


Financial Volatility Modeling with the GARCH-MIDAS-LSTM Approach: The Effects of Economic Expectations, Geopolitical Risks and Industrial Production during COVID-19

Abstract
1. Introduction
2. Literature Review
2.1. Neural Networks, Machine Learning and GARCH
2.2. MIDAS and GARCH-MIDAS
3. Method
4. Results
4.1. Dataset
4.2. Linear and Nonlinear Unit Root Test Results

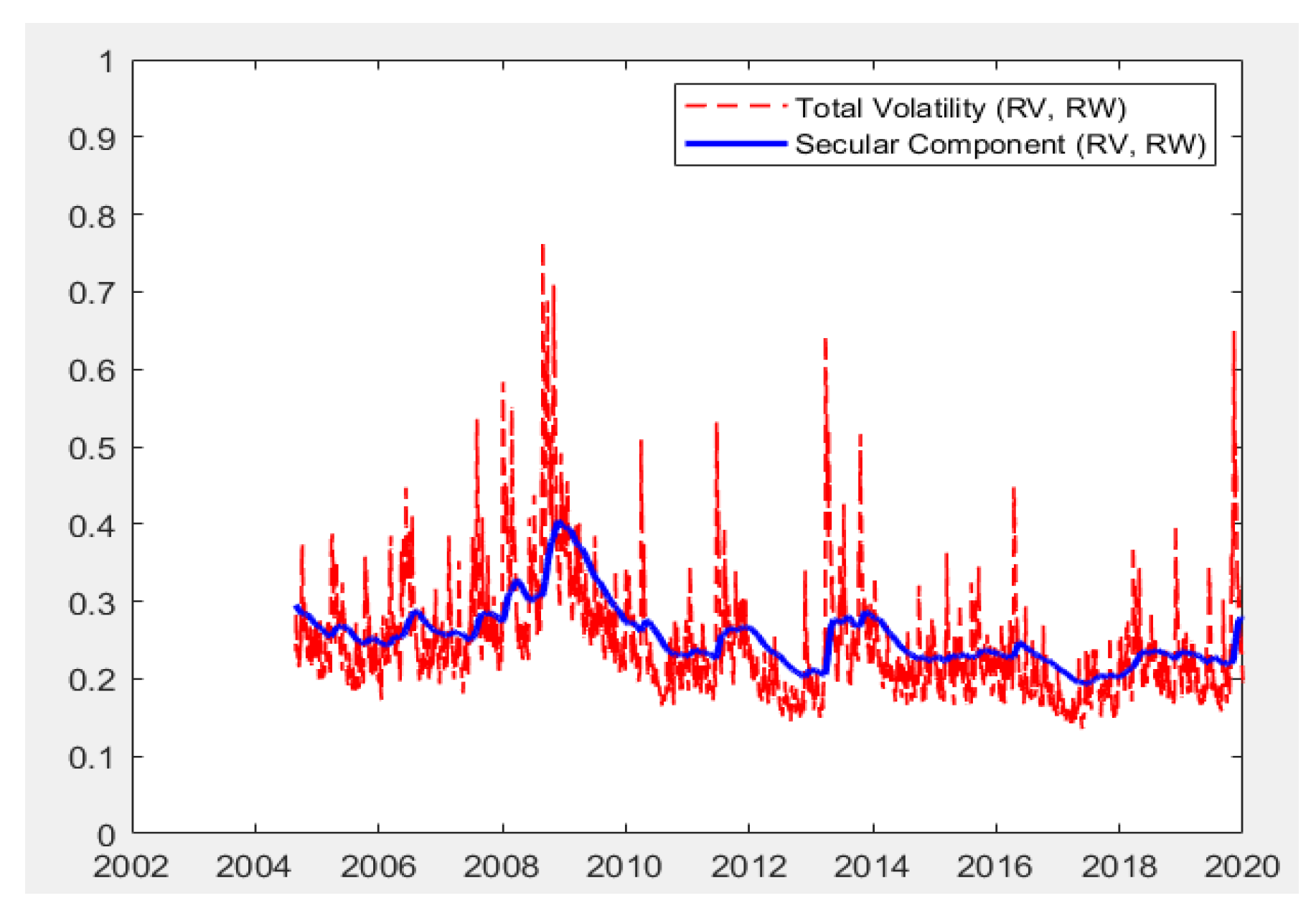{kind=link}
{kind=link}
{kind=link}
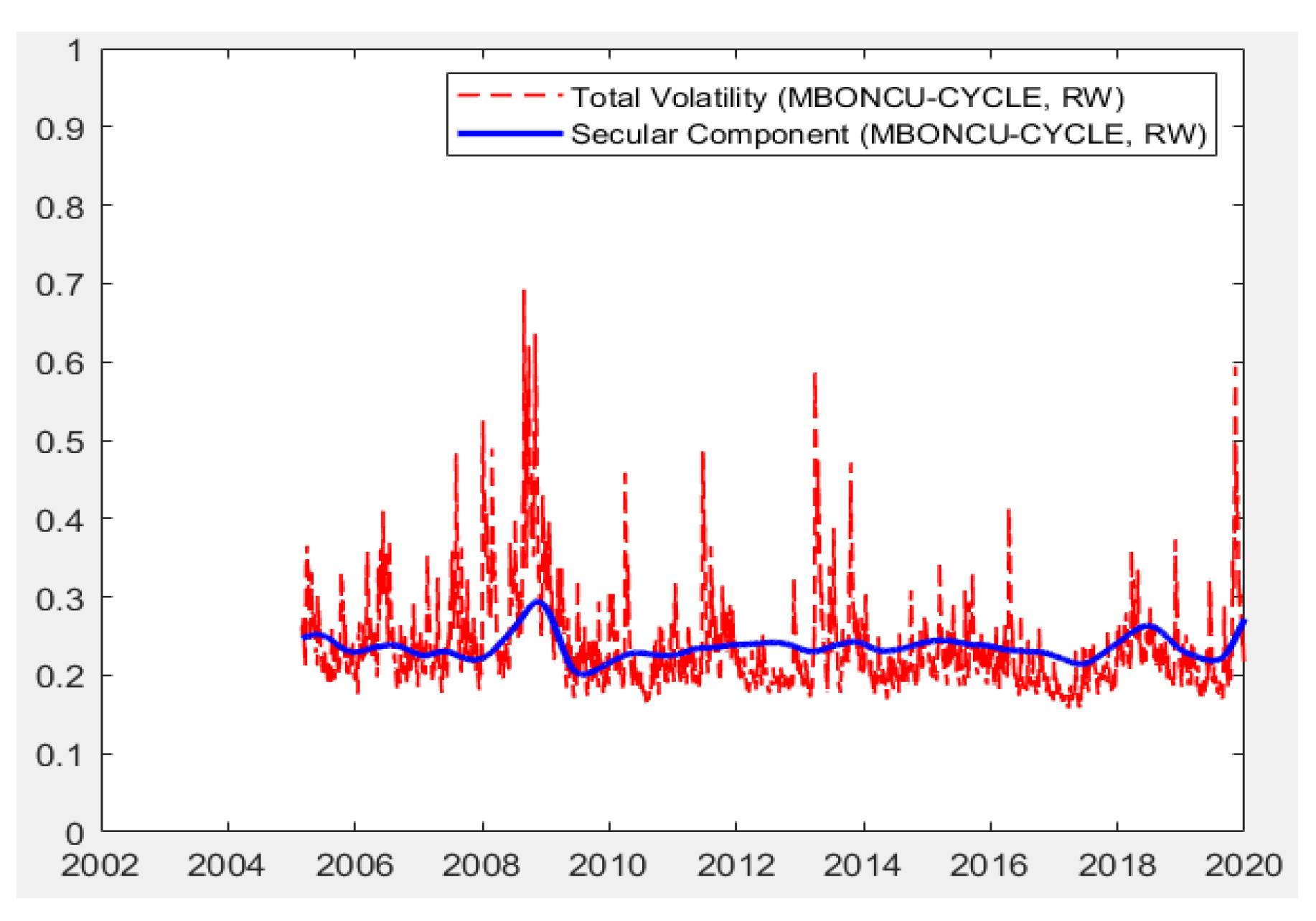{kind=link}
{kind=link}
| ADF | PP | DF-GLS | KPSS | KSS | |
|---|---|---|---|---|---|
| XU100 | −2.1215 [t + i] | −2.1699 [t + i] | −1.9838 [t + i] | 1.0726 ** [t + i] | −2.4479 [t + i] |
| ΔXU100 | −67.6468 ** [i] | −67.6479 ** [i] | −67.6146 ** [i] | 0.0810 [i] | −33.9307 ** [i] |
| IPIC | −0.4662 [i] | −1.0528 [i] | −0.4533 [i] | 0.2864 ** [t + i] | 1.9882 [i] |
| ΔIPIC | −6.5866 ** [i] | −3.7754 ** [i] | −7.5985 ** [i] | 0.0425 [i] | −2.9479 * [i] |
| IPIT | −0.5839 [i] | −0.1208 [i] | 2.3620 [i] | 1.9448 ** [i] | 0.2453 [i] |
| ΔIPIT | −6.5589 ** [i] | −3.5518 ** [i] | −5.2453 ** [i] | 0.0907 [i] | −3.2002 * [i] |
| CLI | −1.3632 [t + i] | −1.9904 [t + i] | −1.8346 [t + i] | 0.8120 [t + i] | −0.0542 ** [t + i] |
| ΔCLI | −5.0547 ** [i] | −4.6978 ** [t + i] | −3.1916 * [t + i] | 0.0778 ** [t + i] | −27.2008 ** [t + i] |
