
Single Earthquake Bond Pricing Framework with Double Trigger Parameters Based on Multi Regional Seismic Information

Abstract
:1. Introduction
2. The Literature Review
3. Framework for Single Earthquake Bond Pricing
3.1. Division of Coverage Area Based on Regional Seismic Information
- (1)
- Clustering subregions that have the same EDRI categories (1 = low, 2 = medium, and 3 = high). The notation for clustering results is .
- (2)
- Clustering subregions for each member of the using the K-Means and K-Medoid algorithms. The random variables used in clustering are the average magnitude and depth of earthquakes, and the average distance between earthquake occurrences within each subregion on . The results of clustering are specific areas with assumptions:
3.1.1. The Distance between Earthquake Occurrences
3.1.2. Elbow Method
| Algorithm 1. Pseudo code of SSE |
| Input: data_seismic = datasets.load_data(), X = data_seismic Output:
|
3.1.3. K-Means Algorithm
| Algorithm 2. Pseudo code of K-Means Algorithm |
| Input: data_seismic = datasets.load_data(), X = data_seismic, = optimal number of clusters Output:
for , j in a range
|
3.1.4. K-Medoids Algorithm
| Algorithm 3. Pseudo code K-medoids algorithm |
|
Input: data_seismic = datasets.load_data(), X = data_seismic, = optimal number of clusters Output:
for , j in a range
for , j in a range
|
3.2. The Earthquake Bond Trigger Mechanism
- (1)
- The maturity time of the SEB is T.
- (2)
- , where represents the largest earthquake that has occurred within each zone at time , while is the earthquake depth, which corresponds to M.
- (3)
- If in [0, T], then the bondholders will receive all the face amount of SEB (FV) at maturity.
- (4)
- If , then the bondholder will receive at maturity.
- (5)
- If , then the bondholder will receive at maturity.
- (6)
- If , then the bondholder will receive at maturity.
- (7)
- If , then the bondholder will receive at maturity.
- (8)
- If , then the bondholder will receive at maturity.
- (9)
- If , then the bondholder will receive at maturity.
- (10)
- If , then the bondholder will receive at maturity.
- (11)
- If , then the bondholder will receive at maturity.
- (12)
- If , then the bondholder will receive at maturity.
- (13)
- If , the bondholder loses all the face amount of the cat bond at maturity.
- (14)
- The value of is constant.
3.3. Selection of Earthquake Magnitude and Earthquake Data
3.4. Earthquake Distribution Model for Magnitude and Depth
3.4.1. Generalized Pareto Distribution
3.4.2. Copula
- (1)
- dan
- (2)
- with and
3.5. Predict Interest Rates and Coupon Rates
- (1)
- Defines the universe set () based on the observed time series data intervals, with the rule , and are two positive numbers.
- (2)
- Partition the universe set into intervals . Meanwhile, the number of intervals will be equal to the number of linguistic variables .
- (3)
- Construct the fuzzy set associated with the intervals in Step 2 and apply the triangular membership function rules for each interval in each built fuzzy set.
- (4)
- Defuzzification of the observed data and form fuzzy logical relationships (FLR) using the rule: If is fuzzy production in year and is fuzzy production in year , then FLR is denoted as . At this stage, is called the current state, and is the next state.
- (5)
- Forecasting
| Algorithm 4. Rules of forecasting |
| (End of time series data) Obtained FLR for year k to Compute Initialization and If and Then and If and Then and If and Then and If and Then and If and Then and If and Then and If and Then and If and Then and If and Then and If and Then and If and Then and If and Then and next k |
3.6. Modeling the Calculation of the Expected Coupon Amount, the Expected Interest Rate Values, and the Expected Face Amount
3.7. Modeling the Calculation of the Expected Face Amount of SEB
3.8. Single Earthquake Bond Pricing Model
4. Simulation
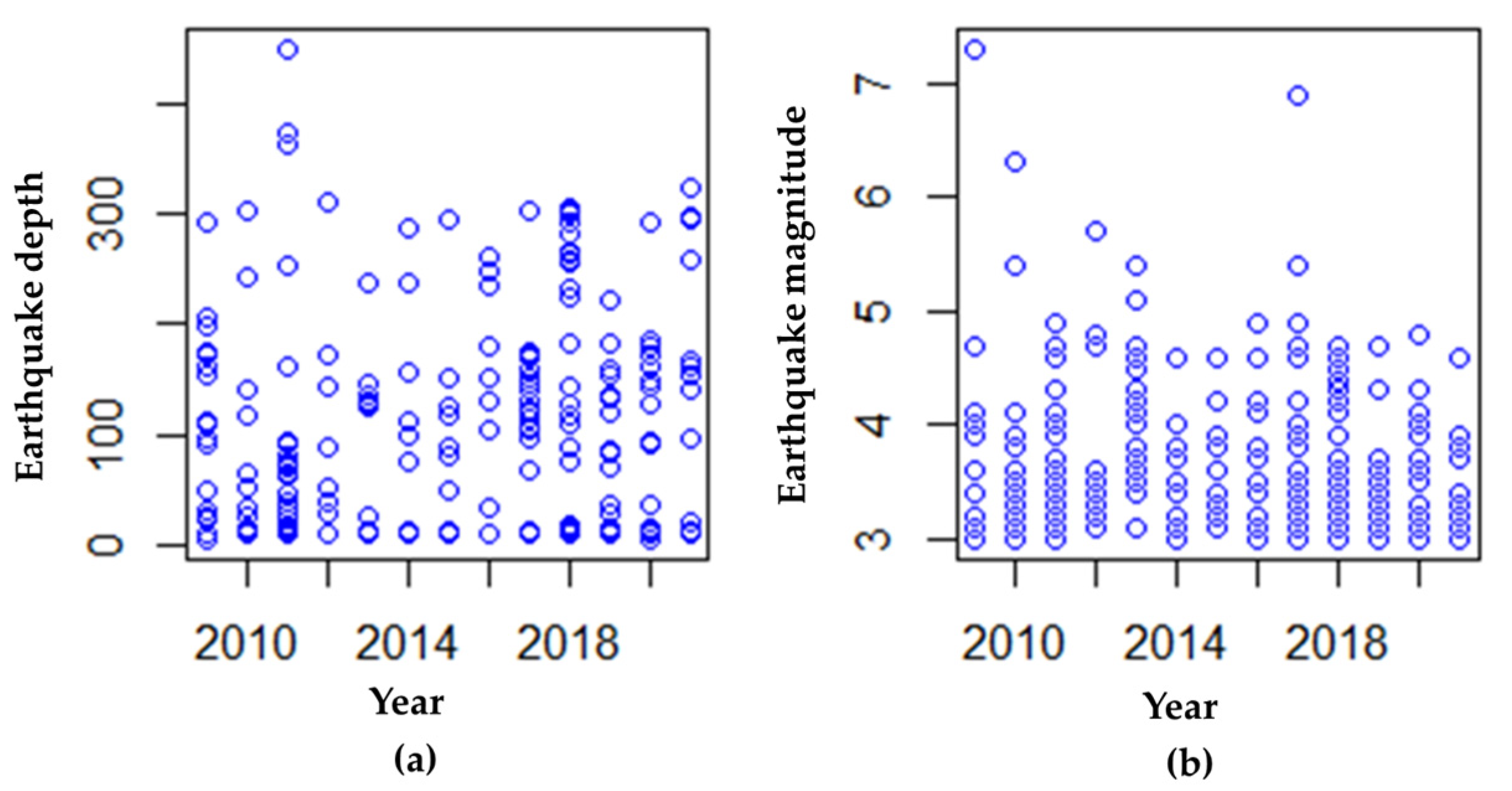
4.1. Data Description
- (1)
- Earthquake data for West Java Province, Indonesia, from 2009 to 2021 was obtained from the Meteorology, Climatology, and Geophysics Agency (BMKG).
