
Column-Type Prediction for Web Tables Powered by Knowledge Base and Text


Abstract
:1. Introduction
- We propose a novel model CNN-Text, which contains the CNN and voting modules, which makes the column-type prediction results more accurate.
- We propose a data augmentation method for column-type prediction, which enables the CNN model to have better generalization ability.
- We conducted a series of experiments to demonstrate that CNN-Text is effective and the performance has been significantly improved compared with the baseline methods.
2. Related Work
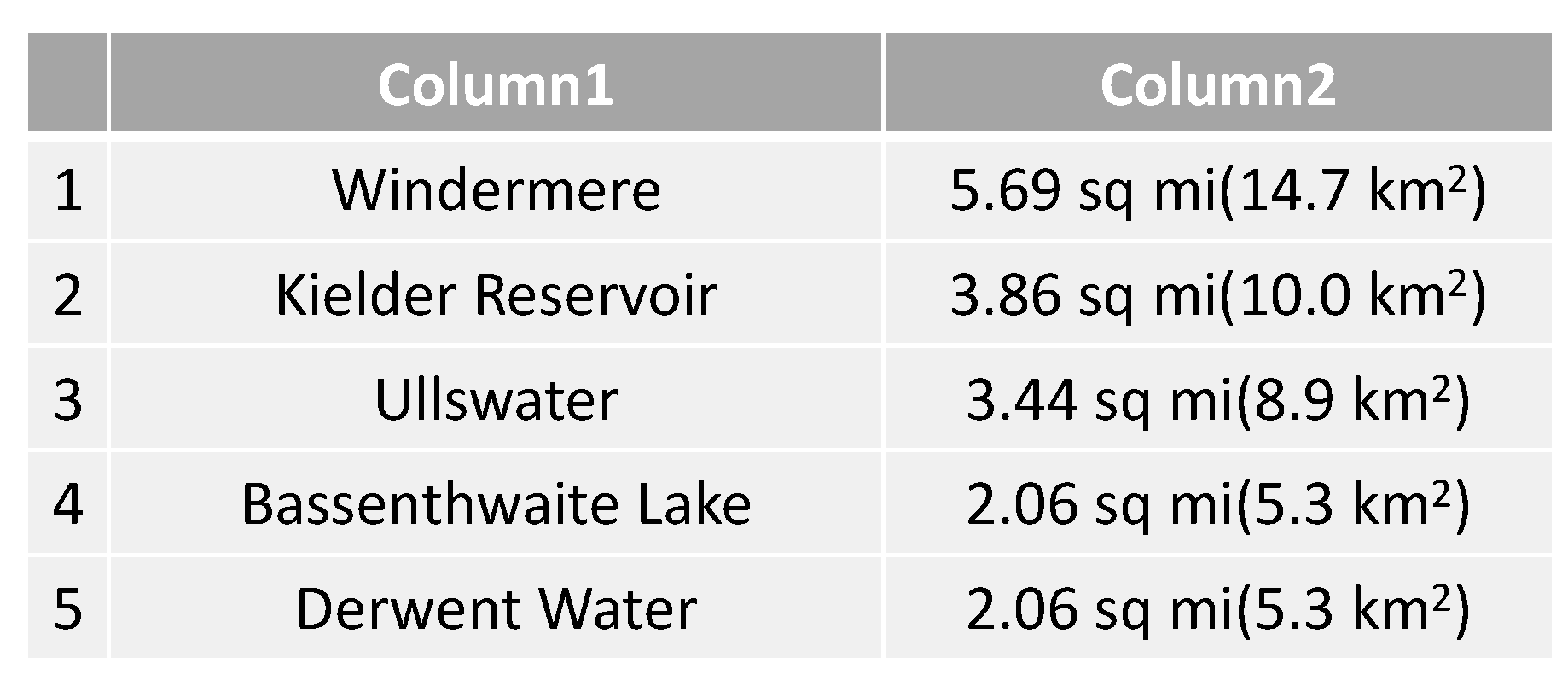
3. Problem Definition
4. Methodology
4.1. Lookup
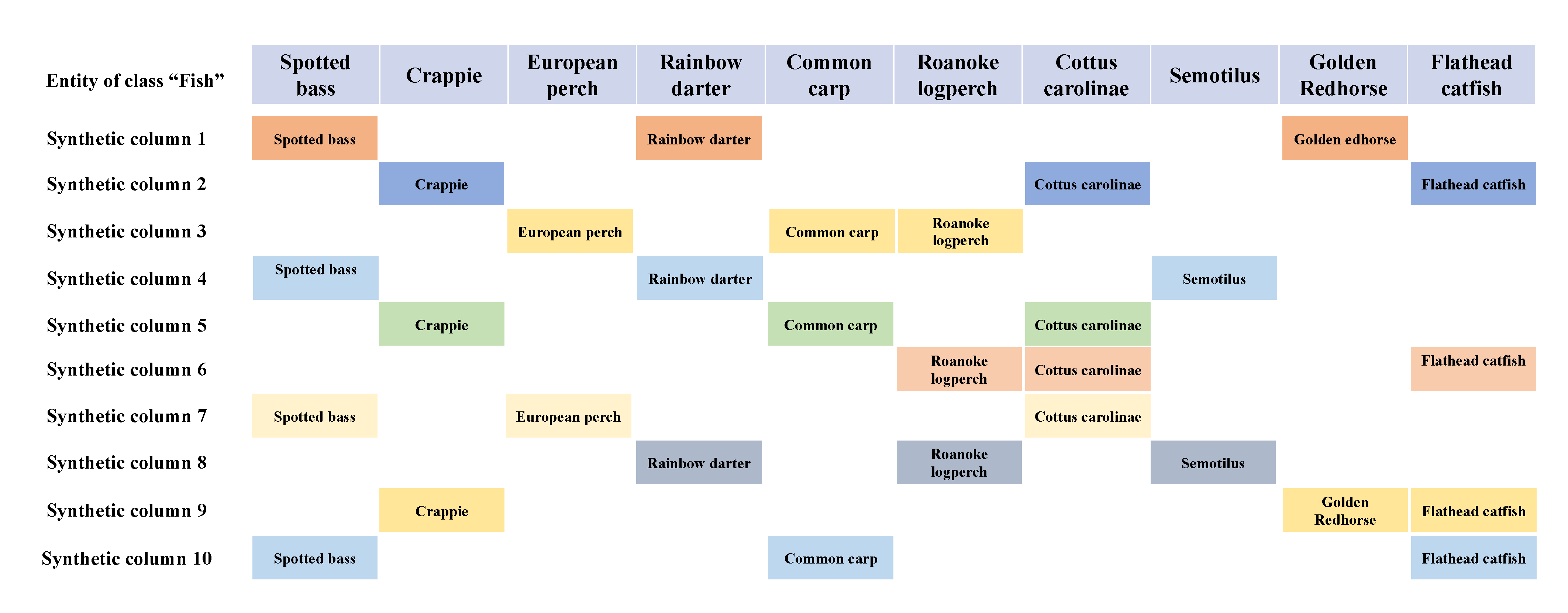
4.2. Data Augmentation
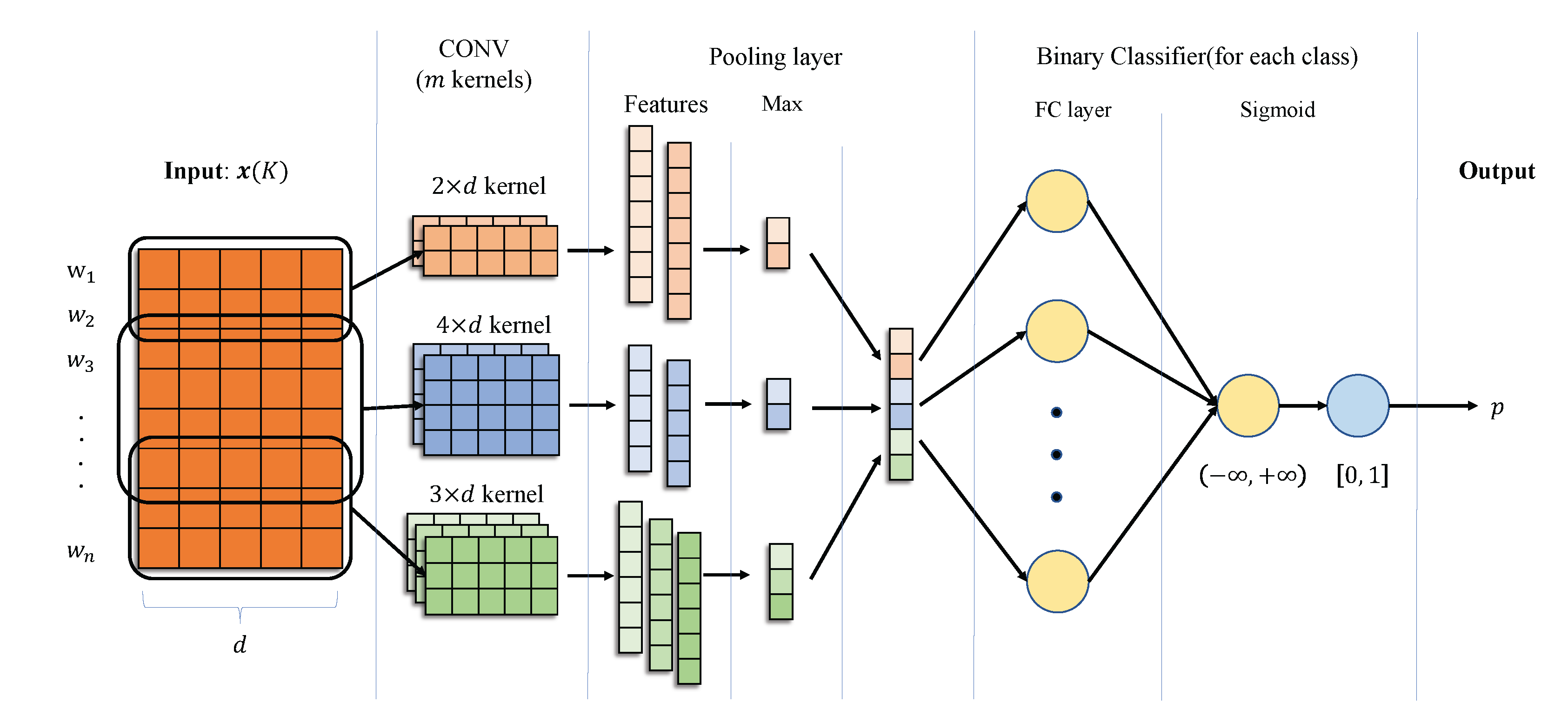
4.3. The CNN Training
4.4. Column-Type Prediction
5. Experiments
5.1. Experiment Setup
- T2K Match [13] is an iterative matching method that combines schema matching and instance matching, the major process of which includes candidate selection, value-based matching, property-based matching, and iterative matching.
- ColNet [12] is a framework that utilizes a KB, word representations, and machine learning to automatically train prediction models for annotating types of entity columns.
