
Community Evolution Analysis Driven by Tag Events: The Special Perspective of New Tags

Abstract
:1. Introduction
2. Related Works
3. Materials and Methods
3.1. Datasets
3.1.1. Delicious
3.1.2. CiteULike
3.1.3. Douban
3.2. Data Processing
- (1)
- Data filtering: in D, if a tag has no common resource object with any other tag, it is called a ‘wander tag.’ The left tag-resource matrix WS is used for clustering analysis after wander tags are screened out.
- (2)
- k-SVD: first, calculate SVD (singular value decomposition) of WS using WS = USVT; second, set k by finding the minimum that satisfies ; third, calculate k-SVD of WS and obtain the k-dimensional coordinate of tags and resources using WS* = UkSkVkT, where WS* is the k-order approximation of WS, and δ is set to 0.2, while λi are the diagonal elements of matrix S.
- (3)
- K-means cluster: input WS* and k, obtained from (2), as the object of the cluster analysis and group number, and calculate the K-means with the initial centroids obtained by Min–Max similarity.
3.3. Methods
3.3.1. Determinations in the Evolution Model
3.3.2. CCR Matrix
3.4. Experimental Setup
4. Results
4.1. Descriptive Statistics
4.1.1. Snapshots
4.1.2. Wander Tags
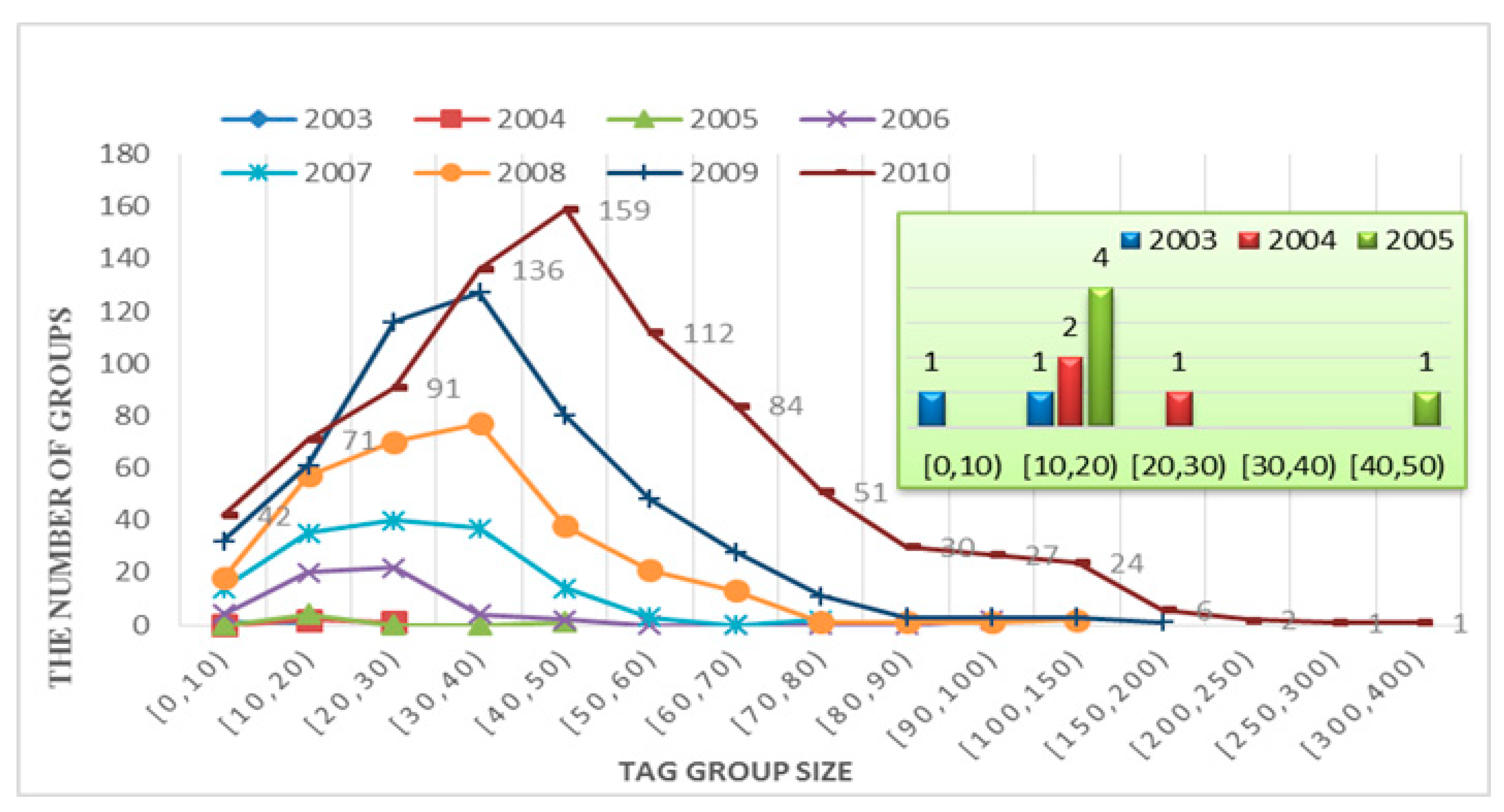
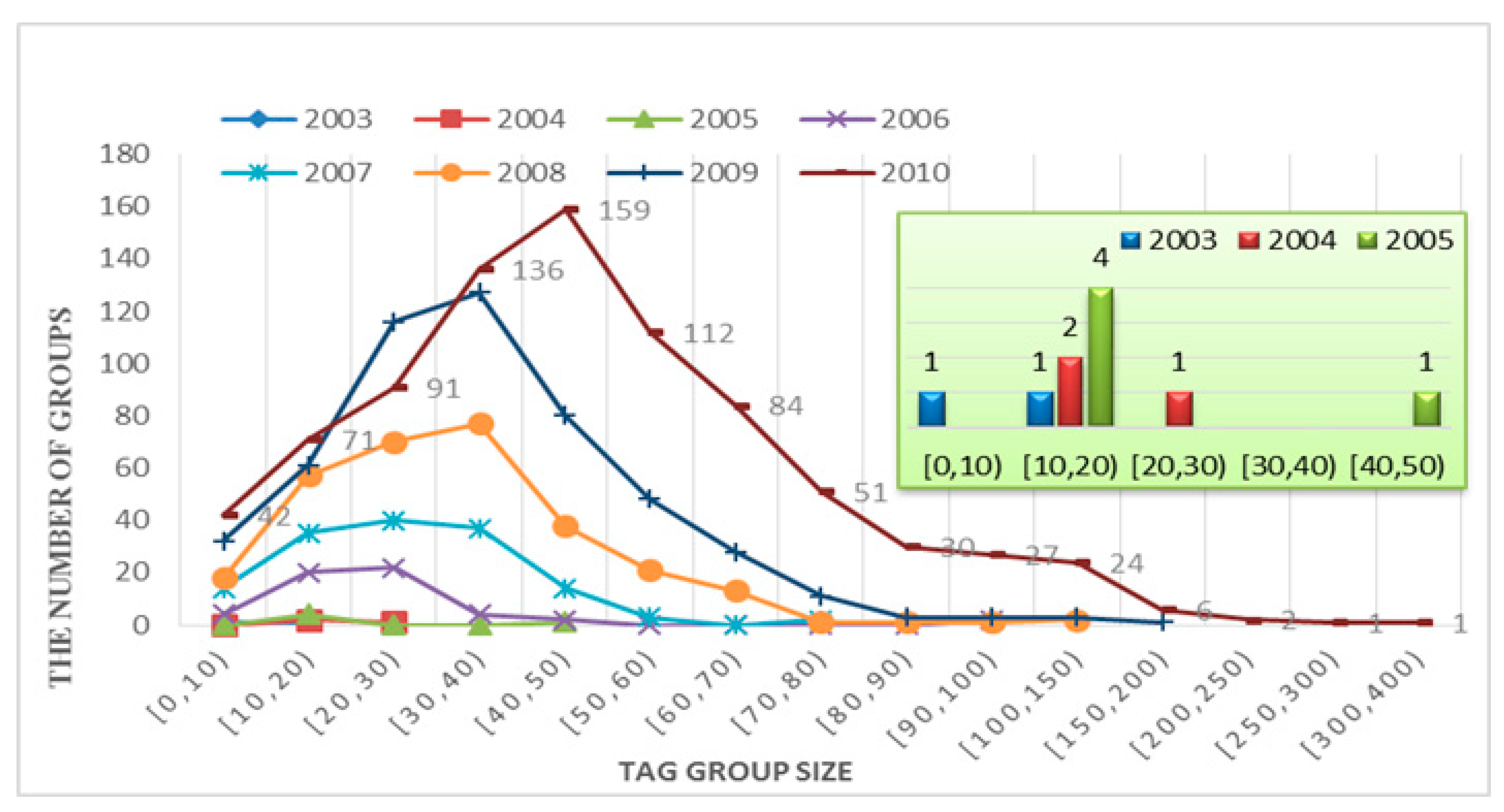
4.1.3. Growth of Tag, Group, and Group Scale
4.2. Tag Group Events in Delicious
4.2.1. Form Event and Continue Event
4.2.2. Split Event
4.2.3. Merge Event
4.2.4. Dissolve Event
4.3. Tag Individual Events in the Delicious Community
4.3.1. Appear Event
4.3.2. Leave and Join Events
4.4. Community Evolution in CiteULike and Douban
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lamere, P. Social Tagging and Music Information Retrieval. J. New Music Res. 2008, 37, 101–114. [Google Scholar] [CrossRef]
- Klašnja-Milićević, A.; Vesin, B.; Ivanović, M. Social Tagging Strategy for Enhancing E-Learning Experience. Comput. Educ. 2018, 118, 166–181. [Google Scholar] [CrossRef]