- (2)
- EDRI data for the Province of West Java, Indonesia, from 2009 to 2021 was obtained from the National Disaster Management Agency (BNPB).
- (3)
- BI interest rate data from 2009 to 2021 was obtained from Bank Indonesia.
- (4)
- LIBOR interest rate data from 2009 to 2021 was obtained from http://www.fedprimerate.com (accessed on 10 October 2022).
4.2. Division Zones of West Java Province Based on Seismic Information
4.3. Clustering Based on EDRI Categories in West Java Province
4.3.1. Calculation of Average Earthquake Magnitude, Earthquake Depth, and Earthquake Distance between Events
4.3.2. Clustering Type I
4.3.3. Clustering Type II
4.4. Simulation of Face Amount Payoff Function and Coupon Payoff Function
4.5. Selection of Magnitude and Depth Earthquakes Simulation
4.6. Magnitude and Depth of Earthquakes Distribution Model Simulation
4.6.1. Earthquake Magnitude Distribution Simulation
4.6.2. Simulation the Archimedean Copula Distribution Function for Earthquake Magnitude and Earthquake Depth
4.7. Interest Rates and Coupons Prediction
4.7.1. Interest Rate Predictions
4.7.2. The Coupon Rate Prediction
4.8. Simulation of the Expected Coupon Amount, Interest Rates, and Face Amount of SEB Price
4.8.1. Simulation of the Expected Coupon Amount and Interest Rate
4.8.2. Simulation of the Calculation of Face Amount
4.9. Simulating SEB Price Based on Seismic Information in Cluster Types I and II
5. Discussion
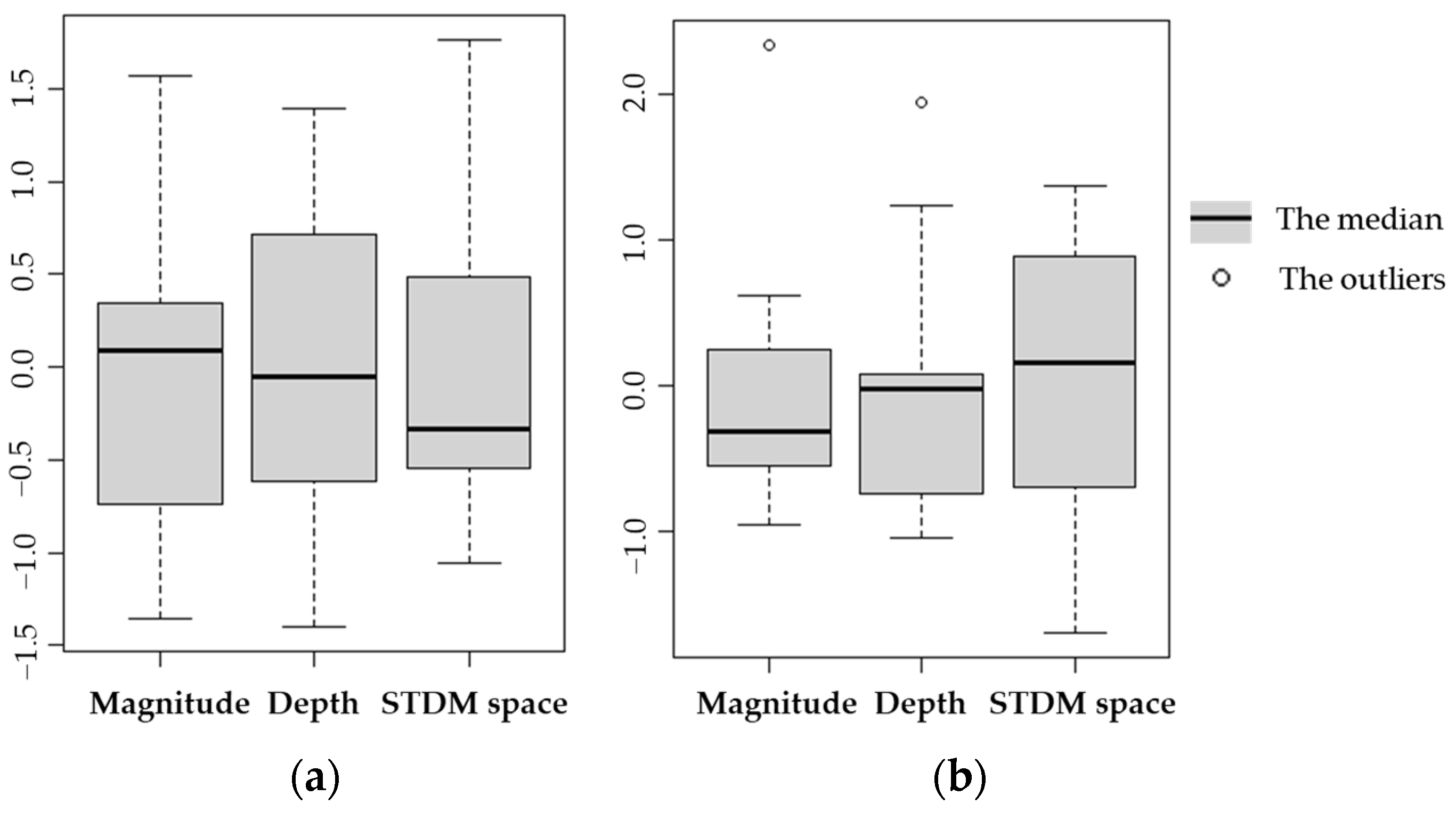
5.1. Analysis of b Values in the Gutenberg-Richter Equation, Fractals, and Distances between Earthquake Events in West Java Province
5.2. Single Earthquake Bond Price Analysis Based on on Seismic Information in Cluster Types I and II
5.3. Analysis of SEB Prices Based on the Earthquake Return Period
5.4. Analysis of the Relationship between Interest Rates and SEB Prices
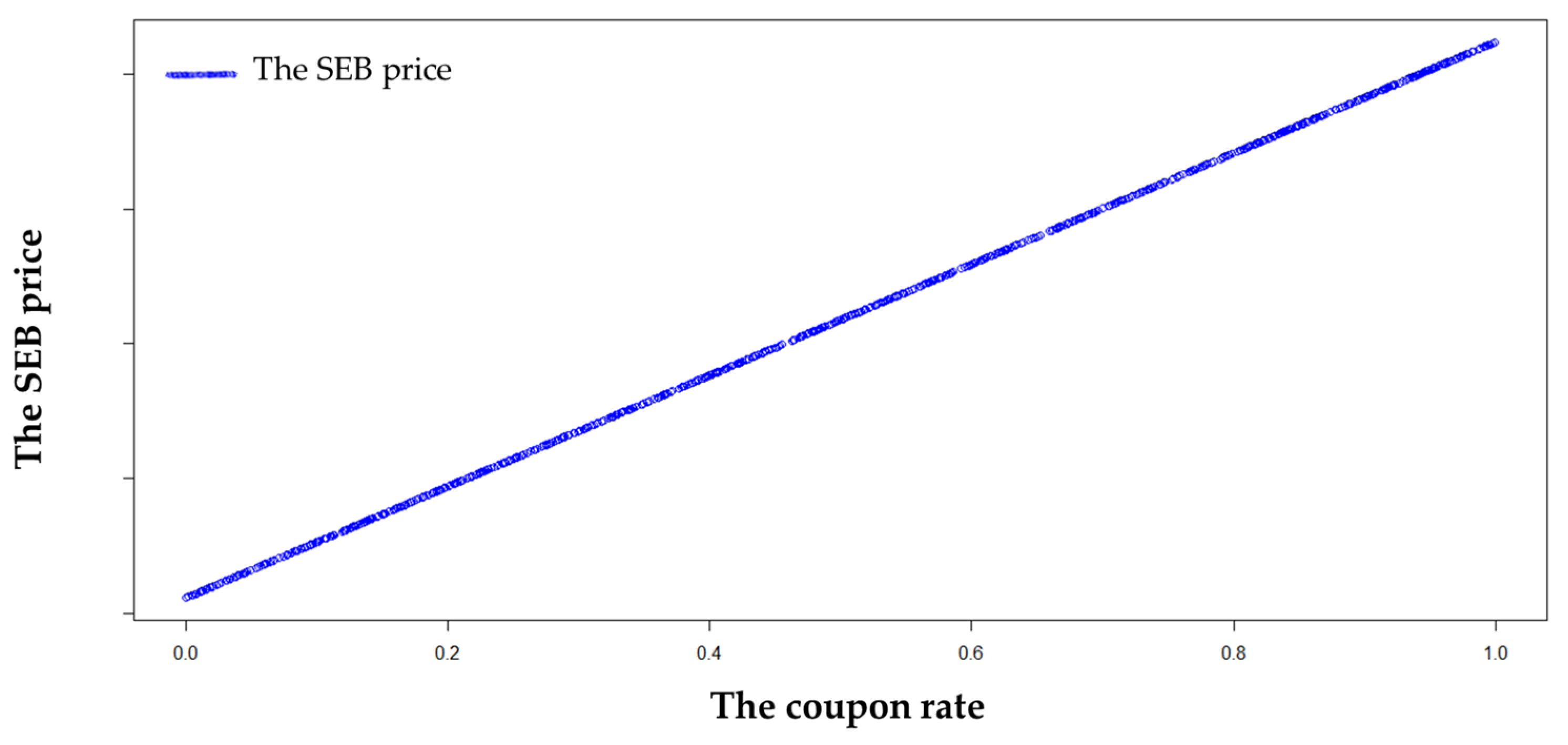
5.5. Analysis of the Relationship between Coupon Rates and SEB Prices
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| the area of coverage. | |
| the number of subregions in W. | |
| The number of zones. | |
| the category of EDRI. | |
| the -th subregion in . | |
| the cluster result of EDRI categories. | |
| the subregion in | |
| the subregion in zone . | |
| the earthquake event at time . | |
| the earthquake event at time . | |
| the time difference between two earthquake events . | |
| the haversine distance between two earthquake events. | |
| Gutenberg Richer parameter. | |
| fractal. | |
| the earthquake depth of the -th earthquake event. | |
| the earthquake magnitude of the -th earthquake event. | |
| the minimum threshold value of the observed earthquake magnitude. | |
| the STDM distance. | |
| the outcome of rescaling | |
| the outcome of rescaling . | |
| the outcome of rescaling . | |
| the number of clusters. | |
| the number of the variable random. | |
| the number of the data. | |
| the optimal number of cluster | |
| the data of observation for the -th data and -th variable. | |
| the center of cluster . | |
| the square of the distance of to . | |
| the distance of to | |
| the sum of square of cluster | |
| the data of observation, which member | |
| the number of cluster | |
| the medoids of of cluster | |
| cost of cluster | |
| the face amount of SEB. | |
| the maturity time. | |
| the -th face amount payoff function. | |
| the proportion of -th face amount. | |
| the payoff function of face amount. | |
| the value prediction of interest rate at time . | |
| the value prediction of coupon rate at time | |
| the extra premium to bear risk of earthquake. | |
| the largest earthquake that has occurred in each zone at the interval . | |
