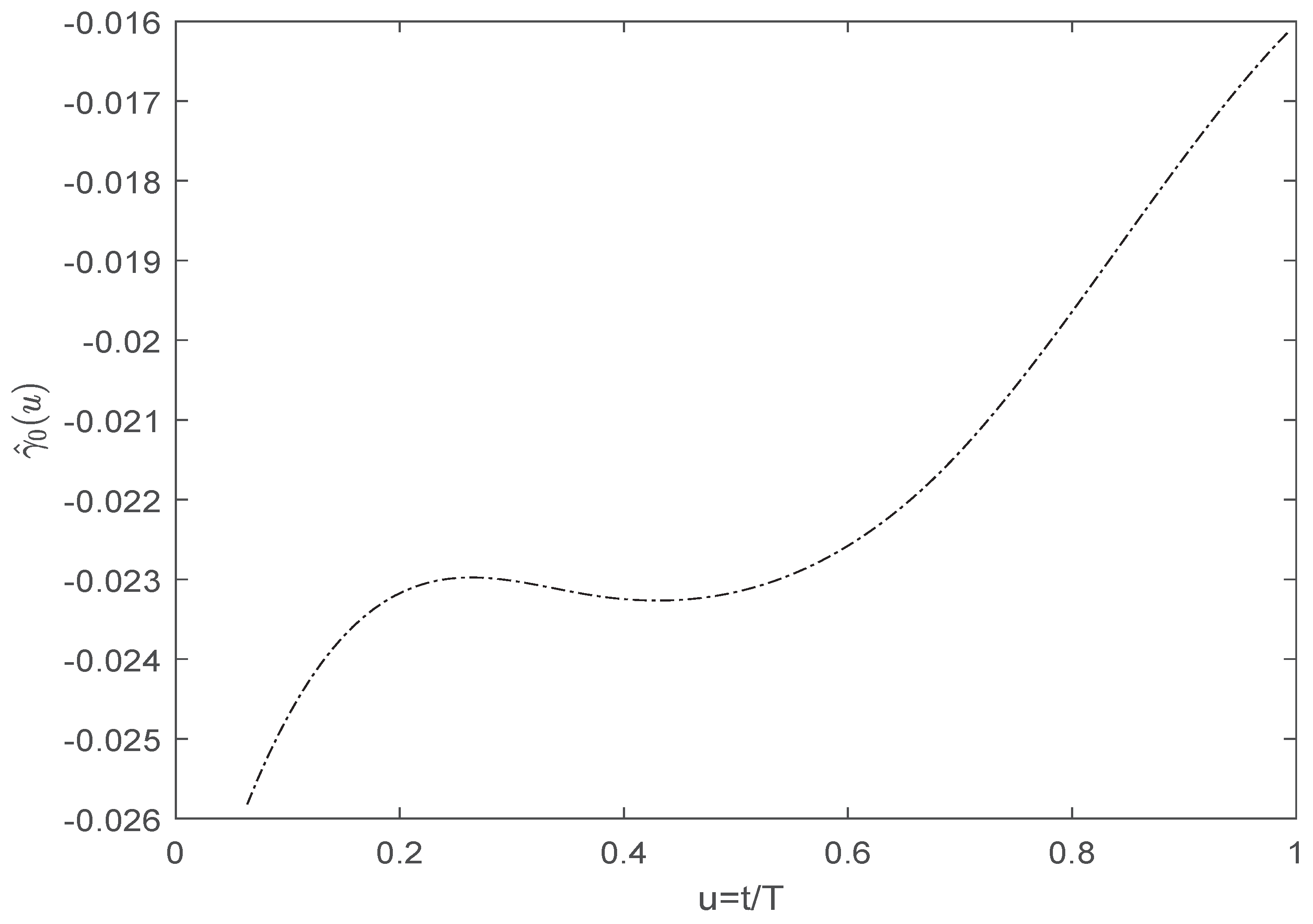

{kind=link}
{kind=link}
| T | Bias | SD | Bias | SD | Bias | SD | RASE | ||
|---|---|---|---|---|---|---|---|---|---|
| 0.2 | 4 | 0.0003 | 0.0077 | 0.0010 | 0.0211 | −0.0023 | 0.0264 | 0.0861 | |
| 6 | 0.0004 | 0.0067 | 0.0015 | 0.0132 | 0.0031 | 0.0189 | 0.0656 | ||
| 4 | −0.0001 | 0.0082 | 0.0011 | 0.0113 | 0.0033 | 0.0184 | 0.0615 | ||
| 6 | −0.0002 | 0.0062 | −0.0012 | 0.0095 | 0.0034 | 0.0141 | 0.0465 | ||
| 4 | 0.0005 | 0.0064 | −0.0005 | 0.0132 | 0.0035 | 0.0092 | 0.0682 | ||
| 6 | −0.0001 | 0.0056 | 0.0035 | 0.0099 | 0.0019 | 0.0089 | 0.0523 | ||
| 4 | 0.0002 | 0.0060 | 0.0007 | 0.0095 | 0.0022 | 0.0086 | 0.0485 | ||
| 6 | −0.0003 | 0.0047 | 0.0007 | 0.0082 | −0.0010 | 0.0075 | 0.0372 | ||
| 0.5 | 4 | −0.0013 | 0.0050 | 0.0020 | 0.0225 | 0.0004 | 0.0265 | 0.0824 | |
| 6 | 0.0002 | 0.0046 | 0.0013 | 0.0141 | 0.0030 | 0.0191 | 0.0656 | ||
| 4 | −0.0001 | 0.0053 | 0.0011 | 0.0113 | 0.0031 | 0.0181 | 0.0615 | ||
| 6 | −0.0001 | 0.0041 | −0.0012 | 0.0096 | 0.0033 | 0.0145 | 0.0466 | ||
| 4 | 0.0003 | 0.0044 | −0.0008 | 0.0139 | 0.0024 | 0.0094 | 0.0688 | ||
| 6 | 0.0001 | 0.0032 | 0.0045 | 0.0104 | 0.0002 | 0.0091 | 0.0522 | ||
| 4 | 0.0001 | 0.0039 | 0.0007 | 0.0097 | 0.0020 | 0.0086 | 0.0481 | ||
| 6 | −0.0002 | 0.0031 | 0.0005 | 0.0082 | 0.0001 | 0.0079 | 0.0372 | ||
| 0.8 | 4 | −0.0006 | 0.0022 | 0.0032 | 0.0241 | 0.0008 | 0.0266 | 0.0872 | |
| 6 | 0.0001 | 0.0020 | 0.0011 | 0.0145 | 0.0029 | 0.0194 | 0.0665 | ||
| 4 | 0.0000 | 0.0021 | 0.0012 | 0.0113 | 0.0033 | 0.0181 | 0.0616 | ||
| 6 | 0.0002 | 0.0017 | −0.0012 | 0.0099 | 0.0013 | 0.0144 | 0.0465 | ||
| 4 | 0.0001 | 0.0019 | −0.0011 | 0.0151 | 0.0031 | 0.0098 | 0.0682 | ||
| 6 | 0.0003 | 0.0014 | 0.0046 | 0.0112 | 0.0020 | 0.0094 | 0.0522 | ||
| 4 | 0.0001 | 0.0016 | 0.0006 | 0.0103 | 0.0012 | 0.0088 | 0.0485 | ||
| 6 | −0.0001 | 0.0013 | −0.0009 | 0.0089 | 0.0005 | 0.0081 | 0.0372 | ||
| T | EL | 2SLS | EL | 2SLS | EL | 2SLS | ||
|---|---|---|---|---|---|---|---|---|
