
CBFISKD: A Combinatorial-Based Fuzzy Inference System for Keylogger Detection
 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
- the automatic simulation of keylogger patterns with ASCII-coded sequences;
- the use of a back-to-back combinatorial algorithm for keylogger detection and analysis;
- the use of a fuzzy inference system to categorize keyloggers into their severity levels;
- the provision of color codes for keylogger detection.
2. Background and Related Work
2.1. Combinatorial Algorithm
2.2. Fuzzy Logic
2.3. Keylogger Detection
2.4. Motivation for the Work
3. Materials and Methods
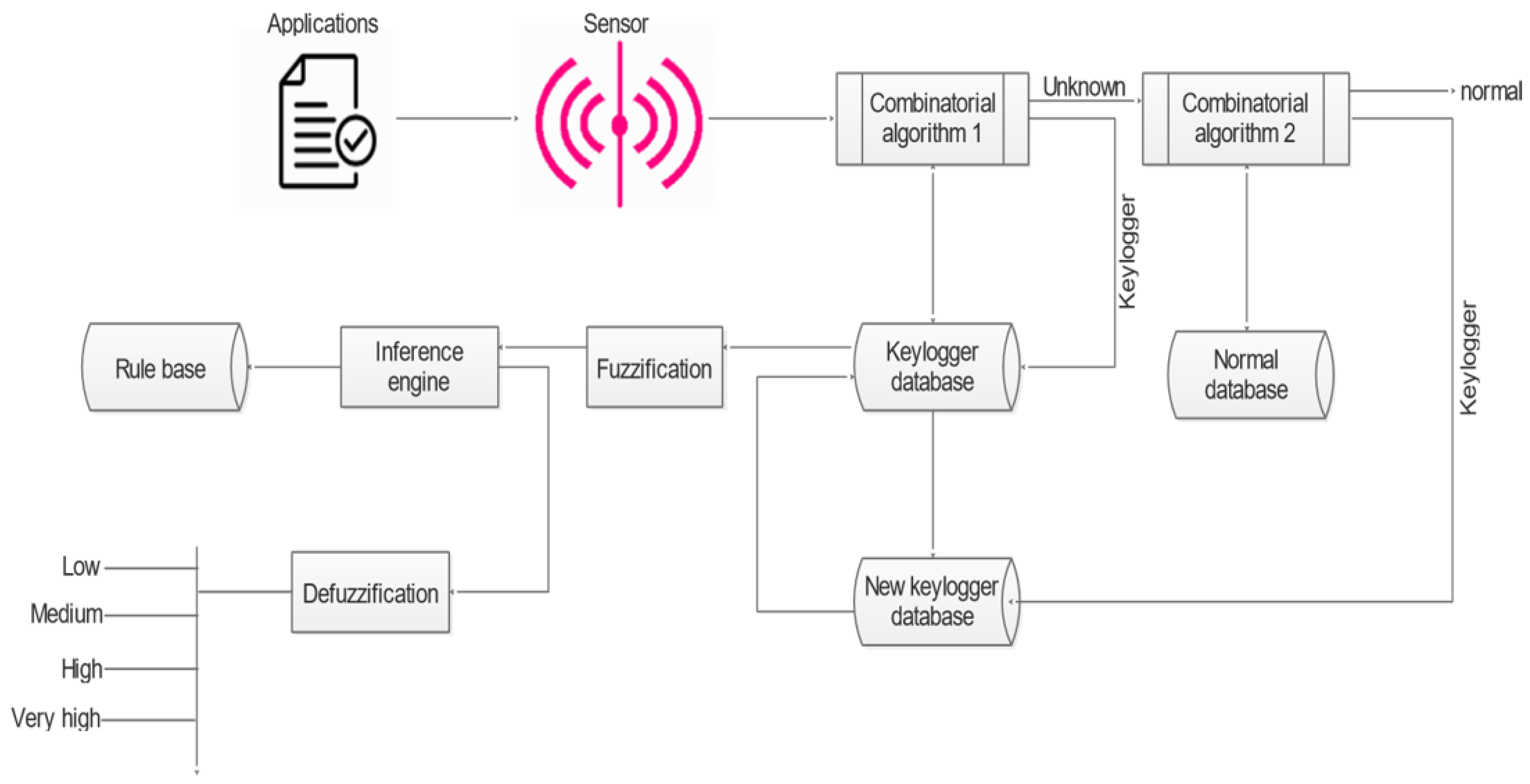
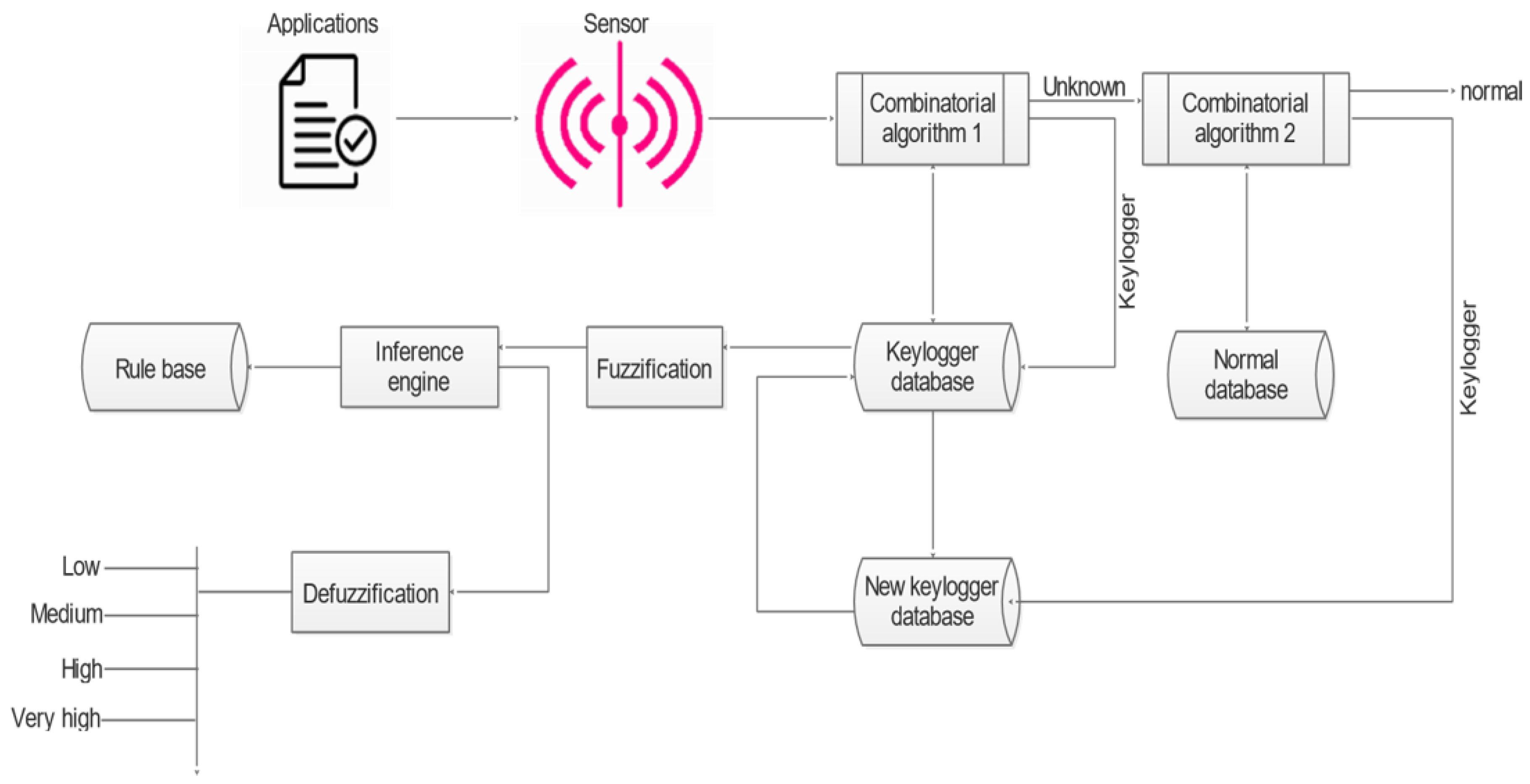
3.1. Overview of the Proposed Method
3.2. Design Approach
3.2.1. Dataset Description
3.2.2. Keylogger Detection
- Sensor
| Algorithm 1 Combinatorial pattern matching (p, t) |
|
- Combinatorial Algorithm 1
| Algorithm 2 CaKLDA: Combinatorial Keylogger Detection Algorithm |
|
- Combinatorial Algorithm 2
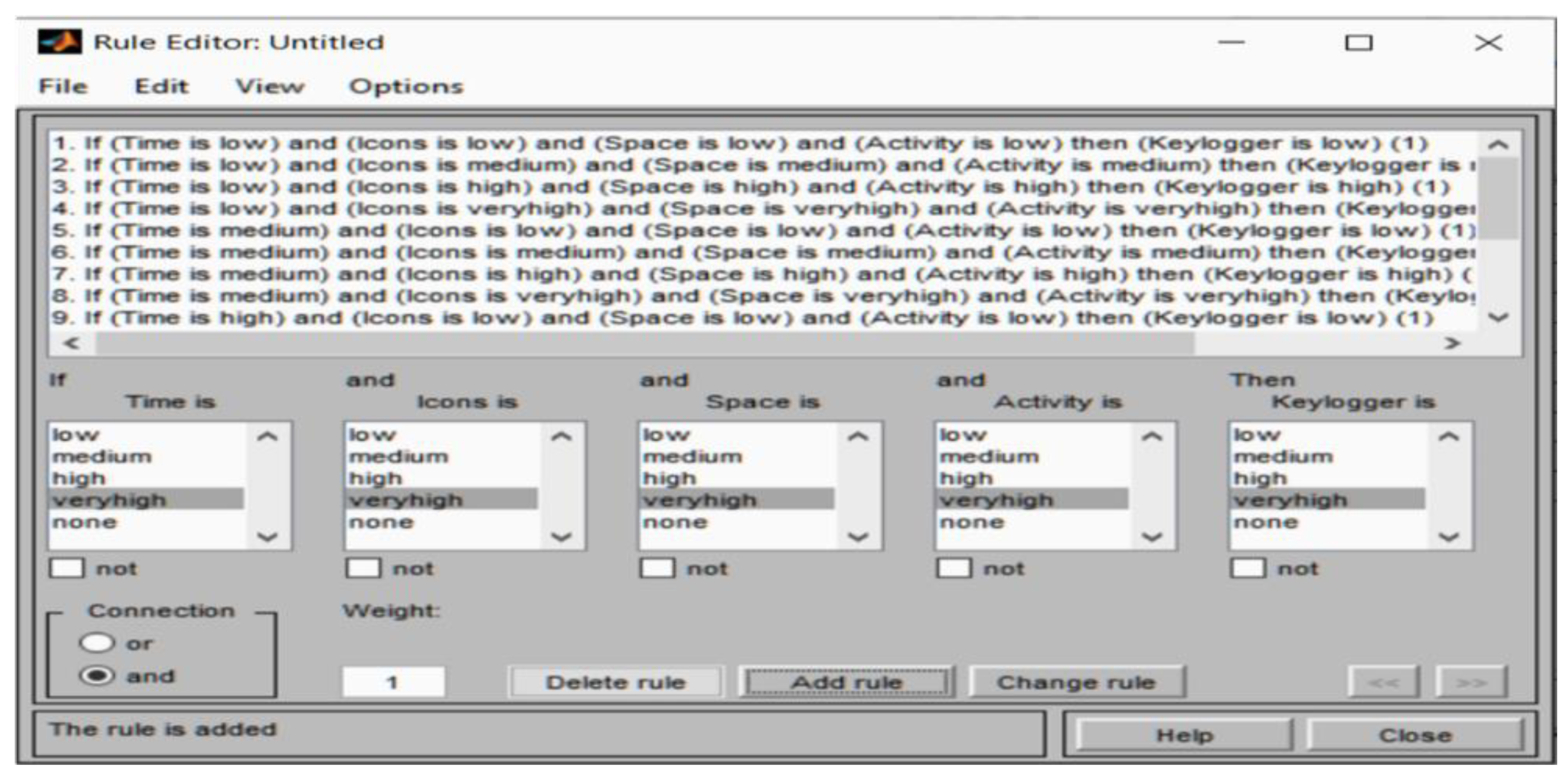
3.2.3. Keylogger Classification
- Fuzzy set
- Response time
- New icons in the system
- A drop in storage space
- Increased hard drive activity
- Linguistic variables
- Fuzzification
- Fuzzy rules
- Inference engine
- Defuzzification
3.2.4. Algorithms
| Algorithm 3 FISCA: Fuzzy Inference System Classification Algorithm |
|
4. Implementation, Results, and Discussion
4.1. Implementation
Training Databases
- GUI design and partition
- Training the system
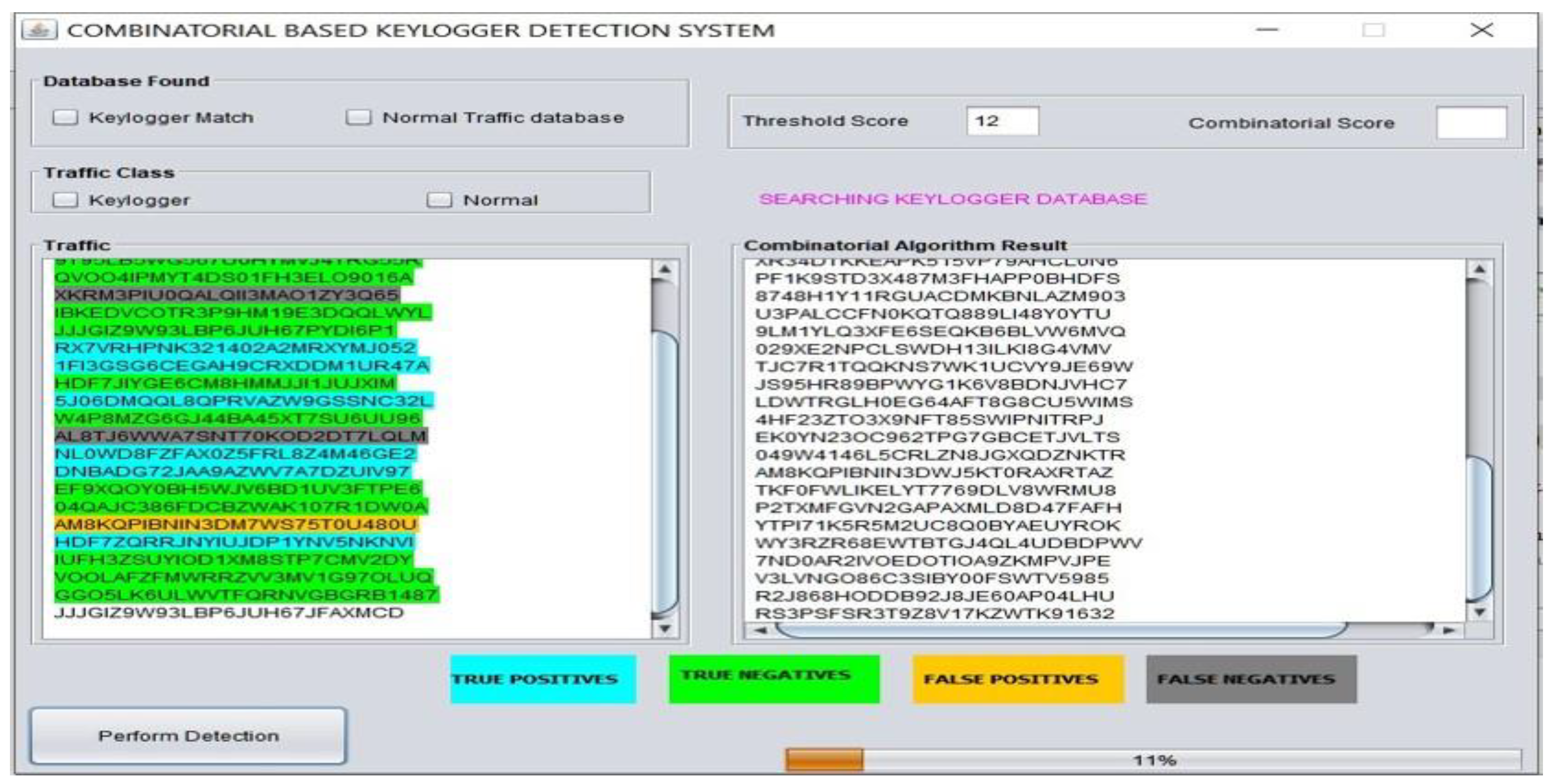
- Threshold score
4.2. Evaluation
4.3. Results
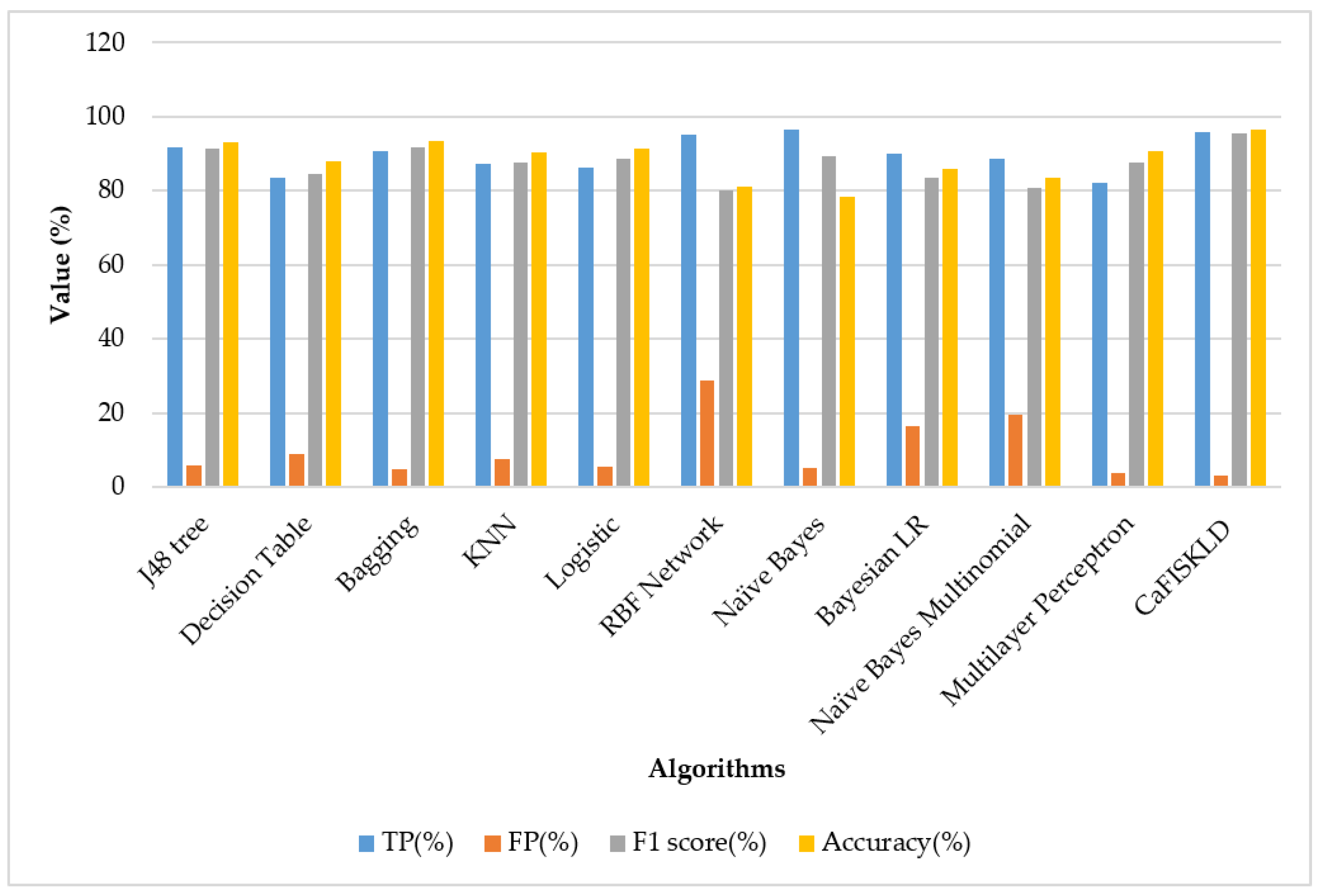
- CaFISKLD and J48 tree
- CaFISKLD and the decision table
- CaFISKLD and bagging
- CaFISKLD and KNN
- CaFISKLD and logistic regression
- CaFISKLD and the RBF network
- CaFISKLD and Naive Bayes
- CaFISKLD and Bayesian LR
- CaFISKLD and the Naive Bayes multinomial
- CaFISKLD and the Multilayer Perceptron
4.4. Complexity Analysis
4.5. Discussion
4.6. Threats to Validity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sagiroglu, S.; Canbek, G. Keyloggers: Increasing threats to computer security and privacy. IEEE Technol. Soc. Mag. 2009, 28, 10–17. [Google Scholar] [CrossRef]