| GPR | −3.1087 [t + i] | −6.9208 ** [t + i] | −1.5647 [t + i] | 0.1635 ** [t + i] | −2.0759 [t + i] |
| ΔGPR | −26.6857 ** [i] | −26.6865 ** [i] | −2.9227 * [t + i] | 0.1132 * [t + i] | −3.9118 ** [i] |
4.3. Estimation Results
4.3.1. GARCH-MIDAS Estimation Results
4.3.2. GARCH-MIDAS-LSTM Estimation Results
4.3.3. Out-of-Sample Forecast Performance Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bildirici, M.; Onat, I.Ş.; Ersin, Ö.Ö. Forecasting BDI Sea Freight Shipment Cost, VIX Investor Sentiment and MSCI Global Stock Market Indicator Indices: LSTAR-GARCH and LSTAR-APGARCH Models. Mathematics 2023, 11, 1242. [Google Scholar] [CrossRef]
- Bildirici, M.; Ersin, O.; Onat, I.Ş. Examination of the predictability of BDI and VIX: A threshold approach. Int. J. Transp. Econ. 2019, 46, 9–28. [Google Scholar] [CrossRef]
- Engle, R.F.; Ghysels, E.; Sohn, B. Stock market volatility and macroeconomic fundamentals. Rev. Econ. Stat. 2013, 95, 776–797. [Google Scholar] [CrossRef]
- Ghysels, E.; Sinko, A.; Valkanov, R. MIDAS regressions: Further results and new directions. Econom. Rev. 2007, 26, 53–90. [Google Scholar] [CrossRef]
- Organization of Economic Coorporation and Development (OECD). Leading Indicators–Composite Leading Indicator (CLI)—OECD Data. 2023. Available online: https://data.oecd.org/leadind/composite-leading-indicator-cli.htm (accessed on 16 February 2023).
