1. Introduction
Deep learning is of great interest in such fields as healthcare, astronomy, and information science, where data are transformed into knowledge and processed intelligently. It is a data-driven information-mining technology that can process massive amounts of data. With the exponential growth of data, the traditional gradient descent method can no longer effectively solve large-scale machine learning problems. There are two types of common methods, and one is to use as many training samples as possible but perform only a tiny number of calculations per sample. The other is to take a small portion of the data for high-intensity calculations. The paper [
1] proposes that the former method is more efficient, and its standard optimization algorithm is stochastic gradient descent (SGD).
With the rapid update and development of neural networks, gradient descent algorithms have received extensive attention from the academic community. In Pytorch, torch.optim is an optimizer package supporting the most common optimization algorithms, including SGD, Adagrad, Adadelta, RMSprop, Adam, AdamW, and so on. The stochastic optimization methods have been added to the PyTorch optimizer and are widely used to solve deep-learning problems [
1,
2,
3].
This article discusses existing algorithms for neural networks and their typical applications in large-scale machine learning and deep learning. The main contributions of this paper are summarized as follows:
- (1)
Introducing the optimization problem for large-scale data and reviewing the related models of deep learning.
- (2)
Providing a review and discussion on recent advances in SGD.
- (3)
Providing some applications, open issues, and research trends.
To the best of our knowledge, there are only a few SGD-related preprinted surveys [
1,
4,
5,
6]. Compared with them, our contribution does the following:
- (1)
Summarizes SGD-related algorithms from machine learning and optimization perspectives. Worth mentioning are the proximal stochastic methods, which still needed to be summarized hitherto.
- (2)
Provides the mathematical properties of models and methods.
- (3)
Discusses the gap between theory and applications.
The remainder of this work describes several common deep-learning applications of SGD and then presents the many types of stochastic gradient descent. Finally, we summarize this article and discuss various unresolved concerns and research directions.
3. Stochastic Methods for Deep Learning
Training a neural network is an optimization procedure that involves determining the network parameters that minimize the loss function. These models require massive datasets and many model parameters to be tuned. In the age of artificial intelligence, finding the optimal method to handle enormous amounts of data is inspiring and challenging.
Stochastic gradient descent (SGD) [
33] is simple and successful among machine learning models. A great deal of work has been suggested in the past several years to solve optimization problems or improve optimization approaches in machine learning.
Given the train data
with
, the general form for optimization problem is:
where
w represents the weights of the model,
h is prediction function, and
is the loss function.
There are some simplified notations. A random seed is used to represent the sample (or a group of samples). Furthermore, f is the combination of the loss function ℓ and the prediction function h, so the loss is rewritten as for any given pair .
Some fundamental optimization algorithms for minimizing risk are given in the rest of this section.
3.1. Batch Gradient Descent
To update the weights
w, the gradient descent technique computes the gradient of the loss function. The learning rate
determines the extent of each iteration, influencing the number of iterations required to get the ideal value. The batch gradient descent [
34], also known as complete gradient descent, uses all samples to update parameters. The following steps are alternated until the algorithm converges:
where
w is the result of the previous iteration.
A cycle of training the entire dataset is called an "epoch," and batch gradient descent stops updating at the end of all training epochs. One update of the dataset needs to calculate all of their gradients. Batch gradient descent is prolonged on large-scale data and intractable for datasets that do not fit in memory. Thus, it also does not suit online learning. However, this method decreases the frequency of updates and results in a stable solution.
The batch gradient descent method is easy to use. If the objective function is convex, the solution is the global optimum. In convex problems, batch gradient descent has a linear convergence rate and is guaranteed to converge to a local minimum in non-convex issues.
Common examples of gradient descent are logistic regression, ridge regression, and smooth hinge loss. Hinge loss is not differentiable. Thus, we can use its subgradient. However, in deep learning, too much layering causes an unstable gradient.
