Abstract
In this article, we present a novel approach for emotional speech lip-reading (EMOLIPS). This two-level approach to emotional speech to text recognition based on visual data processing is motivated by human perception and the recent developments in multimodal deep learning. The proposed approach uses visual speech data to determine the type of speech emotion. The speech data are then processed using one of the emotional lip-reading models trained from scratch. This essentially resolves the multi-emotional lip-reading issue associated with most real-life scenarios. We implemented these models as a combination of EMO-3DCNN-GRU architecture for emotion recognition and 3DCNN-BiLSTM architecture for automatic lip-reading. We evaluated the models on the CREMA-D and RAVDESS emotional speech corpora. In addition, this article provides a detailed review of recent advances in automated lip-reading and emotion recognition that have been developed over the last 5 years (2018–2023). In comparison to existing research, we mainly focus on the valuable progress brought with the introduction of deep learning to the field and skip the description of traditional approaches. The EMOLIPS approach significantly improves the state-of-the-art accuracy for phrase recognition due to considering emotional features of the pronounced audio-visual speech up to 91.9% and 90.9% for RAVDESS and CREMA-D, respectively. Moreover, we present an extensive experimental investigation that demonstrates how different emotions (happiness, anger, disgust, fear, sadness, and neutral), valence (positive, neutral, and negative) and binary (emotional and neutral) affect automatic lip-reading.
Keywords:
lip-reading; visual speech recognition; emotional speech; speech to text; affective computing; deep learning; machine learning; human–computer interaction MSC:
68T10
1. Introduction
When speaking, both audio and visual speech cues are generated simultaneously by human articulators [1,2,3,4,5]. Consequently, there is a strong correlation between lip movements and audio signals, allowing us to extract linguistic information not only from the audio but also from the visual modality. This phenomenon is also evident in human communication. When there is acoustic noise present, individuals often shift their focus to the movement of their interlocutor’s lips in order to enhance their comprehension of the speech. People begin to “watch” speech, not just listen to it.
This fact has led to the development of the Visual Speech Recognition (VSR) field, also known as lip-reading [6,7,8,9]. Its main idea is to understand human speech based solely on lip movements. However, until the recent development of Neutral Network (NN) and Deep Learning (DL), automatic systems were not able to model this feature of human speech perception with sufficient Accuracy (Acc). Nevertheless, at the moment, automatic VSR has achieved tremendous success, especially in limited-vocabulary tasks, far surpassing human abilities to lip-read. VSR is useful when the acoustic signal is corrupted by background noise or when the speaker is too far away to hear distinctly [10].
While the performance of current State-of-the-Art (SOTA) lip-reading methods [8,11,12,13,14,15] has improved significantly in emotionally neutral Speech Recognition (SR) tasks, they still suffer with crucial performance degradations in real application scenarios, in particular, when uttered speech is affected by human emotions. However, in real applications it is often crucially important for a person that an automatic system understands his/her requests in an emotional state. Emotions are expressed differently in acoustic and visual modalities, and there is no “out of the box” solution for emotion-robust VSR to date. It changes depending on a speaker’s emotional state: the timbre, pitch, and loudness of the voice; the duration of sounds, pauses, and articulation. Therefore, the task of recognizing emotional visual Speech-to-Text (S2T) is extremely challenging.
Modern Speech Emotion Recognition (SER) focuses on enabling devices to perform emotion detection using Deep Neutral Network (DNN) models [16,17,18,19]. Currently, they have a wide range of applications in healthcare, education, media, etc. However, the emotional VSR performance is limited by the lack of methodology and the unavailability of labeled corpora suitable for model training.
Motivated by human perception and the recent developments in multimodal DL, we propose a two-level approach to emotional S2T recognition based on visual data processing (EMOLIPS). The approach is built on the results of previous work in emotion recognition [20] and automated lip-reading [8] and leverages recent advances in DL for both. The main advantage of the proposed approach is improving automatic lip-reading Acc by genuinely tackling emotion recognition first, followed by emotion-specific VSR. We make the source code and models free for research use, as we intend to establish a baseline for future research in emotional S2T recognition. The source code and trained models are available in our GitHub (https://github.com/SMIL-SPCRAS/EMOLIPS, accessed on 24 October 2023).
The remainder of this article is organized as follows: Section 2 provides an in-depth analysis of the recent literature pertaining to SOTA approaches in both Visual Emotion Recognition (VER) and lip-reading. In Section 3, we describe the corpora used for training, development, and testing our proposed method and model. In Section 4, we provide a two-level approach called EMOLIPS for emotional speech lip-reading. The experimental results of our approach are presented in Section 5. Finally, some concluding remarks are presented in Section 6.
2. Related Work
In this section we carefully analyze the recent relevant literature related to the SOTA approaches for VER as well as approaches for lip-reading.
2.1. State-of-the-Art Approaches for Visual Emotion Recognition
The SOTA emotion recognition approaches have been improved tremendously over the last five years due to the rapid development of modern Machine Learning (ML) techniques and algorithms, as well as the release of large-scale corpora. Emotion recognition has drawn increasingly intense attention from researchers in a variety of scientific fields. Human emotions can be recognized and analyzed from visual data (facial expressions [21,22,23], behavior [24], gesture [25,26,27], pose [28]), acoustic data (speech) [29], physiological signals [30,31,32,33], or even text [34]. In this section, we will focus on SOTA approaches for VER based on facial expression analysis.
The visual information of facial expressions is a crucial indicator of a speaker’s emotion. According to the SOTA pipeline for VER, the first step is to localize the Region-of-Interest (ROI). Several open-source Computer Vision (CV) libraries allow the detection of facial variations and facial morphology (e.g., the Dlib (http://dlib.net/, accessed on 24 October 2023) or MediaPipe (https://google.github.io/mediapipe/, accessed on 24 October 2023) libraries). This step evaluates the position of the landmarks on a face, which contain meaningful information about a person’s facial expression that helps to perform automatic emotion recognition [35].
For any utterance, the underlying emotions are classified using SER. Classification of SER can be carried out in two ways:
- (a)
- Traditional classifiers;
- (b)
- DL classifiers.
The latter are an order of magnitude superior to traditional ones in terms of Acc of emotion recognition. Therefore, only approaches based on DL will be considered below.
DNN is a multilayered NN used for complex data processing. Many researchers have investigated different deep models, including Deep Belief Networks (DBNs) [36], Convolutional Neural Networks (CNNs) [37], and Long-Short Term Memory (LSTM) networks [38] to improve the performance of SER systems. However, nowadays the most promising approaches to emotion recognition usually rely on CNNs and Recurrent Neural Networks (RNNs) at their core, with attention mechanisms and some additional modifications [18].
A CNN is a NN that consists of various layers sequentially. Usually, the model contains several convolution layers, pooling layers, and fully connected layers, followed by a SoftMax unit. This sequential network forms a feature-extraction pipeline modeling the input in the form of an abstract. The basis of CNNs is convolutional layers, which constitute filters. These layers perform a convolutional operation and pass the output to the pooling layer. The pooling layer’s main aim is to reduce the resolution of the output of the convolutional layers, thereby reducing the computational load. The resulting outcome is fed to a fully connected layer, where the data are flattened and are finally classified by the SoftMax unit.
RNNs and their variations are usually designed for capturing information from sequence/time series data. RNNs work on the recursive equation:
where is the input at time t; (new state) and (previous state) are the state at time t and , respectively; and is the recursive function. The recursive function is a function. The equation is simplified as:
where and are the weights of the previous state and input, respectively, and is the output. An efficient approach based on RNNs for emotion recognition was presented in Ref. [39]. In Ref. [40], it was shown that RNNs can learn temporal aggregation and frame-level characterization over a long period.
With recent developments in NN models, and, more specifically, with the introduction of DNN architectures such as Visual Geometry Group (VGG) [41] and ResNet-like [42] that are able to consume raw data without a feature-extraction phase, modern emotion SR approaches started to shine. For the last five years, numerous research studies have been published, e.g., [43]. In existing DL emotion recognition models for recognizing spatial-temporal input, there are three common topologies: CNN-RNN [44], 3-Dimensional (3D) CNN [45], and Two-Stream Network (TSN) [46].
This enables them to capture both macro- and micro-motions. However, it cannot incorporate transferred knowledge as conveniently as CNNs–RNNs. TSNs contain two parallel CNNs: a network that processes images and a temporal network that processes motions [47].
There are also numerous studies dedicated to multimodal Audio-Visual (AV) emotion recognition [48,49,50,51,52,53,54,55]. Moreover, visual information such NNs consider different information channels. Information fusion is commonly performed using DBNs [56] or attention mechanisms [57].
A notable set of approaches transform each audio sample into a 2-Dimensional (2D) visual representation in order to be able to employ SOTA CNNs based on 2D/3D CNN [58,59]. To this end, the researchers usually compute the discrete Short Time Fourier Transform (STFT), as follows:
where is the discrete input signal, is a window function, is the STFT length, and R is the hop (step) size. Following computation of the spectrograms as the squared magnitude of the STFT, the resulting values are then converted to a logarithmic scale (decibels) and normalized to the interval , generating single-channel images suitable for further image processing.
Furthermore, the authors of Ref. [60] proposed an audio spectrogram Transformer method based on the well-known Transformer [61], the first convolution-free, purely attention-based model for emotion classification.
Since the main goal is to evaluate emotion in videos rather than in images (frames), the researchers in Ref. [62] focused on video analysis and evaluated two strategies to provide a final prediction for the video. The first collapses the sequence of action units generated in each timestamp into a vector that is the average of all the temporal steps. These features fed three static models: a Support Vector Machine (SVM), a k-NN, and a Multilayer Perceptron (MLP). The second strategy employed a sequential Bidirectional (Bi)LSTM with an attention mechanism to extract the video prediction from the sequence of features retrieved from each frame of the video.
As an alternative to static models, the authors adopted a sequential model with an assumption that there is relevant information not only in frames themselves but also in the order of frames. The authors used a BiLSTM network as a sequential model.
The BiLSTM layer operates in a Bi manner, which allows them to collect sequential information in two directions of the hidden states of the LSTMs. To obtain the emotion prediction from the BiLSTM layers, the embeddings of the outputs of each specific direction are concatenated, according to the equation:
where denotes the concatenation operator and L the size of each LSTM.
The general goal of the following attention mechanism is to distinguish the most relevant active unit associated with a specific frame while detecting the emotion in the whole video. The researchers used the actual contribution of each embedding evaluated through MLP with a non-linear activation function, similar to [63].
The attention function is a probability distribution applied to hidden states that allows us to obtain attention weights that each frame of the video receives. The models estimate the linear combination of the LSTM outputs with the weights . Finally, the resulting feature vector is fed to a final task-specific layer for emotion recognition. The authors used a Fully Connected (FC) layer of eight neurons, followed by a SoftMax activation that returns the probability distribution over the emotional class.
A notable set of approaches in VER rely on the implementation of self-attention [61]. Self-attention is formulated via estimating the dot-product similarity in the latent space, where queries q, keys k, and values v are learned from the input feature representation via the trainable projection matrices , and a resulting representation is calculated based on them:
where d is the dimensionality of a latent space.
This idea has been widely employed for solving a variety of tasks in emotion/affect recognition [57,64,65]. In Ref. [64], the authors presented a Transformer-based methodology for unaligned sequences and performed fusion of three modalities of audio, video, and text. The data from each modality are first projected via a 1-Dimensional (1D) convolutional layer to the desired dimensionality, followed by a set of Transformer blocks. Specifically, two Transformer modules were added to each modality. These representations are subsequently concatenated and another Transformer module is applied in each modality branch on the joint representations. The resulting representations from each of the three branches are subsequently concatenated for final emotion classification.
The authors of Ref. [66] recently proposed the use of Emoformer blocks for VER tasks. Emoformer has an Encoder structure similar to Transformer, excluding the decoder part. The previously described self-attention layer is used to extract features that contain emotional information effectively, and the residual structure ensures the integrity of the original information. Finally, the mapping network decouples the features and reduces the feature dimensions.
