
An Intelligent Edge-as-a-Service Framework to Combat COVID-19 Using Deep Learning Techniques
 ,
,  , and
, and
Abstract
:1. Introduction
- First, we propose a secured edge DL-assisted framework that benefits from the power of cloud computing and the service assistance of the edge and 5G network, in addition to the security advantage of blockchains to collect and detect COVID-19 cases.
- Second, we propose a fusion-based DL approach to improve the accuracy of COVID-19 diagnosis and detection.
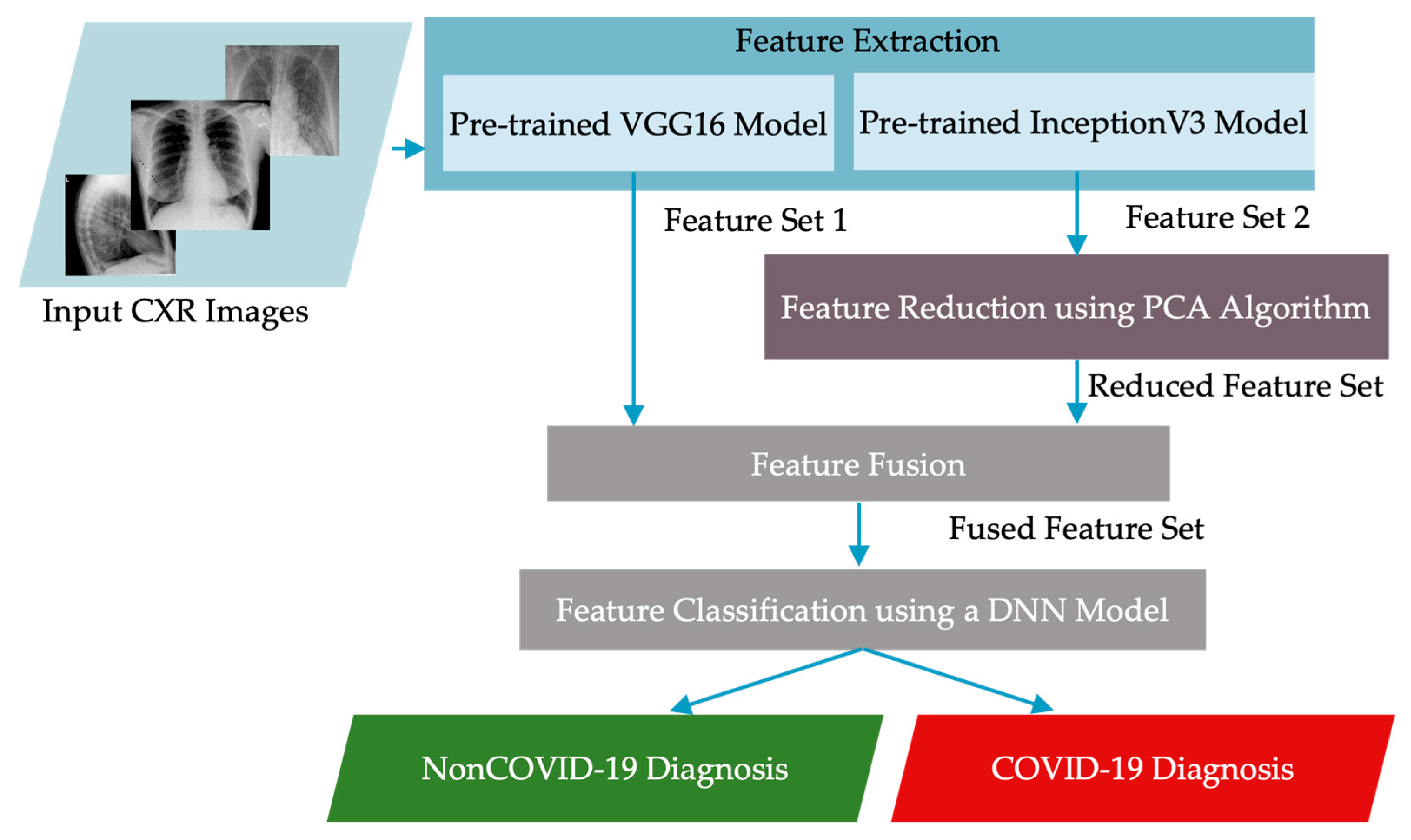
- Third, our proposed approach adopts appropriate DL models, namely VGG-16 and InceptionV3. Functionally, VGG-16 uses a fixed kernel size to reduce the number of trainable variables, speed up the training time, and increase the robustness of the overfitting problem. The Inception model also uses a variable kernel size to extract global and local features, providing good results in detecting area-specific features. However, the global and local features contain some redundant features, leading to a dimensionality problem. We applied principal component analysis (PCA) to reduce the high dimensionality of features extracted by the InceptionV3 model while maintaining the essential features.
