1. Introduction
Variational quantum algorithms in the NISQ [
1] era provide a promising route toward developing useful algorithms that allow for optimizing states in higher dimensional spaces by tuning the polynomial number of parameters. The most prominent techniques within variational methods include the Variational Quantum Eigensolver (VQE) [
2], Quantum Approximate Optimization Algorithm (QAOA) [
3], and other classical machine learning-inspired ones. We ask the readers to refer to [
4] for an exhaustive study on quantum machine learning with applications in chemistry [
5], physics [
6], supervised learning and optimization [
7]. Within the context of optimization and machine learning in general, some of the major problems that need to be addressed include encoding classical data, finding an expressible enough ansatz (Expressibility) [
8], and efficiently computing gradients (Trainability) [
9], generalizability [
10]. These problems are interlinked and thus not treated independently in general.
As we move away from the NISQ era toward deep parameterized quantum circuits (PQC), one of the major problems with regard to trainability that needs addressing is the problem of vanishing gradients referred to as barren plateaus [
11]. This might be an effect of working with a large number of qubits [
11], expressive circuit ansatz [
12], noise inducement [
13] or the use of global cost functions in the learning [
14]. Having efficient procedures to reduce the dimensionality the representation of the input quantum state helps create efficient encoding schemes that could later be used as inputs to other machine learning algorithms, where the cost functions on higher dimensional spaces with expressive ansatz are less likely to be trainable. To this end, we develop machine learning techniques that allow for compact representations of a given input quantum state.
Within the classical machine learning community, autoencoders have been effectively used to develop low-dimensional representation of samples generated from a given probability distribution [
15]. Inspired by these techniques, work on Quantum Autoencoders [
16,
17] have allowed for people to develop compact representations against a fixed finite state. It is not clear that such tensor product states with a fixed finite state are always possible while retaining the maximal possible information. Here, we show that if one were to relax the condition toward maintaining a fixed finite state, a better compact representation can be generated that can be post-processed toward classification. We develop techniques to create subsystem purifications for a given set of inputs and follow it by creating superpositions of these purifications indexed using the subsystem number. This representation is further used for doing classification achieved by applying variational methods over parameterized quantum circuits restricted to this compact representation and showing the learning of the method. We apply an ansatz to create subsystem purification on the Bars and Stripes (BAS) dataset and show that one can reduce the number of qubits required to represent the data by half and achieve a 95% classification accuracy on the Bars and Stripes (BAS) dataset. The demonstrated example shows proof for the working of the method in reducing states represented in large Hilbert spaces while maintaining the features required for any further machine learning algorithm that follows. The scheme thus proposed can be extended to problems with states in large Hilbert spaces where dimensionality reduction plays a key role with regard to the trainability of the parameterized quantum circuit.
2. Method
Given an ensemble of input states, , the objective is to construct a low-dimensional representation of states sampled from this distribution E. Let be a state over qubits. We design a protocol that allows for us to create an equivalent compact representation of with qubits. To simplify the discussion, let us assume that , and thus, we create a representation using half the qubits. We do this in 2 stages.
Stage 1:
In the first stage, we apply a unitary
that decomposes
into
. To produce such a tensor product structure, we could minimize the entropy on either subsystem
A or
B till a zero entropy is achieved. Thus, we could optimize the cost function,
where
represents the tracing operation over the qubits of subsystem
A,
represents the averaging over the
, and
is the entropy of a given density matrix
. The cost function
attains a maximum value equal to
when
is maximally mixed and equal to 0 when
is in a pure state.
Figure 1 shows a schematic representation of the ansatz used for
. The hardware efficient ansatz used here is restricted to
gates on each qubit followed by a ladder of CNOT operators that couples adjacent qubits. This is sufficient for our purpose as the input data vectors used here, associated with bars and stripes, are vectors with real amplitudes.
Variational quantum algorithms have been studied in the past to create thermal systems by minimizing the free energy of the output state [
18,
19]. The main problem tackled in these papers involves developing techniques that allow one to compute the gradients of Entropy required to be optimized over the training. The issue arises from not having exact representations that can compute the logarithm of a given density matrix efficiently. Furthermore, to avoid numerical instabilities in the entropy function arising from the density matrix of pure states being singular, here, we alternatively maximize over the cost function,
where
and
.
attains a maximum value of 1 when
or
are pure states resulting in
and attains a least value
.
is a convex function as
is a convex function of
[
18].
Figure 2 shows a schematic representation to compute
using a destructive swap test. The optimization landscape thus has one local minimum dictated by the expressivity of the ansatz used to capture it.
