Abstract
Disability management in information systems refers to the process of ensuring that digital technologies and applications are designed to be accessible and usable by individuals with disabilities. Traditional methods face several challenges such as privacy concerns, high cost, and accessibility issues. To overcome these issues, this paper proposed a novel method named bidirectional federated learning-based Gradient Optimization (BFL-GO) for disability management in information systems. In this study, bidirectional long short-term memory (Bi-LSTM) was utilized to capture sequential disability data, and federated learning was employed to enable training in the BFL-GO method. Also, gradient-based optimization was used to adjust the proposed BFL-GO method’s parameters during the process of hyperparameter tuning. In this work, the experiments were conducted on the Disability Statistics United States 2018 dataset. The performance evaluation of the BFL-GO method involves analyzing its effectiveness based on evaluation metrics, namely, specificity, F1-score, recall, precision, AUC-ROC, computational time, and accuracy and comparing its performance against existing methods to assess its effectiveness. The experimental results illustrate the effectiveness of the BFL-GO method for disability management in information systems.
Keywords:
disability management; information systems; federated learning; bidirectional long short-term memory; gradient-based optimization MSC:
68T04
1. Introduction
According to the Global Burden of Disease survey, disability is the fastest-growing global burden as the population ages worldwide. Similarly, disability-related healthcare costs are increasing, which requires the development of sustainable policies and approaches to avert and minimize functional impairment []. Environmental factors exert an important influence on human health conditions with evidence recommending that many physical, biological, chemical, and social factors can serve as potential goals to execute effective approaches to improve human health []. Disability management is referred to as a constructive and systematic technique of ensuring job retention in competitive employment for individuals with disabilities. In the 1980s, DM was initially developed in northern Europe and America but is still poorly applied in Italy. Disability management is broadly utilized in the public sector, namely to manage and prevent unavailability to work because of injury, with tools like planning of benefits and sick leave and adjustments of duties when people return to work []. Additionally, the attention of physicians, researchers, and program developers in several fields in terms of possible transformation for treating human diseases has grown. Artificial intelligence supports diagnosis, treatment, and operation, and some people consider that in the future medical practitioners will become outdated []. Despite that, to investigate challenges and opportunities related to AI applications in the healthcare sector, it is important to assess the contribution of AI. AI has broad potential related to real-world applications in the most sophisticated treatment of emergency patients ranging from simple operational process interventions []. In addition, there has been discussion of the contribution of advancements in machine learning and artificial intelligence to those concerned with disability, therapeutic and non-therapeutic users, knowledge consumers, producers, and victims []. To participate in governance discussions, disabled people face specific obstacles like knowledge production and consumption.
Federated learning (FL) is one of the methods that can preserve the privacy of the patient, and it also resolves the issue in the deep learning model’s training process of federated medical data []. With a coordinated central aggregate server, the FL method offers decentralized machine learning model training, and for this, it does not send medical data. Medical institutions sometimes transmit deep learning models to the aggregate server; before this, they train the model and work as client nodes []. To generate a global model, the central server combines the local models between the nodes, and afterward, this global model is distributed, and other nodes receive this model. FL proves that it can improve efficiency in development processes and medicine discovery []. Currently, many large companies, ten pharmaceutical companies, and academic research labs have developed industry-scale FL models in drug discovery. To generate this model, there is no need to share confidential datasets. The reliability of the patient data is secured and to acquire the identification of prediction of drug efficacy, targets, and optimization of treatment protocols, assorted patient data can be trained on the federated learning models []. Multiple methods of applying machine and deep learning are introduced for the enhancement of disability management, and these methods have advantages and disadvantages. These methods struggle to produce better efficiency and have some issues like low accuracy, high cost, and lack of datasets. By permitting organizations to keep control and ownership of data, FL can assist in controlling data, and thus the risks of data can be decreased. So, motivated by this reason, this paper uses the federated learning method and is combined with bidirectional long short-term memory for efficient results in disability management. This study contributes to disability management in information systems by using various techniques. The major contribution of the proposed BFL-GO method is explained below.
Novel method: This paper concerns a novel approach that combines a Bi-LSTM with federated learning, along with the integration of the gradient-based optimizer algorithm with local search strategy. This unique combination of techniques offers a new perspective on disability management in information systems.
Real-time application: By incorporating multiple layers of LSTM, the system can capture complex dependencies in the data and also manage real-time disabilities based on sensor inputs, ensuring timely control of the people’s disabilities conditions.
Efficient hyperparameter optimization: The incorporation of an improved GBO algorithm efficiently optimizes the parameters and enhances the BFL-GO method performance for disability management in information systems.
Enhanced disability management: The composition of the gradient-based optimizer algorithm executes augmented performance for disability management in information systems. The symbiotic assimilation of these methods improves the parameters.
The organization of this work is arranged as follows: A survey of the literature on AI with federated learning is discussed in Section 2, which includes various existing techniques associated with disability management, the drawbacks and challenges of the existing techniques, and the research gaps. Section 3 depicts the proposed methodology that includes different methods to achieve better performance. The results section is shown in Section 4, and the experimental evaluations were conducted by using graphical representations, performance evaluations, and comparison studies. Section 5 concludes the work with future directions.
2. Literature Review
Cheng et al. [] introduced AI in work disability management using a smart work injury management system (SWIM). SWIM was an established, safe cloud platform with some operational devices for data storage and machine learning. Starting from the Jjob damage folder to every other folders, considering static as well as dynamic information, the text mining method was analyzed by using AI, and RTW (return to work) prediction was also utilized. This method contains three levels, as the first is to find the basis of enablers and impediments in regard to detecting the human factor, RTW face meetings, and conversation with various RTW shareholders to gather the information to enablers. Second is to improve the ML. Finally, ML connects long- and short-term memory (LSTM). In summary, these methods predict the price of work injuries. Garcia et al. [] presented a sustainability-based conception for an urban pavement management system (PMS) using deep learning techniques. This method of PMS was improved in the urban area networks and the geographic information system (GIS) was utilized to examine and handle the information in these area networks. Further, the analyzed information that was found by creating the automated materials, a webcam was placed in the automobile, and pictures were evaluated using DL-CNN. As a result, it helped urban areas provide exact information, but this method does not detect different global states and also poorly handles optimization.
