Deep Learning (DL), machine learning (ML), and other forms of Artificial Intelligence (AI) are on the rise in terms of solving numerous varieties of modern business problems and research, and they are used in engineering applications [
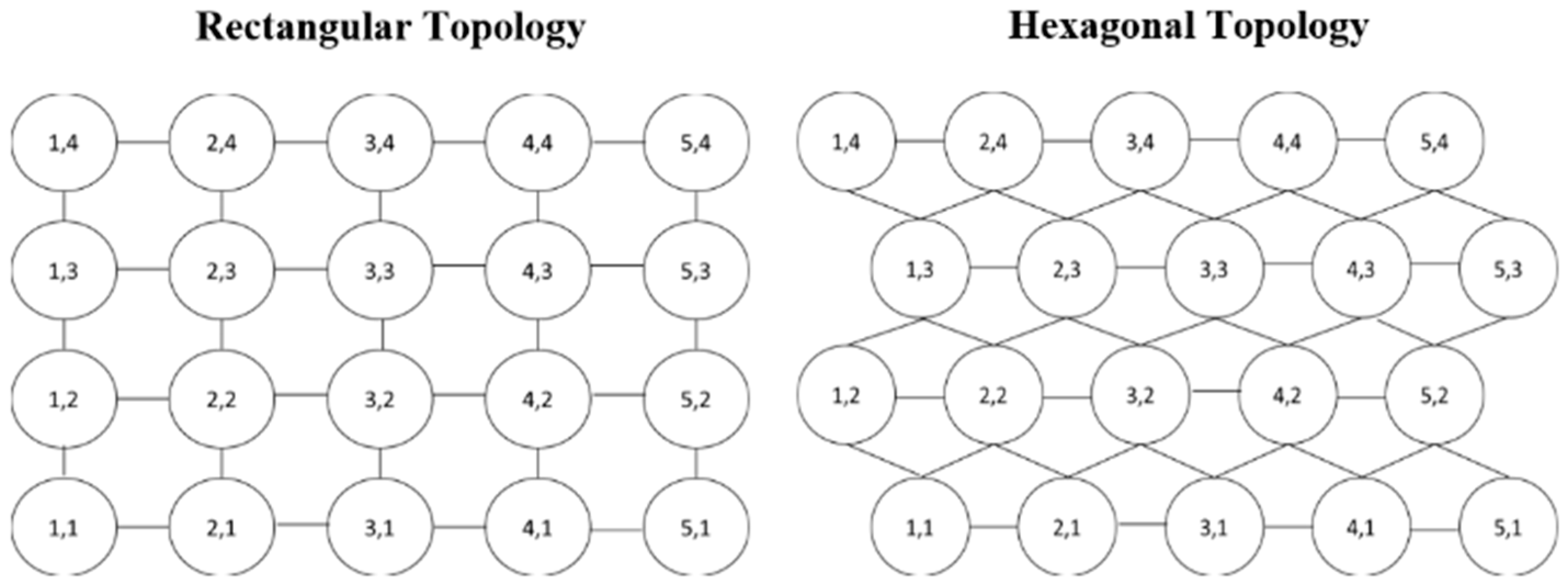
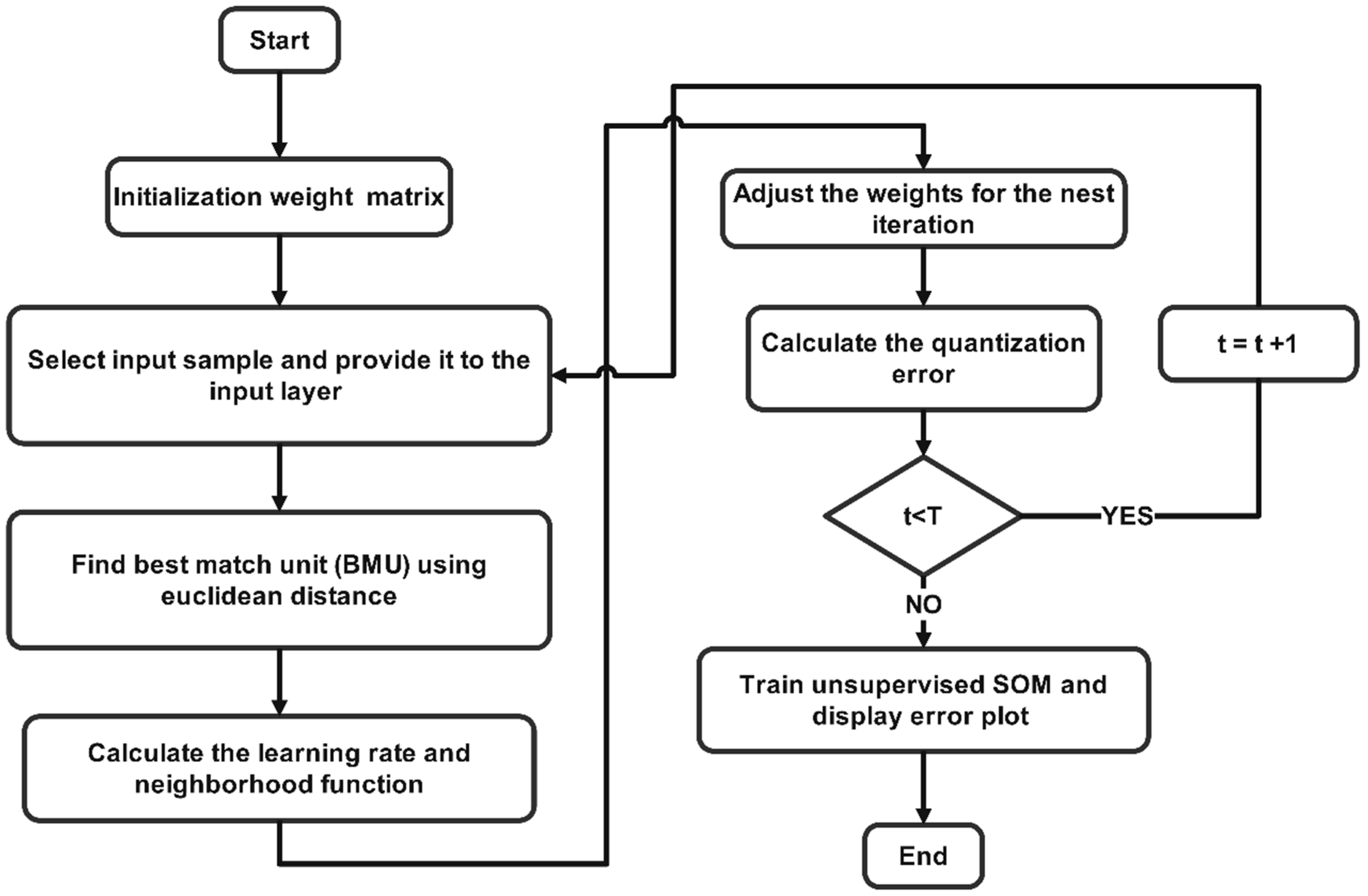
1]. Clustering is a type of unsupervised learning method. This simply means that the references are drawn from datasets that contains input data without labeled responses. However, clustering is useful to find generative features, meaningful structure, and groupings that are inherent in a set of examples. The SOM algorithm was formulated as an optimal control problem with the objective to reduce the quantization error. Hence, giving more flexibility to engineers to manipulate many attributes of optimal control to be further improved, and thus enhancing SOM to obtain more accurate results in shorter periods of time. The slow learning process speed becomes an obstacle for SOM to be employed in real time and dynamic system applications. However, by applying optimal control with the aim to reduce the mean quantization error, a more accurate solution can be obtained. Basically, SOMs differ in the way that they use competitive learning and cooperative learning as opposed to error-correction learning. There are many methods that can be applied to solve