

A Kalman-Based Compensation Strategy for Platoons Subject to Data Loss: Numerical and Empirical Study


Abstract
:1. Introduction
- We propose a new strategy to estimate and replace the predecessor-transmitted data in case of loss. This strategy includes a stage where a linear extrapolation is carried out to estimate data from two vehicles ahead, as well as a stage based on the Kalman filter with intermittent observations [19,20], to estimate the predecessor vehicle’s state.
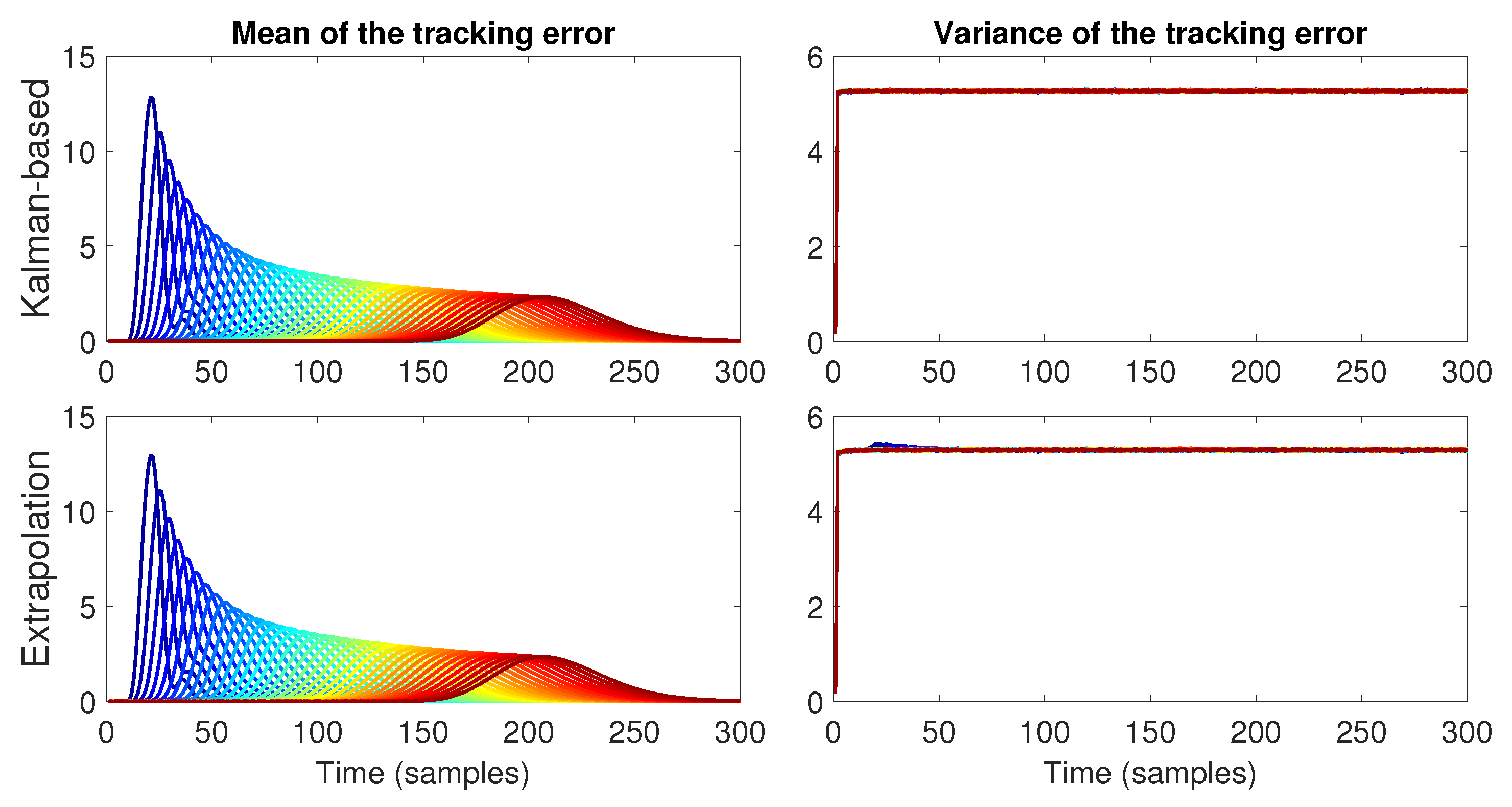
- The performance of the proposed strategy is analyzed numerically for two cases for the data loss probability; a case with a constant data loss probability and another case where the transmission success is dependent on the inter-vehicle distance. As part of this analysis, we also compare the performance of our proposal with a simpler strategy based purely on linear extrapolation [9]. Our numerical results show that although both strategies can achieve string stability for the means and variances of both the tracking and estimation errors, the Kalman filtering-based approach produces better performance compared to the linear extrapolation strategy. Moreover, our proposed strategy is capable of achieving string stability for channels with higher data-loss probability values than those attainable using the extrapolation strategy.
