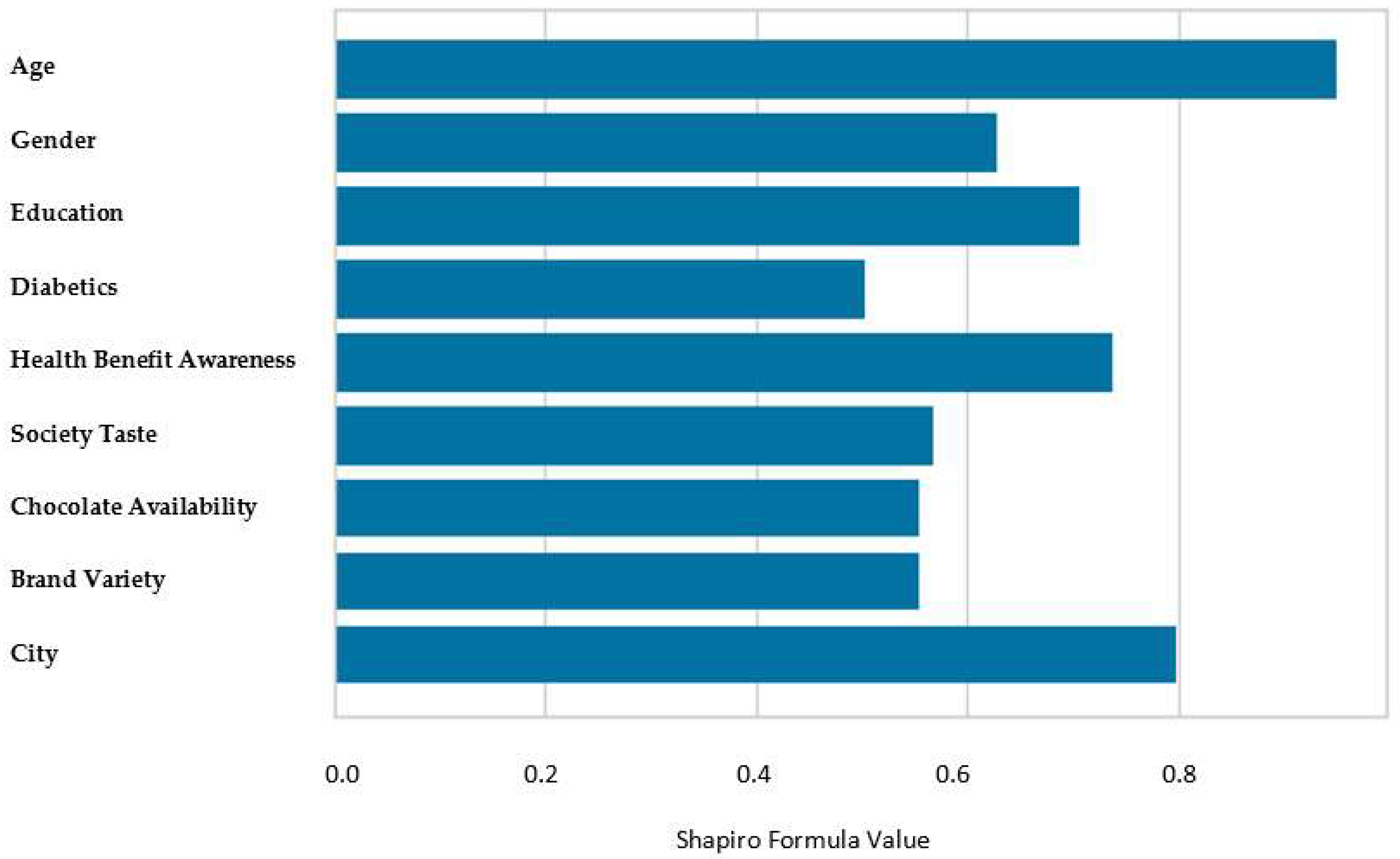
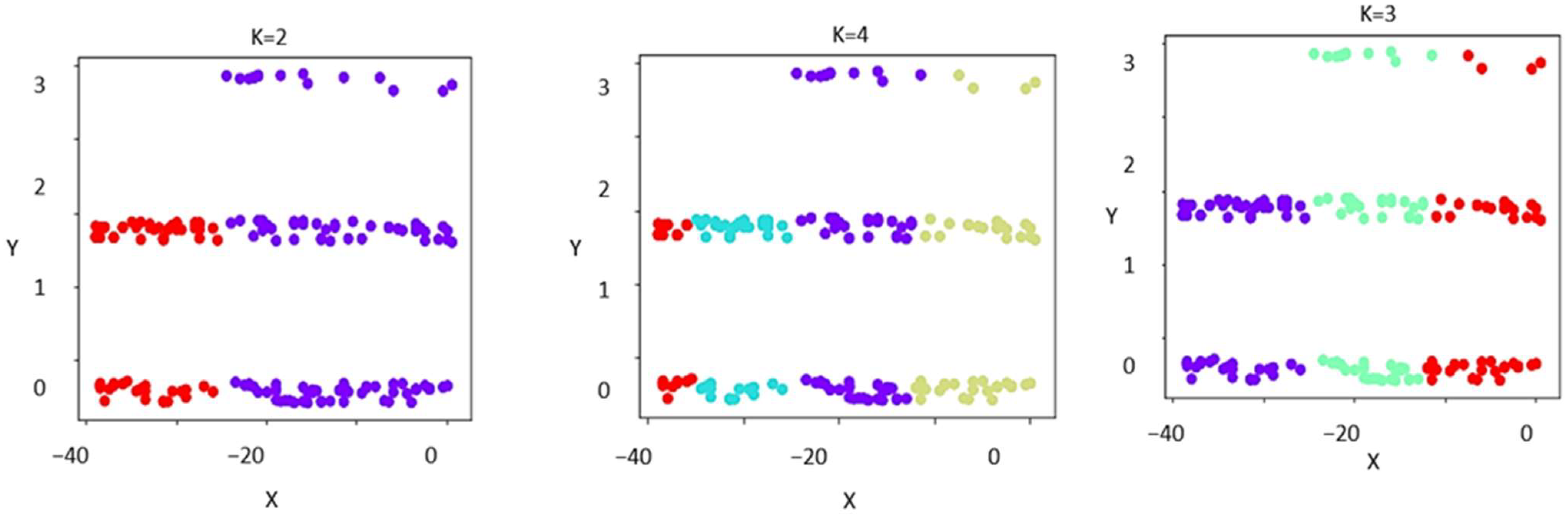
2.1. Product Distribution in Supply Chains
A traditional supply chain, to put it simply, consists of a central manufacturer, a number of wholesalers and a number of retailers. Supply chains can more accurately predict and meet the demands of different markets by employing a hierarchy of processes. Due to the expansion of market demands over the past few decades, new technologies have evolved to expedite the satisfaction of customers’ needs. As a result, numerous innovative approaches to modelling and scheduling supply chains from various perspectives have been offered. Then, a number of crucial references chosen and discussed in relation to the problem statement of this research.
Transporting products is a significant concern in supply chains. The timely fulfilment of market demands can be greatly aided by product transportation, which can also reduce (or raise) system costs by charging more for transportation. According to Fornasiero et al., a discrete-event simulation can be used to tailor a supply chain by leveraging past data [
1]. Sen emphasised the benefits of effective communication between manufacturers and retailers for supply chain effectiveness [
2]. Cultural considerations must be taken into account while constructing supply chains [
3,
4]. Correlations between components that contribute to aligning the retailer’s series in a supply chain were the focus of Iannone et al. [
5]. The statistical study performed by Macchion et al. on the data from 132 Italian manufacturers producing fashion goods resulted in the identification of three distinct factory branches with various production and distribution networks and distinct competitive preferences [
6]. For the purpose of creating an integrated direct and reverse logistics network, Pishvaee et al. presented an mathematical model [
7]. A framework was suggested by Zilberman et al. to describe the critical elements of creative supply chains from several perspectives, including goods and manufacturing systems [
8].