For a given input feature U, three matrices of query , key , and value are calculated from U:
where represent the sequence length of the Q, K, V, respectively; represent the dimensions of the Q, K, V, respectively; and , , .
Multiple self-attention layers are concatenated to obtain a multi-head attention layer:
where are the outputs of the self-attention layers, h is the number of layers, and W is the weight parameter.
A residual connection with the normalization layer is used to normalize the output of the multi-head attention layer, and a feed-forward layer is employed to obtain the output of the self-attention parts:
where , are the weight parameters and , are the bias parameters.
Finally, the original features U and the output of the self-attention parts G are connected through the residual structure, and a mapping network is employed to obtain the final output E:
where the represents the mapping network, which consists of five fully connected layers. Combining the above equations, we can obtain different modality emotion vectors from different input channels with :
where , , represent the original input of audio, visuals and textual features, respectively, and , , represent the emotion vectors of the respective modalities.
The authors of Ref. [67] proposed a method to tackle emotion recognition in dialogue videos. The researchers proposed the Recurrence based Uni-Modality Encoder (RUME), inspired by the famous Transformer architecture [61]. The authors added fully connected networks and residual operations to improve the expressiveness and stability of the emotion recognition system. The proposed structure can be formalized as:
where X denotes the feature matrix of the utterance; , , and denote the RNN, normalization, and feed-forward network layers, respectively. In this study, the and default to Bi Gated Recurrent Unit (GRU) and layer normalization, while the feed-forward layer consists of two fully connected networks, which can be formulated as:
where and denote the fully connected network and dropout operation, respectively, and denotes the activation function.
In this subsection, we have analyzed the SOTA SER systems based on visual data processing. DL classifiers are usually used to recognize emotions. A framework of DNN, CNN, and RNN and modifications along with an attention mechanism is usually used to achieve SOTA performance.
2.2. State-of-the-Art Approaches for Lip-Reading
In this subsection, we evaluate recent progress in VSR methodology. More detailed research on these issues can be found in related studies [68,69].
Traditionally, VSR systems consist of two processing stages: feature extraction from video data followed by lip-reading. For traditional methods, features are usually extracted around the mouth ROI. However, in recent years, with the development of DL technology, the feature-extraction step has been replaced with deep bottleneck architectures.
The first CNN image classifier to discriminate visemes was trained by the researchers in Ref. [70]. In Ref. [71], the deep bottleneck features were used for word recognition in order to take full advantage of deep convolutional layers and explore highly abstract features. Similarly, it was applied to every frame of the video in Ref. [72].
The researchers in Ref. [73] proposed using 3D convolutional filters to process spatio-temporal information of the lips. A basic 2D convolution layer from C channels to channels (without a bias and with unit stride) computes [74]:
for input x and weights , where we define for i, j out of bounds. Spatio-Temporal Convolutional Neural Network (STCNN)s can process video data by applying convolution across both time and spatial dimensions [75], thus:
Then, the researchers in [76] applied an attention mechanism to the mouth ROI. The authors proposed the , , , and networks, which learn to predict characters in sentences being spoken from a video of a talking face without audio. The authors model each character in the output character sequence as a conditional distribution of the previous characters in the input image sequence for lip-reading. Hence, we model the output probability distribution as:
The model consists of three key components: the image encoder , the audio encoder , and the character decoder . Each encoder transforms the respective input sequence into a fixed dimensional state vector s and sequences of encoder outputs . The decoder ingests the state and the attention vectors from both encoders and produces a probability distribution over the output character sequence.
The three modules in the model are trained jointly.
Several training strategies and DNNs have been recently proposed for lip-reading [77]. It has received a lot of attention due to the availability of large publicly available corpora, e.g., the Lip Reading in the Wild dataset (LRW) [78] and the Lip-Reading Sentences in-the-Wild dataset (LRS) [76].
The authors of Ref. [76] proposed an image encoder that consists of a convolutional module that generates image features f for every input time-step x and a recurrent module that produces the fixed dimensional state vector s and a set of output vectors o:
The majority of SOTA approaches follow a similar lip-reading strategy that consists of a visual encoder, followed by a temporal model and a classification layer. The authors of Ref. [11] proposed a modification of self-distillation. It is based on the idea of training a series of models with the same architecture using distillation and has been recently applied to lip-reading. The teacher network provides additional supervisory signals, including inter-class similarity information. The overall loss to be optimized is the weighted combination of the cross-entropy loss for hard targets and the Kullback-Leibler (KL) divergence loss for soft targets:
where and represent the embedded representations from student and teacher networks, respectively; and denote the learnable parameters of the student and teacher models, respectively; y is the target label; stands for the SoftMax function; and is the balancing weight between the two terms.
A visual encoder was initially proposed in Ref. [79], and since then has been widely used and improved in later studies [80]. At the same time, the most recent advances include the temporal model and the training strategy. Bi GRUs and LSTMs, as well as Multi-Scale Temporal Convolution Network (MSTCN)s, have been the most popular temporal models [14].
Recently, as an alternative to RNN for classification, Transformer models using attention mechanisms and temporal convolutional networks have begun to be used [81,82]. The Vision Transformer (ViT) [83] first converts an image into a sequence of patch tokens by dividing it with a certain patch size and then linearly projecting each patch into tokens.
A Transformer encoder is composed of a sequence of blocks, where each block contains Multi-head Self-Attention (MSA) with a feed-forward network. It contains a two-layer multilayer perceptron with an expanding ratio r at the hidden layer, and one Gaussian Error Linear Unit (GELU) non-linearity is applied after the first linear layer. Layer Normalization (LN) is applied before every block, and residual shortcuts after every block. The input of ViT, , and the processing of the k-th block can be expressed as:
where and are the and patch tokens, respectively, and is the position embedding. N and C are the number of patch tokens and the dimension of the embedding, respectively.
However, training such models requires large computing power, as well as a significant amount of training data, so one of the popular approaches in such cases is transfer learning [84]—a method of using a pre-trained model to improve predictions within a different but similar task, allowing a reduction in training time and data requirements, as well as improvement of the performance of the NN.
In order to develop real-world lip-reading systems, high-quality training and testing corpora are essential. A modern trend that has appeared recently is web-based corpora: corpora collected from open sources such as YouTube or TV shows [85]. The most well-known of them are the LRW [78], LRS2-BBC, and LRS3-TED corpora [86], among others. The combination of SOTA DL methods and large-scale visual corpora has been highly successful, achieving significant recognition Acc results and even surpassing human performance.
3. Research Corpora
The selection of a proper AV speech corpus is eventually a key task in building SR systems because SOTA solutions are usually based on data-driven ML methodology. In order to assess the influence of emotions on the Acc of VSR, it is necessary to have an adequate corpus for training models. The corpus must meet the requirements of DL in terms of the number of speakers, vocabulary size, number of repetitions, etc. Compliance with all the necessary parameters is challenging; therefore, it is necessary to conduct a separate analysis of the existing AV corpora and emotional speech that are publicly available and select the most suitable ones to solve the task.
We have reviewed the 28 existing benchmarking corpora for VSR and Audio-Visual Speech Recognition (AVSR) suitable for training DL models in our related study [68]. However, all these existing publicly available corpora (both recorded in laboratory conditions and collected from the internet) contain speech recordings only with neutral emotions, or with a minimal amount of emotions/data not labeled with emotion classes. Therefore, it can be stated that the existing corpora designed for VSR are not suitable for assessing the influence of emotions on the Acc of SR.
Thus, we need to consider corpora containing emotional speech. However, most existing emotional speech corpora were created for recognizing different classes of emotions rather than for SR. Therefore, we need to analyze the existing emotional corpora for the possibility of using them for SR tasks, along with recognition of emotion classes. In Table 1, the most widely used benchmarking corpora of emotional speech are listed with their main characteristics.

Table 1.
Comparison of AV corpora of emotional speech. # means the number of data.
The FABO [87] is a bimodal face and body gesture corpus for the automatic analysis of human nonverbal affective behavior. The corpus contains approximately 1900 videos of emotional facial expressions recorded with two cameras simultaneously. One is a facial camera and the second is a body camera. The corpus was the first to combine facial and body recordings in an organized manner. This AV corpus consists of recordings of 23 speakers, 11 males and 12 females. The age ranges between 18 and 50 years old. The authors recorded nine emotions in total: angry, scared, surprised, happy, disgusted, bored, worried, sad, and uncertain.
The eNTERFACE’05 [88] is an AV emotion corpus that can be used as a benchmarking corpus for testing and evaluating video, audio, or joint AV emotion recognition methods. It includes recordings of 42 speakers of 14 different nationalities uttering English phrases. Among the speakers, thirty-four were men and eight were women. The recordings include only the head area and were recorded on a dark background.
The IEMOCAP [89] corpus consists of 151 videos of recorded dialogues. It has two speakers per session, resulting in 302 videos in the corpus. Each video is annotated for the presence of nine emotions as well as valence, arousal, and dominance. It contains approximately 12 h of AV data, including video, voice, facial motion, and text transcriptions.
The SAVEE [90] is a corpus that consists of recordings of four speakers uttering three phrases with seven different emotions and twelve phrases with a neutral state. The sentences were chosen from the standard the TIMIT corpus [106] and phonetically balanced for each emotion. The emotions were recorded when speakers watched video clips and read text on the display.
The RML (http://www.rml.ryerson.ca/rml-emotion-database.html, accessed on 24 October 2023) is a one of the few multilingual emotion corpora available to date. It contains 720 samples of six different emotions. Each participating speaker speaks several languages. Video recordings were collected from eight speakers, speaking six languages (English, Mandarin, Urdu, Punjabi, Persian, and Italian). The samples were recorded in AV format on a simple front-facing camera with an average duration of each sample of around 5 s.
The SEMAINE [91] corpus is an annotated multimodal record of emotionally colored conversations between a person and a limited agent. It includes recordings of around 150 speakers for a total of 959 conversations with an average duration of 5 min. In total, it has 27 different emotional categories. High-quality recordings were made with five cameras and four microphones.
The AFEW [92] is a movie-extracted emotional corpus representing real-world conditions. The corpus contains recordings demonstrating natural head poses and movements, real-world illumination, multiple speakers in the same frame, a large variety of occlusions, etc. It was collected from 54 Hollywood movies, including 1809 videos. However, due to copyrights, only a small part of the corpus is publicly available.
The RECOLA [93] is an AV corpus of spontaneous collaborative and affective interactions in French. Speakers were recorded during a video conference while completing a task requiring collaboration. In total, 46 speakers participated in the recordings, among them 27 females and 19 males. All speakers are French-speaking while having different mother tongues: thirty-three French, eight Italian, four German and one Portuguese.
The CREMA-D [94] is a corpus of 7442 video clips of 91 actors (48 males and 43 females) from a variety of races and ethnicities. The actors spoke from a selection of 12 sentences. The sentences were presented using one of six different emotions (anger, disgust, fear, happiness, neutral, and sadness) and four different emotion levels (low, medium, high, and unspecified).
The NNIME [95] is a Chinese interactive multimodal emotion corpus. It includes recordings of 44 speakers engaged in spontaneous interactions, among them 24 females and 20 males. Each pair of speakers was instructed to perform spontaneously a short scene with a duration of 3 min. The general goal was to demonstrate one of six emotions (anger, frustration, happiness, neutrality, sadness, and surprise). It is the first large-scale Chinese interaction corpus that has been systematically collected, organized, and publicly released.
The RAVDESS [96] corpus consists of 4904 AV recordings of actors uttering two lexically matched statements in a neutral North American accent. In total, 24 professional actors (12 male and 12 female) participated in the recordings, trying to demonstrate eight different emotions (fear, sadness, surprise, happiness, anger, disgust, calm, and neutral). Each expression was produced at two levels of emotional intensity (normal, strong), with an additional neutral expression.
The RAMAS [97] is the first Russian AV emotional corpus. Ten young actors aged between 18 and 28 y.o. participated in the recordings (five male and five female). They expressed one of the six basic emotions (anger, sadness, disgust, happiness, fear, and surprise). The corpus contains approximately 7 h of high-quality video recordings of speakers’ faces, speech, motion-capture data, and physiological signals. The records were labeled by 21 annotators.