Bolanos et al. [] discussed fleet management and control systems (FMCS) for improving countries’ implementation using intelligent transportation systems (ITS) services. FMCS observes the automobile in the present time and also aids in checking the agenda. Furthermore, FMCS faces some issues like communication, expenses, interactivity, etc. To overcome these issues, this method developed a ITS framework that was only made for the FMCS. Further high-speed conversation, ITS, using this service developing states for FMCS was created. In addition, the test of FMCS utilized transport vehicles in the urban areas along with finding the one path employed in the test. As a result, the merit of this method was improved communication, reduced cost, and more security. Also, this method’s data set was extremely small. Sprunt et al. [] discussed a combination of child functioning data-based learning and support needs data to produce a disability identification method in Fiji’s education management information system (FEMIS). Most of the separated FEMIS by disease occurred in low states and needed more accuracy. This method demonstrated that domain-based certain illness findings for disablement disaggregate FEMIS were possible when action data from the CFM were merged with information on environmental factors following procedures. Further, a LSN was utilized for handicapped infants and Fiji’s policy provides charitable funds for schools. As a result, this method does not handle or collect information from all the countries.
Kim et al. [] established the protection offered by the recent accessibility act and guidelines to people with disabilities utilizing information technology devices. Currently, the population has increased, so IT is utilized in worldwide environments. However, handicapped people face some challenges in using IT. To avoid this problem, a method was developed called the 179 Information Technology Devices. On the other hand, IT interaction disability (ITID) is a method that makes it easy to converse in the virtual world and also plays a role in perceiving disordered patients. The instructions from the UX give new methods to information technology creators. As a result, this method is not relevant to aging people. Alshammari et al. [] presented online training to help caretakers of children with intellectual and developmental disabilities manage issues at home. Caretakers face many challenges in taking care of disabled children and the parents of the children also face strain. This method was developed online for the caretakers to easily handle the disordered children. Furthermore, caretakers mainly focus on providing care, maintenance, daily tasks, and support to those in need. However, they receive information in the house using online techniques. As a result, this reduces stress and makes it easy to interact with children, as a drawback of online learning is limited access to informational resources.
Chiscano et al. [] developed a model of the urban transport experience for people with disabilities. This method aims to provide a service for disabled people within city transport. Further, this method contains two stages; thirty-seven members were involved in Stages 1 and 2, which focused on designing an experience based on humans with disorders. In addition, target groups, contributors during the transit experience, and post-experience questionnaires with semi-structured questions comprising establishing sufficient participant communication encounters before the experience ensured a good design of the urban transportation experience. As a result, this method does not use smart technology for the people’s experience. Elfakki et al. [] implemented effective methods based on experimental laboratories in three 3-dimensional virtual infrastructures for students with learning disabilities. Virtual reality can improve the quality of life and education of students with learning difficulties. In this method, three-dimensional items of various colors easily draw the attention of children. Further, the simulator was 3D VLE, with the incorporation of the altered Moodle training tool, and also aids children with different disorders. In addition, these methods help disabled students improve their reading skills; however, the limitation of three-dimensional methods is that they are more expensive, as well as cause health issues.
The current progress in federated learning, as emphasized in the cited publications, tackles significant obstacles in the area, improving efficiency and efficacy. The emergence of Federated Adaptive Gradient Methods (Federated AGMs) represents a notable advancement in enhancing the generalization of models, specifically in situations involving non-IID (independent and identically distributed) and imbalanced data []. These strategies efficiently utilize first-order and second-order momenta to adapt to the intricacies of real-world data distributions. The authors of [] suggest a hierarchical federated learning system that optimizes edge assignment to tackle the non-IID dilemma. This approach aims to reduce discrepancies in class distribution among nodes, leading to improved model performance and data representation. The distributed quantized gradient strategy developed by the researchers in [] effectively enhances communication efficiency by prioritizing the transmission of more relevant gradient updates, which is critical in large-scale distributed learning environments. The authors in [] propose an auction-based method for cloud-edge systems in federated learning that effectively manages energy usage while maintaining the high accuracy of AI models. This approach not only enhances the allocation of resources, but also corresponds to the increasing demand for sustainable and efficient AI solutions. Together, these progressions demonstrate a deliberate endeavor to enhance the resilience, effectiveness, and flexibility of federated learning in various complex data settings.
Research Gap
Because of disabilities, organizations and individuals encounter considerable difficulties. Via the use of the AI-based recommendation system [] and federated learning, this paper focuses on providing reasonable output in disability management. Therefore, many methods introduced in this domain offer the best effectiveness in disability management; here, the existing methods are not able to generate a model for the improvement of disability management and have challenges such as computational cost, required amount of data, weight optimizations, etc. These issues require increased model complexity in order to provide a better output []. So, to solve these issues, this work proposes a Bidirectional Federated-Learning-based Gradient Optimization (BFL-GO) model. The research gap this work addresses is as follows:
Enhanced accessibility and inclusivity: The Bi-LSTM with Federated Learning was employed because this method can improve the accessibility and inclusivity of information systems for people who have disabilities.
Hyperparameter tuning: The existing methods have difficulty tuning the parameters to enhance efficiency. The gradient-based optimization algorithm can tune the parameters of the model effectively, so this algorithm was combined with the proposed method for hyperparameter tuning.
3. Proposed Methodology
This paper proposes a novel method named the Bidirectional Federated-Learning-based Gradient Optimization (BFL-GO) algorithm to accurately predict diseases in the healthcare system. In this study, a gradient optimization algorithm was employed with Bi-LSTM with a federated learning method to enhance disability management. The Disability Statistics-United States-2018 dataset was given as the input to the developed model. Figure 1 shows the overall structure of the BFL-GO model. It contains 4 phases, namely data collection, data pre-processing, the disability management phase, and the predicted output.
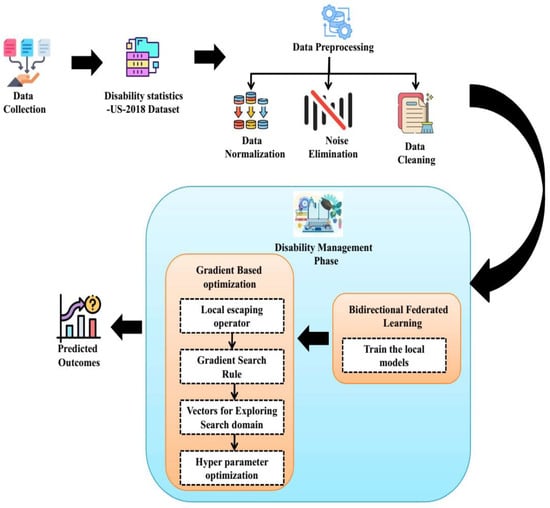
Figure 1.
Overall structure of the BFL-GO model.
3.1. Pre-Processing
Data preprocessing performs a main role in federated learning algorithms; suitable preprocessing is mandatory for obtaining good performance []. In terms of the signal, it clears unnecessary effects, prevents issues, and improves accuracy. In this stage, the dataset Disability Statistics-United States-2018 and three types of operations, namely, data normalization, noise elimination, and data cleaning, were performed for disability management in the information systems.
