Abstract
In this paper, we propose a model averaging estimation for the varying-coefficient partially linear models with missing responses. Within this context, we construct a HR weight choice criterion that exhibits asymptotic optimality under certain assumptions. Our model averaging procedure can simultaneously address the uncertainty on which covariates to include and the uncertainty on whether a covariate should enter the linear or nonlinear component of the model. The simulation results in comparison with some related strategies strongly favor our proposal. A real dataset is analyzed to illustrate the practical application as well.
Keywords:
model averaging; asymptotic optimality; HRCp; varying-coefficient partially linear model; missing data MSC:
62D10; 62G08; 62G20
1. Introduction
Model averaging, an alternative to model selection, addresses both model uncertainty and estimation uncertainty by appropriately compromising over the set of candidate models, instead of picking only one of them, and this generally leads to much smaller risk than that encountered in model selection. Over the past decade, various model averaging approaches, with optimal large sample properties have been actively proposed for complete data setting, such as the following: Mallows model averaging [,], optimal mean squared error averaging [], jackknife model averaging [,,], heteroscedasticity-robust (HR) model averaging [], model averaging based on Kullback–Leibler distance [], model averaging in a kernel regression setup [], and model averaging based on K-fold cross-validation [], among others.
In practice, many datasets in clinical trials, opinion polls and market research surveys often contain missing values. As far as we know, compared with the large body of research regarding model averaging for fully observed data, much less attention has been paid to performing optimal model averaging in the presence of missing data. Reference [] studied a model averaging method applicable to situations in which covariates are missing completely at random, by adapting a Mallows criterion based on the data from complete cases. Reference [] broadened the analysis in [] to a fragmentary data and heteroscedasticity setup. By applying the HR approach in [], Reference [] developed an optimal model averaging method in the presence of responses missing at random (MAR). In the context of missing response data, Reference [] constructed a model averaging method based on a delete-one cross-validation criterion. Reference [] proposed a two-step model averaging procedure for high-dimensional regression with missing responses at random.
The aforementioned model averaging methods in a missing data setting are asymptotically optimal in the sense of minimizing the squared error loss in a large sample case, but they all concentrate mainly on the simple linear regression model. In the context of missing data, it would be interesting to study model averaging in the varying-coefficient partially linear model (VCPLM) introduced by [], which allows interactions between a covariate and an unknown function through effect modifiers. Due to its flexible specification and explanatory power, this model has received extensive attention over the past decades. Different kinds of approaches have been raised to estimate the VCPLM, such as the following: estimation process based on the local polynomial fitting method [], the general series method [], and profile least squares estimation []. References [,,,] have developed various variable selection procedures in the VCPLM. As for model averaging in the VCPLM, only the following works have been conducted. In the measurement error model and the missing data model, References [,], respectively, established the limiting distribution of the resulting model averaging estimators of the unknown parameters of interest under the local misspecification framework. As pointed out by [], this framework, which was suggested by [], is a useful tool for asymptotic analysis, but its realism is subject to considerable criticism. Additionally, these two works studied existing model averaging strategies, based on the focused information criterion, but did not consider any new model averaging method with asymptotic optimality. When all data are available, References [,] developed two asymptotically optimal model averaging approaches for the VCPLM, based on a Mallows-type criterion and a jackknife criterion, respectively.
As far as we know, there remains no optimal model averaging approach developed for the VCPLM with missing responses. The main goal of the current paper was to fill this gap. To the best of our knowledge, this paper is the first to study the asymptotically optimal model averaging approach for the VCPLM in the presence of responses MAR without the local misspecification assumption. However, existing results are difficult to directly extend to our setup for the following two reasons. Firstly, existing optimal model averaging approaches in the VCPLM with complete data, such as the Mallows model averaging method proposed by [], and the jackknife model averaging method advocated by [], cannot be directly applied to our problem. Secondly, in contrast with the case in linear missing data models, studied by [,], our analysis is significantly complicated by two kinds of uncertainty in the VCPLM: the uncertainty on the selection of variables, and the uncertainty on whether a covariate should be allocated to the linear or nonlinear component of the model. These uncertainties have not been investigated much by the VCPLM literature. Motivated by these two challenges, we suggest a new model averaging approach for the VCPLM with responses MAR via the HR criterion. This new approach was developed by introducing a synthetic response based on an inverse probability weighted (IPW) technique. Then, HR model averaging could be conducted easily. Under certain assumptions, the weights selected by minimizing the HR criterion are demonstrated to be asymptotically optimal. Furthermore, we numerically illustrate that our method is always superior to its rivals in several designs with different kinds of model uncertainty. The detailed research procedures and methods can be found in Figure 1.
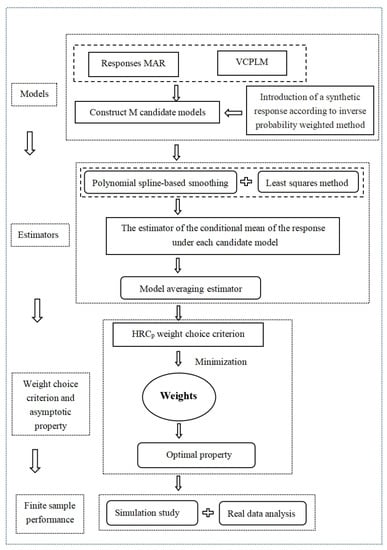
Figure 1.
