

POFCM: A Parallel Fuzzy Clustering Algorithm for Large Datasets

 , , and
, , and
Abstract
:1. Introduction
- 1.
- A parallel version of an optimised variant of the FCM clustering algorithm.
- 2.
- The detailed implementation of the FCM algorithm with the OpenMP parallelisation technique.
- 3.
- The parallel version is discussed and evaluated, in particular, regarding the speedup and parallel efficiency metrics.
- 4.
- Our solution approach is scalable to platforms with higher hardware capabilities and is not limited to solving domain-specific datasets.
2. Related Work
- (a)
- There are few implementations in the OpenMP platform, and these correspond to recently published research. One of the most used platforms is GPU.
- (b)
- The FCM algorithm is sensitive to the values of the initial parameters; it is known that appropriate values can reduce the number of iterations of the algorithm. In this sense, our work proposes a hybrid improvement in the initialisation phase. As shown in column three, other authors also propose improvements in the initialisation phase.
- (c)
- As shown in Table 1, the hybrid improvement approach has been used in various works.
- (d)
- Regarding hardware, it was observed that Intel 5 and 7 processors, which are normally used in desktop computers and laptops, are predominant. Regarding the use of RAM memory, it is shown that RAM ranges between 2 and 16 GB. In addition, most hard drives range in capacity from 512 GB to 2 TB.
- (e)
- An important aspect of the experimentation is the characteristics of the datasets. The datasets are in the size range from 1024 to 400,000 objects. In the case of the distributed architectures, some datasets are 30,000,000,000 objects in size. In some research, the dataset size is expressed in different units, such as pixels or GB.
- (f)
- Three investigations that experimented with real and synthetic datasets, including ours, were identified. Most of the works only carried out experimentation using real datasets.
- (g)
- In our research, like four other studies, the increase in efficiency is calculated based on the performance of the parallelised algorithm in its sequential version, as shown in column 12. In most investigations, the comparison is made with the sequential version of FCM, as indicated in column 10. Six published studies are compared with variants proposed by other authors, as seen in column 11.
3. Clustering Algorithms