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Haneem, F.; Ali, R.; Kama, N.; Basri, S. Descriptive analysis and text analysis in systematic literature review: A review of master data management. In Proceedings of the 2017 International Conference on Research and Innovation in Information Systems (ICRIIS), Langkawi, Malaysia, 16–17 July 2017; pp. 1–6. [Google Scholar]
- White, R.W.; Dumais, S.T.; Teevan, J. Characterizing the influence of domain expertise on web search behavior. In Proceedings of the Second ACM International Conference on Web Search and Data Mining, Barcelona, Spain, 9–11 February 2009; pp. 132–141. [Google Scholar] [CrossRef]
- Fan, J.; Lu, M.; Ooi, B.C.; Tan, W.C.; Zhang, M. A hybrid machine-crowdsourcing system for matching web tables. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 976–987. [Google Scholar] [CrossRef] [Green Version]
- Tanon, T.P.; Weikum, G.; Suchanek, F.M. YAGO 4: A Reason-able Knowledge Base. In Proceedings of the ESWC, Crete, Greece, 31 May–4 June 2020; pp. 583–596. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A Nucleus for a Web of Open Data. In Proceedings of the ISWC, Busan, Korea, 11–15 November 2007; pp. 722–735. [Google Scholar] [CrossRef] [Green Version]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar] [CrossRef]
- Deng, X.; Sun, H.; Lees, A.; Wu, Y.; Yu, C. TURL: Table Understanding through Representation Learning. SIGMOD Rec. 2022, 51, 33–40. [Google Scholar] [CrossRef]
- Iida, H.; Thai, D.; Manjunatha, V.; Iyyer, M. TABBIE: Pretrained Representations of Tabular Data. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 3446–3456. [Google Scholar] [CrossRef]
- Wang, D.; Shiralkar, P.; Lockard, C.; Huang, B.; Dong, X.L.; Jiang, M. TCN: Table Convolutional Network for Web Table Interpretation. In Proceedings of the Web Conference 2021, Virtual Event, Ljubljana, Slovenia, 19–23 April 2021; pp. 4020–4032. [Google Scholar] [CrossRef]
- Limaye, G.; Sarawagi, S.; Chakrabarti, S. Annotating and Searching Web Tables Using Entities, Types and Relationships. In Proceedings of the VLDB Endow, Singapore, 13–17 September 2010; Volume 3, pp. 1338–1347. [Google Scholar] [CrossRef] [Green Version]
- Suhara, Y.; Li, J.; Li, Y.; Zhang, D.; Demiralp, Ç.; Chen, C.; Tan, W.C. Annotating Columns with Pre-trained Language Models. In Proceedings of the 2022 International Conference on Management of Data, Charleston, SC, USA, 7–9 November 2022; pp. 1493–1503. [Google Scholar] [CrossRef]
- Chen, J.; Jiménez-Ruiz, E.; Horrocks, I.; Sutton, C. ColNet: Embedding the Semantics of Web Tables for Column Type Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 29–36. [Google Scholar] [CrossRef] [Green Version]
- Ritze, D.; Lehmberg, O.; Bizer, C. Matching HTML Tables to DBpedia. In Proceedings of the 5th International Conference on Web Intelligence, Mining and Semantics, Larnaca Cyprus, 13–15 July 2015; pp. 10:1–10:6. [Google Scholar] [CrossRef] [Green Version]
- Pramanick, A.; Bhattacharya, I. Joint Learning of Representations for Web-tables, Entities and Types using Graph Convolutional Network. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 1197–1206. [Google Scholar] [CrossRef]
- Takeoka, K.; Oyamada, M.; Nakadai, S.; Okadome, T. Meimei: An Efficient Probabilistic Approach for Semantically Annotating Tables. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 281–288. [Google Scholar] [CrossRef] [Green Version]
- Broder, A.Z.; Glassman, S.C.; Manasse, M.S.; Zweig, G. Syntactic Clustering of the Web. Comput. Netw. 1997, 29, 1157–1166. [Google Scholar] [CrossRef]