3.1.1. Data Normalization
To eliminate the influence of dissimilar scale features, a process was executed to reduce the training model’s implementation time []. By applying the min-max normalization procedure, the numerical features captured from the outlier elimination process were normalized, and the mathematical expression is provided below:
where the and values were assumed to be 0 and 1.
3.1.2. Noise Elimination
Noise is a vital piece used in most edge detection calculations. In the detection cycle, noise is a significant impediment. The method we used removed or reduced data without affecting the original data [].
3.1.3. Data Cleaning
Data cleaning is the process of cleaning and removing missing data, duplicate data, and resolving data inconsistencies from the dataset. This results in an improved quality of data and usefulness of data [].
3.2. Disability Management Phase
Disability management is a dedicated domain for managing the victims of accidents, reducing disabilities, and also returning to the work persons who are affected by incidents. So, for this, the Bidirectional Federated-based Gradient Optimization (BFL-GO) model was applied in this work.
3.2.1. Bidirectional Long Short-Term Memory
The classifier LSTM has 4 major elements, namely, input gate, memory cell, output gate, and forget gate [].The memory cell in the LSTM saves data for long or short durations. To manage the retention of information and hold the amount of information, the input gate and the LSTM cell are utilized with a forget gate. To format and evaluate the output activation for the output gate, the information on the LSTM layer cell can be managed. These networks are an unusual class of RNN and are presented to overcome the difficulties of long-term vanishing and bursting gradients in RNN [,]. Due to the preparation of back-proliferation through time, obtaining long successions from standard RNN is hard, which causes the problem of vanishing or exploding gradients. To overcome these problems, the RNN is transformed into a Bi-LSTM cell with an input cell. The initial gate to select which data to discard from a cell state is an ignore gate, as mentioned in the following equation; this decision is made by a sigmoid layer
To select the updated values, the input gate is next door with a sigmoid layer, and as shown in the below equations, the layer generates new updated vector values
From the above Equations (2)–(4), the updated cell state is
Depending on the updated cell state, the present state’s output is determined, and the sigmoid layer selects the regions of the cell state that are the final specified output.
where denotes the sigmoid activation function, weight metrics, tangent activation function, last hidden state, and input vector. are biased. The Bi-LSTM-based learning algorithm feeds the input sequence in a normal time sequence to a network and the reverse order to an alternate network. The stacked Bik-LSTM layer allows for obtaining both background and forward information about the sequence at every time step, which yields exact maximum categorization. The Bi-LSTM classifier manages the back-to-forward transmission of data.
Bi-LSTM is a slower model and requires additional time for training. To address this issue, federated learning mechanisms are utilized. FL is a model of distributed learning that trains and aggregates the local models on the user side and central manager. The information that each user uploads to the server is not original data, but a sub-model trained on FL []. Despite that, the FL grants asynchronous transmission and approximately reduces the communication cost. Depending on this, the formulation of federated ML can be updated given below:
where represents the number of clients, is the client’s weight value, and the structure of federated learning is the decentralized several users . Each client user has the data set of the present user . These data are scheduled into a dataset in deep learning methods. We consider the global model next to the accomplishment of federal modeling and the training model after aggregation. In particular, is the functioning of the global model because of the parameter interchange and collection operation. At the time of completing the training process, the models lose accuracy, and the performance of the global model is as poor as the performance of the aggregate model . To calculate this deviation, the efficiency of the aggregate model and the global model on the test set is determined. The loss in accuracy is expressed as
where denotes a non-negative number. However, as the fundamental need of federated learning is privacy protection, at the end of the actual scenario, the aggregation model cannot be attained. Bidirectional federated learning is presented in Algorithm 1.
| Algorithm 1: Bidirectional Federated Learning |
| Input: number of clients , weight value of client , global model , federal modeling Output: Obtain global value
|
3.2.2. Gradient-Based Optimizer (GBO)
Through Newton’s method, the search direction is indicated, the GBO utilizes the local escaping operator, gradient search rule, and set of vectors for exploring the search domain, and this algorithm integrates population-based methods and gradient methods []. Concerning optimization issues, the minimization of the objective function is determined.
Initialization: In GBO, the parameters that have probability rates and changes between exploration and exploitation exist, and an optimization issue possesses an objective function, decision variables, and constraints. For balancing the switching in the exploration and exploitation, these probability and control parameters are employed. According to the problem complexity, the population size and the number of iterations are considered. Here, the number of the population of the GBO algorithm is represented as a vector, hence, among d-dimensional search space, the GBO algorithm has vectors. In the d-dimensional search space, the initial parameters of the algorithm are produced at random.
The decision variables are represented as ; its bounds are denoted as and . is specified as a random number having the range of .
Gradient search rule (GSR): The important factor attains global points and near-optimum points and is employed for attaining balanced exploration in the important search space regions. The following equations specify the usage of the :
Here, and are specified as constants with values of and , the total number of iterations is indicated as , and the current iteration number is denoted as . For balancing exploration and exploitation, is viable in terms of the sine function. In the optimization iterations, the parameter value varies, and for expediting convergence, it reduces in the iterations. In a range, the iterations that define the parameter are increased, and as a result, the diversity is raised. The following equation represents the GSR computation:
For generating the randomized exploration mechanism, which has local optima, a random behavior is deployed, and iterations alter the of the variables because of Equation (20).
In this, the element’s random vector is represented with a range of . indicates the phase scale, and are the four integers that are chosen randomly. From the candidate vectors, directional movement employs the best vector for presenting a significant local search. At the direction of the best vector , it changes the current vector .
In this, the random number has a range of . For the adjustment of every vector agent’s phase size, the random parameter is utilized. The computation of the parameter is presented in the below equation:
In terms of the current vector , Equations (23) and (24) can be altered.
This shows that , = , and is equivalent to the average of and .
where the current solution is denoted as , the best and worst solutions are indicated as and , and the random solution vector with dimension is indicated as .
Enhancing exploitation and detection is the major objective of the GBO algorithm; for increasing the process of exploitation of the local search, Equation (26) is employed. Below Equation (28) is the calculation for , where are the denoted as random numbers that have a range of .
Local search escaping operator (LEO): For changing local optima points to boost the convergence of the GBO algorithm, this LEO operator is employed. Here, the LEO operator uses several solutions for generating new solutions that have efficiency and this is specified as the following equation:
where, and are specified as the uniform distribution with , is represented as the probability value, and here the random values are denoted as .
The below equation is represented as the binary parameter with a range of . The value of the binary parameter is equal to one when ; otherwise, the binary parameter is zero.
