
Multilingual Multi-Target Stance Recognition in Online Public Consultations


Abstract
:1. Introduction
2. Materials and Methods
2.1. Debating Europe Dataset
2.1.1. Data Extraction
2.1.2. Annotation
Subset Selection
Annotation Scheme
Final Annotations
2.2. CoFE
2.2.1. CoFE Participatory Democracy Platform
2.2.2. Online Debates with Intra-Multilingual Interactions

2.2.3. Annotation
Annotation Scheme
Annotation Validation and Aggregation
Final Datasets
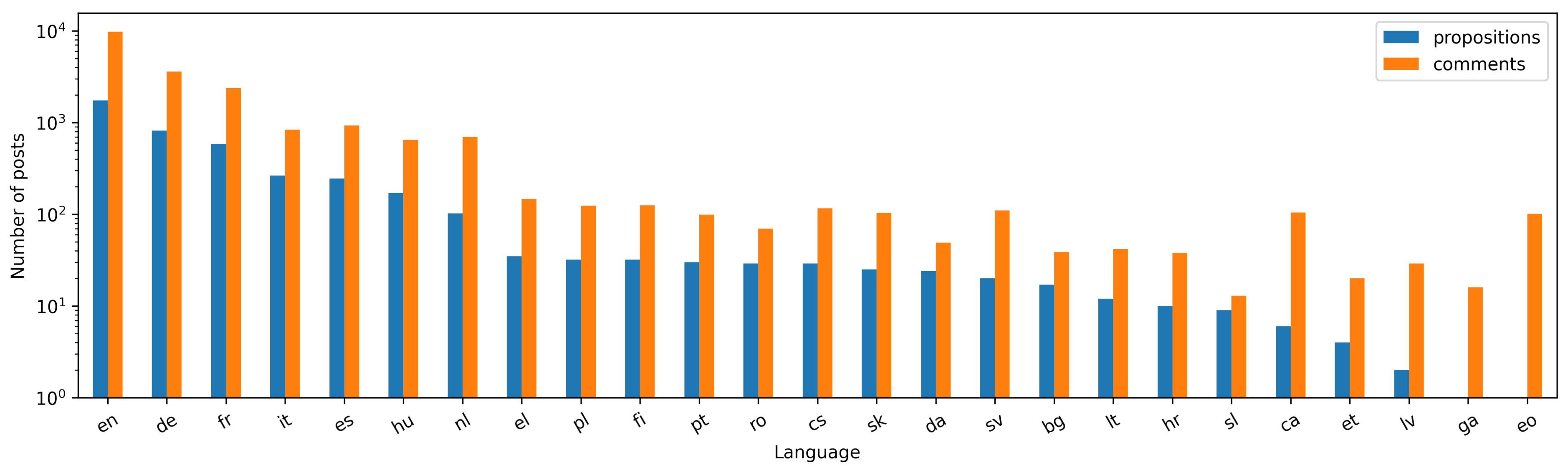
2.3. Dataset Generalities
2.4. X-Stance Dataset
3. Experiments
3.1. Debating Europe
3.1.1. Multilingual Stance Detection Using Transfer Learning
3.1.2. Data Augmentation with Semi-Supervised Learning
3.2. Experiences on CoFE
3.2.1. Multilingual Stance Detection Using Transfer Learning
3.2.2. Data Augmentation with Semi-Supervised Learning
3.3. Methodological Protocol
4. Results and Discussion
4.1. Results on Debating Europe
4.1.1. Cross-Datasets Transfer Learning
4.1.2. Self-Training Setting

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Unsupervised Method | Threshold | Balanced | Model | Prec. | Rec. | F1 | Acc | |
|---|---|---|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | ✗ | XLM-R | 68.6 | 69.3 | 68.9 | 70.1 |
| XLM-R | 70.7 | 69.9 | 70.2 | 72.1 | ||||
| thresh-0.99 | 0.99 | ✗ | ✗ | XLM-R | 68.6 | 69.8 | 69.1 | 70.7 |
| XLM-R | 68.9 | 69.6 | 69.0 | 70.9 | ||||
| k-best-2000 | ✗ | 2000 | ✗ | XLM-R | 67.5 | 68.3 | 67.8 | 69.3 |
| XLM-R | 70.4 | 69.9 | 69.8 | 71.9 | ||||
| k-best-600 | ✗ | 600 | ✗ | XLM-R | 69.4 | 68.5 | 68.0 | 69.5 |
| XLM-R | 72.5 | 70.3 | 71.1 | 73.3 | ||||
| our-2000 | 0.99 | 2000 | ✓ | XLM-R | 69.5 | 69.4 | 69.4 | 71.3 |
| XLM-R | 70.5 | 69.9 | 69.3 | 71.7 | ||||
| our-600 | 0.99 | 600 | ✓ | XLM-R | 70.9 | 71.6 | 71.1 | 72.7 |
| XLM-R | 71.5 | 71.5 | 71.4 | 73.5 |
4.2. Results on CoFE
4.2.1. Baselines for Scarce Annotation Regimes
4.2.2. Self-Training Setting
4.3. Analysis of the Results
Cross-Datasets Data
Binary Labels’ Annotations from CoFE
Ternary Labels’ Annotations from CoFE
Self-Training
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ML | Machine Learning |
| NLP | Natural Language Processing |
| DA | Data Augmentation |
| SSL | Self-Supervised Learning |
| ST | Self-Training |
| CoFE | Conference on the Future of Europe |
| DE | Debating Europe |
Appendix A. Targets of the Annotated Debates from Debating Europe
Appendix B. Statistics on Debating Europe Annotated Dataset
| Aggregation-Level | Debate | Comment | All | |||||
|---|---|---|---|---|---|---|---|---|
| Units | Label | Med | Med | |||||
| Comments | All | 140 | 99 | 101 | 1 | 0 | 1 | 2523 |
| Yes | 56 | 37 | 39 | 1 | 0 | 1 | 1012 | |
| No | 29 | 39 | 14 | 1 | 0 | 1 | 489 | |
| Neutral | 18 | 18 | 11 | 1 | 0 | 1 | 282 | |
| Not answering | 41 | 23 | 35 | 1 | 0 | 1 | 740 | |
| Words | All | 4683 | 2721 | 3794 | 33 | 60 | 16 | 84,289 |
| Yes | 1933 | 1221 | 1772 | 34 | 74 | 13 | 34,790 | |
| No | 942 | 1157 | 554 | 33 | 43 | 19 | 16,012 | |
| Neutral | 814 | 808 | 478 | 46 | 73 | 23 | 13,023 | |
| Not answering | 1137 | 627 | 972 | 28 | 39 | 16 | 20,464 | |