- Bródka, P.; Saganowski, S.; Kazienko, P. GED: The Method for Group Evolution Discovery in Social Networks. Soc. Netw. Anal. Min. 2013, 3, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Takaffoli, M.; Sangi, F.; Fagnan, J.; Zaïane, O.R. Community Evolution Mining in Dynamic Social Networks. Procedia Soc. Behav. Sci. 2011, 22, 48–57. [Google Scholar] [CrossRef] [Green Version]
- Ghosh, S.; Srivastava, A.; Ganguly, N. Effects of a Soft Cut-off on Node-Degree in the Twitter Social Network. Comput. Commun. 2012, 35, 784–795. [Google Scholar] [CrossRef]
- Traud, A.L.; Mucha, P.J.; Porter, M.A. Social Structure of Facebook Networks. Phys. A Stat. Mech. Its Appl. 2012, 391, 4165–4180. [Google Scholar] [CrossRef] [Green Version]
- Hu, Q.; Lin, X.; Han, S.; Li, L. An Investigation of Cross-Cultural Social Tagging Behaviours between Chinese and Americans. Eletronic Libr. 2018, 36, 103–118. [Google Scholar] [CrossRef]
- Yeung, C.M.A.; Gibbins, N.; Shadbolt, N. A Study of User Profile Generation from Folksonomies. In Proceedings of the SWKM’2008: Workshop on Social Web and Knowledge Management, Beijing, China, 20–24 April 2008. [Google Scholar]
- Saari, P.; Eerola, T. Semantic Computing of Moods Based on Tags in Social Media of Music. IEEE Trans. Knowl. Data Eng. 2014, 26, 2548–2560. [Google Scholar] [CrossRef] [Green Version]
- Yu, W.; Chen, J. Enriching the Library Subject Headings with Folksonomy. Electron. Libr. 2020, 38, 297–315. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Hofmann, T. Probabilistic Latent Semantic Indexing. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkley, CA, USA, 15–19 August 1999; pp. 50–57. [Google Scholar]
- Schiavi, G.S.; Behr, A.; Marcolin, C.B. Conceptualizing and Qualifying Disruptive Business Models. RAUSP Manag. J. 2019, 54, 269–286. [Google Scholar] [CrossRef]
- Held, C.; Kimmerle, J.; Cress, U. Learning by Foraging: The Impact of Individual Knowledge and Social Tags on Web Navigation Processes. Comput. Human Behav. 2012, 28, 34–40. [Google Scholar] [CrossRef]
- Sun, K.; Wang, X.; Sun, C.; Lin, L. A Language Model Approach for Tag Recommendation. Expert Syst. Appl. 2011, 38, 1575–1582. [Google Scholar] [CrossRef]
- Symeonidis, P.; Nanopoulos, A.; Manolopoulos, Y. A Unified Framework for Providing Recommendations in Social Tagging Systems Based on Ternary Semantic Analysis. IEEE Trans. Knowl. Data Eng. 2010, 22, 179–192. [Google Scholar] [CrossRef]