From Equation (36), the variable is indicated as the solution that is generated randomly based on the following equation. is referred to as a random number . The algorithm to perform the secure data transmission is presented in Algorithm 2.
| Algorithm 2: The algorithm to perform the secure data transmission |
| Input: Set the optimal threshold value Output: Perform secure data transmission
|
3.2.3. Hyperparameter Tuning Using Gradient-Based Optimization Algorithm
In the development of an efficient and reliable model for disability management, hyperparameter tuning is a significant process. Therefore, for this process of hyperparameter tuning, a Gradient-Based Optimizer algorithm was deployed. This algorithm efficiently tunes the parameters of the proposed Bi-directional with Federated Learning model; thereby, the efficiency of the proposed BFL-GO model is enhanced. Therefore, the proposed BFL-GO method expertly enhances and resolves the requirements of disability management. Applying a gradient-based optimization algorithm to tune hyperparameters substantially improves the field of advancing disability management in data networks; within this context, the process entails utilizing a gradient-based optimization algorithm. The algorithm refines model hyperparameters by iteratively following gradients related to a specific performance metric. It updates hyperparameters to minimize the metric, aiming for the optimal configuration. This method helps in customizing algorithms for specific disability management needs, enhancing information systems. Gradient-based optimization, like gradient descent, iteratively adjusts hyperparameters based on computed gradients to optimize functions like accuracy. This process refines a model’s hyperparameters to improve its work. Gradients, indicating the function’s slope, are used to guide the adjustments to the model’s hyperparameters. These algorithms search hyperparameter options for optimal model performance. Fine-tuning with gradient-based optimization upgrades precision, combination speed, and speculation to new information. This is essential for tailoring machine learning algorithms to specific tasks and datasets, resulting in more effective and reliable models.
The flowchart of the BFL-GO model is presented in Figure 2. In the Figure, we can see the working of the hyperparameter tuning of the developed model.
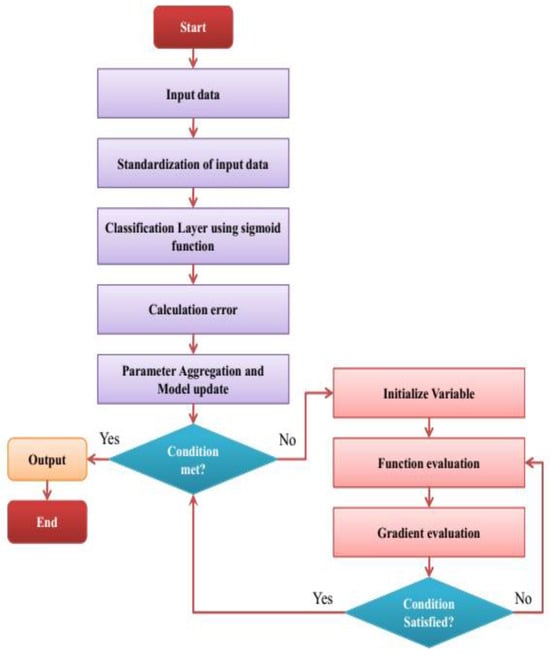
Figure 2.
Flowchart of the BFL-GO Model.
The significant research contributions of the proposed model can be described as follows:
The initial section introduces the Bidirectional Federated Learning-based Gradient Optimization (BFL-GO) model. This novel approach combines the strengths of Bidirectional Long Short-Term Memory (Bi-LSTM) and federated learning to address the specific challenges of disability management in information systems. This model aims to enhance privacy, reduce computational costs, and improve accessibility in processing disability data.
The choice of utilizing Bi-LSTM is strategic for capturing the intricacies of sequential and time-series disability data. This section emphasizes how Bi-LSTM layers are configured and integrated to effectively process and interpret disability-related information over time, capturing both forward and backward dependencies in the data. The methodology further elaborates on the integration of federated learning. This section explains how federated learning is employed to distribute the data processing across multiple nodes, thereby ensuring data privacy and security. It describes the federated learning process, including data distribution, local model training, and aggregation of learning, highlighting how this approach mitigates privacy concerns common in centralized data processing methods. Gradient-based optimization for hyperparameter tuning in the methodology focuses on the application of gradient-based optimization techniques for hyperparameter tuning. Moreover, the inclusion of federated learning distributes the data processing across multiple nodes, thereby ensuring data privacy and security.
4. Experimental Results and Discussions
The effectiveness of the BFL-GO method for disability management in information systems and the results achieved from the study are demonstrated in this section. The BFL-GO method was evaluated with various evaluation measures, namely specificity, recall, F1-score, accuracy, and precision, and the results were compared with existing methods such as SWIM [], UM-PMS [], FMCS [], and FEMIS [].
4.1. Experimental Setup
In this work, the BFL-GO method was implemented in Python; the system used was an Intel Core I7-9700 with 64 GB RAM operating at a clock speed of 3.60 GHz. Furthermore, the computing platform met minimum software and hardware requirements including sufficient storage capacity, computational power, and compatibility with Bi-LSTM with federated learning frameworks. Considering these system requirements and platform specifications, this study ensures the reliable and efficient implementation of the SMGR-BS method for the development of an AAL for aging and disabled people.
4.2. Parameter Settings
The performance of the BFL-GO method was enhanced by implementing parameter settings, and Table 1 depicts the parameter settings of the study. In this process, optimal parameter values were created to improve the performance of the BFL-GO method.

Table 1.
Parameter settings.
In this study, MSE and ReLu were utilized as the loss function and the activation function, respectively. Also, the learning rate was 0.01, the batch size was 64, and the dropout rate was 0.5. In this work, a gradient-based optimizer was utilized for hyperparameter optimization to improve the performance of the BFL-GO method. This study ensures reliable and efficient implementation of the BFL-GO method for disability management in information systems.
4.3. Dataset Description
In this work, the Disability Statistics-United States-2018 dataset [] was utilized to implement the BFL-GO method for disability management in information systems. In this study, 8000 observations were collected from the dataset, and these observations included various types of disabilities. The observations were categorized in terms of sex, age, and the severity of disability and divided into training and testing in the ratio of 80:20 to enhance the performance of the BFL-GO method for disability management in the information system.
4.4. Evaluation Measures
The performance of the BFL-GO method for disability management in information systems was evaluated through evaluation measures, namely specificity, recall, F1-score, accuracy, and precision [,]. The performance evaluation of these metrics was based on the mathematical expressions mentioned below.
Accuracy: Accuracy is the measurement of correctly classified instances to the total number of instances. The accuracy can be expressed as
Precision: Precision is the proportion of correctly predicted positive events to all events predicted as positive. The precision can be represented as
Recall: Recall is the proportion of correctly predicted positive instances out of all actual positive instances. It can be formulated as
F1-score: F1-score is the harmonic mean of recall and precision and during the precision–recall tradeoff, if the precision increases, recall decreases. The F1-score can be expressed as
Specificity: Specificity is the ratio of correctly predicted negative events out of all actual negative events. The specificity can be represented as
In Equations (38)–(42), , , and represent the true positive, true negative, false positive, and false negative, respectively.