- Wajahat, A.; Imran, A.; Latif, J.; Nazir, A.; Bilal, A. A Novel Approach of Unprivileged Keylogger Detection. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 30–31 January 2019; pp. 1–6. [Google Scholar]
- Srivastava, M.; Kumari, A.; Dwivedi, K.K.; Jain, S.; Saxena, V. Analysis and Implementation of Novel Keylogger Technique. In Proceedings of the 2021 5th International Conference on Information Systems and Computer Networks (ISCON), Chaumuhan, India, 22–23 October 2021; pp. 1–6. [Google Scholar]
- Rahaman, N.; Rubel, S.; Marouf, A.A. Keylogger Threat to the Android Mobile Banking Applications. In Computer Networks and Inventive Communication Technologies; Springer: Singapore, 2022; pp. 163–174. [Google Scholar]
- Trabelsi, Z.; Saleous, H. Teaching keylogging and network eavesdropping attacks: Student threat and school liability concerns. In Proceedings of the 2018 IEEE Global Engineering Education Conference (EDUCON), Islas Canarias, Spain, 17–20 April 2018; pp. 437–444. [Google Scholar]
- Coombs, E. Human Rights, Privacy Rights, and Technology-Facilitated Violence. In The Emerald International Handbook of Technology-Facilitated Violence and Abuse (Emerald Studies in Digital Crime, Technology and Social Harms); Bailey, J., Flynn, A., Henry, N., Eds.; Emerald Publishing Limited: Bingley, UK, 2021; pp. 475–491. [Google Scholar]
- Awotunde, J.B.; Misra, S. Feature Extraction and Artificial Intelligence-Based Intrusion Detection Model for a Secure Internet of Things Networks. In Illumination of Artificial Intelligence in Cybersecurity and Forensics; Springer: Cham, Switzerland, 2022; pp. 21–44. [Google Scholar]
- Kumar, A.; Dubey, K.K.; Gupta, H.; Memoria, M.; Joshi, K. Keylogger Awareness and Use in Cyber Forensics. In Rising Threats in Expert Applications and Solutions; Springer: Singapore, 2022; pp. 719–725. [Google Scholar]
- Sbai, H.; Goldsmith, M.; Meftali, S.; Happa, J. A survey of keylogger and screenlogger attacks in the banking sector and countermeasures to them. In International Symposium on Cyberspace Safety and Security; Springer: Cham, Switzerland, 2018; pp. 18–32. [Google Scholar]