- OECD. OECD Composite Leading Indicators: Turning Points of Reference Series and Component Series. 2023. Available online: http://www.oecd.org/std/leading-indicators/ (accessed on 16 February 2023).
- Caldara, D.; Iacoviello, M. Measuring Geopolitical Risk. Am. Econ. Rev. 2022, 112, 1194–1225. [Google Scholar] [CrossRef]
- Bollerslev, T. Glossary to ARCH (GARCH). 2009. Available online: http://public.econ.duke.edu/~boller/Papers/glossary_arch.pdf (accessed on 31 January 2023).
- Donaldson, R.G.; Kamstra, M. An artificial neural network-GARCH model for international stock return volatility. J. Empir. Financ. 1997, 4, 17–46. [Google Scholar] [CrossRef]
- Bildirici, M.; Ersin, Ö.Ö. Improving forecasts of GARCH family models with the artificial neural networks: An application to the daily returns in Istanbul Stock Exchange. Expert Syst. Appl. 2009, 36, 7355–7362. [Google Scholar] [CrossRef]
- Chen, S.; Jeong, K.; Härdle, W. Support Vector Regression Based GARCH Model with Application to Forecasting Volatility of Financial Returns. In SFB Economic Risk Discussion Paper; 2008; pp. 1–27. Available online: https://ssrn.com/abstract=2894286 (accessed on 12 February 2023).
- Bildirici, M.; Ersin, Ö.Ö. Asymmetric power and fractionally integrated support vector and neural network GARCH models with an application to forecasting financial returns in ise100 stock index. Econ. Comput. Econ. Cybern. Stud. Res. 2014, 48, 1–22. [Google Scholar]
- Bildirici, M.; Ersin, Ö.Ö. Support Vector Machine GARCH Models in Modeling Conditional Volatility: An Application to Turkish Financial Markets. In Proceedings of the 13th International Conference on Econometrics, Operations Research and Statistics ICEOS, Yildiz Technical University, Istanbul, Turkey, 24–26 May 2012; pp. 1–14. Available online: http://ssrn.com/abstract=2227747 (accessed on 1 March 2023).
- Peng, Y.; Albuquerque, P.H.M.; de Sá, J.M.C.; Padula, A.J.A.; Montenegro, M.R. The best of two worlds: Forecasting high frequency volatility for cryptocurrencies and traditional currencies with Support Vector Regression. Expert Syst. Appl. 2018, 97, 177–192. [Google Scholar] [CrossRef]
- Bezerra, P.C.S.; Albuquerque, P.H.M. Volatility forecasting via SVR–GARCH with mixture of Gaussian kernels. Comput. Manag. Sci. 2017, 14, 179–196. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sezer, O.B.; Gudelek, U.; Ozbayoglu, A.M. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl. Soft Comput. J. 2020, 90, 106181. [Google Scholar] [CrossRef]
- Kumbure, M.M.; Lohrmann, C.; Luukka, P.; Porras, J. Machine learning techniques and data for stock market forecasting: A literature review. Expert Syst. Appl. 2022, 197, 116659. [Google Scholar] [CrossRef]
- Li, X.; Yang, L.; Xue, F.; Zhou, H. Time series prediction of stock price using deep belief networks with intrinsic plasticity. In Proceedings of the 29th Chinese Control and Decision Conference (CCDC), Chongqing, China, 28–30 May 2017; pp. 1237–1242. [Google Scholar] [CrossRef]
- Krauss, C.; Do, X.A.; Huck, N. Deep neural networks, gradient-boosted trees, random forests: Statistical arbitrage on the S&P 500. Eur. J. Oper. Res. 2017, 259, 689–702. [Google Scholar] [CrossRef]
- Jeong, G.; Kim, H.Y. Improving financial trading decisions using deep Q-learning: Predicting the number of Shares, action Strategies, and transfer learning. Expert Syst. Appl. 2019, 117, 125–138. [Google Scholar] [CrossRef]
- Troiano, L.; Villa, E.M.; Loia, V. Replicating a Trading Strategy by Means of LSTM for Financial Industry Applications. IEEE Trans. Ind. Inform. 2018, 14, 3226–3234. [Google Scholar] [CrossRef]
- Liu, J.; Wang, P.; Chen, H.; Zhu, J. A combination forecasting model based on hybrid interval multi-scale decomposition: Application to interval-valued carbon price forecasting. Expert Syst. Appl. 2022, 191, 116267. [Google Scholar] [CrossRef]
- Hu, Y.; Ni, J.; Wen, L. A hybrid deep learning approach by integrating LSTM-ANN networks with GARCH model for copper price volatility prediction. Phys. A Stat. Mech. Its Appl. 2020, 557, 124907. [Google Scholar] [CrossRef]
- Teräsvirta, T. Specification, Estimation, and Evaluation of Smooth Transition Autoregressive Models. J. Am. Stat. Assoc. 1994, 89, 208–218. [Google Scholar] [CrossRef]