4.5. Performance Analysis
The performance analysis of the BFL-GO method for disability management in information systems using the specified performance metrics, namely specificity, F1-score, recall, precision, and accuracy, provides a comprehensive evaluation of its effectiveness []. The performance was evaluated by comparing the BFL-GO method with the existing methods such as SWIM, UM-PMS, FMCS, and FEMIS. Figure 3, Figure 4, Figure 5, Figure 6 and Figure 7 depicts the comparative graphical representation of the BFL-GO method and the existing methods for different evaluation metrics based on disability management in the information system.
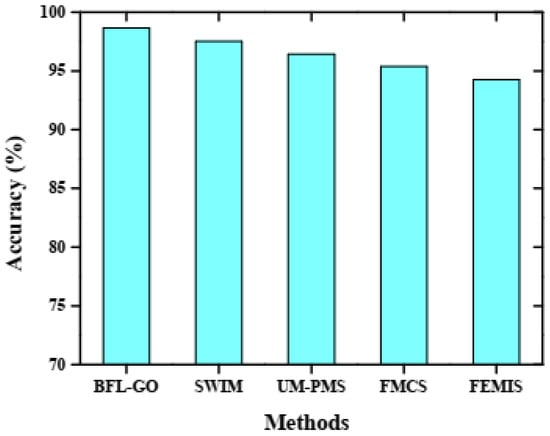
Figure 3.
Performance validation based on accuracy.
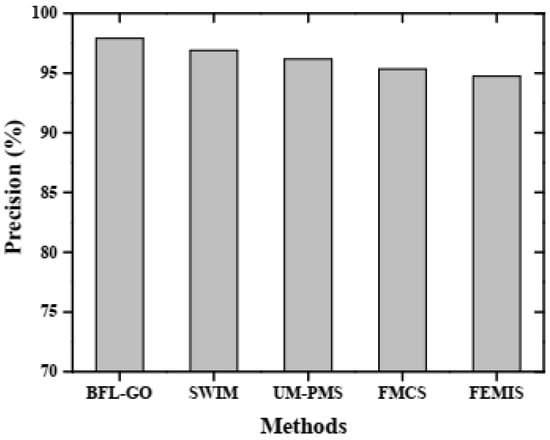
Figure 4.
Graphical representation of precision analysis.
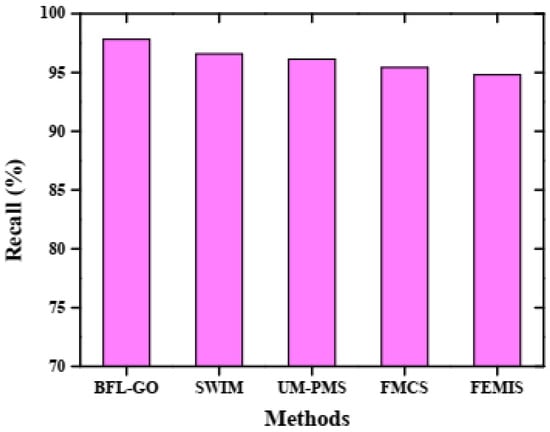
Figure 5.
Recall analysis for performance evaluation.
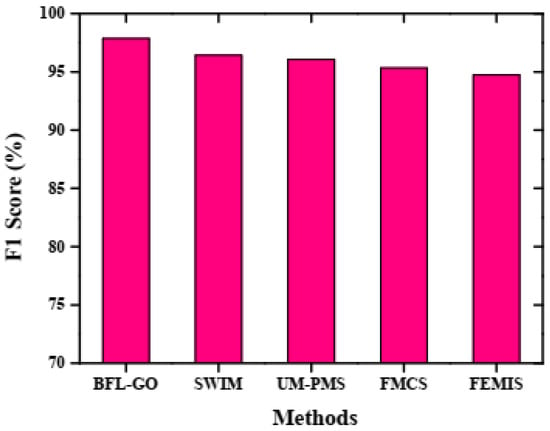
Figure 6.
Performance validation based on F1-score.
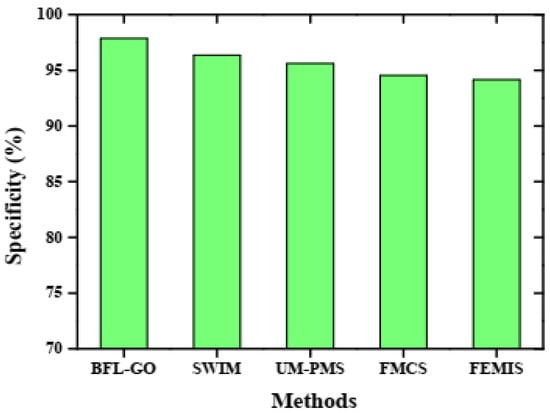
Figure 7.
Graphical representation of specificity analysis.
The accuracy of the BFL-GO method and the existing methods is demonstrated by the graphical analysis shown in Figure 3. The BFL-GO method achieved a high accuracy of 98.65%, while the existing methods such as SWIM, UM-PMS, FMCS, and FEMIS obtained low accuracies of 97.52%, 96.43%, 95.38%, and 94.26%, respectively. Figure 4 illustrates the graphical analysis depicting the precision of the BFL-GO method and the existing methods. The BFL-GO method achieved a high precision of 97.91% while the existing methods such as SWIM, UM-PMS, FMCS, and FEMIS obtained low precisions of 96.89%, 96.17%, 95.34%, and 94.73%, respectively.
In Figure 5, the recall of the BFL-GO method and the existing methods is illustrated by the graphical analysis. The BFL-GO method achieved a high recall of 97.82% while the existing methods such as SWIM, UM-PMS, FMCS, and FEMIS obtained the low recalls of 96.58%, 96.13%, 95.41%, and 94.79%, respectively. Figure 6 represents a graphical analysis illustrating the F1-score of the BFL-GO method and the existing methods. The BFL-GO method attained a high F1-score of 97.86% while the existing methods such as SWIM, UM-PMS, FMCS, and FEMIS obtained low F1-scores of 96.42%, 96.07%, 95.34%, and 94.73%, respectively.
The specificity of the BFL-GO method and the existing methods is represented by the graphical analysis shown in Figure 7. The BFL-GO method achieved a high specificity of 97.85% while the existing methods such as SWIM, UM-PMS, FMCS, and FEMIS obtained low specificities of 96.37%, 95.61%, 94.53%, and 94.16%, respectively. The performance analyses evaluate the effectiveness of the BFL-GO method for disability management in information systems. The results show that the BFL-GO method achieved high precision, recall, accuracy, specificity, and F1-score compared to existing methods.