| the earthquake depth in . | |
| the year before maturity. | |
| the coupon payoff function at time t. | |
| the coupon amount at time . | |
| the return period in zone | |
| the earthquake magnitude return level at period in zone . | |
| the maximum magnitude earthquake return level for in coverage area . | |
| the number of the earthquake occurrence. | |
| the number of zones. | |
| the set of independent and identically random variables representing the earthquake’s magnitude in zone . | |
| the set of earthquake magnitude, with a POT as an outcome. | |
| the set of earthquake depth, which is correspond to . | |
| the set of earthquake depth, which is correspond to . | |
| the cumulative distribution function of earthquake magnitude in the -th zone, with a POT as an outcome. | |
| the dependences cumulative distribution function of earthquake magnitude and earthquake depth, with a POT as an outcome. | |
| the GPD location parameter in zone . | |
| the GPD scale parameter in zone . | |
| the GPD shape parameter in zone . | |
| the cumulative distribution function of GPD. | |
| the value of earthquake magnitude variable in zone , | |
| the estimation of location parameter in zone . | |
| the estimation of scale parameter in zone . | |
| the estimation of shape parameter in zone . | |
| the copula function of earthquake magnitude variable and earthquake depth variable. | |
| the cumulative distribution function of | |
| the cumulative distribution function of | |
| the parameter of AC distribution in zone . | |
| the Kendall’s tau correlation. | |
| the Debye functions. | |
| the likelihood function of a copula in zone . | |
| the earthquake event type where . | |
| the random variable that represent the occurrence an earthquake in zone . | |
| the probability of earthquake occurs in zone . | |
| the probability of earthquake of type occurs where the earthquake event occurs in the z. | |
| the number of earthquake event occurs in zone at . | |
| the rate of earthquake event in the . | |
| the rate of earthquake event in the at time . | |
| the number of earthquakes event | |
| the number of earthquake event type 1 at interval year . | |
| the number of earthquake event type 2 at interval year . | |
| the total probability of earthquake type i occurs. | |
| the first time of earthquake type 1 occurs. | |
| the probability of first-time earthquake type 1 occurs. | |
| the expectation of coupon amount. | |
| the accumulation of coupon amount at time . | |
| the expectation of interest rate at time . | |
| the accumulation amount at time . | |
| the earthquake type , where . | |
| the total probability type . | |
| the probability earthquake type occurs where known the earthquake occurs in . | |
| the expectation of face amount. | |
| the single earthquake bond price. | |
| the universe discourses. | |
| the minimum value of actual data. | |
| the aximum value of actual data. | |
| the set of intervals. | |
| the set of linguistic variables. | |
| the fuzzy production in year . | |
| the fuzzy production in year . | |
| the supremum of . | |
| the lower limit of . | |
| the upper limit of . | |
| the length of the . | |
| the middle value of the . | |
| the result of forecasting. |
References
- Burnecki, K.; Giuricich, M.N.; Palmowski, Z. Valuation of Contingent Convertible Catastrophe Bonds—The Case for Equity Conversion. Insur. Math. Econ. 2019, 88, 238–254. [Google Scholar] [CrossRef]
- UNDRR. Global Natural Disaster Assessment Report 2019. 2020. Available online: https://www.preventionweb.net/files/73363_2019globalnaturaldisasterassessment.pdf (accessed on 4 May 2022).
