1. Introduction
In recent years, due to the existence of several websites that provide huge volumes of information on the same items, users are overloaded with irrelevant and relevant information. Recommender systems take users’ preferences as input and apply certain procedures to filter the available information and deliver the user the maximum relevant information called recommendations. Most of the recommendations are based on the user’s browsing history, item ratings, etc. Recommender systems play a vital role in social websites to predict the user’s preferences and provide the exact item to the exact user [
1].
Whenever a new user navigates through the website, the recommender system is not able to predict a user’s interest due to the lack of the user’s details. This issue is referred to as a cold start problem. On certain websites, the number of items will be large. However, the number of user ratings on certain items is less. This kind of issue affects the recommender system. Commercial websites introduce a lot of products every day. It is difficult to obtain the user’s preference for new items. This leads to a long-tail problem. The user’s interests and preferences vary with time and also tend to affect the efficiency of the recommender system [
2]. Personalization is useful for content providers to raise sales and for consumers to obtain useful content rapidly. This item recommendation (also called personalized ranking) approach created a user-specific ranked list of items. The preferences of users about items are learned from the user’s past interactions such as consumption history, implicit feedback, explicit feedback, etc. Item recommendation using implicit feedback can be matrix factorization (MF) or adaptive k nearest-neighbor (KNN). Explicit feedback from users is obtained through ratings and it is not commonly used. Implicit feedback is obtained by tracking user activities such as monitoring clicks, view times, purchases, etc. The user need not express his taste explicitly [
3].
The recommendations are made more individualized by refining a candidate collection of objects (such as goods or web pages) using a simulation of a personal profile. There are three methods of recommendation, namely the content-based approach, the collaborative approach, and the hybrid approach. Most recommendation systems use a hybrid approach, which is a combination of the first two approaches [
4].
A content-based algorithm utilizes the attributes of products, such as genre, actors, directors, etc., of a movie to provide suggestions. Content-based and collaborative filtering (CF) recommendations are incorporated into hybrid techniques to provide suggestions. CF is a frequently utilized method that builds suggestions on the opinions of users who are related to them regarding the recommended products.
The two categories of CF approaches are model-based and memory-based. Memory-based techniques work with the user-item rating matrix to provide suggestions by locating the target user’s neighborhood depending on the consensus of previous user ratings. Model-based methods train a prototype using the rating data, and then utilize the prototype to provide suggestions.
In real-world applications, memory-based approaches are highly beneficial since they are simple to comprehend and simple to deploy and execute. Nevertheless, memory-based approaches encounter several restrictions when utilized in applications of large scale. The sparseness of rating values in the available user-item matrix, in which every user only assesses a limited subset of a big database of things, is the most critical issue. In order to reduce noise and unreliability, the correlation between products or customers is examined using the fewest possible overlapping scores. Efficiency is a challenge with CF-based memory approaches. To find the neighborhoods of each pair of customers (or things), it must estimate the correlation between them. For ad-hoc recommender systems containing users worldwide and items, this is computationally impractical.
The proposed work introduces a novel technique, TCPRRS, for recommending products. It exploits the timestamp of user consumption characteristics and personalized ranking function to generate recommendations. The clustering method is applied to extract the products with a maximum of rated users. Next, PSO is used to optimize the best solution. A novel algorithm for a timestamp-based personalized ranking algorithm is derived. Experiments are carried out on standard data sets to evaluate the performance of the algorithm and the results are provided.
2. Related Work
Various research works have been performed on recommender systems since the early 1990s. This section elaborates on the literature pertaining to the proposed work. A method for weighted linear hybrid resource recommenders in [
5] is presented. Their recommender system [
6,
7,
8,
9] provided flexible, general, and effective techniques to exploit robust relationships across different dimensions of a dataset. They state that the integrated approach using three-dimensional details (users, resources, tags) accomplished good results in tag recommendation. The mechanism of interaction between the user and the system intensely affected the features of the data. The hybrid approach offered high scalability, ease of updating, and extensibility for recommender systems.
Folk Rank and Adapted PageRank are derived by [
10,
11] for recommending tags. They revealed the significance of an integrated approach in social annotation systems. In this approach, resources, users, and tags were considered nodes and they were connected according to their occurrence in annotations. For tag recommendation, the approach provided the best results. However, for resource recommendation, the computational cost and requirements of this approach were high due to the necessity for the computation of the PageRank vector for every query.
Eigen factor recommends (EFrec) is a novel citation-based approach to enhance research and academic navigation proposed by [
12]. The algorithm exploited the hierarchical structure of scientific knowledge, creating various probable scales of relevance for dissimilar users. Hierarchical clustering was applied for estimating the relevance and then recommendations for papers were created. Hence, a spectrum (or scale) of recommendations was created for any given topic, paper, or set of keywords. EFrec algorithms experimented on the AMiner dataset, which generated recommendations for 1,218,504 papers, 58.2% of the dataset. The computational cost of the method is low.