- AlAgha, I.; Abu-Samra, Y. Tag Recommendation for Short Abrabic Text by Using Latent Semantic Analysis of Wikipedia. Jordanian J. Comput. Inf. Technol. 2020, 6, 165–180. [Google Scholar]
- Leskovec, J.; Lang, K.J.; Dasgupta, A.; Mahoney, M.W. Statistical Properties of Community Structure in Large Social and Information Networks. In Proceedings of the 17th International Conference on World Wide Web (WWW’08), Beijing, China, 21–25 April 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 695–704. [Google Scholar]
- Mislove, A.; Marcon, M.; Gummadi, K.P.; Druschel, P.; Bhattacharjee, B. Measurement and Analysis of Online Social Networks. In Proceedings of the 7th ACM SIGCOMM Conference on Internet Measurement, San Diego, CA, USA, 24–26 October 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 29–42. [Google Scholar]
- Guan, T.; He, Y.; Gao, J.; Yang, J.; Yu, J. On-Device Mobile Visual Location Recognition by Integrating Vision and Inertial Sensors. IEEE Trans. Multimed. 2013, 15, 1688–1699. [Google Scholar] [CrossRef]
- Li, Y.-M.; Lai, C.-Y.; Chen, C.-W. Identifying Bloggers with Marketing Influence in the Blogosphere. In Proceedings of the 11th International Conference on Electronic Commerce, Taipei, Taiwan, 12–15 August 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 335–340. [Google Scholar]
- Jain, L.; Katarya, R. Discover Opinion Leader in Online Social Network Using Firefly Algorithm. Expert Syst. Appl. 2019, 122, 1–15. [Google Scholar] [CrossRef]
- Nguyen, N.P.; Dinh, T.N.; Shen, Y.; Thai, M.T. Dynamic Social Community Detection and Its Applications. PLoS ONE 2014, 9, e91431. [Google Scholar] [CrossRef]
- Kaur, W.; Balakrishnan, V.; Rana, O.; Sinniah, A. Liking, Sharing, Commenting and Reacting on Facebook: User Behaviors’ Impact on Sentiment Intensity. Telemat. Inform. 2019, 39, 25–36. [Google Scholar] [CrossRef]
- Hopp, T.; Santana, A.; Barker, V. Who Finds Value in News Comment Communities? An Analysis of the Influence of Individual User, Perceived News Site Quality, and Site Type Factors. Telemat. Inform. 2018, 35, 1237–1248. [Google Scholar] [CrossRef]