3.1. K++ Algorithm
| Algorithm 1: K++ | |
| 1 | Initialisation: |
| 2 | X: = {x1, …, xn}; |
| 3 | Assign the value for k; |
| 4 | V: = Ø;//The set of centroids is initialised |
| 5 | V: = V U {v1};//Select the first centroid v1 randomly |
| 6 | For i = 2 to k: |
| 7 | Select the i-th centroid vi ϵ X with probability D(xi, vj)/∑xϵX D(xi, vj); |
| 8 | V: = V U {vi}; |
| 9 | Endfor |
| 10 | Return V; |
| 11 | End of algorithm |
3.2. O-K-Means Algorithm
| Algorithm 2: O-K-Means | |
| 1 | Initialisation: |
| 2 | X: = {x1, …, xn}; |
| 3 | V: = {v1, …, vk}; |
| 4 | εok: = Threshold value for determining O-K-Means convergence; |
| 5 | Classification: |
| 6 | For xi ϵ X and vk ϵ V{ |
| 7 | Calculate the Euclidean distance from each xi to the k centroids; |
| 8 | Assign the xi object to the nearest vk centroid; |
| 9 | Compute }; |
| 10 | Calculate centroids: |
| 11 | Calculate the centroid vk; |
| 12 | Convergence: |
| 13 | If (≤ εok): |
| 14 | Stop the algorithm; |
| 15 | Otherwise: |
| 16 | Go to Classification |
| 17 | End of algorithm |
3.3. FCM Algorithm
| Algorithm 3: Standard FCM | |
| Input: dataset X, c, m, ε | |
| Output: V, U | |
| 1 | Initialisation: |
| 2 | t: = 0; |
| 3 | U(t): = {µ11, …, µij}; is randomly generated |
| 4 | Calculate centroids: |
| 5 | Calculate the centroids using Equation (2); |
| 6 | Classification: |
| 7 | Update and calculate the membership matrix using Equation (3); |
| 8 | Convergence: |
| 9 | If max [abs(µij(t) − µij(t+1))] < ε: |
| 10 | Stop the algorithm; |
| 11 | Otherwise: |
| 12 | U(t): = U(t+1) and t: = t + 1; |
| 13 | Go to Calculate centroids |
| 14 | End of algorithm |
3.4. HOFCM Algorithm
| Algorithm 4: HOFCM | |
| Input: dataset X, c, m, ε, εok | |
| Output: V, U | |
| 1 | Initialisation: |
| 2 | i: = 1; |
| 3 | Repeat |
| 4 | Function K++ (X, c): |
| 5 | Return V′; |
| 6 | Function O-K-Means (X, V′, εok, c): |
| 7 | Return V″; |
| 8 | i = i + 1; |
| 9 | While i <= 10; |
| 10 | Select V″ for the value of i at which the objective function obtained the minimum value; |
| 11 | Transformation function s; |
| 12 | r: = 1; |
| 13 | Calculate centroids: |
| 14 | Calculate the centroids using Equation (2); |
| 15 | Classification: |
| 16 | Update and calculate the membership matrix using Equation (3); |
| 17 | Convergence: |
| 18 | If max [abs(µij(r) − µij(r+1))] < ε: |
| 19 | Stop the algorithm; |
| 20 | Otherwise: |
| 21 | U(r): = U(r+1) and r: = r + 1; |