- Hofer, L.; Zanini, M.A.; Gardoni, P. Risk-Based Catastrophe Bond Design for a Spatially Distributed Portfolio. Struct. Saf. 2019, 83, 101908. [Google Scholar] [CrossRef]
- Sukono; Juahir, H.; Ibrahim, R.A.; Saputra, M.P.A.; Hidayat, Y.; Prihanto, I.G. Application of Compound Poisson Process in Pricing Catastrophe Bonds: A Systematic Literature Review. Mathematics 2022, 10, 2668. [Google Scholar] [CrossRef]
- Mistry, H.K.; Lombardi, D. Pricing Risk-Based Catastrophe Bonds for Earthquakes at an Urban Scale. Sci. Rep. 2022, 12, 9729. [Google Scholar] [CrossRef]
- Franco, G. Minimization of Trigger Error in Cat-In-a-Box Parametric Earthquake Catastrophe Bonds with an Application to Costa Rica. Earthq. Spectra 2010, 26, 983–998. [Google Scholar] [CrossRef]
- Tang, Q.; Yuan, Z. Cat Bond Pricing under a Product Probability Measure with Pot Risk Characterization. ASTIN Bull. 2019, 49, 457–490. [Google Scholar] [CrossRef] [Green Version]
- Grossi, P.; Kunreuther, H. Catastrophe Modeling: A New Approach to Managing Risk; Springer Science + Business Media, Inc.: Boston, MA, USA, 2005. [Google Scholar]
- Goda, K.; Franco, G.; Song, J.; Radu, A. Parametric Catastrophe Bonds for Tsunamis: Cat-in-a-Box Trigger and Intensity-Based Index Trigger Methods. Earthq. Spectra 2019, 55, 113–136. [Google Scholar] [CrossRef]
- Mamon, R. Three Ways to Solve for Bond Prices in the Vasicek Model. J. Appl. Math. Decis. Sci. 2004, 8, 131526. [Google Scholar] [CrossRef]
- Samimia, O.; Mehrdoust, F. Vasicek Interest Rate Model under Lévy Process and Pricing Bond Option. Commun. Stat. Simul. Comput. 2022, in press. [Google Scholar] [CrossRef]
- Chao, W. Valuing Multirisk Catastrophe Reinsurance Based on the Cox-Ingersoll-Ross (CIR) Model. Discret. Dyn. Nat. Soc. 2021, 2021, 4472–4484. [Google Scholar] [CrossRef]
- Chao, W.; Zou, H. Multiple-Event Catastrophe Bond Pricing Based on CIR-Copula-POT Model. Discret. Dyn. Nat. Soc. 2018, 2018, 5068480. [Google Scholar] [CrossRef]
- Zimbidis, A.A.; Frangos, N.E.; Pantelous, A.A. Modeling Earthquake Risk via Extreme Value Theory and Pricing the Respective Catastrophe Bonds. ASTIN Bull. 2007, 37, 163–183. [Google Scholar] [CrossRef] [Green Version]
- Shao, J.; Pantelous, A.; Papaioannou, A.D. Catastrophe Risk Bonds with Applications to Earthquakes. Eur. Actuar. J. 2015, 1, 113–138. [Google Scholar] [CrossRef]
- Gunardi; Setiawan, E.P. Valuation of Indonesian Catastrophic Earthquake Bonds with Generalized Extreme Value (GEV) Distribution and Cox-Ingersoll-Ross (CIR) Interest Rate Model. AIP Conf. Proc. 2015, 1692, 020024. [Google Scholar] [CrossRef]
- Orlando, G.; Mininni, R.M.; Bufalo, M. Interest rates calibration with a CIR model. J. Risk Financ. 2019, 20, 370–387. [Google Scholar] [CrossRef]
- Burnecki, K.; Kukla, G. Pricing of Zero-Coupon and Coupon Cat Bonds. Appl. Math. 2003, 30, 315–324. [Google Scholar] [CrossRef]
- Ma, Z.G.; Ma, C.Q. Pricing Catastrophe Risk Bonds: A Mixed Approximation Method. Insur. Math. Econ. 2013, 52, 243–254. [Google Scholar] [CrossRef]
- Ma, Z.; Ma, C.; Xiao, S. Pricing Zero-Coupon Catastrophe Bonds using EVT with Doubly Stochastic Poisson Arrivals. Discret. Dyn. Nat. Soc. 2017, 2017, 3279647. [Google Scholar] [CrossRef] [Green Version]
- Deng, G.; Liu, S.; Li, L.; Deng, C.; Yu, W. Research on the Pricing of Global Drought Catastrophe Bonds. Math. Probl. Eng. 2020, 2020, 3898191. [Google Scholar] [CrossRef]
- Liu, J.; Xiao, J.; Yan, L.; Wen, F. Valuing Catastrophe Bonds Involving Credit Risks. Math. Probl. Eng. 2014, 2014, 563086. [Google Scholar] [CrossRef] [Green Version]
- Härdle, W.K.; Cabrera, B.L. Calibrating CAT bonds for Mexican earthquakes. J. Risk Insur. 2010, 77, 625–650. [Google Scholar] [CrossRef] [Green Version]
- Wei, L.; Liu, L.; Hou, J. Pricing hybrid-triggered catastrophe bonds based on copula-EVT model. Quant. Financ. Econ. 2022, 6, 223–243. [Google Scholar] [CrossRef]
- Braun, A.; Kousky, C. Catastrophe Bond; Wharton Risk Centre Primer; Wharton University of Pennsylvania, Risk Management and Decision Processes Center: Philadelphia, PA, USA, 2021; pp. 1–10. [Google Scholar]
- Anggraeni, W.; Supian, S.; Sukono; Halim, N.B.A. Earthquake Catastrophe Bond Pricing Using Extreme Value Theory: A Mini-Review Approach. Mathematics 2022, 10, 4196. [Google Scholar] [CrossRef]
- Selim, K.S.; Elanany, G.A. A new method for short multivariate fuzzy time series based on genetic algorithm and fuzzy clustering. Adv. Fuzzy Syst. 2013, 2013, 494239. [Google Scholar] [CrossRef] [Green Version]
- Ansari, E.M.; Caldera, H.J.; Heshami, S.; Moshahedi, N.; Wirasinghe, S.C. The Severity of Earthquake Events—Statistical Analysis and Classification. Int. J. Urban Sci. 2017, 20, 4–24. [Google Scholar] [CrossRef]
- Asef, M.R. Modelling the Elements of Country Vulnerability to Earthquake Disasters. Disasters 2008, 32, 480–498. [Google Scholar] [CrossRef] [PubMed]
- Ansari, K.; Bae, T.S. Clustering Analysis of Seismicity in The Space–Time–Depth–Magnitude Domain Preceding the 2016 Kumamoto Earthquake, Southwestern Japan. Int. J. Earth Sci. 2021, 110, 253–261. [Google Scholar] [CrossRef]
- Murnane, R.J.; Daniell, J.E.; Schafer, A.M.; Ward, P.J.; Winsemius, H.C.; Simpson, A.; Tijssen, A.; Toro, J. Future Scenarios for Earthquake and Flood Risk in Eastern Europe and Central Asia. Earth’s Future 2017, 5, 693–714. [Google Scholar] [CrossRef]
- Murnane, R.; Simpson, A.; Jongman, B. Understanding Risk: What Makes a Risk Assessment Successful. Int. J. Disaster Resil. Built Environ. 2016, 7, 186–200. [Google Scholar] [CrossRef]
- Yuan, C.; Yang, H. Research on K-Value Selection Method of K-Means Clustering Algorithm. J. Multidiscip. Sci. J. 2019, 2, 226–235. [Google Scholar] [CrossRef] [Green Version]