The flow chart of our research.
The remainder of this article is organized as follows. We construct the model averaging estimator and establish its asymptotic optimality in Section 2. A simulation study is conducted in Section 3 to illustrate the finite sample performance of our strategy and a real data example is provided in Section 4. Section 5 contains some conclusions. Detailed proofs of the main results are relegated to the Appendix A.
2. Model Averaging Estimation
2.1. Model and Estimators
We considered the following VCPLM:
where is a scalar response variable, are covariates with and being countably infinite, is an unknown coefficient vector associated with , is an unknown coefficient function vector associated with , is a random statistical error with and . As in [,], we assume that the dimension of is one. Model (1) is flexible enough to cover a variety of other existing models, such as the following: the linear model that was studied by [,], the partially linear model that was studied by [] and the varying-coefficient model that was studied by []. For this model, we focus on the case where all covariates are always fully observed while some observations of the response variable may be missing. Specifically, we assume that is MAR in the sense that:
where if is completely observed, otherwise , and the selection probability function is bounded away from 0.
As in most literature on model averaging, we aimed to estimate the conditional mean of the response data , i.e., , which is especially useful in prediction. However, owing to the presence of the missing data, none of the existing optimal model averaging estimations for complete data could be directly utilized in our setting. We addressed this problem by introducing a synthetic response . By the aforementioned MAR assumption and some simple calculations, it is easy to observe that and , where . Therefore, under Model (1) and the MAR assumption, we have:
where satisfying and . As is apparent, in Model (3) the completely observed cases are weighted by their corresponding inverse selection probabilities, while the missing cases are weighted by zeros. Then, the analysis is conducted on the basis of the weighted data. By introducing the fully observed synthetic response , we obtain a new Model (3) the conditional expectation of which is equivalent to that of Model (1). Thus, the HR model averaging estimation for , the conditional mean of Model (1), can be alternatively derived by studying the HR model averaging estimation for Model (3) with the synthetic data when is known.
Supposing that there are M candidate VCPLMs to approximate the true data generating process of , which is given in (1), and the mth candidate VCPLM comprises covariates in and covariates in . Accordingly, there are M candidate models to approximate Model (3), and the mth candidate model contains the same covariates as that of the mth candidate VCPLM for (1). Specifically, the mth candidate model is:
where is the -dimensional sub-vector of and is the corresponding unknown coefficient vector, is the -dimensional sub-vector of and is the corresponding unknown coefficient function, denotes the approximation error of the mth candidate model. Details of the model averaging estimation procedure in our setup are provided below.
We employed the polynomial spline-based smoothing strategy to estimate each coefficient function first. Without loss of generality, suppose that the covariate u is distributed on a compact interval . Denote the polynomial spline space of degree on interval by . We introduce a sequence of knots on the interval : , where the number of interior knots increases with sample size n. The spline basis functions are polynomials of degree on all sub-intervals , and , and are -times continuously differentiable on . Let be a vector of the B-spline basis function in space . According to B-spline theory, there exists a in for some -dimensional spline coefficient vector such that , where is the qth element of . We would like to estimate and by the least squares method based on the criterion:
Let be an -dimensional vector. Denote , and . Here, we assume that the regressor matrix has full column rank . The solution to the minimization problem provided in (5) can be expressed as:
where . Let , then the estimator of under the mth candidate model follows:
Denoting , we obtain .
To smooth estimators across all candidate models, we may define the model averaging estimator of as:
where is a weight vector in the set .
2.2. Weight Choice Criterion and Asymptotically Optimal Property
Obviously, the weight vector w, which represents the contribution of each candidate model in the final estimation, plays a central role in (9). Our weight choice criterion was motivated by applying the HR method of [], which is designed for the complete data setting, and is defined as follows:
where is the residual from a preliminary estimation, is the ith diagonal element of the matrix . As suggested by [], can be obtained by a model, indexed by , which includes all the regressors in the candidate models. That is:
where is the rank of the regressor matrix in model , .
So far, we have assumed that the selection probability function is known. This is, of course, not the case in real-world data analysis, and the proposed criterion (10) is, hence, computationally infeasible. To obtain a feasible criterion in practice, we needed to estimate first. Following much of the missing data literature, and under the MAR assumption defined above, we assume that for an unknown parameter vector and we have:
for some function , the form which is known to be a finite-dimensional parameter . Let be the maximum likelihood estimator (MLE) of . Then the selection probability function can be estimated by . In what follows, the Greek letter indexed by denotes that it is obtained by replacing in its equation with the estimator . A feasible form of the weight choice criterion based on HR method is, thus, given by:
and the weight vector can be obtained by:
Then, the corresponding model averaging estimator of can be expressed as , and its asymptotic optimality can be developed under some regularity conditions.
Some notations and definitions are required before we list these conditions. Write , , , . Define the squared error loss of and the corresponding risk as and . Let , be a vector with the mth element being 1 and the others being 0, and let be the parameter space of . Define r as a positive integer and , such that . Let be a collection of functions s on whose rth derivative exists and satisfies the Lipschitz condition of order , i.e.,
where is a positive constant. All limiting processes discussed throughout the paper are under . The conditions needed to derive asymptotic optimality are as follows:
- (Condition (C.1)) has a unique maximum at in , where is an inner point of and is compact. , and is twice continuously differentiable with respect to , where is a constant. for all ’s in a neighborhood of .