A serendipitous personalized ranking technique was presented to find the relation between the accuracy of recommendation and serendipity. This technique, an extension of the conventional personalized ranking technique, applied item popularity in the optimization of AUC. Experimentations were conducted on the Netflix dataset and the Yahoo! Music dataset and the results proved that this technique improved the recommendation accuracy and serendipity to a greater extent [
5].
A technique based on a KNN-directed graph was developed by [
13] for the expansion of tag expression. This was performed to facilitate the organization of information documents in search and navigation. The KNN algorithm and tag clustering algorithm were applied to filter the “noisy tags” and improve the accuracy of tag neighbors. Experimentations were performed on “MovieLens” and “M-Eco” and the result demonstrated that this approach improved the performance of recommendations significantly.
A constrained clustering [
14] demonstrated the minimization of the Bregman divergence. Then, the conventional CF algorithms were utilized to produce recommendations. The experimentation was conducted on DBLP data sets. The performance of this approach was assessed based on recall, precision, mean absolute error (MAR), and classification time.
A unique context-aware recommendation method called collaborative less-is-more filtering (CLiMF) used the concept of tensor factorization for mean average precision maximization (TFMAP). To create top-N suggestions for diverse categories of context, this method optimized the MAP metric for discovering the parameters of the model such as users’ hidden factors, context types, and items. CLiMF recommends relevant items in the top positions of a recommendation list. The experimental results proved that CLiMF outperformed the existing methods in two social network datasets. Initially, a smoothed version of reciprocal rank was introduced for ranking. Then, a lower bound of the smoothed reciprocal rank was derived, and an objective function was formulated, which enabled the deployment of a standardized optimization technique [
15].
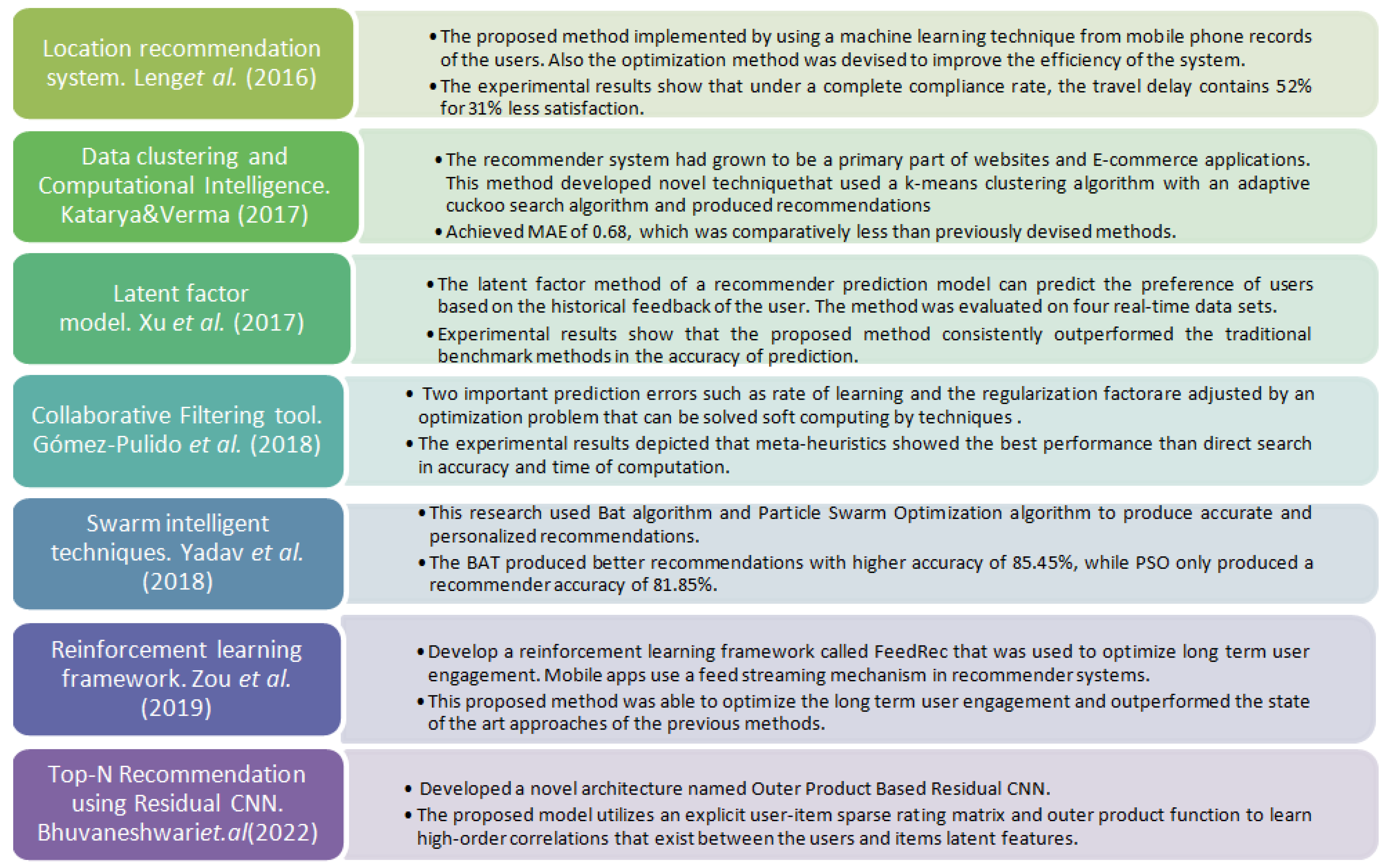
Figure 1 shows the detailed methodology adopted in the various recommendations.