| 0.2 | (30, 4) | 4 | 0.9320 (0.0219) | 0.9240 (0.0264) | 0.9310 (0.0727) | 0.9270 (0.0753) | 0.9350 (0.1185) | 0.9280 (0.1296) |
| 6 | 0.9360 (0.0211) | 0.9270 (0.0263) | 0.9340 (0.0624) | 0.9310 (0.0652) | 0.9390 (0.0814) | 0.9310 (0.0908) | ||
| (30, 8) | 4 | 0.9370 (0.0197) | 0.9310 (0.0189) | 0.9350 (0.0613) | 0.9320 (0.0667) | 0.9390 (0.0765) | 0.9320 (0.0764) | |
| 6 | 0.9410 (0.0158) | 0.9340 (0.0171) | 0.9420 (0.0508) | 0.9360 (0.0516) | 0.9410 (0.0546) | 0.9380 (0.0529) | ||
| (50, 4) | 4 | 0.9390 (0.0206) | 0.9320 (0.0217) | 0.9360 (0.0677) | 0.9320 (0.0717) | 0.9380 (0.0783) | 0.9320 (0.0822) | |
| 6 | 0.9410 (0.0160) | 0.9330 (0.0152) | 0.9410 (0.0551) | 0.9370 (0.0572) | 0.9420 (0.0638) | 0.9360 (0.0637) | ||
| (50, 8) | 4 | 0.9450 (0.0145) | 0.9390 (0.0151) | 0.9440 (0.0438) | 0.9410 (0.0496) | 0.9450 (0.0588) | 0.9400 (0.0607) | |
| 6 | 0.9480 (0.0139) | 0.9440 (0.0148) | 0.9520 (0.0332) | 0.9450 (0.0375) | 0.9510 (0.0579) | 0.9450 (0.0594) | ||
| 0.5 | (30, 4) | 4 | 0.9320 (0.0175) | 0.9220 (0.0165) | 0.9310 (0.0754) | 0.9260 (0.0818) | 0.9330 (0.1257) | 0.9290 (0.1359) |
| 6 | 0.9350 (0.0111) | 0.9260 (0.0139) | 0.9330 (0.0642) | 0.9320 (0.0710) | 0.9380 (0.0899) | 0.9330 (0.1084) | ||
| (30, 8) | 4 | 0.9350 (0.0129) | 0.9290 (0.0137) | 0.9360 (0.0643) | 0.9330 (0.0695) | 0.9390 (0.0856) | 0.9320 (0.0976) | |
| 6 | 0.9390 (0.0109) | 0.9330 (0.0123) | 0.9410 (0.0537) | 0.9370 (0.0641) | 0.9420 (0.0751) | 0.9370 (0.0825) | ||
| (50, 4) | 4 | 0.9390 (0.0116) | 0.9340 (0.0136) | 0.9350 (0.0706) | 0.9320 (0.0742) | 0.9370 (0.0875) | 0.9310 (0.0922) | |
| 6 | 0.9420 (0.0096) | 0.9370 (0.0105) | 0.9410 (0.0551) | 0.9360 (0.0612) | 0.9420 (0.0779) | 0.9350 (0.0793) | ||
| (50, 8) | 4 | 0.9440 (0.0101) | 0.9410 (0.0120) | 0.9450 (0.0509) | 0.9410 (0.0528) | 0.9440 (0.0636) | 0.9410 (0.0737) | |
| 6 | 0.9470 (0.0089) | 0.9430 (0.0108) | 0.9490 (0.0388) | 0.9460 (0.0439) | 0.9480 (0.0680) | 0.9440 (0.0687) | ||
| 0.8 | (30, 4) | 4 | 0.9270 (0.0097) | 0.9210 (0.0095) | 0.9330 (0.0928) | 0.9290 (0.1087) | 0.9320 (0.1286) | 0.9310 (0.1421) |