- Ahmed, Y.A.; Maarof, M.A.; Hassan, F.M.; Abshir, M.M. Survey of Keylogger technologies. Int. J. Comput. Sci. Telecommun. 2014, 5, 25–31. [Google Scholar]
- Datta, P.M. Cybersecurity Threats: Malware in the Code. In Global Technology Management 4.0; Palgrave Macmillan: Cham, Switzerland, 2022; pp. 155–170. [Google Scholar]
- Rawal, B.S.; Manogaran, G.; Peter, A. Hacking for Dummies. In Cybersecurity and Identity Access Management; Springer: Singapore, 2023; pp. 47–62. [Google Scholar]
- An, L.; Yang, G.H. Enhancement of opacity for distributed state estimation in cyber–physical systems. Automatica 2022, 136, 110087. [Google Scholar] [CrossRef]
- Hale, M.T.; Egerstedt, M. Cloud-enabled differentially private multiagent optimization with constraints. IEEE Trans. Control Netw. Syst. 2017, 5, 1693–1706. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E. Forensics and deep learning mechanisms for botnets in internet of things: A survey of challenges and solutions. IEEE Access 2019, 7, 61764–61785. [Google Scholar] [CrossRef]
- Maesschalck, S.; Giotsas, V.; Green, B.; Race, N. Don’t get Stung, cover your ICS in Honey: How do Honeypots fit within Industrial Control System Security. Comput. Secur. 2021, 114, 102598. [Google Scholar] [CrossRef]
- Naït-Abdesselam, F.; Darwaish, A.; Titouna, C. Malware Forensics: Legacy Solutions, Recent Advances, and Future Challenges. In Advances in Computing, Informatics, Networking and Cybersecurity; Springer: Cham, Switzerland, 2022; pp. 685–710. [Google Scholar]
- Pillai, D.; Siddavatam, I. A modified framework to detect keyloggers using machine learning algorithm. Int. J. Inf. Technol. 2019, 11, 707–712. [Google Scholar] [CrossRef]
- Royo, Á.A.; Rubio, M.S.; Fuertes, W.; Cuervo, M.C.; Estrada, C.A.; Toulkeridis, T. Malware Security Evasion Techniques: An Original Keylogger Implementation. In World Conference on Information Systems and Technologies; Springer: Cham, Switzerland, 2021; pp. 375–384. [Google Scholar]