- Yang, J.; Wang, J. Tag Clustering Algorithm LMMSK: Improved K-Means Algorithm Based on Latent Semantic Analysis. J. Syst. Eng. Electron. 2017, 28, 374–384. [Google Scholar] [CrossRef]
- Newman, M.E.J. Assortative Mixing in Networks. Phys. Rev. Lett. 2002, 89, 208701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.-G. A Network Evolution Model Based on Community Structure. Neurocomputing 2015, 168, 1037–1043. [Google Scholar] [CrossRef]
- Danon, L.; Díaz-Guilera, A.; Duch, J.; Arenas, A. Comparing Community Structure Identification. J. Stat. Mech. Theory Exp. 2005, P09008. [Google Scholar] [CrossRef] [Green Version]
- White, S.; Smyth, P. A Spectral Clustering Approach to Finding Communities in Graphs. In Proceedings of the 2005 SIAM International Conference on Data Mining (SDM), Newport Beach, CA, USA, 21–23 April 2005; Kargupta, H., Srivastava, J., Kamath, C., Goodman, A., Eds.; SIAM Publications Library: Newport Beach, CA, USA, 2005; pp. 274–285. [Google Scholar]
- Hopcroft, J.; Khan, O.; Kulis, B.; Selman, B. Tracking Evolving Communities in Large Linked Networks. Proc. Natl. Acad. Sci. USA 2004, 101, 5249–5253. [Google Scholar] [CrossRef] [Green Version]
- Chakrabarti, D.; Kumar, R.; Tomkins, A. Evolutionary Clustering. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; Eliassi-Rad, T., Ungar, L., Graven, M., Gunopulos, D., Eds.; Association for Computing Machinery: New York, NY, USA, 2006; pp. 554–560. [Google Scholar]
- Li, X.; Chen, G. A Local-World Evolving Network Model. Phys. A Stat. Mech. Its Appl. 2003, 328, 274–286. [Google Scholar] [CrossRef]
- Graham, I.; Matthai, C.C. Investigation of the Forest-Fire Model on a Small-World Network. Phys. Rev. E Stat. Nonlinear Soft Matter Phys. 2003, 68, 36109. [Google Scholar] [CrossRef] [Green Version]
- Jin, E.M.; Girvan, M.; Newman, M.E.J. The Structure of Growing Social Networks. Phys. Rev. E 2001, 64, 046132. [Google Scholar] [CrossRef] [Green Version]
- Deng, Z.-H.; Qiao, H.-H.; Song, Q.; Gao, L. A Complex Network Community Detection Algorithm Based on Label Propagation and Fuzzy C-Means. Phys. A Stat. Mech. Its Appl. 2019, 519, 217–226. [Google Scholar] [CrossRef]
