1. Introduction
Feature extraction is an important part of pattern recognition. Therefore, extracting the required features accurately and effectively has always been a concern of researchers [
1,
2,
3]. In recent years, researchers have successfully discovered the inherent features of low-dimensional nonlinear manifold structures and put forward some relevant algorithms [
4,
5]. For example, the classical algorithm locality preserving projections (LPP) [
6] is widely applied in feature extraction. However, because LPP is an algorithm based on a one-dimensional vector, it is easy to encounter unusual problems in its solution process. Therefore, scholars have proposed the two-dimensional locally preserving projection (2DLPP) [
7] algorithm. 2DLPP directly replaces 1D vectors with 2D image matrices. Although the 2DLPP algorithm can process sample data more effectively than the LPP algorithm, its disadvantage is that it cannot use class label information to classify. The two-dimensional discriminant locally preserving projection (2DDLPP) [
8] algorithm proposed by Zhi et al. adds the inter-class scatter matrix and the intra-class discriminant matrix to the objective function of 2DLPP. Although the 2DDLPP algorithm improves the accuracy of image recognition, it is still restricted by the problem of small sample size when processing high dimensional data. In the practical application of face feature extraction, the facial image has high dimensional characteristics, but due to the influence of computer storage capacity and shooting permission, the number of samples that can be used for classification training is far less than the sample dimension. This is a classic small sample size problem. Limited by the SSS problem, the generalization ability of the 2DDLPP algorithm is not strong, and feature extraction ability is also affected, which leads to certain limitations in its application scope. Therefore, the SSS problem has become urgent in the field of feature extraction of high dimensional data.
In recent years, the matrix exponential has been of interest to researchers and widely used to solve the small sample size problem in scientific computing. Firstly, in order to solve the SSS problem of the linear discriminant analysis (LDA) algorithm [
9], researchers pre-processed the sample data with the principal component analysis (PCA) algorithm [
10], but some important feature information would be lost in this way. Therefore, the exponential discriminant analysis (EDA) [
11] algorithm proposed by Zhang et al. used the matrix exponential to address this problem skillfully. Considering that LPP may encounter the same problem as LDA when the sample size is smaller than the sample dimension, singularity of the matrix will be caused. Therefore, Wang et al. integrated LPP with the matrix exponential, and then proposed the exponential locality preserving projection (ELPP) [
12] algorithm, with better performance. Similarly, exponential local discriminant embedding (ELDE) [
13] overcomes the SSS problem of local discriminant embedding (LDE) [
14] by invoking the matrix exponential. Matrix exponential based discriminant locality preserving projections (MEDLPP) [
15] introduce the matrix exponential into discriminant locality preserving projections (DLPP) to solve the small sample size problem, with corresponding improvements to shorten running time. In reference [
16], the matrix exponential is added to the accelerating algorithm and incremental algorithm of large-scale semi-supervised discriminant embedding. In view of this, we use the matrix exponential to solve the SSS problem of 2DDLPP.
At present, sparse algorithms are one of the important research directions in feature extraction. In the process of sparse learning,
and
norms are used to optimally represent the relationship between samples and features, drawing on the idea of regression analysis. This process can not only simplify the data but also retain the key information [
17,
18,
19,
20]. By integrating sparse representation with classical algorithms, many new algorithms have been proposed. Recently, Zhang et al. proposed a new unsupervised feature extraction method, joint sparse representation and local preserving projection (JSRLPP) [
21], which integrates a graph structure and projection matrix into a general framework to learn graphs that are more suitable for feature extraction. The performance of traditional
and
norms are reduced by ignoring local geometric structure in addressing the SSS problem. Similarly, Liu et al. not only used
and
norms for joint sparse regression but also used capped the
norm in the loss function of the locality preserving robust regression (LPRR) [
22] algorithm to further enhance its robustness, achieving good intelligibility and quality. Therefore, in this paper, we use elastic net regression integrated with other algorithms for sparse feature extraction.
According to reference [
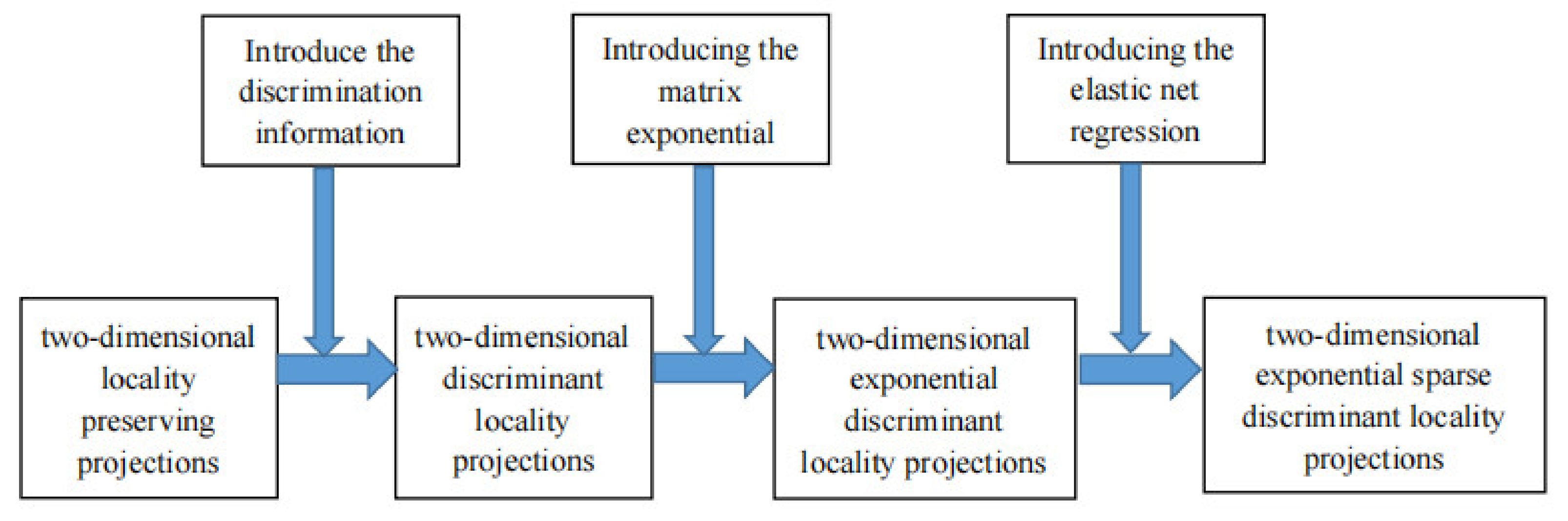