The focus on the global diversification of distribution strategy for products has been noted by numerous authors. Caniato et al. looked into the problem of designing a thorough network while incorporating fresh goods and global retailing [
9]. El-Baz proposed a hybrid fuzzy-AHP to evaluate the performance of a supply chain [
10]. In order to measure the efficiency and economic strategies of supply chains, Olugu et al. presented an expert system [
11]. With a focus on the type of product and the timing of sales in supply chains, Chen et al. suggested an analytical decision framework to address the issue [
12]. There are some linkages between supply chain management, information flows and physical processes [
13]. Therefore, when scheduling the supply chains, an ideal plan style is crucial [
14]. In a supply chain including perishable food products, S. Yang et al. suggested a strategy to boost merchants’ profits [
15]. A strategy for creating new supply chains using the mathematical programming method was proposed by Soolaki et al. [
16]. To solve their model, they employed a hybrid genetic ant-lion optimisation technique. Allaoui et al. proposed a two-stage framework where the best partners were chosen using a hybrid of the AHP and Ordered Weighted Averaging methods in the first stage, and the results were then used in a mathematical model to determine the best designs for the supply chain network in the second stage [
17]. In accordance with governmental policy, Cohen et al. presented tactics and techniques for creating efficient worldwide supply chains [
18]. A mathematical model was created by Mogale et al. to make use of the Indian wheat supply chain. They applied a form of the particle swarm optimisation technique to solve their difficult model [
19]. Singh et al. concentrated on the detrimental effects of COVID-19 on supply chain components. To replicate the three primary issues with food supply networks, they suggested a public distribution network [
20].
Another crucial topic that scientists look at is market demands. Perhaps the major goal of supply chain management is to meet client requests across diverse marketplaces, which is why it is so important. The investigation will next move on to a number of key current research papers that are primarily related to the research’s problem statement. Models for predicting both short-term and long-term client demand have been proposed by Ni et al. [
21]. Wang et al., focused on proposing methods to quickly respond to the customer’s demand in supply chains [
22]. Lo and coworkers concentrated on the benefits of implementing environmental management systems on performance and the economic benefits that can result from doing so [
23]. In order to calculate the greatest profit, Dye et al. presented an inventory model with a variable rate of deterioration and a small downgrading that took the cost of product conservation technology into account [
24]. In a dynamic random programming model, Basu et al. proposed a multi-period inventory control method in 2014 [
25]. Mathematical models are split into two primary categories while uncertain product demands are taken into consideration. The demand for the various predefined items is modelled in the first section of the model, and the demand for products that can be forecast based on historical data or current market analysis is modelled in the second section. Zhao et al. looked into the causes of supply chain uncertainty. They highlighted the primary causes of increased uncertainty as being equipment problems, special sales orders and related items [
26]. Machine-load variation was highlighted by Delgoshaei, Ali and colleagues as a critical flaw in manufacturing systems [
27]. For this reason, a fresh approach to scheduling dynamic production systems with bottlenecks and parallel machines is suggested. They demonstrated how changing machine loads and material routing are both impacted by dynamic cost conditions. A novel strategy for short-term period scheduling of dynamic manufacturing systems in a dual resource-constrained environment was described by Delgoshaei et al. [
28]. While part demands are unpredictable and subject to periodic change, this method seeks to identify the optimal internal manufacturing production strategy employing worker assignment (both temporary and experienced personnel) and outsourcing.
Fuzzy methods have been widely used in modeling uncertainties in supply chains. Novák et al. published valuable research about the mathematical modeling of the fuzzy system; readers can use it [
29]. In order to evaluate the impact of uncertainties in supply chains, Regulwar et al. presented a fuzzy multi-objective programming method [
30]. Liang et al. presented a fuzzy multi-product/multi-period mathematical programming method to overcome integrated production planning difficulties where the aim was to minimise the overall system costs [
31]. Jia et al. used a fuzzy method for developing product strategy in supply chains that worked based on qualitative parameters [
32]. Then, Lootsma focused on important drawbacks and problems of supply chains that supply chains can solve [
33]. Govindan et al. proposed a fuzzy analytic network process to solve a multi-objective, multi-product, closed-loop supply chain that aimed to select appropriate suppliers and assign orders accordingly [
34].