Appendix C. Results of the Stance Models over Other Datasets
| Model | Perspectrum | Poldeb | Snopes | Argmin | Ibmcs | All |
|---|---|---|---|---|---|---|
| Hardalov et al. [37] | 29.6 | 22.8 | 29.28 | 34.16 | 72.93 | 37.8 |
| Cross-dataset | 63.8 | 46.3 | 52.3 | 61.6 | 20.3 | 48.9 |
| Model | Iac1 | Emergent | Mtsd | Semeval16 | Vast | All |
|---|---|---|---|---|---|---|
| Hardalov et al. [37] | 35.2 | 58.49 | 23.34 | 37.01 | 22.89 | 35.4 |
| Cross-dataset | 15.5 | 21.6 | 16.7 | 13.0 | 29.1 | 19.2 |
References
- ALDayel, A.; Magdy, W. Stance detection on social media: State of the art and trends. Inf. Process. Manag. 2021, 58, 102597. [Google Scholar] [CrossRef]
- Hardalov, M.; Arora, A.; Nakov, P.; Augenstein, I. A Survey on Stance Detection for Mis- and Disinformation Identification. arXiv 2021, arXiv:2103.00242. [Google Scholar]
- De Magistris, G.; Russo, S.; Roma, P.; Starczewski, J.T.; Napoli, C. An Explainable Fake News Detector Based on Named Entity Recognition and Stance Classification Applied to COVID-19. Information 2022, 13, 137. [Google Scholar] [CrossRef]
- Yang, R.; Ma, J.; Lin, H.; Gao, W. A Weakly Supervised Propagation Model for Rumor Verification and Stance Detection with Multiple Instance Learning; Association for Computing Machinery: New York, NY, USA, 2022; Volume 1, pp. 1761–1772. [Google Scholar] [CrossRef]
- Beauchamp, N. Predicting and Interpolating State-Level Polls Using Twitter Textual Data. Am. J. Political Sci. 2017, 61, 490–503. [Google Scholar] [CrossRef]
- Sakketou, F.; Lahnala, A.; Vogel, L.; Flek, L. Investigating User Radicalization: A Novel Dataset for Identifying Fine-Grained Temporal Shifts in Opinion. In Proceedings of the LREC, Marseille, France, 20–25 June 2022; pp. 3798–3808. [Google Scholar]
- Barriere, V.; Jacquet, G. CoFE: A New Dataset of Intra-Multilingual Multi-target Stance Classification from an Online European Participatory Democracy Platform. In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing, Online, 21–24 November 2022. [Google Scholar]
- Gupta, A.; Blodgett, S.L.; Gross, J.H.; O’Connor, B. ExPRES: Examining Political Rhetoric with Epistemic Stance Detection. arXiv 2022, arXiv:2212.14486v2. [Google Scholar]
- Gorrell, G.; Bontcheva, K.; Derczynski, L.; Kochkina, E.; Liakata, M.; Zubiaga, A. RumourEval 2019: Determining rumour veracity and support for rumours. In Proceedings of the SemEval 2019, Minneapolis, MN, USA, 6–7 June 2019; pp. 845–854. [Google Scholar]
- Matero, M.; Soni, N.; Balasubramanian, N.; Schwartz, H.A. MeLT: Message-Level Transformer with Masked Document Representations as Pre-Training for Stance Detection. In Proceedings of the Findings of the Association for Computational Linguistics, Findings of ACL: EMNLP 2021, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 2959–2966. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. A Dataset for Detecting Stance in Tweets. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016. [Google Scholar] [CrossRef]
- Augenstein, I.; Rocktäschel, T.; Vlachos, A.; Bontcheva, K. Stance detection with bidirectional conditional encoding. In Proceedings of the EMNLP 2016—Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 876–885. [Google Scholar] [CrossRef]