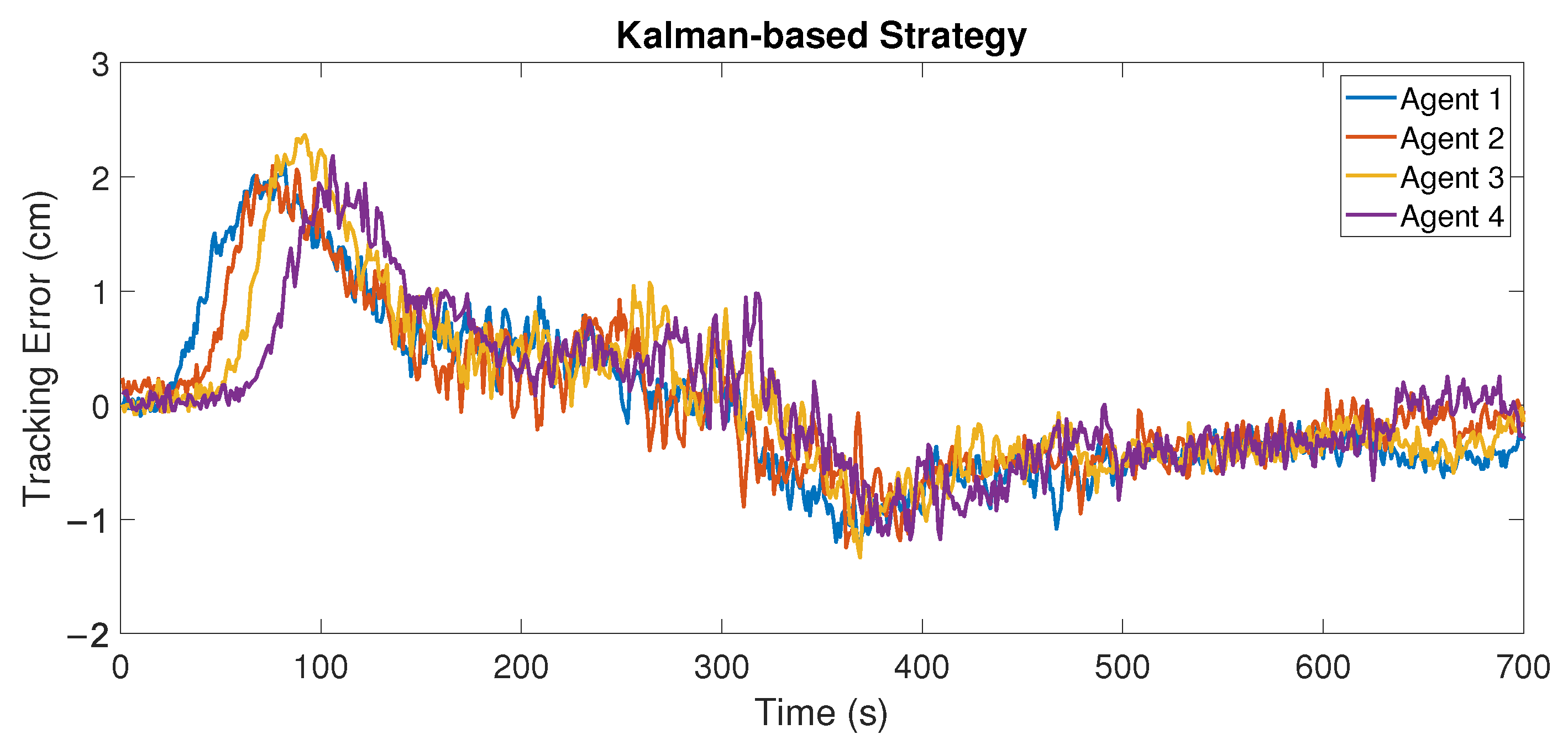
- We also implement these strategies on the experimental platform PL-TOON [31,32], which is a low-cost platform with scale vehicles around 20 cm long that can is suitable for platooning studies. We show that both strategies can achieve tracking errors with string-stable performance, and although the comparison of these strategies does not demonstrate improvements, mainly due to sensor noise levels, the performance of the platoon is slightly better in terms of the variance when using the Kalman filter strategy.