- Garza, S.E.; Schaeffer, S.E. Community Detection with the Label Propagation Algorithm: A Survey. Phys. A Stat. Mech. Its Appl. 2019, 534, 122058. [Google Scholar] [CrossRef]
- Guan, T.; He, Y.; Duan, L.; Yang, J.; Gao, J.; Yu, J. Efficient BOF Generation and Compression for On-Device Mobile Visual Location Recognition. IEEE Multimed. 2014, 21, 32–41. [Google Scholar] [CrossRef]
- Asur, S.; Parthasarathy, S.; Ucar, D. An Event-Based Framework for Characterizing the Evolutionary Behavior of Interaction Graphs. ACM Trans. Knowl. Discov. Data 2009, 3, 16. [Google Scholar] [CrossRef]
- Xu, Z.; Rui, X.; He, J.; Wang, Z.; Hadzibeganovic, T. Superspreaders and Superblockers Based Community Evolution Tracking in Dynamic Social Networks. Knowl.-Based Syst. 2020, 192, 105377. [Google Scholar] [CrossRef]
- Qiao, S.; Han, N.; Gao, Y.; Li, R.-H.; Huang, J.; Sun, H.; Wu, X. Dynamic Community Evolution Analysis Framework for Large-Scale Complex Networks Based on Strong and Weak Events. IEEE Trans. Syst. Man Cybern. Syst. 2020, 51, 6229–6243. [Google Scholar] [CrossRef]
- Palla, G.; Barabási, A.-L.; Vicsek, T. Quantifying Social Group Evolution. Nature 2007, 446, 664–667. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Wang, C.; Li, X.; Gao, C.; Li, X.; Zhu, J. Evolutionary Markov Dynamics for Network Community Detection. IEEE Trans. Knowl. Data Eng. 2022, 34, 1206–1220. [Google Scholar] [CrossRef]
- Saganowski, S.; Bródka, P.; Kazienko, P. Community Evolution. In Encyclopedia of Social Network Analysis and Mining; Alhajj, R., Rokne, J., Eds.; Springer: New York, NY, USA, 2017; pp. 1–14. [Google Scholar]
- Takaffoli, M.; Sangi, F.; Fagnan, J.; Zaïane, O.R. Modec-Modeling and Detecting Evolutions of Communities. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011; The AAAI Press: Menlo Park, CA, USA, 2011; pp. 626–629. [Google Scholar]
- Takaffoli, M.; Sangi, F.; Fagnan, J.; Zaïane, O.R. A Framework for Analyzing Dynamic Social Networks. Available online: http://webdocs.cs.ualberta.ca/~zaiane/postscript/ASNA10.pdf (accessed on 6 June 2022).