| 22 | Go to Calculate centroids |
| 23 | End of algorithm |
4. Proposal for Improvement
4.1. OpenMP Parallelisation Technique
| Program 1: Sample #pragma | |
| 1 | void average(double * a, double * b) { |
| 2 | a[0] = 10; a[1] = 20; a[2] = 30; a[3] = 40; a[4] = 50; a[5] = 60; a[6] = 70; a[7] = 80; a[8] = 90; |
| 3 | #pragma omp parallel for |
| 4 | for(int i = 1; i < 9; i++) { |
| 5 | b[i] = (a[i] + a[i − 1])/2; } |
| 6 | } |
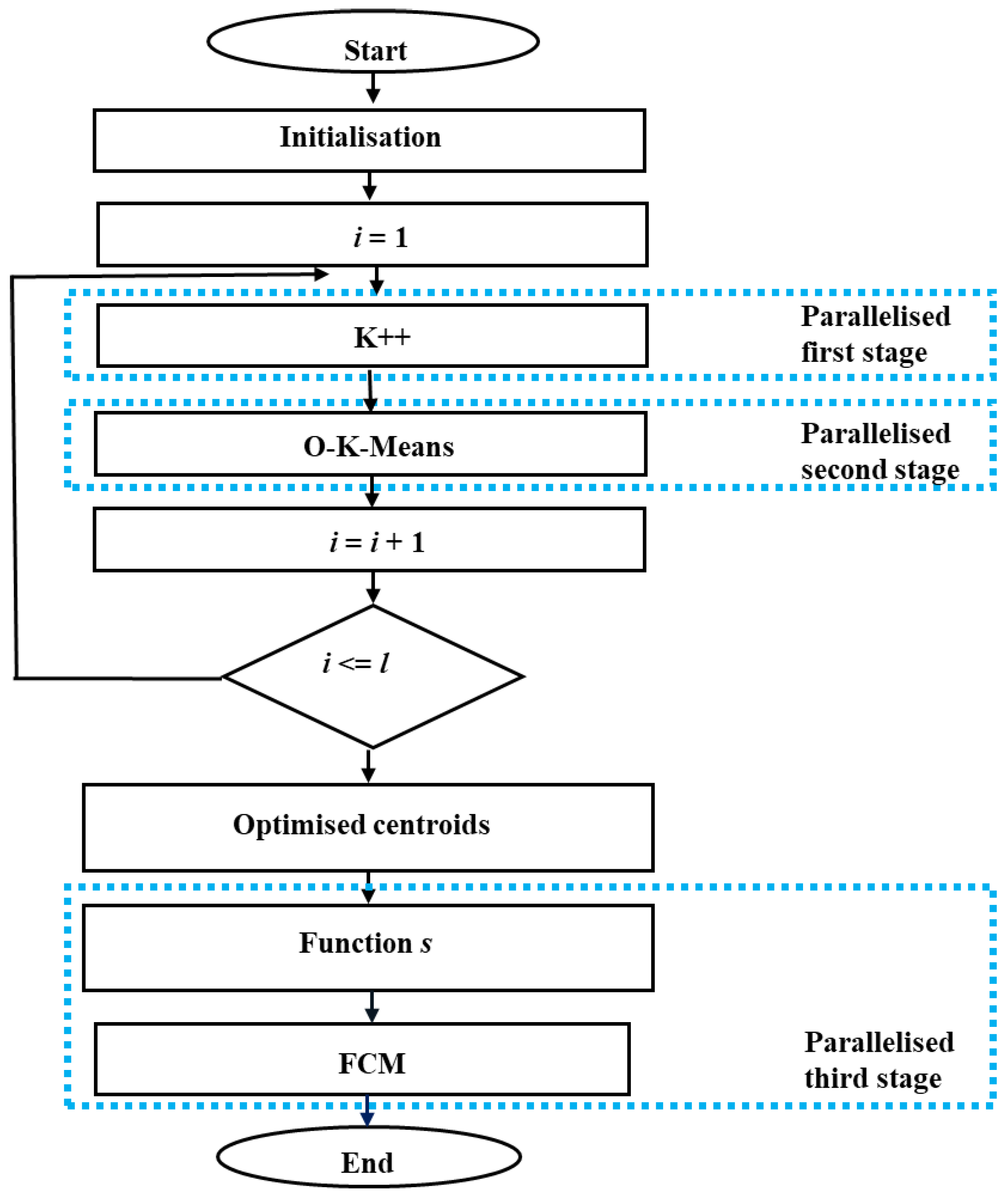
4.2. Proposed POFCM Algorithm
| Algorithm 5: POFCM | |
| Input: dataset X, c, m, ε, εok, T, r, i, stop; | |
| Output: V, U; | |
| 1 | Initialisation: |
| 2 | i: = 1; |
| 3 | Repeat |
| 4 | Function K++ (X, c, T): //This function was parallelised. |
| 5 | Return V’; |
| 6 | Function O-K-Means (X, V’, εok, c, T): //This function was parallelised. |
| 7 | Return V’’; |
| 8 | i = i + 1; |
| 9 | While i <= l; |
| 10 | Select V’’ for the value of i at which the objective function obtained the minimum value; |
| 11 | Function s (X, V’’, m, T); //This function was parallelised. |
| 12 | Return U; |
| 13 | r: = 1; |
| 14 | Calculate centroids: |
| 15 | Function Centroids (X, U, m, T); //This function was parallelised. |
| 16 | //Calculate the centroids using Equation (2); |
| 17 | Return V; |
| 18 | Classification: |
| 19 | Function Classification (X, V, m, T); //This function was parallelised. |
| 20 | //Update and calculate the membership matrix using Equation (3); |
| 21 | Return U; |
| 22 | Convergence: |
| 23 | Function Convergence (X, U, ε, T, r, stop); //This function was parallelised. |
| 24 | If max [abs(µij(r) − µij(r+1))] < ε then: |
| 25 | stop: = 0;//The stop flag of the algorithm is activated. |
| 26 | Return U, stop; |
| 27 | Otherwise: |
| 28 | U(r): = U(r+1) and r: = r + 1; |
| 29 | stop: = 1; |
| 30 | Return U, stop; |
| 31 | If stop = 1 then go to Calculate centroids |
| 32 | End of algorithm |
5. Evaluation
5.1. Experimental Setup
5.2. Description of the Datasets
5.3. Test Cases
5.3.1. Description of Experiment I
5.3.2. Description of Experiment II
5.4. Metrics
6. Results
6.1. Analysis of Results
6.1.1. Analysis of the Results of Experiment I
- For the three datasets, speedup and parallel efficiency tended to improve as the number of clusters increased.
- It was found relevant that for a value of c greater than or equal to 10, the values of speedup and parallel efficiency tended to their upper-limit values.