2. Platooning Problem Description
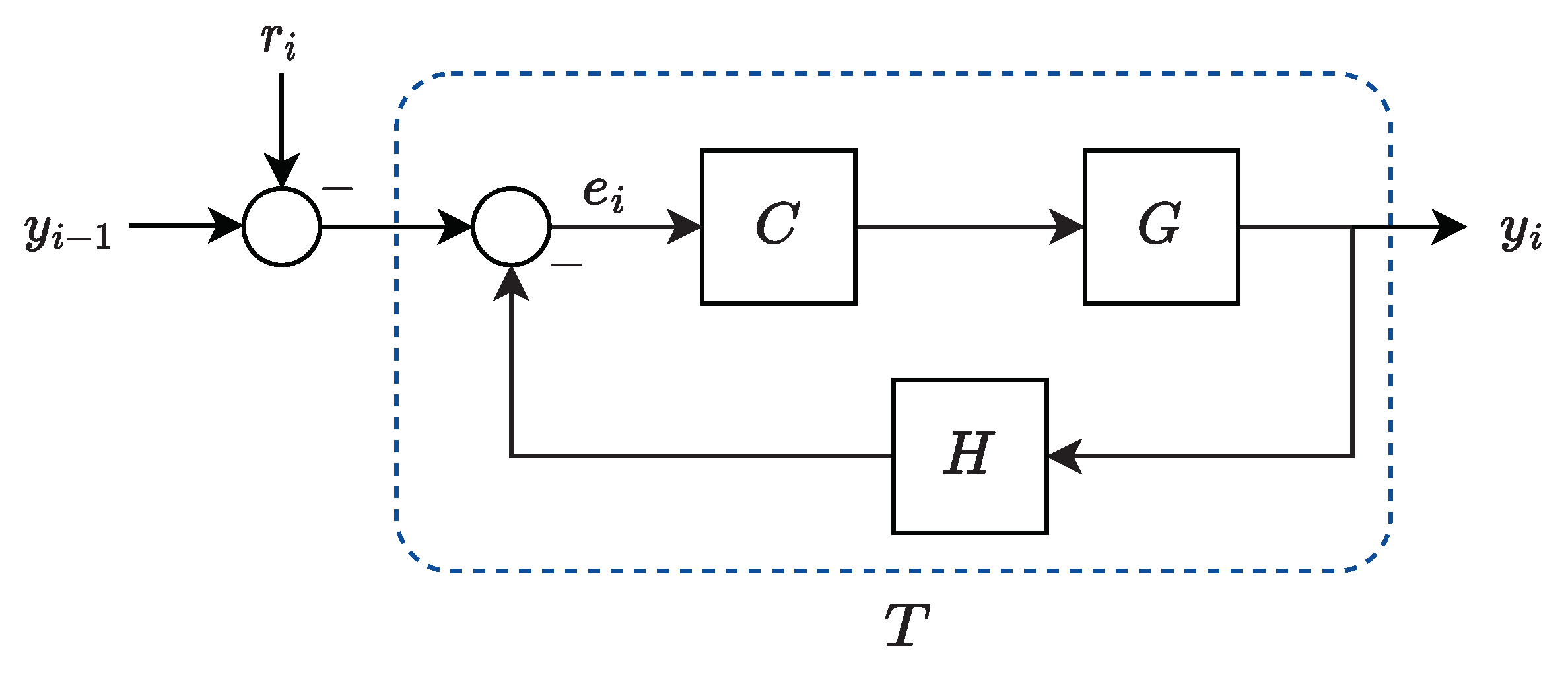
2.1. Platooning Setup with Ideal Communication
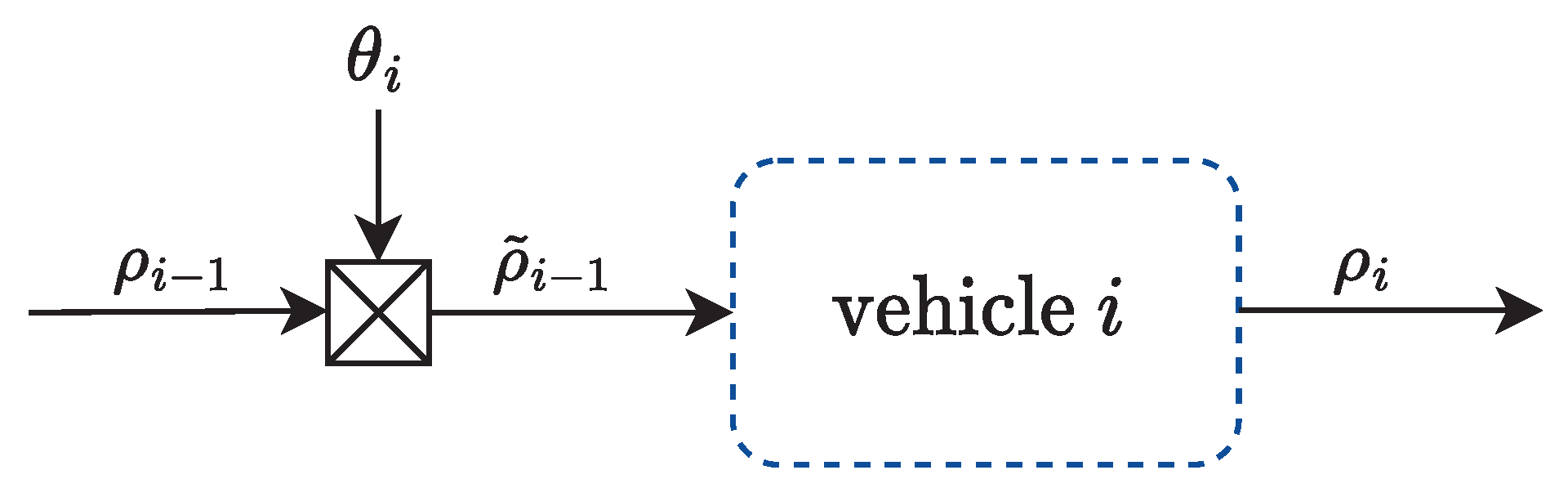
2.2. Platooning with Lossy Communication
2.2.1. Channel Model for Lossy Communications
Constant Probability
Distance-Dependence Probability
2.2.2. Problems with Lossy Communication
2.3. Platoon String Stability
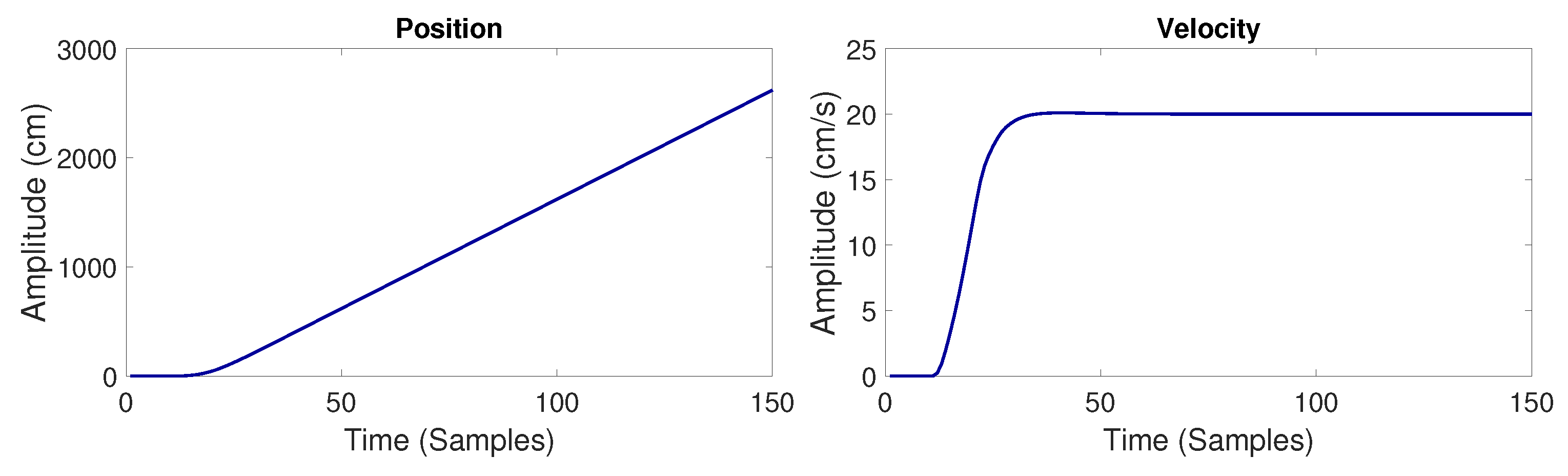
2.4. PL-TOON Implementation Considerations
3. Compensation Strategies
3.1. Linear Extrapolation
3.2. Strategy Based on the Intermittent Kalman Filter