- (Condition (C.2)) for some integer and for some constant . There exists a constant , such that .
- (Condition (C.3)) , where K is given in Condition (C.2).
- (Condition (C.4)) Each coefficient function .
- (Condition (C.5)) The density function of u, say f, is bounded away from 0 and infinity on .
- (Condition (C.6)) , where denotes the ith diagonal element of .
- (Condition (C.7)) .
- (Condition (C.8)) .
Condition (C.1) is from [] and is similar to Condition (C1) of [], which ensures the consistency and asymptotic normality of the MLE . The first part of Condition (C.2) is a commonly used assumption of the conditional moment of the random error term in model averaging literature; see, for example, [,,]. The second part of Condition (C.2) is the same as the assumption (C.2) of [] that bounds the conditional expectation . Condition (C.3) not only requires , but also requires that M and tend to infinity slowly enough. Such a condition can be viewed as an analogous version of Assumption 2.3 in [], in which the authors proposed the HR model averaging method in a complete data setting. Conditions (C.4) and (C.5) are two general requirements that are necessary for studies of the B-spline basis, see [,]. Condition (C.6), an assumption that excludes peculiar models, is from []. A similar condition, which is frequently used in studies of optimal model averaging based on cross-validation, can be found in assumption of [] and of []. Condition (C.7) states that approaches infinity at a rate faster than , and is the same as Condition (C.3) of [] and implied by (A3) of []. Condition (C.8) limits the increasing rate of the number of covariates. A similar condition is used in other model averaging studies, such as (22) in []. In fact, (22) in [] can be obtained by combining our Conditions (C.7) and (C.8).
The following theorem states the asymptotic optimality of the corresponding model averaging estimator based on the feasible HR criterion.
Theorem 1.
Suppose that Conditions (C.1)–(C.8) hold. Then, we have
in probability as .
Theorem 1 reveals that when the selection probability function is estimated by and the conditions listed are satisfied, , the weight vector selected by the feasible HR criterion leads to a squared error loss that is asymptotically identical to that of the infeasible best possible weight vector. This indicates the asymptotic optimality of the resulting model averaging estimator . The detailed proof of Theorem 1 is in Appendix A.
3. A Simulation Study
In this section, we conduct a simulation study with five designs to evaluate the performance of the proposed method, including selection of the interior knot number and a comparison of several model selection and model averaging procedures.
3.1. Data Generation Process
Our setup was based on the setting of [], except that the response variable is subject to missingness. Specifically, we generated data from the following model:
where and are drawn from a multivariate normal distribution with mean 0 and covariance matrix with , , . We changed the value of , so that the population varied from to , where was the sample variance. The coefficients of the linear part were set as , and the coefficient functions were determined by . Under the MAR assumption, we generated the missingness indicator from the following two logistic regression models, respectively:
- Case 1: ;
- Case 2: .
For the preceding two cases, the average missing rates (MR) were about and , respectively. In this simulation, we assumed the parametric function applied in our proposed method was correctly specified in both cases.
To investigate the performance of the methods as comprehensively as possible, the sample sizes were taken to be and , and five simulation designs, with different M and covariate settings, were considered. These five designs are displayed in Table 1, in which INT(·) returns the nearest integer from the corresponding element. So, in Design 1 and Design 3, and 18 for the two sample sizes. We required every candidate model to contain at least one covariate in the linear part, leading to candidate models in Designs 2 and 4. In Design 5, each candidate model included at least one covariate of in the linear part and one covariate of in the nonparametric part, and each covariate could not exist in both parts. This led to candidate models. In summary, in the first four designs, Designs 1 and 3 for the nested case and Designs 2 and 4 for the non-nested case, there was, a priori knowledge of which covariates should enter the nonparametric part of the model, but the specification of the linear part was uncertain. The last design incorporated two types of uncertainty: uncertainty on the choice of variables and uncertainty on whether the variable should be in the linear or nonparametric part given that it is already included in the model.

Table 1.
Summary of designs in simulation study.
3.2. Estimation and Comparison
3.2.1. Selection of the Knot Number
We used the cubic B-splines to approximate each nonparametric function, and the spline basis matrix was produced by the function “bs(·, df)” in the“splines” package of the R project, where the degree of freedom df = 4 + number of knots. We assessed the effect of the knot number on the performance of our proposal based on the following risk:
where 1000 was the number of simulation trials and was the model averaging estimator of in the rth run.
We set and to show the impact of the number of interior knots on the risk of our proposed procedure in the five designs. Since the simulated results produced were similar for Designs 1 and 2, and for Designs 3 and 4, we only report the results from Designs 1, 3 and 5, which are presented in Figure 2. This figure demonstrates the risk against df for a variety of combinations of designs and missing rates considered. From Figure 2, we note that, for almost all situations considered, generally the risk tended to increase with the number of knots. In other words, the larger number of knots yielded a more serious oversmoothing effect, and, hence, lower estimation accuracy. As suggested by this figure, for our proposed model averaging method, we specified df = 4, which corresponded to the smallest risk. Therefore, in this simulation, we adopted the suggestion of applying df = 4 for all five designs. In other words, the number of knots was set to be 0 in our analysis, which resulted in a basis for ordinary polynomial regression. The number of knots of the B-spline basis function was also set to be 0 in [], which examined the influence of the knot number on the model averaging method for the varying-coefficient model when all data were available.