- Ayo, F.E.; Folorunso, S.O.; Abayomi-Alli, A.A.; Adekunle, A.O.; Awotunde, J.B. Network intrusion detection based on deep learning model optimized with rule-based hybrid feature selection. Inf. Secur. J. A Glob. Perspect. 2020, 29, 267–283. [Google Scholar] [CrossRef]
- Meteriz-Yıldıran, Ü.; Yıldıran, N.F.; Awad, A.; Mohaisen, D. A Keylogging Inference Attack on Air-Tapping Keyboards in Virtual Environments. In Proceedings of the 2022 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Christchurch, New Zealand, 12–16 March 2022; pp. 765–774. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Manesh, M.R.; Kaabouch, N. Cyber-attacks on unmanned aerial system networks: Detection, countermeasure, and future research directions. Comput. Secur. 2019, 85, 386–401. [Google Scholar] [CrossRef]
- Solairaj, A.; Prabanand, S.C.; Mathalairaj, J.; Prathap, C.; Vignesh, L.S. Keyloggers software detection techniques. In Proceedings of the 2016 10th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 7–8 January 2016; pp. 1–6. [Google Scholar]
- Folorunso, O.; Ayo, F.E.; Babalola, Y.E. Ca-NIDS: A network intrusion detection system using combinatorial algorithm approach. J. Inf. Priv. Secur. 2016, 12, 181–196. [Google Scholar] [CrossRef]
- Damopoulos, D.; Kambourakis, G.; Gritzalis, S. From keyloggers to touchloggers: Take the rough with the smooth. Comput. Secur. 2013, 32, 102–114. [Google Scholar] [CrossRef]
- Sapra, K.; Husain, B.; Brooks, R.; Smith, M. Circumventing keyloggers and screendumps. In Proceedings of the 2013 8th International Conference on Malicious and Unwanted Software: “The Americas” (MALWARE), Fajardo, PR, USA, 22–24 October 2013; pp. 103–108. [Google Scholar]
- Gunalakshmii, S.; Ezhumalai, P. Mobile keylogger detection using machine learning technique. In Proceedings of the IEEE International Conference on Computer Communication and Systems ICCCS14, Chennai, India, 20–21 February 2014; pp. 51–56. [Google Scholar]
- Case, A.; Maggio, R.D.; Firoz-Ul-Amin, M.; Jalalzai, M.M.; Ali-Gombe, A.; Sun, M.; Richard, G.G., III. Hooktracer: Automatic detection and analysis of keystroke loggers using memory forensics. Comput. Secur. 2020, 96, 101872. [Google Scholar] [CrossRef]