- Bai, L.; Cheng, X.; Liang, J.; Shen, H.; Guo, Y. Fast density clustering strategies based on the k-means algorithm. Pattern Recognit. 2017, 71, 375–386. [Google Scholar] [CrossRef]
- Arora, P.; Deepali; Varshney, S. Analysis of K-Means and K-Medoids Algorithm for Big Data. Phys. Procedia 2015, 78, 507–512. [Google Scholar] [CrossRef] [Green Version]
- Vercelliss, C. Business Intelligence: Data Mining and Optimization for Decision Making; John Wiley & Sons: Milan, Italy, 2009. [Google Scholar] [CrossRef]
- Cummins, J.D. CAT bonds and other risk-linked securities: State of the Market and Recent Developments. Risk Manag. Insur. Rev. 2008, 11, 23–47. [Google Scholar] [CrossRef]
- Vakili, W.; Ghaffari-Hadigheh, A. CAT Bond Pricing in Uncertain Environment. Iran. J. Manag. Stud. 2022, 15, 347–364. [Google Scholar] [CrossRef]
- Marvi, M.T.; Linders, D. Decomposition of Natural Catastrophe Risks: Insurability using Parametric CAT Bonds. Risks 2021, 9, 215. [Google Scholar] [CrossRef]
- Shao, J.; Papaioannou, A.D.; Pantelous, A.A. Pricing and Simulating Catastrophe Risk Bonds in a Markov-Dependent Environment. Appl. Math. Comput. 2017, 309, 68–84. [Google Scholar] [CrossRef] [Green Version]
- Zhao, Y.; Yu, M.T. Predicting catastrophe risk: Evidence from Catastrophe Bond Markets. J. Bank. Financ. 2020, 121, 105982. [Google Scholar] [CrossRef]
- Hofer, L.; Gardoni, P.; Zanini, M.A. Risk-Based CAT Bond Pricing Considering Parameter Uncertainties. Sustain. Resil. Infrastruct. 2021, 6, 315–329. [Google Scholar] [CrossRef]
- Cox, S.H.; Pedersen, H.W. Catastrophe Risk Bonds. N. Am. Actuar. J. 2000, 4, 56–82. [Google Scholar] [CrossRef]
- Patil, V.; Atrey, P.K. GeoSecure-R: Secure Computation of Geographical Distance using Region-anonymized GPS Data. In Proceedings of the 2020 IEEE Sixth International Conference on Multimedia Big Data (BigMM), New Delhi, India, 24–26 September 2020; pp. 28–36. [Google Scholar] [CrossRef]
- Aki, K. Maximum Likelihood Estimate of b in the formula Log N=a-bM and its Confidence Limits. Bull. Earthq. Res. Inst. 1965, 43, 237–239. [Google Scholar]
- Utsu, T. A Statistical Significance Test of The Difference in b-Value between Two Earthquake Groups. J. Phys. Earth. 1966, 14, 37–40. [Google Scholar] [CrossRef]
- Aki, K. A Probabilistic Synthesis of Precursory Phenomena. Maurice Ewing Ser. 1981, 4, 566–574. [Google Scholar]
- Bataineh, K.M.; Naji, M.; Saqer, M. A Comparison Study between Various Fuzzy Clustering Algorithms. Jordan J. Mech. Ind. Eng. 2011, 5, 335–343. [Google Scholar]
- Syakur, M.A.; Khotimah, B.K.; Rochman, E.M.S.; Satoto, B.D. Integration K-Means Clustering Method and Elbow Method for Identification of the Best Customer Profile Cluster. IOP Conf. Ser. Mater. Sci. Eng. 2018, 336, 012017. [Google Scholar] [CrossRef] [Green Version]
- Weatherill, G.; Burton, P.W. Delineation of Shallow Seismic Source Zones Using K-means Cluster Analysis, with application to the Aegean region. Geophys. J. Int. 2009, 176, 565–588. [Google Scholar] [CrossRef] [Green Version]
- Echaust, K.; Just, M. Value at Risk Estimation Using The Garch-evt Approach with Optimal Tail Selection. Mathematics 2020, 8, 114. [Google Scholar] [CrossRef] [Green Version]
- Bermudez, D.Z.P.; Kotz, S. PARAMETER Estimation of the Generalized Pareto Distribution—Part I. J. Stat. Plan. Inference 2010, 140, 1353–1373. [Google Scholar] [CrossRef]
- Chen, W.; Yang, R.; Yao, D.; Long, C. Pareto Parameters Estimation Using Moving Extremes Ranked Set Sampling. Stat. Pap. 2019, 62, 1195–1211. [Google Scholar] [CrossRef]
- Martins, A.L.A.; Liska, G.R.; Beijo, L.A.; de Menezes, F.S.; Cirillo, M.A. Generalized Pareto Distribution Applied to the Analysis of Maximum Rainfall Events in Uruguaiana, RS, Brazil. SN Appl. Sci. 2020, 2, 1479. [Google Scholar] [CrossRef]
- Ghosh, I.; Watts, D.; Chakraborty, S. Modeling Bivariate Dependency in Insurance Data via Copula: A Brief Study. J. Risk Financ. Manag. 2022, 15, 329. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, P.; Wang, D.; Zhang, Y.; Ji, R.; Cai, F. Identification and Risk Characteristics of Agricultural Drought Disaster Events Based on the Copula Function in Northeast China. Atmosphere 2022, 13, 1234. [Google Scholar] [CrossRef]
- Dogan, M.; Karakas, A.M. Archimedean Copula Parameter Estimation with Kendall Distribution Function. J. Inst. Sci. Technol. 2017, 7, 187–198. [Google Scholar] [CrossRef]
- Shing, S.R. A simple method of forecasting based on fuzzy time series. Appl. Math. Comput. 2007, 186, 330–339. [Google Scholar] [CrossRef]
- Singh, S.R. A computational method of forecasting based on fuzzy time series. Math. Comput. Simul. 2008, 79, 539–554. [Google Scholar] [CrossRef]
- Zangeneh, S.Z.; Little, R.J.A. Bayesian inference for the finite population total from a heteroscedastic probability proportional to size sample. J. Surv. Stat. Methodol. 2015, 3, 162–192. [Google Scholar] [CrossRef]
- Ross, S.M. Introduction to Probability Models, 10th ed.; Elsevier: Berkeley, CA, USA, 2010. [Google Scholar] [CrossRef]
- DeMets, C.; Gordon, R.G.; Argus, D.F. Geologically current plate motions. Geophys. J. Int. 2010, 81, 1–80. [Google Scholar] [CrossRef] [Green Version]
- Supendi, P.; Nugraha, A.D.; Puspito, N.T.; Widiyantoro, S.; Daryono, D. Identification of active faults in West Java, Indonesia, based on earthquake hypocenter determination, relocation, and focal mechanism analysis. Geosci. Lett. 2018, 5, 31. [Google Scholar] [CrossRef]
- Asuransi Maypark, P.T. The West Sumatra and the West Java Earthquake of 30 September 2009 and 2 September 2009 Board of Advisors Board of Editors. Waspada 2010, 13. Available online: https://www.maipark.com/assets/uploads/bulletin_waspada/13-maipark-waspada-feb-10-english.pdf (accessed on 1 November 2022).