optimal control problems. One of the methods that has obtained the most attention in recent years is Pontryagin’s minimum principle (PMP). PMP is used in the optimal control theory to identify the optimum feasible control for bringing a dynamical system from one state to another, especially in the face of limitations on the state or input controls. The proper Hamiltonian equation must be formulated to obtain the adjoint equation and switching function. SOM has been modeled as a PMP problem using MATLAB based on the SOM toolbox. Furthermore, the main advantage of using SOM over other clustering algorithms, which we can easily point out, is its ability to reduce dimensionality and perform grid clustering, ultimately revealing similarities in the data that are easy to observe. This means that this algorithm implements a characteristic, non-linear projection from the high-dimensional space of input onto a low dimensional regular grid, which can be effectively utilized to visualize and explore the properties of the data [
2]. The first issue with SOM, which may become a bottleneck for the analysis, is the data. To implement SOM, enough data for generating meaningful clusters are required, as insufficient or extraneous data might add additional randomness to the clusters [
3]. This further motivates us to improve the SOM algorithm using the optimal control as the current data analysis, which requires a large amount of data to be clustered. When training with huge amounts of data, the training tends to be slower [
4]. However, once the training has been completed, new data can be mapped quickly to the SOM. The error measured during the training period can be improved to obtain an improved clustering. The quantization error will be addressed in this study and improved using the optimal control. Generally, the smaller the quantization error, the better the quantization [
5]. Moreover, in [
6], a synthetic neural network-based SOM for the classification problem of Coronary Heart Disease (CHD) was proposed. The simulation results show a better accuracy and error rate compared to another dataset. The authors of [
7] introduced a path planning and control method for a humanoid robot, which requires a path planning system that can take data representing an external sensor, extract the connected paths, and link the paths together to form the Cartesian motion for the robotic system. A comparison of the back-propagation model and the SOMs model in terms of planning the motion in a humanoid robot is presented in this study, showing that SOM performs better and achieves better results. Color image segmentation is based on the SOM and K-means algorithms proposed by [