- Bildirici, M.; Bayazit, N.G.; Ucan, Y. Analyzing Crude Oil Prices under the Impact of COVID-19 by Using LSTARGARCHLSTM. Energies 2020, 13, 2980. [Google Scholar] [CrossRef]
- Wex, F.; Widder, N.; Liebmann, M.; Neumann, D. Early warning of impending oil crises using the predictive power of online news stories. In Proceedings of the Annual Hawaii International Conference on System Sciences, Wailea, HI, USA, 7–10 January 2013; pp. 1512–1521. [Google Scholar] [CrossRef]
- Li, X.; Shang, W.; Wang, S. Text-based crude oil price forecasting: A deep learning approach. Int. J. Forecast. 2019, 35, 1548–1560. [Google Scholar] [CrossRef]
- Yu, L.; Wang, S.; Lai, K.K. A Rough-Set-Refined Text Mining Approach for Crude Oil Market Tendency Forecasting. Int. J. Knowl. Syst. Sci. 2005, 2, 1–14. [Google Scholar]
- Chen, Y.; He, K.; Tso, G.K.F. Forecasting Crude Oil Prices: A Deep Learning based Model. Procedia Comput. Sci. 2017, 122, 300–307. [Google Scholar] [CrossRef]
- Khodayar, M.; Kaynak, O.; Khodayar, M.E. Rough Deep Neural Architecture for Short-Term Wind Speed Forecasting. IEEE Trans. Ind. Inform. 2017, 13, 2770–2779. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, J.; Yu, L. A deep learning ensemble approach for crude oil price forecasting. Energy Econ. 2017, 66, 9–16. [Google Scholar] [CrossRef]
- Xu, B.; Zhang, D.; Zhang, S.; Li, H.; Lin, H. Stock Market Trend Prediction Using Recurrent Convolutional Neural Networks. In Proceedings of the 7th CCF International Conference on Natural Language Processing and Chinese Computing, Hohhot, China, 28–30 August 2018; pp. 166–177. [Google Scholar] [CrossRef]
- Althelaya, K.A.; El-Alfy, E.S.M.; Mohammed, S. Evaluation of Bidirectional LSTM for Short and Long-Term Stock Market Prediction. In Proceedings of the 2018 9th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 3–5 April 2018; pp. 151–156. [Google Scholar] [CrossRef]
- Gupta, V.; Pandey, A. Crude Oil Price Prediction Using LSTM Networks. Int. J. Comput. Inf. Eng. 2018, 12, 226–230. [Google Scholar]
- Zhang, K.; Hong, M.; Zhang, K.; Hong, M. Forecasting crude oil price using LSTM neural networks. Data Sci. Financ. Econ. 2022, 2, 163–180. [Google Scholar] [CrossRef]
- Kim, H.Y.; Won, C.H. Forecasting the volatility of stock price index: A hybrid model integrating LSTM with multiple GARCH-type models. Expert Syst. Appl. 2018, 103, 25–37. [Google Scholar] [CrossRef]
- Fabbri, M.; Moro, G. Dow Jones Trading with Deep Learning: The Unreasonable Effectiveness of Recurrent Neural Networks. In Proceedings of the DATA 2018—Proceedings of the 7th International Conference on Data Science, Technology and Applications, Porto, Portugal, 26–28 July 2018; pp. 142–153. [Google Scholar] [CrossRef]
- Ghosh, I.; Alfaro-Cortés, E.; Gámez, M.; García-Rubio, N. Role of proliferation COVID-19 media chatter in predicting Indian stock market: Integrated framework of nonlinear feature transformation and advanced AI. Expert Syst. Appl. 2023, 219, 119695. [Google Scholar] [CrossRef]
- Jena, P.R.; Majhi, R. Are Twitter sentiments during COVID-19 pandemic a critical determinant to predict stock market movements? A machine learning approach. Sci. Afr. 2023, 19, e01480. [Google Scholar] [CrossRef]
- Lee, M.C.; Chang, J.W.; Hung, J.C.; Chen, B.L. Exploring the effectiveness of deep neural networks with technical analysis applied to stock market prediction. Comput. Sci. Inf. Syst. 2021, 18, 401–418. [Google Scholar] [CrossRef]
- Selvin, S.; Vinayakumar, R.; Gopalakrishnan, E.A.; Menon, V.K.; Soman, K.P. Stock price prediction using LSTM, RNN and CNN-sliding window model. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Manipal, Karnataka, India, 13–16 September 2017; pp. 1643–1647. [Google Scholar] [CrossRef]
- Bhandari, H.N.; Rimal, B.; Pokhrel, N.R.; Rimal, R.; Dahal, K.R.; Khatri, R.K.C. Predicting stock market index using LSTM. Mach. Learn. Appl. 2022, 9, 100320. [Google Scholar] [CrossRef]
- Feng, G.; He, J.; Polson, N.G. Deep Learning for Predicting Asset Returns. arXiv 2018, arXiv:1804.09314v2. Available online: https://EconPapers.repec.org/RePEc:arx:papers:1804.09314 (accessed on 14 February 2023).