- In the best case, POFCM reduced the execution time by 73.4% of the time required by the HOFCM algorithm to solve the URBAN dataset with 26 clusters.
- It is worth noting that the quality with POFCM was the same as with HOFCM.
6.1.2. Analysis of the Results of Experiment II
- When solving the 16 synthetic datasets, it was found that with POFCM, in addition to increasing the speedup when the number of clusters increases, the speedup also increased when the dimension of the datasets grew.
- When running the synthetic dataset S10_10, considered the smallest, the speedup achieved a value of 3.5 for 32 clusters.
- In the best cases, the solution time was reduced by up to 74.7% for the S40_40 dataset of 10,000 objects and 40 dimensions. With this same dataset, a speedup of 3.96 was achieved. It is important to note that this speedup value is higher than other reported values.
6.1.3. Comparative Analysis with Other Works
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Statista Research Departmen. Volume of Data/Information Created, Captured, Copied, and Consumed Worldwide from 2010 to 2020, with Forecasts from 2021 to 2025. Available online: https://www.statista.com/statistics/871513/worldwide-data-created/ (accessed on 13 November 2022).
- Shirkhorshidi, A.S.; Aghabozorgi, S.; Wah, T.Y.; Herawan, T. Big Data Clustering: A Review. In Proceedings of the Computa-tional Science and Its Applications—ICCSA 2014, Guimaraes, Portugal, 30 June–3 July 2014. [Google Scholar]
- Ajin, V.W.; Kumar, L.D. Big data and clustering algorithms. In Proceedings of the 2016 International Conference on Research Advances in Integrated Navigation Systems (RAINS), Bangalore, India, 6–7 April 2016. [Google Scholar]
- Bezdek, J. Elementary Cluster Analysis: Four Basic Methods that (Usually) Work; River Publishers: New York, NY, USA, 2022; pp. 1–10. [Google Scholar]
- Nayak, J.; Naik, B.; Behera, H.S. Fuzzy C-Means (FCM) Clustering Algorithm: A Decade Review from 2000 to 2014. In Proceedings of the Computational Intelligence in Data Mining, Odisha, India, 20–21 December 2014. [Google Scholar]
- Mahdi, M.A.; Hosny, K.M.; Elhenawy, I. Scalable Clustering Algorithms for Big Data: A Review. IEEE Access 2021, 9, 80015–80027. [Google Scholar] [CrossRef]
- Bonilla, J.; Vélez, D.; Montero, J.; Rodríguez, J.T. Fuzzy Clustering Methods with Rényi Relative Entropy and Cluster Size. Mathematics 2021, 9, 1423. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965. [Google Scholar]
- Lee, G.M.; Gao, X. A Hybrid Approach Combining Fuzzy c-Means-Based Genetic Algorithm and Machine Learning for Predicting Job Cycle Times for Semiconductor Manufacturing. Appl. Sci. 2021, 11, 7428. [Google Scholar] [CrossRef]
- Lee, S.J.; Song, D.H.; Kim, K.B.; Park, H.J. Efficient Fuzzy Image Stretching for Automatic Ganglion Cyst Extraction Using Fuzzy C-Means Quantization. Appl. Sci. 2021, 11, 12094. [Google Scholar] [CrossRef]
- Dunn, J.C. A Fuzzy Relative of the ISODATA Process and Its Use in Detecting Compact Well-Separated Clusters. J. Cybern. 1974, 3, 32–57. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Plenum Press: New York, NY, USA, 1981; pp. 43–93. [Google Scholar]