3.2. SGD
A variant of the gradient descent algorithm is stochastic gradient descent (SGD). Instead of computing the gradient of
or
exactly, it only uses one random sample to estimate the gradient
of
in each iteration. Batch gradient descent conducts redundant calculations for large-scale problems because it recomputes the gradients of related samples before each parameter changes, whereas SGD does only one computation per iteration. Algorithm 1 contains the whole SGD algorithm. It is simple to use, saves memory, and can also be suited to online learning.
| Algorithm 1: Stochastic gradient descent (SGD) [33]. |
- 1:
Input: learning rate . - 2:
Initialize, . - 3:
while Stop Criteria is True do - 4:
Sample with - 5:
- 6:
- 7:
- 8:
end while
|
Stochastic gradients are unbiased estimates of the real gradient. Add random noise with a mean of zero to gradient descent to simulate SGD.
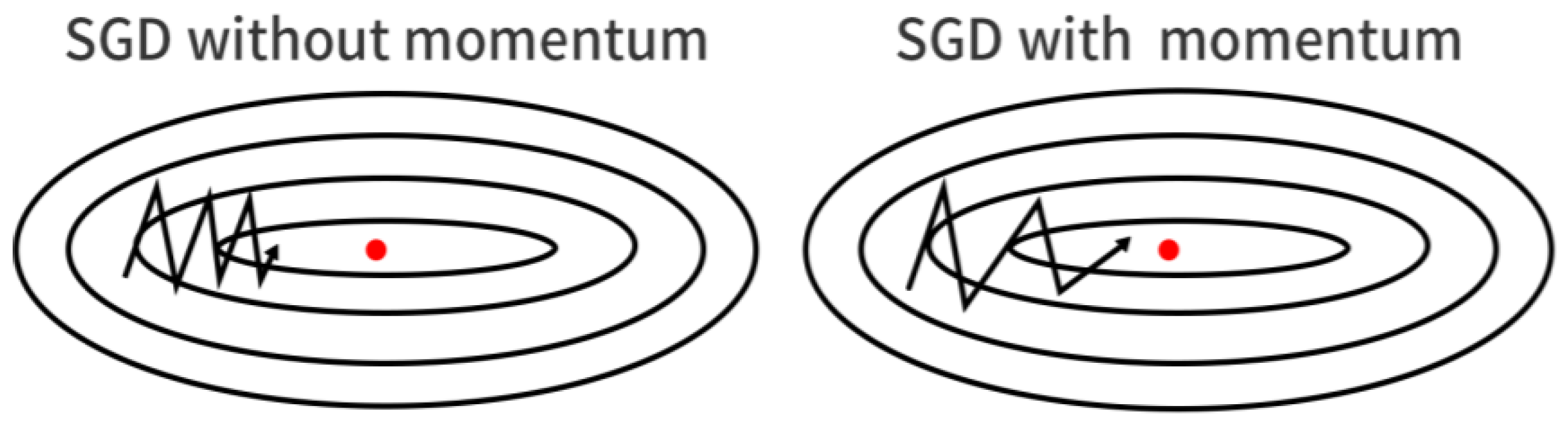
Figure 1 shows a comparison of noiseless and noisy: SGD training with a single example causes fluctuations, making iterative trajectories tortuous and slow at converging.
During backpropagation, the iterations are updated by the chain-derivative rule, which can easily lead to unstable gradients. Specifically, if the multiplier is much larger than one, the update result increases rapidly with the iterative process, and the gradient explodes. If the multiplier is much less than one, the result drops off rapidly with iterations, with gradient decay. To solve the gradient instability and avoid the gradient effect by the scale of the weight, the authors of [
35] proposed batch normalization (BN), which is related to the formulation of the activation function.
The cost of SGD is independent of sample size, allowing it to attain sublinear convergence rates in convex problems [
36]. SGD shortens the update time when dealing with multiple samples and eliminates some computational duplication, which greatly speeds up the computation. SGD can reach the fastest convergence speed in the strong convex problem [
33,
37]. When the condition of the optimization problem is weaker than the strong convex condition, SGD also has a high convergence rate. The authors of [
38] introduced an asynchronous parallel strategy that may achieve linear convergence under an essential strongly convex condition. Ref. [
39] proves that when the Polyak–Lojasiewicz condition is satisfied, the iteration point converges linearly to a stable point when it falls into its neighborhood. Moreover, the paper [
40] proves that if the PL condition is satisfied, SGD finds the global solution.