A number of important references will be studied because integrating a local manufacturer into a national or international supply chain can result in unaffordable costs for the chain owners. Mula and colleagues examined mathematical models for supply networks that had been effectively created for organising manufacturing and transportation [
35]. Qin et al. used a selective control system to solve the product transmission issue [
36]. A crucial consistency between retailers and the distribution chain must be taken into consideration because MacCarthy et al. demonstrated that the distribution of components in clothes shops will effect supply chain performance [
37]. Delgoshaei, Ariffin, et al. examined several internal and external transferring techniques in production systems and identified the key issues that frequently arose while scheduling manufacturing systems [
38]. Paciarotti et al. focused on how logistics might improve the sustainability of short food supply chains [
39]. According to their research, optimising supply chain node locations, streamlining distribution routes and restructuring supply chains are crucial components in enhancing the sustainability of food supply chains.
Sustainability has also been the subject of numerous academic investigations to improve the sustainability of supply networks [
40]. The implications of supply chain scheduling and design on supply chain network design are the basis for this review. Levner et al. concentrated on the function of international regulations in controlling the natural elements that shield oceans from industrial pollution and overfishing [
41]. Levner employed economic mathematical modelling with consideration for economic, technological and social constraints to implement risk analysis techniques for sustainable wastewater management in supply chains [
42]. In the fashion industry, Nagurney et al. discussed a novel strategy for planning multi-product supply chains that took environmental concerns into account [
43]. A strategic model was created by L. Yang et al. for capacity-restricted multi-product supply chains with ambiguous market demands [
44]. The Italian fashion industry’s sustainability of drivers and practises was the subject of Lion et al. [
45]. By incorporating the supplier viewpoint, a novelty in the literature on sustainability, they provided a taxonomy of these approaches. According to Macchion et al., supply networks can become more sustainable by using strategic techniques [
46]. In the meanwhile, Moretto et al. created a five-step plan for improving supply chain sustainability [
47].
2.2. Learning Methods
In the past ten years, many people have embraced learning techniques, particularly in the emergence of industry 4.0. Pattern recognition and clustering are the two main applications for learning algorithms. One of the two aforementioned groups could be used to categorise them. Learning groups can be classified as either supervised learning algorithms (where the data labels are available) or unsupervised learning algorithms (where the data labels are present) depending on the labels for the data. There is an agent that can gather data from the environment and utilise it to train the model in semi-supervised learning techniques.
Despite the supervised methods, unsupervised methods do not use the label of a dataset for classifying its members. The main reason for this strategy is that, in reality, the data label is not always available, even during the training step.
One of the most important uses for unsupervised learning methods is clustering. In clustering, an effort is made to determine the connections between items before assigning them to the cluster with the closest connections. There are two primary types of clustering techniques: agglomerative clustering and divisive clustering. Agglomerative objects will be grouped to accumulate gradually until a distinctive cluster forms [
48]. Despite divisive clustering, a large group of objects will be separated into a number of smaller subgroups, and each of these subgroups can also be broken into even smaller subgroups. Repeating this method will result in a cluster of generally related objects.
Dendrogram can help decision-makers find out where to stop the clustering algorithm, whether it is an agglomerative or divisive method.
Figure 1 shows a graphical view of objectives that are clustered using algorithms.
Different functions for grouping objects may be used depending on the clustering algorithm. While in some methods, the aim is to group the objects with higher similarity, in the other methods, by contrast, the aim might be preventing clustering objects with a high dissimilarity. However, the result will provide a set of clusters where similar objects are grouped to gather. Clustering algorithms can be crisp or fuzzy. However, during the last decades, fuzzy clustering methods have received more attention as they can reflect uncertainties.
Patterns of items will be produced in partitioning methods to place comparable objects closer together (or into any other cost function) into the K partition. Scientists frequently employ the partitioning techniques K-mean, K-medoids and C-mean. A K-means algorithm often seeks out things that are closer to a central point. There will be different partitions depending on how many K points are taken into account. Therefore, figuring out how many partitions to take into account is a crucial first step. The step K-means approach was suggested by Chitta et al. in an effort to determine any relationships between the number and size of the partitions [
49]. The Euclidean distance method can be used to determine the distance between two objects with a K centre-point, although other significant metrics, such Manhattan, are frequently utilised when appropriate. Their method is used by Ünler et al. for making partition objects based on the degree of membership [
50]. In K-medoids, the number clusters (K) are known a priori. In K-medoids, the number of clusters must be specified before partitioning objects. According to Kaufman et al. (2009), in K-medoids, the benchmark points for calculating the cost (distance) function for each individual item are a set of medoids that will form partitions. The objects are then grouped with a partition, with the partition having the lowest distance function value [
51].