8]; the outcomes show that SOM performs better in terms of discriminating the main features of the image, whereas the results from the K-means algorithm present the minimum number of the non-connected regions corresponding to the objects that are contained in the image. SOM also performs better in terms of noise toleration and topology preservation. In [
9], the researchers argue that SOM dataset can be efficiently used for clustering as it can classify image objects with an unknown probability distribution without requiring the determination of complicated parameters. They defined a hierarchical SOM and used it to construct the clustering method. The appropriate number of classes and the hierarchical relations in the datasets can be effectively revealed through SOM. However, the error loss and the learning speed are not discussed in this study. In [
10], a classification system based on a Principal Component Analysis Convolutional Network (PCN) was proposed, where convolutional filters are used to extract discriminative and hierarchical features. According to the experimental results, the proposed PCN system is feasible for real-time applications because of its robustness against various challenging distortions, such as translations, rotations, illumination conditions, and noise contaminations. In general, optimal control problems consist of mathematical expressions that include the objective function and all constraints, and are collectively known as optimization problems. The constraints include the state equation, any conditions that must be satisfied at the beginning and end of the time horizon, and anything that restricts choices between the beginning and end. At a minimum, dynamic optimization problems must include the objective function, the state equation(s), and initial conditions for the state variables [
11]. Furthermore, in [
12], they proposed the application of the Backtracking Search Algorithm (BSA) on fed-batch fermentation processes. However, all the case studies presented in this paper consisted of single objective problems. It is interesting to evaluate the performance of metaheuristics in solving multi-objective fed-batch fermentation problems. Therefore, the problem that is being addressed in this work is to reduce the mean quantization error of SOM by formulating the conventional self-organizing map algorithm as the optimal control problem. The mean quantization error equation becomes the objective function to be minimized and the online mode weight updating equation becomes the state equation. In terms of new designs of the Power Amplifier (PA) for next-generation wireless communication, the researchers in [
13] suggested a new approach to enhance the performance of the PAs in the context of efficiency and linearity. The aim is to eliminate the design cost and space. Additionally, the authors of [