In Figure 8, the AUC-ROC of the BFL-GO method and the existing methods are illustrated by the graphical analysis. The BFL-GO method achieved a high AUC-ROC of 0.9812 while the existing methods such as SWIM, UM-PMS, FMCS, and FEMIS obtained low AUC-ROCs of 0.9721, 0.9632, 0.9574 and 0.9526, respectively. Figure 9 represents the graphical analysis illustrating the computational time of the BFL-GO method and the existing methods. The BFL-GO method achieved a low computation time of 16 s, while the existing methods such as SWIM, UM-PMS, FMCS, and FEMIS obtained high computation times of 19 s, 22 s, 27 s, and 33 s, respectively.
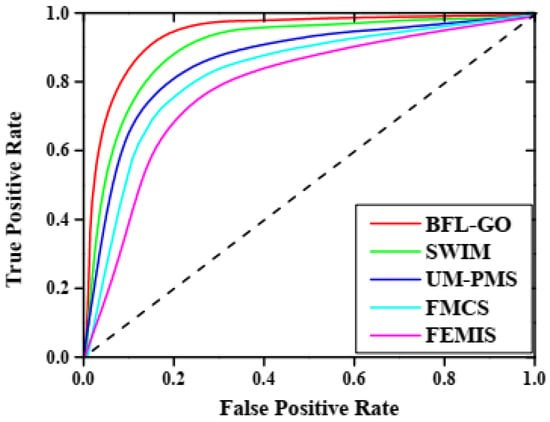
Figure 8.
Performance evaluation based on AUC-ROC.
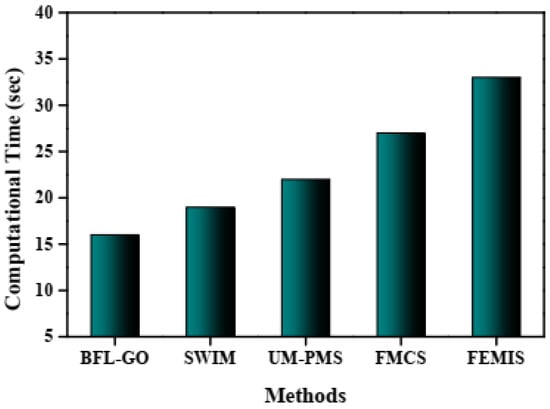
Figure 9.
Graphical analysis based on computational time.
Figure 10 depicts the validation of detection rate. The evaluation determines the ratio of true positive values from the obtained samples. The accurate information was determined by validating with test cases. The evaluation was performed with the proposed BFL-GO and existing SWIM, UM-PMS, FMCS as well as FEMIS techniques. Compared to existing methods, the method proposed attained a better performance by attaining the value of 85.6%.
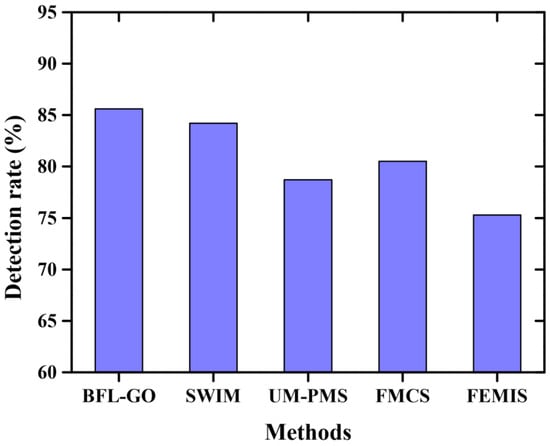
Figure 10.
Validation of detection rate.
The false rate analysis for the proposed and existing methods is delineated in Figure 11. It is highly utilized to detect the faults of information systems in real-world applications. The proposed model’s superior performance is evidenced by its lower results. In this validation, the achieved range of existing methods were 72.6%, 78.5%, 75.4%, and 74.9%, respectively. Meanwhile, the proposed method minimized the false rate at 68.2% and had enhanced performance.
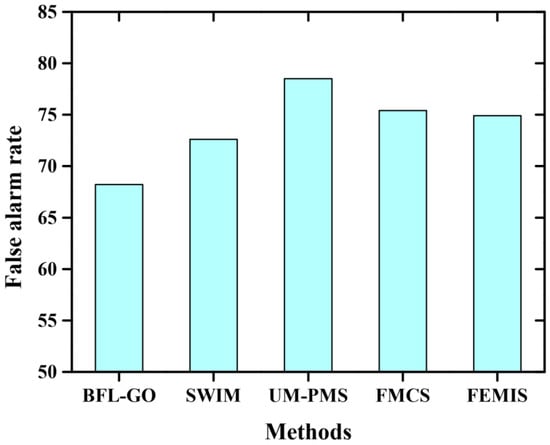
Figure 11.
False alarm rate analysis.
Figure 12 depicts the MSE evaluation to predict the obtained errors in the model. The error validation is performed with the actual as well as the estimated values. We measured the average squares of the error and found that the MSE was equal to zero. However, in the evaluation process, the proposed method diminished the total error by 0.34.
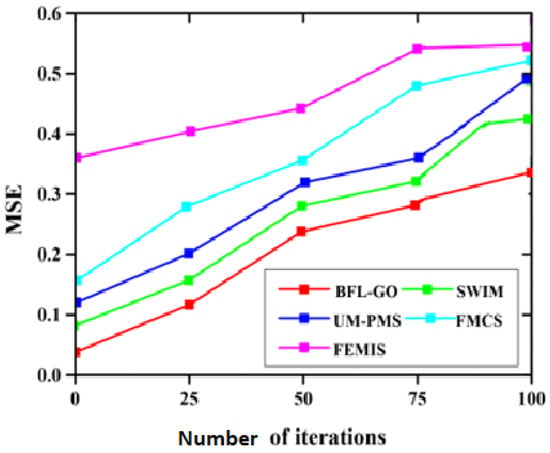
Figure 12.
Evaluation of MSE.
Table 2 depicts the comparison of the BFL-GO method and the existing methods such as SWIM, UM-PMS, FMCS, and FEMIS. The BFL-GO method attained high accuracy, recall, precision, specificity, F1-score, and an AUC-ROC of 98.65%, 97.82%, 97.91%, 97.85%, 97.86%, and 0.9812, respectively. Also, the BFL-GO method achieved a low computation time of 16 s for disability management in information systems.
Table 2.
Comparison of the proposed method with state-of-the-art methods.