- Asur, S.; Parthasarathy, S. A Viewpoint-Based Approach for Interaction Graph Analysis. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; Association for Computing Machinery: New York, NY, USA, 2009; pp. 79–87. [Google Scholar]
- Papadopoulos, S.; Kompatsiaris, Y.; Vakali, A.; Spyridonos, P. Community Detection in Social Media Performance and Application Considerations. Data Min. Knowl. Discov. 2012, 24, 515–554. [Google Scholar] [CrossRef]
- Rossetti, G.; Cazabet, R. Community Discovery in Dynamic Networks: A Survey. ACM Comput. Surv. 2018, 51, 35. [Google Scholar] [CrossRef] [Green Version]
- Dakiche, N.; Benbouzid-Si Tayeb, F.; Slimani, Y.; Benatchba, K. Tracking Community Evolution in Social Networks: A Survey. Inf. Process. Manag. 2019, 56, 1084–1102. [Google Scholar] [CrossRef]
- Trainer, H.M.; Jones, J.M.; Pendergraft, J.G.; Maupin, C.K.; Carter, D.R. Team Membership Change “Events”: A Review and Reconceptualization. Gr. Organ. Manag. 2020, 45, 219–251. [Google Scholar] [CrossRef] [Green Version]
- Kane, A.A.; Rink, F. How Newcomers Influence Group Utilization of Their Knowledge: Integrating versus Differentiating Strategies. Gr. Dyn. 2015, 19, 91–105. [Google Scholar] [CrossRef]
- Rink, F.; Kane, A.A.; Ellemers, N.; van der Vegt, G. Team Receptivity to Newcomers: Five Decades of Evidence and Future Research Themes. Acad. Manag. Ann. 2013, 7, 247–293. [Google Scholar] [CrossRef]
- Beus, J.M.; Jarrett, S.M.; Taylor, A.B.; Wiese, C.W. Adjusting to New Work Teams: Testing Work Experience as a Multidimensional Resource for Newcomers. J. Organ. Behav. 2013, 35, 489–506. [Google Scholar] [CrossRef]
- Cantador, I.; Brusilovsky, P.; Kuflik, T. 2nd Workshop on Information Heterogeneity and Fusion in Recommender Systems (HetRec2011). In Proceedings of the 5th ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 387–388. [Google Scholar]
- Wang, H.; Chen, B.; Li, W.J. Collaborative Topic Regression with Social Regularization for Tag Recommendation. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; Rossi, F., Ed.; AAAI Press: Palo Alto, CA, USA, 2013; pp. 2719–2725. [Google Scholar]
- Mohammadmosaferi, K.K.; Naderi, H. Evolution of Communities in Dynamic Social Networks: An Efficient Map-Based Approach. Expert Syst. Appl. 2020, 147, 113221. [Google Scholar] [CrossRef]
- Ye, X.; Qiao, S.; Han, N.; Yue, K.; Wu, T.; Yang, L.; Huang, F.; Yuan, C. Algorithm for Detecting Anomalous Hosts Based on Group Activity Evolution. Knowl.-Based Syst. 2021, 214, 106734. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, H. Evolvement Procession of Innovation Networks for Strategic Emerging Industries: Based on Life Cycle Curve and Social Network Method. Rev. Tec. Fac. Ing. Univ. Zulia 2016, 39, 231–237. [Google Scholar] [CrossRef]
- Gu, Y. How Long Can Facebook Survive? Complex Physics Model for Predicting the Life Cycle of Social Network. Int. J. Web Appl. 2013, 5, 46–48. [Google Scholar]
- Park, S.; Grosser, T.J.; Roebuck, A.A.; Mathieu, J.E. Understanding Work Teams From a Network Perspective: A Review and Future Research Directions. J. Manag. 2020, 46, 1002–1028. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group Index | ||||
|---|---|---|---|---|
| 4 | 0 | 0 | 0 | |
| 0 | 3 | 1 | 8 | |
| 0 | 3 | 5 | 0 | |
| N3-4 | 1 | 16 | 12 | 4 |
| Period | Merge Event | |
|---|---|---|
| 2006–2007 | (12, 52, 54)->18 | 0.72 |
| (16, 30)->32 | 0.59 | |
| (13, 25)->76 | 0.77 | |
| 2007–2008 | (42, 145)->59 | 0.41 |
| 2008–2009 | (19, 33)->95 | 0.85 |
| (49, 204)->218 | 0.65 | |
| (149, 279)->246 | 0.52 | |
| (106, 170, 300)->267 | 0.60 | |
| 2009–2010 | (22, 470)->247 | 0.49 |
| (233, 428)->495 | 0.70 | |
| (350, 511)->586 | 0.71 |