Some fundamental improvements for SGD in the optimization process [
41] include increasing speed and reducing fluctuation. Choosing a proper learning rate can improve optimization speed. A large learning rate may cause instability near the optimal solution without convergence; otherwise, it results in a slower convergence rate and time-consuming updating. Some acceleration methods take another small step in a particular direction to improve convergence speed. These fundamental improvement methods are provided in detail in the remaining sections.
3.3. Mini-Batch SGD
Mini-batch SGD capitalizes on the benefits of both the gradient descent algorithm and SGD [
33]. It is also the most common implementation of the stochastic method used in deep learning. In each iteration
t, mini-batch SGD uses randomly and uniformly sampled small-batch training data
to compute the gradient, and
is the batch size. When acquiring small batches, it is possible to do put-back sampling with or without put-back. The detailed steps are shown in Algorithm 2.
| Algorithm 2: Mini-batch SGD [33]. |
- 1:
Input: learning rate , - 2:
Initialize, . - 3:
while Stop Criteria is True do - 4:
- 5:
- 6:
- 7:
end while
|
It is easy to see that gradient descent and SGD are two special examples of mini-batch SGD [
42]. SGD trains fast but introduces noise, whereas gradient descent trains slowly but computes gradients accurately. The authors of [
43] proposed a dynamic algorithm that converges linearly to the neighborhood of the optimal point under strongly convex conditions. The authors of [
44] presented a data selection rule that is such that a linear convergence rate can be achieved when updating with mini-batch SGD under the assumption of strong convexity or strong quasi-convexity.
The work [
42] proposes an approximate optimization strategy by adding
norm penalty term in each batch training. The method solves the subproblem
where
is a subset of
and
. We provide a subtle change which uses
instead of step 4 in Algorithm 2.
However, the training result starts to deteriorate when the mini-batch’s size exceeds the threshold, and simply scaling the step size does not help. The authors of [
45] showed that the large batch size could maintain generalization performance. In addition, choosing a batch size between 2 and 32 [
46] is suitable for optimal performance. When the batch size needs to be larger, it will have better parallelism [
47].
Table 2 shows the comparison of SGD, GD and mini-batch SGD.
4. Variance-Reducing Methods
Due to the significant variance in SGD, it converges slowly. To improve this problem, many methods usually compute the full gradient after a certain period to reduce the variance. The stochastic average gradient (SAG) method [
48], which is shown in Algorithm 3, makes the convergence more stable [
49].
| Algorithm 3: Stochastic average gradient (SAG) [48]. |
- 1:
Input: learning rate , - 2:
Initialize, , . - 3:
fordo - 4:
Sample with - 5:
- 6:
- 7:
- 8:
end for
|
The SAG method needs to store the gradient of each sample. Additionally, this method only applies to smooth and convex functions, not non-convex neural networks. The authors of [
36] proposed the stochastic variance reduced gradient (SVRG), method as shown in Algorithm 4. SVRG performs gradient replacement every
m iteration, instead of computing the full gradient.
Many improved variants of variance-reduction methods have emerged, such as SDCA [
50], MISO [
51], and S2GD [
52]. A novel method SARAH combines some good properties of existing algorithms [
53]. Lots of studies improved SARAH in different aspects, resulting in algorithms such as SARAH+ and SARAH++. It is not necessary for careful choices of
m sometimes [
54]. In general, the fundamental SGD variants perform at a sublinear convergence rate. On the other hand, all of the preceding approaches, except S2GD, may achieve a linear convergence speed on severely convex problems. S2GD established linear convergence of expected values and achieved linear convergence in practice. The approaches described above can provide quick convergence to high accuracy by maintaining a large constant step size. To guarantee a linear convergence rate, they are always applied to
regularized logistic regression problems [
53,
55].