The SWIM method obtained accuracy, recall, precision, specificity, F1-score, and AUC-ROC values of 97.52%, 96.58%, 96.89%, 96.37%, 96.42%, and 0.9721, respectively. Also, the SWIM method obtained a high computation time of 19 s compared to the BFL-GO method for disability management in information systems. The UM-PMS method obtained accuracy, recall, precision, specificity, F1-score, and AUC-ROC values of 96.43%, 96.13%, 96.17%, 95.61%, 96.07%, and 0.9632, respectively. Also, the UM-PMS method obtained a high computation time of 22 s compared to the BFL-GO method for disability management in information systems. The FMCS method attained accuracy, recall, precision, specificity, F1-score, and AUC-ROC values of 95.38%, 95.41%, 95.34%, 94.53%, 95.34%, and 0.9574, respectively. Also, the FMCS method obtained a high computation time of 27 s compared to the BFL-GO method for disability management in information systems. The FEMIS method obtained accuracy, recall, precision, specificity, F1-score, and AUC-ROC values of 94.26%, 94.79%, 94.73%, 94.16%, 94.73%, and 0.9526, respectively. Also, the FEMIS method attained a high computation time of 33 s compared to the BFL-GO method for disability management in information systems.
5. Conclusions
This paper proposes a novel method named Bidirectional Federated Learning-based Gradient Optimization (BFL-GO) for disability management in information systems, and it holds significant advantages. In this study, Bi-LSTM was utilized to capture sequential disability data, and federated learning was employed to enable training the BFL-GO method across decentralized and distributed data sources while keeping the data localized and without the need to centralize it. A gradient-based optimizer is used to adjust the proposed BFL-GO method’s parameters during the training process to minimize its loss function. The utilization of the Disability Statistics-United States-2018 dataset, with its diverse and extensive disability data, enhances the BFL-GO method to make informed decisions. The performance of the proposed BFL-GO method was evaluated using different evaluation measures, namely specificity, accuracy, precision, recall, and F1-score, and these results were compared with existing methods such as SWIM, UM-PMS, FMCS, and FEMIS. The BFL-GO method achieved a high accuracy of 98.65%, precision of 97.91%, recall of 97.82%, F1-score of 97.86%, specificity of 97.85%, AUC-ROC of 0.9812, and computational time of 16 s. The results illustrate that the BFL-GO method achieves better results in improving disability management in information systems.
Limitation and Future Scope
A drawback of the suggested method is the complexity of Bidirectional Federated Learning-based Gradient Optimization. This complexity may demand significant computational resources and strong network connections. The method’s effectiveness depends on dataset diversity and size, affecting its applicability in specific contexts. Future advancements in computational power and communication technology may enhance accessibility and efficiency. Exploring the integration of emerging technologies like blockchain or edge computing could improve the methodology’s versatility and dependability. This could open avenues for more extensive applications in disability boards inside data frameworks. Additionally, real-world case studies and user feedback analysis can give significant experiences into the strategy’s ease of use and viability, leading to continuous improvements.
Author Contributions
Conceptualization, S.B.K. and M.A.; Methodology, S.B.K.; Software, M.A.; Validation, M.A.; Formal analysis, S.B.K. and M.A.M.; Data curation, S.B.K.; Writing—original draft, S.B.K.; Writing—review & editing, M.A. and M.A.M.; Visualization, M.A.; Project administration, M.A.M. All authors have read and agreed to the published version of the manuscript.
Funding
The authors extend their appreciation to the King Salman center For Disability Research for funding this work through Research Group no KSRG-2023-394.
Data Availability Statement
The datasets used during the current study are available from the corresponding author on reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lippi, L.; de Sire, A.; Folli, A.; Turco, A.; Moalli, S.; Ammendolia, A.; Maconi, A.; Invernizzi, M. Environmental Factors in the Rehabilitation Framework: Role of the One Health Approach to Improve the Complex Management of Disability. Int. J. Environ. Res. Public Health 2022, 19, 15186. [Google Scholar] [CrossRef] [PubMed]
- Camisa, V.; Gilardi, F.; Di Brino, E.; Santoro, A.; Vinci, M.R.; Sannino, S.; Bianchi, N.; Mesolella, V.; Macina, N.; Focarelli, M.; et al. Return on Investment (ROI) and Development of a Workplace Disability Management Program in a Hospital—A Pilot Evaluation Study. Int. J. Environ. Res. Public Health 2020, 17, 8084. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Dai, W.; Zhang, C.; Zhu, J.; Ma, X. A Compact Constraint Incremental Method for Random Weight Networks and Its Application. IEEE Trans. Neural Netw. Learn. Syst. 2023. [Google Scholar] [CrossRef] [PubMed]
- Jain, A.; Hassard, J.; Leka, S.; Di Tecco, C.; Iavicoli, S. The role of occupational health services in psychosocial risk management and the promotion of mental health and well-being at work. Int. J. Environ. Res. Public Health 2021, 18, 3632. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Li, Y.; Hoque, M.A.; Xia, T.; Tarkoma, S.; Hui, P. To What Extent We Repeat Ourselves? Discovering Daily Activity Patterns Across Mobile App Usage. IEEE Trans. Mob. Comput. 2022, 21, 1492–1507. [Google Scholar] [CrossRef]
- Zhou, X.; Liu, X.; Zhang, G.; Jia, L.; Wang, X.; Zhao, Z. An Iterative Threshold Algorithm of Log-Sum Regularization for Sparse Problem. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 4728–4740. [Google Scholar] [CrossRef]
- Magrin, M.E.; Marini, E.; Nicolotti, M. Employability of disabled graduates: Resources for a sustainable employment. Sustainability 2019, 11, 1542. [Google Scholar] [CrossRef]
- Li, C.; Dong, M.; Xin, X.; Li, J.; Chen, X.; Ota, K. Efficient Privacy-preserving in IoMT with Blockchain and Lightweight Secret Sharing. IEEE Internet Things J. 2023, 10, 22051–22064. [Google Scholar] [CrossRef]
- Prayitno; Shyu, C.R.; Putra, K.T.; Chen, H.C.; Tsai, Y.Y.; Hossain, K.T.; Jiang, W.; Shae, Z.Y. A systematic review of federated learning in the healthcare area: From the perspective of data properties and applications. Appl. Sci. 2021, 11, 11191. [Google Scholar] [CrossRef]