Methods in multi-objective optimization, hybrid model, genetic algorithms, CNN, and collaborative filtering methods were used in order to achieve the betterment of the accuracy in the top recommended items.
This paper is organized as follows:
Section 3 provides a description of the proposed recommender algorithm. The workflow of the algorithm, different phases of the algorithm supported with mathematical derivations, and the pseudo code of TCPRRS are provided. In
Section 4, the experimentations are performed on standard datasets to validate the proposed work. Finally,
Section 5 discusses the results highlighting the performance efficiency of TCPRRS when compared to other existing techniques.
3. Time Cluster Personalized Ranking Recommender System (TCPRRS)
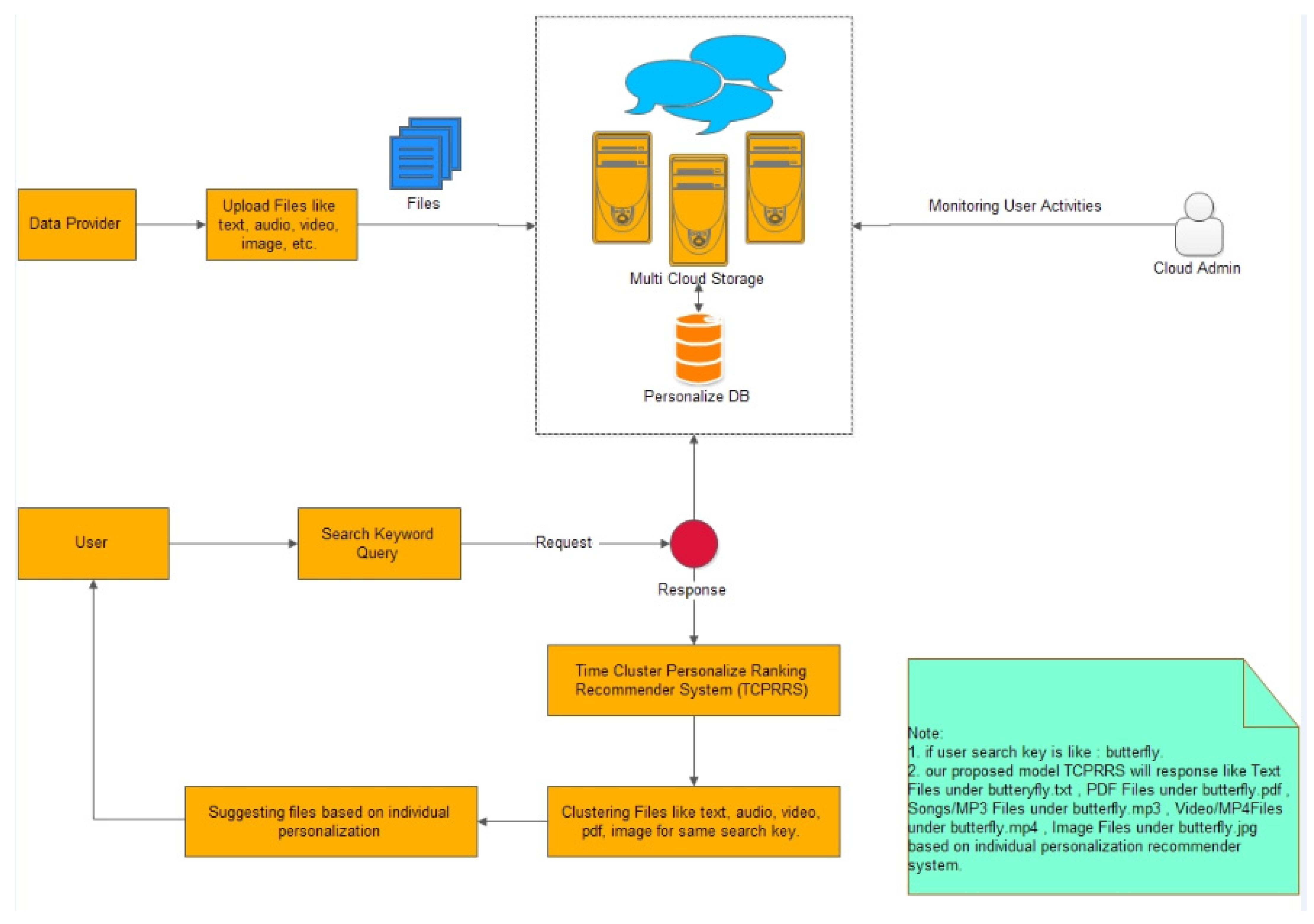
The proposed recommender system focuses on providing recommendations based on personalized ranking and temporal information of user consumption characteristics in a multi-cloud environment [
23,
24]. The data provider uploads resources on multi-cloud storage. The resources are indexed and stored in a personalized database. Whenever a user query arrives, TCPRRS generates recommendations for the user through five phases. After indexing, the clustering technique is applied to classify the products according to the number of rated users. PSO is then applied to obtain the best swarm solution. The outcome of PSO is applied to the time clustering personalized rating recommender system for clustering based on user ratings. Finally, recommendations are generated based on timestamp information. The framework for the proposed system is given in
Figure 2.