- Ghosh, S.; Kumar, S. Comparative Analysis of K-Means and Fuzzy C-Means Algorithms. Int. J. Adv. Comput. Sci. Appl. 2013, 4, 35–39. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness; W. H. Freeman & Co.: New York, NY, USA, 1979; pp. 109–120. [Google Scholar]
- Barrah, H.; Cherkaoui, A. Fast Robust Fuzzy Clustering Algorithm for Grayscale Image Segmentation. In Proceedings of the Xth International Conference on Integrated Design and Production, Tangier, Morocco, 2–4 December 2015. [Google Scholar]
- Hashemzadeh, M.; Golzari Oskouei, A.; Farajzadeh, N. New fuzzy C-means clustering method based on feature-weight and cluster-weight learning. Appl. Soft Comput. 2019, 78, 324–345. [Google Scholar] [CrossRef]
- Stetco, A.; Zeng, X.J.; Keane, J. Fuzzy C-means++: Fuzzy C-means with effective seeding initialization. Expert Syst. Appl. 2015, 42, 7541–7548. [Google Scholar] [CrossRef]
- Wu, Z.; Chen, G.; Yao, J. The Stock Classification Based on Entropy Weight Method and Improved Fuzzy C-means Algorithm. In Proceedings of the 4th International Conference on Big Data and Computing, Guangzhou, China, 10–12 May 2019. [Google Scholar]
- Liu, Q.; Liu, J.; Li, M.; Zhou, Y. Approximation algorithms for fuzzy C-means problem based on seeding method. Theor. Comput. Sci. 2021, 885, 146–158. [Google Scholar] [CrossRef]
- Pérez, J.; Roblero, S.S.; Almanza, N.N.; Solís, J.F.; Zavala, C.; Hernández, Y.; Landero, V. Hybrid Fuzzy C-Means Clustering Algorithm Oriented to Big Data Realms. Axioms 2022, 11, 377. [Google Scholar] [CrossRef]
- Manacero, A.; Guariglia, E.; de Souza, T.A.; Lobato, R.S.; Spolon, R. Parallel fuzzy minimals on GPU. Appl. Sci. 2022, 12, 2385. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, Z.; Leng, Y. Distributed fuzzy c-means algorithms for big sensor data based on cloud computing. Int. J. Sens. Netw. 2015, 18, 32. [Google Scholar] [CrossRef]
- Qin, J.; Fu, W.; Gao, H.; Zheng, W.X. Distributed k-Means Algorithm and Fuzzy c-Means Algorithm for Sensor Networks Based on Multiagent Consensus Theory. IEEE Trans. Cybern. 2016, 47, 772–783. [Google Scholar] [CrossRef] [PubMed]
- Al-Ayyoub, M.; Abu-Dalo, A.M.; Jararweh, Y.; Jarrah, M.; Sa’d, M.A. A GPU-based implementations of the fuzzy C-means algorithms for medical image segmentation. J. Supercomput. 2015, 71, 3149–3162. [Google Scholar] [CrossRef]
- Ali, N.A.; Cherradi, B.; Abbassi, A.E.; Bouattane, O.; Youssfi, M. New parallel hybrid implementation of bias correction fuzzy C-means algorithm. In Proceedings of the 2017 International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Fez, Morocco, 22–24 May 2017. [Google Scholar]
- Al-Ayyoub, M.; Al-andoli, M.; Jararweh, Y.; Smadi, M.; Gupta, B. Improving fuzzy C-mean-based community detection in social networks using dynamic parallelism. Comput. Electr. Eng. 2018, 74, 533–546. [Google Scholar] [CrossRef]
- AlZu’bi, S.; Shehab, M.; Al-Ayyoub, M.; Jararweh, Y.; Gupta, B. Parallel implementation for 3D medical volume fuzzy segmentation. Pattern Recognit. Lett. 2020, 130, 312–318. [Google Scholar] [CrossRef]
