1. Introduction
Machine learning has started making inroads in daily life; its use in various practical applications, particularly deep learning with its advantages of handling huge data, is significant. Due to the excellent performance of deep learning in natural language processing tasks, it has also been applied to other research fields where data are in the form of sequences [
1]. Digital music data has increased significantly, as the Internet has become more widely used and streaming services have become more popular. Treating music as a special language and using deep learning models to accomplish melody recognition [
2,
3], music generation [
4,
5], and music analysis [
6,
7] has proven feasible. Music-related research has primarily focused on melody thus far. Additionally, chord progression is an essential element in music and equally significant as melody. Chord progression refers to a sequence of chords that create various emotional effects and is the foundation of harmony in western music theory.
In early computer composition, researchers attempted to design a set of rules based on music theory to guide computers in creating chord progressions. One approach [
8] suggests that a trance is the section of a song that contains highlights and usually repeats a chord in a 16-measure loop. A statistical model was designed to generate chord loops that could be trained on a chord corpus. Another approach [
9] suggests a system, namely, the artificial immune system (AIS), which uses a penalty function for encoding musical rules. The penalty function was minimized during the training process of the AIS for generating chords in chord progressions. The trained AIS provides multiple suitable chords in parallel to produce chord progressions.
Unlike the acquisition of knowledge through encoding music theory, a few researchers produced chord progressions based on reinforcement learning. An automatic chord progression generator [
10] based on reinforcement learning was introduced, which uses music theory to define rewards and Q-learning algorithms to train an agent. A trained agent can serve as an alternative tool for generating chord progressions and producing suitable chord progressions that composers can use in their compositions. Although the utilization of music theory can assist in the generation of harmonically sound chord progressions by the model, the modeling of music theory or the definition of rewards based on it is challenging. Additionally, this reliance on music theory may cause limitations in model generalization and diversity of generated chord progressions. Therefore, researchers have attempted to view music data as a special type of language by applying language modeling techniques.
Given that grammar is not required in natural language modeling, music theory may not be required in music modeling. In the early days of machine learning, when deep learning technology was not mature, the hidden Markov model (HMM) was used in language modeling to generate chord progressions. One such system, MySong [
11], uses the HMM model to automatically select chords to accompany vocal melodies. Results indicate that chord progressions assigned to melodies using MySong received subjective scores similar to those assigned manually by musicians. Recurrent neural networks (RNNs), including long short-term memory (LSTM) and gate recurrent unit (GRU), show improved performance in the processing of discrete temporal sequence data. An LSTM-based dynamic chord progression generation system [
12] is designed to handle polyphonic guitar music. Chord progression generation is formulated as a prediction process. Therefore, an LSTM-based network architecture incorporating neural attention is proposed, which can learn the mapping between previous symbolic representations of chords and future chord candidates. Additionally, a bidirectional long short-term memory (BLSTM)-based chord-progression generation approach [
13] was introduced to generate chord progressions from symbolic melodies. Furthermore, BLSTM networks are trained on a lead sheet database, where a group of feature vectors composed of 12 semitones is extracted from the notes in each measure of the monophonic melodies. To ensure that the notes share a uniform key and duration, the key and time signatures of the vectors are normalized. Subsequently, BLSTM learn temporal dependencies from the music corpus to generate chord progressions. However, the length of the sequence representing the melody is a limitation of a chord progression generator based on RNNs. Because of back-propagation through time (BPTT), RNNs cannot handle long-distance dependencies well. A common approach to resolving this issue is to shorten the length of the sequences to the extent possible, enabling only a few measures of melodies as input and only generating a single chord for each measure.
This paper proposes a method for generating chord progressions for melodies using a transformer-based sequence-to-sequence (Seq2Seq) model. The model consists of two parts: a pre-trained encoder and decoder. The pre-trained encoder takes melodies as input and analyzes them from both directions to extract contextual information. Subsequently, the contextual information is passed to the decoder. The decoder receives the same melodies as the input, however, in an asynchronous manner. The decoder generates chords step-by-step by considering contextual information and input melodies and finally outputs chord progressions.
The proposed method has several advantages. First, it relies entirely on a music corpus and does not require music theory. Second, it addresses the issue of long-distance dependencies, which RNNs cannot handle well. Finally, the pretrained encoder ensures that chord progressions generated are suitable for melodies by pulling contextual information from them.