23], 2D methods are not always superior to 1D methods. Although the 2DDLPP algorithm is simple and efficient, it performs poorly with limited training samples. When the dimension of the samples exceeds the sample size, singularity of the matrix will be generated. It also appears to have limitations in some public databases. In summary, we propose the two-dimension exponential sparse discriminant local preserving projection (2DESDLPP) algorithm in this paper, which adds matrix exponential into the 2DDLPP objective function to improve performance. Based on the property of the matrix function, 2DDLPP is reconstructed using the generalized matrix exponential function. If 2DESDLPP first uses PCA to reduce the dimension of the image data, it will lead to the loss of a large amount of effective feature information and reduce the recognition performance of the 2DESDLPP algorithm. The matrix exponential function avoids the singular divergence matrix in the generalized eigenvalue problem of the 2DDLPP algorithm by ensuring the orthogonality of the basis vector obtained, so as to solve the SSS problem. Then, for each test sample, Euclidean distance is used to measure the similarity relationship between the test sample and each training sample, and as the weight of the training sample, in order to form a weighted training sample set. This is equivalent to transforming the original image to another new subspace, using distance diffusion mapping that further widens the margins between labels. After solving the small sample problem, each row (or column) of the 2D face image is then treated as a separate vector using the 2D expansion form of elastic net regression, and these vectors are then used as independent model units to perform the corresponding vector-based regression in order to obtain the optimal sparse projection matrix. Finally, experiments were conducted on three face databases, ORL, Yale and AR, to verify the effectiveness of the algorithm by comparing the average recognition rate with two 1D algorithms (ELPP and MEDLPP) and five other 2D algorithms (2DPCA, 2DLDA, 2DLPP, 2DDLPP and 2DEDLPP). The development route for 2DESDLPP is shown in
Figure 1 below.
The main contributions of the algorithm we propose are as follows:
- (1)
The 2DESDLPP algorithm not only retains the classification information between samples satisfactorily, but also solves the SSS problem of the 2DDLPP algorithm by integrating matrix exponential.
- (2)
We use the idea of sparse feature extraction not only to obtain the optimal projection matrix through the 2D extended form of elastic net regression. but also to reduce the computational complexity of 2DESDLPP.
- (3)
The 2DESDLPP algorithm can widen the distance between category labels and discriminate the identification information contained in the zero space, so it has higher recognition accuracy.
The content of this paper is arranged as follows. We briefly review three underlying algorithms, namely 2DDLPP, matrix exponential and elastic net regression, in
Section 2.
Section 3 describes the proposed 2DESDLPP in detail.
Section 4 is composed of seven experiments designed to evaluate our 2DESDLPP algorithm. Finally,
Section 5 provides conclusions.
2. Introduction of Underlying Algorithms
Assume that
is a training sample set, among which
is the amount of training sample images whose size is
dimension. We aim to map the initial space sized
into the space sized
by means of a linear transformation, where
. Let
be the matrix sized
, where
is a cell column vector. The projection applied to each data is as follows:
Each whose size is dimension is mapped through the projection matrix to obtain matrix whose size is dimension.
2.1. 2DDLPP Algorithm
2DDLPP minimizes intra-class distances and maximizes inter-class distances by adding inter-class dispersion constraints and class label discriminant information to the 2DLPP objective function. Suppose
are the class labels of
, among which
is the amount of
.
and
represent the
class projection image matrix of the original images. According to reference [
9], we know that the 2DDLPP objective function is defined as follows:
where
and
are both weight matrices. The sample size of the category
is
, and
is the mean value matrix of the projection matrix of category
and
samples, respectively:
Referring to the algorithm idea of 2DDLPP, the 2DESDLPP algorithm proposed in this paper not only ensures that adjacent points maintain a neighborhood relationship after projection to maintain local information for the data, but also makes full use of label information of data features to narrow the distance between data in the same category and to increase the distance between data in different labels, which is more favorable for feature extraction.
2.2. Matrix Exponential
A square matrix
whose size is
dimension is given. Its matrix exponential is shown below:
is a unit matrix whose size is dimension. The properties of an exponential matrix are as follows:
- (1)
is the sum of a finite matrix sequence.
- (2)
is the full rank matrix.
- (3)
Supposing that matrix and matrix are commutative, like , then we can have .
- (4)
Assuming that the matrix is non-singular, we have .
- (5)
For every eigenvector of that corresponded to eigenvalues , with as eigenvalues of having the same eigenvectors, then the matrix is non-singular.
The introduction of the matrix exponential function not only solves the SSS problem of the 2DDLPP algorithm, but also stretches the distance between different categories of samples, which makes the algorithm achieve better classification ability in the face of recognition tasks.
2.3. Elastic Net Regression
Suppose there are datasets
, where
is the sample size.
are the independent variables corresponding to the
observations.
is the number of columns of
.
are corresponding variables. Its regression model is defined as:
If
,
, then
Here are the penalty parameters, is the variable coefficient, and is the constant term, which can be generally ignored in the penalty function, because the constant term does not affect the regression coefficient. Thus, the regular term of Elastic Net regression is a convex linear combination of the regular terms of Lasso regression and Ridge regression. When , it is the Ridge regression algorithm. When , it is the Lasso regression algorithm. 2DESDLPP uses the elastic net regression method for face recognition and classification. After sparse representation of the elastic net, the problem of feature information redundancy can be solved, which not only reduces the computational complexity of the 2DESDLPP algorithm, but also shortens its running time, and greatly improves the efficiency of face recognition.