- Republik Indonesia. Nota Keuangan dan Anggaran Pendapatan Belanja Negara Tahun Anggaran 2010. 2010. Available online: https://anggaran.kemenkeu.go.id/assets/FTPPortal/Peraturan/NK%20UU%20APBN%20Lapsem/NK%20APBN%202010.pdf (accessed on 1 November 2022).
- Mellado, J.L.A.; Esteban, A.M.; Álvarez, F.M. Mapping of Seismic Parameters of the IBERIAN Peninsula by Means of a Geographic Information System. Cent. Eur. J. Oper. Res. 2018, 26, 739–758. [Google Scholar] [CrossRef]
- Mogi, K. Magnitude-Frequency Relation for Elastic Shocks Accompanying Fractures of Various Materials and Some Related Problems in Earthquakes (2nd Paper). Bull. Earthq. Res. Inst. 1962, 40, 831–853. [Google Scholar]
- Kamer, Y.; Hiemer, S. Data-Driven Spatial b Value Estimation with Applications to California seismicity: To b or not to b. J. Geophys. Solid Earth 2015, 120, 2191–5214. [Google Scholar] [CrossRef]
- Singh, C.; Singh, S. Imaging b-Value Variation Beneath the Pamir-Hindu Kush region. Bull. Seismol. Soc. Am. 2015, 105, 808–815. [Google Scholar] [CrossRef]
- Chan, C.H.; Wu, Y.M.; Tseng, T.L.; Lin, T.L.; Chen, C.C. Spatial and Temporal Evolution of b-Values before Large Earthquakes in Taiwan. Tectonophysics 2012, 532–535, 215–222. [Google Scholar] [CrossRef] [Green Version]
- Scholz, C.H. The frequency-magnitude relation of microfracturing in rock and its relation to earthquakes. Bull. Seismol. Soc. Am. 1968, 58, 399–415. [Google Scholar] [CrossRef]
- Wyss, M. Towards a Physical Understanding of the Earthquake Frequency Distribution. Geophys. J. R. Astron. Soc. 1973, 31, 341–359. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, K.; Rani, S.; Srinagesh, D. A review of b-Value Imaging and Fractal Dimension Studies in the Andaman Sumatra subduction. Nat. Hazards 2015, 77, S97–S107. [Google Scholar] [CrossRef]
- Ozer, N.; Ceylan, S. Fractal Properties and Simulation of Micro-Seismicity for Seismic Hazard Analysis: A Comparison of North Anatolian and San Andreas Fault Zones. Res. Geophys. 2012, 2, e1. [Google Scholar] [CrossRef] [Green Version]
- Tosi, P. Seismogenic Structure Behaviour Revealed by Spatial Clustering of Seismicity in the Umbria-Marche Region (Central Italy). Ann. Geophys. 2021, 41, 215–224. [Google Scholar] [CrossRef]
- Ibrahim, R.A.; Sukono; Napitupulu, H. Multiple-Trigger Catastrophe Bond Pricing Model and Its Simulation Using Numerical Methods. Mathematics 2022, 10, 1363. [Google Scholar] [CrossRef]
- Sukono; Ibrahim, R.A.; Saputra, M.P.A.; Hidayat, Y.; Juahir, H.; Prihanto, I.G.; Halim, N.B.A. Modeling Multiple-Event Catastrophe Bond Prices Involving the Trigger Event Correlation, Interest, and Inflation Rates. Mathematics 2022, 10, 4685. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Magnitude Level (SR) | Category | Effect |
|---|---|---|
| 1.0–2.9 | Micro | Generally not felt by people, though recorded on local instrument |
| 3.0–3.9 | Minor | Felt by many people; no damage |
| 4.0–4.9 | Light | Felt by all; minor breakage of objects |
| 5.0–5.9 | Moderate | Some damage to weak structures |
| 6.0–6.9 | Strong | Moderate damage in populated areas |
| 7.0–7.9 | Major | Serious damage over large areas; loss of life |
| 8 | great | Severe destruction and loss of life over large areas |
| Copula Class | Description | |||
|---|---|---|---|---|
| Clayton | ||||
| Frank | ||||
| Gumbel |
| EDRI Category | Member of Cluster |
|---|---|
| High | Banjar City, Tasikmalaya City, Sukabumi Regency, Bekasi City, Bandung Regency, Purwakarta Regency, Tasikmalaya Regency, Sukabumi City, Cirebon City, Bogor Regency, Depok City, West Bandung Regency, Cianjur Regency, Garut Regency, and Bandung City |
| Medium | Sumedang Regency, Kuningan Regency, Cimahi City, Majalengka Regency, Ciamis Regency, Subang Regency, Pangandaran Regency, Karawang Regency, Bogor City, Bekasi Regency, and Cirebon Regency |
| Low | Indramayu Regency |
| Subregion | ||||||||
|---|---|---|---|---|---|---|---|---|
| Indramayu | 0.123 | 0.449 | 1.165 | 0.506 | 1.012 | 3.76 | 205 | 13.55 |
| Sumedang | 0.162 | 0.513 | 1.875 | 0.814 | 1.628 | 3.43 | 97.44 | 12.36 |
| Kuningan | 0.130 | 0.513 | 1.200 | 0.521 | 1.042 | 3.73 | 63.33 | 10.35 |
| Majalengka | 0.214 | 0.513 | 0.857 | 0.372 | 0.744 | 4.07 | 135.22 | 8.60 |
| Ciamis | 0.129 | 0.617 | 2.778 | 1.206 | 2.412 | 3.26 | 185.40 | 15.46 |
| Subang | 0.168 | 0.486 | 1.370 | 0.595 | 1.190 | 3.63 | 109.40 | 10.39 |
| Karawang | 0.325 | 0.468 | 1.264 | 0.549 | 1.098 | 3.69 | 155.81 | 9.85 |
| Tasikmalaya | 0.207 | 0.344 | 0.761 | 0.330 | 0.661 | 4.21 | 88.48 | 7.85 |
| Bekasi | 0.143 | 0.542 | 1.143 | 0.496 | 0.993 | 3.78 | 196.25 | 9.41 |
| Bandung | 0.094 | 0.254 | 2.030 | 0.881 | 1.763 | 3.39 | 54.63 | 12.43 |
| Purwakarta | 0.282 | 0.617 | 1.818 | 0.789 | 1.579 | 3.45 | 43.33 | 12.71 |