The following are the contribution of this research work. A novel algorithm is developed that integrates the timestamp information and personalized ranking procedure to generate recommendations. A new clustering technique is adapted to group the products based on the number of users rated as well as the ranking values. The best recommendations are derived using PSO.
There are five stages in the proposed algorithm to predict the individual’s interest and suggest the demand for particular products based on their search.
Indexing products;
Clustering products based on user rating;
PSO;
Time clustering personalized rating recommender system;
Clustering products based on personalized ratings with timestamp.
The outcome of PSO is applied to time clustering personalized rating recommender system for clustering based on user ratings. Finally, recommendations are generated based on timestamp information. The framework for the proposed system is given in
Figure 3.
There are five stages in the proposed algorithm to predict the individual’s interest and suggest the demand for particular items based on their search.
3.1. Auto Indexing
Data pre-processing makes the data ready for further processing. It includes steps such as the removal of stop words, stemming, and the like. Stop words occur frequently, but they carry no information. In this step, words such as prepositions, articles, and pronouns are removed. Then resources are auto-indexed in order to enhance the accuracy of the indexing process, and they are classified according to the item types. The number of users ranked for each item is retrieved, and indexing is carried out based on the item naming and the ranking information. In the proposed algorithm, the index writer assigns an index for each product. Maxrat is assigned to the item with a maximum number of users rated. The selection of the index writer is given below. Instead of looking for similar users, consider similar items. The corresponding prediction is defined by Equation (1).
where
denotes the neighborhood of the item restricted to those ranked by user
u and
denotes similarity of items. The classifier is defined similarly by
r with the highest mean.
where
denotes the neighborhood of the item restricted to those ranked by user
u and
denotes similarity of items. The classifier is defined similarly by
r with the highest mean.
3.2. Clustering
Clustering is performed to cluster the products based on the number of rated users. A cluster of products with a particular rating contains products of the same type but with the same or different branding. The product with the highest number of rated users is taken as the criteria for clustering. The clustering process is a twofold process, which is described in
Figure 4.
The cluster selection is given in (3)
where
C is the
ith cluster, t is a point, and
Ci is the mean of the
ith cluster. We can solve the
kth centroid, which minimizes the Equation (3) by using differentiation the SSE (sum of square error) with setting is equal to 0.
where
j = 1, 2, 3, …,
.
3.3. Particle Swarm Optimization (PSO)
Evolutionary approaches [
25] work on the basis of handling several solutions for the candidates in the search space of PSO. In every step of the iteration, optimization is performed to obtain the objective function to estimate fitness. Each solution is indicated by the particle swarm algorithm through the fitness score. The particles swarm through the search space for finding the maximum value of the objective function [
26]. Three steps are evolved in the PSO algorithm such as:
Evaluating the fitness function;
Updating the separate and global best fitness as well as locations;
Modifying the location and velocity for every particle.
Every particle has its best position in the search space (solution and fitness), velocity, and individual location. In fact, the swarm has the highest spot in the world.
Consider “P” particles in position vector
=
and velocity vector
=
at “
t” iteration. These vectors are updated n dimension “
j” using below Equation (6),
The particle updation by using,
“w” represents the inertia weight constant;
represents the current position;
and represent the positive constant.
The global search defines the higher values that are set and the local search defines the local values that are set. Fitness assessment shall be carried out by presenting a solution of the candidate to the objective task. Separate and global best fitness, as well as positioning, is updated by contrasting newly measured fitness with the previous approach. If it is appropriate to replace the best fitness and positions, the best fitness and positions are modified. The pace and location upgrade phase plays a vital role in improving optimization capability. The velocity update equation is defined as below,
where
m is the particle index,
y is the inertial coefficient,
l1,
l2 are coefficients of velocity, and 0 ≤
l1,
l2 ≤ 2.
a1,
a2 are random values (0 ≤
a1,
a2 ≤ 1) regenerated for every velocity update.
is the velocity of the particle at time
t,
is the position of the particle at time
t,
is the individual best solution of the particle as of time
t.
b(
t) is the swarm’s best solution at time
t.
If the velocity of each particle is determined, the position of each particle is modified by applying the new velocity to the previous location of the particle.
Until stopping criteria are met, the process will be iterated. Some of the conditions involve the number of iterations of the PSO algorithm, candidate solution, or a pre-determined target fitness value. After matching the user query to the best solution for the swarm, it calculates the similarity coefficient for each and every product.