The proposed method makes the following contributions: (1) compared to the chord progression generation approaches based on music theory, the Seq2Seq model of the proposed method trained on a music corpus has higher adjustability and generalizability; (2) it overcomes the limitations of traditional RNN-based approaches in chord progression generation, which are unable to handle long-distance dependencies and makes the transitions in chord progression smoother rather than being limited to only one chord per measure; and (3) by considering melody compatibility, the proposed method can generate suitable chord progressions for melodies and serve as an alternative tool for composition.
The remainder of this paper is organized as follows.
Section 2 reviews studies on transformer-based music generation.
Section 3 describes the proposed method for the generation of chord progressions.
Section 4 presents the experimental results and discussions of the results.
Section 5 presents the concluding remarks.
3. Transformer-Based Seq2Seq Model for Chord Progression Generation
In this paper, a method is proposed to generate chord progressions for melodies using a transformer-based Seq2Seq model. First, the representations of melodies and chord progressions are demonstrated. Then, the process of pre-training the encoder is introduced. Finally, the process of generating chord progressions for melodies based on the Seq2Seq model is explained.
3.1. Symbolic Data Representation
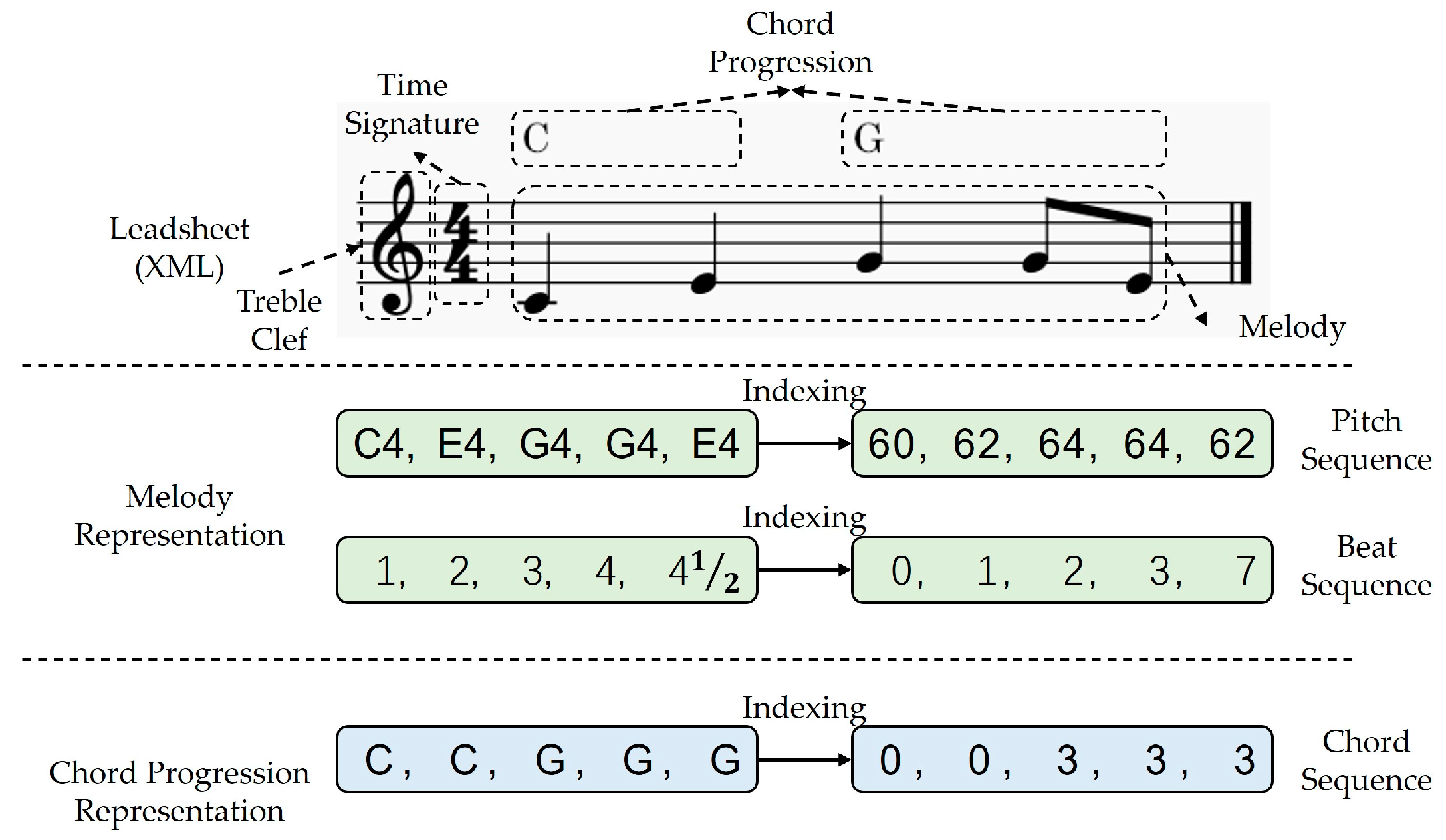
Figure 1 shows that the required melodies and chord progressions for training are obtained from lead sheets in XML format, which are sourced from the OpenEWLD music corpus. The Python library music21 is utilized to extract relevant events for notes and chords, which include information on time signature, pitch, beat, and chord types. The time signature specifies how many beats are contained in each measure, and which note value is equivalent to a beat. For example, in a 4/4 time signature, each measure consists of four quarter notes, and each quarter note lasts for one beat. In order for computers to understand melody and chord progression, they must be converted into a kind of indexed sequence.