3. Two-Dimensional Exponential Sparse Discriminant Local Preserving Projections
The 2DDLPP algorithm uses two-dimensional images to represent data, which is beneficial in maintaining discriminant information about the local manifold structure of the data. Although it has been successfully applied in many fields, matrix-based methods do not always outperform vector-based methods, even with limited training samples. There may be a lot of redundant information in the retained features of the 2DDLPP algorithm, which requires a high computational cost. To address the above problems, we propose a new algorithm, two-dimensional exponential sparse discriminant local preserving projections (2DESDLPP), for feature extraction. This allows for the selection of salient features that fit the current pattern from the abundant features in the original data, in order to find a minimal subset of the original set of features for an optimal representation of the data.
Firstly, according to Equation (1), the molecule of Equation (2) can be simplified as:
Here,
is the weight matrix between any two samples in the
class, which is defined as follows:
Consisting of the diagonal matrix, is the sum of the rows or columns of , . The symbol represents the Kronecker product of a matrix. For the point, the larger value of , the more important is , because matrix provides a natural measure of the data point corresponding to raw images. is a Laplace matrix, .
Next, the denominator of Equation (2) is simplified similarly:
is the mean value matrix of the sample, . is the weight of the means of any two kinds of sample, , while is an adjustable positive parameter. Consisting of the diagonal matrix is the sum of the rows or columns of , . is a Laplace matrix, .
Substituting the simplified Equation (7) as well as Equation (8) into Equation (2), the objective function of 2DDLPP is:
Minimizing Equation (10), then we can obtain:
Next, the matrix exponential and sparse constraint are added to Equation (11) to obtain the objective function of 2DESDLPP as:
The number of non-zero elements in matrix
is
,
. Therefore,
is the sparse constraint on matrix
, using the elastic net regression. Equation (12) does not have a solution in a closed form, so it can be expressed more simply:
Inspired by the 2D-MELPP algorithm in reference [
24], we solve the eigenvalues of Equation (13) to obtain its solution.
After orthogonalizing the projection matrix
, we can achieve:
where
is the eigenvalue and
is the eigenvector corresponding to
. Then, we take the eigenvectors corresponding to the first
minimum non-zero eigenvalues of Equation (15) and combine them to obtain the projection matrix
.
According to the properties of the matrix exponential, and are both full rank matrices. That is, even in the case of SSS problems, and are non-singular, although and are still singular. Therefore, 2DESDLPP can extract the identification information contained in the null space.
However, the resulting projection matrix
is not the sparsest at present. Therefore, we take a 2D extension of elastic net regression by treating each row (or column) of a 2D face image as a separate vector and then use these vectors as independent model units for the corresponding vector-based regression. That is:
Now, the optimal sparse projection matrix obtained not only has higher recognition accuracy, because it is based on the image matrix, but also has a reduced computational complexity. Next, we will carry out the specific analysis.
The time complexity of calculating and is . Therefore, for the eigenvalue problem of Equation (15), the complexity of the operation is also the same. Then, after sparse processing of Equation (16), the calculation complexity is reduced to . Finally, the whole time complexity of the 2DESDLPP algorithm is , while the calculation complexity of 2DEDLPP is .
4. Results and Analysis of the Experiment
The experiments in feature extraction were conducted on the three public face databases, ORL, Yale and AR, using Euclidean distance and nearest neighbor classifiers. Then we compared the performance of several other algorithms (ELPP, MEDLPP, 2DPCA, 2DLDA, 2DLPP, 2DDLPP and 2DEDLPP) to verify the effectiveness of the 2DESDLPP algorithm proposed. In the experiments, we resized the images in each face database to 50 × 40 to reduce the amount of computer memory used, and randomly selected images for each person as training samples. The rest were used as test samples.
We first set
, which is used to count the number of non-zero elements in the projection matrix, and the number of training samples was six. Then, a comparison experiment was conducted with the original images with a size of 92 × 112, and the resized images with a size of 50 × 40, in the ORL database to test how the accuracy of the 2DESDLPP algorithm depends on the size of the training sample. Finally, the comparison results are recorded in
Table 1.
It can be seen from
Table 1 that the size of the training sample has little influence on the accuracy of the 2DESDLPP algorithm, and its variation range is within 0.5, which is acceptable.