P-median problem (PMP) is a mathematical programming method to find the minimum distances between objects:
A PMP variation was used by Won et al. [
52] to compute similarity coefficients using a machine-component index matrix (MICM). A quick machine localisation approach based on PMP that reduces the differences between centroid and machine locations was discussed by Goldengorin et al. [
53]. Krushinsky et al. mentioned that the MCIM matrix’s information is insufficient for providing good layouts [
54]. To reduce differences in their research, a novel, simple alternative formulation was applied. Meta-heuristic algorithms have been used to portion or cluster things successfully in specific situations. To increase grouping effectiveness, Paydar et al. suggested using a genetic algorithm with a variable neighbourhood search approach [
55].
C-means is another partitioning method that is frequently used in manufacturing problems. In the C-means method, a threshold value is used for determining partitions. The C-means method can be successfully used for reflecting uncertainties. Using the provided data sets, fuzzy c-means algorithms (FCM) often produce a partition matrix. The elements are then assigned to the relevant partition and represented by membership values. M.-S. Yang et al. proposed a modified version of fuzzy C-means that used mixed variable indexes according to MCIM and could consider symbolic and fuzzy variables [
56]. Izakian et al. presented a combination of fuzzy C-means and Particle Swarm Optimization, which could easily pass local optimum points [
57]. In a cell-forming problem where the clusters are produced based on the cell-size limitation, Oliveira et al. applied a spectral clustering technique to reduce inter-cell movements [
58].
Hybrid meta-heuristic algorithms frequently use unsupervised learning techniques. They are typically employed to cluster or split a set of data. Rogers et al. compared the results of a bivariate clustering that applied for small-size problems with a GA, which was used for medium- and large-scale problems where the aim was minimising the sum of dissimilarity measures [
59]. Adenso-Diaz et al. presented a 2-phase heuristic-based framework in layout design problems using weighted similarity coefficients [
60]. In a factory architecture, Banerjee et al. discussed a two-phase genetic algorithm for creating adaptive clusters and, in turn, detecting bottleneck machines [
61]. In a clustering approach, Kao et al. used the ant colony optimisation technique to use agglomerative ants to recognise objects [
62]. When grouping objects, F. Yang et al. used a hybrid particle swarm method and KHM technique dubbed PSOKHM to avoid local optimum traps [
63]. Then, the material transference issue in manufacturing systems was later addressed by Nouri et al. using the Bacteria Forging Algorithm [
64].
Guerrero et al. focused on solving product family and machine grouping problems using a quadratic assignment problem (QAP), where the results were then clustered with a 2-stage Self-Organised Map (SOM) method [
65]. The selection of the SOM’s ideal size, according to Chattopadhyay et al., is a significant issue when utilising it [
66]. In order to establish the proper size of SOM, they presented a new method that employed the average distortion values during the training phase in SOM as a criterion. To create family problems that might enhance learning processes and provide better patterns, Kuo et al. presented a fuzzy set in a variation of ART [
67]. Zdemir et al. concentrated on preventing pointless clusters in the clustering process by employing the proliferation problem in ART [
68]. By altering vigilance parameters and training vectors, M.-S. Yang et al. employed a novel technique to enhance the learning process in ART [
69]. A novel version of ART that could accept operation sequences and time as inputs was employed by Pandian et al. [
70].
The findings of the literature research indicate that learning algorithms have been successfully applied to a variety of supply chain industry issues, making them a viable technology. Additionally, it was discovered that the distribution of products and the recognition of food consumption patterns have not utilised the learning methods. According to what was discovered through reading the articles, the following conclusions were reached: the literature analysis concluded that it is crucial to identify the crucial elements while establishing a new supply chain network. Determining the different product kinds is essential and must be taken into account while establishing a new supply chain. Finding the ideal locations for the supply chain nodes (wholesaler’s centre points) is essential when developing the new supply chain and can reduce transit time and expense. However, learning algorithms were not utilised to convert a local plant into a nationwide supply chain network. Learning algorithms have been widely employed for different engineering issues, including supply chains.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}