| 6 | 0.9310 (0.0085) | 0.9240 (0.0088) | 0.9350 (0.0723) | 0.9310 (0.0862) | 0.9380 (0.1014) | 0.9320 (0.1017) | ||
| (30, 8) | 4 | 0.9330 (0.0072) | 0.9280 (0.0093) | 0.9350 (0.0653) | 0.9320 (0.0729) | 0.9380 (0.0896) | 0.9330 (0.0934) | |
| 6 | 0.9360 (0.0066) | 0.9310 (0.0078) | 0.9390 (0.0508) | 0.9360 (0.0571) | 0.9410 (0.0813) | 0.9360 (0.0869) | ||
| (50, 4) | 4 | 0.9350 (0.0066) | 0.9310 (0.0086) | 0.9340 (0.0716) | 0.9320 (0.0838) | 0.9360 (0.0908) | 0.9330 (0.0992) | |
| 6 | 0.9390 (0.0053) | 0.9350 (0.0067) | 0.9390 (0.0551) | 0.9370 (0.0657) | 0.9410 (0.0845) | 0.9360 (0.0911) | ||
| (50, 8) | 4 | 0.9420 (0.0057) | 0.9380 (0.0062) | 0.9440 (0.0514) | 0.9420 (0.0554) | 0.9430 (0.0816) | 0.9390 (0.0838) | |
| 6 | 0.9450 (0.0043) | 0.9410 (0.0059) | 0.9470 (0.0388) | 0.9470 (0.0513) | 0.9470 (0.0774) | 0.9420 (0.0825) | ||
| Model (11) | Model (12) | |||||
|---|---|---|---|---|---|---|
| EST | EST | |||||
| 0.0908 | [0.0036, 0.1780] | [0.0419, 0.1386] | 0.0838 | [0.0108, 0.1568] | [0.0346, 0.1318] | |
| −0.0122 | [−0.1110, 0.0866] | [−0.1312, 0.1067] | — | — | — | |
| 0.8633 | [0.7773, 0.9493] | [0.8104, 0.9169] | 0.8657 | [0.7797, 0.9517] | [0.8122, 0.9197] | |
| −0.0039 | [−0.0055,−0.0023] | [−0.0048,−0.0030] | −0.0040 | [−0.0056,−0.0025] | [−0.0049,−0.0031] | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, S.; Tong, T.; Chiu, S.N. Statistical Inference for Partially Linear Varying Coefficient Spatial Autoregressive Panel Data Model. Mathematics 2023, 11, 4606. https://doi.org/10.3390/math11224606
Feng S, Tong T, Chiu SN. Statistical Inference for Partially Linear Varying Coefficient Spatial Autoregressive Panel Data Model. Mathematics. 2023; 11(22):4606. https://doi.org/10.3390/math11224606
Chicago/Turabian StyleFeng, Sanying, Tiejun Tong, and Sung Nok Chiu. 2023. "Statistical Inference for Partially Linear Varying Coefficient Spatial Autoregressive Panel Data Model" Mathematics 11, no. 22: 4606. https://doi.org/10.3390/math11224606