- Cecilia, J.M.; Cano, J.-C.; Morales-García, J.; Llanes, A.; Imbernón, B. Evaluation of Clustering Algorithms on GPU-Based Edge Computing Platforms. Sensors 2020, 20, 6335. [Google Scholar] [CrossRef]
- Cebrian, J.M.; Imbernón, B.; Soto, J.; Cecilia, J.M. Evaluation of Clustering Algorithms on HPC Platforms. Mathematics 2021, 9, 2156. [Google Scholar] [CrossRef]
- Ali, N.A.; Abbassi, A.E.; Cherradi, B. The performances of iterative type-2 fuzzy C-mean on GPU for image segmentation. J. Supercomput. 2022, 78, 1583–1601. [Google Scholar] [CrossRef]
- Liu, B.; He, S.; He, D.; Zhang, Y.; Guizani, M. A Spark-based Parallel Fuzzy C-means Segmentation Algorithm for Agricultural Image Big Data. IEEE Access 2019, 7, 42169–42180. [Google Scholar] [CrossRef]
- Ma, Y.; Cheng, W. Optimization and Parallelization of Fuzzy Clustering Algorithm Based on the Improved Kmeans++ Clustering. IOP Conf. Ser. Mater. Sci. Eng. 2020, 768, 072106. [Google Scholar] [CrossRef]
- Yu, Q.; Ding, Z. An improved Fuzzy C-Means algorithm based on MapReduce. In Proceedings of the 2015 8th International Conference on Biomedical Engineering and Informatics (BMEI), Shenyang, China, 14–16 October 2015. [Google Scholar]
- Dai, W.; Yu, C.; Jiang, Z. An Improved Hybrid Canopy-Fuzzy C-Means Clustering Algorithm Based on MapReduce Model. J. Comput. Sci. Eng. 2016, 10, 1–8. [Google Scholar] [CrossRef]
- Sardar, T.H.; Ansari, Z. MapReduce-based Fuzzy C-means Algorithm for Distributed Document Clustering. J. Inst. Eng. India Ser. B 2022, 103, 131–142. [Google Scholar] [CrossRef]
- Almomany, A.; Jarrah, A.; Al Assaf, A.H. FCM Clustering Approach Optimization Using Parallel High-Speed Intel FPGA Technology. J. Electr. Comput. Eng. 2022, 2022, 8260283. [Google Scholar] [CrossRef]
- Sakarya, O. Applying fuzzy clustering method to color image segmentation. In Proceedings of the 2015 Federated Conference on Computer Science and Information Systems, Lodz, Poland, 13–16 September 2015. [Google Scholar]
- Vela-Rincón, V.V.; Mújica-Vargas, D.; de Jesus Rubio, J. Parallel hesitant fuzzy C-means algorithm to image segmentation. Signal Image Video Process. 2022, 16, 73–81. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. k-means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007. [Google Scholar]
- Pérez, J.; Almanza, N.N.; Romero, D. Balancing effort and benefit of K-means clustering algorithms in Big Data realms. PLoS ONE 2018, 13, e0201874. [Google Scholar] [CrossRef]
- Ruspini, E.H. A new approach to clustering. Inf. Control 1969, 15, 22–32. [Google Scholar] [CrossRef]
- Chandra, R.; Dagum, L.; Kohr, D.; Menon, R.; Maydan, D.; McDonald, J. Parallel Programming in OpenMP; Academic Press: San Diego, CA, USA, 2001; pp. 2–9. [Google Scholar]
- Schmidt, B.; Gonzalez-Dominguez, J.; Hundt, C.; Schlarb, M. Parallel Programming: Concepts and Practice; Elsevier Science: Cambridge, MA, USA, 2017; pp. 165–179. [Google Scholar]
- OpenMP. Application Programming Interface. Available online: https://www.openmp.org/wp-content/uploads/openmp-examples-4.5.0.pdf (accessed on 20 January 2023).
- UCI Machine Learning Repository, University of California. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 26 November 2022).