3.3. Strategies for Relative Distance Model
3.3.1. Linear Extrapolation
| Algorithm 1 Data replacement using linear extrapolation (holding previous distance) |
|
3.3.2. Strategy Based on the Intermittent Kalman Filter
| Algorithm 2 Data replacement using strategy based on intermittent Kalman filter |
|
4. Simulation Results
4.1. Constant Transmission Probability
4.2. Distance-Dependent Transmission Probability
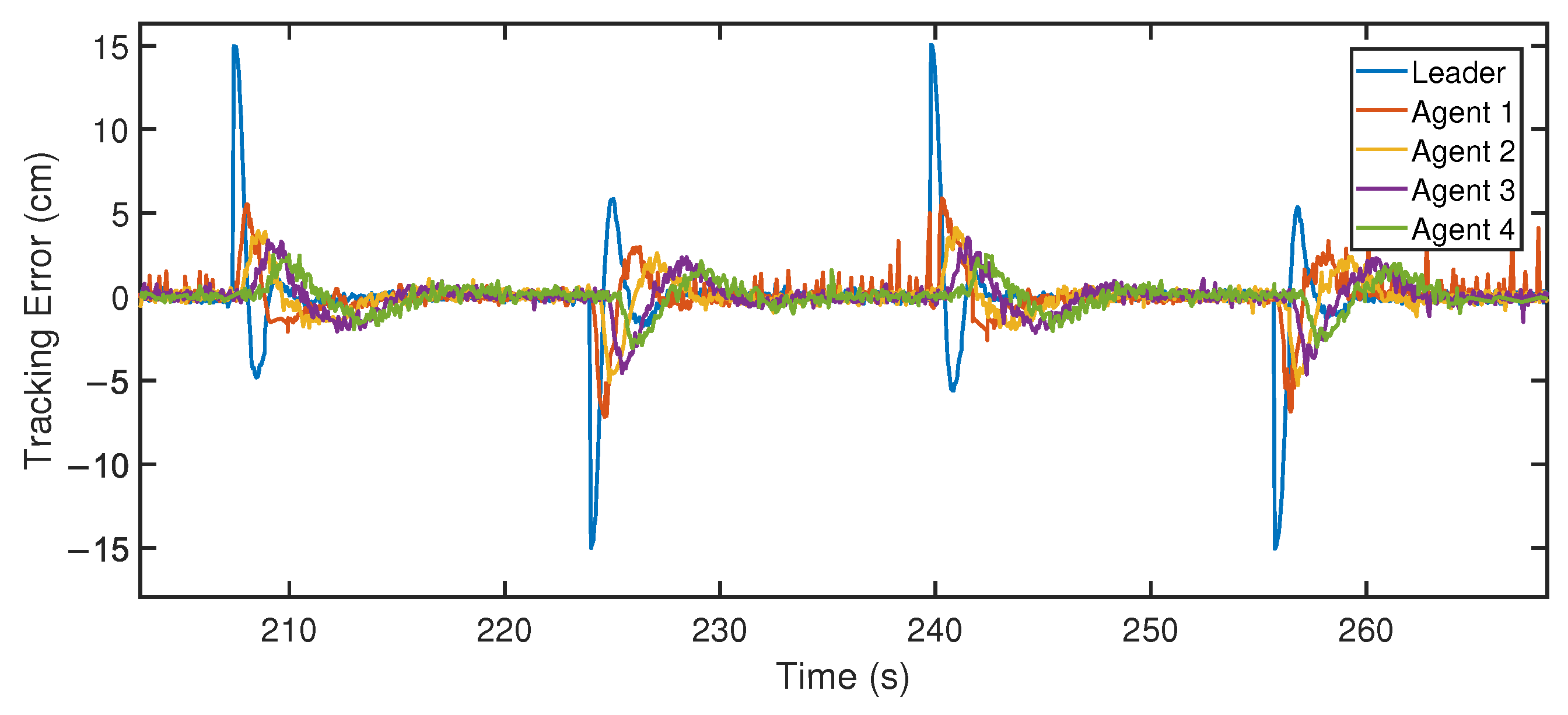
5. Experimental Results
5.1. Experiment 1
5.2. Experiment 2
5.3. Discussion about Noise Level
5.4. Discussion about Other Potential Issues in Real Scenarios
- In practice, heterogeneous platoons are expected to be more common than homogeneous ones. This implies that the models of the vehicles are generally different, which is beyond our framework setup. One way to deal with this is to design stabilizing controllers such that the closed-loop system T is common to all vehicles in the platoon, if possible. Another approach is to extend our setup to heterogeneous platoons by considering a different model of the preceding vehicle in our derivations.