Without theoretical results, the authors of [
56] showed SVRG’s effectiveness at addressing various convex and non-convex problems. Moreover, experiments [
36,
57] showed the superior performance of SVRG to non-convex neural networks. However, applying these algorithms to the higher-cost and deeper neural nets is a critical issue that needs to be further investigated.
Table 3 shows these variance-reducing methods. Subsequent sections provide more strategies for improving the stochastic algorithms.
| Algorithm 4: Stochastic variance reduced gradient (SVRG) [36] |
- 1:
Input: learning rate , and the inner loop size m. - 2:
Initialize. - 3:
fordo - 4:
- 5:
- 6:
- 7:
for do - 8:
Sample with - 9:
- 10:
end for - 11:
Set or with t chosen uniformly at random from - 12:
end for - 13:
Output:
|
6. Adaptive Learning Rate Method
The learning rate is an essential hyperparameter for stochastic algorithms. If the learning rate is manageable, convergence may be achieved. The parameter update will be very time-consuming if the learning rate is too low. Unfortunately, the computed gradients may be sparse or may differ in magnitude in each dimension. This leads to some dimensions being very sensitive to the same learning rate. To solve this problem, an intuitive way is to choose different learning rates for each dimension. An adaptive learning rate method is proposed because it is time-consuming to select different learning rates for different dimensions manually. This section will talk about how to set an appropriate learning rate, which improves SGD and applies to the variant reduce methods and accelerate methods [
2,
74].
AdaGrad modifies the learning rate dynamically based on the gradients acquired in previous rounds. The updated formulas are as follows:
where
is a default value of 0.01 and
is the gradient.
here is a diagonal matrix where each diagonal element is the sum of the squares of the past gradients. We take an example to explain how to compute
:
Given
,
, and
, we have:
This computive fomulate of is the same in the following algorithms.
One significant advantage of AdaGrad is that it eliminates the need to adjust the learning rate manually. The approach may be used to solve sparse gradient issues. The settings update ineffectively when the algorithm no longer needs to learn anything new. Adagrad provides convex optimization sublinear convergence [
75]. Adagrad is nearly certainly asymptotically convergent in the non-convex problems [
76]. The authors of [
77] provided robust linear convergence guarantees for either highly convex or non-convex functions that meet the Polyak–Lojasiewicz (PL) assumption for most minor squares problems.
This algorithm has a small cumulative gradient and a large learning rate in the first few rounds of training. However, as the training time increases, the incremental gradient becomes larger and larger, resulting in a learning rate that tends to zero, and the weights of the model may not be updated. Adadelta [
78] and RMSProp [
79] are two extensions of Adagrad to overcome its drawback. They focus on the gradients in a window over a period instead of accumulating all historical gradients. They are inspired by the momentum method, which uses an exponential moving average to calculate the second-order cumulative momentum. The process of them:
Adadelta:
where
is the expectation. Then,
The update should have the same hypothetical units as the parameter.
RMSProp:
where
is the expectation. Then,
where
is always set to 0.9, and a good default value for the learning rate
is 0.001.
They are suitable for non-convex problems and end up oscillating around local minima.
Adaptive moment estimation (Adam) [
2] is not only computationally efficient, but also memory-efficient, and it is suitable for large-scale data problems. Adam is a combination of adaptive learning rate and momentum methods:
and
are first moment and second moment of the gradients.
where
and
.
Due to its stable process, it is suited to non-convex problems in high-dimensional space. However, Adam and RMSProp are confirmed to be divergent in some scenarios via convex cases [
80]. Considering the original schemes are convergent by using a full-batch gradient, the authors of [
81] adopted a big batch size. The sublinear convergence rates of RMSProp and ADAM are provided in the non-convex stochastic setting by setting a specific batch size. These theoretical theories are helpful in the training of machine learning and deep neural networks, such as LeNet and ResNet [
82].
Nadam combines Adam and NAG [
83]. AdaMax gives a general momentum term, which replaces
(can be seen as
norm) with
which can be regarded as the
norm.
AdamW [
84] is an improved quality method using Adam’s
regularization/weight decay, which avoids the negative effect of the interaction between
and
.
where
.