- Fan, M.-H.; Chen, M.-Y.; Liao, E.-C. A deep learning approach for financial market prediction: Utilization of Google trends and keywords. Granul. Comput. 2021, 6, 207–216. [Google Scholar] [CrossRef]
- Clements, M.P.; Galvão, A.B. Macroeconomic Forecasting with Mixed Frequency Data: Forecasting US output growth and inflation. In The Warwick Economics Research Paper Series (TWERPS); 2006; Available online: https://ideas.repec.org/p/wrk/warwec/773.html (accessed on 8 March 2023).
- Andreou, E.; Ghysels, E.; Kourtellos, A. Should Macroeconomic Forecasters Use Daily Financial Data and How? J. Bus. Econ. Stat. 2013, 31, 240–251. [Google Scholar] [CrossRef]
- Ferrara, L.; Marsilli, C. Financial variables as leading indicators of GDP growth: Evidence from a MIDAS approach during the Great Recession. Appl. Econ. Lett. 2012, 20, 233–237. [Google Scholar] [CrossRef]
- Pettenuzzo, D.; Valkanov, R.; Timmermann, A. A Bayesian MIDAS Approach to Modeling First and Second Moment Dynamics. J. Econom. 2016, 193, 315–334. [Google Scholar] [CrossRef]
- Kuzin, V.; Marcellino, M.; Schumacher, C. MIDAS vs. mixed-frequency VAR: Nowcasting GDP in the euro area. Int. J. Forecast. 2011, 27, 529–542. [Google Scholar] [CrossRef]
- Raza, S.A.; Masood, A.; Benkraiem, R.; Urom, C. Forecasting the volatility of precious metals prices with global economic policy uncertainty in pre and during the COVID-19 period: Novel evidence from the GARCH-MIDAS approach. Energy Econ. 2023, 120, 106591. [Google Scholar] [CrossRef]
- Ersin, Ö.Ö.; Gül, M.; Aşik, B. Are the Policy Uncertainty and CLI ‘Effective’ Indicators of Volatility? GARCH-MIDAS Analysis of the G7 Stock Markets. Econ. Comput. Econ. Cybern. Stud. Res. 2022, 56, 141–158. [Google Scholar] [CrossRef]
- Liu, J.; Chen, Z. How do stock prices respond to the leading economic indicators? Analysis of large and small shocks. Financ. Res. Lett. 2023, 51, 103430. [Google Scholar] [CrossRef]
- Segnon, M.; Gupta, R.; Wilfling, B. Forecasting stock market volatility with regime-switching GARCH-MIDAS: The role of geopolitical risks. Int. J. Forecast. 2023. (In Press, Corrected Proof). [Google Scholar] [CrossRef]
- Zhang, C.; Liu, X.; Li, X.; Tang, C. Gjr-Garch Midas Model Based Analyse Geopolitical Risk and Energy Price Volatility. 2023. Available online: https://ssrn.com/abstract=4326097 (accessed on 7 April 2023).
- Chuang, O.C.; Yang, C. Identifying the Determinants of Crude Oil Market Volatility by the Multivariate GARCH-MIDAS Model. Energies 2022, 15, 2945. [Google Scholar] [CrossRef]
- Andreani, M.; Candila, V.; Morelli, G.; Petrella, L. Multivariate Analysis of Energy Commodities during the COVID-19 Pandemic: Evidence from a Mixed-Frequency Approach. Risks 2021, 9, 144. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized Autoregressive Conditional Heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Conrad, C.; Custovic, A.; Ghysels, E. Long- and Short-Term Cryptocurrency Volatility Components: A GARCH-MIDAS Analysis. J. Risk Financ. Manag. 2018, 11, 23. [Google Scholar] [CrossRef]
- Conrad, C.; Loch, K. Anticipating Long-Term Stock Market Volatility. J. Appl. Econom. 2015, 30, 1090–1114. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Dickey, D.A.; Fuller, W.A. Distribution of the Estimators for Autoregressive Time Series with a Unit Root. J. Am. Stat. Assoc. 1979, 74, 427. [Google Scholar] [CrossRef]
- Elliott, G.; Rothenberg, T.J.; Stock, J.H. Efficient Tests for an Autoregressive Unit Root. Econometrica 1996, 64, 813. [Google Scholar] [CrossRef]
- Kwiatkowski, D.; Phillips, P.C.B.; Schmidt, P.; Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root? J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]
- Lee, D.; Schmidt, P. On the power of the KPSS test of stationarity against fractionally-integrated alternatives. J. Econom. 1996, 73, 285–302. [Google Scholar] [CrossRef]
- Kapetanios, G.; Shin, Y.; Snell, A. Testing for a unit root in the nonlinear STAR framework. J. Econom. 2003, 112, 359–379. Available online: http://www.elsevier.com/locate/econbase (accessed on 28 February 2023). [CrossRef]
- Mackinnon, J.G. Critical Values for Cointegration Tests. In Long Run Economic Relationships, 1st ed.; Engle, R., Granger, C., Eds.; Oxford University Press: Oxford, UK, 2011; pp. 267–276. Available online: http://www.econ.queensu.ca/faculty/mackinnon/ (accessed on 28 February 2023).