- Aslam, M.; Idrees, R.N.; Baig, M.M.; Arshad, M.A. Anti-hook shield against the software key loggers. In Proceedings of the 2004 National Conference on Emerging Technologies, Cork, Ireland, 26–29 July 2004; pp. 189–191. [Google Scholar]
- Simms, S.; Maxwell, M.; Johnson, S.; Rrushi, J. Keylogger detection using a decoy keyboard. In IFIP Annual Conference on Data and Applications Security and Privacy; Springer: Cham, Switzerland, 2017; pp. 433–452. [Google Scholar]
- Ortolani, S.; Giuffrida, C.; Crispo, B. KLIMAX: Profiling memory write patterns to detect keystroke-harvesting malware. In International Workshop on Recent Advances in Intrusion Detection; Springer: Berlin/Heidelberg, Germany, 2011; pp. 81–100. [Google Scholar]
- Sreenivas, R.S.; Anitha, R. Detecting keyloggers based on traffic analysis with periodic behaviour. Netw. Secur. 2011, 2011, 14–19. [Google Scholar] [CrossRef]
- Fu, J.; Liang, Y.; Tan, C.; Xiong, X. Detecting software keyloggers with dendritic cell algorithm. In Proceedings of the 2010 International Conference on Communications and Mobile Computing, Shenzhen, China, 12–14 April 2010; Volume 1, pp. 111–115. [Google Scholar]
- Le, D.; Yue, C.; Smart, T.; Wang, H. Detecting Kernel Level Keyloggers through Dynamic Taint Analysis; College of William & Mary, Department of Computer Science: Williamsburg, VA, USA, 2008. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Method | Strength | Weakness |
|---|---|---|---|
| Sbai et al. (2018) [9] | Optical Character Recognition (OCR) | −Provides a comparative analysis of OCR systems −Provides countermeasures to keyloggers process | −Not a completely effective solution against keyloggers |
| Gunalakshmii and Ezhumalai (2014) [28] | Support Vector Machine algorithm | −Avoids the over-fitting problem −Provides a mobile-based application | −High expense of learning several support vectors −Detection phase moves slowly |