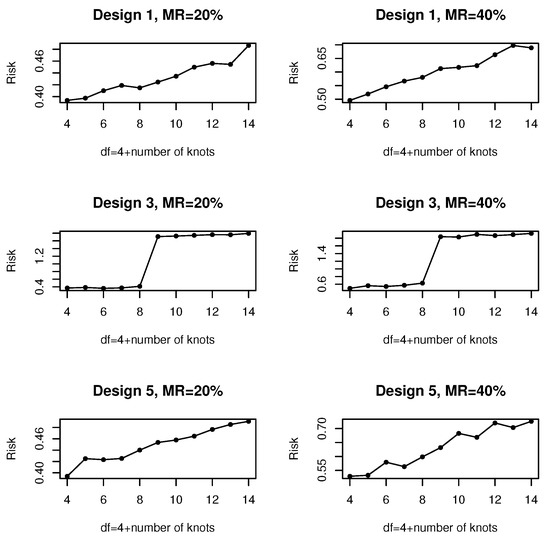
Figure 2.
The curves of the risk with the number of knots over 1000 replications.
3.2.2. Alternative Methods
We conducted some simulation experiments to assess the finite sample performance of our proposed model averaging approach, called the HR approach, in VCPLM with missing data. We compared it with four alternatives, the missing data problems of which were addressed by the IPW method discussed in Section 2. The alternatives included two well-known model selection methods (AIC and BIC) and two widely-used model averaging methods (SAIC and SBIC). Along the lines of [], we defined the AIC and BIC scores under the varying-coefficient partially linear missing data framework as:
and
where . These two model selection methods select the model corresponding to the smallest score of the information criterion. The two model averaging methods, SAIC and SBIC, respectively, assign weights:
and
to the mth candidate model. As suggested by a referee, we also compared our proposal with the Mallows model averaging approach of [] with a complete-case analysis, which just excluded the individuals with missingness (denoted as CC-MMA). We evaluated the performance of these six methods by computing their risks, and the corresponding results for Designs 1–5 are respectively displayed in Figure 3, Figure 4, Figure 5, Figure 6 and Figure 7. For better comparison, all risks were normalized by the risk of the AIC model selection method.
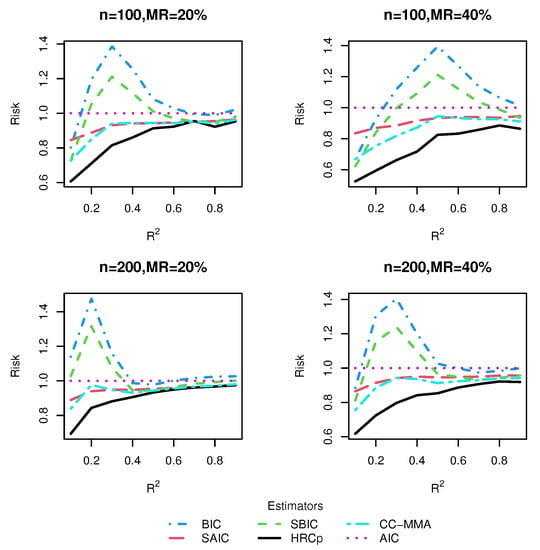
Figure 3.
Risk comparisons for Design 1.
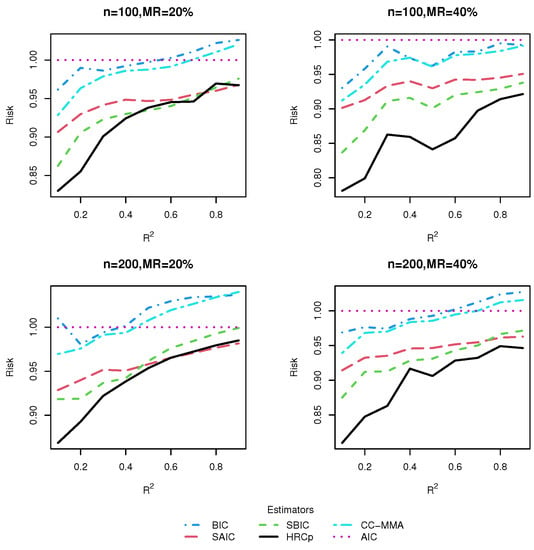
Figure 4.
Risk comparisons for Design 2.
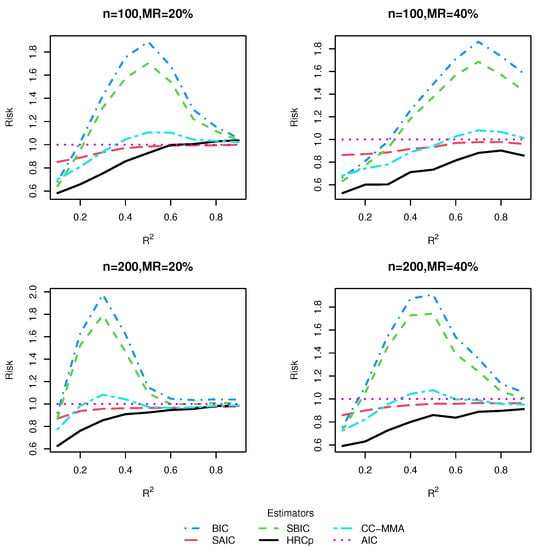
Figure 5.