| Variable | Description | Source | Frequency | n |
|---|---|---|---|---|
| XU100 | Borsa İstanbul 100 Stock Market Index (BIST100) | CBRT EVDS Database | Daily | 4812 |
| IPIC | Industrial production leading indicator index, cycle series | CBRT EVDS Database | Monthly | 22 |
| IPIT | Industrial production leading indicator index, trend series | CBRT EVDS Database | Monthly | 22 |
| CLI | Composite leading indicator (Amplitude) for Türkiye | OECD Database | Monthly | 222 |
| GPR | Geopolitical Risk Index, Türkiye | Policyuncertainty.com | Monthly | 222 |
| Mean | Min. | Max. | SD | SKW | KR | JB | ARCH | |
|---|---|---|---|---|---|---|---|---|
| Daily Dataset, n = 4812 | ||||||||
| XU100 | 10.788 | 9.063 | 11.725 | 0.683 | −0.921 | 2.859 | 660.5 [0.00] | 430,658 [0.00] |
| ΔXU100 | 0.0004 | −0.133 | 0.1212 | 0.018 | −0.209 | 7.932 | 4740.4 [0.00] | 57.18 [0.00] |
| Monthly Dataset, n = 390 | ||||||||
| IPIC | 4.605 | 4.535 | 4.673 | 0.019 | −0.813 | 4.689 | 12.4 [0.00] | 39,996.2 [0.00] |
| ΔIPIC | 0.026 | −0.015 | 0.015 | 0.494 | −1.164 | 4.835 | 142.4 [0.00] | 2653.4 [0.00] |
| IPIT | 4.847 | 4.301 | 5.411 | 0.293 | 0.274 | 2.317 | 89.3 [0.00] | 9853.80 [0.00] |
| ΔIPIT | −0.029 | −0.019 | 0.012 | 0.462 | −1.299 | 5.984 | 253.7 [0.00] | 2877.9 [0.00] |
| CLI | 4.604 | 4.374 | 4.718 | 0.034 | −1.704 | 10.174 | 1024.9 [0.00] | 36.63 [0.00] |
| ΔCLI | −0.027 | −0.032 | 0.022 | 0.747 | −1.129 | 6.521 | 283.5 [0.00] | 1976.7 [0.00] |
| GPR | 4.675 | 3.787 | 5.769 | 0.357 | 0.229 | 2.837 | 31.8 [0.00] | 21.31 [0.00] |
| ΔGPR | 0.105 | −0.009 | 0.015 | 0.296 | 0.644 | 4.633 | 70.1 [0.00] | 4.94 [0.03] |
| Model: | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| X: | RV | RV | IPIT | IPIT | IPIC | IPIC | GPR | GPR | CLI | CLI |
| type: | f | rw | f | rw | f | Rw | f | rw | f | rw |
| Parameter estimates: | ||||||||||
| µ | 0.00093 ** (4.5026) | 0.00094 ** (4.5345) | 0.00095 ** (4.3601) | 0.00095 ** (4.3819) | 0.00092 ** (4.085) | 0.00092 ** (4.0917) | 0.0009 ** (4.0563) | 0.0010 ** (4.6432) | 0.0009 ** (4.0545) | 0.0009 ** (4.4027) |
| α | 0.11566 ** (15.282) | 0.11662 ** (15.17) | 0.09716 ** (13.536) | 0.09794 ** (13.683) | 0.09193 ** (13.337) | 0.09238 ** (13.359) | 0.0871 ** (14.745) | 0.1176 ** (13.486) | 0.0931 ** (13.395) | 0.1109 * (15.471) |
| β | 0.80705 ** (62.064) | 0.80072 ** (58.97) | 0.80802 ** (56.775) | 0.81186 ** (58.328) | 0.8172 ** (61.533) | 0.8177 ** (61.988) | 0.8807 ** (112.08) | 0.7967 ** (45.809) | 0.8098 ** (59.727) | 0.8413 ** (82.098) |
| θ | 0.03111 ** (12.348) | 0.03183 ** (12.776) | −0.0209 ** (−6.8337) | −0.0211 ** (−6.6477) | −0.0099 ** (−3.2215) | −0.0108 ** (−3.2082) | 0.0052 ** (8.6137) | 0.0247 ** (6.3436) | −0.008 * (−2.329) | −0.0334 (1.0056) |
| ω | 3.64030 ** (4.575) | 4.77050 ** (4.5963) | 2.7006 ** (4.3842) | 2.5853 ** (4.282) | 11.758 * (2.3582) | 10.205 * (2.5122) | 1.2624 ** (13.103) | 9.245 ** (3.2151) | 4.8722 * (2.3151) | 1.0056 ** (5.0055) |
| m | 0.00009 ** (6.8231) | 0.00008 ** (6.91) | 0.00029 ** (20.307) | 0.00029 ** (19.659) | 0.00022 ** (32.902) | 0.00022 ** (32.558) | 0.0003 ** (13.949) | 0.0001 ** (6.4681) | 0.0002 ** (33.977) | 0.0003 ** (16.553) |