- Dos Santos, W.R.; Paraboni, I. Moral stance recognition and polarity classification from twitter and elicited text. In Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP, Varna, Bulgaria, 2–4 September 2019; pp. 1069–1075. [Google Scholar] [CrossRef]
- Li, Y.; Sosea, T.; Sawant, A.; Nair, A.J.; Inkpen, D.; Caragea, C. P-Stance: A Large Dataset for Stance Detection in Political Domain. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Punta Cana, Dominican Republic, 1–6 August 2021; pp. 2355–2365. [Google Scholar] [CrossRef]
- Derczynski, L.; Bontcheva, K.; Liakata, M.; Procter, R.; Hoi, G.W.S.; Zubiaga, A. SemEval-2017 Task 8: RumourEval: Determining rumour veracity and support for rumours. arXiv 2017, arXiv:1704.05972. [Google Scholar]
- Somasundaran, S.; Wiebe, J. Recognizing stances in online debates. In Proceedings of the ACL-IJCNLP 2009—Joint Conference of the 47th Annual Meeting of the Association for Computational Linguistics and 4th Internation Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 226–234. [Google Scholar] [CrossRef]
- Somasundaran, S.; Wiebe, J. Recognizing Stances in Ideological On-Line Debates. In Proceedings of the NAACL Workshop, Los Angeles, CA, USA, 2 June 2010. [Google Scholar]
- Walker, M.A.; Anand, P.; Tree, J.E.; Abbott, R.; King, J. A corpus for research on deliberation and debate. In Proceedings of the 8th International Conference on Language Resources and Evaluation, LREC 2012, Istanbul, Turkey, 21–27 May 2012; pp. 812–817. [Google Scholar]
- Thomas, M.; Pang, B.; Lee, L. Get out the vote: Determining support or opposition from Congressional floor-debate transcripts. In Proceedings of the COLING/ACL 2006—EMNLP 2006: 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, Australia, 22–23 July 2006; pp. 327–335. [Google Scholar]
- Anand, P.; Walker, M.; Abbott, R.; Tree, J.E.F.; Bowmani, R.; Minor, M. Cats Rule and Dogs Drool!: Classifying Stance in Online Debate. In Proceedings of the 2nd Workshop on Computational Approaches to Subjectivity and Sentiment Analysis (WASSA 2011), Portland, OR, USA, 24 June 2011; pp. 1–9. [Google Scholar]
- Abbott, R.; Walker, M.; Anand, P.; Fox Tree, J.E.; Bowmani, R.; King, J. How can you say such things?!?: Recognizing disagreement in informal political argument. In Proceedings of the Workshop on Languages in Social Media, Portland, OR, USA, 23 June 2011; pp. 2–11. [Google Scholar]
- Walker, M.A.; Anand, P.; Abbott, R.; Grant, R. Stance classification using dialogic properties of persuasion. In Proceedings of the NAACL HLT 2012—2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings, Montreal, QC, Canada, 3–8 June 2012; pp. 592–596. [Google Scholar]
- Sridhar, D.; Foulds, J.; Huang, B.; Getoor, L.; Walker, M. Joint Models of Disagreement and Stance in Online Debate. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 27–31 July 2015; pp. 116–125. [Google Scholar]
- Barriere, V. Hybrid Models for Opinion Analysis in Speech Interactions. In Proceedings of the ICMI, Glasgow, UK, 13–17 November 2017; pp. 647–651. [Google Scholar]