14] explored the effect of two classes of grass-trimming machine engine noise on the operator in the natural working environment. The experimental results indicate that the sound pressure level of the grass trimmer machine’s engine exceeds the noise limit recommended for other machine engines by approximately 98 h per week. The authors of [
15] carried out a Genetic Algorithm (GA) to determine the optimal chip placement of the Multi-Chip Model (MCM) and Printed Circuit Board (PCB) under certain thermal constraints. The comparison results of the optimal placement utilizing a GA with other placement techniques were elaborated. However, the evaluation is valid under steady-state conditions and for MCM or PCB constant characteristics. The chip/component can only be a specific standard size. Furthermore, [
16] developed a Variable Order Ant System (VOAS) to optimize the area and wirelength by combining the VOAS with a floorplan model called a Corner List (CL), where two classes of ants are introduced to determine the local information in this study. The results showed that VOAS has better improvement, purely in terms of area optimization and the composite function of the area and wirelength compared to other benchmark techniques. The author of [
17] proposed a Hierarchical Congregated Ant System (H-CAS) to perform a variable order bottom-up hierarchical placer that can generate compact placement in a chip layout for hard and soft modules of floor planning. The empirical outcomes demonstrated that H-CAS performs a more efficient placer than state-of-the-art technique in terms of the circuit size, complexity increase, stability, and scalability. Additionally, H-CAS excels in all other techniques for higher-size issues in area minimization. Additionally, a novel non-linear consequent part recurrent T2FS (NCPRT2FS) for the prediction and identification of renewable energy systems was proposed [
18]. Furthermore, this study took the advantages of the non-linear consequent and recurrent structure, in order to create a better model for highly non-linear systems and assist with the proper selection for the identification of system dynamics, respectively. The simulations indicated that the NCPRT2FS based on the backpropagation algorithm and adaptive optimization rate performed better than the other techniques in terms of identifications with fewer errors and a smaller number of fuzzy rules. Another work proposed a sequential quadratic Hamiltonian (SQH) algorithm for solving non-smooth supervised learning problems (SLPs) where the stability of the proposed algorithm is theoretically investigated in the framework of residual neural networks with a Runge–Kutta structure; a numerical comparison of