The parameters are variationally optimized to obtain . If reaches an optimal value of zero, we can express , thus expressing a state with degrees of freedom, effectively using degrees of freedom. Having expressed the input state as a tensor product of subsystems, we now move to stage 2 of the algorithm.
Stage 2:
Note that the above representation still makes use of
qubits to capture the features of
. If the subsystems are not equal in size, additional ancillary qubits are included to match the system size. We now show how this representation can be compressed using
qubits. To carry this out, we apply an ancillary CSWAP (controlled swap/Fredkin) gate acting on the qubits of systems A and B. The additional ancillary qubit works as an index register for these states. Thus, we obtain
. If
and
are not orthogonal states, then there exists at least one basis element
in the computational basis with a nonzero coefficient in both these states. Without a loss of generality, let us assume that the measurement collapses onto
, giving rise to
, where
c and
are real numbers. The factor
is generated from the relative difference in the coefficients of the state corresponding to
.
Figure 3 shows a schematic representation of the main steps involved in creating a superposition, with the ancilla register being used as an index to the subsystem outputs of Stage 1.
Output:
Thus, we have successfully managed to map the input state to , apart from an arbitrary relative phase and amplitude c in the representation. Note that this procedure is reversible, thus preserving all information content encoded into input state . To show that it is reversible, one just needs to take two copies of the output state , measure the corresponding ancilla to project out , and then apply the inverse of , giving back . Thus, the encoding scheme allows for us to create a representation of the input state with qubits into only qubits. We now show that the presence of the arbitrary phase and relative coefficient can be ignored if we work with an ansatz with a specific structure for an L2 cost function, which can be generalized to other cost functions as well.
Let
be the ansatz used for classification after creating the compact state representation. We calculate the label corresponding to each state by averaging the expectation value across an ensemble of representative states for each datapoint obtained via projection of the second state. The expected label for a datapoint indexed by
t is thus given by
where
i indexes the projection of the second subsystem and
is the probability of that projection. Using the L2 norm, the classification cost function with respect to this ansatz is given by
where
. Note here
is an ansatz that acts on
qubits. The cost expression chosen abive can be re-expressed on the non-projected state as follows:
where
. The above extension is supported by the presence of
in the original expression. We now choose an ansatz that allows us to get rid of the effects of arbitrary relative phase and amplitude via the projection of the second subsystem in our original expression. Let
, where
. Thus we obtain
The above expression thus obtained is akin to the averaging over the ensemble for each datapoint producing a state that is oblivious to the relative amplitude and phase factor produced via the projection. For both
and
, we use the hardware efficient ansatz, as shown in
Figure 1, which we shall employ for supervised learning in the next section.
3. Results
To demonstrate the working of the method described above, we pick a toy dataset with images of Bars and Stripes (BAS) and build a compact representation of it. The BAS dataset we consider is a square grid with either some columns being only vertically filled (Bars) or some rows being horizontally filled (Stripes) [
21]. One can easily generate such a supervised dataset and realize that the distribution from which these images are sampled has a low entropy characterization. We randomly sample 1000 data points from a grid size of
from the BAS dataset consisting of 131,068 datapoints represented using amplitude encoding on eight qubits. Note that, despite other classically trained and more efficient encodings that could be straightforwardly employed, here, we use amplitude encoding, as the representation is efficient in the number of qubits while remaining data-agnostic.
Applying the protocol described above, we reduce the representation of the state into a tensor product of two subsystems of equal size.
Figure 4 shows the learning of optimal parameters
as the cost function falls. Note that the dataset has been factorized from a non-trivially entangled state. We use the standard gradient descent [
22] approach in performing the training. Note that the cost function drops to zero, implying that the representation thus created is exact with a lossless transformation created by
. For the 16 × 16 grid case, the ansatz
is made of D = 5 layers, while that for the 8 × 8 grid is made of D = 3 layers. At this point, we apply a layer of swap gates to reduce the eight-qubit representation of 16 × 16 grid samples into five qubits and the six-qubit representation of 8 × 8 grid samples into four qubits.
We now use this as input for performing supervised classification. We use approximately 80% of the samples from the output of the encoded samples for training and keep the remaining 20% of the samples for testing. An ansatz
with the same number of qubits as that of the input samples is trained, with the expectation value of pauli-
Z operator being used as a label for differentiating between bars and stripes. The input image is classified as an image of bars if the expectation value is positive and as stripes image if it is negative. We use the sum of two norm errors over the dataset labels (1 for bars and
for stripes) as the cost function (
6) to be minimized over, i.e,
where the summation index
i labels the dataset,
refers to the labels corresponding to the sample input and
is used to denote the compact representation of the state that the above encoding scheme provides. For the 8 × 8 grid, a total of 508 bars and stripe images are produced, with half of them belonging to each category. We use 400 of these samples for training and 108 samples for testing. By default, we have used 8192 shots for each measurement during the training for creating subsystem purifications and carrying out the classification. We use 1000 representative samples corresponding to each datapoint, which are characterized by an arbitrary relative phase and amplitude.