- Grauman, K.; Darrell, T. The Pyramid Match Kernel: Discriminative Classification with Sets of Image Features. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; pp. 1458–1465. [Google Scholar] [CrossRef] [Green Version]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. In Proceedings of the Advances in Neural Information Processing Systems 14, Vancouver, BC, Canada, 3–8 December 2001; pp. 601–608. [Google Scholar]
- Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Deerwester, S. Using latent semantic analysis to improve access to textual information. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Washington, DC, USA, 15–19 May 1988; pp. 281–285. [Google Scholar] [CrossRef]
- Adewumi, T.P.; Liwicki, F.; Liwicki, M. Word2Vec: Optimal hyperparameters and their impact on natural language processing downstream tasks. Open Comput. Sci. 2022, 12, 134–141. [Google Scholar] [CrossRef]
- Bhagavatula, C.S.; Noraset, T.; Downey, D. TabEL: Entity Linking in Web Tables. In Proceedings of the International Semantic Web Conference, Bethlehem, PA, USA, 11–15 October 2015; pp. 425–441. [Google Scholar] [CrossRef]
- Chu, X.; Morcos, J.; Ilyas, I.F.; Ouzzani, M.; Papotti, P.; Tang, N.; Ye, Y. KATARA: A Data Cleaning System Powered by Knowledge Bases and Crowdsourcing. In Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, Melbourne, VIC, Australia, 31 May–4 June 2015; pp. 1247–1261. [Google Scholar] [CrossRef]
- Efthymiou, V.; Hassanzadeh, O.; Rodriguez-Muro, M.; Christophides, V. Matching Web Tables with Knowledge Base Entities: From Entity Lookups to Entity Embeddings. In Proceedings of the International Semantic Web Conference, Vienna, Austria, 21–25 October 2017; pp. 260–277. [Google Scholar] [CrossRef]
- Chiche, A.; Yitagesu, B. Part of speech tagging: A systematic review of deep learning and machine learning approaches. J. Big Data 2022, 9, 10. [Google Scholar] [CrossRef]
- Samohi, A.; Mitelman, D.W.; Bar, K. Using Cross-Lingual Part of Speech Tagging for Partially Reconstructing the Classic Language Family Tree Model. In Proceedings of the 3rd Workshop on Computational Approaches to Historical Language Change, Dublin, Ireland, 26–27 May 2022; pp. 78–88. [Google Scholar] [CrossRef]
- Schmitt, X.; Kubler, S.; Robert, J.; Papadakis, M.; LeTraon, Y. A Replicable Comparison Study of NER Software: StanfordNLP, NLTK, OpenNLP, SpaCy, Gate. In Proceedings of the 2019 Sixth International Conference on Social Networks Analysis, Management and Security (SNAMS), Granada, Spain, 22–25 October 2019; pp. 338–343. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # Column (Labeled) | # Cell (Avg.) |
|---|---|---|
| T2Dv2 | 411 | 124 |
| Limaye | 84 | 23 |
| Evaluation Mode | Method | All Columns | PK Columns | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | ||
| Tolerant | T2K Match | 0.664 | 0.773 | 0.715 | 0.738 | 0.895 | 0.809 |
| ColNet | 0.886 | 0.807 | 0.847 | 0.942 | 0.906 | 0.924 | |
| CNN-Text | 0.868 | 0.829 | 0.848 | 0.923 | 0.912 | 0.918 | |
| Strict | T2K Match | 0.624 | 0.727 | 0.671 | 0.729 | 0.884 | 0.799 |
| ColNet | 0.749 | 0.757 | 0.753 | 0.853 | 0.874 | 0.864 | |
| CNN-Text | 0.743 | 0.767 | 0.754 | 0.843 | 0.883 | 0.863 | |
| Evaluation Mode | Method | PK Columns | ||
|---|---|---|---|---|
| Precision | Recall | F1 | ||
| Tolerant | T2K Match | 0.560 | 0.408 | 0.472 |
| ColNet | 0.796 | 0.799 | 0.798 | |
| CNN-Text | 0.811 | 0.791 | 0.801 | |