- Allaway, E.; McKeown, K. Zero-Shot Stance Detection: A Dataset and Model Using Generalized Topic Representations. arXiv 2020, arXiv:2010.03640. [Google Scholar]
- Villa-Cox, R.; Kumar, S.; Babcock, M.; Carley, K.M. Stance in Replies and Quotes (SRQ): A New Dataset For Learning Stance in Twitter Conversations. In Proceedings of the AAAI, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Hazarika, D.; Poria, S.; Zimmermann, R.; Mihalcea, R. Emotion Recognition in Conversations with Transfer Learning from Generative Conversation Modeling. arXiv 2019, arXiv:1910.04980. [Google Scholar]
- Lai, M.; Cignarella, A.T.; Hernández Farías, D.I.; Bosco, C.; Patti, V.; Rosso, P. Multilingual stance detection in social media political debates. Comput. Speech Lang. 2020, 63, 101075. [Google Scholar] [CrossRef]
- Hardalov, M.; Arora, A.; Nakov, P.; Augenstein, I. Few-Shot Cross-Lingual Stance Detection with Sentiment-Based Pre-Training. arXiv 2022, arXiv:2109.06050. [Google Scholar] [CrossRef]
- Zotova, E.; Agerri, R.; Nuñez, M.; Rigau, G. Multilingual stance detection: The catalonia independence corpus. In Proceedings of the LREC 2020—12th International Conference on Language Resources and Evaluation, Marseille, France, 11–16 May 2020; pp. 1368–1375. [Google Scholar]
- Zheng, J.; Baheti, A.; Naous, T.; Xu, W.; Ritter, A. STANCEOSAURUS: Classifying Stance Towards Multicultural Misinformation. In Proceedings of the EMNLP, Abu Dhabi, United Arab Emirates, 7–11 December 2022. [Google Scholar]
- Sobhani, P.; Inkpen, D.; Zhu, X. A Dataset for Multi-Target Stance Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 551–557. [Google Scholar]
- Vamvas, J.; Sennrich, R. X-stance: A Multilingual Multi-Target Dataset for Stance Detection. In Proceedings of the SwissText, Zurich, Switzerland, 23–25 June 2020. [Google Scholar]
- Deng, R.; Panl, L.; Clavel, C. Domain Adaptation for Stance Detection towards Unseen Target on Social Media. In Proceedings of the 2022 10th International Conference on Affective Computing and Intelligent Interaction, ACII 2022, Nara, Japan, 18–21 October 2022. [Google Scholar] [CrossRef]
- Hosseinia, M.; Dragut, E.; Mukherjee, A. Stance Prediction for Contemporary Issues: Data and Experiments. arXiv 2020, arXiv:2006.00052. [Google Scholar]
- Barriere, V.; Jacquet, G. How does a pre-trained transformer integrate contextual keywords? Application to humanitarian computing. In Proceedings of the International ISCRAM Conference, Blacksburg, VA, USA, May 2019 2021; pp. 766–771. [Google Scholar]
- Hardalov, M.; Arora, A.; Nakov, P.; Augenstein, I. Cross-Domain Label-Adaptive Stance Detection. In Proceedings of the EMNLP, Virtual, 7–11 November 2021; Volume 19. [Google Scholar]
- Augenstein, I.; Ruder, S.; Søgaard, A. Multi-Task learning of pairwise sequence classification tasks over disparate label spaces. In Proceedings of the NAACL HLT 2018—2018 Conference North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 1896–1906. [Google Scholar]