- Lastly, we conducted a set of experiments to evaluate the DL model accuracy and the efficiency of the network and blockchain.
2. Overview of the Proposed Framework
3. Feature-Level Fusion Deep Learning Approach
3.1. Feature Extraction
- Computing the sample mean and the sample covariance matrix by
- Computing the eigenvalues and eigenvectors of ;
- Defining the transformation matrix with the eigenvectors associated to the largest eigenvalues;
- Projecting the data into the PCA subspace as follows:
3.2. Feature Fusion
3.3. Classification Using a Deep Neural Network (DNN) Model
4. Experiments and Discussion
4.1. Deep-Learning Performance Results
4.1.1. Hyper-Parameter Tuning of the DNN Model
4.1.2. Experimental Results
4.2. Network Efficiency Results
- D represents the time of detection per unit, ranging from 1 to n. The tasks must be completed within a defined latency threshold, or the system’s performance will suffer.
- G indicates the geolocation of the edge devices. We subdivide the area into square Gis, and any city is regarded as a compilation of Gi blocks (cells of a network), where i ∈ [1; N], and N signifies the total number of blocks. We evaluate the necessity of enhancing the cloud–edge system’s capacity in any of the blocks by examining the number of hospitals served by them.
- T represents the detection model’s maximum bearable latency.
- A: the distribution of time between arrivals. M is for Markovian (i.e., exponential), D is for deterministic (constant), and G is for general distribution (i.e., an unknown distribution). There are other values for less common distributions.
- B: the service time distribution, which can generally have the same values as the inter-arrival distribution.
- c: the number of servers taking parts of the queue.
- K: the capacity of the system, i.e., the maximum length of the queue plus the number of servers. For this reason, it is sometimes written as K + c. If the value is omitted, the queue is infinite.
- Z: the service discipline, e.g., First-In, First-Out (FIFO), The Last-In, First-Out (LIFO) priority. When this is left blank, the discipline is assumed to be FIFO.
4.2.1. Network Experimental Results
4.2.2. Impact of Network Bandwidth Parameters
4.2.3. Impact of Resource Distribution
4.2.4. Detection Model Traffic Parameters and Their Impact
- With unlimited computing resources, the cloud–edge scheme outperforms the core due to lower latency in proximity to hospitals.
- Increasing core bandwidth beyond the load point will not reduce overall application latency as computational latency takes over.
- Higher loads result in increased propagation and queuing delays as limited bandwidth is shared among multiple application streams.
- Continuous increases in front haul edge connectivity cannot improve response time beyond the load level.
- Distributing additional resources only at the edge worsens application performance with lower bandwidth.
4.3. Blockchain Experimental Results
4.3.1. Testbed Configurations
4.3.2. Execution Time
4.3.3. Throughput
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- News.Google.Com. Before You Continue. Available online: https://news.google.com/covid19/map?hl=en-US&gl=US&ceid=US%3Aen (accessed on 27 January 2023).
- Akay, M.; Subramaniam, S.; Brennan, C.; Bonato, P.; Waits, C.; Wheeler, B.; Fotiadis, D. Healthcare innovations to address the challenges of the COVID-19 pandemic. IEEE J. Biomed. Health Inform. 2022, 26, 3294–3302. [Google Scholar] [CrossRef] [PubMed]
- Qayyum, A.; Ahmad, K.; Ahsan, M.; Al-Fuqaha, A.; Qadir, J. Collaborative federated learning for healthcare: Multi-modal covid-19 diagnosis at the edge. IEEE Open J. Comput. Soc. 2022, 3, 172–184. [Google Scholar] [CrossRef]
- Hassan, M.; Ismail, W.; Chowdhury, A.; Hossain, S.; Huda, S.; Hassan, M. A framework of genetic algorithm-based CNN on multi-access edge computing for automated detection of COVID-19. J. Supercomput. 2022, 78, 10250–10274. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; He, Q.; Cui, G.; Xia, X.; Chen, F.; Jin, H.; Yang, Y. READ: Robustness-oriented edge application deployment in edge computing environment. IEEE Trans. Serv. Comput. 2020, 15, 1746–1759. [Google Scholar] [CrossRef]