The PolishDB [98] is probably the only corpus available for the Polish language. The recordings were made by sixteen professional actors (eight male and eight female). The corpus covers the following modalities: facial expressions, body movement and gestures, and speech. The data are labeled with six basic emotion categories, according to Ekman’s emotion categories. To check the quality of performance, all recordings were evaluated by experts and volunteers.
The MELD [99] is a multimodal multi-party corpus for emotion recognition in conversations collected from TV series. It contains about 13,000 utterances from 1433 dialogues from the TV series Friends. Each utterance is annotated with emotion and sentiment labels and encompasses audio, visual, and textual modalities. The number of participants was limited, and 84% of the sessions were obtained with six starring actors.
The CHEAVD [100] is a Chinese natural emotional AV corpus. It contains about 140 min of emotional speeches extracted from movies, TV series, and talk shows. In total, 238 speakers, aging from children to the elderly, participated in the collected corpus. This corpus is the first large-scale Chinese natural emotion corpus dealing with multimodal and natural emotions.
The HEU Emotion [101] is currently the largest video-based AV emotion recognition corpus in the wild. It consists of 19,004 video clips. The speakers in the video recordings include Asians, Africans, and Caucasians. The recordings of the HEU corpus were taken under uncontrollable natural conditions and included a variety changes in multi-view face and body posture, local occlusion, illumination, and expression intensity.
The AVSP-ESD [102] corpus consists of 13,285 AV files collected from movies, TV shows, and YouTube containing speech and non-speech. It covers twelve different natural emotions (boredom, neutral, happiness, sadness, anger, fear, surprise, disgust, excitement, pleasure, pain, disappointment) with two levels of intensity. It is also a multi-language corpus that includes recordings in Chinese, English, French, Russian, and other languages.
CelebV-HQ [103] is a large-scale video facial attributes corpus. It consists of 35,666 video clips with a resolution of 512 × 512 at least, involving 15,653 speakers. All videos are labeled manually with 83 facial attributes, covering appearance, action, and eight different emotions. The corpus has a variety of age, ethnicity, brightness stability, motion smoothness, head pose diversity, and data-quality parameters.
The MimicME [104] corpus contains recordings of 4700 speakers. The recordings are in the form of 4-Dimensional (4D) videos of subjects displaying a multitude of facial behaviors, resulting in over 280,000 video files. The corpus has great diversity in age, gender, and ethnicity. Not all the files have been categorized with the corresponding emotions.
The EmoSet [105] corpus aims at predicting people’s emotional responses to visual stimuli. EmoSet consists of 3.3 million files in total, with only 118,102 of these files labeled by human annotators. Nevertheless, it is by far the largest existing emotional corpus. EmoSet is well-balanced between different emotion categories.
Based on the conducted analysis, we can conclude that most of the existing corpora are not suitable for the task of emotional speech lip-reading. Many corpora have been recorded for the task of emotion recognition, rather than SR. Due to this, they do not have the required vocabulary and the amount of repetitions per phrase with target emotions. From this list, we selected two publicly available emotional corpora suitable for SER and VSR evaluations. Only these two emotional corpora among those available in the scientific literature have a sufficient amount of data to train NN-based lip-reading systems, as well as the number of required parameters, such as number of speakers, vocabulary size, number of repetitions, emotionally balanced data, etc. The details of the selected corpora are presented below.
3.1. RAVDESS Corpus
The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) corpus [62] comprises 4904 AV recordings of 24 actors, evenly divided between genders (12 females and 12 males). The corpus was recorded in laboratory conditions. These actors articulate with neutral North American accent two phrases (see Table 2) that are lexically matched. The phrases are spoken by actors with two vocal channels (speech, song) and two emotional intensities (normal, strong). The speech vocal channel represents eight emotions (Neutral (NE), Happy (HA), Angry (AN), Sad (SA), Disgust (DI), Fearful (FE), Calm (CA), Surprised (SU)), while the song vocal channel provides six emotions (DI and SU are excluded).
Table 2.
Phrases and their labels in the RAVDESS corpus.
We divided the recordings into three samples, taking into account speaker independence: Train (first eighteen speakers or 75%), Development (next two speakers or 8%), Test (remaining four speakers or 17%). The distribution of recordings per emotion in three subsets is presented in Figure 1, while Figure 2 illustrates the distribution of recordings per phrase.
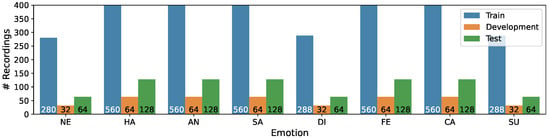
Figure 1.
Distribution of recordings per emotion in the Train/Development/Test subsets of the RAVDESS corpus.
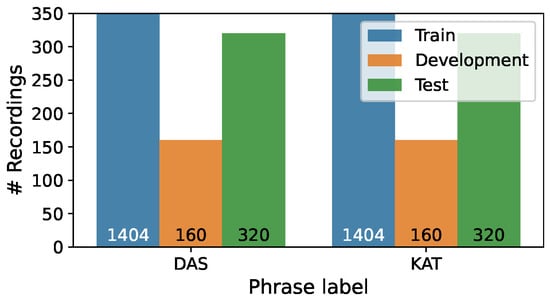
Figure 2.
Distribution of recordings per phrase in the Train/Development/Test subsets of the RAVDESS corpus.
3.2. CREMA-D Corpus
The Crowd-Sourced Emotional Multimodal Actors Dataset (CREMA-D) [94] comprises 7442 AV recordings of 91 actors, divided between genders (43 females and 48 males). The corpus was recorded in laboratory conditions. These actors uttered twelve phrases (see Table 3). The phrases were spoken by actors with three emotional intensities (low, medium, high) and six emotions (NE, HA, AN, SA, DI, FE). Neutral phrase recordings are not presented with different intensities.
Table 3.
Phrases and their labels in the CREMA-D corpus.
We divided the data into three subsets, taking into account the even distribution by speakers’ age and gender, as well as speaker independence: Train (70%), Development (10%), and Test (20%). The distribution of recordings per emotion in the three subsets is presented in Figure 3, while Figure 4 illustrates the the distribution of recordings per phrase.
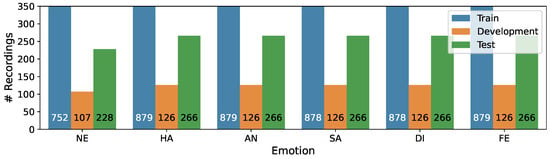
Figure 3.
Distribution of recordings per emotion in the Train/Development/Test subsets of the CREMA-D corpus.
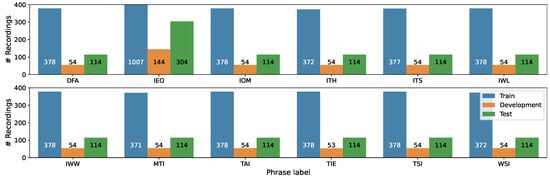
Figure 4.
Distribution of recordings per phrase in the Train/Development/Test subsets of the CREMA-D corpus.
4. Methodology
We consider three different strategies for emotional speech lip-reading and compare them to the classical one (lip-reading model trained on emotionally neutral recordings). Our approach consists of visual speech data pre-processing followed by two main levels (see Figure 5). At the first level, the emotion recognition task is solved; at the second level, depending on the emotion, a specific model is used for VSR. The emotional strategies are divided into: (1) 6 emotions, (2) 3 valences, and (3) a binary (emotional/neutral data) category. In this section, we introduce our visual speech emotion recognition part based on an EMO-3DCNN-GRU network. We then describe our lip-reading model based on 3DCNN-BiLSTM architecture. Both models are trained specifically for six, three, and two emotion classes.
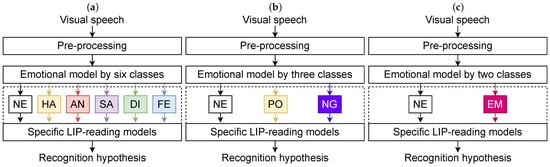
Figure 5.
EMOLIPS general processing flow in terms of three emotional strategies: (a) 6 emotions, (b) 3-level valence, (c) binary.
All three strategies of the EMOLIPS approach shown in Figure 5 work on the same principle. The input data of the approach are a visual signal consisting of K frames. A face landmark detection algorithm [15] is used to detect the face and lip region images. The face and lip images are normalized, scaled to the correct size, and written to the corresponding lists (for face images) and (for lip images). For emotion recognition, only five Frames per Second (FPS) are analyzed. The value range depends on the video FPS; M is the number of frames left after reduction. Depending on the emotional strategy, the facial images are fed into one of three models: (1) an emotional model for 6-emotion recognition, (2) an emotional model for for 3-valence recognition, and (3) an emotional model for binary classification. The emotional model predicts an emotional class . According to the obtained label, the lip images are fed into a specific lip-reading model trained on phrases spoken with the predicted emotion. Finally, the lip-reading model predicts a phrase class presented on the visual signal. The algorithm of the proposed EMOLIPS approach is presented in Algorithm 1.
| Algorithm 1: EMOLIPS Approach |
|
4.1. Data Pre-Processing
Both VER and lip-reading models require a certain pre-processing of the raw video speech data. Identifying the face ROI on each video sequence is the first step. We use the MediaPipe open-source library to detect a face ROI in each frame [15]. For both classification tasks, we divide the videos into 2-second segments; the final prediction is the maximum sum of the probability vectors of all segments. Then we consider further pre-processing that is different for each model.
We apply an emotion recognition pre-processing pipeline similar to [107] that includes: (1) video downsampling to five FPS (ten frames per 2-second segment) to ensure the same processing conditions for recurrent NNs in terms of temporality; (2) channel normalization of the face image; (3) resizing the image to pixels. Lip-reading pre-processing includes detection of a mouth ROI with the same approach (MediaPipe) on each frame and cropping it. We resized the mouth image to . In order to maintain the mouth proportions, we pad the image to the desired size with the average pixel value along the vertical of the image itself. We then use a linear normalization technique. We do not apply any FPS downsampling at this stage and use all 60 frames for a 2-second segment. This data pre-processing showed the highest performance results in our related research [20]; we keep it unchanged in the current research.
4.2. Visual Emotion Recognition
For efficient emotion recognition, we use the open-source static 2DCNN model proposed in Ref. [107]. This model has confirmed its performance in the emotion recognition task in comparison to other open-source models [108]. Similar to article [109], we convert the 2DCNN model based on ResNet50 architecture to a 3DCNN model with the addition of recurrent layers to capture changes in facial expression over time. However, unlike previous SOTA approaches [107,109], we extract features from different residual blocks of the CNN. We freeze the weights up to the 2nd residual block, and we fine-tune the weights of the 3rd and 4th blocks in the new research corpora. This approach allows us to combine the features of different scales in order to capture both larger and smaller facial-feature changes, as actively employed in object detection [110]. We use GRU as RNN, since it requires less computational effort and is not inferior in performance to LSTM [111]. Each GRU layer extracts a feature vector of size 128. To fuse the contribution of each feature vector within the emotion classification, we use the gated fusion mechanism [109,112], which is calculated as follows:
where is the tanh activation function and , and are the weight matrices for a, b and z feature vectors, respectively. The weight matrices have a size of , where N refers to the number of features in a feature vector and U to the number of output neurons, which is equal to 64. and are gated representations of the a and b feature vectors, respectively. is the sigmoid activation function, ⊙ is the element-wise product, and g is the final feature vector for the following classification.
4.3. Lip-Reading
We use the 3DCNN [42] and BiLSTM to tackle emotional speech lip-reading (see the right part of Figure 6).
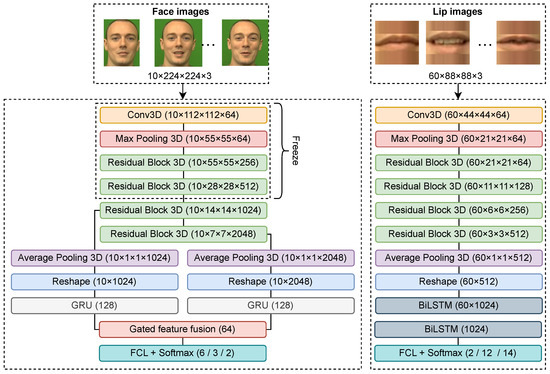
Figure 6.