| Damopoulos et al. (2013) [26] | Machine learning approach | −Direct record of every keystroke on the touch devices −Compares the accuracies of machine learning algorithms −Collection of keyloggers profiles | −No formal method for keyloggers’ detection −Low classification speed −Long learning time |
| Pillai and Siddavatam (2019) [18] | Modified Support Vector Machine algorithm | −Good classification accuracy −Provides I/O hook mechanism | −Framework is not generic to all applications |
| Wajahat et al. (2019) [2] | Unprivileged keylogger detection | −Can detect a user space keylogger −Offers protection to information system | −Limited in the application of intelligent systems to keyloggers |
| Case et al. (2020) [29] | Hook tracer | −Automated keylogger detection −Scalable | −Reverse engineering of the method exhibited malicious behaviors −Low classification accuracy |
| Simms et al. (2017) [31] | Decoy keyboard | −Decent detection precision −Secure to use −Does not obstruct the user’s work | −Limited in the application of intelligent systems to keyloggers |
| Meteriz-Yıldıran et al. (2022) [21] | Keylogging inference attack | −Achieved the best accuracy for inferring the keystrokes from the user’s hand movement | −Focused on building Keylogger rather than keylogger detection |
| Royo et al. (2021) [19] | Malware security evasion techniques | −Successfully gathered confidential information | −Focused on building Keylogger rather than keylogger detection |
| Ortolani et al. (2011) [32] | Behavior-based detection technique | −Allows for no false negatives −Possible to classify and analyze malware on a wide scale | −Not concerned with malware resistance strategies that hide or postpone data leakage |
| Sreenivas and Anitha (2011) [33] | Anomaly-based detection mechanism | −Provides an accurate keyloggers detection using traffic analysis −Generic for other applications | −For erratic time intervals, there is a lack of quantitative analysis |
| Fu et al. (2010) [34] | Dendritic cell algorithm | −High detection rate −Low false alarm rate | −Keylogger behavior is the same as that of programs that hook system message execution −The system would identify all normal programs that attach it as malicious |