- Our approach requires estimating the previous vehicle information, which implies having an accurate model of such a vehicle. Model uncertainty may yield a poor estimation. To deal with this issue, collaborative systems identification algorithms can be included in order to reduce model uncertainty [36], as well as the inclusion of robust estimation techniques [37].
- In our setup, we assume linear models. In practice, general models are expected to be nonlinear; hence, our setup cannot be straightforwardly applied. One solution is to use feedback-linearization techniques [38] or obtain a closed-loop linear model. Another alternative is to extend our approach by considering an estimator for nonlinear systems such as the unscented Kalman filter (UKF) with intermittent observations [39].
- The inter-vehicle communication channels can suffer from different types of phenomena that can affect the performance of the platoon beyond data loss. These phenomena include random delays, fading, signal-to-noise ratio limitations, and cyber attacks, among others. Our approach could be extended to include tools from networked control systems theory to reduce the effect of such communication issues on the control performance (see, e.g., [40,41,42,43,44]).
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Z.; Wu, G.; Barth, M.J. A review on cooperative adaptive cruise control (CACC) systems: Architectures, controls, and applications. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2884–2891. [Google Scholar]
- Shladover, S.E.; Nowakowski, C.; Lu, X.Y.; Ferlis, R. Cooperative adaptive cruise control: Definitions and operating concepts. Transp. Res. Rec. 2015, 2489, 145–152. [Google Scholar] [CrossRef]
- Javed, M.A.; Zeadally, S.; Hamida, E.B. Data analytics for cooperative intelligent transport systems. Veh. Commun. 2019, 15, 63–72. [Google Scholar] [CrossRef]
- Raza, H.; Ioannou, P. Vehicle Following Control Design for Automated Highway Systems [25 Years Ago]. IEEE Control Syst. Mag. 2021, 41, 13–15. [Google Scholar] [CrossRef]
- Stüdli, S.; Seron, M.M.; Middleton, R.H. From vehicular platoons to general networked systems: String stability and related concepts. Annu. Rev. Control 2017, 44, 157–172. [Google Scholar] [CrossRef]
- Feng, S.; Zhang, Y.; Li, S.E.; Cao, Z.; Liu, H.X.; Li, L. String stability for vehicular platoon control: Definitions and analysis methods. Annu. Rev. Control 2019, 47, 81–97. [Google Scholar] [CrossRef]
- Qin, W.B.; Gomez, M.M.; Orosz, G. Stability and frequency response under stochastic communication delays with applications to connected cruise control design. IEEE Trans. Intell. Transp. Syst. 2016, 18, 388–403. [Google Scholar] [CrossRef]
- Gordon, M.A.; Vargas, F.J.; Peters, A.A.; Maass, A.I. Platoon Stability Conditions Under Inter-vehicle Additive Noisy Communication Channels. IFAC-PapersOnLine 2020, 53, 3150–3155. [Google Scholar] [CrossRef]
- Gordon, M.A.; Vargas, F.J.; Peters, A.A. Comparison of Simple Strategies for Vehicular Platooning With Lossy Communication. IEEE Access 2021, 9, 103996–104010. [Google Scholar] [CrossRef]
- Vargas, F.J.; Maass, A.I.; Peters, A.A. String stability for predecessor following platooning over lossy communication channels. In Proceedings of the International Symposium on Mathematical Theory of Networks and Systems, Hong Kong, China, 16–20 July 2018. [Google Scholar]
- Zhao, C.; Cai, L.; Cheng, P. Stability analysis of vehicle platooning with limited communication range and random packet losses. IEEE Internet Things J. 2020, 8, 262–277. [Google Scholar] [CrossRef]
- Elahi, A.; Alfi, A.; Modares, H. H∞ consensus of homogeneous vehicular platooning systems with packet dropout and communication delay. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 3680–3691. [Google Scholar] [CrossRef]
- Acciani, F.; Frasca, P.; Heijenk, G.; Stoorvogel, A.A. Stochastic string stability of vehicle platoons via cooperative adaptive cruise control with lossy communication. IEEE Trans. Intell. Transp. Syst. 2021, 23, 10912–10922. [Google Scholar] [CrossRef]