Melody is represented as pitch and beat sequences, where each element in pitch sequence consists of two parts: pitch name and octave. The pitch names consist of 12 different types, which are C, C#(=Db), D, D#(=Eb), E, F, F#(=Gb), G, G#(=Ab), A, A#(=Bb), and B. The octaves are represented by integers, and adjacent octaves differ by 12 semitones. In treble clef, the note represented by a ledger line below the staff is C4. To index the pitch sequence, the Musical Instrument Digital Interface (MIDI) is used as a reference. MIDI is the most widely used music standard format in the music composition industry and can represent a range of 128 pitches from C-1 (index = 0) to G9 (index = 127). In addition, the index of <PAD> is defined as 128 to ensure a same input length during model training.
The elements in the beat sequence and pitch sequence correspond one-to-one. Each beat of a measure starts at 1, and the interval between adjacent integer beats is the length of a quarter note. The music in the corpus is all monophonic, meaning that only one note is played at a time. Beats are used to indicate the starting position of notes, and they last until the beginning of the next note. As shown in
Figure 1, the beat sequence of a measure is “1, 2, 3, 4, 4
,” meaning that the notes in this measure start at beats 1, 2, 3, 4, and 4
. The note on the first beat represents a note that starts at the beat 1 and lasts for one quarter note. The note on the last beat represents a note that starts at the beat 4
and lasts for a half quarter note (because the length of a measure with 4/4 time signature is 4 quarter notes). A total of 46 kinds of beat in different kinds of time signature are extracted from the music corpus, and each beat is assigned an index from 0 to 45. The index of <PAD> is set to 46, and the index of <UNK> is set to 47. The reason for adding <UNK> is to prevent the model from failing to run due to uncommon beats during testing or actual application.
The chord progressions are represented by sequences of chords, which includes triads, seventh, ninth chords, and so on. Additionally, chords can also be further classified into major, minor, augmented, and diminished chords. In the music corpus, a total of 428 chords were extracted and assigned an index from 0 to 429, where 0 represents <PAD> and 401 represents <UNK>. As shown in
Figure 1, the chord sequence corresponding to the pitch and beat sequences is generated. “C” represents the C major triad converted to index 1, and “G” represents the G major triad converted to index 2. Each chord influences the pitch of the current and subsequent pitches in the melody until a new chord is appeared. For example, C major triad affects the pitches of C4 and E4, while G major triad affects the pitches of G4, B4, and D5.
3.2. Pre-Training of Encoder
During the pre-training of the encoder, five noise patterns are designed to encourage the encoder to understand the melodies, as shown in
Figure 2. The noise patterns include Start Note Permutation, End Note Permutation, Random Notes Changing, Random Notes Masking, and Neighbor Notes Rotation. Start Note Permutation is designed to swap the starting note of a melody with a random note from the melody. This enables the encoder to learn the relationship between the starting note and remaining melody as well as potential effects of changing the starting note on the overall structure of the melody. End Note Permutation is similar to Start Note Permutation, which involves swapping the position of the last note with the other notes in the melody. Random Notes Changing and Random Notes Masking are designed to randomly replace notes in a melody with notes from the melody, or with the special masking symbol “_”. The two patterns refer to masked language modeling [
23]. This helps the encoder learn to detect incorrect notes and fill in missing notes, thereby deepening the understanding of melodies. Neighbor Notes Rotation is designed to randomly swap the positions of two adjacent notes in a melody. Because melodies have a certain trend, such as rising or falling, the encoder can strengthen its understanding of the melody by rotating the notes. During pre-training, a melody can have all five noise patterns applied to them simultaneously.