3.4. Time Cluster Personalized Ranking
The output of the PSO best swarm solution is fed as input for the TCPRRS procedure. A personalized rating of the individual is considered to obtain the individual customer details. The personalized solution and swarm solution are matched to obtain the recommended product. Several iterations were carried out to obtain the best product for the user. Temporal information is used for providing a recent user buying strategy. Personalized ranking with timestamp obtains the recently bought product as well as the best product as a suggestion. Finally, recommendations are derived using personalized ratings with the timestamp as depicted in Algorithm 1 for providing the best-suggested product to the customer.
Table 1 represents the notations used in TCPRRS.
| Algorithm 1: TCPRRS |
Input: User query
Output: Best recommendations
for each items i to n do
begin //indexing
index writer[i] = prods[i];
Marat[i] = index writer[i].get rat();
end;
begin//clustering products based on user rating
for each max rat j to m do
begin
if max rat[j] > max rat[j + 1] then
cluster[j] = max rat[j];
else
cluster[j] = max rat[j + 1];
end;
end;
end;
begin//pso
for each cluster i to m do
begin
for each particle bc do
begin
rand_part = rand_val[0,((insf + 1)*2)/2];
rand_glob = rand_val[0,((insf + 1)*2)/2];
vl[bc] = insf*vl[bc]+rand_part*(part[bc]-nwvl[bc]) + rand_glob*(bss-nwvl[bc]);
nwvl[bc] = (nwvl[bc]+vl[bc]) mod (totdocscount) + 1;
if f(nwvl[bc]) > f(part[bc]) then
part[bc] = nwvl[bc];
if f(part[bc]) > f(bss) then
bss = part[bc]’
end;
end;
end;
begin//Time Clustering Personalize Rating Recommender System
for each bss i to n do
begin
for each prsrat j to m do
begin
if prsrat[j] == bss[i] then
recom_prod[i] = prsrat[j];
end;
end;
begin//clustering products based on personalize rating with timestamp.
for each recom_prod j to m do
begin
if recom_prod[j] > recom_prod[j + 1] then
bcluster[j] = recom_prod[j];
else
bcluster[j] = recom_prod[j + 1];
end;
for each bcluster j to k do
begin
if bcluster[j]. get stamp() > bcluster[j + 1]. get stamp () then
best sugg[j] = bcluster[j];
else
best sugg[j] = bcluster[j + 1];
end;
end;
end; |
The workflow of the entire proposed recommender system is given below:
- Step 1.
Data collections having 1 lakh items approximately.
- Step 2.
For auto-indexing process prods (i = 1 to n = 1 lakh).
- Step 3.
Add all products to auto-index writer (1 to 1 lakh).
- Step 4.
Find no of user ratings present in each and every item then assign it into maxrat (1 to 1 lakh items).
Indexing process completed.
- Step 5.
For clustering process maxrat (j = 1 to m = 1 lakh ratings).
- Step 6.
Find the maximum no of user ratings present in a product then form a cluster based on maxrat.
Clustering process completed.
- Step 7.
For PSO process cluster (i = 1 to m = 1 lakh clusters).
For each particle passing the best cluster for the process.
It will find the confidence coefficient, inertial factor, velocity, and best solution for swarm.
- Step 8.
After matching the user query to the best solution for swarm to calculate a similarity coefficient.
- Step 9.
For the time clustering process (bss) to pass the best swarm solution for iteration.
- Step 10.
For personalized rating process (prsrat) to obtain the individual customer details for iteration.
- Step 11.
Matching the prsrat to bss then collect the recommended products.
For recommender product list for iteration.
- Step 12.
Find the best cluster for recommended products.
For best time cluster process to obtain clustered product timestamp for iteration.
- Step 13.
Find the best product for suggestion (best sugg).
- Step 14.
Suggest best recommender products to customers.
Thus, the proposed recommender system provides efficient recommendations using the timestamp-based personalized ranking information of users.
4. Results and Discussion
4.1. Data Set Description
The experiments have been performed by using the dataset MovieLens100K (Dataset DS1) contains about 100,000 ratings (1–5) from 943 users on 1664 movies. Each user has rated at least 20 movies. This dataset has demographic information for users such as gender, occupation, age, and zip code.
4.2. Model Evaluation
The model evaluation contains two different approaches, such as offline and online evaluation. The evaluations are described below:
4.2.1. Offline Evaluation
To increase overall accuracy and validate the model, it depends on the 5-fold cross-validation approach used to estimate accuracy. The training dataset is subdivided into k-subsets, and the subset is retained while the model is completely trained on the remaining subsets. In order to use the ratings in the training set, the recommendation algorithm tries to identify the ratings in the test set, which could then be compared to the actual ratings. Train and test datasets are the two significant perceptions in the TCPRRS model learning, wherever the training dataset is cast off to appropriate the model, and the test dataset is recycled to assess the model.
Figure 5 illustrates the cross validation method for training and testing datasets and shows the first 5-fold cross validation approach. This technique eliminates the over-fitting issues that arise when a model trains data too closely to the dataset, which can lead to failure to predict future information reliably. Several real users are involved in an offline assessment, and an existing data collection is used. Stable accuracy will solve the random precision issue and give knowledge about proving model oversimplification. It provides the impression of in what way the classical will simplify to an unidentified dataset. A commonly used and observed predictive accuracy measure is a mean absolute error, or MAE, and a mean square error, or MSE.