| Le et al. (2008) [35] | Dynamic taint analysis technique | −Accurate detection of kernel level keylogging activities −Identifies the root causes of a detected keylogger | −Integration with modern methods is required |
| Aslam et al. (2004) [30] | Anti-hook technique | −Simple to find all suspicious files at an application level | −A lot of computation involved. −A lot of false positives occur |
| Linguistic Value | Value Range |
|---|---|
| 1. Low | 0.1 ≤ x < 0.3 |
| 2. Medium | 0.3 ≤ x < 0.6 |
| 3. High | 0.6 ≤ x < 0.8 |
| 4. Very high | 0.8 ≤ x ≤ 1.0 |
| Linguistic Value | ||||
|---|---|---|---|---|
| Low | 0, if = 0.1 | , if [0.1, 0.3] | , if [0.2, 0.3] | 0, if ≥ 0.3 |
| Medium | 0, if = 0.3 | , if [0.3, 0.6] | , if [0.45,0.6] | 0, if ≥ 0.6 |
| High | 0, if = 0.6 | , if [0.6, 0.8] | , if [0.7, 0.8] | 0, if ≥ 0.8 |
| Very high | 0, if = 0.8 | , if [0.8, 1.0] | , if [0.9, 1.0] | 0, if ≥ 1.0 |
| #No | Time | Icons | Space | Activity | Keylogger Classification (Conclusion) | Non Zero Min No. |
|---|---|---|---|---|---|---|
| 1 | 0.25 | 0.25 | 0.25 | 0.25 | Low | 0.25 |
| 2 | 0.25 | 0.5 | 0.5 | 0.5 | Medium | 0.25 |
| 3 | 0.25 | 0.75 | 0.75 | 0.75 | High | 0.25 |
| 4 | 0.25 | 0.9 | 0.9 | 0.9 | High | 0.25 |
| 5 | 0.5 | 0.25 | 0.25 | 0.25 | Low | 0.25 |
| 6 | 0.5 | 0.5 | 0.5 | 0.5 | Medium | 0.5 |
| 7 | 0.5 | 0.75 | 0.75 | 0.75 | High | 0.5 |
| 8 | 0.5 | 0.9 | 0.9 | 0.9 | Very high | 0.5 |
| 9 | 0.75 | 0.25 | 0.25 | 0.25 | Low | 0.25 |
| 10 | 0.75 | 0.5 | 0.5 | 0.5 | Medium | 0.5 |
| 11 | 0.75 | 0.75 | 0.75 | 0.75 | High | 0.75 |
| 12 | 0.75 | 0.9 | 0.9 | 0.9 | Very high | 0.75 |
| 13 | 0.9 | 0.25 | 0.25 | 0.25 | Low | 0.25 |
| 14 | 0.9 | 0.5 | 0.5 | 0.5 | Medium | 0.5 |
| 15 | 0.9 | 0.75 | 0.75 | 0.75 | High | 0.75 |
| 16 | 0.9 | 0.9 | 0.9 | 0.9 | Very high | 0.9 |
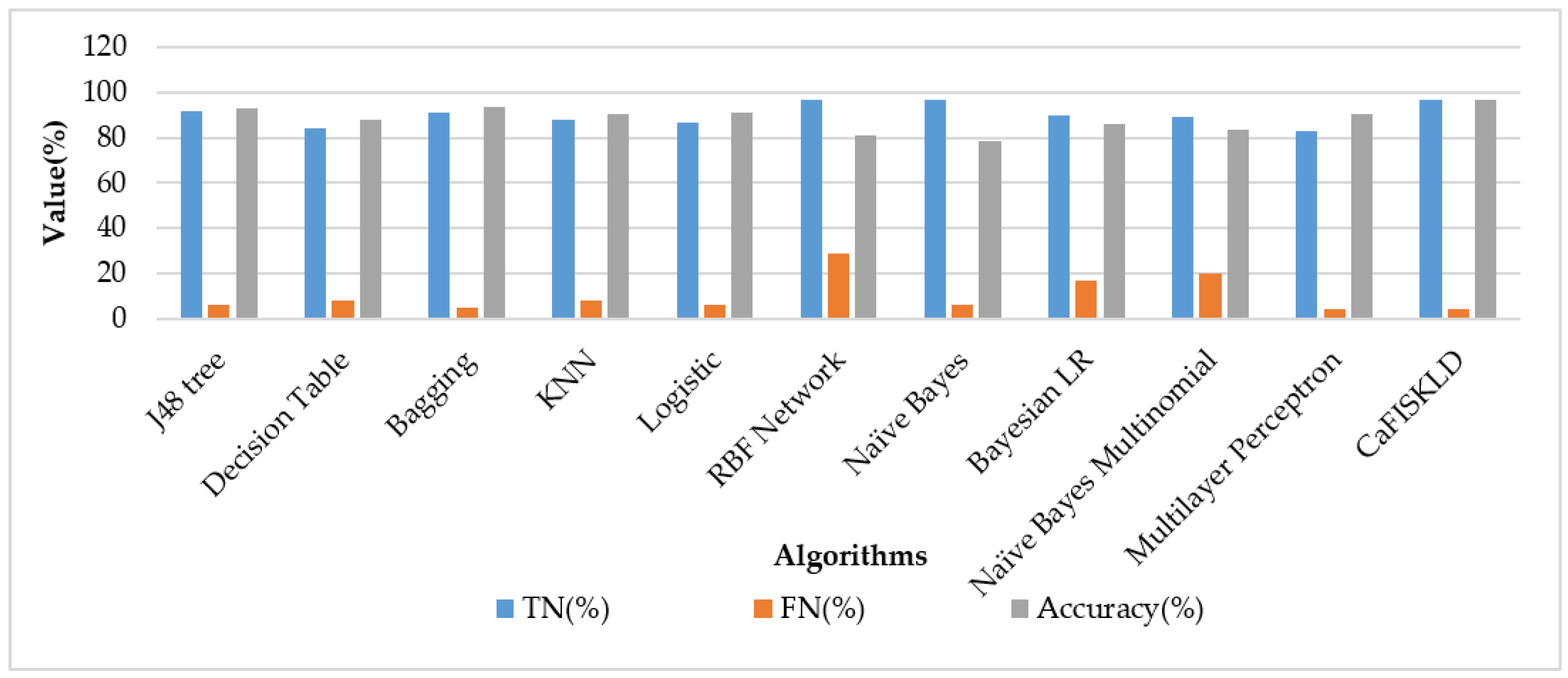
| Algorithm | TP (%) | FP (%) | TN (%) | FN (%) | F1 score | Accuracy (%) | Time (s) |
|---|---|---|---|---|---|---|---|
| J48 tree | 91.7 | 5.9 | 92 | 6 | 91.3 | 93.132 | 11.48 |
| Decision table | 83.7 | 9 | 84 | 8 | 84.7 | 88.090 | 14.05 |
| Bagging | 90.7 | 4.7 | 91 | 5 | 91.6 | 93.480 | 12.52 |