- Gordon, M.A.; Vargas, F.J.; Peters, A.A. Mean square stability conditions for platoons with lossy inter-vehicle communication channels. Automatica 2023, 147, 110710. [Google Scholar] [CrossRef]
- Schenato, L. To zero or to hold control inputs with lossy links? IEEE Trans. Autom. Control 2009, 54, 1093–1099. [Google Scholar] [CrossRef] [Green Version]
- Wen, S.; Guo, G.; Wang, W. Vehicles platoon control in vanets with capacity limitation and packet dropouts. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 1709–1714. [Google Scholar]
- Salvi, A.; Santini, S.; Valente, A.S. Design, analysis and performance evaluation of a third order distributed protocol for platooning in the presence of time-varying delays and switching topologies. Transp. Res. Part C Emerg. Technol. 2017, 80, 360–383. [Google Scholar] [CrossRef]
- Tang, Y.; Yan, M.; Yang, P.; Zuo, L. Consensus based control algorithm for vehicle platoon with packet losses. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 7684–7689. [Google Scholar]
- Sinopoli, B.; Schenato, L.; Franceschetti, M.; Poolla, K.; Jordan, M.I.; Sastry, S.S. Kalman filtering with intermittent observations. IEEE Trans. Autom. Control 2004, 49, 1453–1464. [Google Scholar] [CrossRef]
- Schenato, L.; Sinopoli, B.; Franceschetti, M.; Poolla, K.; Sastry, S.S. Foundations of control and estimation over lossy networks. Proc. IEEE 2007, 95, 163–187. [Google Scholar] [CrossRef] [Green Version]
- Maass, A.I.; Vargas, F.J.; Silva, E.I. Optimal control over multiple erasure channels using a data dropout compensation scheme. Automatica 2016, 68, 155–161. [Google Scholar] [CrossRef]
- Vargas, F.J.; Cid, F.A.; Maass, A.I. Plant and buffer state estimation for networked predictive control over multiple erasure channels. ISA Trans. 2023. [Google Scholar] [CrossRef]
- Zhong, Y.; Liu, Y. Flexible optimal Kalman filtering in wireless sensor networks with intermittent observations. J. Frankl. Inst. 2021, 358, 5073–5088. [Google Scholar] [CrossRef]
- Nie, T.; Deng, Z.; Wang, Y.; Qin, X. A Robust Unscented Kalman Filter for Intermittent and Featureless Aircraft Sensor Faults. IEEE Access 2021, 9, 28832–28841. [Google Scholar] [CrossRef]
- Wang, Y.; Masoud, N.; Khojandi, A. Real-Time Sensor Anomaly Detection and Recovery in Connected Automated Vehicle Sensors. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1411–1421. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.; Lin, Y.; Eskandarian, A. Cooperative adaptive cruise control with adaptive Kalman filter subject to temporary communication loss. IEEE Access 2019, 7, 93558–93568. [Google Scholar] [CrossRef]
- Liu, R.; Ren, Y.; Yu, H.; Li, Z.; Jiang, H. Connected and automated vehicle platoon maintenance under communication failures. Veh. Commun. 2022, 35, 100467. [Google Scholar] [CrossRef]
- Dutta, R.G.; Hu, Y.; Yu, F.; Zhang, T.; Jin, Y. Design and analysis of secure distributed estimator for vehicular platooning in adversarial environment. IEEE Trans. Intell. Transp. Syst. 2020, 23, 3418–3429. [Google Scholar] [CrossRef]
- Hidavatullah, M.R.; Juang, J.C.; Fang, Z.H.; Chang, W.H. Heterogeneous platooning vehicle with robust sensor fault detection and estimation. In Proceedings of the 2020 International Symposium on Computer, Consumer and Control (IS3C), Taichung, Taiwan, 13–16 November 2020; pp. 436–439. [Google Scholar]
- Villenas, F.; Vargas, F.; Peters, A. A numerical study of a Kalman filtering based strategy for platooning with lossy communication. In Proceedings of the 2022 IEEE International Conference on Automation/XXV Congress of the Chilean Association of Automatic Control (ICA-ACCA), Curico, Chile, 24–28 October 2022. [Google Scholar]
- Peters, A.A.; Vargas, F.J.; Garrido, C.; Andrade, C.; Villenas, F. Pl-toon: A low-cost experimental platform for teaching and research on decentralized cooperative control. Sensors 2021, 21, 2072. [Google Scholar] [CrossRef]