- Gu, X.; Sabrina, F.; Fan, Z.; Sohail, S. A Review of Privacy Enhancement Methods for Federated Learning in Healthcare Systems. Int. J. Environ. Res. Public Health 2023, 20, 6539. [Google Scholar] [CrossRef]
- Cheng, A.S.; Ng, P.H.; Sin, Z.P.; Lai, S.H.; Law, S.W. Smart work injury management (swim) system: Artificial intelligence in work disability management. J. Occup. Rehabil. 2020, 30, 354–361. [Google Scholar] [CrossRef] [PubMed]
- García-Segura, T.; Montalbán-Domingo, L.; Llopis-Castelló, D.; Sanz-Benlloch, A.; Pellicer, E. Integration of Deep Learning Techniques and Sustainability-Based Concepts into an Urban Pavement Management System. Expert Syst. Appl. 2023, 231, 120851. [Google Scholar] [CrossRef]
- Bolaños, C.; Rojas, B.; Salazar-Cabrera, R.; Ramírez-González, G.; de la Cruz, Á.P.; Molina, J.M.M. Fleet management and control systems for developing countries implemented with Intelligent Transportation Systems (ITS) services. Transp. Res. Interdiscip. Perspect. 2022, 16, 100694. [Google Scholar] [CrossRef]
- Sprunt, B.; Marella, M. Combining child functioning data with learning and support needs data to create disability-identification algorithms in Fiji’s Education Management Information System. Int. J. Environ. Res. Public Health 2021, 18, 9413. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.K.; Park, J. Examination of the protection offered by current accessibility acts and guidelines to people with disabilities in using information technology devices. Electronics 2020, 9, 742. [Google Scholar] [CrossRef]
- Alshammari, M.; Doody, O.; Richardson, I. Software Engineering Issues: An exploratory study into the development of Health Information Systems for people with Mild Intellectual and Developmental Disability. In Proceedings of the 2020 IEEE First International Workshop on Requirements Engineering for Well-Being, Aging, and Health (REWBAH), Zurich, Switzerland, 31 August 2020; pp. 67–76. [Google Scholar]
- Chiscano, M.C. Improving the design of urban transport experience with people with disabilities. Res. Transp. Bus. Manag. 2021, 41, 100596. [Google Scholar] [CrossRef]
- Elfakki, A.O.; Sghaier, S.; Alotaibi, A.A. An Efficient System Based on Experimental Laboratory in 3D Virtual Environment for Students with Learning Disabilities. Electronics 2023, 12, 989. [Google Scholar] [CrossRef]
- Algarni, M.; Saeed, F.; Al-Hadhrami, T.; Ghabban, F.; Al-Sarem, M. Deep learning-based approach for emotion recognition using electroencephalography (EEG) signals using bi-directional long short-term memory (Bi-LSTM). Sensors 2022, 22, 2976. [Google Scholar] [CrossRef]
- Hu, K.; Li, Y.; Xia, M.; Wu, J.; Lu, M.; Zhang, S.; Weng, L. Federated learning: A distributed shared machine learning method. Complexity 2021, 2021, 8261663. [Google Scholar] [CrossRef]
- Deb, S.; Abdelminaam, D.S.; Said, M.; Houssein, E.H. Recent methodology-based gradient-based optimizer for economic load dispatch problem. IEEE Access 2021, 9, 44322–44338. [Google Scholar] [CrossRef]
- Available online: https://www.kaggle.com/datasets/michaelacorley/disability-statistics-united-states-2018 (accessed on 1 August 2023).
- Chen, M.; Xu, Y.; Xu, H.; Huang, L. Enhancing Decentralized Federated Learning for Non-IID Data on Heterogeneous Devices. In Proceedings of the 2023 IEEE 39th International Conference on Data Engineering (ICDE), Anaheim, CA, USA, 3–7 April 2023. [Google Scholar] [CrossRef]
- Mhaisen, N.; Awad, A.; Mohamed, A.M.; Erbad, A.; Guizani, M. Analysis and Optimal Edge Assignment for Hierarchical Federated Learning on Non-IID Data. arXiv 2020, arXiv:2012.05622. [Google Scholar]
- Sun, J.; Chen, T.; Giannakis, G.B.; Yang, Q.; Yang, Z. Lazily Aggregated Quantized Gradient Innovation for Communication-Efficient Federated Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2031–2044. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Jiao, L.; Zhu, K.; Lin, X.; Li, L. Toward Sustainable AI: Federated Learning Demand Response in Cloud-Edge Systems via Auctions. In Proceedings of the IEEE INFOCOM 2023—IEEE Conference on Computer Communications, New York City, NY, USA, 17–20 May 2023; pp. 1–10. [Google Scholar] [CrossRef]
- Gerges, F.; Shih, F.; Azar, D. Automated diagnosis of acne and rosacea using convolution neural networks. In Proceedings of the 2021 4th International Conference on Artificial Intelligence and Pattern Recognition, Xiamen, China, 20–21 September 2023. [Google Scholar] [CrossRef]
- Lian, Z.; Zeng, Q.; Wang, W.; Gadekallu, T.R.; Su, C. Blockchain-based two-stage federated learning with non-IID data in IoMT system. IEEE Trans. Comput. Soc. Syst. 2022, 10, 1701–1710. [Google Scholar] [CrossRef]
- Rani, S.; Babbar, H.; Srivastava, G.; Gadekallu, T.R.; Dhiman, G. Security Framework for Internet of Things based Software Defined Networks using Blockchain. IEEE Internet Things J. 2022, 10, 6074–6081. [Google Scholar] [CrossRef]
- Chahoud, M.; Sami, H.; Mourad, A.; Otoum, S.; Otrok, H.; Bentahar, J.; Guizani, M. ON-DEMAND-FL: A Dynamic and Efficient Multi-Criteria Federated Learning Client Deployment Scheme. IEEE Internet Things J. 2023, 10, 15822–15834. [Google Scholar] [CrossRef]
- Sirine, T.; Abbas, N. Hybrid Machine Learning Classification and Inference of Stalling Events in Mobile Videos. In Proceedings of the 2022 4th IEEE Middle East and North Africa COMMunications Conference, Amman, Jordan, 6–8 December 2022; pp. 209–214. [Google Scholar] [CrossRef]
- Wehbi, O.; Arisdakessian, S.; Wahab, O.A.; Otrok, H.; Otoum, S.; Mourad, A.; Guizani, M. FedMint: Intelligent Bilateral Client Selection in Federated Learning with Newcomer IoT Devices. IEEE Internet Things J. 2023, 1, 20884–20898. [Google Scholar] [CrossRef]
- Ibrahim, J.N.; Audi, L. Anxiety Symptoms among Lebanese Health-care Students: Prevalence, Risk Factors, And Relationship With Vitamin D Status. J. Health Sci. 2021, 11, 29–36. [Google Scholar] [CrossRef]
- Khouloud, S.; El Akoum, F.; Tekli, J. Unsupervised knowledge representation of panoramic dental X-ray images using SVG image-and-object clustering. Multimed. Syst. 2023, 29, 2293–2322. [Google Scholar] [CrossRef]
- Hassan, H.F.; Koaik, L.; Khoury, A.E.; Atoui, A.; El Obeid, T.; Karam, L. Dietary exposure and risk assessment of mycotoxins in thyme and thyme-based products marketed in Lebanon. Toxins 2022, 14, 331. [Google Scholar] [CrossRef]
- Judith, A.M.; Priya, S.B.; Mahendran, R.K.; Gadekallu, T.R.; Ambati, L.S. Two-phase classification: ANN and A-SVM classifiers on motor imagery BCI. Asian J. Control 2022, 25, 3318–3329. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).