| Cirebon | 0.116 | 0.734 | 1.538 | 0.668 | 1.336 | 3.55 | 156.75 | 13.28 |
| Bogor | 0.07 | 0.288 | 1.675 | 0.727 | 1.455 | 3.50 | 87.34 | 11.13 |
| Cianjur | 0.100 | 0.288 | 1.265 | 0.549 | 1.098 | 3.69 | 92.97 | 9.62 |
| Garut | 0.089 | 0.184 | 1.469 | 0.638 | 1.276 | 3.58 | 48.07 | 10.1 |
| Sukabumi | 0.076 | 0.252 | 1.694 | 0.735 | 1.471 | 3.49 | 30.97 | 11.15 |
| EDRI Category | Cluster | Centre Point | Member of Cluster | ||
|---|---|---|---|---|---|
| Medium | 1 | 3.597 | 90.057 | 11.033 | Sumedang, Kuningan, Subang |
| 2 | 3.673 | 158.810 | 11.303 | Majalengka, Ciamis, Karawang | |
| High | 1 | 3.616 | 63.684 | 10.713 | Tasikmalaya, Bandung, Purwakarta, Bogor, Cianjur, Garut, Sukabumi |
| 2 | 3.665 | 176.500 | 11.345 | Bekasi and Cirebon | |
| Zone | Member of Cluster |
|---|---|
| 1 | Indramayu |
| 2 | Majalengka, Ciamis, Karawang |
| 3 | Sumedang, Kuningan, Subang |
| 4 | Bekasi dan Cirebon |
| 5 | Tasikmalaya, Bandung, Purwakarta, Bogor, Cianjur, Garut, Sukabumi |
| EDRI Category | Cluster | Centre | Member of Cluster | ||
|---|---|---|---|---|---|
| Medium | 1 | 3.43 | 97.44 | 12.36 | Sumedang, Kuningan, Subang |
| 2 | 3.69 | 155.81 | 9.85 | Majalengka, Ciamis, Karawang | |
| High | 1 | 4.21 | 88.48 | 7.85 | Tasikmalaya, Bogor, Cianjur |
| 2 | 3.55 | 156.75 | 13.28 | Bekasi, Cirebon | |
| 3 | 3.45 | 43.33 | 12.71 | Bandung, Purwakarta, Garut, Sukabumi | |
| Zone | Member of Cluster |
|---|---|
| 1 | Indramayu |
| 2 | Majalengka, Ciamis, Karawang |
| 3 | Sumedang, Kuningan, Subang |
| 4 | Bekasi, Cirebon, |
| 5 | Bandung, Purwakarta, Garut, Sukabumi |
| 6 | Tasikmalaya, Bogor, Cianjur |
| Zone | Parameter Value | Domain | Statistical Value | |||
|---|---|---|---|---|---|---|
| 1 | −0.65775 | 1.5053 | 2.8503 | 0.106 | 0.449 | |
| 2 | −0.54225 | 1.4089 | 2.8265 | 0.130 | 0.316 | |
| 3 | −0.27305 | 0.85587 | 2.9277 | 0.091 | 0.299 | |
| 4 | −0.34862 | 1.051 | 2.9207 | 0.153 | 0.449 | |
| 5 | 0.03996 | 0.5901 | 2.9734 | 0.075 | 0.103 | |
| Zone | |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 |
| Zone | Parameter Value | Domain | Statistical Value | |||
|---|---|---|---|---|---|---|
| 1 | −0.65775 | 1.5053 | 2.8503 | 0.106 | 0.449 | |
| 2 | −0.54225 | 1.4089 | 2.8265 | 0.130 | 0.316 | |
| 3 | −0.27305 | 0.85587 | 2.9277 | 0.091 | 0.299 | |
| 4 | −0.34862 | 1.051 | 2.9207 | 0.41918 | 0.44905 | |
| 5 | −0.15852 | 0.62727 | 2.9657 | 0.0819 | 0.12606 | |
| 6 | 0.13107 | 0.69289 | 2.9496 | 0.07145 | 0.17421 | |
| Zone | |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 |
| Zone | 10 | 20 | 50 | 100 | 200 | 500 | 1000 |
|---|---|---|---|---|---|---|---|
| 1 | 4.63 | 4.82 | 4.96 | 5.03 | 5.06 | 5.1 | 5.11 |
| 2 | 4.67 | 4.92 | 5.11 | 5.21 | 5.28 | 5.34 | 5.36 |
| 3 | 4.39 | 4.68 | 4.98 | 5.17 | 5.32 | 5.48 | 5.59 |
| 4 | 4.58 | 4.87 | 5.16 | 5.33 | 5.46 | 5.59 | 5.66 |
| 5 | 4.39 | 4.85 | 5.47 | 5.95 | 6.45 | 7.13 | 7.66 |
| Zone | 10 | 20 | 50 | 100 | 200 | 500 | 1000 |
|---|---|---|---|---|---|---|---|
| 1 | 4.63 | 4.82 | 4.96 | 5.03 | 5.06 | 5.1 | 5.11 |
| 2 | 4.67 | 4.92 | 5.11 | 5.21 | 5.28 | 5.34 | 5.36 |
| 3 | 4.39 | 4.68 | 4.98 | 5.17 | 5.32 | 5.48 | 5.59 |
| 4 | 4.58 | 4.87 | 5.16 | 5.33 | 5.46 | 5.59 | 5.66 |
| 5 | 4.18 | 4.46 | 4.79 | 5.02 | 5.21 | 5.45 | 5.60 |
| 6 | 4.81 | 5.49 | 6.49 | 7.33 | 8.25 | 9.60 | 10.74 |
| Zone | Distribution | Loglike | AIC Value | ||
|---|---|---|---|---|---|
| 1 | Clayton | 1.04 | 0.34 | 1.53 | −1.05 |
| Gumbel | 1.43 | 0.3 | 0.77 | 0.47 | |
| Frank | 3.23 | 0.33 | 1.28 | −0.55 | |
| 2 | Clayton | 1.36 | 0.41 | 4.49 | −6.98 |
| Gumbel | 1.59 | 0.37 | 3 | −4.01 | |
| Frank | 3.91 | 0.38 | 3.71 | −5.42 | |
| 3 | Clayton | 0.52 | 0.21 | 0.55 | 0889 |
| Gumbel | 1.23 | 0.19 | 0.73 | 0.53 | |
| Frank | 1.45 | 0.16 | 0.58 | 0.85 | |
| 4 | Clayton | 0.36 | 0.15 | 0.17 | 1.67 |
| Gumbel | 1.03 | 0.03 | 0.00 | 1.99 | |
| Frank | 0.55 | 0.06 | 0.04 | 1.93 | |
| 5 | Clayton | 0.32 | 0.14 | 3.05 | −4.11 |
| Gumbel | 1.1 | 0.09 | 2.36 | −2.71 | |
| Frank | 1.12 | 0.12 | 4.05 | −6.11 |
| Zone | Cumulative Distribution Function |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 |
| Zone | Distribusi | Loglike | Nilai AIC | ||
|---|---|---|---|---|---|
| 1 | Clayton | 1.04 | 0.34 | 1.53 | −1.05 |
| Gumbel | 1.43 | 0.3 | 0.77 | 0.47 | |
| Frank | 3.23 | 0.33 | 1.28 | −0.55 | |
| 2 | Clayton | 1.36 | 0.41 | 4.49 | −6.98 |
| Gumbel | 1.59 | 0.37 | 3 | −4.01 | |
| Frank | 3.91 | 0.38 | 3.71 | −5.42 | |
| 3 | Clayton | 0.52 | 0.21 | 0.55 | 0.889 |
| Gumbel | 1.23 | 0.19 | 0.73 | 0.53 | |
| Frank | 1.45 | 0.16 | 0.58 | 0.85 | |
| 4 | Clayton | 0.36 | 0.15 | 0.17 | 1.67 |
| Gumbel | 1.03 | 0.03 | 0.00 | 1.99 | |
| Frank | 0.55 | 0.06 | 0.04 | 1.93 | |
| 5 | Clayton | 0.01 | 0 | 0 | 2.00 |