- Barriere, V.; Balahur, A.; Ravenet, B. Debating Europe: A Multilingual Multi-Target Stance Classification Dataset of Online Debates. In Proceedings of the First Workshop on Natural Language Processing for Political Sciences (PoliticalNLP), LREC, Marseille, France, 20–25 June 2022; European Language Resources Association: Marseille, France, 2022; pp. 16–21. [Google Scholar]
- Bai, F.; Ritter, A.; Xu, W. Pre-train or Annotate? Domain Adaptation with a Constrained Budget. In Proceedings of the EMNLP 2021—2021 Conference on Empirical Methods in Natural Language Processing, Virtual, 7–11 November 2021; pp. 5002–5015. [Google Scholar]
- Yarowsky, D. Unsupervised word sense disambiguation rivaling supervised methods. In Proceedings of the ACL, Cambridge, MA, USA, 26–30 June 1995; pp. 189–196. [Google Scholar] [CrossRef]
- Zhu, X.; Ghahramani, Z. Learning from Labeled and Unlabelled Data with Label Propagation; Technical Report; Technical Report CMU-CALD-02-107; Carnegie Mellon University: Pittsburgh, PA, USA, 2002. [Google Scholar]
- Zhou, D.; Bousquet, O.; Navin Lal, T.; Weston, J.; Schölkopf, B. Learning with Local and Global Consistency. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, Canada, 8–13 December 2003. [Google Scholar] [CrossRef]
- Giasemidis, G.; Kaplis, N.; Agrafiotis, I.; Nurse, J.R. A Semi-Supervised Approach to Message Stance Classification. IEEE Trans. Knowl. Data Eng. 2020, 32, 1–11. [Google Scholar] [CrossRef]
- Glandt, K.; Khanal, S.; Li, Y.; Caragea, D.; Caragea, C. Stance Detection in COVID-19 Tweets. In Proceedings of the ACL-IJCNLP, Virtual, 1–6 August 2021; pp. 1596–1611. [Google Scholar] [CrossRef]
- Wei, C.; Sohn, K.; Mellina, C.; Yuille, A.; Yang, F. CReST: A Class-Rebalancing Self-Training Framework for Imbalanced Semi-Supervised Learning. In Proceedings of the CVPR, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Klie, J.C.; Bugert, M.; Boullosa, B.; de Castilho, R.E.; Gurevych, I. The INCEpTION Platform: Machine-Assisted and Knowledge-Oriented Interactive Annotation. In Proceedings of the International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 5–9. [Google Scholar]
- Küçük, D.; Fazli, C.A. Stance detection: A survey. ACM Comput. Surv. 2020, 53, 1–37. [Google Scholar] [CrossRef]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology; SAGE Publications: Los Angeles, CA, USA, 2013. [Google Scholar] [CrossRef]
- Joseph, K.; Shugars, S.; Gallagher, R.; Green, J.; Mathé, A.Q.; An, Z.; Lazer, D. (Mis)alignment Between Stance Expressed in Social Media Data and Public Opinion Surveys. In Proceedings of the EMNLP 2021—2021 Conference on Empirical Methods in Natural Language Processing, Virtual, 7–11 November 2021; pp. 312–324. [Google Scholar] [CrossRef]
- Yin, W.; Hay, J.; Roth, D. Benchmarking zero-shot text classification: Datasets, evaluation and entailment approach. In Proceedings of the EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; pp. 3914–3923. [Google Scholar] [CrossRef]
- Rosenstein, M.T.; Marx, Z.; Kaelbling, L.P.; Dietterich, T.G. To transfer or not to transfer. In Proceedings of the NIPS 2005 Workshop Transfer Learning, Vancouver, BC, Canada, 5–8 December 2005; Volume 898, p. 3. [Google Scholar]