EMO-3DCNN-GRU model (left) and LIP-3DCNN-BiLSTM model (right).
Unlike other emotional models, this model is based on the ResNet18 [42] architecture. We use a simpler model architecture because lip recognition requires analyzing each frame of a video, which increases the computational effort. Additionally, the region covering the lips within each frame is smaller compared to the whole face, so there is no need for a more complex, deeper model. However, since the sequence of analyzed frames in the lip-reading model is six times greater than in the emotional model, we use a BiLSTM. The BiLSTM network consists of two BiLSTM layers with 512 consecutive neurons in each layer. Our model was previously trained and achieved SOTA results for lip-reading on the LRW corpus [8].
Three-dimensional CNN inputs an image that passes through the first 3D convolution layer and the pooling layer, then four residual blocks with 3D convolution layers follow, each of which is repeated twice. The 3D average pooling and reshape layers are next. For each image in a sequence of length T equal to 60 frames, the 3DCNN returns a feature vector , where N is the number of features and . This is followed by the first BiLSTM layer of the sequence-to-sequence type, which consists of forward and backward LSTMs ( and , respectively). It returns a new feature matrix h by concatenating the output of the two LSTMs. The last BiLSTM layer is of the sequence-to-one type; it takes the feature matrix h as input and returns the final feature vector s for the last time-step of the sequence to perform the next classification. In general, the operation of the model can be represented by the following equations:
5. Experimental Results
To develop and research the EMOLIPS approach, we conducted a series of experiments. Initially, we trained three emotion recognition models. Then, we trained several lip phrase recognition models. Finally, we assessed the performance of the proposed EMOLIPS approaches by applying the trained models.
We assessed the experimental results using three metrics: the Mean Accuracy (mAcc) demonstrates the assessment of phrase recognition in the context of emotion/valence class; Acc demonstrates phrase recognition performance without taking into account emotions/valency; Unweighted Average Recall (UAR), Acc, and F1-measure (F1) are used to evaluate emotion recognition by the EMO-3DCNN-GRU model.
We trained the emotional models using the Stochastic Gradient Descent (SGD) optimizer with the Cosine Annealing Warm Restarts [113] scheduler for 100 epochs and five restart cycles. The learning rates varied from 0.001 to 0.0001. The lip models were trained using the Adam optimizer with a learning rate of 0.0001. The parameters of the models and of the training were selected experimentally using grid search.
5.1. Visual Emotion Recognition
Emotion recognition models were intended for specific tasks: (1) six-emotion recognition, (2) three-level valence recognition, and (3) binary emotion recognition. We excluded recordings of phrases with the CA and SU emotions from the RAVDESS research corpus, as they are not present in the CREMA-D corpus. Additionally, we conducted a tenfold cross-validation on both research corpora including all recordings of phrases to allow for a comparison of our proposed emotion recognition approach with SOTA approaches.
The performance measures for each emotional strategy across the different corpora are presented in Table 4. The results obtained from training on two research corpora simultaneously are also included. As expected, a reduction in the number of classes resulted in higher average performance measures. However, combining the two corpora did not enhance the average performance measures for each emotional strategy. This phenomenon is likely due to variations in emotional expressions within the research corpora, which could complicate and confuse the model.
Table 4.
Comparison of the emotion recognition performance measures for three strategies.
Figure 7 shows the confusion matrices reflecting the UAR values for the emotions from Table 4. The multi-corpus confusion matrices replicate patterns that are comparable to the CREMA-D corpus. Primarily, this is because the CREMA-D corpus offers a larger volume of training data in comparison to RAVDESS. Overall, in the case of balanced classes, the RAVDESS corpus displays accurate recognition of all six emotions with a minimum Acc (recall) of 78%, while the CREMA-D corpus varies between 44% and 95%. The other two strategies demonstrate class imbalance increases; however, the average Acc across all classes remains no lower than 69%. This result was attained by implementing logarithmic class weighting, as suggested in the research conducted by the authors of Ref. [109].

Figure 7.
Confusion matrices for 6 emotions, 3 valences, and binary classification obtained for Test subsets: (a) RAVDESS corpus, (b) CREMA-D corpus, (c) multi-corpus.
Additionally, we compared the Acc measures of our approach with SOTA approaches presented for the same corpora using a tenfold cross-validation scheme, as presented in Table 5. The comparison highlights that our approach demonstrates at a least 1% superiority over the SOTA for both corpora.
Table 5.
Comparison of the emotion recognition Acc with SOTA in 10-fold cross-validation.
5.2. Lip-Reading
We conducted four experiments with the lip-recognition model. In the first experiment, we trained six models based on phrases spoken with one of six emotions. We provide the results of phrase recognition Acc obtained by all models in the context of each emotion class separately. We also trained the models based on phrases spoken with each emotion. But since in this case the Train subset was increased by six times, we divided it into six evenly distributed folds by gender, age, phrase labels, and speakers. The first experiment results are presented in Table 6.
Table 6.
Comparison of the phrase recognition Acc for 6-emotion strategy. TM is the training model.
Table 6 demonstrates the results of the six-emotions strategy, as well as the classical (trained only on emotionless NE phrases) and emotional (trained on all emotional phrases with six emotions) approaches. In the case where the VSR approach was trained only on NE phrases ( Train model), the mAcc is equal to 85.1%, 84.2%, and 66.9% for RAVDESS, CREMA-D, and multi-corpus data, respectively. In the case where the VSR approach was trained on all emotional phrases with six emotions ( Train model), the mAcc is equal to 84.5%, 88.7%, and 68.0% for RAVDESS, CREMA-D, and multi-corpus data, respectively. For our approach with the six-emotions strategy, we trained six different models for every emotion (see values on the diagonal) and the mAcc is equal to 86.2%, 90.7%, and 71.3% for RAVDESS, CREMA-D, and multi-corpus data, respectively. Using our approach, we achieved an average increase of 4% compared to the classical approach and 2% compared to the emotional approach across all corpora.
It is worth noting that, depending on the emotional training model, the values of mAcc (horizontally) vary. For the RAVDESS corpus, the mAcc varies from 70.8% to 89.1%, displaying an 18.3% contrast between the DI and HA training models. Conversely, for the CREMA-D corpus, mAcc shows a range of 79.2% to 87.2%, with an 8% deviation between the AN and FE training models. For the multi-corpus data, the mAcc increases from 65.4% to 68.5%, or by 3%, depending on whether the AN/DI or SA/FE training models are used. The mAcc (vertically) for emotional phrase recognition also varies regardless of the emotional training model used. For AN and SA spoken phrases in the RAVDESS corpus, the mAcc ranges from 76.9% to 84.2%. Meanwhile, the CREMA-D corpus shows an increase in mAcc from 79.2% to 91.5% for phrases uttered with DI and AN emotions. A comparable trend is observed in the multi-corpus data, where mAcc changes from 63.7% to 71.2%. This phenomenon arises because all emotions elicit specific lip movements that enable differentiation between emotions. This variation in articulation impacts phrase recognition performance.
In the second experiment, we grouped all categorical emotions into classes according to their valence: Negative (NG) valence (includes AN, DI, FE, and SA emotions), NE valence, Positive (PO) valence (includes HA emotion). Since we obtained the models for the NE and PO valence classes in the first experiment, we only trained the models for the NG valence class. Since the size of the Train subset for NE valence exceeded the size of the Train subset for other valences by four times, we divided the Train subset into four folds, similarly to the experiment in the first experimental study. We report the experimental results in Table 7.
Table 7.
Comparison of the phrase recognition Acc for 3-level valence strategy. TM is the training model.
The results presented in Table 7 show that when emotions are grouped according to their valence, the mAcc values for recognition of twelve phrases are 92.5%, 92.6%, and 71.8% for RAVDESS, CREMA-D, and multi-corpus data, respectively. These values exceed mAcc using our six-emotion strategy by 6.3%, 1.9%, and 0.5% for the same respective corpora (where mAcc = 86.2%, 90.7%, and 71.3%, respectively; see Table 6). This result shows that all emotions of NG valence have similar facial features that differ from other valence classes.
In addition, in Table 8 we examine how the Acc of phrase recognition varies with respect to vocal channel (for the RAVDESS corpus) and emotional intensity (for the RAVDESS and CREMA-D corpora). In the case of NE valence in the RAVDESS corpus, strong emotional intensity is absent. Similarly, for NE valence in the CREMA-D corpus, low, medium and high intensities are missing. Table 8 shows that the Acc of phrase recognition is higher for the speech vocal channel than for the song one. Furthermore, for the RAVDESS corpus, the Acc of SR is higher for normal emotional intensity than for strong emotional intensity, with a difference of no more than 5.7%. On the other hand, for CREMA-D, emotional intensity plays a crucial role in phrase recognition, as the difference between different emotional valences and intensities is 62.9%. It can therefore be concluded that variations in articulation significantly distort the Acc of phrase recognition across different vocal channels and emotional intensities.
Table 8.
Comparison of the phrase recognition Acc for 3-level valence strategy in terms of vocal channels and emotional intensities. TM is the training model. SP and SO refer to speech and song vocal channels, respectively. NR and ST refer to normal and strong emotional intensities, respectively. LO, MD, and HI refer to low, medium, and high emotional intensities, respectively.
In the third experiment, we grouped the emotions into two classes: NE and Emotional (EM) (all emotions excluding NE), i.e., we implement binary classification. The model for the NE class remains unchanged. For the EM class, we divided the Train subset into five folds. Similarly to the previous experimental studies, we present the maximal results obtained in only one of the folds in Table 9.
Table 9.
Comparison of the phrase recognition Acc for binary strategy. TM is the training model.
Table 7 and Table 9 show that for the RAVDESS corpus and multi-corpus data, the Acc of phrase recognition is approximately the same for the three-level valence and binary strategies. For the CREMA-D corpus, the binary strategy shows a 1.4% reduction in mAcc (92.6% vs. 91.2%). Since the NG and PO valences have completely different facial features, the union of these two opposite valences results in an mAcc value drop.
In Table 10, we examine how the Acc of phrase recognition varies with respect to vocal channel and emotional intensity, similar to Table 8. The Acc of the vocal channel phrase recognition is higher than that of the speech one for emotionally spoken phrases. However, the recognition Acc is higher for normal-intensity phrases than for strong-intensity phrases, as in the three-level valence strategy on the RAVDESS corpus. Furthermore, for the CREMA-D corpus, the Acc of phrase recognition is approximately the same for different levels of intensity, but higher for medium intensity.
Table 10.
Comparison of the phrase recognition Acc for binary strategy in terms of vocal channels and emotional intensities. TM is the training model. SP and SO refer to speech and song vocal channels, respectively. NR and ST refer to normal and strong emotional intensities, respectively. LO, MD, and HI refer to low, medium, and high emotional intensities, respectively.
5.3. EMOLIPS
The values of mAcc = 86.2%, 90.7%, and 71.3% (six-emotion strategy); 92.5%, 92.6%, and 71.8% (three-level valence strategy); and 93.8%, 91.2%, and 72.0% (binary strategy) have been achieved with the assumption that an emotional model makes predictions with a high Acc. However, at the moment there are no such models that make such predictions with a high Acc on different corpora. We therefore applied the three emotional models proposed in this article (see Section 5.1) as the first level of the EMOLIPS approache.
The result of recognition of twelve phrases (see Table 11) taking into account the distribution of emotions using the EMO-3DCNN-GRU model and two-level recognition was achieved relative to two baselines (a model trained only on neutral phrases and all emotional phrases). The experimental results demonstrate that the EMOLIPS approach with a six-emotion strategy does not yield any improvement over the baselines for the RAVDESS and CREMA-D corpora. For the CREMA-D corpus, the maximum Acc of 90.9% was achieved with a three-level valence strategy, which is 6.7% higher than the NE baseline and 2.2% higher than the All baseline. For the RAVDESS and multi-corpus data, the binary strategy outperformed the three-level valence strategy by an average of 1%, resulting in a maximum phrase recognition Acc of 91.9% and 71.7%, respectively.