Risk comparisons for Design 3.
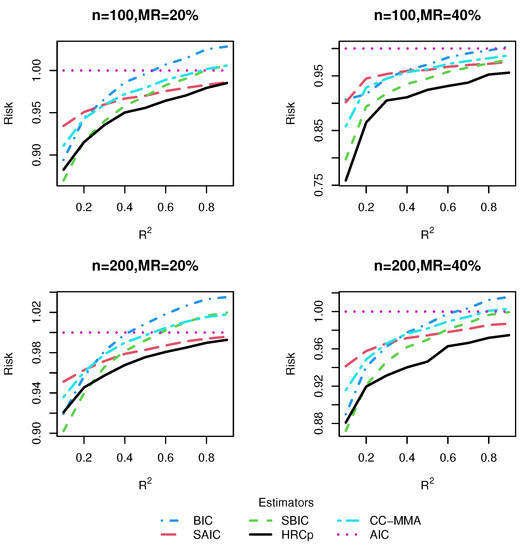
Figure 6.
Risk comparisons for Design 4.
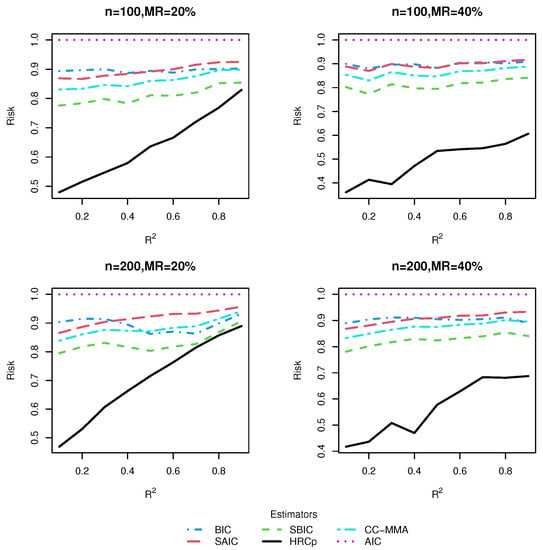
Figure 7.
Risk comparisons for Design 5.
Besides, following an anonymous referee’s suggestion, we make a comparison of computation time between different model selection and averaging methods. To be more specific, we examined the resulting computation time in seconds by, respectively, employing six methods for five designs when , and MR = . The corresponding results are listed in Table 2.
Table 2.
Averaged computation time in seconds over 3 runs, when , and MR .
3.3. Simulation Results
3.3.1. Risk Comparison
From these five figures, we observe that, in general, model averaging approaches worked better than model selection approaches. As shown in most figures, the risk difference in favor of model averaging over model selection was more pronounced when was small or moderate than when was large. This is hardly surprising as it is hard to identify only one best model in the presence of much noise corresponding to a small , while the model averaging method shields against selecting a very poor model by compromising across all possible models. On the other hand, when was large, model selection could sometimes be a better strategy than model averaging. A possible reason for this is that the small noise in the data allows the model selection strategy to select the right model with very high frequencies.
As for the comparison of HR method with its rivals, we found that no matter whether the candidate models were nested or not, our proposed model averaging method yielded the smallest risk in almost all combinations of simulation designs, sample sizes and missing rates considered, although when was very high, the information criterion-based model averaging methods could sometimes be marginally preferable to ours. The superiority of our method was more marked in Design 5, which was subject to two kinds of uncertainty simultaneously, uncertainty in covariate inclusion and uncertainty in structure, than in Designs 1–4, which were only associated with uncertainty in the linear part specification. This finding provided evidence that our model averaging method was most effective when both the linear and nonlinear components of the model are uncertain, as in most real-world applications. The good performance of our method in finite samples can be partially explained by noting that the optimality of the HR estimator does not depend on the correct specification of candidate models. As expected, it was observed that information criterion-based model averaging methods invariably produced more accurate estimators than their model selection counterparts. The advantage of our approach became more noticeable as the missing rate increased.
To sum up, within the context of the VCPLM with missing responses, and when the missing data is handled by an IPW method, our proposed HR model averaging method performs better than information criterion-based model selection and averaging methods in terms of risk, especially when the model is characterized by much noise. By and large, our results are parallel to those of [], which investigated model averaging in the VCPLM with complete data. Additionally, we found evidence of our proposed IPW technique-based model averaging method, HR, enjoying significantly smaller risk than a model averaging method with complete-case analysis, CC-MMA.
3.3.2. Computation Time Comparison
According to Table 2, it was hardly surprising that model selection methods always needed less computation time than model averaging methods in all designs. Among all model averaging methods, two data-driven methods (CC-MMA and HR) spent slightly more time than the two information criterion-based methods (SAIC and SBIC). As for the comparison between CC-MMA and HR, it was expected that our method would perform slightly more slowly than CC-MMA because of the need to approximate the unknown propensity score function. In general, from the perspective of computation time, our method was slightly inferior to other methods, but it greatly dominated its competitors in terms of estimation accuracy. Thus, it is worthwhile to carry out the HR model averaging method to obtain a comparatively accurate estimator, even if a little computation time has to be sacrificed.