Figure 6 shows the offline performance measures for the proposed machine learning model in the 80–20 training and test data of TCPRRS. The TCPRRS achieves 80% accuracy, justifying that selected features have more impact in the cluster separation and in the cluster performance evaluation. The normalized mutual information metric can be applied, and it is a score to scale the results between 0 (no dissimilar cluster) and 1 (similar perfect clustering) to obtain a good and robust clustering to combine the results of multiple clustering.
Figure 7 shows MAE and MSE measures for the proposed machine learning model in the cross-fold validation. In the 80–20, MAE and MSE achieve good performance, justifying that selected features have more impact on the cluster separation.
4.2.2. Online Evaluation
In an online assessment, users are associated with processing recommendation programs and ultimately obtain a recommendation [
27,
28]. Feedback is then obtained from users by asking them questions. Such a live user observation may be managed in a way in which the proposed program is applied in real life and the results are evaluated. It is the best way to progress true user satisfaction.
Figure 8 depicts the Top-K (K = 5, 10, 15, 20) recommendation of the active user with respect to rating 3, which shows the TCPRRS reaches the best accuracy from the categorized cluster environment. With the investigational findings, the optimized TCPRRS approach produced different recommendations to the active user and this model delivered the best accuracy for the Top-K (K = 5, 10, 15, 20).
Figure 9 and
Table 2 shows the comparison of distance measures such as Euclidean distance, Cosine, and Manhattan distance in K-means clustering by using the number of cluster values is
n = 2, 4, 5. In the experimental findings, Euclidean distance is not balanced, which means that distances calculated power is twisted contingent on the components of the features and requirements to normalize the data, which outputs the dimensionality upsurges of cluster data, the fewer valuable is created.
Figure 10 shows the measured values of the sum of squares in 10 iterations, which indicate that the error rate with K-means clustering approach is reduced with the number of iterations starting from 1 to 10. With the experimental findings, we need to go for the optimized clustering approaches to enhance the cluster quality.
Figure 11 shows the measured values of the sum of squares in 10 iterations which indicate the error rate with the K-means clustering approach and PSO-K-means optimization approach. In the PSO-means method, the error rate is reduced with the number of iterations starting from 1 to 10. With the experimental findings globalized search approach that can be cast off in the K-means algorithm to discover the optimal solution.
4.3. Multi-Cloud Storage
Cloud storage plays a significant role in where data is stored as a cloud data center is used to access data on the Internet in cloud computing.
There are various kinds of clouds, namely private, public, and hybrid clouds. (Akter et al. 2018 [
23]). This storage provides the versatility and reliability of cloud computing. Recently, numerous cloud storage services became obtainable in the public cloud at low cost, making them more user-friendly. Among these, the public cloud uses all forms of users with a web portal, but its security feature is high due to information theft by hackers based on brute force attacks.
Public cloud: This is hosted off-site, over the Internet, and typically operated by a cloud service provider. Their services are provided to the public cloud. It is less secure than a private cloud. The public cloud is Amazon EC2, Dropbox, and Microsoft Azure. The TCPRRS movie recommender system in the web/mobile framework was developed in the multi-cloud storage environment. This framework provides good performance in accessibility, cost savings, geographic scalability, storage immortality, data redundancy and replication, regulatory compliance, and pay as you go service. The following are the steps to proceed in the various cloud storage.
4.3.1. Verification Step for Dropbox
Two authentication steps have been performed with password protection.
Use the particular message sent to the user’s phone number at the Dropbox account development time.
While uploading the file, encryption is performed. The encryption technique is utilized to store the information in the public cloud.
4.3.2. Verification Step for Google Drive
Step of two authentication process with password protection.
Create a single Google folder in Box crypto for encryption.
End-to-end encryption with security. Google drive aids multiple uploads at the same time. Uploading a file is achieved as quickly as possible. It generates the Google folder for encrypting the file that is uploaded by the active user.
4.3.3. Verification Step for One Drive
Authentication process with password protection.
File-Sharing at any time.
At the time of syncing, encryption is performed in the cloud. The speed limit for uploading and downloading a file in the cloud can be set to kilobytes per second.
In the TCPRRS-cloud framework, downloading and uploading data is considered as a significant workflow for the top-n item recommendation. Downloading files from cloud storage is for active users to access files in a cloud storage bucket and view these files on their web browser, mobile framework, and local storage. Users can upload all the information about movies in the respective cloud storage bucket and this process happens internally. A movie-based web/mobile recommender system considered with the performance of internet speed, architecture of cloud storage bucket, and active user information. Here, the TCPRRS web/mobile framework is deployed in different cloud storage to manage the network traffic.