Table 11.
Comparison of mAcc of our two-level approaches with baseline (model trained only on NE phrases and all emotional phrases.
It is worth noting that our EMOLIPS approach, based on the CREMA-D corpus, outperformed our previous result by 23.1% [20]. Compared to our previous approach, we have not only introduced a two-stage phrase recognition based on lip-reading, but also improved the phrase recognition model itself.
6. Conclusions
In this article, we proposed the EMOLIPS approach for automatic emotional speech lip-reading. This two-level approach based on visual data processing was motivated by human perception and the recent developments in multimodal DL. The proposed approach uses visual speech data to determine the type of speech emotion. The speech data are then processed using one of the emotional lip-reading models trained from scratch. This essentially resolves the multi-emotional lip-reading issue associated with most real-life scenarios. We implemented these models as a combination of EMO-3DCNN-GRU architecture for emotion recognition and 3DCNN-BiLSTM architecture for automatic lip-reading.
In addition, this article provided a detailed review of the recent advances in automated lip-reading and emotion recognition that have been developed over the last 5 years (2018–2023). In comparison to existing research, we mainly focused on the valuable progress brought with the introduction of DL to the field and skip the description of traditional approaches. Moreover, we presented an extensive experimental investigation that demonstrates how different emotions (happiness, anger, disgust, fear, sadness, and neutral), valence (positive, neutral, and negative) and binary (emotional and neutral) affect automatic lip-reading.
The evaluation on the RAVDESS and CREMA-D corpora demonstrated that the proposed approach achieved SOTA performance with up to 91.9% and 90.9% emotional phrase recognition Acc, respectively. We also trained three emotional models for specific tasks: (1) six-emotion recognition, (2) three-level valence recognition, and (3) binary emotion recognition. Our proposed emotional model outperformed SOTA results for emotion recognition by more than 1% in terms of the Acc using a tenfold cross-validation setup.
There are various potential areas for future research. These include improving the performance of emotional lip-reading models by using more complex model architectures and applying them to real-time applications in affective computing and Human-Computer Interaction (HCI). Additionally, it is vital to explore multimodal approaches that integrate lip-reading with other modalities such as audio and text. The results of this research are crucial for pushing the boundaries of emotion recognition and automatic lip-reading.
All source code and trained models are available on our GitHub repository at https://github.com/SMIL-SPCRAS/EMOLIPS (accessed on 24 October 2023).
Author Contributions
Conceptualization, E.R. and D.I.; methodology, E.R.; validation, E.R.; formal analysis, D.R.; investigation, E.R.; resources, D.I.; writing—original draft preparation, E.R. and D.I.; writing—review and editing, D.R. and D.I.; visualization, D.R., E.R. and D.I.; supervision, D.R.; project administration, D.R.; funding acquisition, D.I. All authors have read and agreed to the published version of the manuscript.
Funding
Section 1, Section 3, Section 4, Section 5.2, Section 5.3 and Section 6 were financially supported by the Russian Science Foundation (No. 23-71-01056, https://rscf.ru/en/project/23-71-01056/, accessed on 24 October 2023), Section 5.1 was financially supported by a grant (No. MK-42.2022.4), and Section 2 was financially supported by the State research (Topic No. FFZF-2022-0005).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
In this study, we used two large-scale publicly available corpora: RAVDESS—https://zenodo.org/records/1188976 (accessed on 24 October 2023) and CREMA-D—https://github.com/CheyneyComputerScience/CREMA-D (accessed on 24 October 2023).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| 1D | 1-Dimensional |
| 2D | 2-Dimensional |
| 3D | 3-Dimensional |
| 4D | 4-Dimensional |
| Acc | Accuracy |
| AN | Angry |
| ASR | Audio Speech Recognition |
| AV | Audio-Visual |
| AVSR | Audio-Visual Speech Recognition |
| Bi | Bidirectional |
| CA | Calm |
| CNN | Convolutional Neural Network |
| CREMA-D | Crowd-Sourced Emotional Multimodal Actors Dataset |
| CV | Computer Vision |
| DBN | Deep Belief Network |
| DI | Disgust |
| DL | Deep Learning |
| DNN | Deep Neutral Network |
| EM | Emotional |
| F1 | F1-measure |
| FC | Fully Connected |
| FE | Fearful |
| FPS | Frames per Second |
| GELU | Gaussian Error Linear Unit |
| GRU | Gated Recurrent Unit |
| HA | Happy |
| HCI | Human-Computer Interaction |
| KL | Kullback-Leibler |
| LN | Layer Normalization |
| LOCO | Leave-One-Corpus-Out |
| LRS | Lip-Reading Sentences in-the-Wild dataset |
| LRW | Lip Reading in the Wild dataset |
| LSTM | Long-Short Term Memory |
| mAcc | Mean Accuracy |
| ML | Machine Learning |
| MLP | Multilayer Perceptron |
| MSA | Multi-head Self-Attention |
| MSTCN | Multi-Scale Temporal Convolution Network |
| NE | Neutral |
| NG | Negative |
| NN | Neutral Network |
| PO | Positive |
| RAVDESS | Ryerson Audio-Visual Database of Emotional Speech and Song |
| RNN | Recurrent Neural Network |
| ROI | Region-of-Interest |
| RUME | Recurrence based Uni-Modality Encoder |
| S2T | Speech-to-Text |
| SA | Sad |
| SER | Speech Emotion Recognition |
| SGD | Stochastic Gradient Descent |
| SOTA | State-of-the-Art |
| SR | Speech Recognition |
| STCNN | Spatio-Temporal Convolutional Neural Network |
| STFT | Short Time Fourier Transform |
| SU | Surprised |
| SVM | Support Vector Machine |
| TSN | Two-Stream Network |
| UAR | Unweighted Average Recall |
| VER | Visual Emotion Recognition |
| VGG | Visual Geometry Group |
| ViT | Vision Transformer |
| VSR | Visual Speech Recognition |
References
- Benoit, C.; Martin, J.C.; Pelachaud, C.; Schomaker, L.; Suhm, B. Audio-Visual and Multimodal Speech Systems. Handb. Stand. Resour. Spok. Lang. Syst.-Suppl. 2000, 500, 1–95. [Google Scholar]
- Chen, T. Audiovisual Speech Processing. IEEE Signal Process. Mag. 2001, 18, 9–21. [Google Scholar] [CrossRef]
- Hardison, D.M. Acquisition of Second-Language Speech: Effects of Visual cues, Context, and Talker Variability. Appl. Psycholinguist. 2003, 24, 495–522. [Google Scholar] [CrossRef]
- Campbell, R. The Processing of Audio-Visual Speech: Empirical and Neural bases. Philos. Trans. R. Soc. B Biol. Sci. 2008, 363, 1001–1010. [Google Scholar] [CrossRef]
- Michon, M.; López, V.; Aboitiz, F. Origin and Evolution of Human Speech: Emergence from a Trimodal Auditory, Visual and Vocal Network. Prog. Brain Res. 2019, 250, 345–371. [Google Scholar] [CrossRef]
- Dupont, S.; Luettin, J. Audio-Visual Speech Modeling for Continuous Speech Recognition. IEEE Trans. Multimed. 2000, 2, 141–151. [Google Scholar] [CrossRef]
- Shillingford, B.; Assael, Y.; Hoffman, M.W.; Paine, T.; Hughes, C.; Prabhu, U.; Liao, H.; Sak, H.; Rao, K.; Bennett, L.; et al. Large-Scale Visual Speech Recognition. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 4135–4139. [Google Scholar] [CrossRef]