4. Real Data Analysis
In this section, we applied our model averaging method to analyze data including information about aged patients from 36 for-profit nursing homes in San Diego, California, provided in [] and studied by [,]. The response variable, y, was the natural logarithm of the days in the nursing home. The five covariates were , a binary variable indicating whether the patient was treated at a nursing home; , a binary variable indicating whether the patient was male; , a binary variable indicating whether the patient was married; , a health status variable, with a smaller value indicating better health condition; , the normalized age of the patients was the effect modifier, with age ranging from 65 to 102.
We considered fitting the data by the VCPLM, but we were not sure which of , , and to include, and we were uncertain whether to assign a variable in the linear or nonparametric part. Therefore, we considered all possibilities, namely, a variable in the linear part or in the nonparametric part or not in the model. Similar to the simulation study, we required all candidate models to include no fewer than one linear and one nonparametric variable. This resulted in 50 possible models. In our analysis, we ignored 332 censored observations from the original data, and only focused on the remaining 1269 uncensored sample points. Further, we randomly selected observations from the 1269 uncensored observations as the training set and the remaining observations were taken as test set, where and 1100. Since the data points we used could be fully observed, to illustrate the application of our method, we artificially created missing responses in the training data, according to the following missing data mechanism:
Hence, the corresponding mean missing rate was about .
We employed observations in the training set to obtain estimators of model parameters in each candidate model, and then performed four model averaging (HR, CC-MMA, SAIC and SBIC) and two model selection (AIC and BIC) procedures. We fitted each candidate model by applying the estimation method introduced in Section 2. The cubic B-splines were adopted to approximate each coefficient function. Following the suggestion in the simulation study, we set the number of knots to be 0. We then evaluated the predictive performance of these six approaches by computing their mean squared prediction error (MSPE). As suggested by [,], the observations in the test set were utilized to compute the MSPE as follows:
where is the predicted value for the ith patient based on each approach. We repeated the above process 500 times and calculated the mean, median and standard deviation (SD) of the MSPEs of the six strategies across the replications. For comparison convenience, all MSPEs were normalized by dividing the MSPE of AIC, which was referred to as the relative MSPE (RMSPE). The results are summarized in Table 3.
Table 3.
The mean, median and SD of RMSPE across 500 repetitions.
The results in Table 3 show that in almost all situations, our proposed HR method had the best predictive efficiency among the six approaches considered. The superiority of our method was particularly obvious in terms of the mean and median, since the smallest mean and median were invariably produced by our method for all training sample sizes. The SBIC always yielded a mean and median that were second to the HR but the best among the remaining five methods. As for the comparison of SD, we found evidence that our method had an edge over other methods when was not less than 1000, while the SBIC frequently yielded the smallest SD when was less than 1000. This implied that our HR method outperformed the SBIC method when the size of the training set was large. We further noted that all numbers in this table were smaller than 1, which implied that the AIC was the worst method among those considered, irrespective of the performance yardstick.
We also provide the Diebold and Mariano test results for the differences in MSPE, which are displayed in Table 4. A positive/negative test statistic in this table denotes that the estimator in the numerator leads to a bigger/smaller MSPE than the estimator in the denominator. The test statistics and p-values listed in columns 3, 6, 7 and 9 provide evidence that the MSPE differences between our proposed HR estimator and the BIC, SAIC, AIC and CC-MMA estimators were statistically significant for all training set sizes. Considering the HR and SBIC estimators, column 8 demonstrates that the advantage of HR over SBIC was statistically significant in the case with and 1100. However, the same cannot be reported about the differences in performance between the HR and SBIC estimators when was less than 1000, as presented in column 8. This result reinforced the intuition that the HR estimator was more reliable than the SBIC estimator when the training set size was large. The test results shown in columns 3–7 indicate that the MSPE differences between AIC estimator and the remaining five estimators were statistically significant in all situations. The test results given in columns 3, 8, 9 and 10 imply the same about the differences between the BIC and the other five estimators.
Table 4.
Diebold–Mariano test results for the differences in MSPE.
5. Conclusions
Considering model averaging estimation in the VCPLM with missing responses, we propose a HR weight choice criterion and its feasible form. Our model averaging process can jointly incorporate two layers of model uncertainty: the first concerns which covariates to include and the second further concerns whether a covariate should be in the linear or nonparametric component. The resultant model averaging estimator is shown to be asymptotically optimal in the sense of achieving the lowest possible squared error loss under certain regularity conditions. The simulation results demonstrated that, in several designs with different types of model uncertainty, our model averaging method always performed much better in comparison with existing methods. The real data analysis also reveals the superiority of the proposed strategy.
There are still many issues deserving future research. Firstly, we only considered model averaging for the VCPLM in the context of missing response data, so it would be worthwhile considering cases where some covariates are also subject to missingness, or missing data arise in a more general framework, such as the generalized VCPLM which permits a discrete response variable. Secondly, in our analysis the missing data mechanism was MAR. The development of a model averaging procedure in a more natural, but more complex, non-ignorable missing data case and the establishment of its asymptotic property is still challenging and warrants future studies. Thirdly, our procedure is applicable only when the dimension parameters and are less than the sample size n. The consideration of an asymptotically optimal model averaging method for high dimensional VCPLM with missing data is meaningful and, thus, merits future research.
Author Contributions
Conceptualization, W.C.; methodology, J.Z., W.C. and G.H.; software, J.Z. and G.H.; supervision, W.C. and G.H.; writing-original draft, J.Z.; writing—review and editing, G.H. All authors have read and agreed to the published version of the manuscript.