4.1. Experiments to Determine the Value of K
First of all, we set
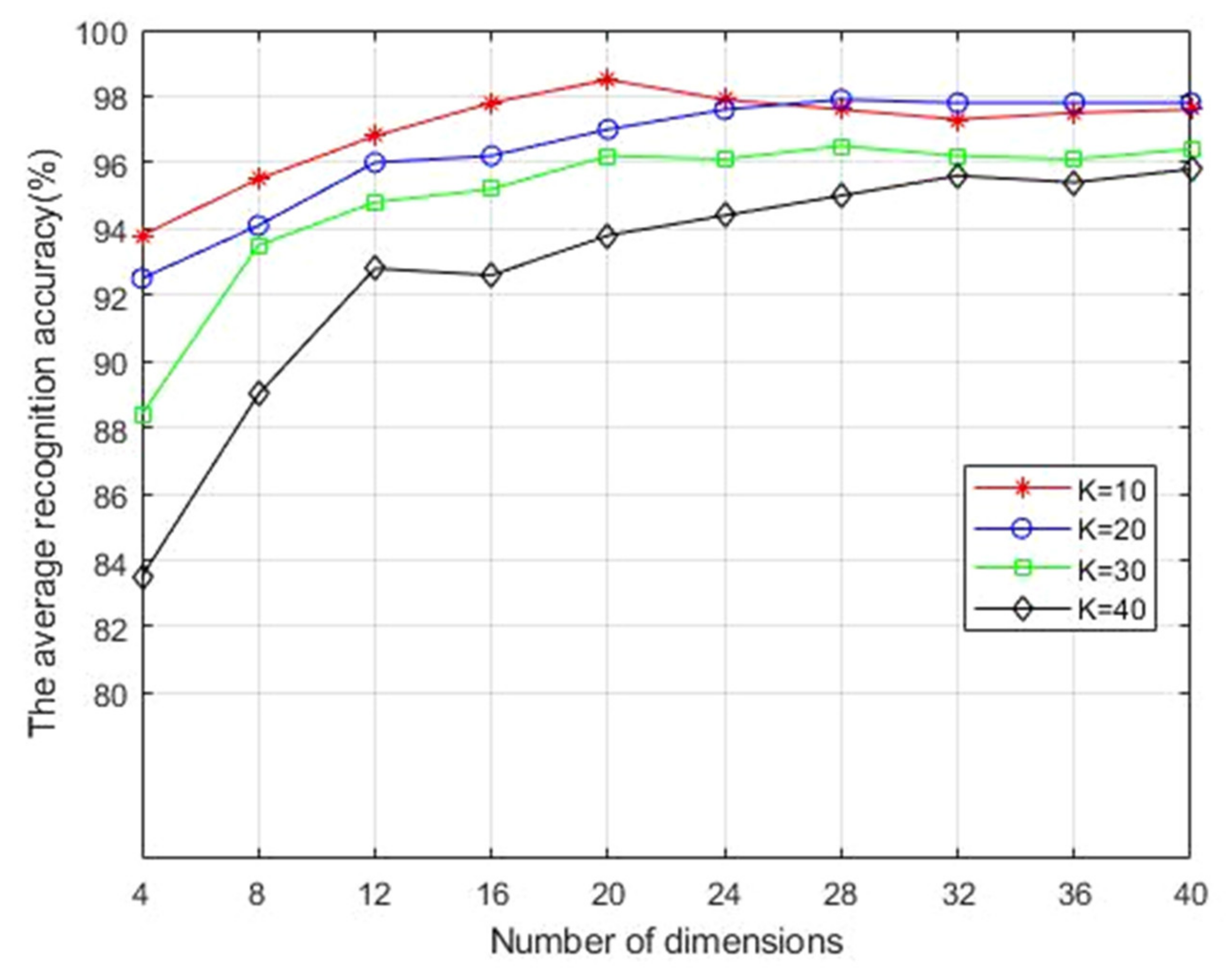
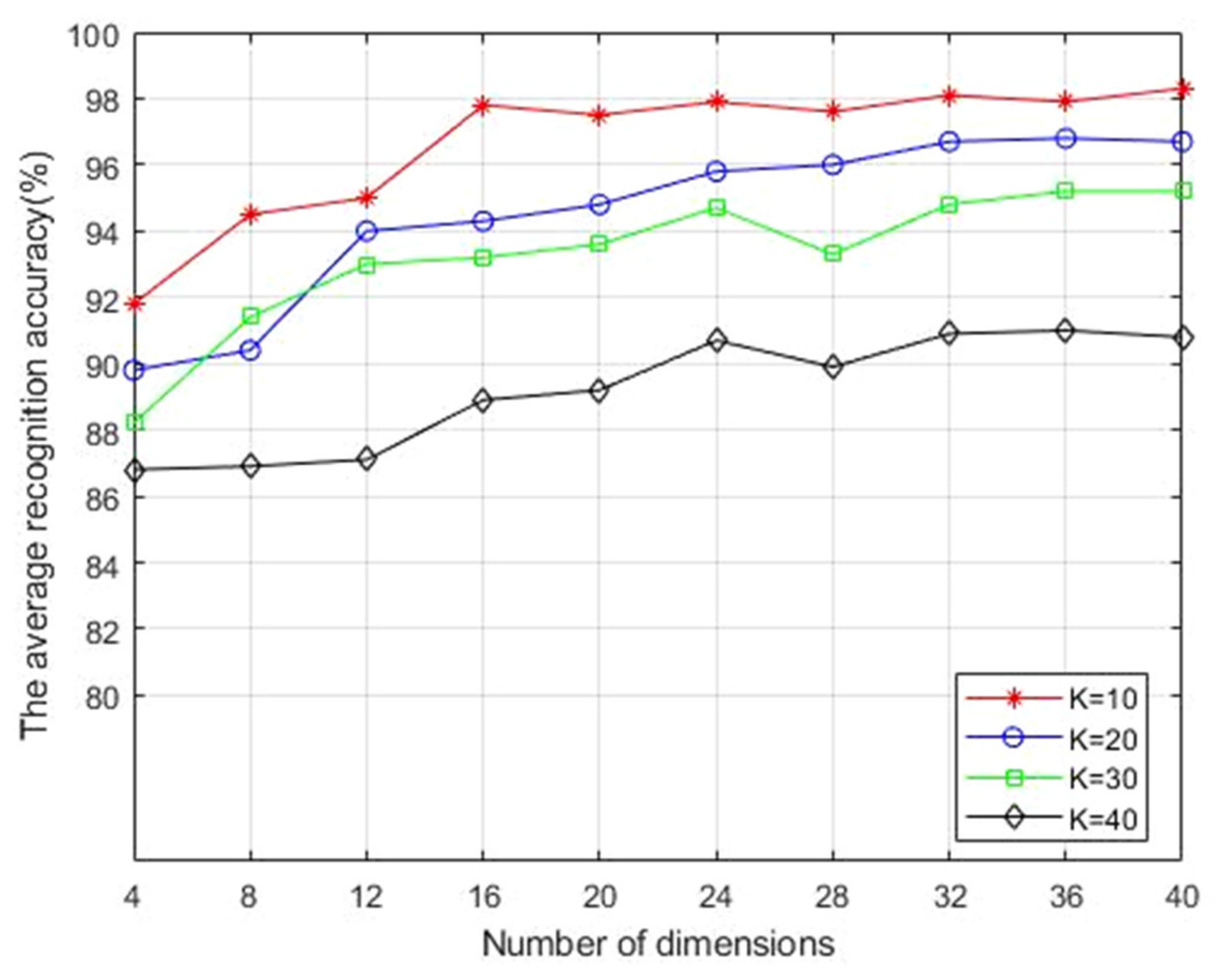
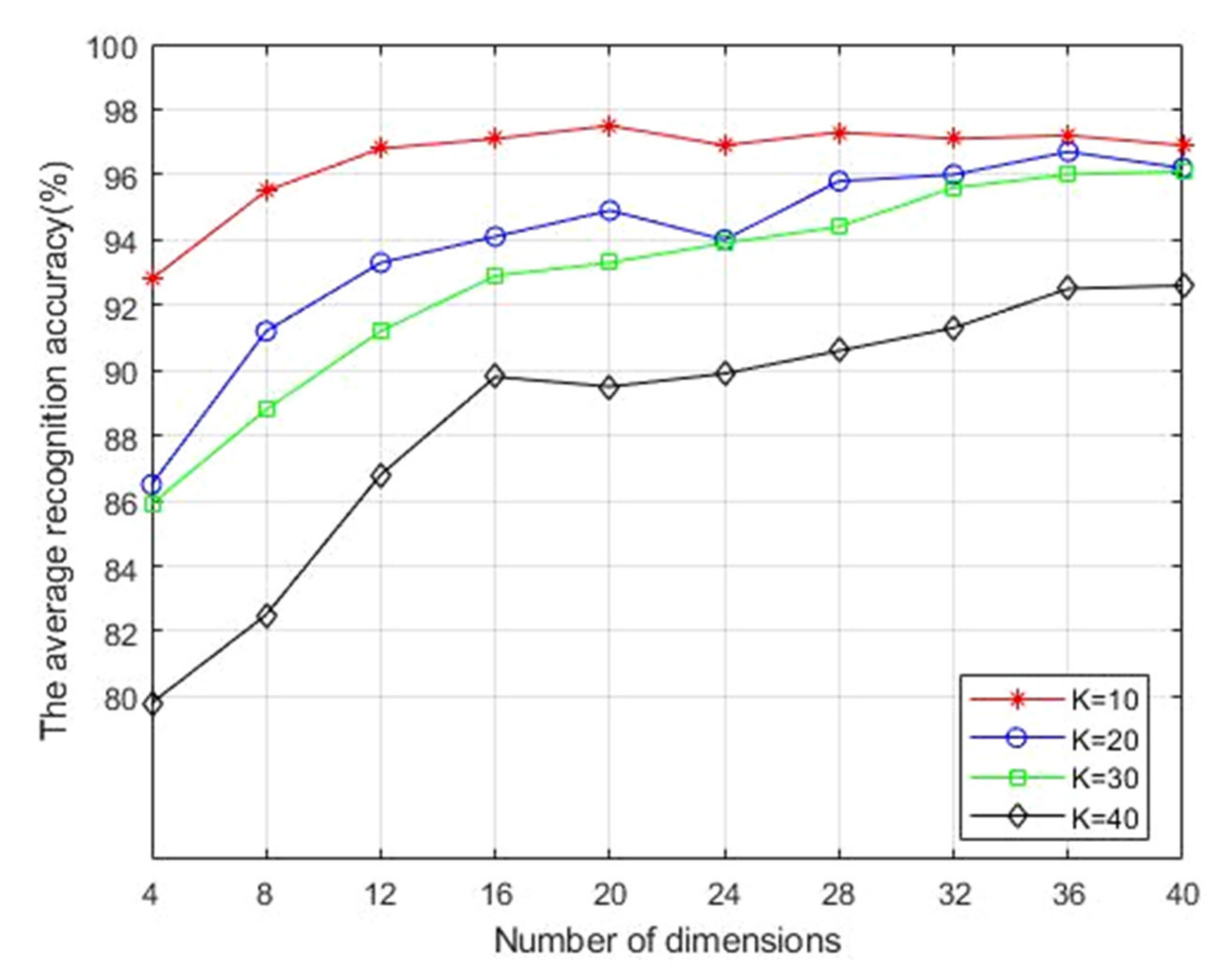
as 10, 20, 30 and 40. Next, six face images of each person in ORL, Yale and AR databases were randomly selected as training samples, and finally their average values were recorded and compared after ten experiments.
Figure 2,
Figure 3 and
Figure 4 show the average recognition accuracy (%) of the 2DESDLPP algorithm, corresponding to different feature dimensions in ORL, Yale and AR databases with different
values, respectively. It is obvious that the average recognition accuracy reached the maximum in all three face databases when
. Therefore, this is selected in subsequent experiments.
4.2. Experiments in ORL Database
There are 400 grayscale faces images from 40 persons in the ORL database and everyone has ten images. All images were acquired under changing external conditions, including lighting intensity, facial angle, posture change and expression changes. All face images in the ORL database were unified into pure black-backed scenery with a gray scale of 92 × 112 pixels, as shown in
Figure 5.