| KNN | 87.3 | 7.5 | 88 | 8 | 87.8 | 90.480 | 6.56 |
| Logistic regression | 86.2 | 5.5 | 87 | 6 | 88.6 | 91.241 | 11.74 |
| RBF network | 95.2 | 28.8 | 97 | 29 | 80.1 | 81.048 | 12.44 |
| Naive Bayes | 96.5 | 5.2 | 97 | 6 | 89.3 | 78.353 | 10.15 |
| Bayesian Logistic Regression (Bayesian LR) | 89.9 | 16.5 | 90 | 17 | 83.5 | 85.981 | 10.9 |
| Naive Bayes Multinomial | 88.6 | 19.7 | 89 | 20 | 80.9 | 83.569 | 10.13 |
| Multilayer Perceptron | 82.2 | 3.7 | 83 | 4 | 87.5 | 90.741 | 62.73 |
| CaFISKLD | 96 | 3 | 97 | 4 | 95.5 | 96.543 | 6.22 |
| No | Time | Icons | Space | Activity | Fuzzy Value |
|---|---|---|---|---|---|
| 1 | 0.72 | 0.777 | 0.735 | 0.5 | High |
| 2 | 0.129 | 0.177 | 0.417 | 0.854 | Medium |
| 3 | 0.932 | 0.962 | 0.932 | 0.915 | Very high |
| 4 | 0.932 | 0.192 | 0.189 | 0.485 | Low |
| 5 | 0.265 | 0.254 | 0.705 | 0.3 | Medium |
| 6 | 0.0833 | 0.715 | 0.0682 | 0.0846 | Medium |
| 7 | 0.962 | 0.946 | 0.886 | 0.1 | Medium |
| 8 | 0.962 | 0.946 | 0.886 | 0.823 | High |
| 9 | 0.644 | 0.638 | 0.689 | 0.669 | High |
| 10 | 0.0985 | 0.0692 | 0.0985 | 0.192 | Low |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ayo, F.E.; Awotunde, J.B.; Olalekan, O.A.; Imoize, A.L.; Li, C.-T.; Lee, C.-C. CBFISKD: A Combinatorial-Based Fuzzy Inference System for Keylogger Detection. Mathematics 2023, 11, 1899. https://doi.org/10.3390/math11081899
Ayo FE, Awotunde JB, Olalekan OA, Imoize AL, Li C-T, Lee C-C. CBFISKD: A Combinatorial-Based Fuzzy Inference System for Keylogger Detection. Mathematics. 2023; 11(8):1899. https://doi.org/10.3390/math11081899
Chicago/Turabian StyleAyo, Femi Emmanuel, Joseph Bamidele Awotunde, Olasupo Ahmed Olalekan, Agbotiname Lucky Imoize, Chun-Ta Li, and Cheng-Chi Lee. 2023. "CBFISKD: A Combinatorial-Based Fuzzy Inference System for Keylogger Detection" Mathematics 11, no. 8: 1899. https://doi.org/10.3390/math11081899
APA StyleAyo, F. E., Awotunde, J. B., Olalekan, O. A., Imoize, A. L., Li, C.-T., & Lee, C.-C. (2023). CBFISKD: A Combinatorial-Based Fuzzy Inference System for Keylogger Detection. Mathematics, 11(8), 1899. https://doi.org/10.3390/math11081899