Funding
The work of Zeng is supported by the Important Natural Science Foundation of Colleges and Universities of Anhui Province (No.KJ2021A0929). The work of Hu is supported by the Important Natural Science Foundation of Colleges and Universities of Anhui Province (No.KJ2021A0930).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in real data analysis is available at: https://www.stats.ox.ac.uk/pub/datasets/csb/ (accessed on 27 January 2023).
Acknowledgments
The authors would like to thank the reviewers and editors for their careful reading and constructive comments.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Lemma A1.
If Conditions (C.1) and (C.2) hold, then there exists a positive constant , such that:
where K is given in Condition (C.2).
Proof of Lemma A1.
Note that:
where the second inequality is from Condition (C.1) and the third inequality from Condition (C.2). Let . By means of inequality, we have:
According to Condition (C.2), we obtain:
where . □
Lemma A2.
Under Conditions (C.1) and (C.2), one has .
Proof of Lemma A2.
By Cauchy–Schwarz inequality and Taylor expansion, this lemma could be proved, based on some arguments used in the proof of Lemma 1 of []. So we omitted it here. □
Proof of Theorem 1.
Let be the largest singular value of a matrix, be an diagonal matrix whose ith diagonal element is , be an diagonal matrix whose ith diagonal element is , , . From Lemma 1, we obtain . After some simple calculations, we know is an idempotent matrix with , and, hence, for any . Observe that:
where , . Since is unrelated to w, minimizing is equivalent to minimizing . Therefore, to prove Theorem 1, we only need to verify that:
We observe, for any , that:
where is a constant, the second inequality is from Chebyshev’s inequality, the third inequality is from Theorem 2 of [], and the last inequality is because and , and the equality is ensured by Condition (C.3). Then (A6) holds because of the following fact:
By means of similar steps, we obtain
where is a constant, and the last inequality is due to and . Therefore, (A7) is satisfied by previous argument, which along with (A6), implies (A4). On the other hand, (A5) can be easily obtained by Lemma A2 and Condition (C.7). So (A1) is correct.
From Cauchy–Schwarz inequality, (A1), Lemma A2 and Condition (C.7), one has:
So, (A2) is true. In what follows, we provide the proof of (A3), which yields the desired result of Theorem 1.
By Cauchy–Schwarz inequality and some algebraic manipulations, we obtain:
Similar to the proof steps in (A7) and (A6), respectively, it is not difficult to obtain (A8) and (A9). As for (A10), it is readily seen that:
Following an argument similar to that used in [], we know that both two terms in the second line of (A14) are equal to . So, (A10) is valid. We now prove (A11) and (A12). From Lemma A1, we find that , and, thus, . Consequently, based on Condition (C.7), we have:
So, we establish (A11). By Condition (C.6), it is easy to show that . This, together with Conditions (C.7) and (C.8), and Lemma A2, yields:
References
- Hansen, B.E. Least squares model averaging. Econometrica 2007, 75, 1175–1189. [Google Scholar] [CrossRef]
- Wan, A.T.K.; Zhang, X.; Zou, G. Least squares model averaging by Mallows criterion. J. Economet. 2010, 156, 277–283. [Google Scholar] [CrossRef]
- Liang, H.; Zou, G.; Wan, A.T.K.; Zhang, X. Optimal weight choice for frequentist model average estimators. J. Am. Stat. Assoc. 2011, 106, 1053–1066. [Google Scholar] [CrossRef]
- Hansen, B.E.; Racine, J.S. Jackknife model averaging. J. Economet. 2012, 167, 38–46. [Google Scholar] [CrossRef]
- Zhang, X.; Wan, A.T.K.; Zou, G. Model averaging by jackknife criterion in models with dependent data. J. Economet. 2013, 174, 82–94. [Google Scholar] [CrossRef]
- Lu, X.; Su, L. Jackknife model averaging for quantile regressions. J. Economet. 2015, 188, 40–58. [Google Scholar] [CrossRef]
- Liu, Q.; Okui, R. Heteroscedasticity-robust Cp model averaging. Economet. J. 2013, 16, 463–472. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, G.; Carroll, R.J. Model averaging based on Kullback-Leibler distance. Stat. Sinica 2015, 25, 1583–1598. [Google Scholar] [CrossRef] [PubMed]
- Zhu, R.; Zhang, X.; Wan, A.T.K.; Zou, G. Kernel averaging estimators. J. Bus. Econ. Stat. 2022, 41, 157–169. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, C.A. Model averaging prediction by K-fold cross-validation. J. Economet. 2022, in press. [Google Scholar]
- Zhang, X. Model averaging with covariates that are missing completely at random. Econ. Lett. 2013, 121, 360–363. [Google Scholar] [CrossRef]
- Fang, F.; Lan, W.; Tong, J.; Shao, J. Model averaging for prediction with fragmentary data. J. Bus. Econ. Stat. 2019, 37, 517–527. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Q.; Liu, W. Model averaging for linear models with responses missing at random. Ann. I. Stat. Math. 2021, 73, 535–553. [Google Scholar] [CrossRef]