| Diagnostics: | ||||||||||
| LogL | 12,621.2 | 12,622.7 | 11,123.2 | 11,123.9 | 10,740 | 10,740.4 | 10,913.4 | 10,945.6 | 10,736.2 | 10,750.8 |
| AIC | −25,230.4 | −25,233.4 | −22,234.4 | −22,235.8 | −21,468 | −21,468.8 | −21,814.8 | −21,879.2 | −21,460.4 | −21,489.6 |
| BIC | −25,191.6 | −25,194.6 | −22,195.6 | −22,197 | −21,429.2 | −21,430 | −21,776 | −21,840.4 | −21,421.6 | −21,450.8 |
| HQ | −25,140.7 | −25,143.7 | −22,144.7 | −22,146.1 | −21,378.3 | −21,379.1 | −21,725.1 | −21,789.5 | −21,370.7 | −21,399.9 |
| Model: | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
|---|---|---|---|---|---|---|---|---|---|---|
| X: | RV | RV | IPIT | IPIT | IPIC | IPIC | GPR | GPR | CLI | CLI |
| type: | f | rw | f | rw | f | rw | f | rw | f | rw |
| Parameter estimates: | ||||||||||
| µ | 0.0008 ** (3.4121) | 0.0008 ** (3.4277) | 0.0009 ** (4.1590) | 0.001 ** (4.2306) | 0.0010 ** (4.2021) | 0.0001 ** (1.2004) | 0.0009 ** (4.0472) | 0.0009 ** (4.1255) | 0.0009 (1.5904) | 0.001 ** (4.3932) |
| α | 0.1134 ** (15.178) | 0.1133 ** (16.0142) | 0.0970 ** (13.574) | 0.0978 ** (13.692) | 0.0911 ** (12.985) | 0.0910 ** (12.849) | 0.0903 ** (14.540) | 0.1006 ** (14.649) | 0.0899 ** (13.448) | 0.0972 ** (14.041) |
| β | 0.8144 ** (52.673) | 0.8151 ** (49.916) | 0.8106 ** (51.768) | 0.8106 ** (53.022) | 0.8196 ** (54.058) | 0.8181 ** (61.094) | 0.8841 ** (101.65) | 0.8004 ** (39.905) | 0.8105 ** (57.954) | 0.8295 ** (79.881) |
| θ | 0.0304 ** (14.802) | 0.0303 ** (13.109) | −0.0211 ** (−9.6581) | −0.0240 ** (−6.7843) | −0.0103 ** (−7.4490) | −0.0139 ** (−8.4522) | 0.0031 ** (10.4062) | 0.0307 ** (10.7601) | −0.029 ** (−6.001) | −0.0301 ** (−6.1583) |
| ω | 3.4504 ** (4.692) | 3.8941 ** (4.9470) | 2.6826 ** (5.2351) | 2.6756 ** (5.377) | 12.002 ** (5. 2676) | 11.870 ** (6.5513) | 8.2547 ** (14.5063) | 9.0499 ** (11.6502) | 5.2190 ** (3.6774) | 4.79411 ** (4.07101) |
| m | 0.0001 ** (4.7440) | 0.0001 ** (4.8913) | 0.0003 ϯ (1.93491) | 0.0003 * (1.9625) | 0.0003 ** (21.876) | 0.0003 ** (17.4662) | 0.0002 * (1.9672) | 0.00027 * (2.02486) | 0.00026 ** (19.503) | 0.00025 ** (19.8474) |
| Diagnostics: | ||||||||||
| LogL | 11,998.3 | 12,001.6 | 12,806.8 | 12,839.7 | 12,661.4 | 12,058.02 | 12,105.8 | 11,174.5 | 10,796.9 | 11,027.5 |
| AIC | −23,984.6 | −23,991.2 | −25,601.6 | −25,667.4 | −25,310.8 | −24,104 | −24,199.6 | −22,337 | −21,581.8 | −22,043 |
| BIC | −23,945.8 | −23,952.4 | −25,562.8 | −25,628.6 | −25,272 | −24,065.2 | −24,160.8 | −22,298.2 | −21,543 | −22,004.2 |
| HQ | −23,894.9 | −23,901.5 | −25,511.9 | −25,577.7 | −25,221.1 | −24,014.4 | −24,109.9 | −22,247.3 | −21,492.1 | −21,953.3 |
| Model No: | I | II | III | IV | V | VI | VII | VIII | IX | X |
| X: | RV | RV | IPIT | IPIT | IPIC | IPIC | GPR | GPR | CLI | CLI |
| type: | f | rw | f | rw | f | rw | f | rw | f | rw |
| Group 1: GARCH-MIDAS models | ||||||||||
| RMSE: | 0.000172 | 0.000181 | 0.000191 | 0.0001812 | 0.000174 | 0.000174 | 0.000192 | 0.000161 | 0.000227 | 0.000227 |