- Zavala-Díaz, J.C.; Cruz-Chávez, M.A.; López-Calderón, J.; Hernández-Aguilar, J.A.; Luna-Ortíz, M.E. A Multi-Branch-and-Bound Binary Parallel Algorithm to Solve the Knapsack Problem 0–1 in a Multicore Cluster. Appl. Sci. 2019, 9, 5368. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Algorithm | P | D | Platforms | I | H | Equipment Features | Largest Dataset (Objects × Attributes) | Type | Sec. FCM | Others | Variant Sec. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| DFCM DOFCM DKFCM [22] | ✓ | Cloud base Map Reduce | ✓ | ✓ | 20 machines, Intel® Core™ i7 3.2 GHz, 8 GB RAM, 2 TB Hard drive | (30,000,000,000 × 150) | 2 R | ✓ | ✓ | ||
| DFCM [23] | ✓ | Cloud base | ----- | (1024 × 10) | 1 R | ✓ | ✓ | ||||
| PFMGPU [21] | ✓ | GPU-MPI | Intel® Core™ i7 3.4 GHz, 16 GB RAM, GPU NVidia GeForce GTS 450 with 4 SMs | (40,646 × 2) | 2 R 1 S | ✓ | ✓ | ||||
| brFCM [24] | ✓ | GPU | ✓ | Intel® Core™ i5 Compiler GCC 4.7, Ubuntu OS, Tesla M2070 y Tesla K20m | 262,144 pixels | 2 R | ✓ | ||||
| PBCFCM1 PBCFCM2 [25] | ✓ | GPU | ✓ | Intel® Core™ i5-3230M, 2.6 GHz, NVidia GeForce GT 740m, 2 GB GPU | 7,929,856 pixels | 4 R | ✓ | ||||
| DP/HCG/ HNP [26] | ✓ | GPU | ✓ | Intel® Core™ i7, 8 GB RAM, NVidia GeForce GT 840M, Windows 8 | ----- | 2 R | ✓ | ✓ | |||
| PFCM [27] | ✓ | GPU | Intel® Core™ i7 32 GB RAM, NVidia GTX 970 6 GB | ----- | 1 R | ✓ | |||||
| K-Means FM/FCM [28] | ✓ | GPU | Intel Xeon® Silver 4216, 3.20 GHz, Nvidia RTX 2080 Ti | (100,000 × 80) | 1 S | ✓ | ✓ | ||||
| FM FCM GK-FCM [29] | ✓ | GPU | Intel® Skylake-X™ i7-37820X, 3.60 GHz. Nvidia A100, 2.4 GHz Nvidia V100, 2.7 GHz | (800,000 × 104) | 1 S | ✓ | ✓ | ||||
| PIT2FCM_1 [30] | ✓ | GPU | ✓ | Intel® Core™ i5-3230M, 2 cores, 2.6 GHz, Nvidia GeForce GT 740 m 2 GB | 1,331,200 pixels | 9 R | ✓ | ||||
| PFCM [31] | ✓ | Spark | Intel® Xeon™ E7-4820 2.00 GHz, 8 GB RAM, 600 GB Hard Disk | 2.5 GB | 6 R | ||||||
| FCM-Ck [32] | ✓ | Spark | ✓ | ✓ | Intel® Core™ i5-8400, 16 GB RAM, 2 TB Hard Disk, Windows 7 | (400,000 × 42) | 3 R | ✓ | ✓ | ||
| ICFCM [33] | ✓ | Map Reduce | ✓ | ✓ | CPU 2.40 GHz, 2 GB RAM, Ubuntu 14.10 | ----- | ✓ | ✓ | |||
| HCFCM [34] | ✓ | Map Reduce | ✓ | ✓ | CPU 2.2 GHz, 4 GB RAM, 500 GB Hard Disk, Ubuntu 12.10 | (1728 × 4) | 2 R | ✓ | |||
| FCM [35] | ✓ | Map Reduce | ✓ | AMD, 8 GB RAM, 500 GB Hard Disk, Ubuntu 18.04 OS | 1 GB | 6 S | ✓ | ||||
| FPGA [36] | ✓ | OpenCL | Intel® Core™ i7-6700 3.4 GHz, 16 GB RAM | (100,000 × 2) | 1 R 3 S | ✓ | |||||
| FCM [37] | ✓ | OpenMP | Intel Core 2 | 241,200 pixels | 1 R | ✓ | |||||
| PHFCM [38] | ✓ | OpenMP | Intel® Core™ i7-4510U con 4 cores, 2.00 GHz, 8 GB RAM | 2,073,600 pixels | 4 R | ✓ | |||||