Figure 12 shows that Dropbox demonstrates an earlier completion time than the other Cloud Services. One Drive and Google Drive accomplished alike performance. For instance, to upload 1 MB data size, the time of completion attained for Dropbox, Google Drive, and One Drive is 10 s, 14 s, 18 s, and 22 s. The speed of uploading and downloading files is different in cloud storage. Generally, it is based on the cloud storage, files, and speed of internet connection. File upload and download speeds vary among cloud storage services. Typically, it is based on the files, the cloud storage architecture, and the internet connection speed.
Figure 12 and
Figure 13 indicate the average time of uploading and downloading operations of a specific service for various data transmission sizes. Each activity is conducted on the TCPRS services website, comprising file syncing. It can see that One Drive used the most time for uploading and downloading, while Google Drive and DropBox took a few seconds. Finally, it performs the uploading and downloading operations in the TCPRS mobile/web services.
5. Conclusions
In this work, recommendations for movies in the multi-cloud environment were generated using temporal information in the personalized ranking system. Clustering methods offer better scalability than CF methods as they make predictions within clusters rather than the entire data. TCPRRS consists of five stages, namely indexing, clustering, PSO, and time-based clustering with personalized ranking and recommendation. The indexing of items was performed initially, followed by clustering based on user ranking. Then, PSO was carried out. The output of PSO (best swarm solution) was fed as input to the TCPRRS process. A personalized rating of the user was used to obtain particular user information. Finally, the timestamp value was applied for making recommendations. The experimentation was performed and evaluated using similarity metrics, and the results revealed that TCPRRS provides the best recommendations in a multi-cloud environment.
5.1. Recommended Aspects in a Technical Way
To improve the accuracy and scalability of the RS and to ensure that the system makes real-time decisions depending on the large-scale data, it is essential to carry out in-depth exploration and analysis of the recommended technology.
5.2. Deep Learning Based on Neural Networks
This has been of great interest due to their performance in complex auto-recognition tasks in many fields of artificial intelligence, such as computer vision, expert systems, and language recognition. Moreover, the guidelines are not completely applied, and most systems rely on traditional collaborative filtering with matrix factorization techniques. The advancement of deep learning technology has been slowly applied to RS due to good characteristic representation. It can study the user-item rating of the hidden object directly for predictive recommendations without using a similarity test. Nowadays, some recommendation models are based on deep learning and tensor factorization. CNNs assistance in reducing the cold start problem or authorizing outdated schemes such as collaborative filtering and RNN container assistance, shape period-centered recommendations short of consumer empathy data and straightly forecast what consumers are able to buy based on their connected account.
Author Contributions
Conceptualization, K.I. and S.A.; Methodology, K.I. and S.A.; Software, K.I., S.A. and S.K.; Validation, K.I. and S.A.; Formal analysis, K.I., S.A. and T.R.; Investigation, S.A.; Resources, S.K. and T.R.; Data curation, S.K., and T.R.; Visualization, S.K., Writing—original draft, K.I. and S.A.; Writing—review & editing, T.R. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Acknowledgments
We are extremely indebted to Vellore Institute of Technology, Chennai for supporting us with the payment of Article Processing Charge.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Aggarwal, C.C. An Introduction to Recommender Systems Recommender Systems; Springer: Berlin, Germany, 2016; pp. 1–28. [Google Scholar]
- Ahmadian, S.; Afsharchi, M.; Meghdadi, M. An effective social recommendation method based on user reputation model and rating profile enhancement. J. Inf. Sci. 2018, 45, 607–642. [Google Scholar] [CrossRef] [Green Version]
- Ahmadian, S.; Afsharchi, M.; Meghdadi, M. A novel approach based on multi-view reliability measures to alleviate data sparsity in recommender systems. Multimed. Tools Appl. 2019, 78, 17763–17798. [Google Scholar] [CrossRef]
- Jnr, B.A. A case-based reasoning recommender system for sustainable smart city development. AI Soc. 2020, 36, 159–183. [Google Scholar] [CrossRef]
- Chandak, M.; Girase, S.; Mukhopadhyay, D. Introducing Hybrid Technique for Optimization of Book Recommender System. Procedia Comput. Sci. 2015, 45, 23–31. [Google Scholar] [CrossRef] [Green Version]
- Abinaya, S.; Devi, M.K.K.; Alphonse, A.S. Enhancing Context-Aware Recommendation Using Hesitant Fuzzy Item Clustering by Stacked Autoencoder Based Smoothing Technique. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2022, 30, 595–624. [Google Scholar] [CrossRef]