- Wei, Y.; Wang, Q. Cross-validation-based model averaging in linear models with responses missing at random. Stat. Probabil. Lett. 2021, 171, 108990. [Google Scholar] [CrossRef]
- Xie, J.; Yan, X.; Tang, N. A model-averaging method for high-dimensional regression with missing responses at random. Stat. Sinica 2021, 31, 1005–1026. [Google Scholar] [CrossRef]
- Li, Q.; Huang, C.J.; Li, D.; Fu, T.T. Semiparametric smooth coefficient models. J. Bus. Econ. Stat. 2002, 20, 412–422. [Google Scholar] [CrossRef]
- Zhang, W.; Lee, S.Y.; Song, X. Local polynomial fitting in semivarying coefficient model. J. Multivariate Anal. 2002, 82, 166–188. [Google Scholar] [CrossRef]
- Ahmad, I.; Leelahanon, S.; Li, Q. Efficient estimation of a semiparametric partially linear varying coefficient model. Ann. Stat. 2005, 33, 258–283. [Google Scholar] [CrossRef]
- Fan, J.; Huang, T. Profile likelihood inferences on semiparametric varying-coefficient partially linear models. Bernoulli 2005, 11, 1031–1057. [Google Scholar] [CrossRef]
- Li, R.; Liang, H. Variable selection in semiparametric regression modeling. Ann. Stat. 2008, 36, 261–286. [Google Scholar] [CrossRef]
- Zhao, P.; Xue, L. Variable selection for semiparametric varying coefficient partially linear models. Stat. Probabil. Lett. 2009, 79, 2148–2157. [Google Scholar] [CrossRef]
- Zhao, P.; Xue, L. Variable selection for semiparametric varying coefficient partially linear errors-in-variables models. J. Multivariate Anal. 2010, 101, 1872–1883. [Google Scholar] [CrossRef]
- Zhao, W.; Zhang, R.; Liu, J.; Lv, Y. Robust and efficient variable selection for semiparametric partially linear varying coefficient model based on modal regression. Ann. I. Stat. Math. 2014, 66, 165–191. [Google Scholar] [CrossRef]
- Wang, H.; Zou, G.; Wan, A.T.K. Model averaging for varying-coefficient partially linear measurement error models. Electron. J. Stat. 2012, 6, 1017–1039. [Google Scholar] [CrossRef]
- Zeng, J.; Cheng, W.; Hu, G.; Rong, Y. Model averaging procedure for varying-coefficient partially linear models with missing responses. J. Korean Stat. Soc. 2018, 47, 379–394. [Google Scholar] [CrossRef]
- Zhu, R.; Wan, A.T.K.; Zhang, X.; Zou, G. A Mallows-type model averaging estimator for the varying-coefficient partially linear model. J. Am. Stat. Assoc. 2019, 114, 882–892. [Google Scholar] [CrossRef]
- Hjort, N.L.; Claeskens, G. Frequentist model average estimators. J. Am. Stat. Assoc. 2003, 98, 879–899. [Google Scholar] [CrossRef]
- Hu, G.; Cheng, W.; Zeng, J. Model averaging by jackknife criterion for varying-coefficient partially linear models. Commun. Stat.-Theor. M. 2020, 49, 2671–2689. [Google Scholar] [CrossRef]
- Xia, X. Model averaging prediction for nonparametric varying-coefficient models with B-spline smoothing. Stat. Pap. 2021, 62, 2885–2905. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, W. Optimal model averaging estimation for partially linear models. Stat. Sinica 2019, 29, 693–718. [Google Scholar] [CrossRef]
- White, J. Maximum likelihood estimation of misspecified models. Econometrica 1982, 50, 1–25. [Google Scholar] [CrossRef]
- Liang, Z.; Chen, X.; Zhou, Y. Mallows model averaging estimation for linear regression model with right censored data. Acta Math. Appl. Sin. E. 2022, 38, 5–23. [Google Scholar] [CrossRef]
- Zhang, X.; Liang, H. Focused information criterion and model averaging for generalized additive partial linear models. Ann. Stat. 2011, 39, 174–200. [Google Scholar] [CrossRef]
- Li, K.C. Asymptotic optimality for Cp, CL, cross-validation and generalized cross-validation: Discrete index set. Ann. Stat. 1987, 15, 958–975. [Google Scholar] [CrossRef]
- Zhang, X.; Yu, D.; Zou, G.; Liang, H. Optimal model averaging estimation for generalized linear models and generalized linear mixed-effects models. J. Am. Stat. Assoc. 2016, 111, 1775–1790. [Google Scholar] [CrossRef]
- Ando, T.; Li, K.C. A weighted-relaxed model averaging approach for high-dimensional generalized linear models. Ann. Stat. 2017, 45, 2654–2679. [Google Scholar] [CrossRef]
- Morris, C.N.; Norton, E.C.; Zhou, X.H. Parametric duration analysis of nursing home usage. In Case Studies in Biometry; Lang, N., Ryan, L., Billard, L., Brillinger, D., Conquest, L., Greenhouse, J., Eds.; Wiley: New York, NY, USA, 1994. [Google Scholar]
- Fan, J.; Lin, H.; Zhou, Y. Local partial-likelihood estimation for lifetime data. Ann. Stat. 2006, 34, 290–325. [Google Scholar] [CrossRef]
- Whittle, P. Bounds for the moments of linear and quadratic forms in independent variables. Theor. Probab. Appl. 1960, 5, 331–335. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).