In addition, many modified versions of the above methods have been proposed, namely, AdaFTRL [
85], AdaBatch [
86], SC-MSProp [
87], AMSGRAD [
80], and Padam [
88].
Table 5 shows these adaptive learning rate methods.
7. Proximal SGD
The previous sections discussed the smooth regularizer, such as the squared
norm. For the nonsmooth regularizer, one is the subgradient method. The other is the proximal gradient method (generalized gradient descent), which has a better convergence rate than the secondary gradient. In a generalized sense, it is considered a projection. This section will introduce the case when
is the nonzero nonsmooth and the proximal operator of
is easy to compute.
where
.
The proximal operator of
p is defined as
where
u is known.
In the context of solving the indicator function
where
C is a convex set. The proximal operator is projection operator onto
C, i.e.,
. Thus, the step is
. That is, perform usual gradient update and then project back onto
C. The method is called projected gradient descent.
Table 6 shows the regularization term and the corresponding proximity operator. These regularizers always induce sparsity in the optimal solution. For machine learning, the dataset contains a lot of redundant information, and increasing the feature sparsity of the dataset can be seen as a feature selection that makes the model simpler. Unlike principal component analysis (PCA), feature selection projects to a subset of the original space rather than a new space with no interpretability.
A standard (batch) method using proximal operator is the
proximal-gradient method (PROXGD) which can be described by the following update rule for
:
where
. It differs from the gradient method in the regularization term (last one). It is equivalent to
that is
Stochastic proximal gradient descent (SPGD) is a stochastic form of PGD in which
i is randomly chosen from
at each iteration
:
It relies on the combination of a gradient step and a proximal operator. Ref. [
97] proposed a randomized stochastic projected gradient (RSPG) algorithm which also employs a general distance function to replace the Euclidean distance in Equation (
15).
The stochastic proximal gradient (SPG) algorithm has been proved a sublinear convergence rate for the expected function values in the strongly convex case, and almost sure convergence results under weaker assumptions [
98]. For the objective function
The iteration is as follows:
where
and
. It can be applied to regression problems and deconvolution problems. The authors of [
99] derived the sublinear convergence rates of SPG with mini-batches (SPG-M) under a strong convexity assumption. Stochastic splitting proximal gradient (SSPG) was presented when
was the finite-sum function, which has proved the linear convergence rate under the convex setting in [
100]. A short proof provides a proximal decentralized algorithm (PDA) to establish its linear convergence for a strongly convex objective function [
101]. A novel method called PROXQUANT [
102] has been proven to converge to stationary points under the mild smoothness assumption, which can apply to deep-learning problems, such as ResNets and LSTM. PROXGEN achieved the same convergence rate as SGD without preconditioners, which can apply to the DNNs [
103].
Many works can be studied by combining other variants of SGD. The authors of [
104] proposed the Prox-SVRG algorithm based on the well-known variance-reduction technique SVRG. It achieves a linear convergence rate under the strongly convex assumption. For the nonsmooth nonconvex case, the authors of [
105] provided ProxSVRG and ProxSAGA, which can achieve to linear convergence under PL inequality. Additionally, in a broader framework of resilient optimization, this paper [
106] analyzes the issue where
p might be nonconvex. They both compute a stochastic step and then take a proximal step. ProxSVRG+ [
107] does not need to compute the full gradient at each iteration but uses only the proximal projection in the inner loop. The mS2GD method combines S2GD with the proximal method [
108]. The authors of [
109] combined the HB method with a proximal method called iPiano, which can be used to solve image-denoising problems. In addition, Acc-Prox-SVRG [
110] and the averaged implicit SGD (AI-SGD) [
111] can achieve linear convergence under the strongly convex assumption.
It is true for many applications in machine learning and statistics, including
regularization, box-constraints, and simplex constraints, among others [
105]. On the one hand, combine the proximal methods with deep learning. On the other hand, use deep learning to learn the proximal operators.
The former case, ProxProp, closely resembles the classical backpropagation (BP) but replaces the parameter update with a proximal mapping instead of an explicit gradient descent step. The weight
w is composed of all parameters
. The last layer update is
and for all other layers,
,
which takes the proximal steps. While in principle one can take a proximal step on the loss function, for efficiency reasons, here we choose an explicit gradient step.