- Badillo, D.; Huidobro, C.; Villenas, F.; Peters, A.; Vargas, F. Sensor Calibration and Filtering for an Agent of the PL-TOON Platooning Platform. In Proceedings of the 2021 IEEE CHILEAN Conference on Electrical, Electronics Engineering, Information and Communication Technologies (CHILECON), Online, 6–9 December 2021; pp. 1–6. [Google Scholar]
- Goodwin, G.C.; Graebe, S.F.; Salgado, M.E. Control System Design; Prentice Hall: Upper Saddle River, NJ, USA, 2001; Volume 240. [Google Scholar]
- Klinge, S.; Middleton, R.H. Time headway requirements for string stability of homogeneous linear unidirectionally connected systems. In Proceedings of the 48h IEEE Conference on Decision and Control (CDC) Held JOINTLY with 2009 28th Chinese Control Conference, Shanghai, China, 5–18 December 2009; pp. 1992–1997. [Google Scholar]
- Kurt, S.; Tavli, B. Path-Loss Modeling for Wireless Sensor Networks: A review of models and comparative evaluations. IEEE Antennas Propag. Mag. 2017, 59, 18–37. [Google Scholar] [CrossRef]
- Stegagno, P.; Yuan, C. Distributed cooperative adaptive state estimation and system identification for multi-agent systems. IET Control Theory Appl. 2019, 13, 815–822. [Google Scholar] [CrossRef]
- Zorzi, M. Distributed Kalman Filtering Under Model Uncertainty. IEEE Trans. Control Netw. Syst. 2020, 7, 990–1001. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Isidori, A.; Lu, R.; Khalil, H.K. Performance Recovery of Dynamic Feedback-Linearization Methods for Multivariable Nonlinear Systems. IEEE Trans. Autom. Control 2020, 65, 1365–1380. [Google Scholar] [CrossRef]
- Li, L.; Xia, Y. Unscented Kalman Filter Over Unreliable Communication Networks With Markovian Packet Dropouts. IEEE Trans. Autom. Control 2013, 58, 3224–3230. [Google Scholar] [CrossRef]
- Wu, Z.; Li, B.; Gao, C.; Jiang, B. Observer-based H∞ control design for singular switching semi-Markovian jump systems with random sensor delays. ISA Trans. 2022, 124, 290–300. [Google Scholar] [CrossRef]
- Vargas, F.J.; Silva, E.I.; Chen, J. Stabilization of two-input two-output systems over SNR-constrained channels. Automatica 2013, 49, 3133–3140. [Google Scholar] [CrossRef]
- González, R.A.; Vargas, F.J.; Chen, J. Mean Square Stabilization Over SNR-Constrained Channels With Colored and Spatially Correlated Additive Noises. IEEE Trans. Autom. Control 2019, 64, 4825–4832. [Google Scholar] [CrossRef]
- Liu, W.; Shi, P. Optimal linear filtering for networked control systems with time-correlated fading channels. Automatica 2019, 101, 345–353. [Google Scholar] [CrossRef]
- Pang, Z.H.; Fan, L.Z.; Guo, H.; Shi, Y.; Chai, R.; Sun, J.; Liu, G.P. Security of networked control systems subject to deception attacks: A survey. Int. J. Syst. Sci. 2022, 53, 3577–3598. [Google Scholar] [CrossRef]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vehicle | Kalman-Based | Extrapolation |
|---|---|---|
| 1 | 0.5425 | 0.5654 |
| 2 | 0.4367 | 0.4387 |
| 3 | 0.5049 | 0.5721 |
| 4 | 0.4244 | 0.5144 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villenas, F.I.; Vargas, F.J.; Peters, A.A. A Kalman-Based Compensation Strategy for Platoons Subject to Data Loss: Numerical and Empirical Study. Mathematics 2023, 11, 1228. https://doi.org/10.3390/math11051228
Villenas FI, Vargas FJ, Peters AA. A Kalman-Based Compensation Strategy for Platoons Subject to Data Loss: Numerical and Empirical Study. Mathematics. 2023; 11(5):1228. https://doi.org/10.3390/math11051228
Chicago/Turabian StyleVillenas, Felipe I., Francisco J. Vargas, and Andrés A. Peters. 2023. "A Kalman-Based Compensation Strategy for Platoons Subject to Data Loss: Numerical and Empirical Study" Mathematics 11, no. 5: 1228. https://doi.org/10.3390/math11051228
APA StyleVillenas, F. I., Vargas, F. J., & Peters, A. A. (2023). A Kalman-Based Compensation Strategy for Platoons Subject to Data Loss: Numerical and Empirical Study. Mathematics, 11(5), 1228. https://doi.org/10.3390/math11051228