- Ivanko, D.; Ryumin, D.; Kashevnik, A.; Axyonov, A.; Karnov, A. Visual Speech Recognition in a Driver Assistance System. In Proceedings of the 2022 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; pp. 1131–1135. [Google Scholar] [CrossRef]
- Ma, P.; Petridis, S.; Pantic, M. Visual Speech Recognition for Multiple Languages in the Wild. Nat. Mach. Intell. 2022, 4, 930–939. [Google Scholar] [CrossRef]
- Choi, J.; Kim, M.; Ro, Y.M. Intelligible Lip-to-Speech Synthesis with Speech Units. arXiv 2023, arXiv:2305.19603. [Google Scholar]
- Ma, P.; Wang, Y.; Petridis, S.; Shen, J.; Pantic, M. Training Strategies for Improved Lip-Reading. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 8472–8476. [Google Scholar] [CrossRef]
- Koumparoulis, A.; Potamianos, G. Accurate and Resource-Efficient Lipreading with EfficientNetV2 and Transformers. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 8467–8471. [Google Scholar] [CrossRef]
- Kim, M.; Yeo, J.H.; Ro, Y.M. Distinguishing Homophenes Using Multi-Head Visual-Audio Memory for Lip Reading. AAAI Conf. Artif. Intell. 2022, 36, 1174–1182. [Google Scholar] [CrossRef]
- Ma, P.; Martínez, B.; Petridis, S.; Pantic, M. Towards Practical Lipreading with Distilled and Efficient Models. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 7608–7612. [Google Scholar] [CrossRef]
- Feng, D.; Yang, S.; Shan, S.; Chen, X. Learn an Effective Lip Reading Model without Pains. arXiv 2020, arXiv:2011.07557. [Google Scholar]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on Speech Emotion Recognition: Features, Classification Schemes, and Databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Swain, M.; Routray, A.; Kabisatpathy, P. Databases, Features and Classifiers for Speech Emotion Recognition: A Review. Int. J. Speech Technol. 2018, 21, 93–120. [Google Scholar] [CrossRef]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Malik, M.I.; Latif, S.; Jurdak, R.; Schuller, B.W. A Preliminary Study on Augmenting Speech Emotion Recognition Using a Diffusion Model. In Proceedings of the Interspeech, Dublin, Ireland, 20–24 August 2023; pp. 646–650. [Google Scholar] [CrossRef]
- Ryumina, E.; Ivanko, D. Emotional Speech Recognition Based on Lip-Reading. In Proceedings of the International Conference on Speech and Computer (SPECOM), Dharwad, India, 29 Novenber–2 December 2022; Springer: Cham, Switzerland, 2022; pp. 616–625. [Google Scholar] [CrossRef]
- Tarnowski, P.; Kołodziej, M.; Majkowski, A.; Rak, R.J. Emotion Recognition Using Facial Expressions. Procedia Comput. Sci. 2017, 108, 1175–1184. [Google Scholar] [CrossRef]
- Mellouk, W.; Handouzi, W. Facial Emotion Recognition Using Deep Learning: Review and Insights. Procedia Comput. Sci. 2020, 175, 689–694. [Google Scholar] [CrossRef]
- Ouzar, Y.; Bousefsaf, F.; Djeldjli, D.; Maaoui, C. Video-Based Multimodal Spontaneous Emotion Recognition Using Facial Expressions and Physiological Signals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Orleans, LA, USA, 19–20 June 2022; pp. 2460–2469. [Google Scholar] [CrossRef]
- Kansizoglou, I.; Misirlis, E.; Tsintotas, K.; Gasteratos, A. Continuous Emotion Recognition for Long-Term Behavior Modeling through Recurrent Neural Networks. Technologies 2022, 10, 59. [Google Scholar] [CrossRef]
- Ryumin, D.; Karpov, A.A. Towards Automatic Recognition of Sign Language Gestures Using Kinect 2.0. In Proceedings of the International Conference on Universal Access in Human-Computer Interaction (UAHCI), Vancouver, BC, Canada, 9–14 July 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 89–101. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, Y.; Sun, S.; Li, Q.; Zhao, X. Generalized Zero-Shot Emotion Recognition from Body Gestures. Appl. Intell. 2022, 52, 8616–8634. [Google Scholar] [CrossRef]
- Ryumin, D.; Ivanko, D.; Axyonov, A. Cross-Language Transfer Learning Using Visual Information for Automatic Sign Gesture Recognition. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2023, 48, 209–216. [Google Scholar] [CrossRef]
- Shi, H.; Peng, W.; Chen, H.; Liu, X.; Zhao, G. Multiscale 3D-Shift Graph Convolution Network for Emotion Recognition from Human Actions. IEEE Intell. Syst. 2022, 37, 103–110. [Google Scholar] [CrossRef]
- Atmaja, B.T.; Sasou, A.; Akagi, M. Survey on Bimodal Speech Emotion Recognition from Acoustic and Linguistic Information Fusion. Speech Commun. 2022, 140, 11–28. [Google Scholar] [CrossRef]
- Zhang, T.; El Ali, A.; Hanjalic, A.; Cesar, P. Few-Shot Learning for Fine-Grained Emotion Recognition Using Physiological Signals. IEEE Trans. Multimed. 2022, 25, 3773–3787. [Google Scholar] [CrossRef]
- Zhang, T.; El Ali, A.; Wang, C.; Hanjalic, A.; Cesar, P. Weakly-Supervised Learning for Fine-Grained Emotion Recognition Using Physiological Signals. IEEE Trans. Affect. Comput. 2022, 14, 2304–2322. [Google Scholar] [CrossRef]
- Saganowski, S.; Perz, B.; Polak, A.; Kazienko, P. Emotion Recognition for Everyday Life Using Physiological Signals from Wearables: A Systematic Literature Review. IEEE Trans. Affect. Comput. 2022, 14, 1876–1897. [Google Scholar] [CrossRef]
- Lin, W.; Li, C. Review of Studies on Emotion Recognition and Judgment based on Physiological Signals. Appl. Sci. 2023, 13, 2573. [Google Scholar] [CrossRef]
- Kumar, P.; Raman, B. A BERT Based Dual-Channel Explainable Text Emotion Recognition System. Neural Netw. 2022, 150, 392–407. [Google Scholar] [CrossRef]
- Poulose, A.; Kim, J.H.; Han, D.S. Feature Vector Extraction Technique for Facial Emotion Recognition Using Facial Landmarks. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1072–1076. [Google Scholar] [CrossRef]
- Latif, S.; Rana, R.; Younis, S.; Qadir, J.; Epps, J. Transfer Learning for Improving Speech Emotion Classification Accuracy. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 257–261. [Google Scholar] [CrossRef]
- Yenigalla, P.; Kumar, A.; Tripathi, S.; Singh, C.; Kar, S.; Vepa, J. Speech Emotion Recognition Using Spectrogram & Phoneme Embedding. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 3688–3692. [Google Scholar] [CrossRef]
- Wöllmer, M.; Metallinou, A.; Katsamanis, N.; Schuller, B.; Narayanan, S. Analyzing the Memory of BLSTM Neural Networks for Enhanced Emotion Classification in Dyadic Spoken Interactions. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 4157–4160. [Google Scholar] [CrossRef]
- Lee, J.; Tashev, I. High-Level Feature Representation Using Recurrent Neural Network for Speech Emotion Recognition. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015; pp. 1537–1540. [Google Scholar] [CrossRef]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic Speech Emotion Recognition Using Recurrent Neural Networks with Local Attention. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2227–2231. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Schoneveld, L.; Othmani, A.; Abdelkawy, H. Leveraging Recent Advances in Deep Learning for Audio-Visual Emotion Recognition. Pattern Recognit. Lett. 2021, 146, 1–7. [Google Scholar] [CrossRef]
- Kim, B.; Lee, J. A Deep-Learning based Model for Emotional Evaluation of Video Clips. Int. J. Fuzzy Log. Intell. Syst. 2018, 18, 245–253. [Google Scholar] [CrossRef]