As shown in
Figure 3, the pitch (
) and beat sequences (
) of a melody are paired and then noised (an example utilized two noise patterns, Start Note Permutation and Random Notes Masking) to obtain (
) and (
), which are then embedded in the encoder. The encoder is composed of multiple layers of transformers. The encoder uses transformers to capture long-distance dependencies in both directions, which is crucial for understanding and restoring a melody to obtain (
) and (
). This enables the encoder to accurately identify and repair errors or inconsistencies in the melody. After pretraining, the pitch and beat prediction layers were discarded.
3.3. Generating Chord Progressions by Seq2Seq Model
In this paper, a transformer-based Seq2Seq model is proposed to generate chord progressions for melodies. The Seq2Seq model consists of a pre-trained encoder and decoder. As shown in
Figure 4, the Seq2Seq model generates chord progressions based on melodies. First, pitch (
) and beat sequences (
) were passed through the note and beat embedding layers, respectively. These embedded features were then concatenated and fed into the pre-trained encoder. The transformers within the pre-trained encoder were fully connected, enabling full consideration of the input melodies from both directions and extraction of contextual information to ensure that the future generated chord progressions were suitable for the input melodies.
Additionally, the decoder input is divided into two types. One is the concatenated embedding feature obtained from the embedding layers and the other is the contextual information extracted from the pre-trained encoder. This contextual information is input as the key and the value through cross-attention in each transformer in the decoder, whereas the query uses the concatenated embedding features of the pitch and beat sequences. In the decoder, the connections between transformers are unidirectional. This implies that when predicting the current chord, only the current and previous pitches and beats can be considered. In this manner, chord sequences are generated asynchronously by the chord prediction layer, which is a linear layer with Softmax. The chord prediction layer output is a probability distribution that predicts the chord corresponding to both the pitch and beat. To obtain the chord sequence (), the argmax function is used to identify the indexes with the highest values. To present the result, the chord sequences are first reverse indexed to get chord progressions. Then, the chord progressions are re-encoded using the Python library music21 to output music in MIDI format.
It should be noted that compared to traditional Seq2Seq models that use RNNs, transformer-based Seq2Seq models have greater advantages. Firstly, the parallel mechanism of the transformer does not require sequential calculation like RNNs. Therefore, even if the number of layers and dimensions of the transformer increases, it can still be trained and inferred more quickly. Secondly, the transformer-based decoder can asynchronously receive input to obtain information for the current time step. Compared to traditional Seq2Seq models that only rely on last hidden states of encoder, transformer-based Seq2Seq models consider both contextual and asynchronous features simultaneously.
5. Conclusions
This paper proposes a method for generating chord progressions using a transformer-based Seq2Seq model. The model was divided into two parts: a pre-trained encoder and decoder. The pre-trained encoder uses transformers to understand melodies from both the forward and reverse directions, extracting context information to pass on to the decoder. Additionally, the decoder takes the melodies as input and generates chord progressions asynchronously, considering the contextual information obtained from the pre-trained encoder. Based on the experimental results, the proposed method outperformed the three baseline models based on BLSTM, BERT, and GPT2 by 25.89, 1.54, and 2.13%, respectively, in terms of the Hits@k (k = 1) quantitative evaluation. Furthermore, BLSTM was unable to generate effective chord progressions due to the difficulty in handling long-term dependencies.
This transformer-based Seq2Seq model can be used in fields such as automatic music composition, chord recommendation, and automatic music accompaniment. For example, in music composition, the model can assist composers in creating more beautiful melodies and harmonies by generating chord progressions. In terms of chord recommendation, the model can automatically generate corresponding chord progressions based on the input melodies, thus providing users with a richer and more diverse selection of chords. In terms of automatic music accompaniment, the model can generate corresponding chord progressions based on the input melodies and use them as a basis for automatic accompaniment. In future research, to increase the diversity and uniqueness of generated chord progressions, melody and chords recognition and data balancing should be studied while continuously exploring the relationship between melodies and chord progressions.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}