We selected
training sample images randomly from the ORL database and record the maximum average recognition rates and the number of dimensions in
Table 2. As can be seen from
Table 2, with the increase of the number of training samples, the recognition rate of the eight algorithms has improved. When the number of training samples is two, the recognition rate of all algorithms is not high, but the highest recognition rate of the 2DESDLPP algorithm is still 91.79%, 1.52 times that of the ELPP algorithm, and about 5.54% higher than that of the 2DDLPP algorithm. Even when the number of training samples is much smaller than the feature dimension, the 2DESDLPP algorithm can still achieve better performance, which indicates that the 2DESDLPP algorithm can indeed effectively solve the problem of the small sample size in the 2DDLPP algorithm. When the training sample size is six, the changes in 2DESDLPP recognition results and those of the other seven comparison algorithms are shown in
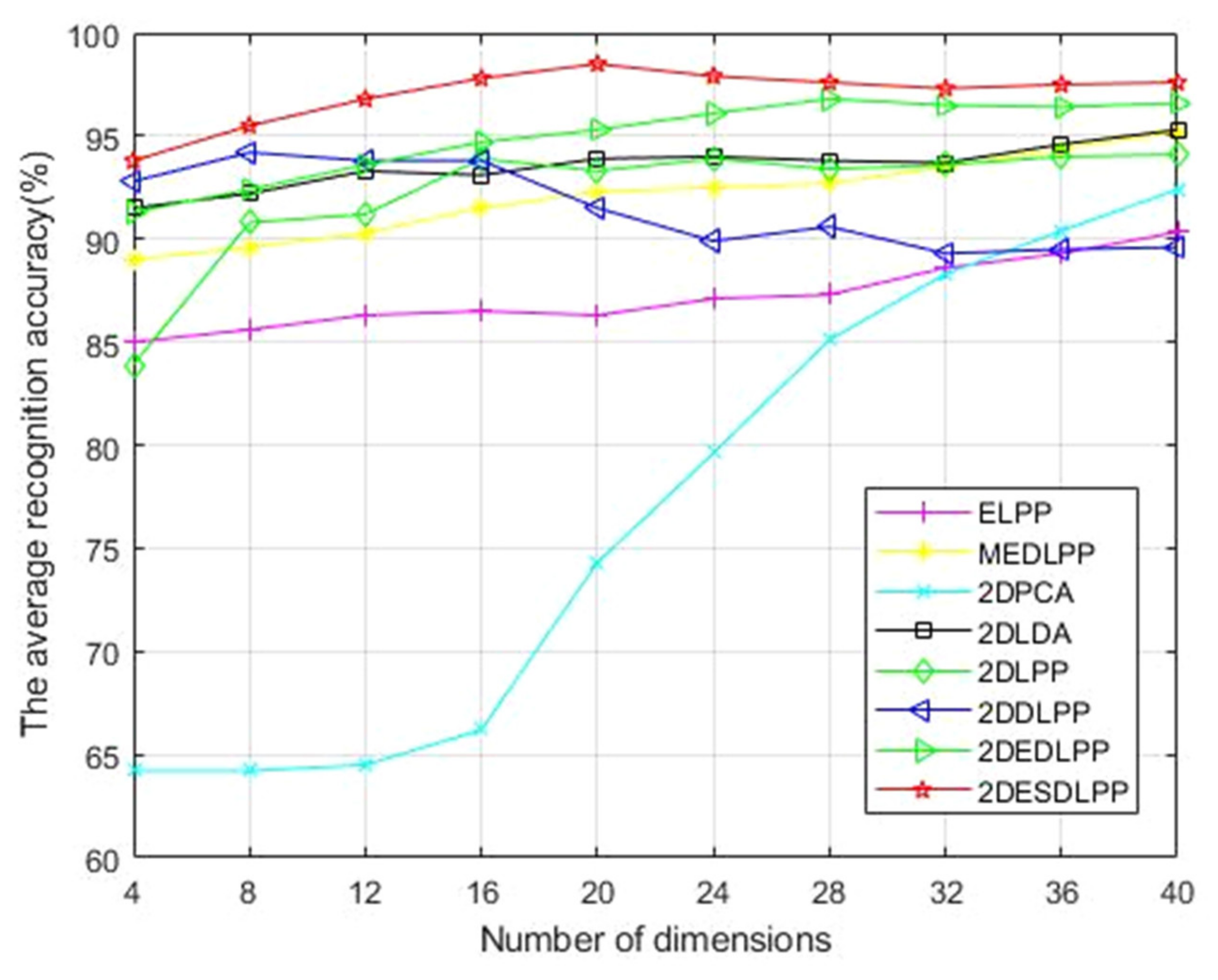
Figure 6.
It can be clearly seen from
Figure 6 that the recognition rate of supervised algorithms is higher than that of unsupervised algorithms, indicating that the use of label information is indeed helpful in improving the accuracy of the algorithm. Especially when the feature dimension is 20, the recognition rate of the 2DESDLPP algorithm is up to 98.5%, which is about 6.2% higher than that of the 2DDLPP algorithm with the same dimensional number. This is because 2DESDLPP converts the original image into a new subspace using distance diffusion mapping, further expanding the boundaries between labels. This allows more characteristic information to be retained for classification. In addition, the variation trend for algorithm accuracy of 2DESDLPP is relatively flat, indicating that the algorithm has strong robustness.
Table 3 shows the average running time of each algorithm in the ORL database when the number of training samples is six. It is not difficult to see that the running time of the 2DESDLPP algorithm after sparse representation is shortened, and is within the acceptable range.
4.3. Experiment in Yale Database
In the Yale database, there are 15 different subjects and each has 11 images taken under different external conditions, with a total of 165 grayscale images. Each image was created under different conditions of expression, lighting, etc. Most of them were used to verify the illumination robustness of the algorithm except for the face recognition rate, as shown in
Figure 7.