- Hao, P.; Hu, L.; Jiang, J.; Hu, J.; Che, X. Mobile edge provision with flexible deployment. IEEE Trans. Serv. Comput. 2018, 12, 750–761. [Google Scholar] [CrossRef]
- Liu, C.; Cao, Y.; Luo, Y.; Chen, G.; Vokkarane, V.; Yunsheng, M.; Chen, S.; Hou, P. A new deep learning-based food recognition system for dietary assessment on an edge computing service infrastructure. IEEE Trans. Serv. Comput. 2017, 11, 249–261. [Google Scholar] [CrossRef]
- Wang, S.; Kang, B.; Ma, J.; Zeng, X.; Xiao, M.; Guo, J.; Cai, M.; Yang, J.; Li, Y.; Meng, X. A deep learning algorithm using CT images to screen for Corona Virus Disease (COVID-19). Eur. Radiol. 2020, 31, 6096–6104. [Google Scholar] [CrossRef]
- Song, Y.; Zheng, S.; Li, L.; Zhang, X.; Zhang, X.; Huang, Z.; Chen, J.; Zhao, H.; Jie, Y.; Wang, R. Deep learning enables accurate diagnosis of novel coronavirus (COVID-19) with CT images. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 18, 2775–2780. [Google Scholar] [CrossRef]
- Sethy, P.K.; Behera, S.K. Detection of coronavirus disease (COVID-19) based on deep features. Preprints 2020, 2020030300, 2020. [Google Scholar]
- Wang, L.; Lin, Z.Q.; Wong, A. COVID-net: A tailored deep convolutional neural network design for detection of COVID-19 cases from chest x-ray images. Sci. Rep. 2020, 10, 19549. [Google Scholar] [CrossRef]
- Hossain, M.S.; Muhammad, G.; Guizani, N. Explainable AI and mass surveillance system-based healthcare framework to combat COVID-I9 like pandemics. IEEE Netw. 2020, 34, 126–132. [Google Scholar] [CrossRef]
- Rahman, M.A.; Hossain, M.S.; Alrajeh, N.A.; Guizani, N. B5G and explainable deep learning assisted healthcare vertical at the edge: COVID-I9 perspective. IEEE Netw. 2020, 34, 98–105. [Google Scholar] [CrossRef]
- Rahman, M.A.; Hossain, M.S.; Islam, M.S.; Alrajeh, N.A.; Muhammad, G. Secure and Provenance Enhanced Internet of Health Things Framework: A Blockchain Managed Federated Learning Approach. IEEE Access 2020, 8, 205071–205087. [Google Scholar] [CrossRef] [PubMed]
- ARoy; Kumbhar, F.H.; Dhillon, H.S.; Saxena, N.; Shin, S.Y.; Singh, S. Efficient Monitoring and Contact Tracing for COVID-19: A Smart IoT-Based Framework. IEEE Internet Things Mag. 2020, 3, 17–23. [Google Scholar]
- Ranaweera, P.S.; Liyanage, M.; Jurcut, A.D. Novel MEC based Approaches for Smart Hospitals to Combat COVID-19 Pandemic. IEEE Consum. Electron. Mag. 2020, 10, 80–91. [Google Scholar] [CrossRef]
- Alanazi, S.A.; Kamruzzaman, M.; Alruwaili, M.; Alshammari, N.; Alqahtani, S.A.; Karime, A. Measuring and preventing COVID-19 using the SIR model and machine learning in smart health care. J. Healthc. Eng. 2020, 2020, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Jamshidi, M.; Lalbakhsh, A.; Talla, J.; Peroutka, Z.; Hadjilooei, F.; Lalbakhsh, P.; Jamshidi, M.; La Spada, L.; Mirmozafari, M.; Dehghani, M. Artificial intelligence and COVID-19: Deep learning approaches for diagnosis and treatment. IEEE Access 2020, 8, 109581–109595. [Google Scholar] [CrossRef]
- Hussain, A.A.; Bouachir, O.; Al-Turjman, F.; Aloqaily, M. AI techniques for COVID-19. IEEE Access 2020, 8, 128776–128795. [Google Scholar] [CrossRef]
- Aloi, G.; Fortino, G.; Gravina, R.; Pace, P.; Savaglio, C. Simulation-driven platform for Edge-based AAL systems. IEEE J. Sel. Areas Commun. 2020, 39, 446–462. [Google Scholar] [CrossRef]
- El-Shafai, W.; El-Samie, F.A. Extensive COVID-19 X-Ray and CT Chest Images Dataset. Mendeley Data 2020, V3. [Google Scholar] [CrossRef]
- Siegal, S.; Castellan, N.J. Nonparametric Statistics for the Behavioral Sciences; McGraw-Hill: New York, NY, USA, 1988. [Google Scholar]
- Gelenbe, E.; Pujolle, G.; Gelenbe, E.; Pujolle, G. Introduction to Queueing Networks; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Lee, H.L.; Cohen, M.A. A note on the convexity of performance measures of M/M/c queueing systems. J. Appl. Probab. 1983, 20, 920–923. [Google Scholar] [CrossRef]