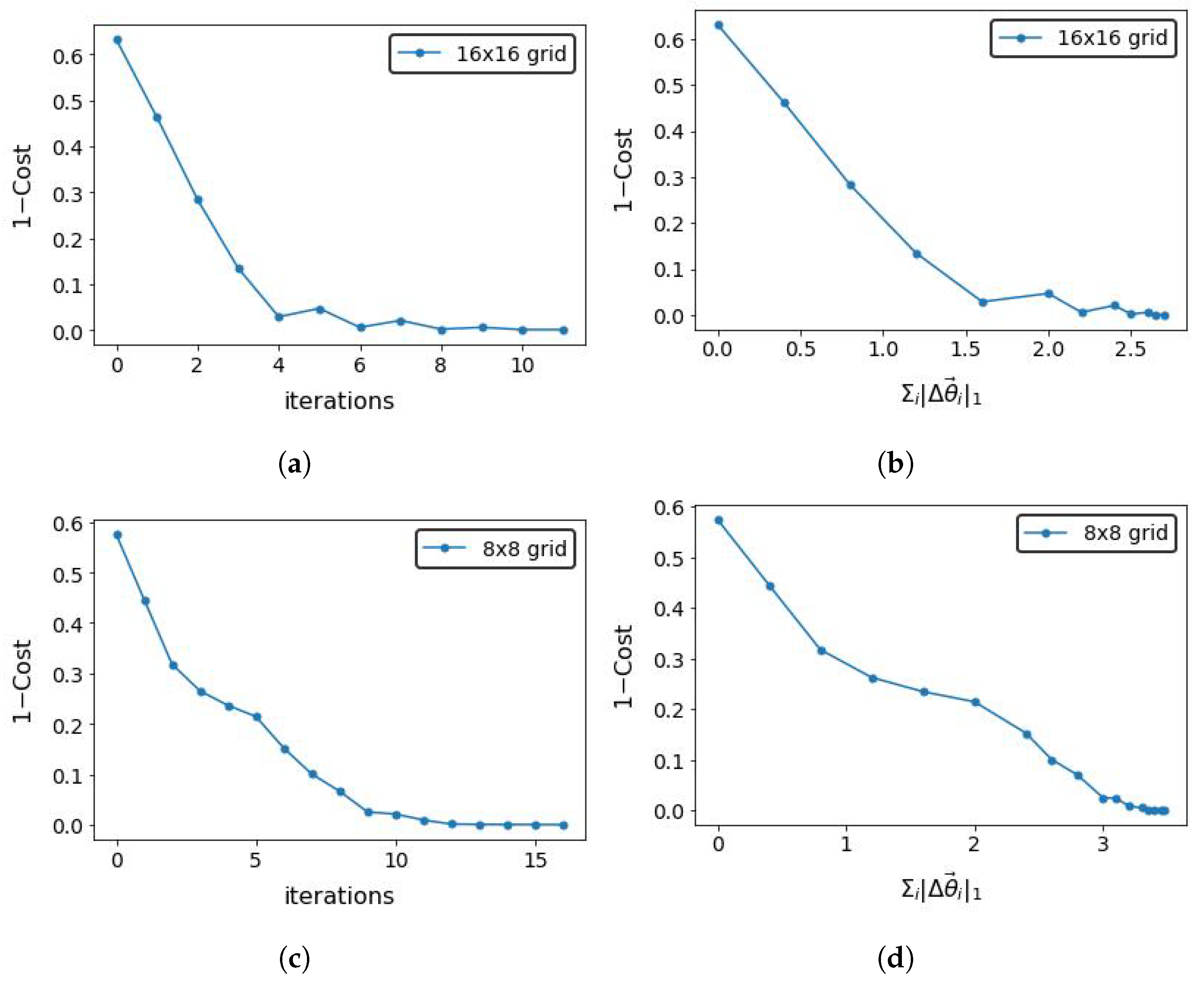
Figure 5 shows the cost of optimizing the parameters of
as a function of the number of iterations. We achieved a 95% accuracy on the testing data, showing that the method used to generate the compact representation did not destroy the features of the input state.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