The experimental performance of the algorithm will be affected by external factors such as the facial expression changes of each subject and the different lighting conditions during shooting. Therefore, we chose to test whether 2DESDLPP is susceptible to random factors in the Yale database in order to evaluate its accuracy and robustness on small sample size data. In the experiments,
images of every person were selected as training sample sets randomly, and the rest were used as the test. The recognition performances of 2DESDLPP and the other seven comparison algorithms are shown in
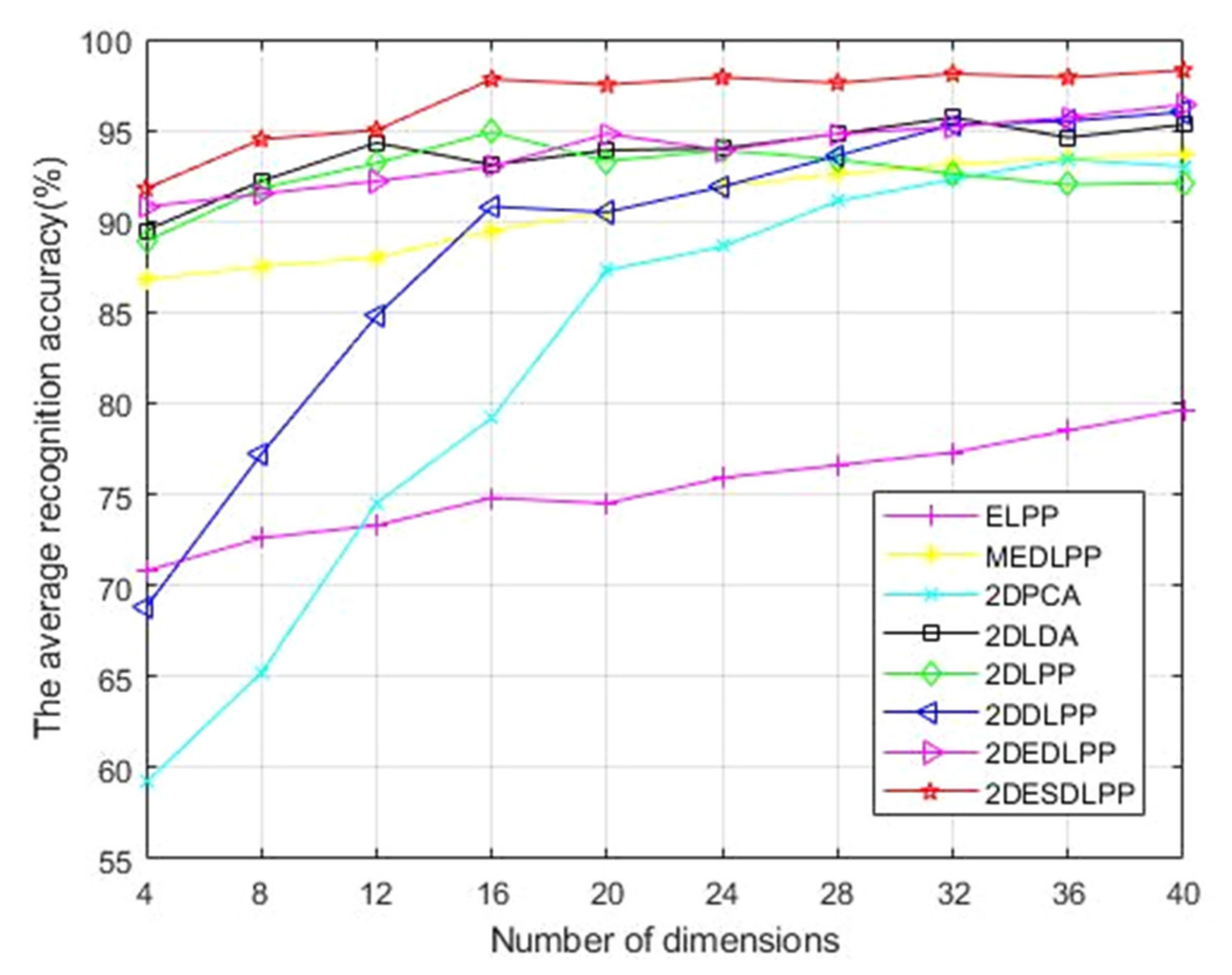
Figure 8 when the number of training samples is six. As can be seen, the average recognition rate of 2DESDLPP is highest when the feature dimension is 40, at about 98.33%. Moreover, when the feature dimension is greater than 16, the recognition rate of 2DESDLPP fluctuates little and is relatively stable.
For convenience of comparison, the specific values of the maximum average recognition rates of eight algorithms and the corresponding projected dimension numbers (in brackets) in the Yale database when the training sample sizes are 2, 3, 4, 5 and 6 are shown in
Table 4 respectively. When the number of training samples is 2 or 3, the performance of 2DESDLLP is better than the two one-dimensional algorithms and five two-dimensional algorithms used for comparison. After this improvement, the recognition rate of 2DESDLPP is about 3.7% higher than that of 2DDLPP. This indicates that, even when tested on small sample size data affected by external factors such as illumination changes, 2DESDLPP can obtain the best results compared with other algorithms.
Table 5 shows the average running time of each algorithm in the Yale database when the number of training samples is six. Compared with 2DDLPP, the computation speed of 2DESDLPP is improved. Although it is not the fastest algorithm, it has the best comprehensive performance when combined with the recognition rate.
4.4. Experiment in AR Database
The AR database includes 126 people (70 male and 56 female) with a total of more than 3000 frontal face images. The photos of each person were taken under different conditions of expression, lighting and occlusion. It is worth noting that the most significant external factors for the AR database focus on expression changes and facial occlusion, so its use consists mainly of face and expression recognition. Everyone has 15 images, as shown in
Figure 9.