- Yang, J.; Wang, K.; Peng, X.; Qiao, Y. Deep Recurrent Multi-Instance Learning with Spatio-Temporal Features for Engagement Intensity Prediction. In Proceedings of the International Conference on Multimodal Interaction (ICMI), Boulder, CO, USA, 16–20 October 2018; pp. 594–598. [Google Scholar] [CrossRef]
- Deng, D.; Chen, Z.; Zhou, Y.; Shi, B. Mimamo Net: Integrating Micro-and Macro-Motion for Video Emotion Recognition. AAAI Conf. Artif. Intell. 2020, 34, 2621–2628. [Google Scholar] [CrossRef]
- Pan, X.; Ying, G.; Chen, G.; Li, H.; Li, W. A Deep Spatial and Temporal Aggregation Framework for Video-Based Facial Expression Recognition. IEEE Access 2019, 7, 48807–48815. [Google Scholar] [CrossRef]
- Ma, F.; Li, Y.; Ni, S.; Huang, S.L.; Zhang, L. Data Augmentation for Audio-Visual Emotion Recognition with an Efficient Multimodal Conditional GAN. Appl. Sci. 2022, 12, 527. [Google Scholar] [CrossRef]
- Middya, A.I.; Nag, B.; Roy, S. Deep Learning Based Multimodal Emotion Recognition Using Model-Level Fusion of Audio-Visual Modalities. Knowl.-Based Syst. 2022, 244, 108580. [Google Scholar] [CrossRef]
- Tran, M.; Soleymani, M. A Pre-Trained Audio-Visual Transformer for Emotion Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 4698–4702. [Google Scholar] [CrossRef]
- John, V.; Kawanishi, Y. Audio and Video-Based Emotion Recognition Using Multimodal Transformers. In Proceedings of the International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 2582–2588. [Google Scholar] [CrossRef]
- Praveen, R.G.; de Melo, W.C.; Ullah, N.; Aslam, H.; Zeeshan, O.; Denorme, T.; Pedersoli, M.; Koerich, A.L.; Bacon, S.; Cardinal, P.; et al. A Joint Cross-Attention Model for Audio-Visual Fusion in Dimensional Emotion Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; pp. 2485–2494. [Google Scholar] [CrossRef]
- Lei, Y.; Cao, H. Audio-Visual Emotion Recognition with Preference Learning based on Intended and Multi-Modal Perceived Labels. IEEE Trans. Affect. Comput. 2023, 1–16. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, Y.; Chen, C.; Zhang, X.; Leng, Q.; Zhao, X. Deep Learning-Based Multimodal Emotion Recognition from Audio, Visual, and Text Modalities: A Systematic Review of Recent Advancements and Future Prospects. Expert Syst. Appl. 2023, 237. [Google Scholar] [CrossRef]
- Mocanu, B.; Tapu, R.; Zaharia, T. Multimodal Emotion Recognition Using Cross Modal Audio-Video Fusion with Attention and Deep Metric Learning. Image Vis. Comput. 2023, 133, 104676. [Google Scholar] [CrossRef]
- Nguyen, D.; Nguyen, K.; Sridharan, S.; Ghasemi, A.; Dean, D.; Fookes, C. Deep Spatio-Temporal Features for Multimodal Emotion Recognition. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1215–1223. [Google Scholar] [CrossRef]
- Huang, J.; Tao, J.; Liu, B.; Lian, Z.; Niu, M. Multimodal Transformer Fusion for Continuous Emotion Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3507–3511. [Google Scholar] [CrossRef]
- Ristea, N.C.; Ionescu, R.T. Self-Paced Ensemble Learning for Speech and Audio Classification. arXiv 2021, arXiv:2103.11988. [Google Scholar]
- Georgescu, M.I.; Ionescu, R.T.; Ristea, N.C.; Sebe, N. Non-Linear Neurons with Human-like Apical Dendrite Activations. Appl. Intell. 2023, 53, 25984–26007. [Google Scholar] [CrossRef]
- Gong, Y.; Chung, Y.A.; Glass, J. Ast: Audio Spectrogram Transformer. arXiv 2021, arXiv:2104.01778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Luna-Jiménez, C.; Kleinlein, R.; Griol, D.; Callejas, Z.; Montero, J.M.; Fernández-Martínez, F. A Proposal for Multimodal Emotion Recognition Using Aural Transformers and Action units on RAVDESS Dataset. Appl. Sci. 2021, 12, 327. [Google Scholar] [CrossRef]
- Pavlopoulos, J.; Malakasiotis, P.; Androutsopoulos, I. Deep Learning for User Comment Moderation. arXiv 2017, arXiv:1705.09993. [Google Scholar]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal Transformer for Unaligned Multimodal Language Sequences. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), Florence, Italy, 28 July–2 August 2019; NIH Public Access: Bethesda, MA, USA, 2019; pp. 6558–6569. [Google Scholar] [CrossRef]
- Krishna, D.; Patil, A. Multimodal Emotion Recognition Using Cross-Modal Attention and 1D Convolutional Neural Networks. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 4243–4247. [Google Scholar] [CrossRef]
- Li, Z.; Tang, F.; Zhao, M.; Zhu, Y. EmoCaps: Emotion Capsule based Model for Conversational Emotion Recognition. In Findings of the Association for Computational Linguistics: ACL 2022; Association for Computational Linguistics: Dublin, Ireland, 2022. [Google Scholar] [CrossRef]
- Li, J.; Liu, Y.; Wang, X.; Zeng, Z. CFN-ESA: A Cross-Modal Fusion Network with Emotion-Shift Awareness for Dialogue Emotion Recognition. arXiv 2023, arXiv:2307.15432. [Google Scholar]
- Ivanko, D.; Ryumin, D.; Karpov, A. A Review of Recent Advances on Deep Learning Methods for Audio-Visual Speech Recognition. Mathematics 2023, 11, 2665. [Google Scholar] [CrossRef]
- Ryumin, D.; Ivanko, D.; Ryumina, E. Audio-Visual Speech and Gesture Recognition by Sensors of Mobile Devices. Sensors 2023, 23, 2284. [Google Scholar] [CrossRef]
- Noda, K.; Yamaguchi, Y.; Nakadai, K.; Okuno, H.G.; Ogata, T. Lipreading Using Convolutional Neural Network. In Proceedings of the Interspeech, Singapore, 14–18 September 2014; pp. 1149–1153. [Google Scholar] [CrossRef]
- Tamura, S.; Ninomiya, H.; Kitaoka, N.; Osuga, S.; Iribe, Y.; Takeda, K.; Hayamizu, S. Audio-Visual Speech Recognition Using Deep Bottleneck Features and High-Performance Lipreading. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA), Hong Kong, China, 16–19 December 2015; pp. 575–582. [Google Scholar] [CrossRef]
- Petridis, S.; Pantic, M. Deep Complementary Bottleneck Features for Visual Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 2304–2308. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar] [CrossRef]
- Assael, Y.; Shillingford, B.; Whiteson, S.; de Freitas, N. LipNet: Sentence-level Lipreading. arXiv 2016, arXiv:1611.01599. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-Scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar] [CrossRef]
- Chung, J.S.; Senior, A.W.; Vinyals, O.; Zisserman, A. Lip Reading Sentences in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3444–3453. [Google Scholar] [CrossRef]
- Shi, B.; Hsu, W.N.; Mohamed, A. Robust Self-Supervised Audio-Visual Speech Recognition. In Proceedings of the Interspeech, Incheon, Republic of Korea, 18–22 September 2022; pp. 2118–2122. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Lip Reading in the Wild. In Asian Conference on Computer Vision; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Stafylakis, T.; Tzimiropoulos, G. Combining Residual Networks with LSTMs for Lipreading. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 3652–3656. [Google Scholar] [CrossRef]
- Martínez, B.; Ma, P.; Petridis, S.; Pantic, M. Lipreading Using Temporal Convolutional Networks. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6319–6323. [Google Scholar] [CrossRef]