| Strict | T2K Match | 0.453 | 0.330 | 0.382 |
| ColNet | 0.603 | 0.639 | 0.620 | |
| CNN-Text | 0.607 | 0.697 | 0.649 | |
| Mode Metric | Strict (All Columns) | Tolerant (All Columns) | Strict (PK Columns) | Tolerant (PK Columns) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | Precision | Recall | F1 | Precision | Recall | F1 | |
| (A) | 0.5679 | 0.0335 | 0.0632 | 0.4610 | 0.1130 | 0.1810 | 0.7931 | 0.0587 | 0.1094 | 1.0000 | 0.0270 | 0.0520 |
| (B) | 0.5097 | 0.1142 | 0.1866 | 0.4851 | 0.2495 | 0.3295 | 0.7931 | 0.0587 | 0.1094 | 1.0000 | 0.0270 | 0.0520 |
| (C) | 0.4952 | 0.1135 | 0.1846 | 0.4908 | 0.2516 | 0.3327 | 0.6555 | 0.1992 | 0.3056 | 1.0000 | 0.1230 | 0.2180 |
| Mode Metric | Strict | Tolerant | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1 | Precision | Recall | F1 | |
| (A) | 0.1459 | 0.5533 | 0.2310 | 0.1980 | 0.8074 | 0.3180 |
| (B) | 0.6186 | 0.4918 | 0.5479 | 0.7004 | 0.7664 | 0.7319 |
| (C) | 0.5644 | 0.5205 | 0.5416 | 0.4561 | 0.7869 | 0.5774 |
| Evaluation Mode | Method | PK Columns | ||
|---|---|---|---|---|
| Precision | Recall | F1 | ||
| Tolerant | CNN | 0.763 | 0.820 | 0.791 |
| Voting | 0.732 | 0.660 | 0.694 | |
| CNN-Text | 0.811 | 0.791 | 0.801 | |
| Strict | CNN | 0.576 | 0.619 | 0.597 |
| Voting | 0.571 | 0.447 | 0.501 | |
| CNN-Text | 0.607 | 0.697 | 0.649 | |
| Filename(.csv) | Truth Value | Predicte Result | ||
|---|---|---|---|---|
| Target | ColNet | CNN-Text | ||
| file151614_2_cols1_rows105 | Book | Place | 0.09 | 0.09 |
| Architectural Structure | 0.09 | 0.09 | ||
| Work | 0.91 | 0.91 | ||
| Location | 0.10 | 0.10 | ||
| Sport Facility | 0.08 | 0.08 | ||
| Book | 0.8 | 1.00 | ||
| Television Show | 0.31 | 0.31 | ||
| Person | 0.16 | 0.16 | ||
| Agent | 0.19 | 0.19 | ||
| Film | 0.32 | 0.32 | ||
| Organisation | 0.13 | 0.13 | ||
| Written Work | 0.81 | 0.81 | ||
| file223755_0_cols1_rows27 | Film | File | 0.76 | 1.00 |
| Musical Work | 0.28 | 0.28 | ||
| Work | 0.99 | 0.99 | ||
| Album | 0.18 | 0.18 | ||
| Filename(.csv) | Truth Value | Predicte Result | ||
|---|---|---|---|---|
| Target | ColNet | CNN-Text | ||
| file101640_0_cols1_rows31 | University, EducationalInstitution, Agent, Collage, Organisation | Location | 0.15 | 0.15 |
| College | 0.31 | 1.00 | ||
| Agent | 0.92 | 0.92 | ||
| Place | 0.14 | 0.14 | ||
| Soccer Club | 0.03 | 0.03 | ||
| City | 0.05 | 0.05 | ||
| Populated Place | 0.03 | 0.03 | ||
| Educational Institution | 0.95 | 0.95 | ||
| Person | 0.05 | 0.05 | ||
| Architectural Structure | 0.14 | 0.14 | ||
| Building | 0.16 | 0.16 | ||
| University | 0.94 | 1.00 | ||
| Organisation | 0.92 | 0.92 | ||
| file227142_1_cols1_rows7 | Work, Software | Software | 0.97 | 0.97 |
| Work | 0.96 | 0.96 | ||
| Device | 0.41 | 0.41 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Ye, C.; Zhi, H.; Jiang, S. Column-Type Prediction for Web Tables Powered by Knowledge Base and Text. Mathematics 2023, 11, 560. https://doi.org/10.3390/math11030560
Wu J, Ye C, Zhi H, Jiang S. Column-Type Prediction for Web Tables Powered by Knowledge Base and Text. Mathematics. 2023; 11(3):560. https://doi.org/10.3390/math11030560
Chicago/Turabian StyleWu, Junyi, Chen Ye, Haoshi Zhi, and Shihao Jiang. 2023. "Column-Type Prediction for Web Tables Powered by Knowledge Base and Text" Mathematics 11, no. 3: 560. https://doi.org/10.3390/math11030560
APA StyleWu, J., Ye, C., Zhi, H., & Jiang, S. (2023). Column-Type Prediction for Web Tables Powered by Knowledge Base and Text. Mathematics, 11(3), 560. https://doi.org/10.3390/math11030560