- Maheshwari, S.; Raychaudhuri, D.; Seskar, I.; Bronzino, F. Scalability and performance evaluation of edge cloud systems for latency constrained applications. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018; pp. 286–299. [Google Scholar]
- Chen, H.; Pendleton, M.; Njilla, L.; Xu, S. A survey on ethereum systems security: Vulnerabilities, attacks, and defenses. ACM Comput. Surv. 2020, 53, 1–43. [Google Scholar] [CrossRef]
- Li, M.; Qin, Y.; Liu, B.; Chu, X. Enhancing the efficiency and scalability of blockchain through probabilistic verification and clustering. Inf. Process. Manag. 2021, 58, 102650. [Google Scholar] [CrossRef]
- Yang, D.; Long, C.; Xu, H.; Peng, S. A review on scalability of blockchain. In Proceedings of the 2020 the 2nd International Conference on Blockchain Technology, Hilo, HI, USA, 12–14 March 2020; pp. 1–6. [Google Scholar]
- Khan, D.; Jung, L.T.; Hashmani, M.A. Systematic literature review of challenges in blockchain scalability. Appl. Sci. 2021, 11, 9372. [Google Scholar] [CrossRef]
- Christyono, B.B.A.; Widjaja, M.; Wicaksana, A. Go-Ethereum for electronic voting system using clique as proof-of-authority. TELKOMNIKA (Telecommun. Comput. Electron. Control) 2021, 19, 1565–1572. [Google Scholar] [CrossRef]
- Ivanov, N.; Yan, Q. System-Wide Security for Offline Payment Terminals. In Proceedings of the Security and Privacy in Communication Networks: 17th EAI International Conference, SecureComm 2021, Virtual Event, 6–9 September 2021; pp. 99–119. [Google Scholar]
- Tilkov, S.; Vinoski, S. Node. js: Using JavaScript to build high-performance network programs. IEEE Internet Comput. 2010, 14, 80–83. [Google Scholar] [CrossRef]
- Lee, W.-M. Using the web3. js APIs. Beginning Ethereum Smart Contracts Programming; Apress: Berkeley, CA, USA, 2019; pp. 169–198. [Google Scholar]
- Samsel, C.; Gökay, S.; Heiniz, P.; Krempels, K.-H. Web Service to JSON-RPC Transformation. In Proceedings of the 8th International Joint Conference on Software Technologies (ICSOFT), Reykjavík, Iceland, 29–31 July 2023; pp. 214–219. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Precision | Recall | F1-Score |
|---|---|---|---|
| COVID-19 | 0.934 | 0.938 | 0.936 |
| Non-COVID-19 | 0.955 | 0.952 | 0.953 |
| Weighted avg. | 0.946 | 0.946 | 0.946 |
| Test Variable | Model | N | Mean Rank | Sum of Ranks |
|---|---|---|---|---|
| Accuracy | Others (InceptionV3, VGG16, VGG16+ InceptionV3) | 90 | 45.50 | 4095.00 |
| Our Model | 30 | 105.50 | 3165.00 | |
| Total | 120 | 26.00 | 210.00 | |
| Statistics | Wilcoxon W | 4095.00 | ||
| Z | −8.183125 | |||
| Asymp. Sig. (2-tailed) (p-value) | 0.0000000000000003 | |||
| Parameter | Value/Range |
|---|---|
| Cloud Bandwidth | 10–500 Gbps |
| Core Cluster | 0–5 K servers |
| Edge Clusters | 0–5 K servers |
| Latency Requirements | 50–100 ms |
| Parameter | Value |
|---|---|
| Area | 5.18 km2 |
| Number of hospitals | 10 K |
| Distribution of hospitals | Random |
| Bandwidth (Uplink) | 27, 150, and 300 Mbps |
| Bandwidth (downlink) | 54, 300, and 600 Mbps |
| Packet Size | 1500 Bytes |
| Edge Resources (baseline) | 5 Machines/hospital |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, M.M.; AlRakhami, M.S.; Alabrah, A.A.; AlQahtani, S.A. An Intelligent Edge-as-a-Service Framework to Combat COVID-19 Using Deep Learning Techniques. Mathematics 2023, 11, 1216. https://doi.org/10.3390/math11051216
Hassan MM, AlRakhami MS, Alabrah AA, AlQahtani SA. An Intelligent Edge-as-a-Service Framework to Combat COVID-19 Using Deep Learning Techniques. Mathematics. 2023; 11(5):1216. https://doi.org/10.3390/math11051216
Chicago/Turabian StyleHassan, Mohammad Mehedi, Mabrook S. AlRakhami, Amerah A. Alabrah, and Salman A. AlQahtani. 2023. "An Intelligent Edge-as-a-Service Framework to Combat COVID-19 Using Deep Learning Techniques" Mathematics 11, no. 5: 1216. https://doi.org/10.3390/math11051216