| POFCM | ✓ | OpenMP | ✓ | Intel® Core™ i5-4570, 4 cores, 3.30 GHz, 14 GB RAM, and 512 GB HDD, Windows 10, Compiler MSVC 2020 | (40,000 × 40) | 3 R 16 S | ✓ |
| ID | Name | Type | n | d | Size Indicator n × d |
|---|---|---|---|---|---|
| 1 | ABALONE | Real | 4177 | 7 | 29,239 |
| 2 | SPAM | Real | 4601 | 57 | 262,257 |
| 3 | URBAN | Real | 360,177 | 2 | 720,354 |
| 4 | S10_10 | Synthetic | 10,000 | 10 | 100,000 |
| 5 | S10_20 | Synthetic | 10,000 | 20 | 200,000 |
| 6 | S10_30 | Synthetic | 10,000 | 30 | 300,000 |
| 7 | S10_40 | Synthetic | 10,000 | 40 | 400,000 |
| 8 | S20_10 | Synthetic | 20,000 | 10 | 200,000 |
| 9 | S20_20 | Synthetic | 20,000 | 20 | 400,000 |
| 10 | S20_30 | Synthetic | 20,000 | 30 | 600,000 |
| 11 | S20_40 | Synthetic | 20,000 | 40 | 800,000 |
| 12 | S30_10 | Synthetic | 30,000 | 10 | 300,000 |
| 13 | S30_20 | Synthetic | 30,000 | 20 | 600,000 |
| 14 | S30_30 | Synthetic | 30,000 | 30 | 900,000 |
| 15 | S30_40 | Synthetic | 30,000 | 40 | 1,200,000 |
| 16 | S40_10 | Synthetic | 40,000 | 10 | 400,000 |
| 17 | S40_20 | Synthetic | 40,000 | 20 | 800,000 |
| 18 | S40_30 | Synthetic | 40,000 | 30 | 1,200,000 |
| 19 | S40_40 | Synthetic | 40,000 | 40 | 1,600,000 |
| ABALONE | SPAM | URBAN | ||||
|---|---|---|---|---|---|---|
| Cluster | Speedup Sp | Parallel Efficiency Pe | Speedup Sp | Parallel Efficiency Pe | Speedup Sp | Parallel Efficiency Pe |
| 2 | 1.88 | 0.47 | 1.78 | 0.45 | 1.87 | 0.47 |
| 4 | 2.10 | 0.53 | 2.31 | 0.58 | 2.48 | 0.62 |
| 6 | 2.61 | 0.65 | 2.58 | 0.64 | 2.79 | 0.70 |
| 8 | 2.82 | 0.70 | 3.24 | 0.81 | 3.35 | 0.84 |
| 10 | 3.13 | 0.78 | 3.14 | 0.79 | 3.12 | 0.78 |
| 14 | 3.39 | 0.85 | 3.50 | 0.88 | 3.45 | 0.86 |
| 18 | 3.49 | 0.87 | 3.60 | 0.90 | 3.55 | 0.89 |
| 26 | 3.60 | 0.90 | 3.64 | 0.91 | 3.76 | 0.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez-Ortega, J.; Rey-Figueroa, C.D.; Roblero-Aguilar, S.S.; Almanza-Ortega, N.N.; Zavala-Díaz, C.; García-Paredes, S.; Landero-Nájera, V. POFCM: A Parallel Fuzzy Clustering Algorithm for Large Datasets. Mathematics 2023, 11, 1920. https://doi.org/10.3390/math11081920
Pérez-Ortega J, Rey-Figueroa CD, Roblero-Aguilar SS, Almanza-Ortega NN, Zavala-Díaz C, García-Paredes S, Landero-Nájera V. POFCM: A Parallel Fuzzy Clustering Algorithm for Large Datasets. Mathematics. 2023; 11(8):1920. https://doi.org/10.3390/math11081920
Chicago/Turabian StylePérez-Ortega, Joaquín, César David Rey-Figueroa, Sandra Silvia Roblero-Aguilar, Nelva Nely Almanza-Ortega, Crispín Zavala-Díaz, Salomón García-Paredes, and Vanesa Landero-Nájera. 2023. "POFCM: A Parallel Fuzzy Clustering Algorithm for Large Datasets" Mathematics 11, no. 8: 1920. https://doi.org/10.3390/math11081920