- Abinaya, S.; Devi, M.K. Enhancing top-N recommendation using stacked autoencoder in context-aware recom-mender system. Neural Process. Lett. 2021, 53, 1865–1888. [Google Scholar] [CrossRef]
- Abinaya, S.; Devi, M.K.K. Trust-Based Context-Aware Collaborative Filtering Using Denoising Autoencoder. In Pervasive Computing and Social Networking; Springer: Singapore, 2022; pp. 35–49. [Google Scholar] [CrossRef]
- Abinaya, S.; Alphonse, A.S.; Abirami, S.; Kavithadevi, M.K. Enhancing Context-Aware Recommendation Using Trust-Based Contextual Attentive Autoencoder. Neural Process. Lett. 2023, 1–22. [Google Scholar] [CrossRef]
- Ansari, A.; Li, Y.; Zhang, J.Z. Probabilistic topic model for hybrid recommender systems: A stochastic variational bayesian approach marketing science. Mark. Sci. 2018, 37, 987–1008. [Google Scholar] [CrossRef]
- Cañamares, R.; Castells, P. A probabilistic reformulation of memory-based collaborative filtering: Implications on popularity biases. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 215–224. [Google Scholar]
- Yang, C.; Bai, L.; Zhang, C.; Yuan, Q. Bridging collaborative filtering and semi-supervised learning: A neural approach for POI recommendation. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’17), New York, NY, USA, 26–29 August 2017; pp. 1245–1254. [Google Scholar]
- Cheng, H.-T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Ispir, M. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 1–4. [Google Scholar]
- Codina, V.; Ricci, F.; Ceccaroni, L. Distributional semantic pre-filtering in context-aware recommender systems. User Model. User-Adapt. Interact. 2016, 26, 1–32. [Google Scholar] [CrossRef]
- Chu, W.-T.; Tsai, Y.-L. A hybrid recommendation system considering visual information for predicting favorite restaurants. World Wide Web 2017, 20, 1313–1331. [Google Scholar] [CrossRef]
- Leng, Y.; Rudolph, L.; Pentland, A.; Zhao, J.; Koutsopolous, H. Managing travel demand: Location recommendation for system efficiency based on mobile phone data. In Proceedings of the Data for Good Exchange (D4GX), New York, NY, USA, 25 September 2016; pp. 1–8. [Google Scholar]
- Katarya, R.; Verma, O.P. A collaborative recommender system enhanced with particle swarm optimization technique. Multimed. Tools Appl. 2016, 75, 9225–9239. [Google Scholar] [CrossRef]
- Xu, J.; Yao, Y.; Tong, H.; Tao, X.; Lu, J. HoOrays: High-order optimization of rating distance for recommender systems. In Proceedings of the 23rd ACM SIGKDD, International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 525–534. [Google Scholar]
- Gómez-Pulido, J.A.; Cortés-Toro, E.; Durán-Domínguez, A.; Crawford, B.; Soto, R. Novel and classic metaheuristics for tunning a recommender system for predicting student performance in online campus. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Lecture Notes in Computer Science, Madrid, Spain, 21–23 November 2018; Springer: Berlin, Germany, 2018; pp. 125–133. [Google Scholar] [CrossRef]
- Yadhav, S.; Vikash, S.; Nagpal, S. Trust aware recommender system using swarm intelligence. J. Comput. Sci. 2018, 180–192. [Google Scholar] [CrossRef]
- Zou, L.; Xia, L.; Ding, Z.; Song, J.; Liu, W.; Yin, D. Reinforcement learning to optimize long-term user engagement in recommender systems. In Proceedings of the KDD’19: The 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2810–2818. [Google Scholar]
- Bhuvaneshwari, P.; Rao, A.N.; Robinson, Y.H. Top-N Recommendation System Using Explicit Feedback and Outer Product Based Residual CNN. Wirel. Pers. Commun. 2022, 128, 967–983. [Google Scholar] [CrossRef]
- Akter, M.; Gani, A.; Rahman, M.O.; Hassan, M.M.; Almogren, A.; Ahmad, S. Performance Analysis of Personal Cloud Storage Services for Mobile Multimedia Health Record Management. IEEE Access 2018, 6, 52625–52638. [Google Scholar] [CrossRef]
- Aldawsari, B.; Baker, T.; Asim, M.; Maamar, Z.; Al-Jumeily, D.; Alkhafajiy, M. A Survey of Resource Management Challenges in Multi-cloud Environment: Taxonomy and Empirical Analysis. Azerbaijan J. High Perform. Comput. 2018, 1, 51–65. [Google Scholar] [CrossRef]
- da Silva, E.Q.; Camilo-Junior, C.G.; Pascoal, L.M.; Rosa, T. An evolutionary approach for combining results of recom-mender systems techniques based on collaborative filtering. Expert Syst. Appl. 2016, 53, 204–218. [Google Scholar] [CrossRef]
- Choudhary, P.; Kant, V.; Dwivedi, P. A Particle Swarm Optimization Approach to Multi Criteria Recommender System Utilizing Effective Similarity Measures. In Proceedings of the 9th International Conference on Machine Learning and Computing, Association for Computing Machinery, New York, NY, USA, 24–26 February 2017; pp. 81–85. [Google Scholar] [CrossRef]
- Indira, K.; Kavitha Devi, M.K. Multi Cloud Based Service Recommendation System Using DBSCAN Algorithm. Wireless Pers. Commun. 2020, 115, 1019–1034. [Google Scholar] [CrossRef]
- Indira, K.; Kavitha Devi, M.K. Enhanced Recommender System For Managing Sparse Data In Secured Cloud For E-Business Management. Adv. Math. Sci. J. 2020, 9, 5731–5744. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}