We use AR database photos to test whether the 2DESDLPP algorithm is affected by the changes in human expressions and the occlusion of human faces, so as to evaluate its performance on high-dimensional noisy data. In the experiments, we performed a random selection of
images among all images of every person as a training sample set, and the rest are used as a test set, and then recorded 2DESDLPP, as well as the other seven comparison methods’, maximum average recognition rates and the number of dimensions in
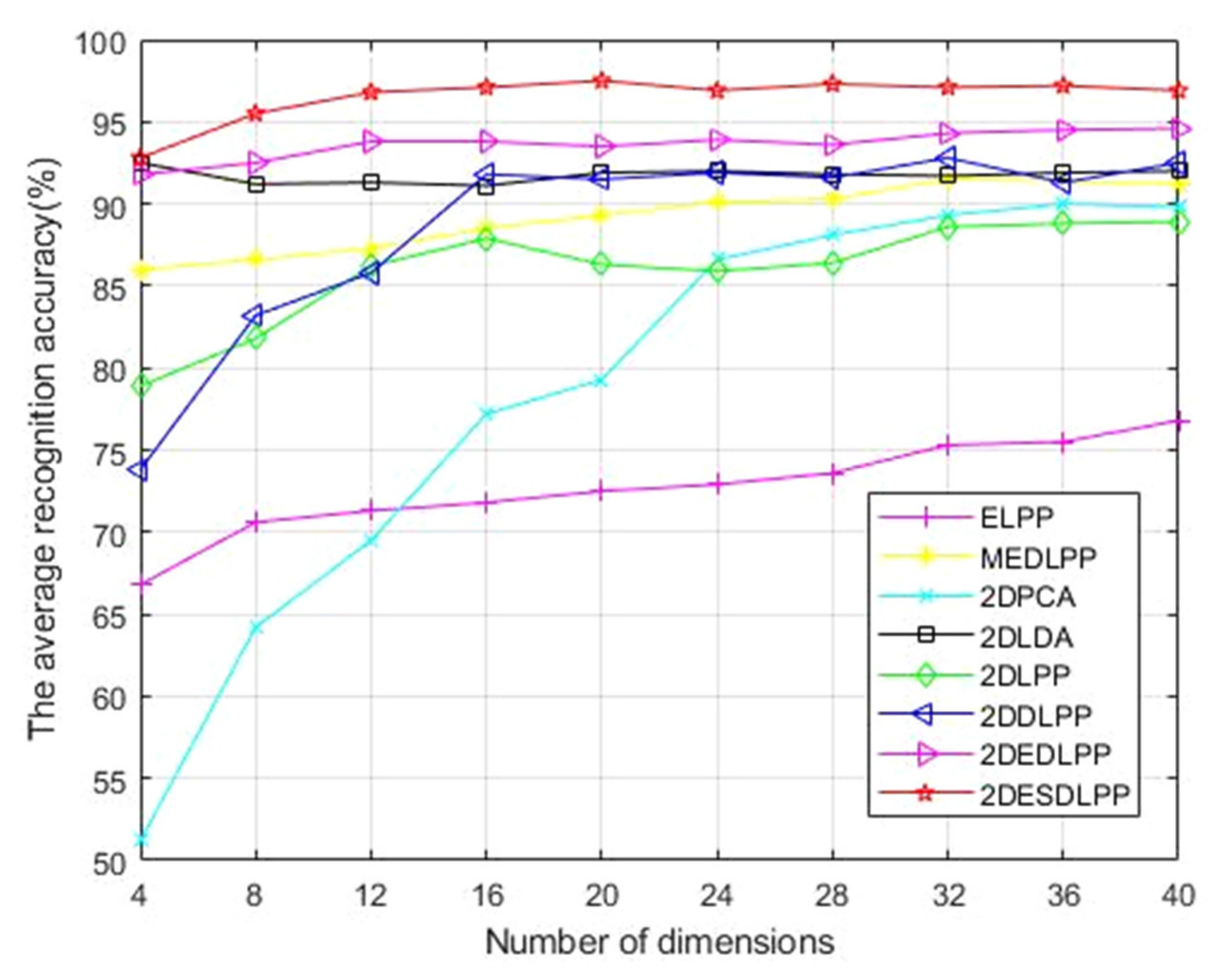
Table 6. Although the accuracy of all experimental algorithms in the AR database is lower than the ORL database and the Yale database due to the challenges of the database itself, no matter how small the number of training samples, the accuracy of 2DESDLPP is always slightly higher than that of the other algorithms. When the number of training samples was two, the highest accuracy of 2DESDLPP was 88.24% when the feature dimension was 24. When the number of training samples was three, the highest accuracy of 2DESDLPP was 89.98% when the feature dimension was 26. When the number of training samples was four, the highest accuracy of 2DESDLPP was 90.75% when the feature dimension was 25. When the training sample size is six, the changes are shown in
Figure 10. The average highest recognition rate obtained by 2DESDLPP is 97.56% when the number of training samples is six, and its feature dimension is 20 at this time. The highest recognition rate of 2DESDLPP is about 5.06% higher than that of 2DDLPP, and 1.27 times higher than that of ELPP.
Table 7 shows the average running time of each algorithm in the AR database when the number of training samples is six. Although facial occlusion in AR database improves the difficulty of face recognition, resulting in an increase in the running time of the eight algorithms, the operation of the 2DESDLPP algorithm does not take too much time.
4.5. Summary of Experimental Results
The following conclusions are drawn by analyzing the results of the experiments on the three public face databases mentioned above:
- (1)
From
Figure 2,
Figure 3 and
Figure 4, we can see that, when
, 2DESDLPP achieves the maximum recognition rate in three face databases, ORL, Yale and AR, indicating that 2DESDLPP has the best feature extraction ability at this time.
- (2)
As can be seen from the data in
Table 2,
Table 4 and
Table 6, with the increase in training sample size, the maximum average recognition accuracy increases to some extent for most experiments. As can be seen from the data in
Table 3,
Table 5 and
Table 7, the running time of the 2DESDLPP algorithm after sparse representation is shortened, and is within the acceptable range.
- (3)
It is not difficult to find that the recognition accuracy of 2DESDLPP outperforms the other 1D algorithms (ELPP and MEDLPP) and 2D algorithms (2DPCA, 2DLDA, 2DLPP, 2DDLPP and 2DEDLPP) for the same training sample size from
Figure 8,
Figure 9 and
Figure 10.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}