| Gumbel | 1 | 0 | 0 | 2.00 | |
| Frank | 0.12 | 0.01 | 0 | 1.94 | |
| 6 | Clayton | 0.84 | 0.3 | 7.75 | −13.50 |
| Gumbel | 1.23 | 0.19 | 2.59 | −3.18 | |
| Frank | 2.43 | 0.25 | 5.96 | −9.93 |
| Zona | |
|---|---|
| 1 | |
| 2 | |
| 3 | |
| 4 | |
| 5 | |
| 6 |
| The lowest interest rate | |
| lower interest rate | |
| Low interest rate | |
| Below-average interest rate | |
| Average interest rate | |
| Upper-interest rate | |
| High-interest rate | |
| Higher interest rate | |
| The highest coupon rate |
| Prediction | 3.429 | 3.392 | 3.370 | 3.356 | 3.347 |
| The lowest coupon rate | |
| Lower coupon rate | |
| low coupon rate | |
| Below average coupon rate | |
| Average coupon rate | |
| Upper coupon rate | |
| High coupon rate | |
| Higher coupon rate | |
| The highest coupon rate |
| Year | |||||
|---|---|---|---|---|---|
| Prediction | 0.645 | 0.653 | 0.658 | 0.662 | 0.663 |
| Probability | Zone | ||||
|---|---|---|---|---|---|
| 0.0013 | 0.0011 | 0.0010 | 0.0025 | 0.0010 | |
| 0.9987 | 0.9989 | 0.9990 | 0.9975 | 0.9990 | |
| Probability | Zone | |||||
|---|---|---|---|---|---|---|
| 0.0013 | 0.0011 | 0.0010 | 0.0010 | 0.0010 | 0.0010 | |
| 0.9987 | 0.9989 | 0.9990 | 0.9990 | 0.9990 | 0.9990 | |
| Cluster Type | |||||
|---|---|---|---|---|---|
| I | 0.97371 | 0.94810 | 0.92317 | 0.89890 | 0.87527 |
| II | 0.97398 | 0.948636 | 0.923952 | 0.899911 | 0.876495 |
| Cluster Type | |||||
|---|---|---|---|---|---|
| I | 3140 | 6196 | 9161 | 12,035 | 14,816 |
| II | 3141 | 6198 | 9167 | 12,046 | 14,831 |
| Cluster Type | |||||
|---|---|---|---|---|---|
| I | 1.669 | 3.269 | 4.803 | 6.278 | 7.6961 |
| II | 1.670 | 3.270 | 4.807 | 6.284 | 7.704 |
| Earthquake Type | Zone 1 | Zone 2 | Zone 3 | Zone 4 | Zone 5 | |||
|---|---|---|---|---|---|---|---|---|
| 1 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5 | 1,000,000 | 500,000 |
| 2 | 0.0276 | 0.0263 | 0.0352 | 0.030985 | 0.034202 | 0.033 | 900,000 | 29,700 |
| 3 | 0.0392 | 0.0418 | 0.0359 | 0.034669 | 0.034069 | 0.035 | 800,000 | 28,000 |
| 4 | 0.0332 | 0.0319 | 0.0288 | 0.034347 | 0.031728 | 0.032 | 700,000 | 22,400 |
| 5 | 0.0348 | 0.0353 | 0.0378 | 0.067975 | 0.036765 | 0.038 | 600,000 | 22,800 |
| 6 | 0.0380 | 0.0402 | 0.0356 | 0.034118 | 0.033881 | 0.035 | 500,000 | 17,500 |
| 7 | 0.0272 | 0.0246 | 0.0266 | 0.032025 | 0.029354 | 0.029 | 400,000 | 11,600 |
| 8 | 0.0451 | 0.0484 | 0.0405 | 0.037793 | 0.039404 | 0.04 | 300,000 | 12,000 |
| 9 | 0.0345 | 0.0349 | 0.0350 | 0.033126 | 0.033509 | 0.034 | 200,000 | 6800 |
| 10 | 0.0205 | 0.0168 | 0.0245 | 0.029081 | 0.027087 | 0.026 | 100,000 | 2600 |
| 11 | 0.2000 | 0.2000 | 0.2000 | 0.2000 | 0.2000 | 0.2 | 0 | 0 |
| The face amount expectation | 653,400 | |||||||
| Earthquake Type | Zone 1 | Zone 2 | Zone 3 | Zone 4 | Zone 5 | Zone 6 | |||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5000 | 0.5 | 1,000,000 | 500,000 |
| 2 | 0.0276 | 0.0263 | 0.0352 | 0.0310 | 0.0335 | 0.0285 | 0.031 | 900,000 | 27,900 |
| 3 | 0.0392 | 0.0418 | 0.0359 | 0.0347 | 0.0333 | 0.0377 | 0.036 | 800,000 | 28,800 |
| 4 | 0.0332 | 0.0319 | 0.0288 | 0.0343 | 0.0332 | 0.0338 | 0.033 | 700,000 | 23,100 |
| 5 | 0.0348 | 0.0353 | 0.0378 | 0.0339 | 0.0337 | 0.0345 | 0.034 | 600,000 | 20,400 |
| 6 | 0.0380 | 0.0402 | 0.0356 | 0.0341 | 0.0333 | 0.0367 | 0.035 | 500,000 | 17,500 |
| 7 | 0.0272 | 0.0246 | 0.0266 | 0.0320 | 0.0329 | 0.0288 | 0.031 | 400,000 | 12,400 |
| 8 | 0.0451 | 0.0484 | 0.0405 | 0.0378 | 0.0340 | 0.0430 | 0.038 | 300,000 | 11,400 |
| 9 | 0.0345 | 0.0349 | 0.0350 | 0.0331 | 0.0333 | 0.0341 | 0.034 | 200,000 | 6800 |
| 10 | 0.0205 | 0.0168 | 0.0245 | 0.0291 | 0.0327 | 0.0229 | 0.028 | 100,000 | 2800 |
| 11 | 0.2000 | 0.2000 | 0.2000 | 0.2000 | 0.2000 | 0.2000 | 0.2 | 0 | 0 |
| The expectation face amount | 651,100 | ||||||||
| Clustering Type | SEB Price | ||||
|---|---|---|---|---|---|
| I | 614,181 | 607,250 | 600,689 | 594,463 | 584,326 |
| II | 612,027 | 605,126 | 598,591 | 592,387 | 586,483 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Anggraeni, W.; Supian, S.; Sukono; Halim, N.A. Single Earthquake Bond Pricing Framework with Double Trigger Parameters Based on Multi Regional Seismic Information. Mathematics 2023, 11, 689. https://doi.org/10.3390/math11030689
Anggraeni W, Supian S, Sukono, Halim NA. Single Earthquake Bond Pricing Framework with Double Trigger Parameters Based on Multi Regional Seismic Information. Mathematics. 2023; 11(3):689. https://doi.org/10.3390/math11030689
Chicago/Turabian StyleAnggraeni, Wulan, Sudradjat Supian, Sukono, and Nurfadhlina Abdul Halim. 2023. "Single Earthquake Bond Pricing Framework with Double Trigger Parameters Based on Multi Regional Seismic Information" Mathematics 11, no. 3: 689. https://doi.org/10.3390/math11030689