- Ruder, S. Neural Transfer Learning for Natural Language Processing. Ph.D. Thesis, University of Galway, Galway, Ireland, 2019. [Google Scholar]
- Barriere, V.; Balahur, A. Improving Sentiment Analysis over non-English Tweets using Multilingual Transformers and Automatic Translation for Data-Augmentation. In Proceedings of the COLING, Barcelona, Spain, 12 December 2020. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-art Natural Language Processing. arXiv 2019, arXiv:1910.03771. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-Lingual Representation Learning at Scale. arXiv 2020, arXiv:1911.02116. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014; pp. 1–13. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2016, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Bondarenko, A.; Fröbe, M.; Kiesel, J.; Schlatt, F.; Barriere, V.; Ravenet, B.; Hemamou, L.; Luck, S.; Reimer, J.H.; Stein, B.; et al. Overview of Touché, 2023: Argument and Causal Retrieval. In Proceedings of the ECIR, Dublin, Ireland, 2–6 April 2023. [Google Scholar]
- Mirzakhmedova, N.; Kiesel, J.; Alshomary, M.; Heinrich, M.; Handke, N.; Cai, X.; Barriere, V.; Dastgheib, D.; Ghahroodi, O.; Sadraei, M.A.; et al. The Touché23-ValueEval Dataset for Identifying Human Values behind Arguments. arXiv 2023, arXiv:2301.13771. [Google Scholar]
- Pelachaud, C. Multimodal Expressive Embodied Conversational Agents. In Proceedings of the 13th annual ACM International Conference on Multimedia, Singapore, 6–11 November 2005; pp. 683–689. [Google Scholar] [CrossRef]
- Argyle, L.P.; Busby, E.; Gubler, J.; Bail, C.; Howe, T.; Rytting, C.; Wingate, D. AI Chat Assistants can Improve Conversations about Divisive Topics. arXiv 2023, arXiv:2302.07268v1. [Google Scholar]


| Label | % DE | Unit | |||
|---|---|---|---|---|---|
| ✗ | 100% | Comments | ⌀ | 89.5 | 125,798 |
| Words | 51.7 | 4623 | 6,499,625 | ||
| ✓ | 2.0% | Comments | ⌀ | 140 | 2523 |
| Words | 33.4 | 4683 | 84,289 |
| Title | Topic | Proposal | Comment | Stance | Url |
|---|---|---|---|---|---|
| Focus on Anti-Aging and Longevity research | Health | The EU has presented their green paper on ageing, and correctly named the aging… | The idea of prevention being better than a cure is nothing new or revolutionary. Rejuvenation… | Pro |  |
| Set up a program for returnable food packaging… | Climate change and the environment | The European Union could set up a program for returnable food packaging made from… | Bringing our own packaging to stores could also be a very good option. People would be… | Pro | |
| Impose an IQ or arithmetic-logic test to immigrants | Migration | We should impose an IQ test or at least several cognitive tests making sure immigrants have… | On ne peut pas trier les migrants par un simple score sur les capacités cognitives. Certains fuient la guerre et vous… | Against | |
| Un Président de la Commission directement élu… | European democracy | Les élections, qu’elles soient présidentielles ou législatives, sont au coeur du processus… | I prefer sticking with a representative system and have the President of the… | Against | |