| Rank in Group 1: | 9 | 4 | 5 | 10 | 2 | 3 | 6 | 1 | 8 | 7 |
| Group 2: GARCH-MIDAS-LSTM models | ||||||||||
| Model No: | XI | XII | XIII | XIV | XV | XVI | XVII | XVIII | XIX | XX |
| X: | RV | RV | IPIT | IPIT | IPIC | IPIC | GPR | GPR | CLI | CLI |
| type: | f | rw | f | rw | f | rw | f | rw | f | rw |
| RMSE: | 0.000076 | 0.000093 | 0.000049 | 0.000036 | 0.000073 | 0.000079 | 0.000091 | 0.000034 | 0.000138 | 0.000078 |
| Rank in Group 2: | 5 | 9 | 3 | 2 | 4 | 7 | 8 | 1 | 10 | 6 |
| Comparative analysis of GARCH-MIDAS and GARCH-MIDAS-LSTM models | ||||||||||
| Rel.RMSE * | 0.44 | 0.52 | 0.26 | 0.20 | 0.42 | 0.46 | 0.21 | 0.28 | 0.61 | 0.34 |
| RMSE%Δ ** | −55.81 | −48.46 | −74.38 | −95.55 | −58.23 | −54.35 | −78.88 | −71.90 | −39.23 | −65.62 |
| Forecast Rank | RMSE (Ascending) | Economic Indicator | Effect * | Model Name: | Spec. |
|---|---|---|---|---|---|
| 1 | 0.000034 | GPR | + | GARCH-MIDAS-LSTM | rw |
| 2 | 0.000036 | IPI, trend | - | GARCH-MIDAS-LSTM | rw |
| 3 | 0.000049 | IPI, trend | - | GARCH-MIDAS-LSTM | f |
| 4 | 0.000073 | IPI, cycle | - | GARCH-MIDAS-LSTM | f |
| 5 | 0.000076 | RV | + | GARCH-MIDAS-LSTM | f |
| 6 | 0.000078 | CLI | - | GARCH-MIDAS-LSTM | rw |
| 7 | 0.000079 | IPI, cycle | - | GARCH-MIDAS-LSTM | rw |
| 8 | 0.000091 | GPR | + | GARCH-MIDAS-LSTM | f |
| 9 | 0.000093 | RV | + | GARCH-MIDAS-LSTM | rw |
| 10 | 0.000138 | CLI | - | GARCH-MIDAS-LSTM | f |
| 11 | 0.000161 | GPR | + | GARCH-MIDAS | rw |
| 12 | 0.000174 | IPI, cycle | - | GARCH-MIDAS | f |
| 13 | 0.000174 | IPI, cycle | - | GARCH-MIDAS | rw |
| 14 | 0.000172 | RV | + | GARCH-MIDAS | f |
| 15 | 0.000181 | RV | + | GARCH-MIDAS | rw |
| 16 | 0.000191 | IPI, trend | - | GARCH-MIDAS | f |
| 17 | 0.000192 | GPR | + | GARCH-MIDAS | f |
| 18 | 0.000227 | CLI | - | GARCH-MIDAS | f |
| 19 | 0.000227 | CLI | - | GARCH-MIDAS | rw |
| 20 | 0.000812 | IPI, trend | - | GARCH-MIDAS | rw |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ersin, Ö.Ö.; Bildirici, M. Financial Volatility Modeling with the GARCH-MIDAS-LSTM Approach: The Effects of Economic Expectations, Geopolitical Risks and Industrial Production during COVID-19. Mathematics 2023, 11, 1785. https://doi.org/10.3390/math11081785
Ersin ÖÖ, Bildirici M. Financial Volatility Modeling with the GARCH-MIDAS-LSTM Approach: The Effects of Economic Expectations, Geopolitical Risks and Industrial Production during COVID-19. Mathematics. 2023; 11(8):1785. https://doi.org/10.3390/math11081785
Chicago/Turabian StyleErsin, Özgür Ömer, and Melike Bildirici. 2023. "Financial Volatility Modeling with the GARCH-MIDAS-LSTM Approach: The Effects of Economic Expectations, Geopolitical Risks and Industrial Production during COVID-19" Mathematics 11, no. 8: 1785. https://doi.org/10.3390/math11081785
APA StyleErsin, Ö. Ö., & Bildirici, M. (2023). Financial Volatility Modeling with the GARCH-MIDAS-LSTM Approach: The Effects of Economic Expectations, Geopolitical Risks and Industrial Production during COVID-19. Mathematics, 11(8), 1785. https://doi.org/10.3390/math11081785