- Serdyuk, D.; Braga, O.; Siohan, O. Transformer-Based Video Front-Ends for Audio-Visual Speech Recognition for Single and Muti-Person Video. In Proceedings of the Interspeech, Incheon, Republic of Korea, 18–22 September 2022; pp. 2833–2837. [Google Scholar] [CrossRef]
- Chen, C.F.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 347–356. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Fernandez-Lopez, A.; Sukno, F.M. Survey on Automatic Lip-Reading in the Era of Deep Learning. Image Vis. Comput. 2018, 78, 53–72. [Google Scholar] [CrossRef]
- Afouras, T.; Chung, J.S.; Zisserman, A. LRS3-TED: A Large-Scale Dataset for Visual Speech Recognition. arXiv 2018, arXiv:1809.00496. [Google Scholar]
- Gunes, H.; Piccardi, M. A Bimodal Face and Body Gesture Database for Automatic Analysis of Human Nonverbal Affective Behavior. In Proceedings of the International Conference on Pattern Recognition (ICPR), Hong Kong, China, 20–24 August 2006; Volume 1, pp. 1148–1153. [Google Scholar] [CrossRef]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 Audio-Visual Emotion Database. In Proceedings of the International Conference on Data Engineering Workshops (ICDEW), Atlanta, GA, USA, 3–7 April 2006; IEEE: Piscataway, NJ, USA, 2006; p. 8. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, E.A.; Provost, E.M.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive Emotional Dyadic Motion Capture Database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Haq, S.; Jackson, P.J.; Edge, J. Speaker-Dependent Audio-Visual Emotion Recognition. Audit.-Vis. Speech Process. 2009, 2009, 53–58. [Google Scholar]
- McKeown, G.; Valstar, M.; Cowie, R.; Pantic, M.; Schroder, M. The SEMAINE Database: Annotated Multimodal Records of Emotionally Colored Conversations between a Person and a Limited Agent. IEEE Trans. Affect. Comput. 2012, 3, 5–17. [Google Scholar] [CrossRef]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Collecting Large, Richly Annotated Facial-Expression Databases from Movies. IEEE Multimed. 2012, 19, 34–41. [Google Scholar] [CrossRef]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA Multimodal Corpus of Remote Collaborative and Affective Interactions. In Proceedings of the International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22-26 April 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Cao, H.; Cooper, D.G.; Keutmann, M.K.; Gur, R.C.; Nenkova, A.; Verma, R. CREMA-D: Crowd-Sourced Emotional Multimodal Actors Dataset. IEEE Trans. Affect. Comput. 2014, 5, 377–390. [Google Scholar] [CrossRef] [PubMed]
- Chou, H.C.; Lin, W.C.; Chang, L.C.; Li, C.C.; Ma, H.P.; Lee, C.C. NNIME: The NTHU-NTUA Chinese Interactive Multimodal Emotion Corpus. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 292–298. [Google Scholar] [CrossRef]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A Dynamic, Multimodal Set of Facial and Vocal Expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef]
- Perepelkina, O.S.; Kazimirova, E.; Konstantinova, M. RAMAS: Russian Multimodal Corpus of Dyadic Interaction for Studying Emotion Recognition. PeerJ Prepr. 2018, 6, e26688v1. [Google Scholar] [CrossRef]
- Sapinski, T.; Kamińska, D.; Pelikant, A.; Ozcinar, C.; Avots, E.; Anbarjafari, G. Multimodal Database of Emotional Speech, Video and Gestures. In Pattern Recognition and Information Forensics; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. In Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics (ACL): Florence, Italy, 2019; pp. 527–536. [Google Scholar] [CrossRef]
- Li, Y.; Tao, J.; Schuller, B.; Shan, S.; Jiang, D.; Jia, J. MEC 2017: Multimodal Emotion Recognition Challenge. In Proceedings of the Asian Conference on Affective Computing and Intelligent Interaction (ACII Asia), Beijing, China, 20–22 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Chen, J.; Wang, C.; jun Wang, K.; Yin, C.; Zhao, C.; Xu, T.; Zhang, X.; Huang, Z.; Liu, M.; Yang, T. HEU Emotion: A Large-Scale Database for Multimodal Emotion Recognition in the Wild. Neural Comput. Appl. 2020, 33, 8669–8685. [Google Scholar] [CrossRef]
- Landry, D.; He, Q.; Yan, H.; Li, Y. ASVP-ESD: A Dataset and its Benchmark for Emotion Recognition Using Both Speech and Non-Speech Utterances. Glob. Sci. Journals 2020, 8, 1793–1798. [Google Scholar]
- Zhu, H.; Wu, W.; Zhu, W.; Jiang, L.; Tang, S.; Zhang, L.; Liu, Z.; Loy, C.C. CelebV-HQ: A Large-Scale Video Facial Attributes Dataset. In Proceedings of the IEEE/CVF European Conference on Computer Vision (ECCV), Glasgow, UK, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 650–667. [Google Scholar] [CrossRef]
- Papaioannou, A.; Gecer, B.; Cheng, S.; Chrysos, G.; Deng, J.; Fotiadou, E.; Kampouris, C.; Kollias, D.; Moschoglou, S.; Songsri-In, K.; et al. MimicME: A Large Scale Diverse 4D Database for Facial Expression Analysis. In Proceedings of the IEEE/CVF European Conference on Computer Vision (ECCV), Glasgow, UK, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 467–484. [Google Scholar] [CrossRef]
- Yang, J.; Huang, Q.; Ding, T.; Lischinski, D.; Cohen-Or, D.; Huang, H. EmoSet: A Large-Scale Visual Emotion Dataset with Rich Attributes. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 30 September–6 October 2023; pp. 20383–20394. [Google Scholar]
- Garofolo, J.S. Timit Acoustic Phonetic Continuous Speech Corpus; Linguistic Data Consortium: Philadelphia, PA, USA, 1993. [Google Scholar]
- Ryumina, E.; Dresvyanskiy, D.; Karpov, A. In Search of a Robust Facial Expressions Recognition Model: A Large-Scale Visual Cross-Corpus Study. Neurocomputing 2022, 514, 435–450. [Google Scholar] [CrossRef]
- Fromberg, L.; Nielsen, T.; Frumosu, F.D.; Clemmensen, L.H. Beyond Accuracy: Fairness, Scalability, and Uncertainty Considerations in Facial Emotion Recognition. In Proceedings of the Northern Lights Deep Learning Conference, Tromsø, Norway, 9–11 January 2024; pp. 1–9. [Google Scholar]
- Ryumina, E.; Markitantov, M.; Karpov, A. Multi-Corpus Learning for Audio–Visual Emotions and Sentiment Recognition. Mathematics 2023, 11, 3519. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Yu, M.; Zheng, H.; Peng, Z.; Dong, J.; Du, H. Facial Expression Recognition based on a Multi-Task Global-Local Network. Pattern Recognit. Lett. 2020, 131, 166–171. [Google Scholar] [CrossRef]
- Liu, P.; Li, K.; Meng, H. Group Gated Fusion on Attention-Based Bidirectional Alignment for Multimodal Emotion Recognition. In Proceedings of the Interspeech, Shanghai, China, 25–29 October 2020; pp. 379–383. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar] [CrossRef]
- Ghaleb, E.; Niehues, J.; Asteriadis, S. Joint Modelling of Audio-Visual Cues Using Attention Mechanisms for Emotion Recognition. Multimed. Tools Appl. 2023, 82, 11239–11264. [Google Scholar] [CrossRef]
- Ghaleb, E.; Popa, M.; Asteriadis, S. Multimodal and Temporal Perception of Audio-Visual cues for Emotion Recognition. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 552–558. [Google Scholar] [CrossRef]
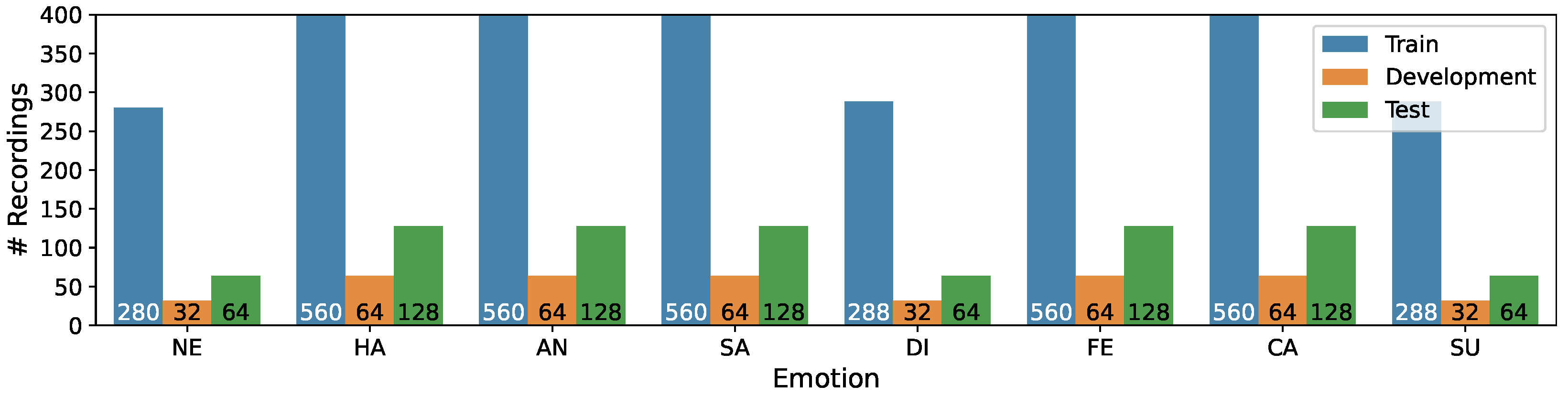
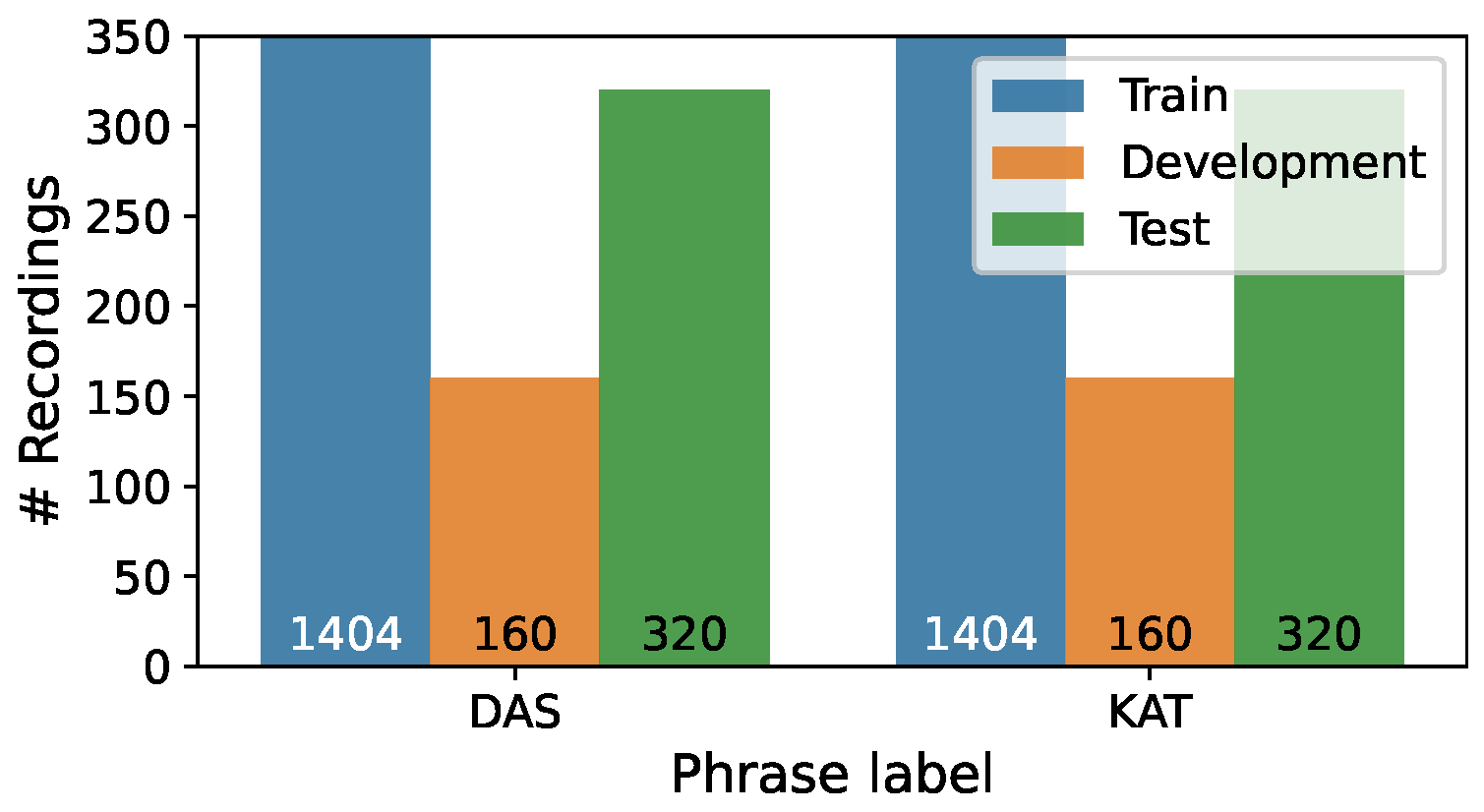
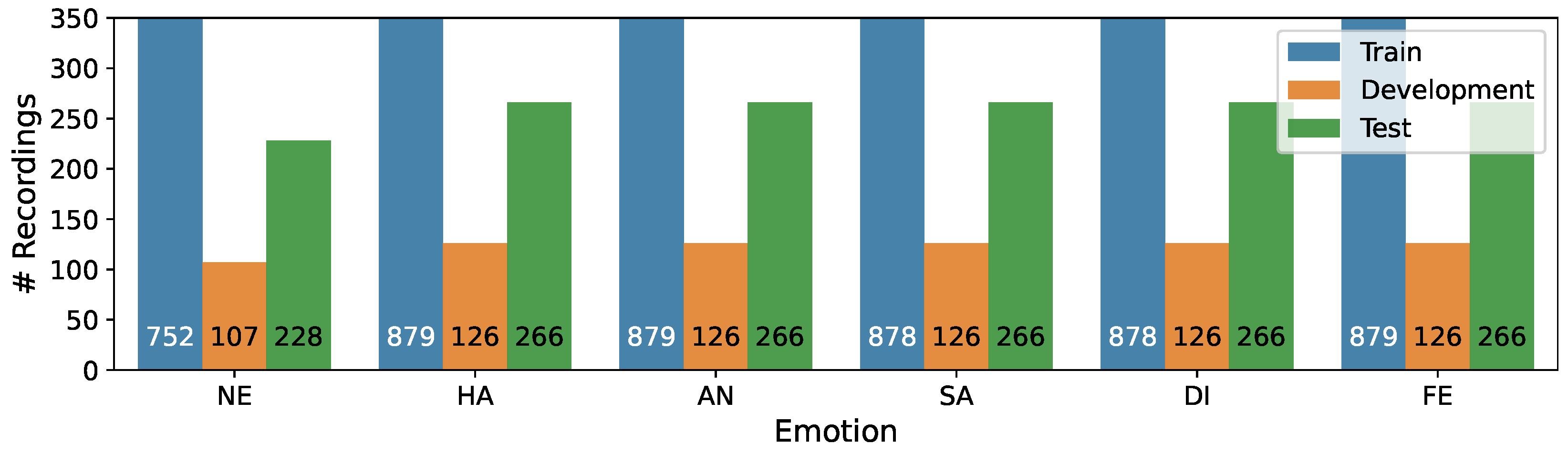
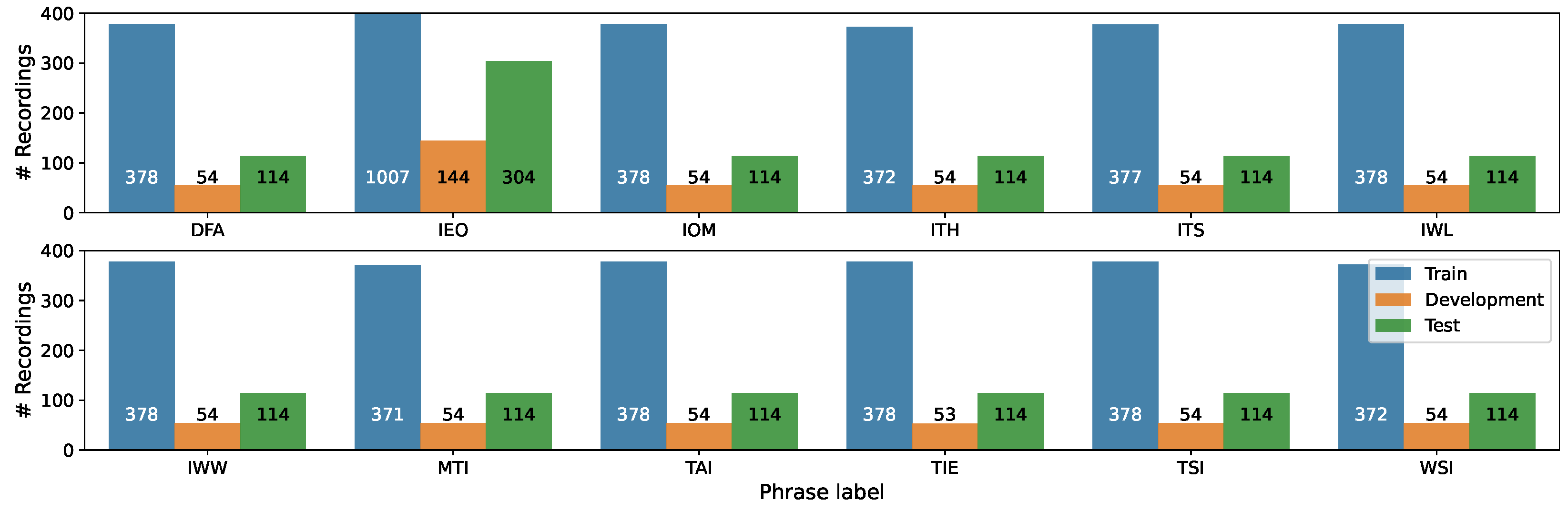
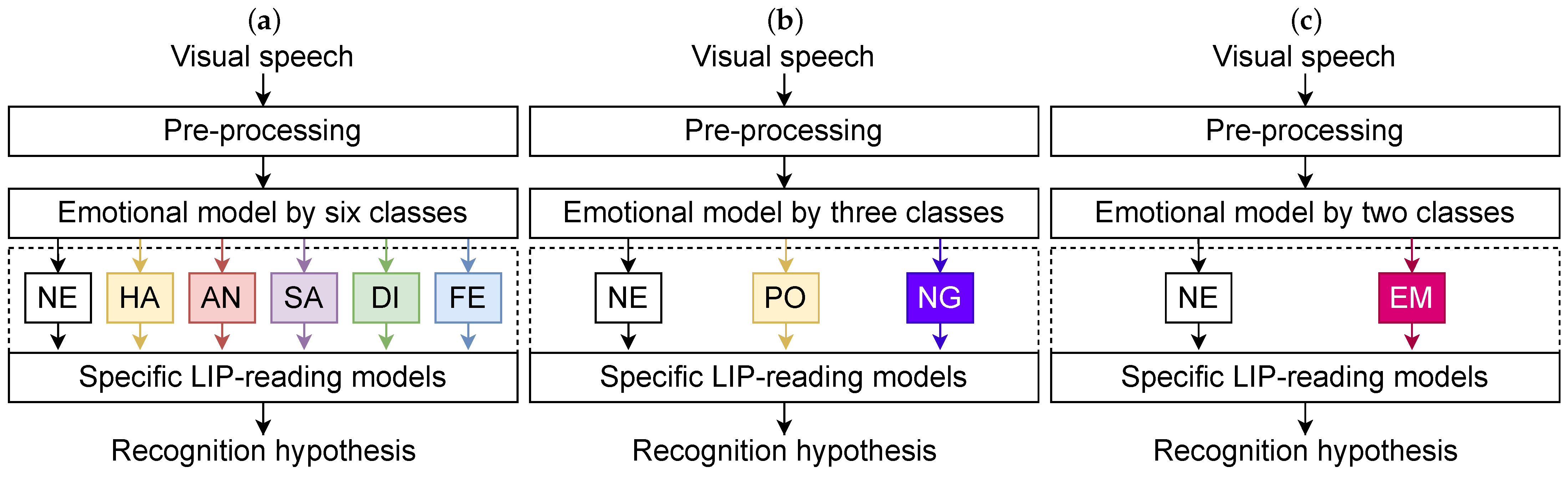
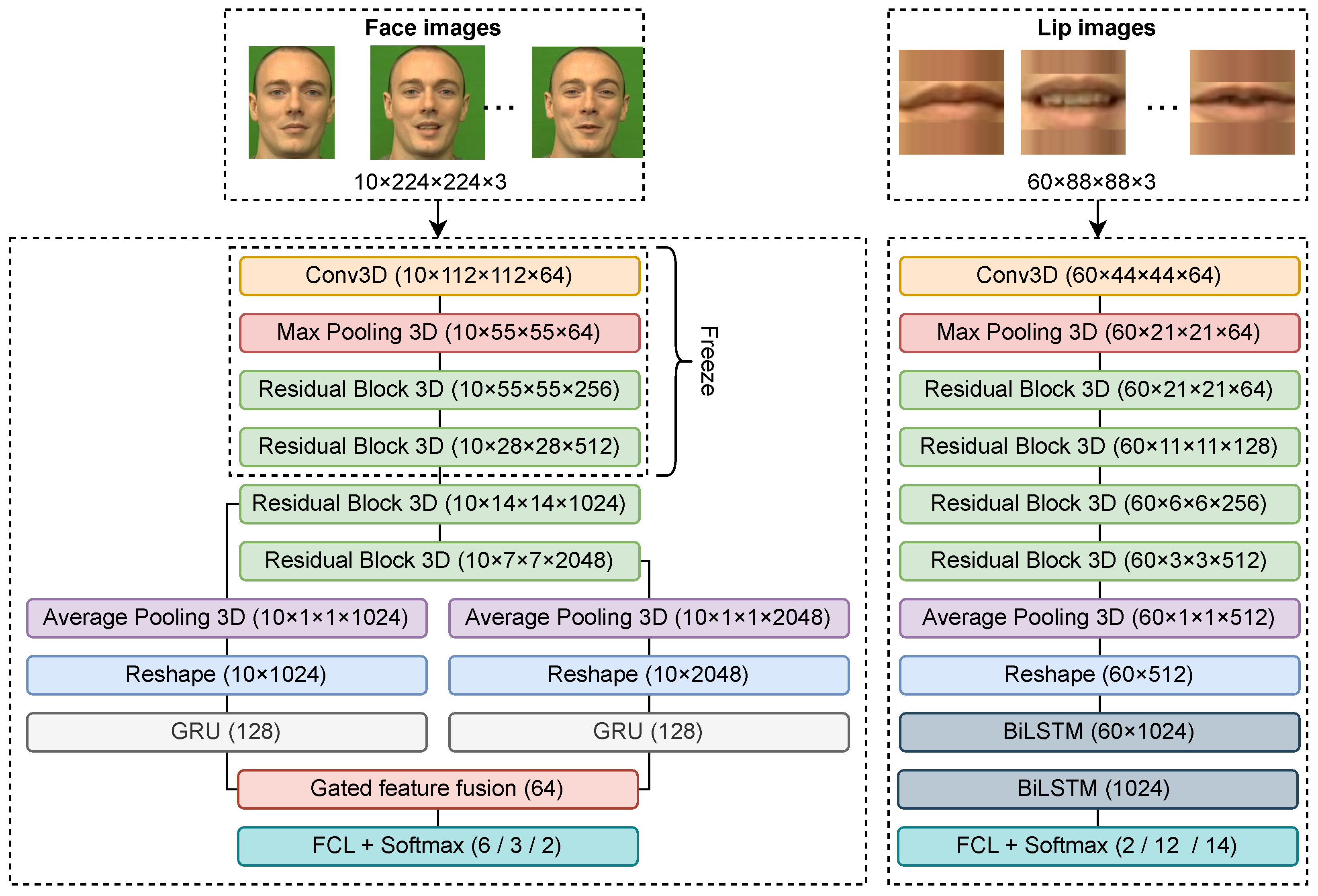

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).