| Period | Dissolved Groups |
|---|---|
| 2006–2007 | Books/remediation/opinion/caf?/society |
| 2007–2008 | online_education/keyphrase/gtd/raamattu/briefing/educacion |
| 2008–2009 | Constructions/nurturing/rockmelt |
| 2009–2010 | Heroes/supybot/visualnotetaking/vizthink/colorspace |
| higher-education/facebookplaces/rss-feedservices/ customer_service/html5rocks | |
| base_de_datos/rapidprototyping/Nings/minmal/scarf/esr/ alcohol_quiz /melatonin/szerver/deleted/dabbleboard/er/ primarysources/arthistory/chrismerritt/enewsletter/cthulhu | |
| webdev/glossy/finally/hmm/martial_arts/krav_maga/ Vietnamese/location_aware/unit_testing/scrollbar/tolisten/ opensso/jsync/iframe/recursosonline/httperf | |
| forms/omfg/migrant/venn/fractalart/twitrank/ latinoaménica/sweets/rsg/meegenius/thirdspace /dickflash/ photoediting/ obit /fast-flux/web20_tools/lesson_ideas | |
| thinking/a_z_listed_resources/tables/company/drhorrible/ hiring/objectives/frontend/empresa_20/servicedesign/ Ogilvy/pylons/defragmentation | |
| glitch/gettext/localization/=-o | |
| oauth/informationisbeautiful | |
| Mod#isation/zbrush/failcamp/econmicgrowth/ life_monitoring | |
| templates/awards/certificates |
| Former-D | Later-D |
|---|---|
| Constructions Nurturing Rockmelt | Doe/constructions/alternative_assessment/critical-infrastructure/recycle_mckinney/sch#ze/localization/naxos/several/coherence/cheapo/cipav/green-business/g13n |
| Digitalfootprints/meta/calendar/facture/charles_brokoski/ical/blemnder/babilonia/element/referencias/rsstools/schemas/nurturing/charlotte/lawenforcement/Susie/redcarpet/webcal/numanuma/udelljon/fandom/icalendar/gruffrhys/hops/neil-freeman/calendar-swamp/udell/tent/anti-marketing/ | |
| attention_economy/packages/architects_netherlands/intellisense/hal/Sherlock/fromjenblacker/Silos/firefly/debian/Barclays/agencymap/thebeatles/expertise/????/pop/sbir/rightclick/pd108munin/description/rockmelt/know-why/know-what |
| Time | Coefficients Related to Scale Variation | |
|---|---|---|
| With Leave | With Join | |
| 2003–2004 | 0.1889822 | 0.9449112 |
| 2004–2005 | −0.718132 | −0.262071 |
| 2005–2006 | −0.401565 | 0.9754618 |
| 2006–2007 | 0.1023321 | 0.9727505 |
| 2007–2008 | 0.26323 | 0.9496789 |
| 2008–2009 | 0.3019457 | 0.9340135 |
| 2009–2010 | 0.0729574 | 0.9816468 |
| Period | CiteULike | Douban | |
|---|---|---|---|
| From T1/2017 to T2/2018 | 68.35% | 52.64% | |
| From T2/2018 to T3/2019 | 84.26% | 69.72% | |
| Supplement: New tags’ proportion in consequents of Form and Split events (2018–2019 in Douban) | |||
| Form events | New tags in Form consequents | Split events’ antecedents | New tags in Split consequents |
| 3 | 95.00% | 2 | 77.92% |
| 7 | 95.24% | 4 | 73.66% |
| 28 | 93.55% | 5 | 65.52% |
| 78 | 77.78% | 6 | 71.13% |
| 87 | 83.33% | 8 | 64.96% |
| 92 | 95.00% | 9 | 82.86% |
| 93 | 88.89% | 11 | 51.47% |
| Average | 89.83% | 12 | 67.52% |
| 13 | 69.66% | ||
| 15 | 70.51% | ||
| 16 | 72.89% | ||
| 17 | 48.39% | ||
| 19 | 66.67% | ||
| 22 | 92.50% | ||
| 24 | 70.21% | ||
| Average | 69.72% | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, J.; Wang, J.; Gao, M. Community Evolution Analysis Driven by Tag Events: The Special Perspective of New Tags. Mathematics 2023, 11, 1361. https://doi.org/10.3390/math11061361
Yang J, Wang J, Gao M. Community Evolution Analysis Driven by Tag Events: The Special Perspective of New Tags. Mathematics. 2023; 11(6):1361. https://doi.org/10.3390/math11061361
Chicago/Turabian StyleYang, Jing, Jun Wang, and Mengyang Gao. 2023. "Community Evolution Analysis Driven by Tag Events: The Special Perspective of New Tags" Mathematics 11, no. 6: 1361. https://doi.org/10.3390/math11061361