the SQH algorithm with the extended method of successive approximation (EMSA) was involved. The numerical results showed a better performance of the SQH algorithm in terms of the efficiency and robustness of the training process [
19]. On the hand, a sequential quadratic Hamiltonian (SQH) scheme for solving non-smooth quantum optimal control problems was discussed in [
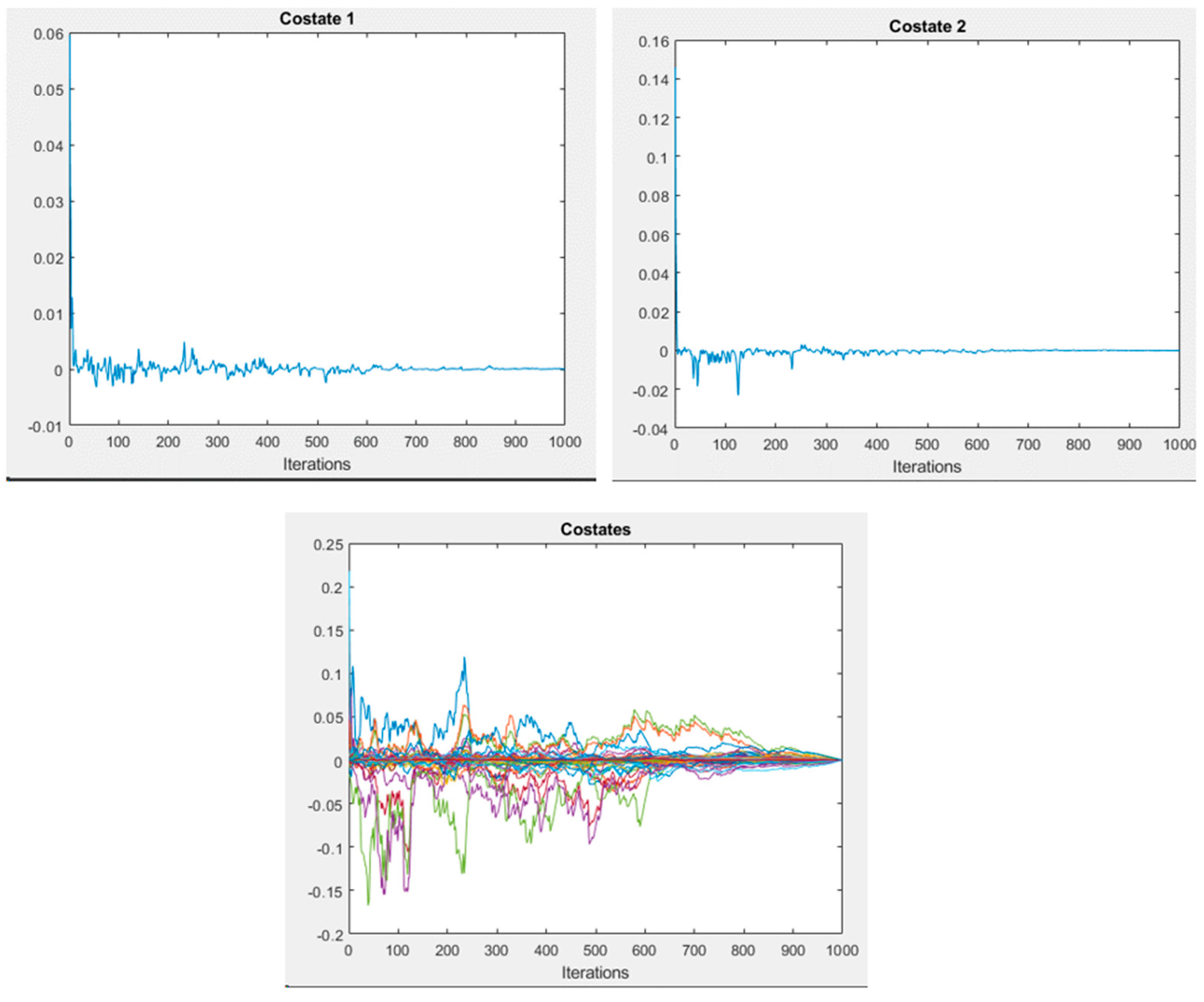
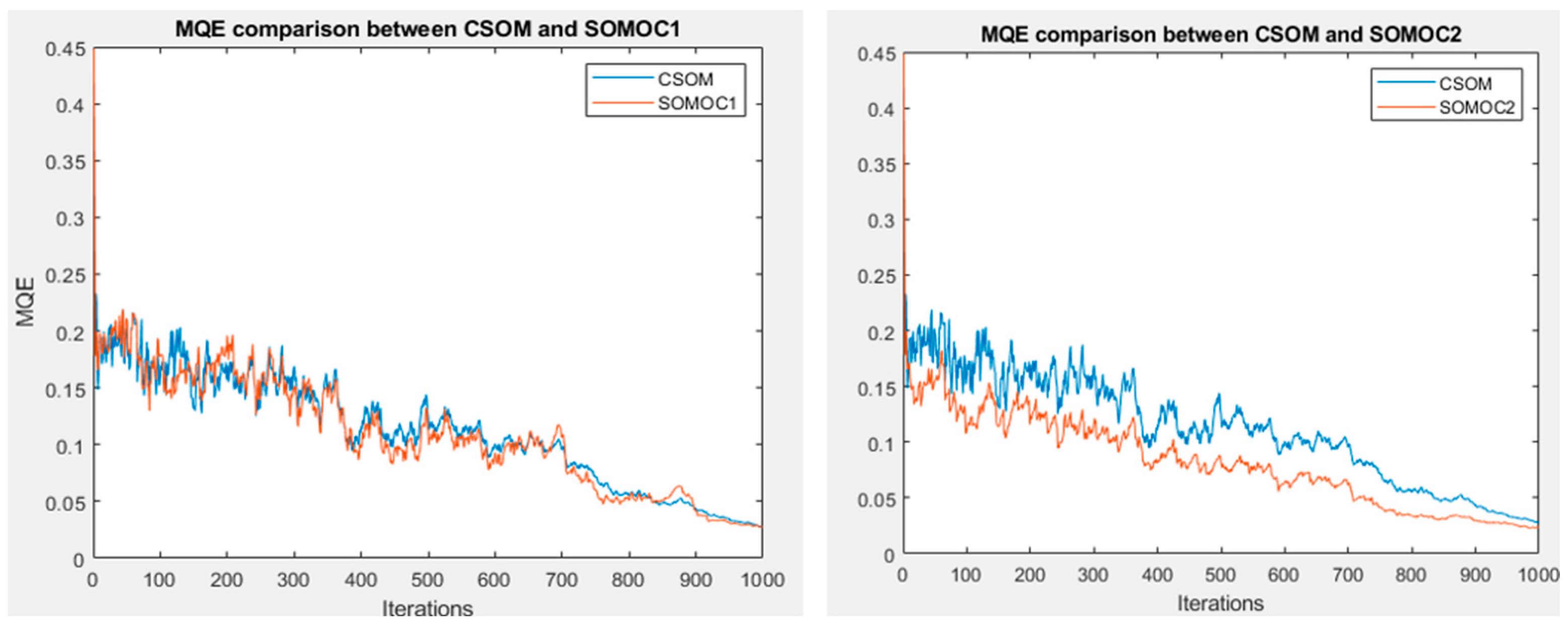
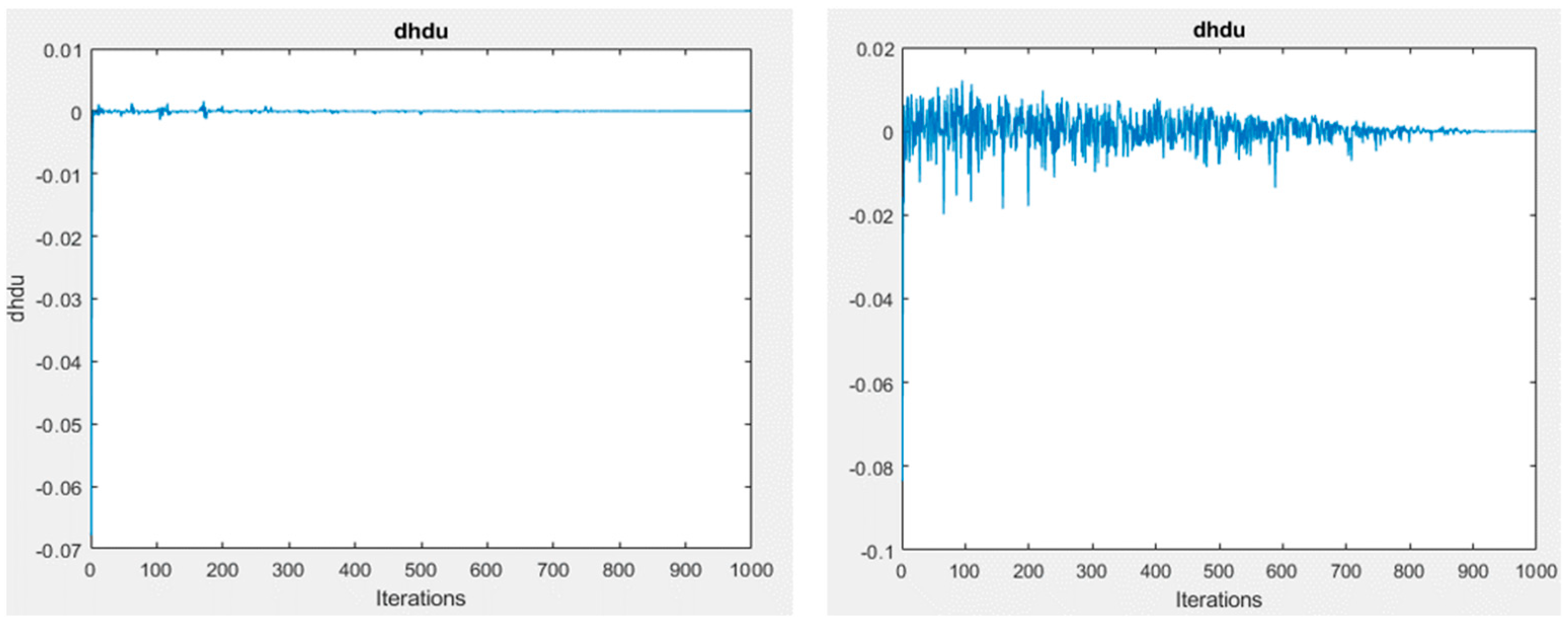
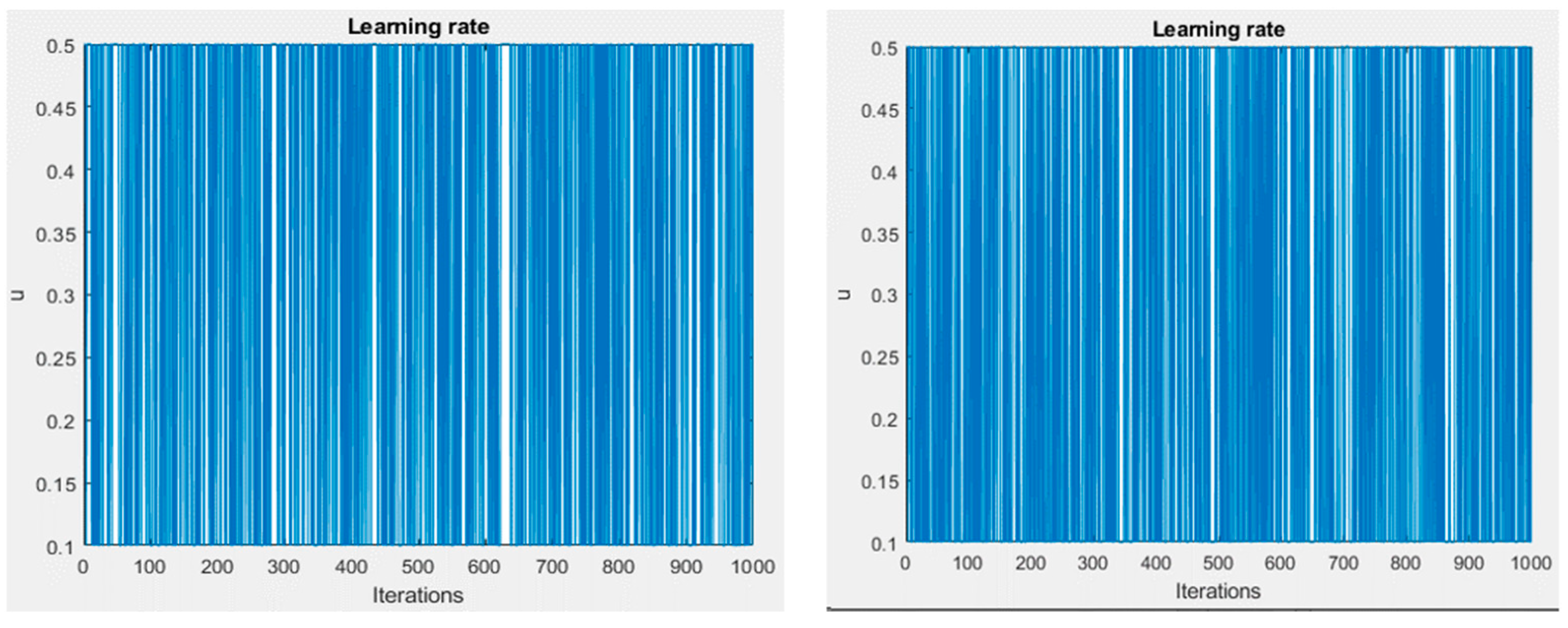
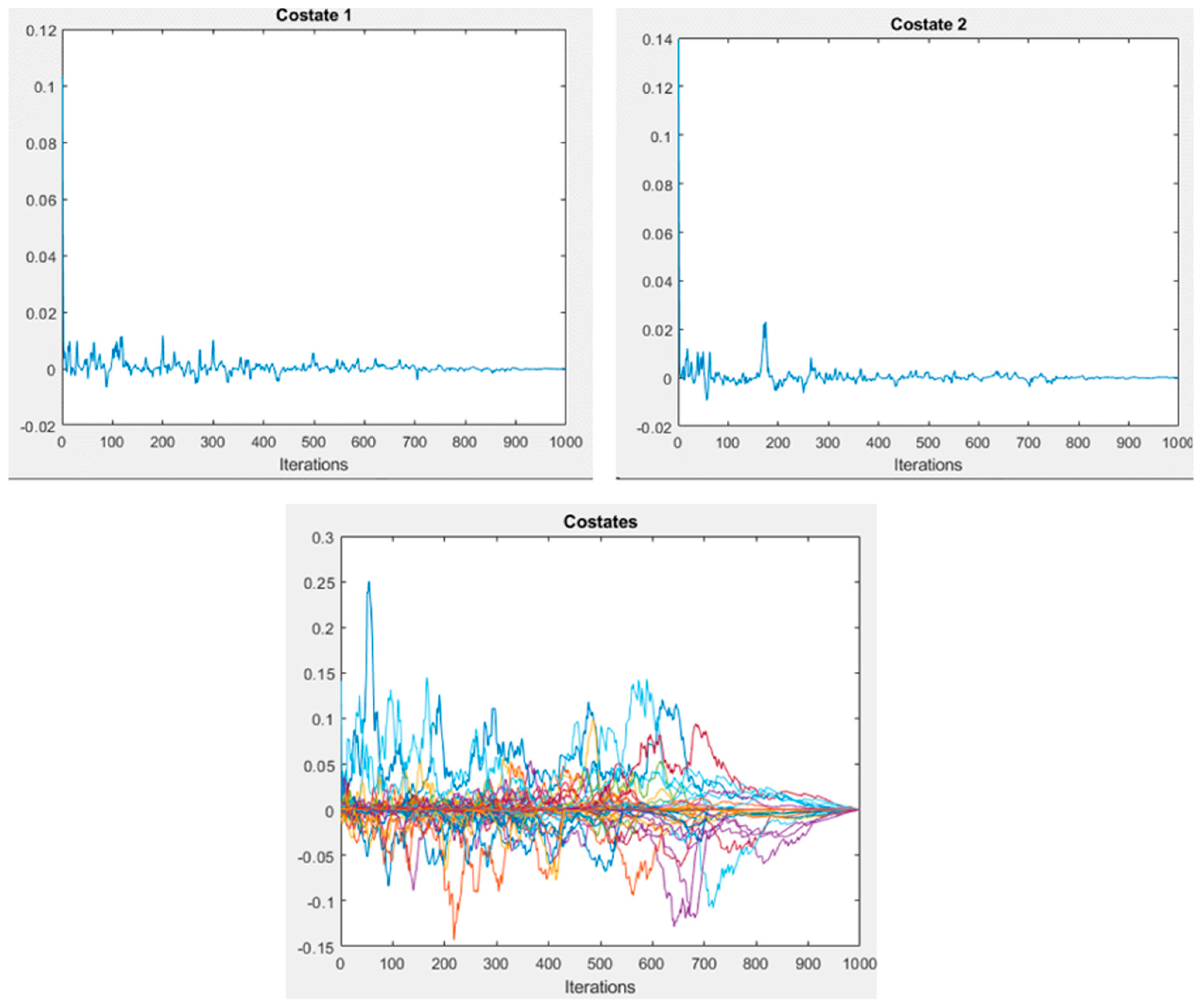
20], where the numerical and theoretical outcomes that were presented demonstrate the ability of the SQH scheme to solve control problems that are governed by quantum spin systems. The main contribution of this study is to create a SOM model based on Hamiltonian optimal control theory. This is mainly to tackle the error of the algorithm to obtain minimal errors compared to the conventional SOM algorithm. Specifically, the contributions can be summarized as follows: Firstly, minimize the error loss of SOM using the optimal control by utilizing quantization and topological errors as the main measurement to assess the quality of the SOC algorithm. Secondly, develop an input control as an adaptive learning rate using the bang-bang control.



 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}