| Europa sí, pero no así | Values and rights, rule of law, security | En los últimos años, las naciones que forman parte de la UE han visto como su soberanía ha sido… | Zdecydowanie nie zgadzam się z pomysłem, aby interesy indywidualnych Państw miały… | Against | |
| Length | 1 | 2 | 3 | 4 | All |
|---|---|---|---|---|---|
| Number | 10,876 | 2365 | 1920 | 800 | 15,961 |
| Dataset | X-Stance | DE | CF | CF | CF |
|---|---|---|---|---|---|
| Classes | 2 | 3 | 2 | 3 | ⌀ |
| Languages | 3 | 2 | 25 | 22 | 26 |
| Targets | 150 | 18 | 2724 | 757 | 4274 |
| Comments | 67,271 | 2523 | 6985 | 1206 | 12,024 |
| Debate | ✗ | ✓ | ✓ | ✓ | ✓ |
| Intra Mult. | ✗ | ✗ | ✓ | ✓ | ✓ |
| Intra-Target | X-Question | X-Topic | X-Lingual | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| DE | FR | Mean | DE | FR | Mean | DE | FR | Mean | IT | |
| M-BERT [33] | 76.8 | 76.6 | 76.6 | 68.5 | 68.4 | 68.4 | 68.9 | 70.9 | 69.9 | 70.2 |
| XLM-R | 76.3 | 78.0 | 77.1 | 71.5 | 72.9 | 72.2 | 71.2 | 73.7 | 72.4 | 73.0 |
| XLM-R | 77.3 | 79.0 | 78.1 | 71.5 | 74.8 | 73.1 | 72.2 | 74.7 | 73.4 | 73.9 |
| Model | Annotations Used | − | ∼ | + | Acc. | M-F1 | ||
|---|---|---|---|---|---|---|---|---|
| CoFE-3 | CoFE-2 | OODataset | ||||||
| Hardalov et al. [37] + MT | ✗ | ✗ | ✓ | 7.7 | 29.5 | 61.4 | 46.3 | 32.8 |
| Hardalov et al. [29] | ✗ | ✗ | ✓ | 20.7 | 19.1 | 58.9 | 43.2 | 32.9 |
| Cross-datasets | ✗ | ✗ | ✓ | 45.3 | 44.0 | 62.6 | 52.7 | 50.6 |
| All-1 training | ✗ | ✓ | ✓ | 56.8 | 00.6 | 77.9 | 62.9 | 45.1 |
| Cross-debates | ✗ | ✓ | ✓ | 54.3 | 41.4 | 77.3 | 63.0 | 57.6 |
| All-2 trainings | ✗ | ✓ | ✓ | 52.9 | 45.0 | 76.3 | 63.1 | 58.1 |
| CF-1 training | ✓ | ✓ | ✗ | 42.1 | 39.9 | 75.6 | 62.3 | 52.5 |
| All-1 training | ✓ | ✓ | ✓ | 57.9 | 30.0 | 78.5 | 65.4 | 55.5 |
| All-2 trainings | ✓ | ✓ | ✓ | 57.3 | 40.2 | 80.5 | 67.3 | 59.3 |
| Unsupervised Method | Threshold | Balanced | − | ∼ | + | Acc | M-F1 | |
|---|---|---|---|---|---|---|---|---|
| ✗ | ✗ | ✗ | ✗ | 57.3 | 40.2 | 80.5 | 67.3 | 59.3 |
| thresh-0.99 | 0.99 | ✗ | ✗ | 43.6 | 55.8 | 77.3 | 65.2 | 58.9 |
| k-best-2000 | ✗ | 2000 | ✗ | 59.6 | 42.6 | 79.9 | 66.2 | 60.4 |
| k-best-600 | ✗ | 600 | ✗ | 51.8 | 50.4 | 78.8 | 66.4 | 60.3 |
| our-2000 | 0.99 | 2000 | ✓ | 57.6 | 52.7 | 79.2 | 67.8 | 63.2 |
| our-600 | 0.99 | 600 | ✓ | 56.8 | 51.5 | 76.4 | 65.1 | 61.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barriere, V.; Balahur, A. Multilingual Multi-Target Stance Recognition in Online Public Consultations. Mathematics 2023, 11, 2161. https://doi.org/10.3390/math11092161
Barriere V, Balahur A. Multilingual Multi-Target Stance Recognition in Online Public Consultations. Mathematics. 2023; 11(9):2161. https://doi.org/10.3390/math11092161
Chicago/Turabian StyleBarriere, Valentin, and Alexandra Balahur. 2023. "Multilingual Multi-Target Stance Recognition in Online Public Consultations" Mathematics 11, no. 9: 2161. https://doi.org/10.3390/math11092161
APA StyleBarriere, V., & Balahur, A. (2023). Multilingual Multi-Target Stance Recognition in Online Public Consultations. Mathematics, 11(9), 2161. https://doi.org/10.3390/math11092161