The latter case: For a denoising network,
where
. It yields the update equation:
The work [
112] replaces the proximal operator with the neural network
.
Table 7 shows these proximal methods.
8. High Order
The above stochastic gradient descent algorithm only utilizes the first-order gradient in each round of iteration, ignoring the second-order information. However, the second-order approach brings highly non-linear and ill-conditioned problems while calculating the inverse matrix of the Hessian matrix [
113,
114]. Meanwhile, it makes them impractical or ineffective for neural network training. This section provides technology called the sampling method, which provides a stochastic idea to the second-order method.
To solve the problem of difficult operation of the inverse matrix, many approaches calculate an approximation of the Hessian matrix and apply them to large-scale data problems [
114,
115,
116].
The Hessian-free (HF) [
114] Newton method employs second-order information, which performs a sub-optimization, avoiding the expensive cost of the inverse Hessian matrix. However, HF is not suitable for large-scale problems. The authors of [
117] proposed a sub-sampled technique that the stochastic gradient approximation (similar to mini-batch SGD):
and the stochastic Hessian approximation is:
Replace
with
to obtain the approximate solution of direction
, i.e., solving the linear system by CG:
where
is the subset of samples.
BFGS [
118,
119] and LBFGS [
120,
121] are two quasi-Newton methods. Stochastic BFGS and stochastic LBFGS [
122] are the variations in BFGS. However, the shortage of samples caused by randomness makes the situation pathological and has an impact on the convergence outcomes. As illustrated in Algorithm 5, a regularized stochastic BFGS (RES) technique [
123] is presented to facilitate the aforementioned numerical conditions. Under the convex assumption, it obtains a linearly predicted convergence rate. However, it still has limitations on non-convex problems. SdREG-LBFGS overcomes the shortcomings, making it applicable to non-convex problems, and converges to a stable point almost everywhere [
124]. However, using two gradient estimates leads to irrationality in the inverse Hessian approximations.
| Algorithm 5: Regularized stochastic BFGS (RES) [123]. |
- 1:
Input:, Hessian approximation - 2:
fordo - 3:
Compute - 4:
Update - 5:
Compute - 6:
Compute - 7:
Compute - 8:
Update Hessian approximation matrix: - 9:
- 10:
end for - 11:
Output:
|
The stochastic quasi-Newton (SQN) method avoids the mentioned drawbacks of quasi-Newton method for large datasets and globally convergent for strongly convex objective functions [
125]. The detailed procedure of SQN method is shown in Algorithm 6. The two-loop recursion is used to calculate the matrix-vector product
[
126].
| Algorithm 6: SQN framework [125]. |
- 1:
Input:, , m, learning rate - 2:
fordo - 3:
utilize Two-Loop Recursion [ 126] to calculate . - 4:
- 5:
if then - 6:
Compute - 7:
Compute - 8:
Add a new displacement pair to V - 9:
end if - 10:
if then - 11:
Remove the oldest added update pair from V. - 12:
end if - 13:
end for - 14:
Output:
|
Many works have achieved good results in stochastic quasi-Newton. We described combined algorithms in the previous sections. The authors of [
127] combined the L-BFGS and SVRG, which can achieve a linear convergence rate under strongly convex and smooth functions. The authors of [
128] proposed the limited-memory stochastic block BFGS, which combines the ideas of BFGS and variance reduction. For nonconvex problems, the authors of [
129] proposed SQN, and it converges almost everywhere to a stationary point. The stochastic proposed Newton method can be applied to machine-learning and deep-learning problems, such as the linear least-squares problem [
130].
There remains much to be explored for second-order methods in machine-learning applications. The works [
4,
131] demonstrate that some performance enhancements are possible, but the full potential of second-order approaches is unknown.
Table 8 shows these high order methods. Additionally, the convergence of all of the mentioned stochastic methods is summarized in
Table 9.







{kind=link}
{kind=link}
{kind=link}